【机器学习深度学习】魔塔社区模型后缀全解析:Base、Chat、Instruct、Bit、Distill背后的技术密码
目录
前言
一、后缀背后的技术逻辑
二、核心后缀详解
1. Base:基石模型
2. Chat:对话专家
3. Instruct:指令执行者
4. Bit:量化精简版
5. Distill:知识精华
6. Tiny / Small / Medium / Large / XL
7. Ada / Babbage / Curie / Davinci
小结:对比表
三、进阶后缀解析
1. MoE(Mixture of Experts):专家联盟
2. Multimodal:多面手
3. SFT/RLHF:对齐技术双雄
四、模型名称解密实战
五、最佳实践建议
1、实验优先原则
2、硬件匹配指南
3、进阶使用技巧
结语

前言
在魔塔社区(ModelScope)探索AI模型时,你是否曾被各种后缀搞得眼花缭乱?这些看似简单的标签背后,隐藏着模型的核心能力和技术特性。本文将为你彻底解密这些"模型密码",助你精准选择最适合的AI工具!
不管是在魔塔社区,还是hugging平台,可以发现里面有很多模型,但是都加了不同类型的后缀,这篇文章就是对这些模型的后缀的意义进行全面解析,以便读者能够更加高效的选择合适的模型。
下图是魔塔社区的“模型库”页面: 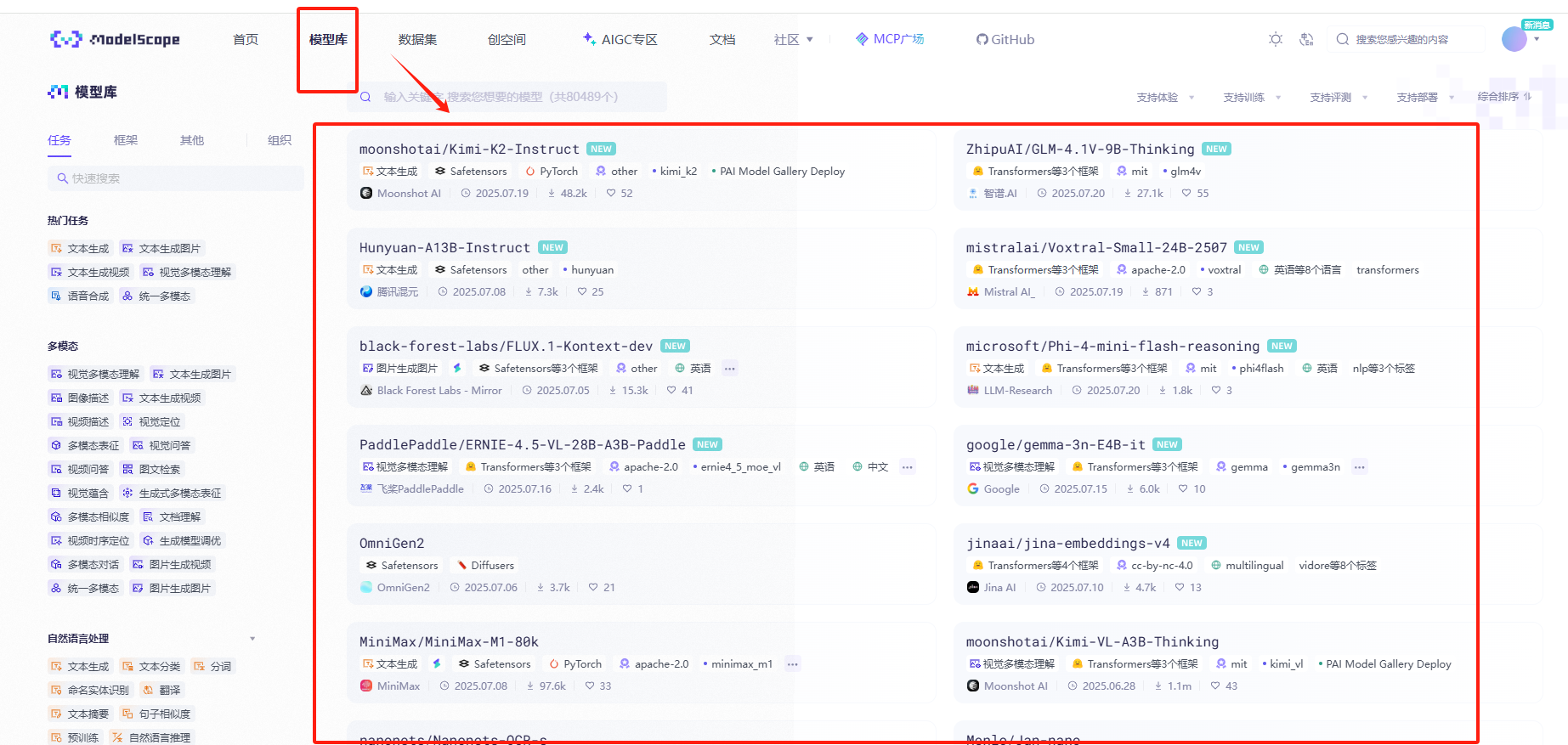
一、后缀背后的技术逻辑
在AI模型开发中,模型后缀是开发团队精心设计的"功能标识",它直观传达了三个关键信息:
-
训练方法:模型如何获得能力(预训练、微调、蒸馏等)
-
功能定位:模型擅长什么任务(对话、指令执行、多模态等)
-
部署特性:模型的运行效率(量化压缩、专家结构等)
理解这些后缀,能让你在数百个模型中快速锁定目标,就像掌握了解锁模型宝库的密钥。
二、核心后缀详解
1. Base:基石模型
-
技术本质:在大规模通用语料上预训练的原始模型
-
训练数据:通常使用万亿token级的网页、书籍、代码等
-
特点:
-
通用语言理解能力强
-
未经过任务优化
-
参数量大(7B-72B+)
-
-
典型代表:
Qwen-7B-Base,LLaMA-3-8B-Base -
适用场景:
-
作为下游任务的预训练基座
-
研究人员进行模型架构实验
-
需要最大程度控制微调过程的场景
-
💡 专业建议:Base模型如同"未雕琢的玉石",需要配合特定数据微调才能发挥最大价值。
2. Chat:对话专家
-
技术本质:Base模型+对话数据微调+人类偏好优化
-
关键训练技术:
-
SFT(监督微调)
-
RLHF(人类反馈强化学习)
-
DPO(直接偏好优化)
-
-
特点:
-
流畅的多轮对话能力
-
理解上下文和人类意图
-
安全内容过滤机制
-
-
典型代表:
Qwen1.5-14B-Chat,DeepSeek-VL-Chat -
适用场景:
-
智能客服机器人
-
社交陪伴应用
-
语音助手后台
-

3. Instruct:指令执行者
-
技术本质:针对指令-响应对优化的模型
-
关键训练数据:
-
人工编写的指令样本
-
高质量任务数据集(如FLAN集合)
-
-
特点:
-
精准执行复杂指令
-
结构化输出能力(JSON/XML/表格)
-
多步骤任务分解能力
-
-
典型代表:
DeepSeek-Coder-Instruct,LLaMA-3-70B-Instruct -
适用场景:
-
自动化工作流
-
数据分析报告生成
-
工具调用(Function Calling)
-
🤖 Chat vs Instruct:
Chat模型更擅长开放式对话,Instruct模型更擅长精确执行具体任务。新一代模型(如Qwen1.5)正融合这两种能力。
4. Bit:量化精简版
-
技术本质:通过降低参数精度减小模型体积
-
量化技术:
-
GPTQ(GPU优化)
-
GGML(CPU优化)
-
AWQ(激活感知量化)
-
-
精度对比:
精度 显存节省 性能损失 典型用途 FP16 0% 0% 研究开发 8bit 50% <1% 本地部署 4bit 75% 2-5% 移动设备 -
典型代表:
Phi-2-mini-4bit,Qwen1.5-1.8B-8bit -
适用场景:
-
手机端AI应用
-
低显存GPU推理
-
边缘计算设备
-
5. Distill:知识精华
-
技术本质:知识蒸馏技术提取的小模型
-
训练过程:
-
大模型(教师)生成软标签
-
小模型(学生)模仿教师行为
-
通过损失函数对齐输出分布
-
-
特点:
-
体积比教师小50-70%
-
推理速度提升3-5倍
-
保留80-90%原模型能力
-
-
典型代表:
DistilBERT,TinyLlama-1.1B -
适用场景:
-
实时响应系统
-
大规模模型服务
-
成本敏感型应用
-
6. Tiny / Small / Medium / Large / XL
-
含义:这些后缀表示模型的 大小,通常与模型的参数数量或计算能力相关。
Tiny表示最小、最轻量的版本,而XL表示超大版本。 -
用途:不同大小的模型适用于不同的硬件和任务。例如,
Tiny和Small模型适合资源受限的环境,而Large或XL模型适合需要更高性能的任务。 -
示例:
LLaMA-7B-Tiny或LLaMA-7B-XL,后者比前者的参数更多,计算能力更强。
7. Ada / Babbage / Curie / Davinci
-
含义:这些名称通常用于 OpenAI GPT 系列模型,表示不同大小的模型。它们通常用来指代不同规模的 GPT 模型,例如:
-
Ada: 轻量级版本 -
Babbage: 中等版本 -
Curie: 大型版本 -
Davinci: 最大版本
-
-
用途:这些模型的性能逐渐提升,适合不同规模的计算任务。
小结:对比表
以下表格总结了 Base、Chat、Instruct、Bit 和 Distill 后缀的含义和特性:
| 后缀 | 定义 | 训练方式 | 特点 | 应用场景 | LLaMA-Factory 支持 |
|---|---|---|---|---|---|
| Base | 预训练模型,未微调 | 大规模文本预训练 | 通用语言能力,需提示工程或微调 | 研究、自定义微调 | 支持加载 Base 模型(如 LLaMA-3) |
| Chat | 对话优化模型 | 对话数据微调 | 自然对话,保持上下文 | 聊天机器人、虚拟助手 | 支持 Chat 模板(如 vicuna) |
| Instruct | 指令优化模型 | 指令-响应对微调 | 任务导向,精准执行指令 | 代码生成、翻译、摘要 | 支持 Instruct 模板(如 ### Instruction) |
| Bit | 量化模型 | 降低存储精度(如 4bit、8bit) | 低资源占用,快速推理 | 边缘设备、低成本部署 | 支持 GGUF 等量化格式 |
| Distill | 蒸馏模型 | 知识蒸馏,从大模型到小模型 | 小模型高性能,效率高 | 高效部署、资源受限场景 | 支持加载蒸馏模型(如 SmolLM) |
在魔塔社区或 LLaMA-Factory 环境中,模型后缀(如 Base、Chat、Instruct、Bit、Distill)反映了模型的训练方式和优化目标:
- Base 是未经微调的通用模型,适合研究。
- Chat 优化对话,适合交互式场景。
- Instruct 优化任务执行,适合指令导向应用。
- Bit 表示量化模型,优化了存储和计算性能。适合资源受限环境。
- Distill 表示通过知识蒸馏生成的小型高效模型。
- Tiny/Small/Medium/Large/XL:表示模型大小和计算能力的不同级别。
三、进阶后缀解析
1. MoE(Mixture of Experts):专家联盟
-
技术亮点:
-
模型由多个专家子网络组成
-
每轮推理仅激活部分专家
-
参数量≠计算量(如Mixtral-8x7B实际激活12.9B参数)
-
-
优势:
-
同等计算量下性能更强
-
支持更大知识容量
-
-
代表模型:
Mixtral-8x7B-MoE,Qwen1.5-MoE-A2.7B
2. Multimodal:多面手
-
支持模态:
-
文本+图像(如Qwen-VL)
-
文本+音频(如Whisper)
-
文本+视频(如Video-LLaMA)
-
-
技术架构:
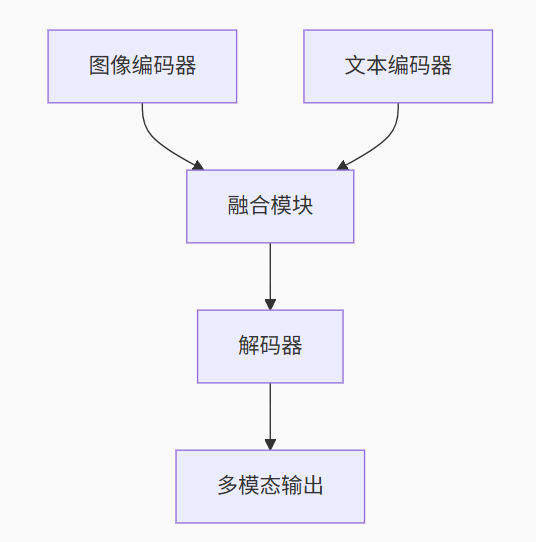
-
代表模型:
Qwen-VL-Chat,DeepSeek-VL
3. SFT/RLHF:对齐技术双雄
| 技术 | 全称 | 作用 | 训练复杂度 |
|---|---|---|---|
| SFT | 监督微调 | 使用标注数据优化输出 | 中等 |
| RLHF | 人类反馈强化学习 | 基于人类偏好优化模型 | 高 |
四、模型名称解密实战
案例解析:Qwen1.5-72B-Chat-AWQ
-
Qwen1.5:模型家族(通义千问1.5代架构) -
72B:参数量(720亿参数) -
Chat:对话优化版本 -
AWQ:量化算法(激活感知权重量化)
选择指南:
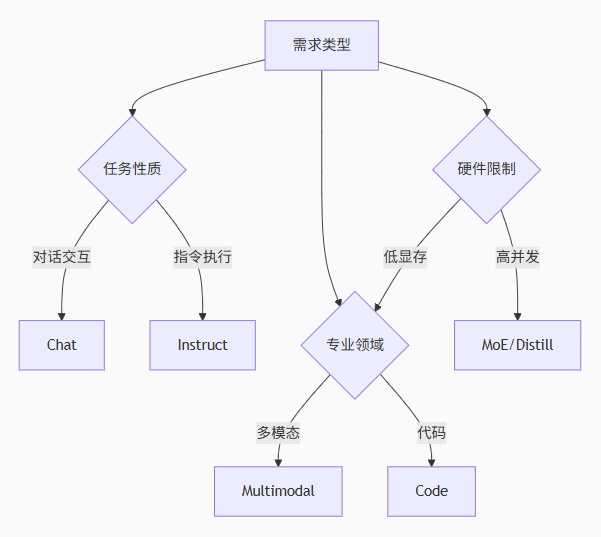
五、最佳实践建议
1、实验优先原则
# 使用魔塔社区测试API快速验证模型
from modelscope import AutoModelForCausalLM
model = AutoModel.for_pretrained('qwen/Qwen1.5-7B-Chat')2、硬件匹配指南
| 设备 | 推荐模型类型 | 典型配置 |
|---|---|---|
| 手机 | 4bit量化 | 2-4GB内存 |
| 笔记本 | 8bit量化 | 8-16GB内存+入门GPU |
| 服务器 | Base/MoE | A100/H100集群 |
3、进阶使用技巧
-
组合使用
Base+LoRA实现低成本领域适配 -
对
Instruct模型添加系统提示提升任务精度 -
使用
FlashAttention加速MoE模型推理
结语
掌握模型后缀的"密码本",你就能在魔塔社区的模型海洋中精准导航。技术发展日新月异,新的后缀如MoA(混合专家注意力)、Long(长上下文优化)等不断涌现。建议持续关注魔塔社区官方文档获取最新动态。
行动号召:现在打开ModelScope,用
qwen1.5-14b-chat模型创建一个对话机器人,体验后缀带来的能力差异吧!遇到有趣发现,欢迎在评论区分享交流~