RCU机制及常见锁的理解
目录
一、互斥锁
二、读写锁
三、RCU机制
读操作:
写操作:
四、各种锁的加锁解锁操作
四、关于数据不一致问题
在Linux中,往往会有多线程的场景,但是可能临界资源只有一份(比如磁盘文件、网卡等),如果多个进程同时访问和修改,就会出现数据不一致的问题。同步机制就是保证数据一致性,避免竞争的关键。RCU机制、读写锁、互斥锁等内核机制各自承担着不同的任务,开发者应当因地制宜选择合适的锁机制来提高效率。
一、互斥锁
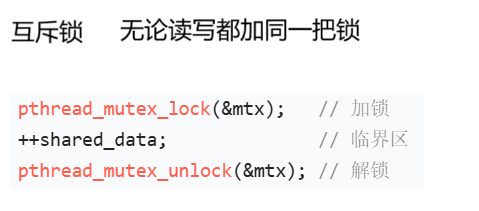
互斥锁的任务比较纯粹:保证同一时刻只能有一个进程或者线程进入临界区,无论这个进程是想写还是读。在linux内核中,互斥锁也是一种资源,就好比磁盘等。
struct mutex
{atomic_long_t owner; // 标记锁的持有者(线程ID等)struct list_head wait_list; // 等待队列:存放阻塞的线程// 其他状态标记(如是否被锁、递归计数等)
};之前我们画了一幅图表示磁盘等外设都有自己的描述结构体,而这个结构体内部一定也有着阻塞队列。互斥锁结构体就好像Linux内核抽象出来的一个软件层面的资源,程序员必须保证在访问临界区之前该线程得到了互斥锁,如果没有得到互斥锁,则会被挂载到互斥锁的阻塞队列中。
同一时刻只能有一个线程持有该互斥锁(即标记owner成员为当前线程),当他释放互斥锁(清楚owner成员)之后,会由内核把互斥锁交给阻塞队列中的第一位。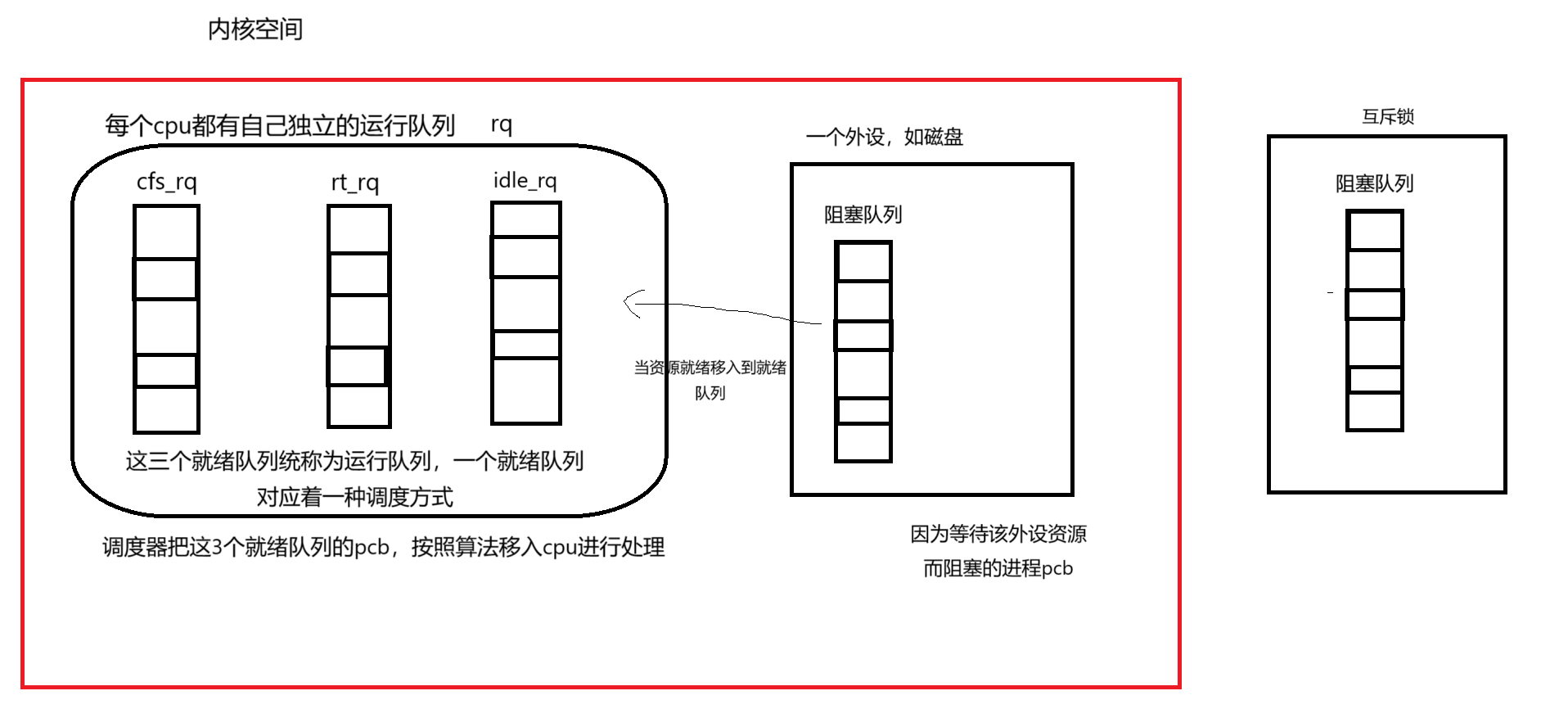
二、读写锁
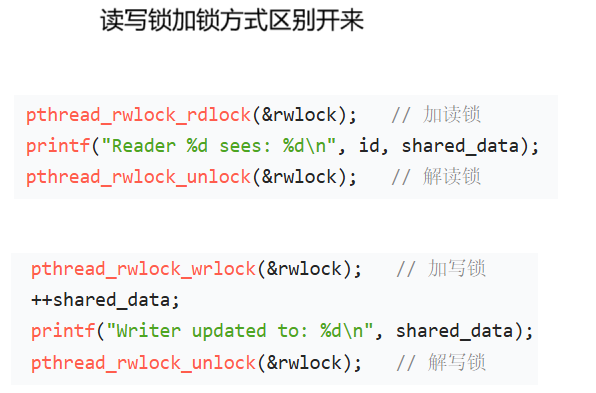
互斥锁的出现能解决一般性问题,但是如果出现了频繁读,而写很少的情况。互斥锁就会大大限制其效率,因为同一时刻只能有一个线程读取。那能不能让只读不修改的线程同时读呢?读写锁的出现较好的解决了这个问题。
struct rw_semaphore
{atomic_t count; // 读者计数/写者标记(正数:读者数;-1:写者持有)struct list_head wait_list; // 等待队列:区分读者、写者的等待节点
}; 当有读者来临时候,会把count++,每退出一个读者count--;反之有写者想要加锁的时候,会检测count的值是否为0。如果为0则设置count=-1,否则把该写者进程加入到wait_list阻塞队列中。写线程结束的时候,会把count重新置0。
注意:当读者正在读(count>0)时,读者只需要++count就表示获取到锁,阻塞队列中的全都是写线程;当写者正在写(count==-1)时,阻塞队列中可能有读线程,也可能有写进程。
读写锁的缺陷:
(1)写操作可能饥饿:如不断有读进程来获取锁,count始终不能变为0,写者永远不可能写,而一直等待。
(2)读写均匀的时候,可能因为高并发导致加锁解锁开销过大。
三、RCU机制
RCU完全舍弃了读者需要加锁的操作(虽然读写锁情况下,读者仅仅需要一个原子操作让count++即表示持有锁,但是大量线程同时++count也会带来一定的性能开销),让高并发读者场景的性能得到进一步提升。
相比于读写锁的原子++操作,RCU的rcu_read_lock() 仅仅只是标记了临界区,开销远小于原子操作,这也是RCU机制的关键。
注意:RCU临界区内禁止调用一切和阻塞相关的函数,如sleep,等待信号量等。因为这会让宽限期计算错误,提前释放了旧数据。虽然理论上需要所有读者都调用rcu_read_unlock 才能判定为宽限期结束,但Linux采取的是近似算法,即所有CPU都完成一次调度则认为宽限期结束。这也是对程序员的开发约束。
读操作:
- 读开始:通过
rcu_read_lock()标记进入读临界区(本质是禁止当前 CPU 发生上下文切换时 “忽略旧数据”,仅记录状态,几乎无开销)。- 读过程:直接访问数据(如遍历链表),此时可能读到旧版本数据(若写操作正在进行),但不会阻塞。
- 读结束:通过
rcu_read_unlock()标记退出读临界区。
写操作:
步骤 1:复制(Copy)
写操作先复制一份待修改的数据(如链表节点),在副本上进行修改(避免直接修改原数据影响读操作)。
// 示例:修改链表节点 struct node *old_node = find_node(...); // 找到要修改的旧节点 struct node *new_node = kmalloc(...); // 复制旧节点并分配新内存 *new_node = *old_node; // 复制数据 new_node->field = new_value; // 修改新节点的字段
步骤 2:替换(Update)
通过原子操作(如
rcu_assign_pointer())将指向旧数据的指针替换为指向新数据的指针。此时,新的读操作会看到新数据,而正在进行的旧读操作仍访问旧数据(临界区未退出)。rcu_assign_pointer(head->next, new_node); // 原子替换指针
步骤 3:等待旧读者完成,才能垃圾回收
写操作必须等待所有在 “替换指针” 前已进入读临界区的读操作全部退出(即不再访问旧数据),才能安全释放旧数据。
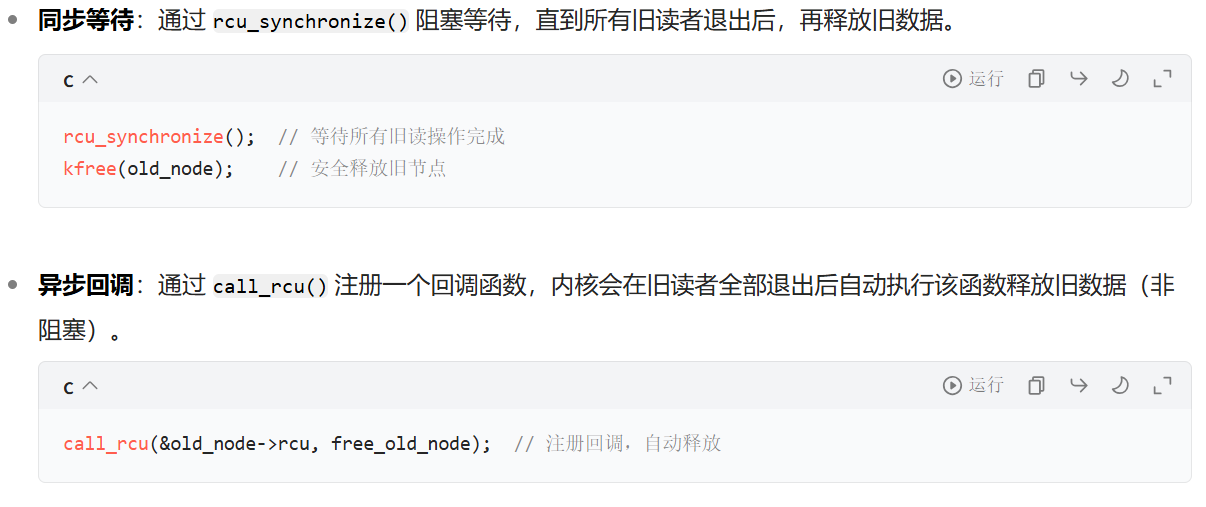
内核通过跟踪每个 CPU 的 “RCU 时钟”(如调度周期、上下文切换事件),确定一个 “ grace period(宽限期)”,可认为所有旧读操作已退出(因为读临界区不能跨上下文切换长期存在)。宽限期的确定和上述的rcu_read_unlock()密不可分,只有所有读者都调用了rcu_read_unlock()宽期限才结束。
每一个宽限期,都是内核释放老数据的时机。
虽然RCU机制提供了高并发的读,但是他不能保证你读到的就是最新的数据。RCU机制就好像一个版本管理器,随时都可以有读者进入临界区,我写者也可以随时修改数据,但是我会保证修改的是拷贝出的数据,所有在我写结束之前的读者都是读到了老数据,而当一个宽期限结束后,才会丢弃老数据(因为所有进程都已经读完了老数据)。
四、各种锁的加锁解锁操作
传统的互斥锁、读写锁都是有明确的加解锁操作,只有加完了锁才能进行后续的读写操作。
而RCU则没有传统的加解锁包裹,需要程序员根据RCU机制手动编写read-copy-update逻辑。


四、关于数据不一致问题
对于互斥锁和读写锁的本质都是利用完全串行操作,让多个线程无法同时修改一个临界资源。这需要程序员对加锁解锁的粒度掌握的很好,如果粒度太大,则会极大降低并行度;如果粒度太细,则容易出现疏忽导致读写操作执行到中途就被切换线程,出现数据不一致问题(如空指针)。
而RCU机制这种版本管理模式,则根本不需要程序员考虑锁的粒度。只管一股脑地让读者rcu_read_lock和rcu_read_unlock,写者直接修改,在宽限期后才释放旧数据。这样读者仅会出现读到老版本数据,而不会出现空指针等错误。
不过正是由于RCU的版本管理特征,通常只会使用指针。因为指针可以非常方便的创建新副本,并在合适时机用新副本替代老数据。如果不使用指针,则可能出现大量的拷贝消耗。