JVM-Java
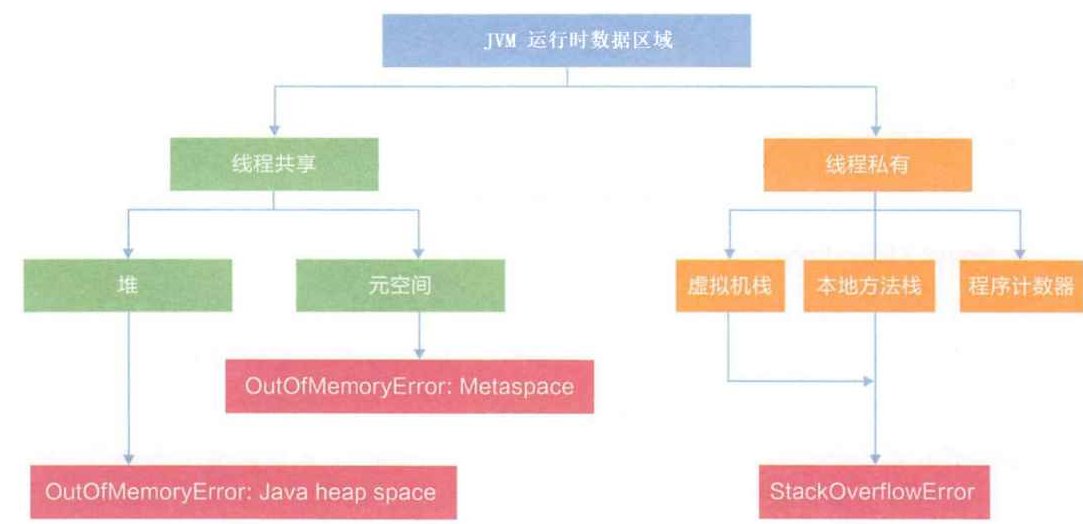
JVM内存区域划分
为啥要划分区域?
JVM-Java虚拟机,是仿照真实的机器,真实的操作系统进行设计的;
而真实的操作系统中,对于进程的地址空间是进行了分区域的设计;
JVM也就仿照了操作系统的情况,也进行了分区域的设计;
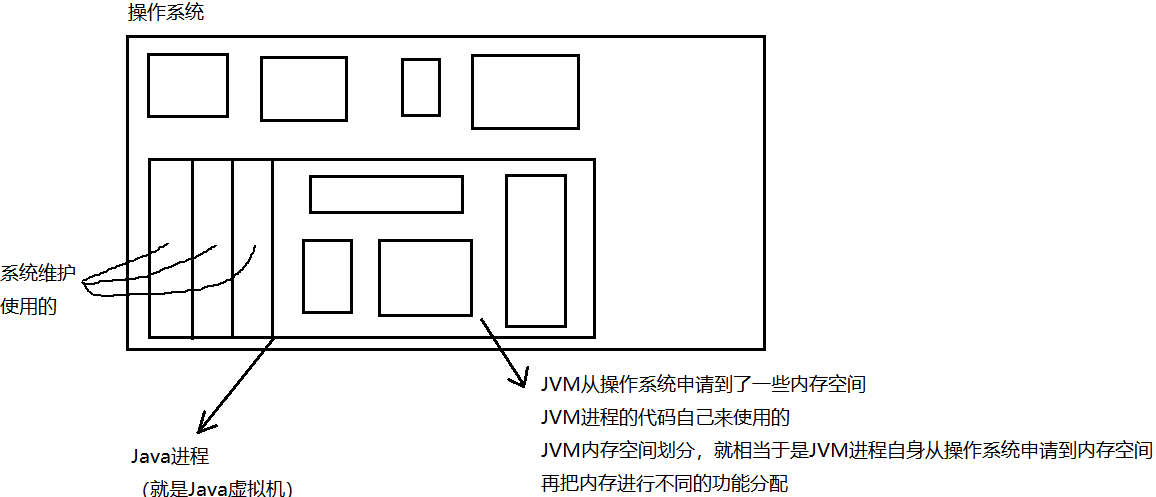
那具体是怎么划分的呢?
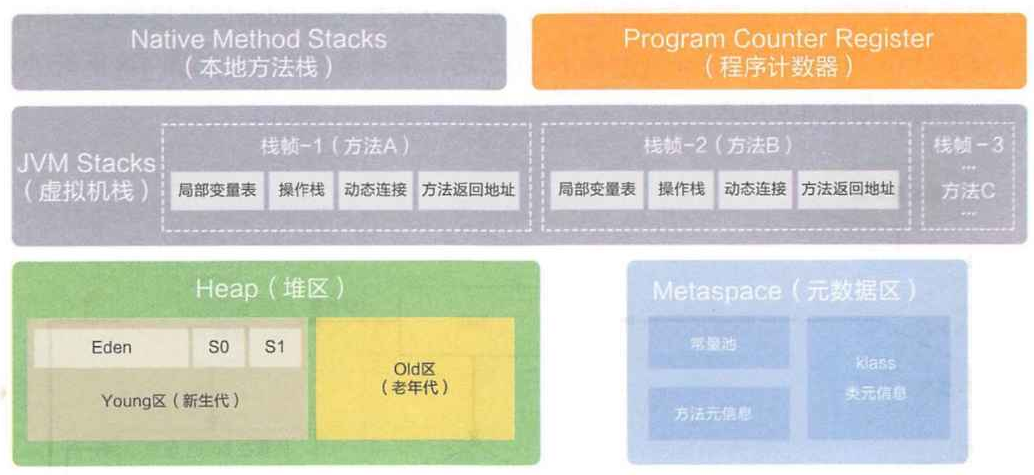
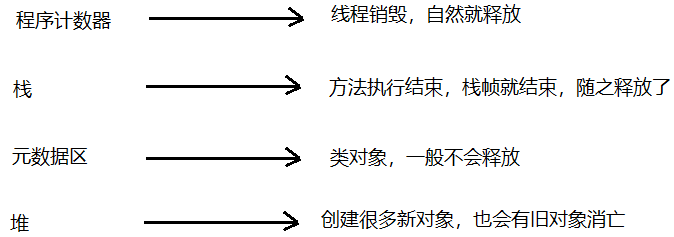
线程计数器
程序计数器的作用:用来记录当前线程执行的行号的。
程序计数器是一块比较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。
如果当前线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址,如果正在执行的是一个Native方法,这个计数器值位空。
元数据区
元数据区的作用:用来存储被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据的。元信息:指的就是一些属性。比如,类叫啥名字,是不是public,继承自哪些类,实现了哪些接口方法叫啥名字,参数有几个,都叫啥,都是啥类型,返回值是啥类型。
虚拟机栈
保存方法的调用关系;
Java虚拟机栈的作用:Java虚拟机栈的生命周期和线程相同,Java虚拟机栈描述的是Java方法执行 的内存模型:每个方法在执行的同时都会创建一个栈帧(StackFrame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈;
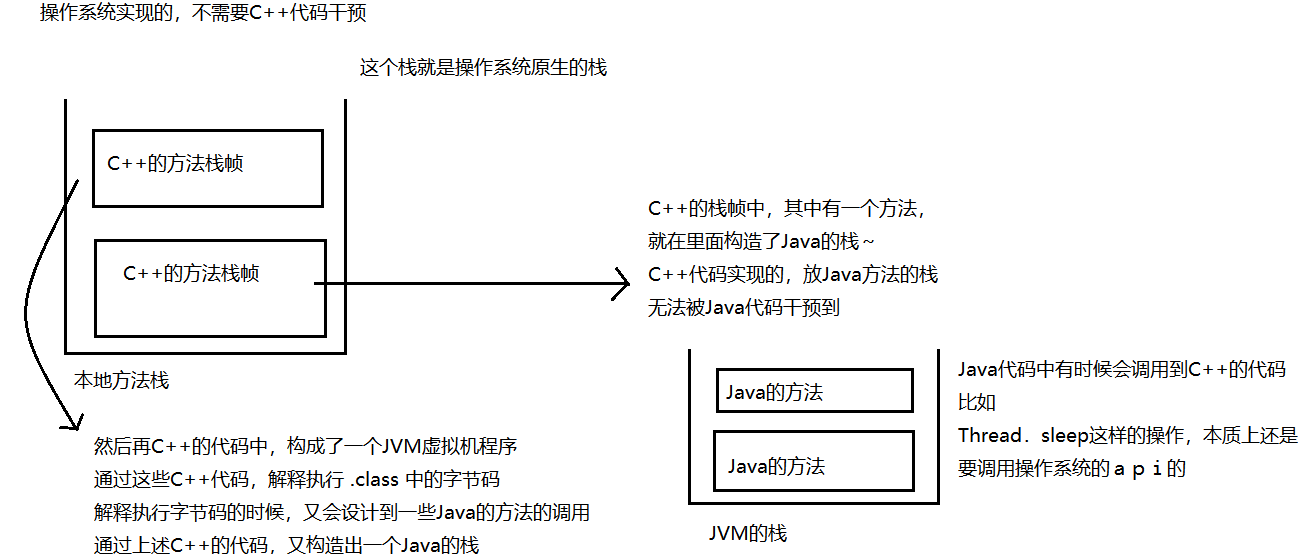
Java虚拟机中包含了以下四个部分:
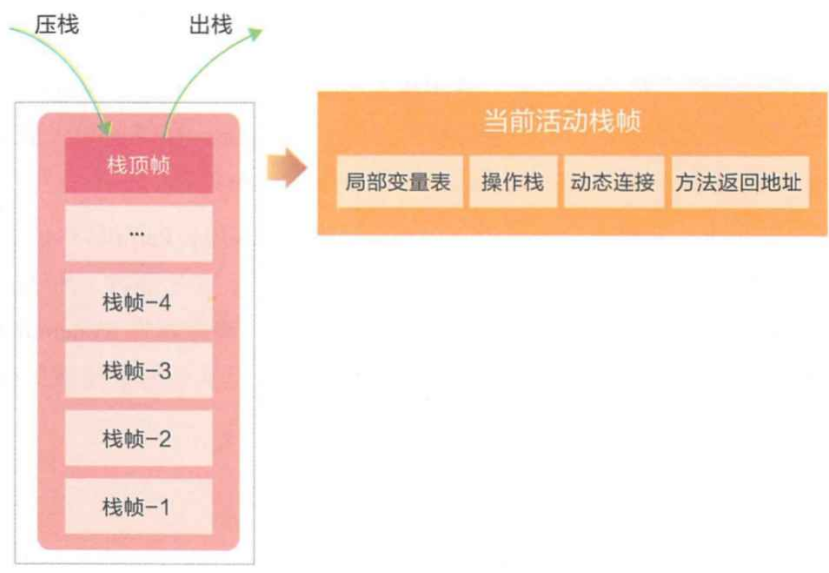
- 局部变量表: 存放了编译器可知的各种基本数据类型(8⼤基本数据类型)、对象引⽤。局部变量表所需的内存空间在编译期间完成分配,当进⼊⼀个⽅法时,这个⽅法需要在帧中分配多⼤的局部变量空间是完全确定的,在执⾏期间不会改变局部变量表⼤⼩。简单来说就是存放⽅法参数和局部变量。
- 操作栈:每个⽅法会⽣成⼀个先进后出的操作栈。
- 动态链接:指向运⾏时常量池的⽅法引⽤。
- ⽅法返回地址:PC 寄存器的地址
堆
堆的作用:程序中创建的所有对象都保存在堆中。(保存 new 的对象的)
Test t = new Test();
- 如果 t 是一个 局部变量,t 就在栈上;
- 如果 t 是一个 成员变量,t 就在堆上;
- 如果 t 是一个 静态成员变量,t 就在元数据区上;
堆是JVM中最大的空间区域了。往集合类里面添加元素,如果堆上的对象,不再使用了,就需要被释放掉(垃圾回收)
元数据区和堆,整个Java进程共同用一份。
程序计数器和栈一个进程中可能有多份。(每个线程有一份)
JVM类加载
类加载本身是一个复杂的事情,但从面试的角度,主要关心两个方面:1.类加载步骤有哪些 2.类加载中的“双亲委派模型”是咋回事;
类加载步骤
对于⼀个类来说,它的⽣命周期是这样的:
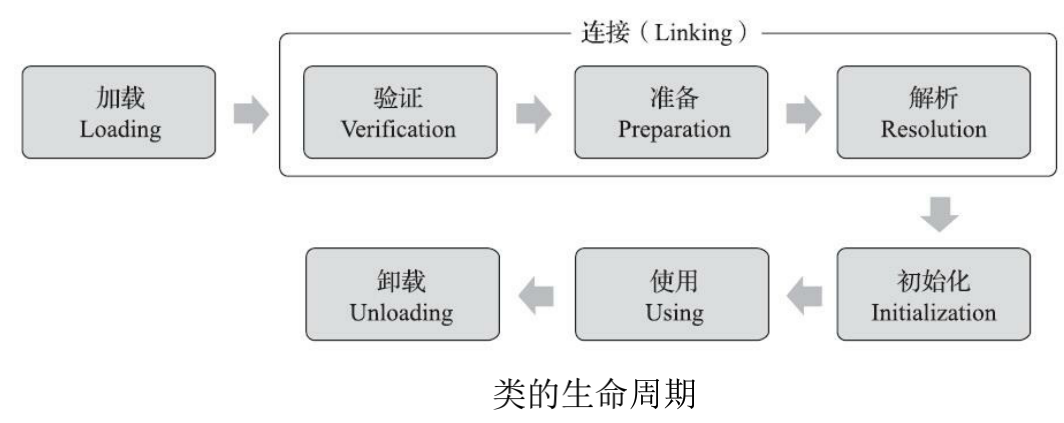
- 加载:找到 .class 文件。根据类的全限定名(包名+类名,形如java.lang.String)打开文件,读取文件内容到内存里。
- 验证:解析,校验 .class 文件读到的内容,是否是合法的,并且把这里的内容转成 结构化的数据。
- 准备:给类对象申请内存空间。(此处申请的内存空间,相当于是“全0”空间)
- 解析:针对字符串常量,进行初始化。字符串常量,本身就包含在 .class 文件中,就需要 .class 文件里解析出来的字符串常量放到内存空间里(元数据区,常量池中)。
- 初始化:针对刚才谈到的类对象进行最终的初始化,针对类对象的各种属性进行填充,包括类中的静态成员,如果这个类还有父类,并且父类还没有加载,此环节也会触发父类的类加载。

类加载触发的时机:

双亲委派模型
类加载器:JVM中有专门的模块,负责加载类;
JVM默认提供了三种类加载器:
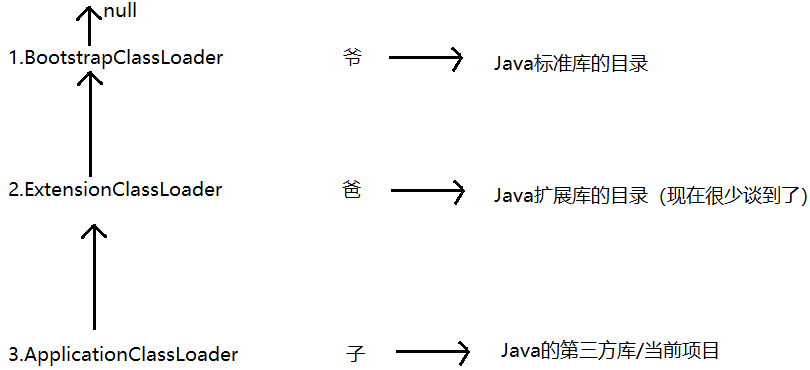
这三个类加载器,负责找的目录的范围是不同的。
此处的“父子关系”不是“父类子类”,而是通过parent这样的引用指向;
这三个类加载器,首当其冲的就是要进行“找.clas”文件环节。
双亲委派的过程:
- 进行类加载,通过全限定类名,找 .class 的时候就会从ApplicationClassLoader 作为入口开始,然后把 加载类 这样的任务,委托给 父亲ExtensionClassLoader 来进行;
- ExtensionClassLoader 也不会立即进行查找,而是也委托给 父亲 来进行,BootstrapClassLoader。
- BootstrapClassLoader 也想委托给父亲来进行,由于没有父亲,只能自己进行类加载,根据类名,找标准库范围,是否存在匹配的 .class 文件;
- BootstrapClassLoader 没有找到,再把任务还给孩子 ExtensionClassLoader,接下来ExtensionClassLoader 来负责进行找 .class 文件的过程,找到就加载,没找到,也就把任务还给孩子 ApplicationClassLoader ;
- 接下来 ApplicationClassLoader 负责找 .class 文件,找到就加载,没找到就抛出异常。
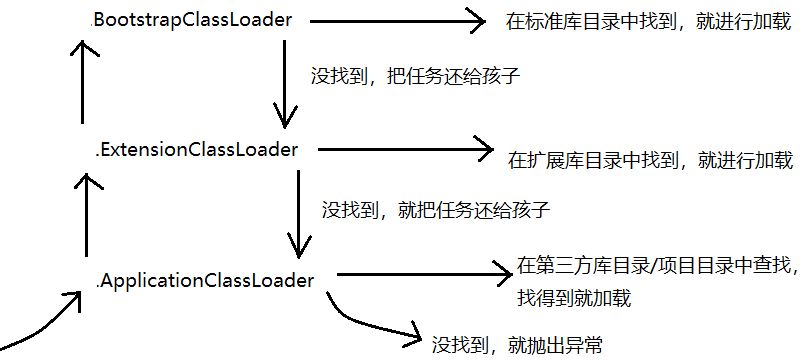
这一套流程,目的是为了约定”优先级“收到一个类名之后,一定是现在标准库中找,再到扩展库中找,最后才是第三方库找。
给出的这三个类加载器,是属于JVM自带的,程序员是可以自定义类加载器的,当你自定义的时候,就可以把你的类加载器,也放到双亲委派模型中,也可以不放到里面。Tomcat(Java中知名的HTTP服务器)的内部就有自定义的类加载器(从指定的webapps目录加载对应的类)。(由于现在用的SpringMVC内置了 tomcat,用的时候感知不到了)
双亲委派模型的优点:
- 避免重复加载类:⽐如 A 类和 B 类都有⼀个⽗类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进⾏加载时就不需要在重复加载 C 类了。
- 安全性:使⽤双亲委派模型也可以保证了 Java 的核⼼ API 不被篡改,如果没有使⽤双亲委派模 型,⽽是每个类加载器加载⾃⼰的话就会出现⼀些问题,⽐如我们编写⼀个称为 java.lang.Object 类的话,那么程序运⾏的时候,系统就会出现多个不同的 Object 类,⽽有些 Object 类⼜是⽤⼾⾃⼰提供的因此安全性就不能得到保证了。
垃圾回收(GC)
垃圾回收是Java中释放内存的手段。就像C语言中,申请内存malloc,申请之后,一定要手动调用free进行释放,否则会出现内存泄漏。由于手动释放内存,太麻烦,太容易出错了,所以Java引入垃圾回收,进行自动释放。JVM会自动识别出某个内存,是不是后续不再使用了,从而自动释放。
(GC的代价是会对程序运行的效率产生影响,此外GC中还有一个臭名昭著的STW(stop the world)问题:触发大规模GC,就可能会因为GC使得其他业务代码不得不暂停下来,等待GC结束再继续走了。)
GC回收的是JVM中堆内存区域:
所以说是“回收内存”,其实是回收堆中的对象。
GC工作过程:
- 找到垃圾(不再使用的对象);
- 释放垃圾(对应的内存释放掉);
找到垃圾
找到垃圾有两种方法:
**引用计数[**python,php采用了这个方案]
每个对象在new 的时候,都搭配一个小的内存空间,保存一个整数。
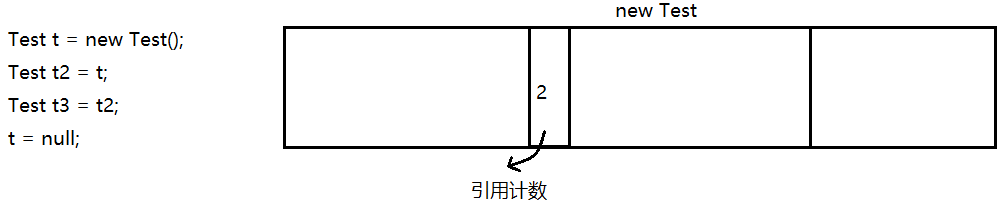
这个整数就表示当前对象,有多少个引用指向它。
每次进行引用赋值的时候,都会自动触发引用计数的修改,通过引用计数记录有多少个引用。
在Java中,要想使用某个对象,一定是通过引用来完成的。如果引用计数为0了,就说明没有引用指向这个对象了,这个对象就是垃圾。
缺点:
内存消耗的更多。
尤其是对象本身比较小,引用计数消耗的空间的比例就更大。
假设引用计数是4个字节,对象本身是8个字节,那么引用计数就相当于提高了50%的空间占用率
可能出现“循环引用”这样的问题。
class Test{Test t = null; } Test a = new Test(); Test b = new Test(); a.t = b; b.t = a; a = null; b = null;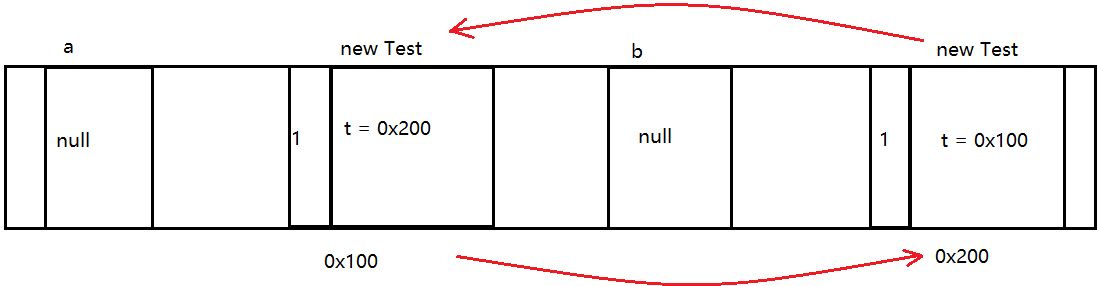
此时,这俩对象的引用,都不为0,虽然不为0,但这俩对象都无法使用。类似死锁。
Python,PHP虽然使用引用计数,但是需要搭配其他的方案,辅助解决上述的引用计数的循环引用问题。
**可达性分析[**Java采用了这个方案]
引用计数,是有空间开销。可达性分析,是时间换空间。
具体步骤:
以代码中的一些特定对象,作为遍历的“起点” ⇒ GCRoots
- 栈上的局部变量(引用类型)
- 常量池引用指向的对象
- 静态成员(引用类型)
这三个是程序运行到任何一个时刻,JVM都是容易获取到的。
尽可能的进行遍历,判定某个对象是否能访问到。
每次访问到一个对象,都会把这个对象标记成“可达”,当完成所有对象的遍历之后,未被标记成“可达”的对象就是“不可达”。
JVM一共有多少个对象,JVM自身是知道的,通过可达性分析,知道了哪些是“可达”的,剩下的就是“不可达”,也就是接下来要回收的垃圾。
可达性分析很像“树”结构的遍历或者“图”结构的遍历。
例子:
class Node{private String val;private Node left;private Node right;public Node(String val){this.val = val;} } Node build(){Node a = new Node("a");Node b = new Node("b");Node c = new Node("c");Node d = new Node("d");Node e = new Node("e");Node f = new Node("f");Node g = new Node("g");a.left = b;a.right = c;b.left = d;b.right = e;e.left = g;c.right = f;return a; } Node root = build();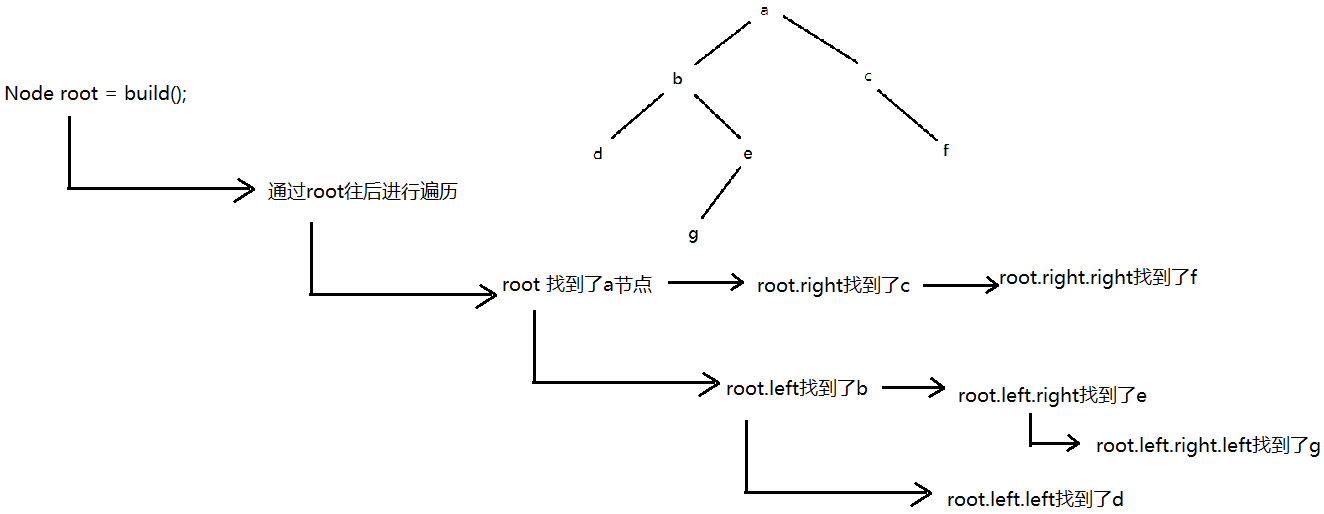
root.right.right = null;这样的操作就会使f不可达,在下一轮GC过程中,此处的f就会被当作垃圾。(可达性分析,这个过程是“周期性”每隔一定的时间,触发一次这样的可达性分析的遍历)
释放垃圾
当前已经知道哪些对象是垃圾了,如何进行释放呢?
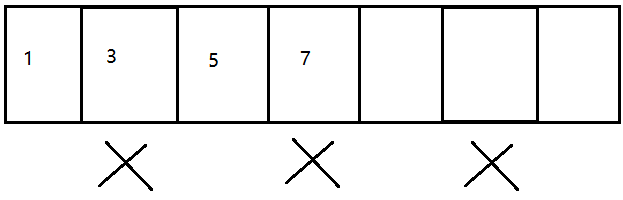
标记-清除算法
把垃圾对象的内存,直接进行释放。但这样做会产生内存碎片问题。
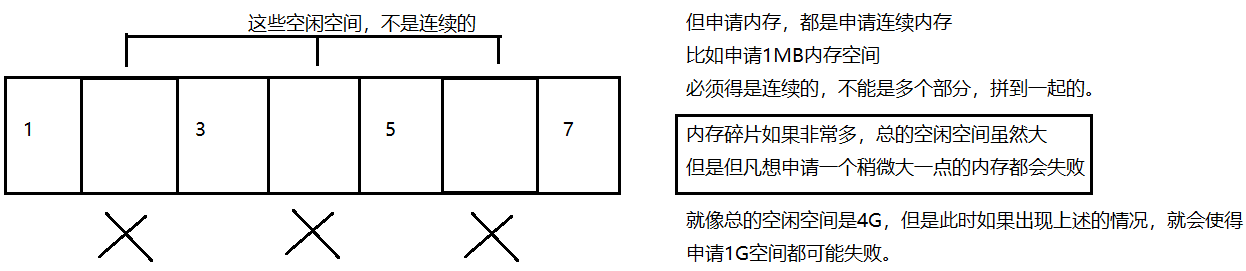
复制算法
将可⽤内存按容量划分为⼤⼩相等的两块,一次只使用其中的一半,把不是垃圾的对象,拷贝到另一侧,然后在把这一侧给整体的释放掉。此时可以确保,空闲的内存就都是连续的了。
缺点:
- 内存的空间利用率是很低的;
- 一旦不是垃圾的对象较多,复制的成本就会很高。(尤其是这样的对象中包含大的对象的时候)
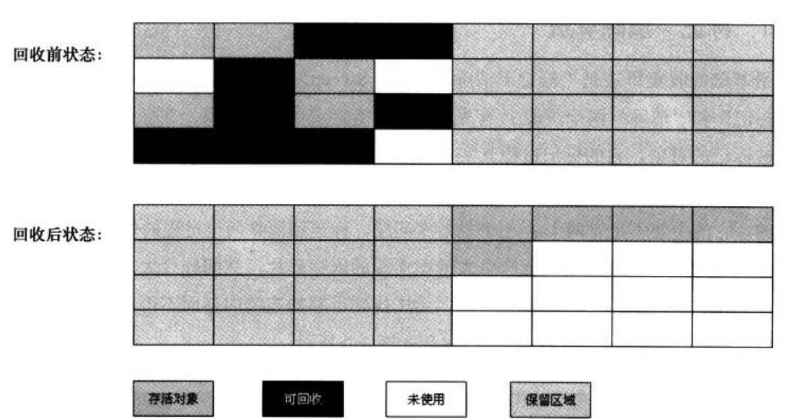
标记-整理算法
标记过程仍与"标记-清除"过程⼀致,但后续步骤不是直接对可回收对象进⾏清理,⽽是让所有存活对象都向⼀端移动,然后直接清理掉端边界以外的内存。
优点:解决内存碎片以及保证内存利用率
缺点:内存搬运数据的操作,开销是挺大的。(复制成本的问题任然还在)
分代回收算法(Java给出的答卷,把上面的123(主要是23)结合起来,扬长避短)
代:对象的年龄;
某个对象,经历一轮GC可达性分析之后,不是垃圾;此时对象的年龄就+1;初始情况是0;

针对不同的年龄的对象采取不同的策略,因为不同年龄的对象,特点是不同的~
如果某个对象,已经是一个年龄大的对象了,此时大概率还会继续存在很久,毕竟要死早就死了,之所以现在还没死,说明这个东西有特殊之处,大概率以后还会持续存在。
如果一个对象是小年轻,这个对象就很可能快速就挂掉了。
如果一个对象是老油条,这个对象就可能继续存在。
新生代,GC频率就会比较高。
老年代,GC频率就会比较低。
新创建的对象就放到“伊甸区”,绝大部分的伊甸区的对象,活不过第一轮GC。所以幸存区比伊甸区小。
伊甸区 ⇒ 幸存区:复制算法。复制的对象规模是很少,因此复制的开销是可控的。
幸存区中的对象,也要经历GC的扫描。每一轮GC都会消灭一大部分对象,剩余的对象再次通过复制算法,复制到另一个幸存区。如果这个对象在幸存区中经历了多次复制,都存活下来了,对象的年龄就大了,就会晋升到老年代中。
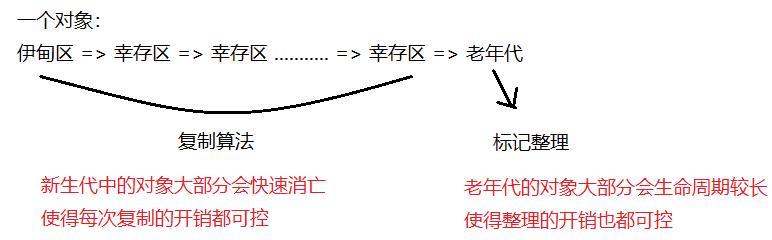
当然也会出现如果某个对象特别大,就会直接进入到老年代这种情况。
垃圾收集器
如果说上⾯我们讲的收集算法是内存回收的⽅法论,那么垃圾收集器就是内存回收的具体实现。 垃圾收集器的作⽤:垃圾收集器是为了保证程序能够正常、持久运⾏的⼀种技术,它是将程序中不⽤ 的死亡对象也就是垃圾对象进⾏清除,从⽽保证了新对象能够正常申请到内存空间。