An End-to-End Attention-Based Approach for Learning on Graphs NC 2025
NC 2025 | 一种基于端到端注意力机制的图学习方法
Nature Communications IF=15.7 综合性期刊 1区

参考:https://mp.weixin.qq.com/s/cZ-d8Sf8wtQ9wfcGOFimCg
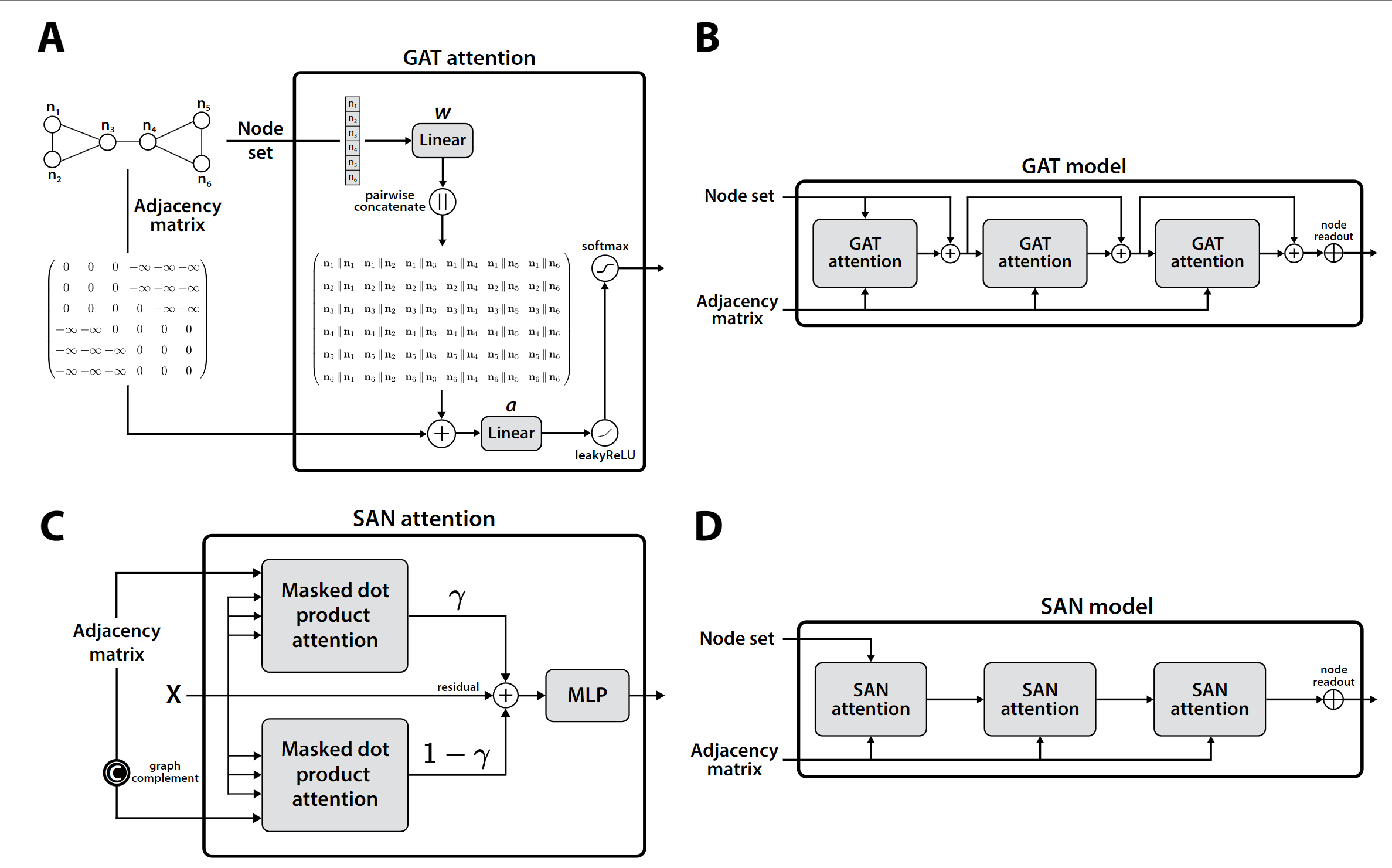
今天介绍一篇发表在 Nature Communications 的图学习论文《An end-to-end attention-based approach for learning on graphs》。该工作提出了一种全新范式的图学习方法 ESA(Edge-Set Attention),不再依赖传统的节点消息传递机制,而是将图建模为边集合,并通过纯注意力机制进行信息交互。该方法无需结构先验和位置编码,模型结构简洁却具备强表达力,在70项图与节点任务中大幅超越GNN与图Transformer,展现出优异的性能、鲁棒性与迁移能力,是一项值得关注的图学习基础模型探索工作。
摘要:
近年来,基于 Transformer 的图学习架构迅速兴起,主要受到注意力机制作为高效学习方法的推动,以及希望取代消息传递机制中手工设计算子的需求。然而,也有研究对这些方法在实际效果、可扩展性以及预处理步骤的复杂性方面提出质疑,尤其是相较于那些结构更简单、但在各种基准测试中表现相当的图神经网络(GNNs)。
为了解决这些问题,我们将图视为一组边,提出了一种纯粹基于注意力机制的方法,由编码器和注意力池化模块组成。编码器交替使用掩蔽和标准的自注意力模块,能够有效地学习边的表示,并应对输入图中可能存在的不规范结构。
尽管方法结构简单,我们的方法在70多个节点级和图级任务上(包括具有挑战性的长距离依赖任务)均超越了经过精调的消息传递模型和近期提出的 Transformer 方法。此外,我们在多个任务上取得了当前最先进的性能,涵盖了从分子图到视觉图,以及异质图节点分类等不同类型任务。
在迁移学习任务中,该方法也优于主流的图神经网0络和 Transformer,并且在保持相似性能或表达能力的同时,具备更强的可扩展性。
Introduction
我们从实证角度出发,研究了一种纯基于注意力机制的方法在学习图结构数据有效表示方面的潜力。传统上,图上的学习通常采用“消息传递”(message passing)框架建模,它是0.
一种迭代过程,依赖于消息函数来聚合一个节点邻居的信息,并利用更新函数将编码后的消息整合到节点的输出表示中。生成的图神经网络(GNN)通常会堆叠多个这样的层,以基于节点为根的子树结构学习节点表示,这一过程本质上模仿了一维 Weisfeiler-Lehman(1-WL)图同构判别测试 [wl79, wlneural24]。消息传递的变种已被成功应用于多个领域,如生命科学 [STOKES2020688, Wong2023 等]、电气工程 [Chien2024] 和天气预测 [doi:10.1126/science.adi2336]。
尽管图神经网络(GNN)在实践中取得了广泛成功和广泛应用,但随着时间推移,人们也发现了其若干实际挑战。尽管消息传递框架具有很高的灵活性,设计新的 GNN 层仍是一项具有挑战性的研究问题,通常需要多年才能实现改进,并常常依赖于手工设计的算子。这种情况在不利用其他输入模态(例如原子坐标)的通用图神经网络中尤为明显。例如,主邻域聚合(PNA)被认为是最强大的消息传递层之一,但它是通过一组手动选择的邻域聚合函数构建的,并且需要预先计算数据集的度直方图,还使用了手动设定的度缩放因子。
消息传递机制的本质也带来了一些限制,这些限制在现有文献中占据主导地位。其中一个最突出的例子是 readout 函数,它被用于将节点级特征汇聚成图级表示,并且要求对节点顺序具备置换不变性。 因此,在 GNN 和图 Transformer 中,默认的 readout 函数通常是简单且不可学习的函数,例如 sum(求和)、mean(平均)或 max(最大值)。Wagstaff 等人指出,这种方法存在局限性,简单的 readout 函数可能需要复杂的项嵌入函数,而这些函数难以用标准神经网络学习得到。
此外,图神经网络在“过平滑”(over-smoothing)和“过压缩”(over-squashing)方面也表现出一定的局限性。“过平滑”是指随着网络层数增加,节点表示变得越来越相似,进而降低模型在异质图节点分类任务中的性能。 有研究假设这源于 GNN 表现得像低通滤波器。近期,Di Giovanni 等人通过研究图上的梯度流,进一步表明某些时间连续的 GNN 确实受到低频成分的主导。
相对的,“过锐化”(over-sharpening)也被观察到,尤其是在使用线性图卷积和对称权重的情形中,这是由权重矩阵负特征值所引起的“排斥”效应导致的。而“过压缩”则会在需要远距离节点信息的预测任务中影响性能,这被归因于图结构中的瓶颈边,即当 k 值(k-hop)或网络层数增加时,k 邻域的数量迅速增加。Topping 等人对“过压缩”进行了理论刻画,并引入了图曲率的概念来量化该问题,同时提出了一种图重构算法——随机离散 Ricci 流(stochastic discrete Ricci flow),用于缓解这些瓶颈效应。
针对上述两个问题,研究者提出了一些替代方案,主要是基于消息正则化(message regularisation)的方法,例如 Simple Graph Convolution、PairNorm 和 GraphNorm 等。
然而,目前尚无公认的最佳架构选择可以用来构建有效的深度消息传递神经网络,也无法同时有效地解决这些挑战。此外,与大型语言模型不同,图神经网络中迁移学习、预训练和微调等策略的效果有限或存在争议,因此使用并不广泛。
图