Python 图片爬取入门:从手动下载到自动批量获取
前言
想批量下载网页图片却嫌手动保存太麻烦?本文用 Python 带你实现自动爬取,从分析网站到代码运行,步骤清晰,新手也能快速上手,轻松搞定图片批量获取。
1.安装模块
在开始爬取图片前,我们需要准备好工具和环境。这就像盖房子前要准备好砖瓦和工具一样,合适的环境能让后续操作更顺畅。
1.1环境安装
《Python开发环境终极指南:从Conda环境配置到VSCode、PyCharm、Jupyter深度优化》_conda系统环境配置-CSDN博客文章浏览阅读1.4k次,点赞47次,收藏31次。Jupyter Notebook允许用户在一个文档中结合代码、文字、数学公式和可视化图表,是教学、实验记录和可重复研究的理想工具。Jupyter Notebook是一种互动式的网页应用程序,让你在一个文档中写代码、运行代码、添加注释和插入图表。【菜单】---【设置】--【项目:你的项目目录】--【python解释器】--【添加解释器】--【添加本地解释器】不建议使用类似C:\Users\15740\\.conda\envs**这样的默认路径去创建虚拟环境。然后就可以创建python文件、写代码、运行即可~_conda系统环境配置https://blog.csdn.net/xw3373409564/article/details/149201204?fromshare=blogdetail&sharetype=blogdetail&sharerId=149201204&sharerefer=PC&sharesource=xw3373409564&sharefrom=from_link这里建议使用Pycharm
1.2第三方模块与模块的调用
Python 模块化编程全解析:模块、包与第三方库管理指南-CSDN博客文章浏览阅读1.1k次,点赞30次,收藏22次。学好模块和包,是从"写脚本"到"开发项目"的关键一步。下次写代码时,试试把常用功能拆成模块——你会发现代码变得清爽又好维护!https://blog.csdn.net/xw3373409564/article/details/149452387?fromshare=blogdetail&sharetype=blogdetail&sharerId=149452387&sharerefer=PC&sharesource=xw3373409564&sharefrom=from_link
2.分析网站
爬取图片的关键是找到图片的真实地址。就像找宝藏需要先看地图,我们需要用浏览器的 “开发者工具” 分析网站结构,找到图片的来源。
浏览器建议使用谷歌
2.1打开网页
打开一个包含图片的网页,例如:
2.2进入检查(或开发者选项)
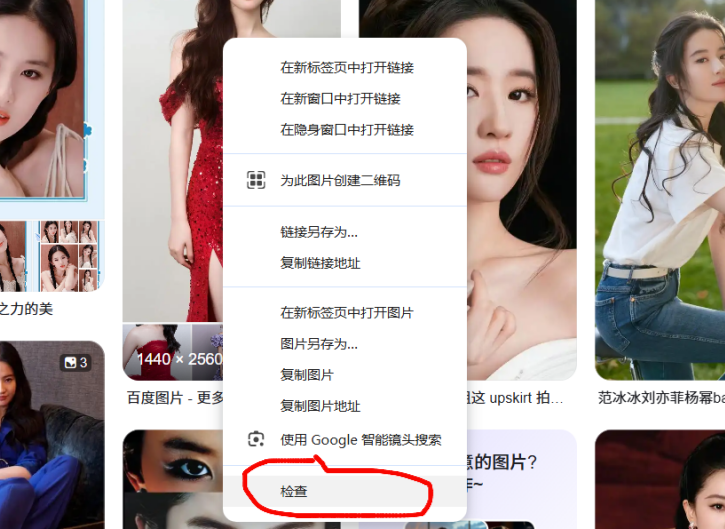
- 右键网页空白处,选择 “检查”(或按 F12 快捷键),打开开发者工具。
- 这个工具就像 “透视镜”,能看到网页背后的代码和网络请求。
2.3Elements
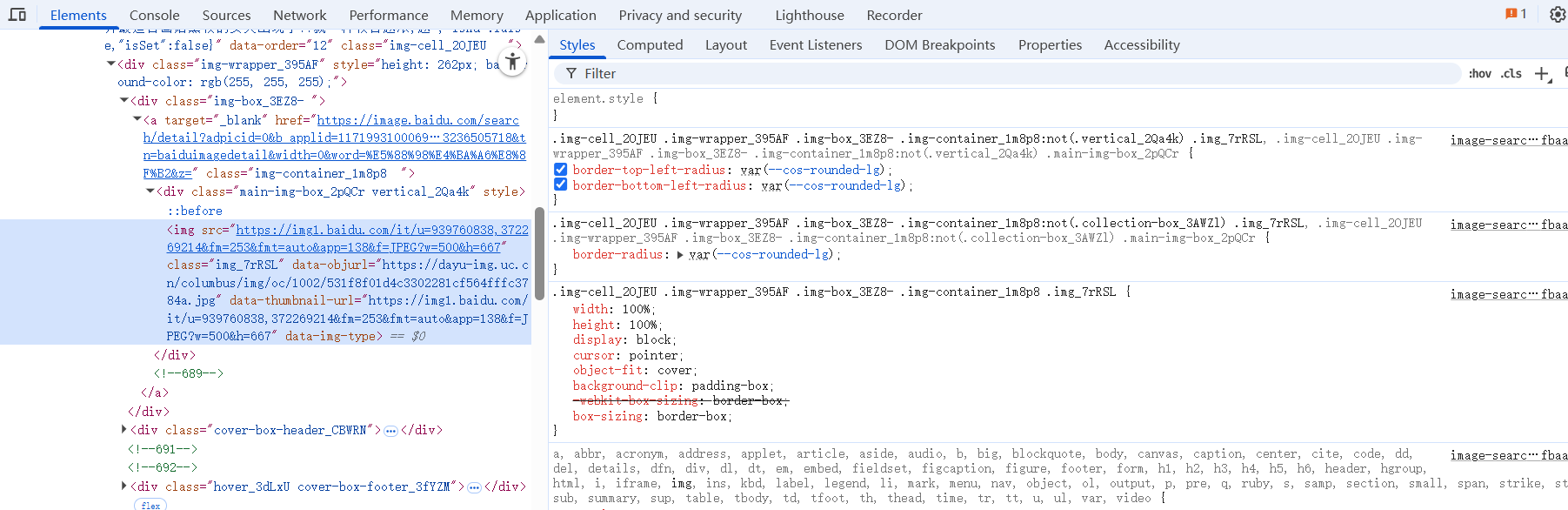
进入如如下页面,Elements是网页的全部内容,
2.4network
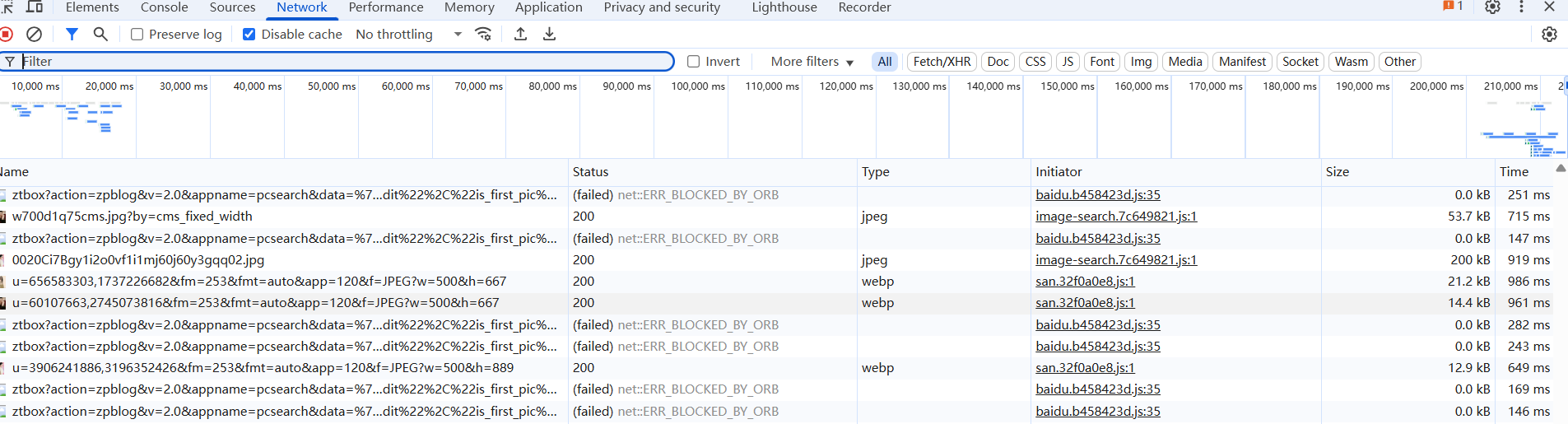
- 切换到 Network 面板:这里记录了网页加载时的所有网络请求(如图片、文字、脚本等)。
- 选择 Fetch/XHR:图片数据通常通过 “异步请求” 加载,这里能过滤出我们需要的动态数据请求。
- 刷新网页或滑动加载:滑动网页时,新的图片会被加载,Network 面板会出现新的请求记录。
2.5Fetch/XHR
- 查看请求的 Preview:在 Fetch/XHR 列表中,点击一个请求,切换到 “Preview” 标签,这里能看到请求返回的数据(通常是 JSON 格式)。
- 寻找图片地址字段:在数据中逐层查找,会发现一个
images列表,里面的thumburl字段就是图片的真实地址(试试复制这个地址到浏览器,能直接打开图片哦~)。 - 记录请求 URL 和参数:每个请求都有一个 URL(如
https://image.baidu.com/search/acjson?...),里面的word参数是搜索关键词(如 “刘亦菲”),pn是分页参数(控制第几页),rn是每页图片数量 —— 这些参数能帮我们控制爬取的内容和数量。
选择Fetch/XHR,里面放的是各种请求
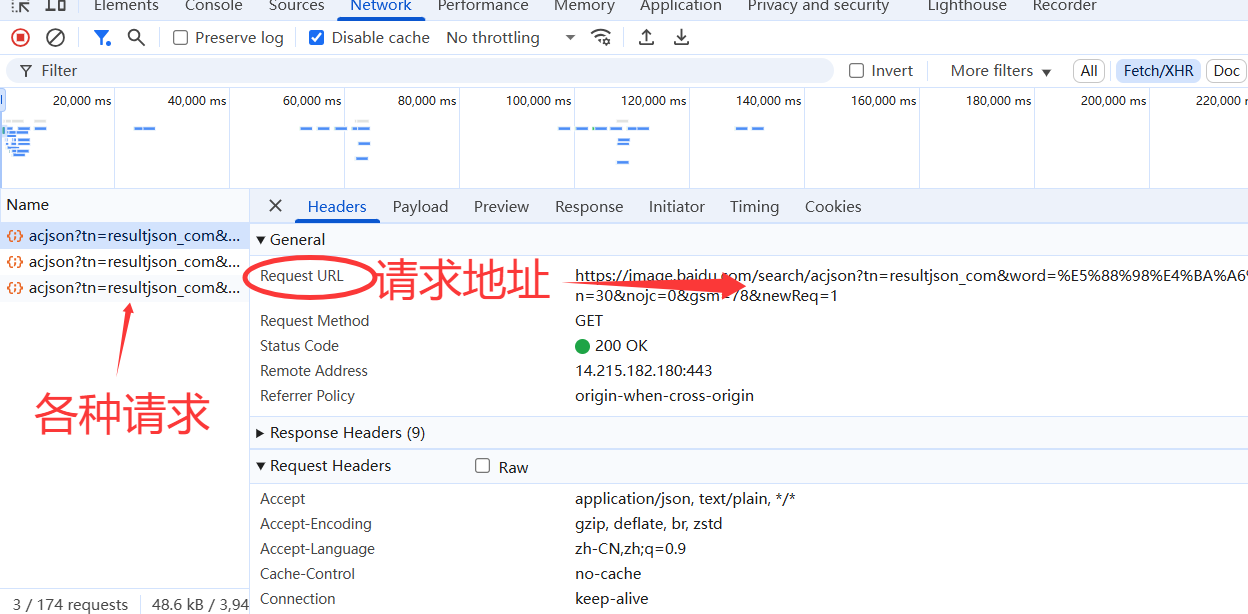
2.5.1Header
在Header中往下滑,在request headers中找到 user-agent
user-agent;用户代理”,是一个在客户端(如浏览器、APP、爬虫程序等)向服务器发送请求时,包含在 HTTP 请求头中的字符串。它的核心作用是向服务器 “说明” 自己的身份信息,让服务器了解请求来自哪种客户端、操作系统、设备类型等,从而返回适配的内容。
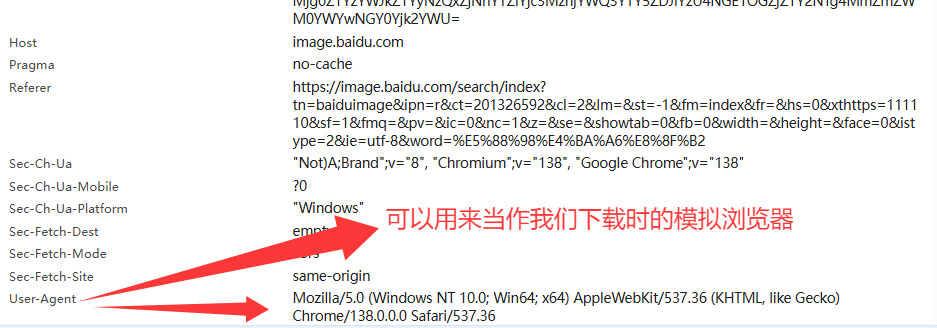
user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36
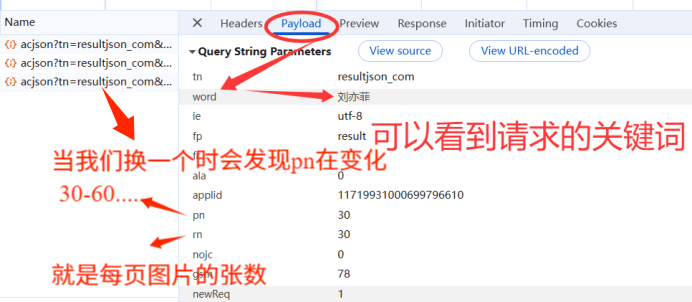
2.5.2 Payload
2.5.3Preview
点击Preview 里面放的是我们请求的数据,我们需要在里面找到图片地址
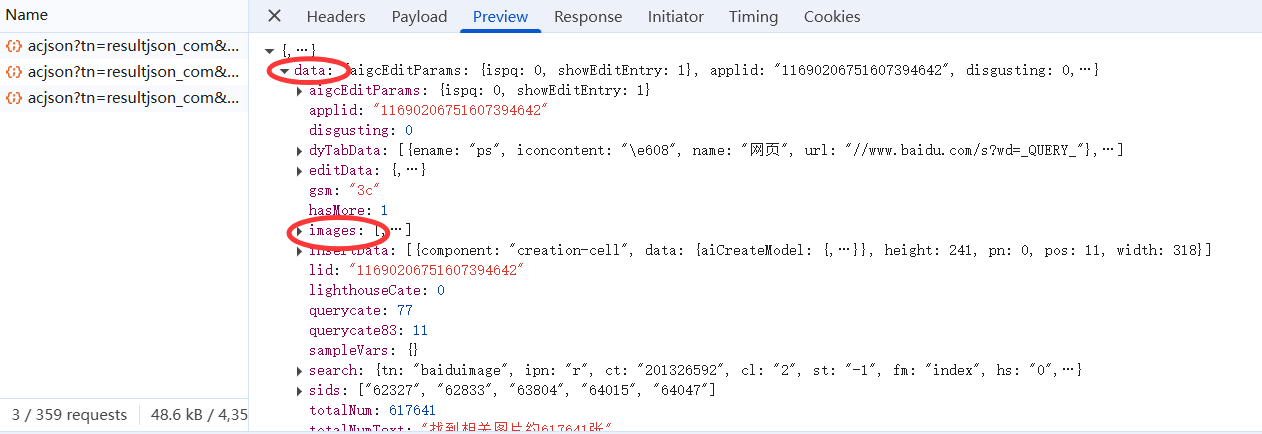
可以看出images是一个列表list
2.5.3.1在images中找到图片地址
例如jumpUrl

结果如下
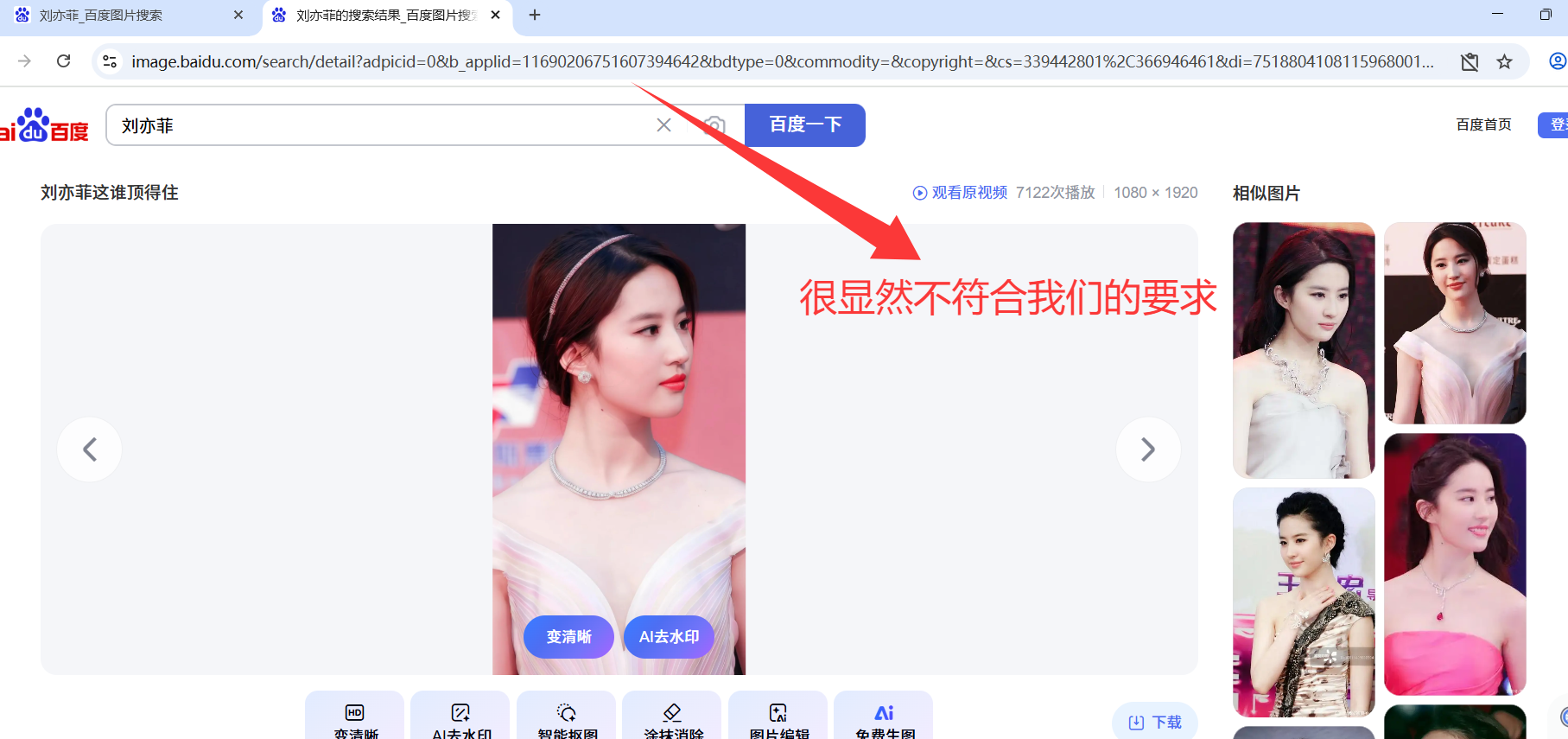
继续往下找

结果如下
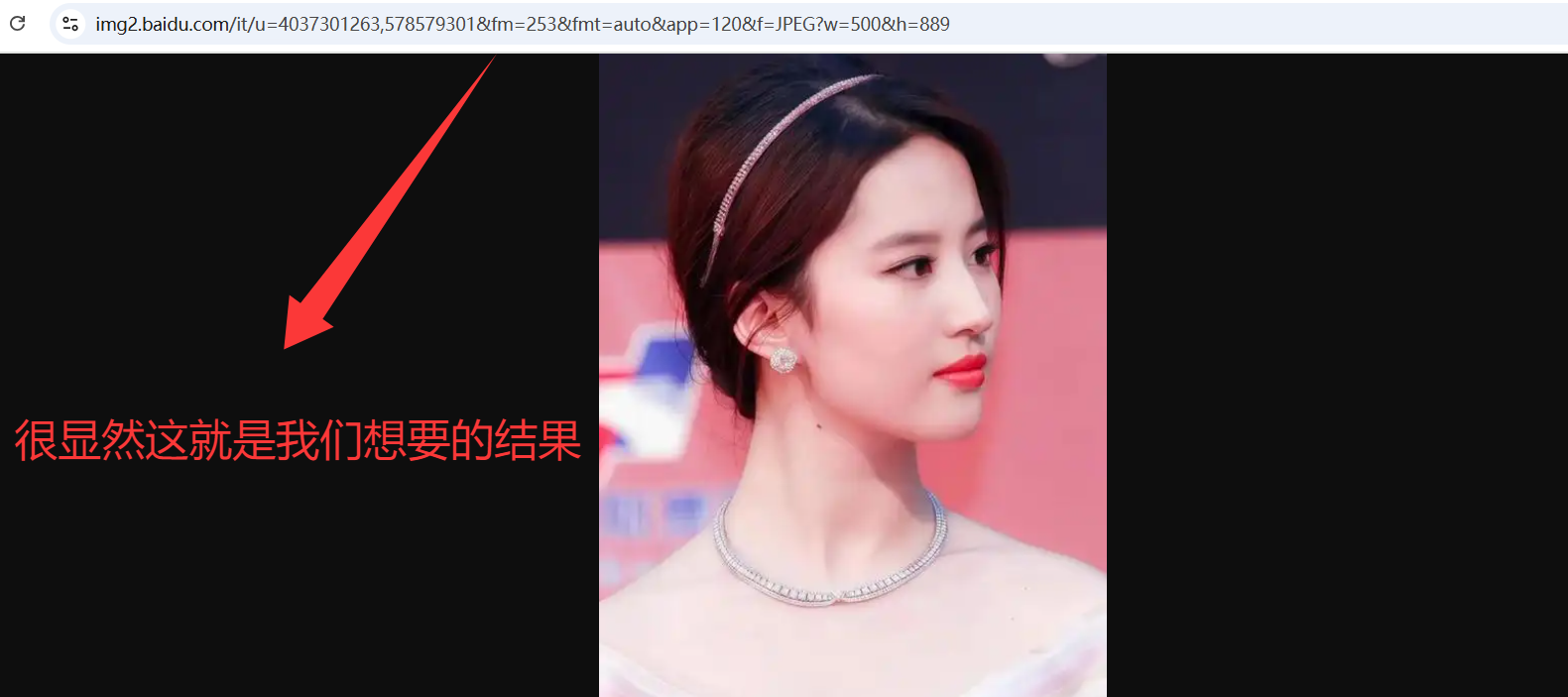
然后换一个 继续访问看是否一致

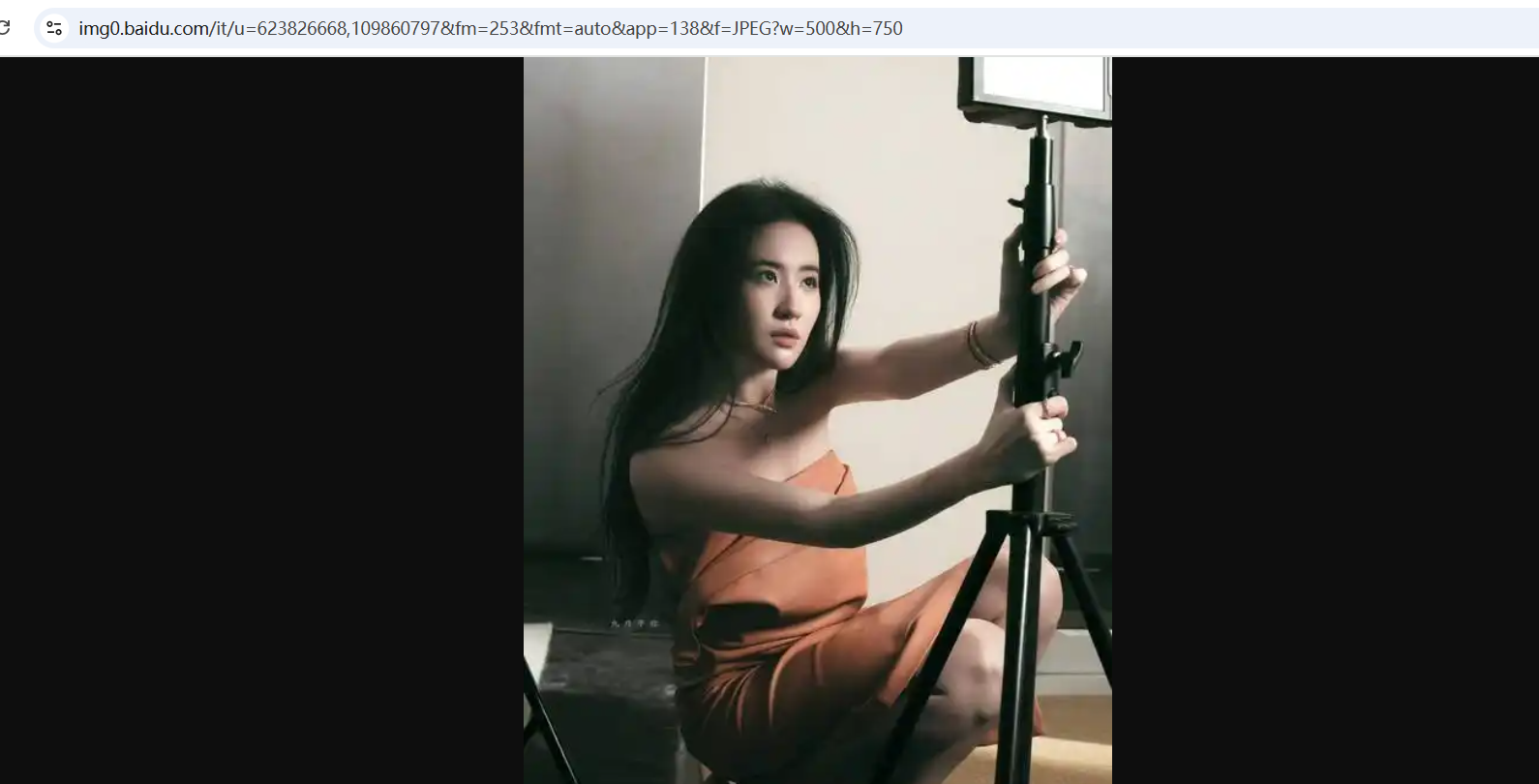
结果如下,很显然thumburl就是我们要找的地址 ,同时从这里也可以看出每个请求里有30张图片
2.5.4获取请求的url地址
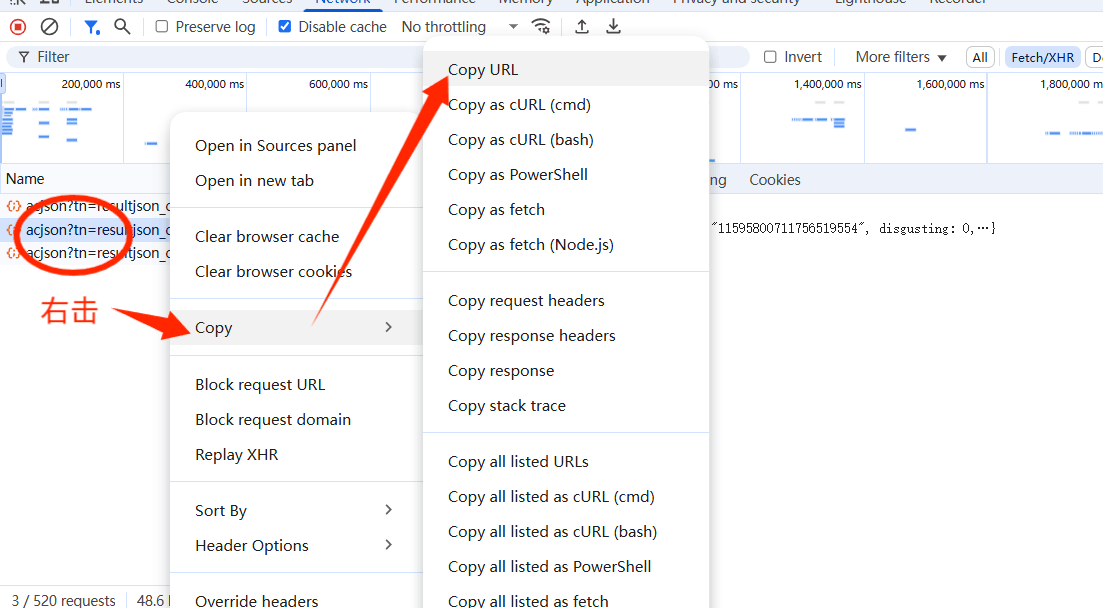
这样我们就获得了一个请求地址(访问不同地址不同):
https://image.baidu.com/search/acjson?tn=resultjson_com&word=%E5%88%98%E4%BA%A6%E8%8F%B2&ie=utf-8&fp=result&fr=&ala=0&applid=11719931000699796610&pn=60&rn=30&nojc=0&gsm=3c&newReq=1
3.编写爬虫代码:从请求到下载图片
我这里使用pycharm
3.1打开pycharm
3.2设置地址变量(url)
设置一个变量来保存url地址,这里的地址应该是动态的,因为图片的地址不一样,后续会处理
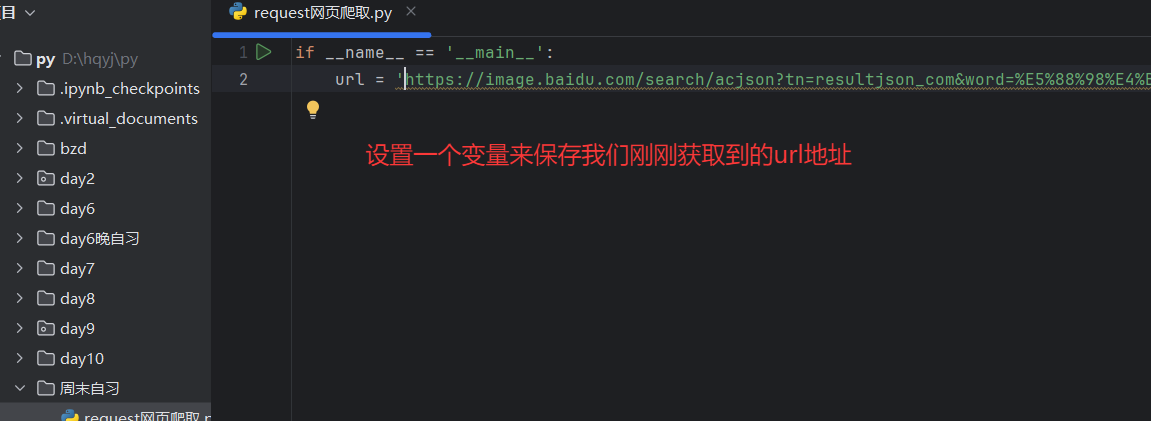
3.2设置请求头:模拟浏览器
- 请求头的作用:
User-Agent告诉网站 “我是浏览器”,避免被识别为爬虫而拒绝请求。
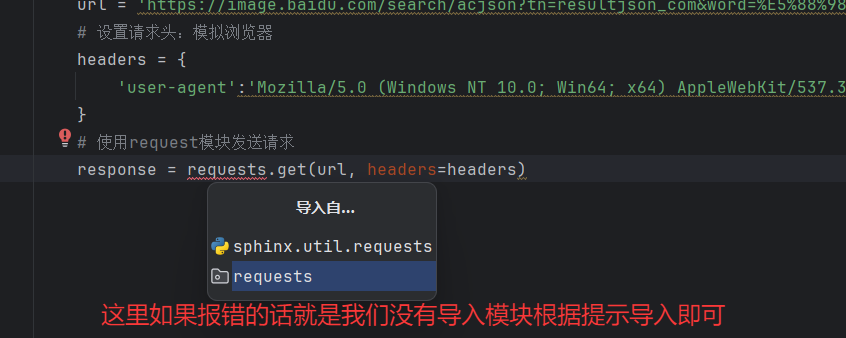
3.3使用request模块发送请求
3.3.1检查是否 请求成功
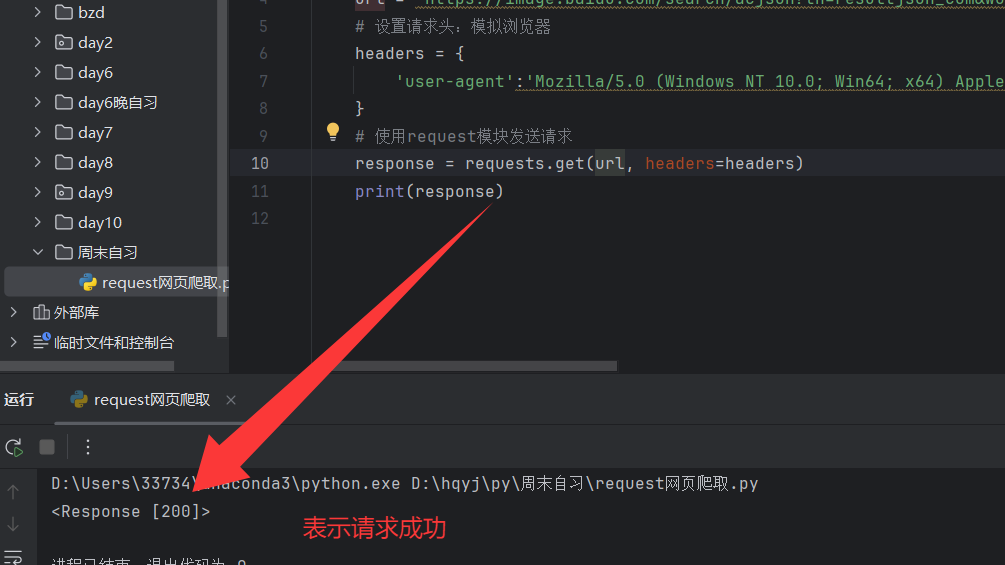
3.3.2看看是否抓取到信息
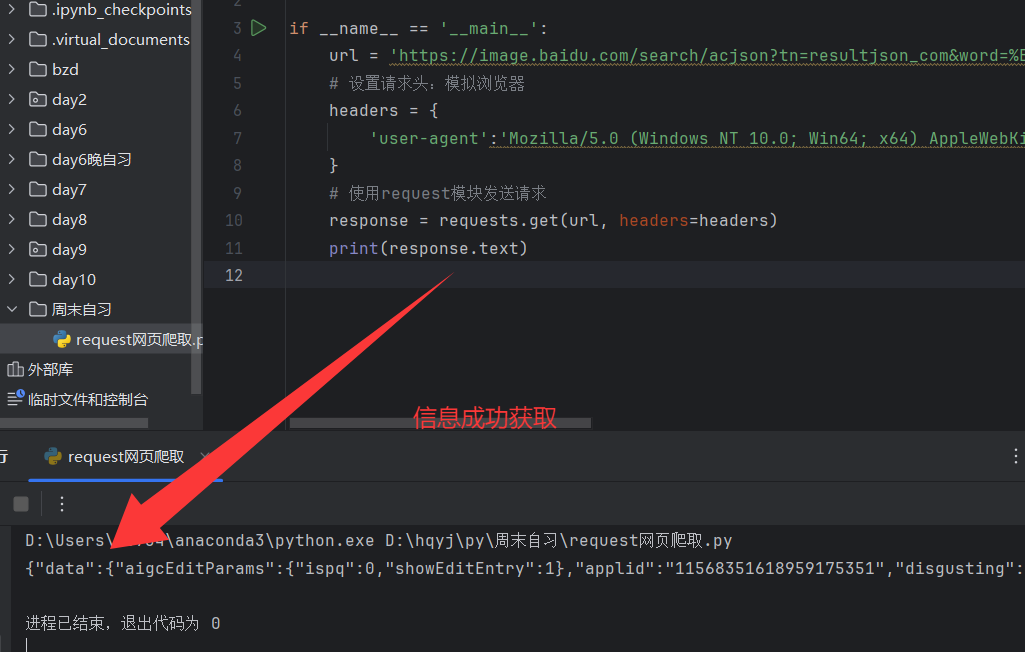
3.3.3然后查看文件类型
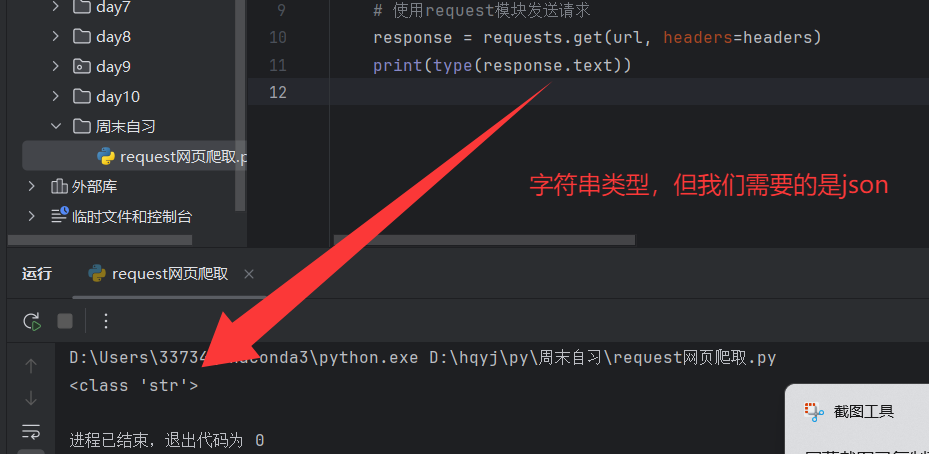
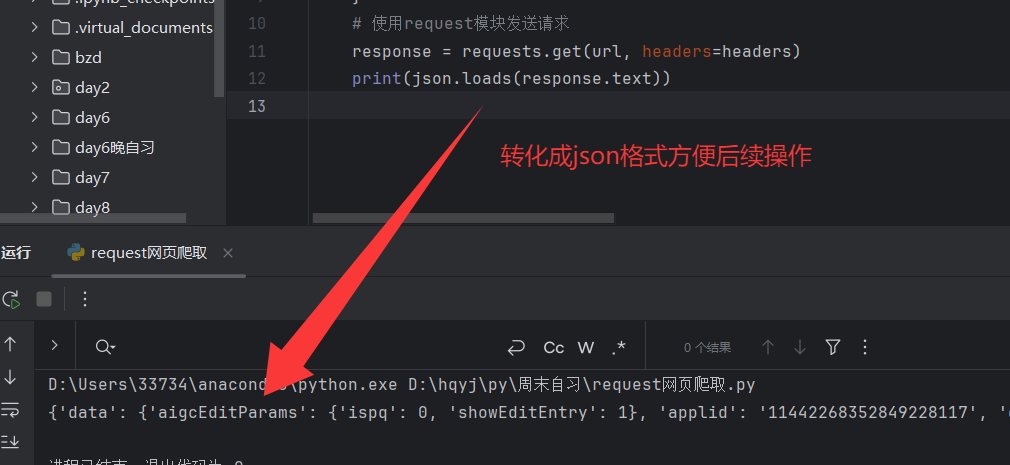
3.3.4将其转换为json
json.loads() 是 Python 标准库 json 模块中的一个重要函数,用于将 JSON 格式的字符串转换为 Python 数据类型(如字典、列表、字符串、数字等),实现 JSON 数据的 “反序列化”,方便我们提取图片地址。。
3.4获取图片信息
根据我们分析网页时(在分析网页模块2.5.3Preview 里面放的是我们请求的数据,我们需要一层一层的在里面找到图片地址)url地址get( ) 方法获取
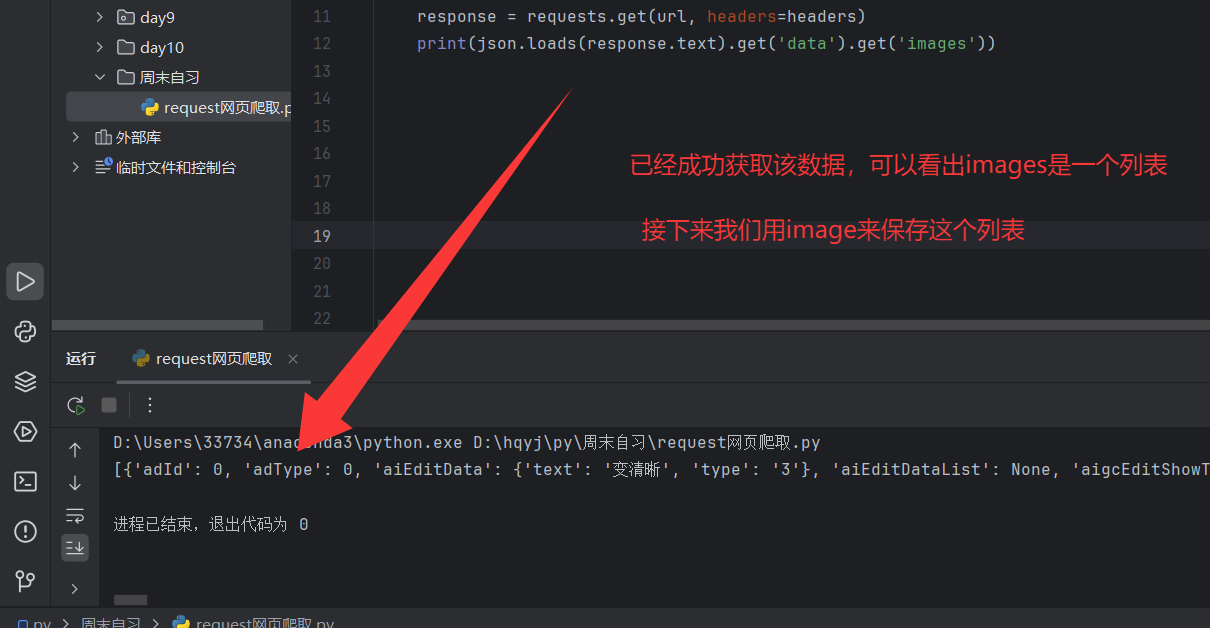
3.4.1打印thumburl地址
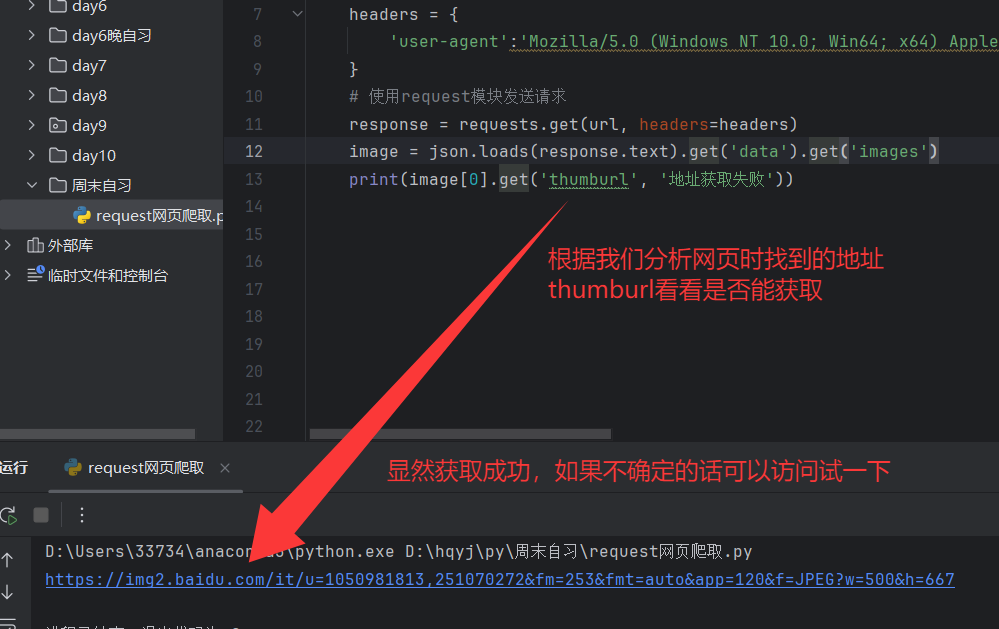
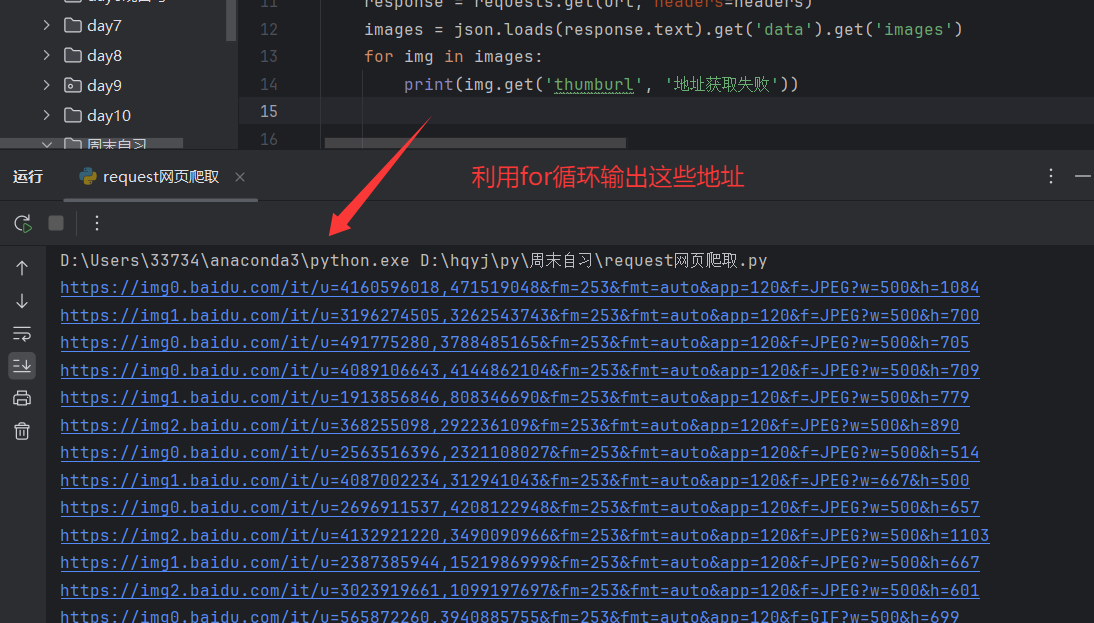
我们拿到图片地址就是想把它下载到本地
3.5下载图片
创建一个用于存放图片的文件夹这里我创建的是images
3.5.1使用request发起请求get(图片地址)
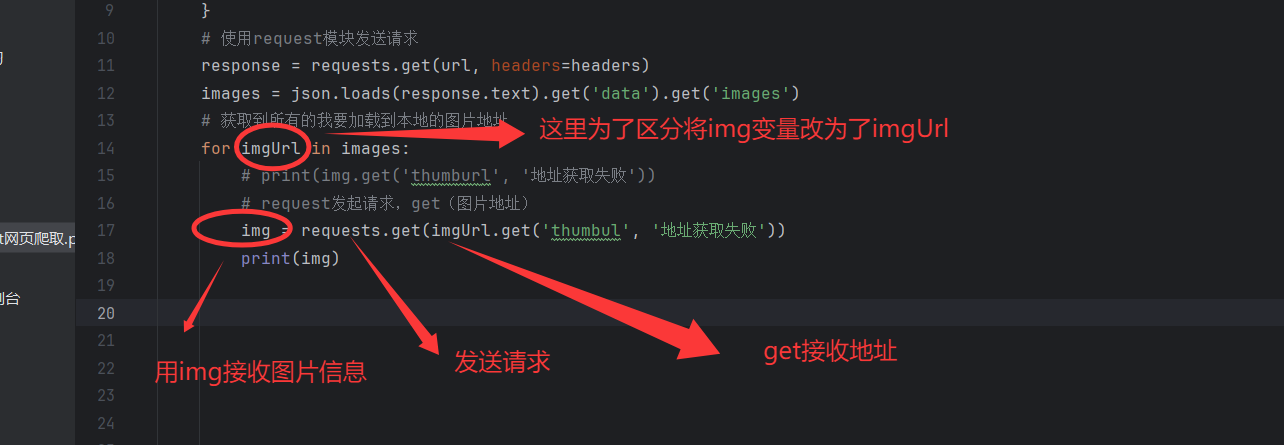
3.5.2 下载
3.5.2.1查看是否获取到图片数据
- 二进制保存:图片是二进制文件,所以用
"wb"模式(写入二进制)打开文件。
显然获取数据成功
3.5.2.2保存图片数据
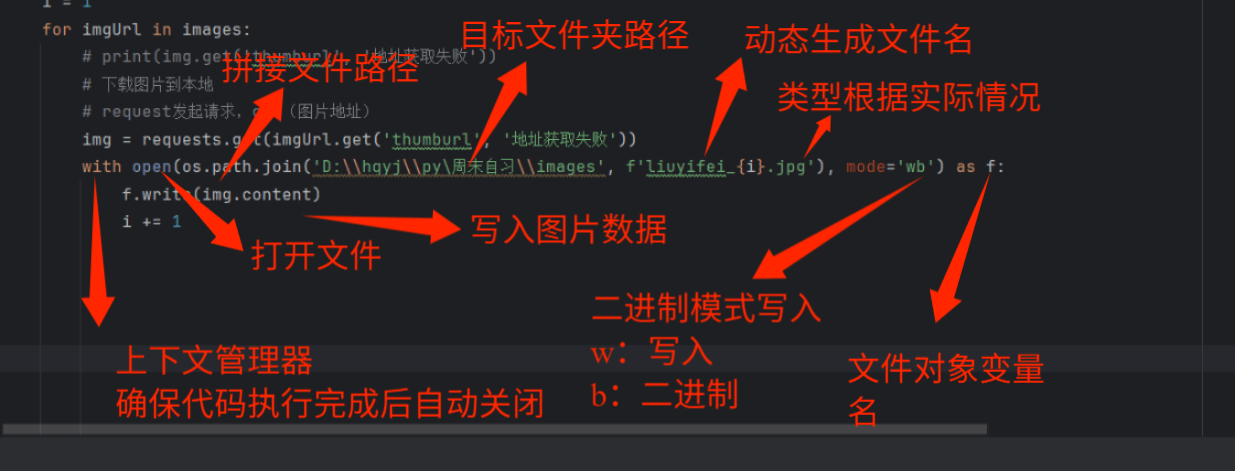
注意:这里的地址D:\hqyj\py\周末自习\images要用 \ \,在python中 \ 是转义字符
3.5.3运行
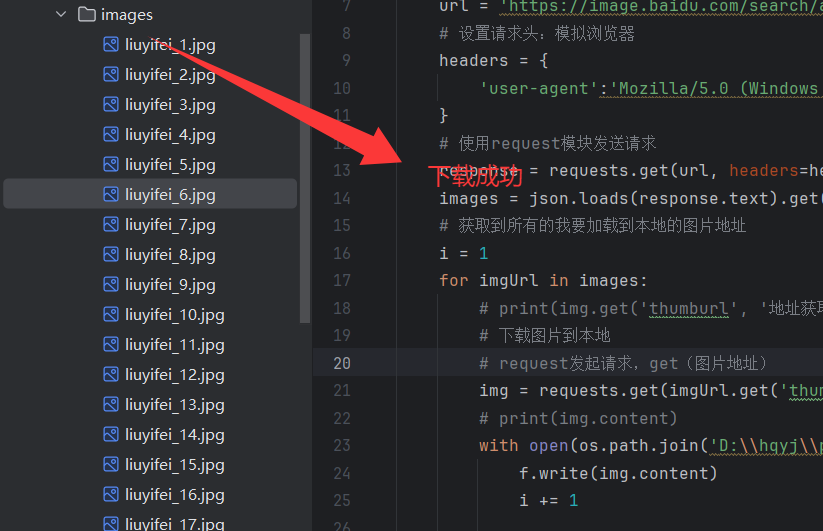
到这里我们就完成了简单的下载功能
4.代码优化:让爬虫更实用
4.1获取当前目录地址
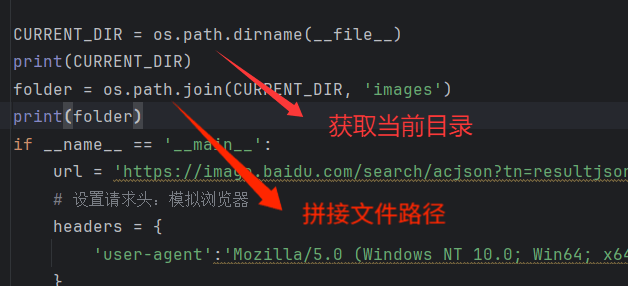
结果如下:
D:\hqyj\py\周末自习
D:\hqyj\py\周末自习\images
4.1.1不同方法
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 将图片保存到脚本所在目录 | os.path.dirname(__file__) | 无论脚本从何处运行,都能准确定位到脚本自身所在的目录。 |
| 将图片保存到当前工作目录 | os.getcwd() | 适用于需要与用户当前操作目录保持一致的场景(如命令行工具)。 |
4.1.2检测
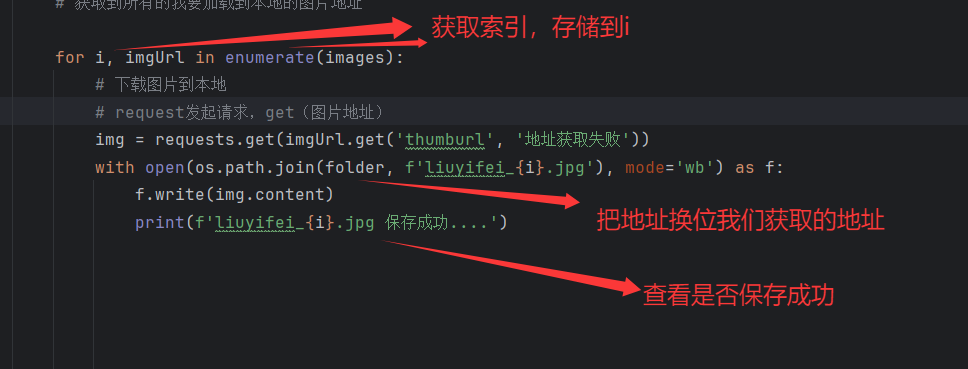
4.2 优化下载数量
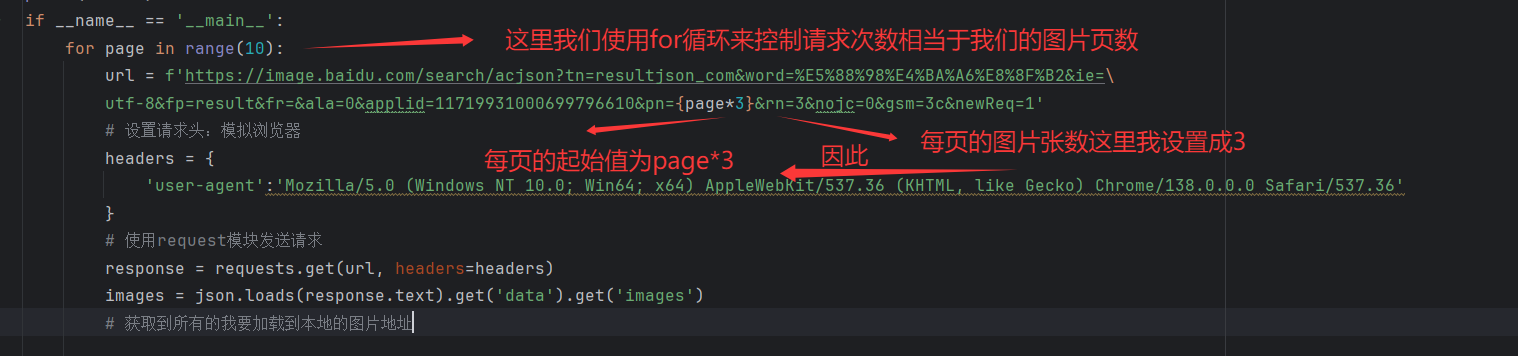
从(2.5.2 点击Payload)中我们可以看出pn时为了设置每页起始值,而rn是每页图片张数,通过修改 URL 中的pn参数(分页起始值),实现多页爬取:如下:
注意,为了方便操作这里使用了换行符 \
由于这里做了更改,保存图片是的文件名也需更改
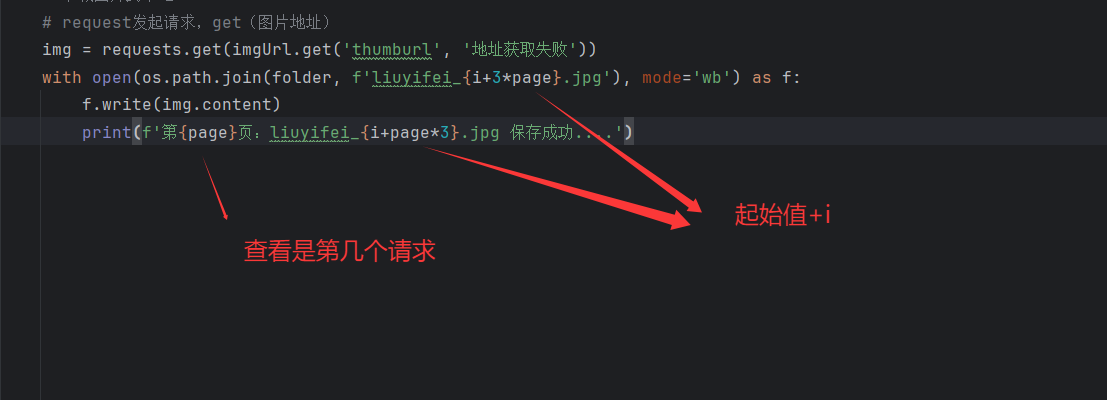
然后执行看是否成功
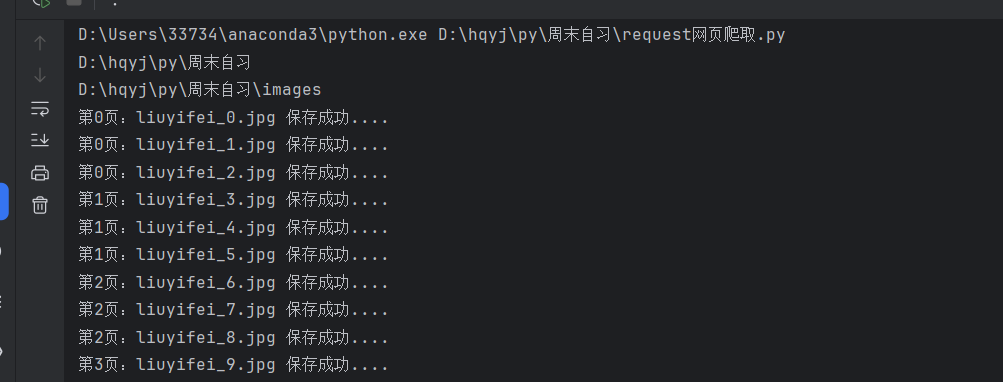
显然是成功的
4.3支持多关键词爬取,同时下载不同的内容
(2.5.2 点击Payload)可以发面word是用来存储我们搜索的关键词
我们可以用一个列表存储这些关键词来映射,动态获取内容

同样的我们需要对文件保存做出修改
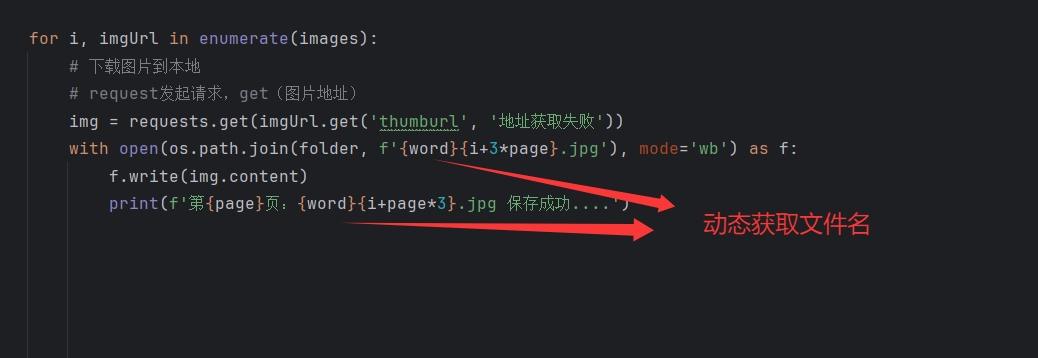
运行看是否成功
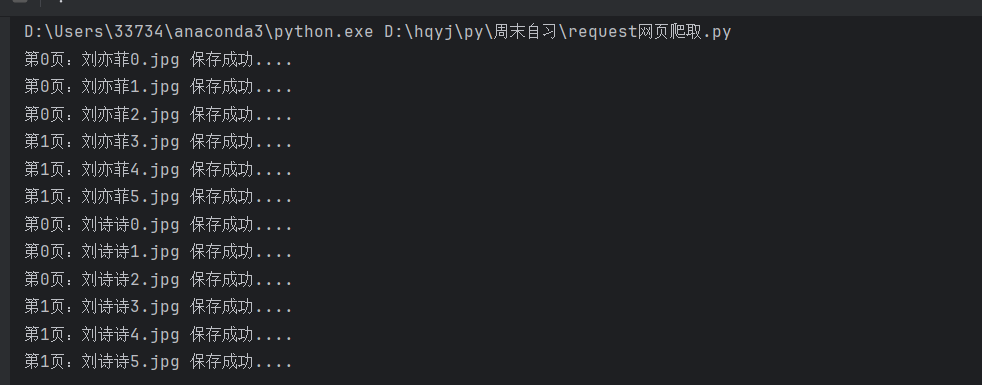
显然这是成功的两页,每页3张
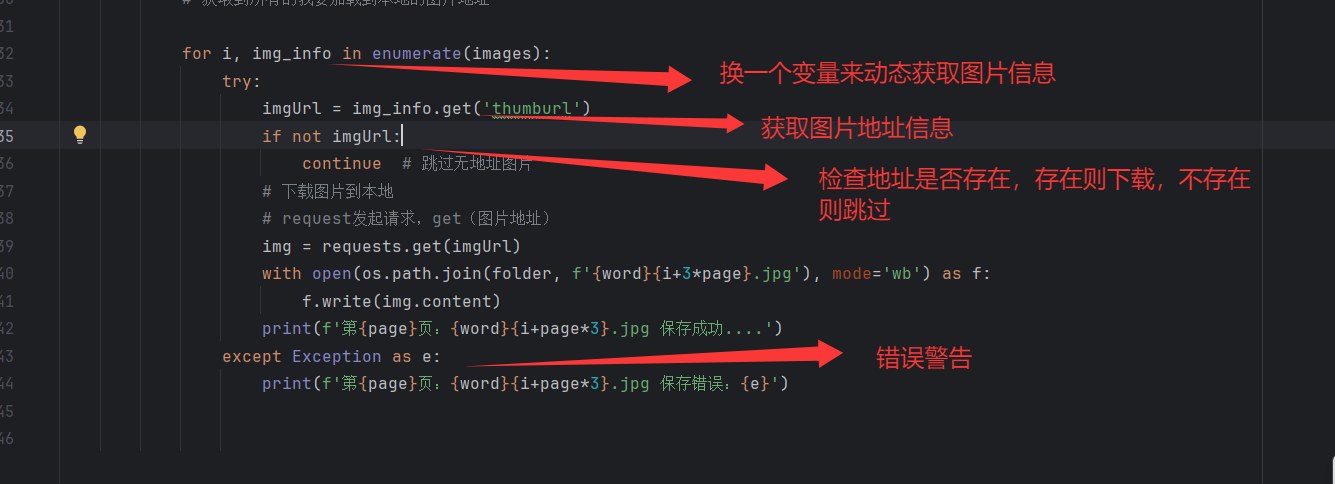
4.4增加错误处理
用try-except捕获错误,避免因个别图片地址无效导致程序崩溃:
5.源代码
import os
import requests
import json# 关键词映射
keyword = {'liuyifei': '刘亦菲','liushishi': '刘诗诗'
}
# 本地目录获取,当前文件所在目录
CURRENT_DIR = os.path.dirname(__file__)
PAGES_NUM = 2
if __name__ == '__main__':for key, word in keyword.items():# 下载图片到本地目录folder = os.path.join(CURRENT_DIR, key)if not os.path.exists(folder):os.makedirs(folder)# 遍历的方式爬取多页for page in range(PAGES_NUM):url = f'https://image.baidu.com/search/acjson?tn=resultjson_com&word={word}&ie=\utf-8&fp=result&fr=&ala=0&applid=11719931000699796610&pn={page*3}&rn=3&nojc=0&gsm=3c&newReq=1'# 设置请求头:模拟浏览器headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36'}# 使用request模块发送请求response = requests.get(url, headers=headers)images = json.loads(response.text).get('data').get('images')# 获取到所有的我要加载到本地的图片地址for i, img_info in enumerate(images):try:imgUrl = img_info.get('thumburl')if not imgUrl:continue # 跳过无地址图片# 下载图片到本地# request发起请求,get(图片地址)img = requests.get(imgUrl)with open(os.path.join(folder, f'{word}{i+3*page}.jpg'), mode='wb') as f:f.write(img.content)print(f'第{page}页:{word}{i+page*3}.jpg 保存成功....')except Exception as e:print(f'第{page}页:{word}{i+page*3}.jpg 保存错误:{e}')6总结
核心步骤回顾
- 分析网站:用开发者工具找到图片的请求 URL 和数据结构(关键是找到图片真实地址)。
- 发送请求:用
requests库模拟浏览器发送请求,获取数据。 - 提取信息:从返回的 JSON 数据中提取图片地址。
- 保存数据:将图片以二进制形式保存到本地文件夹。
- 优化扩展:支持多页、多关键词爬取,增加错误处理。
注意事项
- 尊重网站规则:查看网站的
robots.txt(如https://image.baidu.com/robots.txt),遵守爬取限制,不要频繁请求(可以加time.sleep()控制间隔)。 - 反爬应对:设置合理的请求头(
User-Agent),避免被识别为爬虫;不要一次性爬取过多数据。 - 合法性:确保爬取的内容用于学习,不侵犯版权或用于商业用途
通过这篇教程,你已经掌握了 Python 爬取网页图片的基本方法。爬虫的核心是 “分析网站→模拟请求→提取数据”,多练习不同的网站(如豆瓣图片、壁纸网站),你会越来越熟练!