[NIPST AI]对抗性机器学习攻击和缓解的分类和术语
原文link:https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-2e2025.pdf
Introduction
人工智能(AI)系统在过去几年中持续全球扩展。这些系统正在被众多国家开发并广泛部署于各自的经济体系中,人们在生活的许多领域都获得了更多使用AI系统的机会。本报告区分了两大类AI系统:预测型AI(Predictive AI,PredAI)和生成型AI(Generative AI,GenAI)。尽管大多数工业应用仍以PredAI为主,但近年来GenAI在企业和消费者领域的应用正在迅速增加。随着这些系统渗透数字经济并成为日常生活中不可或缺的一部分,对其安全、稳健和弹性运行的需求也日益增长。这些运行特性是NIST AI风险管理框架及NCSC机器学习原则下可信AI的关键要素。
对抗性机器学习(Adversarial Machine Learning,AML)领域研究那些利用机器学习系统统计、数据驱动特性的攻击。尽管AI和机器学习技术在各应用领域取得了显著进展,这些技术依然容易受到可导致严重失败的攻击。随着ML系统在可能面临新型或对抗性交互的环境中使用,这类失败的概率会增加,且在高风险领域应用时后果更加严重。例如,在PredAI的计算机视觉任务(如目标检测与分类)中,已知的对抗性扰动可以导致自动驾驶车辆偏离正常车道、将停车标志误判为限速标志,甚至在高安全场所将戴眼镜的人错误识别。类似地,随着更多ML模型部署到医疗等领域,通过对抗性输入诱使模型泄露隐藏信息的风险也日益突出,如医疗记录泄露可能暴露敏感个人信息。
在GenAI领域,大型语言模型(LLMs)正日益成为软件应用和互联网基础设施的核心部分。LLMs被用于构建更强大的在线搜索工具、辅助软件开发者编写代码,以及支持每天被数百万人使用的聊天机器人。LLMs还通过与企业数据库、文档的交互,实现强大的检索增强生成(RAG),并通过训练或推理时技术,使LLMs能够执行现实世界操作,如浏览网页或以LLM为核心的Agent操作bash终端。因此,GenAI系统的脆弱性可能使敏感用户数据或模型结构与训练数据的专有信息面临更广泛的攻击面,并带来广泛系统完整性与可用性风险。
随着GenAI的普及,这些系统不断增强的能力也为模型开发者带来了新的挑战:如何管理因系统能力被不当或有害使用所带来的风险。开发者日益寻求通过技术干预降低模型被滥用的可能性,但这也带来了新的高风险攻击面,即攻击者试图绕过或破坏这些保护措施。
从根本上说,许多AI系统不仅易受AML攻击,也易受传统网络安全攻击(如针对部署平台的攻击),但本报告聚焦前者,将后者视为传统网络安全范畴。
PredAI和GenAI系统在开发和部署各阶段都易受攻击者多种能力的威胁。攻击者可以操控训练数据(包括用于大规模模型训练的互联网数据),或通过添加对抗性扰动或后缀修改推理阶段数据和资源;还可以通过植入特洛伊木马功能攻击AI系统组件。随着组织愈发依赖可直接使用或通过新数据集微调的预训练模型,其遭受此类攻击的脆弱性也在上升。
现代密码学往往依赖在信息论意义上安全的算法,即能在特定条件下形式化证明其安全性。但用于现代AI系统的主流机器学习算法并没有类似的信息论安全证明。相反,文献中已出现关于常用缓解技术有效性极限的信息论不可能性结果。因此,许多针对不同类型AML攻击的缓解技术主要基于经验,因其在实践中有效而被采用,而非具备信息论安全保证。这意味着这些缓解手段本身也可能易受新型攻击技术的影响。
本报告旨在为以下方面提供指导:
- 建立AML术语标准化体系,用于ML与网络安全等相关领域,弥合不同利益相关方间的术语差异,适应AI在企业和消费者领域的广泛应用;
- 梳理AML领域最具代表性和当前有效的攻击分类,包括:
- 对PredAI系统的规避(evasion)、投毒(poisoning)、隐私(privacy)攻击
- 对GenAI系统的投毒、直接提示攻击、间接提示注入攻击
- 讨论这些攻击的潜在缓解措施及现有缓解技术的局限性。
Predictive AI Taxonomy
2.1. Attack Classification
本节根据攻击者目标与能力,对抗性机器学习(AML)中针对预测型AI(PredAI)系统的攻击进行了分类。分类框架(见Figure 1)以攻击者目标(可用性、完整性、隐私)为核心,围绕目标列出攻击者可利用的能力,并将具体攻击类型与所需能力相连。
攻击分类维度包括:
- 攻击发起所在的学习方法与学习阶段
- 攻击者的目标与意图
- 攻击者能力
- 攻击者对学习过程的了解程度
![![[Screenshot 2025-07-16 at 14.18.03.png]]](https://i-blog.csdnimg.cn/direct/b0cb02d990fa4bb2b629fa7e5129253c.png)
2.1.1. 学习阶段
预测型机器学习包含两个主要阶段:
- 训练阶段:利用训练数据训练模型,优化损失函数。常见的学习方式有监督学习(分类、回归)、无监督学习、半监督学习、强化学习、联邦学习、集成学习等。
- 部署阶段:将训练好的模型应用于新样本,生成预测结果。
AML文献主要关注攻击在训练阶段(如投毒攻击)和部署阶段(如规避、隐私攻击)的发生。
-
训练阶段攻击(Poisoning Attacks)
- 数据投毒(Data Poisoning):攻击者插入或修改部分训练样本。
- 模型投毒(Model Poisoning):攻击者控制模型参数,常见于联邦学习和供应链攻击。
-
部署阶段攻击
- 规避攻击(Evasion Attacks):攻击者在测试阶段对输入样本进行微小扰动,影响预测结果。
- 可用性攻击与隐私攻击:如成员推断、数据重建等。
2.1.2. 攻击者目标与意图
- 可用性攻击(Availability Breakdown)
通过训练或部署阶段的投毒、能量延迟攻击等方式,使系统不可用或反应迟缓。 - 完整性攻击(Integrity Violation)
通过规避或投毒手段,使模型输出错误预测。可包括定向投毒、后门攻击、模型投毒等。 - 隐私攻击(Privacy Compromise)
通过成员推断、数据重建、模型提取等手段泄露或推断敏感信息。
2.1.3. 攻击者能力
攻击者可利用的能力包括:
- 训练数据控制:插入或修改部分训练数据(用于数据投毒、定向/后门投毒等)
- 模型控制:直接修改模型参数(如在联邦学习中提交恶意本地模型)
- 测试数据控制:对部署阶段输入进行扰动(如规避攻击)
- 标签控制限制:控制标签与否影响攻击方式(如干净标签投毒)
- 源代码控制:篡改ML算法的源代码
- 查询访问:通过API等接口查询模型输出,用于黑盒规避、能量延迟、隐私攻击等
2.1.4. 攻击者知识
- 白盒攻击:攻击者完全了解模型架构、参数、训练数据等,适用于分析系统最坏情况下的脆弱性。
- 黑盒攻击:攻击者仅能通过查询获得模型输出,对内部结构不了解,贴近实际应用环境。
- 灰盒攻击:攻击者部分了解模型(如知道架构但不知参数),介于白盒与黑盒之间。
2.1.5. 数据模态
对抗性攻击可面向不同数据类型,包括:
- 图像:如图像对抗样本与后门攻击
- 文本:规避、投毒和隐私攻击均有案例
- 音频、视频:同样存在针对性攻击
- 网络安全数据:如恶意软件检测、垃圾邮件分类、网络入侵检测
- 表格数据:如金融、医疗领域的隐私与可用性攻击
多模态(如图文结合)模型的对抗性鲁棒性成为新的挑战和研究热点。
2.2. Evasion Attacks and Mitigations
-
对抗性规避攻击的发现
规避攻击(evasion attacks)指攻击者通过生成对抗样本,使其被机器学习模型错误分类为攻击者选择的任意类别,且通常只需对原始样本做最小幅度的扰动。例如,在图像分类任务中,这些扰动对人类不可察觉,但足以让模型将样本误判为其他类别。 -
历史与早期实例
规避攻击的早期研究可追溯至1988年Kearns和Li的工作。2004年,Dalvi等人与Lowd和Meek分别在垃圾邮件过滤场景下,展示了线性分类器也易受对抗样本攻击。Szegedy等人进一步证明了深度神经网络在图像分类任务中同样脆弱,易被对抗样本误导。 -
攻击生成技术的发展
2013年,Szegedy等人与Biggio等人分别提出了基于梯度优化生成对抗样本的方法,适用于线性模型和神经网络。这些技术需要攻击者拥有模型的白盒访问权限(即对模型结构和参数完全知晓),后续方法进一步减小扰动幅度,使对抗样本更不易被人察觉。 -
黑盒场景下的规避攻击
对抗样本不仅限于白盒场景。即便攻击者只能通过查询模型接口获得预测标签或置信分数(黑盒访问),深度神经网络依然脆弱。常见黑盒攻击技术包括零阶优化、离散优化、贝叶斯优化等;此外,通过在不同模型上生成白盒对抗样本再迁移到目标模型(迁移攻击)也是有效手段。
2.2.1. White-Box Evasion Attacks
在白盒威胁模型(white-box threat model)中,攻击者拥有对机器学习模型结构和参数的全部了解。攻击者的主要目标是对测试样本进行微小扰动,使其分类标签发生改变,且通常对扰动的可感知度或大小有约束。白盒环境下,生成对抗样本通常可通过求解一个从攻击者角度出发的优化问题来实现,该问题明确了优化目标(如将目标标签更改为某一类别),并采用距离度量衡量测试样本与对抗样本的相似性。
基于优化的攻击方法
- Szegedy等人和Biggio等人分别提出了利用优化技术生成对抗样本的方法。在这些威胁模型中,攻击者可以访问完整模型并计算损失函数的梯度。这些攻击可以是有目标的(攻击者指定对抗样本的类别),也可以是无目标的(使对抗样本被错误分类为任何其他类别)。
- Szegedy等人提出了“对抗样本”这一术语,并采用( l_2 )范数最小化扰动,同时使模型预测改变为目标类别。该优化问题通过L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno)算法求解。
- Biggio等人将此方法应用于线性分类器、核SVM和多层感知机,其优化目标是最小化判别函数,以生成置信度最高的对抗样本。
- Goodfellow等人引入了快速梯度符号法(FGSM),这是一种为深度学习模型生成对抗样本的高效方法,仅需一次梯度下降。Kurakin等人进一步将其扩展为迭代FGSM攻击。
通用规避攻击
Moosavi-Dezfooli等人提出了“通用扰动”,即可以对大多数图像添加同一微小扰动并导致误分类。该方法通过对数据分布中多个样本的连续优化实现,属于功能型攻击。研究发现,通用扰动在不同模型之间具有较强的泛化能力。
物理可实现攻击
某些攻击可在物理世界中实际实施。例如Sharif等人通过定制眼镜框攻击人脸识别系统;Eykholt等人通过在交通标志上贴黑白贴纸,使视觉分类器在现实环境中失效;ShapeShifter攻击则针对目标检测器,需扰动对多个边界框的分类,同时保证扰动在不同距离、角度、光照和摄像头条件下仍然有效。
其他模态
在计算机视觉中,对抗样本通常设计为对人类可感知性极低,因此扰动很小,人在视觉上依然能识别原始类别,但模型会被误导。此外,也可以通过在图像中加入对人类无害或难以察觉的触发物,导致模型误分类。对抗样本的概念也已扩展到音频、视频、自然语言处理和网络安全等其他领域,不同模态下攻击手法和约束条件会有所区别。
2.2.2. Black-Box Evasion Attacks
黑盒规避攻击(black-box evasion attacks)是在更为现实的对抗模型下设计的,此时攻击者对模型结构或训练数据没有任何先验知识。攻击者只能通过对已训练好的机器学习模型进行查询,获得模型针对不同输入样本的预测结果。类似的查询接口也广泛存在于云服务提供的机器学习即服务(MLaaS)平台,用户可以在不了解模型内部细节的情况下获取指定输入的模型预测。
黑盒规避攻击主要分为两类:
1. Score-based attacks(基于置信分数的攻击)
在这种设置下,攻击者可以获得模型的置信分数(confidence scores)或logits(未归一化得分)。攻击者可以利用多种优化技术来生成对抗样本。常用的方法包括:
- 零阶优化(zeroth-order optimization),该方法可以在无需显式求导的情况下估计模型的梯度。
- 其他优化方法还包括离散优化(discrete optimization)、自然进化策略(natural evolution strategies) 和随机游走(random walks)。
2. Decision-based attacks(基于决策的攻击)
在这种更受限的设置下,攻击者只能获得模型的最终预测标签。
- 最早的相关攻击方法是Boundary Attack,该方法基于在决策边界上的随机游走和重采样。
- 此方法在HopSkipJumpAttack中通过改进梯度估计减少了所需的查询次数。
- 最近还出现了其他优化方法,例如:
- 寻找最近决策边界方向的OPT攻击
- 使用Sign SGD替代二分搜索的Sign-OPT攻击
- 贝叶斯优化(Bayesian optimization)
主要挑战
在黑盒设置下生成对抗样本的主要挑战是如何减少对机器学习模型的查询次数。近期的技术已经可以在较少的查询次数下(通常少于1000次)成功规避机器学习分类器。
2.2.3 Transferability of Attacks
- 核心观点:对抗攻击具有可迁移性,即在一个模型上生成的对抗样本通常能够成功攻击其它结构或参数不同的模型。
- 原因:不同模型对输入数据的决策边界存在重叠,因此对抗样本往往能“跨模型”生效。
- 实践方法:攻击者可训练替代模型(通过查询目标模型或集成多模型),在替代模型上生成对抗样本并转移到目标模型实施攻击。
- 技术进展:如Expectation over Transformation方法,使生成的样本在现实环境(视角、光照等变化)下依旧有效。
- 意义:即便攻击者无法直接访问目标模型参数,也能通过迁移性实现有效攻击。
2.2.4 Evasion attacks in the real world
- 现实威胁:规避攻击已在多个现实场景中出现,影响人脸识别、恶意软件检测、钓鱼网站检测等系统。
- 典型案例:
- 美国ID.me人脸识别遭遇数万起规避攻击,黑客通过口罩、深度伪造、假发等方式骗取身份验证,造成数百万美元损失。
- 钓鱼网站检测系统被简单裁剪、模糊等“低技术”对抗手法绕过。
- 恶意软件检测与邮件防护系统也被通用对抗样本规避,甚至出现通过影子模型绕过商业安全系统的现象。
2.2.5 Mitigations
- 挑战性:规避攻击防御难度极大,许多看似有效的防御在面对更强攻击或自适应攻击时很快被破解。
- 主流方法:
- 对抗训练:在训练过程中持续加入并优化对抗样本,提升模型鲁棒性,但通常牺牲部分准确率,并且计算开销大。
- 随机平滑:通过加入噪声实现部分样本的鲁棒性认证,适用于大规模数据集和(l_2)范数下的攻击,但不是所有输入都能认证。
- 形式化验证:用形式方法为部分网络提供鲁棒性保证,但目前难以扩展到大规模模型。
- 趋势与注意事项:需用自适应攻击严格评估防御有效性,防御和准确率、资源消耗之间存在明显权衡。鲁棒性提升同时带来准确率下降和计算成本增加。
2.3 Poisoning Attacks and Mitigations
概述
- 投毒攻击(poisoning attacks)是指针对机器学习算法训练阶段的对抗性攻击,攻击者通过控制或篡改训练数据、标签甚至训练过程,影响模型的性能或行为。
- 这些攻击已在多个领域得到研究,包括计算机安全(如垃圾邮件检测、网络入侵检测、恶意软件分类)、计算机视觉、自然语言处理以及医疗和金融等表格数据领域。
- 投毒攻击可分为两大类威胁:
- 可用性攻击(Availability poisoning):导致模型整体性能下降。
- 完整性攻击(Integrity poisoning,包括Targeted和Backdoor):只影响特定样本或带有特定触发器的样本。
2.3.1 可用性投毒攻击(Availability Poisoning)
- 该类攻击旨在让模型在所有样本上的性能大幅退化,常见于早期垃圾邮件分类、蠕虫签名生成等场景。
- 攻击方法包括:伪造带有合法特征的垃圾邮件、篡改模型训练流程等,通常在白盒环境下进行(攻击者了解训练算法和数据)。
- 黑盒投毒方法如标签翻转(label flipping),即向训练集加入错误标签的数据,或者通过优化方法自动生成“最优”投毒样本。
- 防御措施包括:
- 训练数据清洗(如多数投票、RONI、标签清理、异常点检测、聚类方法等)
- 鲁棒性训练(如模型集成、修剪损失函数、随机平滑)
- 监控模型性能指标以检测异常
2.3.2 定向投毒攻击(Targeted Poisoning)
- 不同于可用性攻击,定向攻击只改变模型对少量特定目标样本的预测。常见于“clean-label”场景,即攻击者无法直接控制标签,只能对输入特征做微小调整。
- 代表性方法包括:影响函数(influence functions)、StingRay、特征碰撞、优化生成对抗样本等。
- 子群体投毒(subpopulation poisoning)可以针对一组具有特定特征的样本,实现“群体”级别的影响。
- 防御措施包括:
- 数据访问控制、数据清洗、溯源与完整性验证
- 差分隐私(DP)等机制,但通常有准确率和鲁棒性之间的权衡
2.3.3 后门投毒攻击(Backdoor Poisoning)
- 攻击者在训练集中植入带有特定触发器(如图像中的小块、文本中的特定词)的样本,并将其标签改为目标类别,从而让模型潜在地学会“后门”。触发器可以是固定的、动态的、物理的(如墨镜、耳环)或功能性的。
- 除视觉外,后门攻击已被扩展到语音、NLP和网络安全等领域。
- 防御措施包括:
- 数据清洗(如特征空间异常检测、激活聚类等)
- 触发器重构(如NeuralCleanse,ABS等)
- 模型检查与清理(如神经元分析、生成模型检测、修剪、微调等)
- 认证防御(如BagFlip、模型分区集成等)
- 溯源分析(poison forensics)用于追溯投毒源
2.3.4 模型投毒(Model Poisoning)
- 主要针对联邦学习(federated learning)等场景,攻击者通过发送恶意模型更新,使全局模型注入后门或整体性能下降。也可在供应链环节通过篡改模型、代码或超参数实现。
- 防御措施包括:
- Byzantine鲁棒聚合方法(识别并剔除异常更新)
- 梯度裁剪、差分隐私、模型检查和清理
- 供应链安全(但仍然面临验证难题)
2.3.5 现实世界中的投毒攻击
- 虽然需要对训练流程有一定控制,投毒攻击在现实中已有案例,包括Tay.AI聊天机器人、Gmail垃圾邮件过滤器和VirusTotal恶意软件分类系统等。
- 这些案例突显了在线学习和持续更新模型的风险,攻击者可在模型发布后持续投毒。
2.4. Privacy Attacks and Mitigations
本节讨论了与隐私相关的攻击,包括数据重构(data reconstruction)、训练数据记忆(memorization of training data)、成员推断(membership inference)、属性推断(property inference)和模型提取(model extraction)等攻击类型,以及针对部分攻击的缓解措施和在设计通用缓解策略方面的未决问题。
2.4.1 Data Reconstruction
- 数据重构攻击(Data Reconstruction)旨在从已训练模型获取个体用户记录或其他敏感输入数据的私有信息。
- Dinur和Nissim首次提出了这种攻击方式,利用线性统计信息恢复用户数据。最初的攻击需要指数级查询,后续工作将其优化为多项式级别查询。
- 相关综述由Dwork等人提供。美国人口普查局对人口普查数据重构的风险进行了大规模研究,推动了2020年人口普查中差分隐私(DP)的采用。
- 在机器学习分类器领域,Fredrickson等人提出了模型反演攻击(model inversion),可以从模型训练数据中重构类别代表样本。
- 进一步研究表明,利用神经网络参数可恢复二分类和多分类神经网络的训练数据,部分原因在于神经网络存在记忆训练数据的倾向。
- Zhang等讨论了神经网络对随机数据集的记忆能力,Feldman等则证明了标签记忆对于获得近乎最优泛化误差的必要性。
2.4.2 Membership Inference
- 成员推断攻击(Membership Inference)允许攻击者判断某条记录是否在训练集内,这对涉及敏感数据的场景(如罕见疾病医疗研究)尤其敏感。
- 该攻击最早由Homer等人提出,用于基因组数据,后续被广泛应用于深度神经网络等模型。
- 攻击可以在白盒(已知模型参数与结构)和黑盒(仅能查询模型)环境下进行,但大多数研究集中在黑盒环境。
- 技术方法包括:
- 基于损失的攻击(Yeom等):判断目标样本的损失是否低于阈值。
- 阴影模型(Shadow Models,Shokri等):训练多个“影子模型”构建元分类器,区分样本是否在训练集。
- LiRA攻击(Carlini等):用少量影子模型,假设logit分布为高斯分布,进行假设检验。
- 仅标签攻击(label-only threat model):攻击者仅能获得模型预测标签。
- 公开的隐私攻击工具库包括TensorFlow Privacy和ML Privacy Meter。
2.4.3 Property Inference
- 属性推断攻击(Property Inference,也称分布推断)旨在获取训练数据集的全局属性信息,例如敏感属性(如人口统计信息)的比例。
- 该攻击可以在白盒或黑盒设置下展开,适用于多种模型(如隐马尔可夫模型、支持向量机、前馈神经网络、卷积神经网络、联邦学习、生成对抗网络、图神经网络等)。
- Ateniese等提出了此类攻击,并通过区分博弈形式化;后续研究表明,针对感兴趣属性的投毒可提升推断效果。
- Chaudhauir等提出了高效的属性规模估计算法,可恢复特定属性在训练集中的确切比例。
- Salem等则统一梳理了成员推断、属性推断等多类训练集推断攻击的关系。
2.4.4 Model Extraction
- 模型提取攻击(Model Extraction)主要针对ML即服务(MLaaS)场景,攻击者通过查询模型试图恢复其架构和参数。
- Tramer等首次展示了不同ML服务(如逻辑回归、决策树、神经网络)的模型窃取攻击。
- Jagielski等证明,精确还原原始模型参数不可行,但可以提取功能等价的模型(NP-hard问题,计算上极难)。
- 攻击技术包括:
- 直接提取:利用神经网络等模型的数学结构恢复权重;
- 学习型提取:如主动学习、强化学习等,用于高效指引查询;
- 侧信道提取:如电磁信号(Batina等)或Rowhammer攻击(Rakin等)。
- 模型提取往往不是最终目的,知晓架构和参数后可实施更强的白盒/灰盒攻击,因此防止模型提取有助于缓解后续攻击。
2.4.5 Mitigations
- 差分隐私(Differential Privacy, DP)是对抗重构和成员推断攻击的主流理论工具,通过定义隐私预算ε(及辅助参数δ),对单条记录的泄露风险设定上限。常见算法有DP-SGD、DP-FTRL等,实际使用中需在隐私与模型效用之间权衡。DP针对数据重构与成员推断有效,但无法防御模型提取攻击,对属性推断的防御效果也有限。
- 隐私审计(Privacy Auditing)通过“金丝雀”样本等方法,实测实际隐私泄漏,补充理论分析。
- 其他防御模型提取的方法包括:限制模型查询、检测可疑查询、设计更健壮的模型架构等,但面对高资源攻击者仍可能失效。
- 机器遗忘(Machine Unlearning)是新兴隐私防护手段,允许用户请求从已训练模型中删除其数据,分为精确遗忘(重训)与近似遗忘(参数调整),各有计算与隐私权衡。
Generative AI Taxonomy
3.1 攻击分类(Attack Classification)
攻击类型概述
- 许多在传统AI(PredAI)攻击分类中的攻击类型同样适用于生成式AI(GenAI),包括数据投毒(data poisoning)、模型投毒(model poisoning)、模型提取(model extraction)等。
- 近年来,针对GenAI系统也出现了一些新的对抗性机器学习(AML)攻击类型。
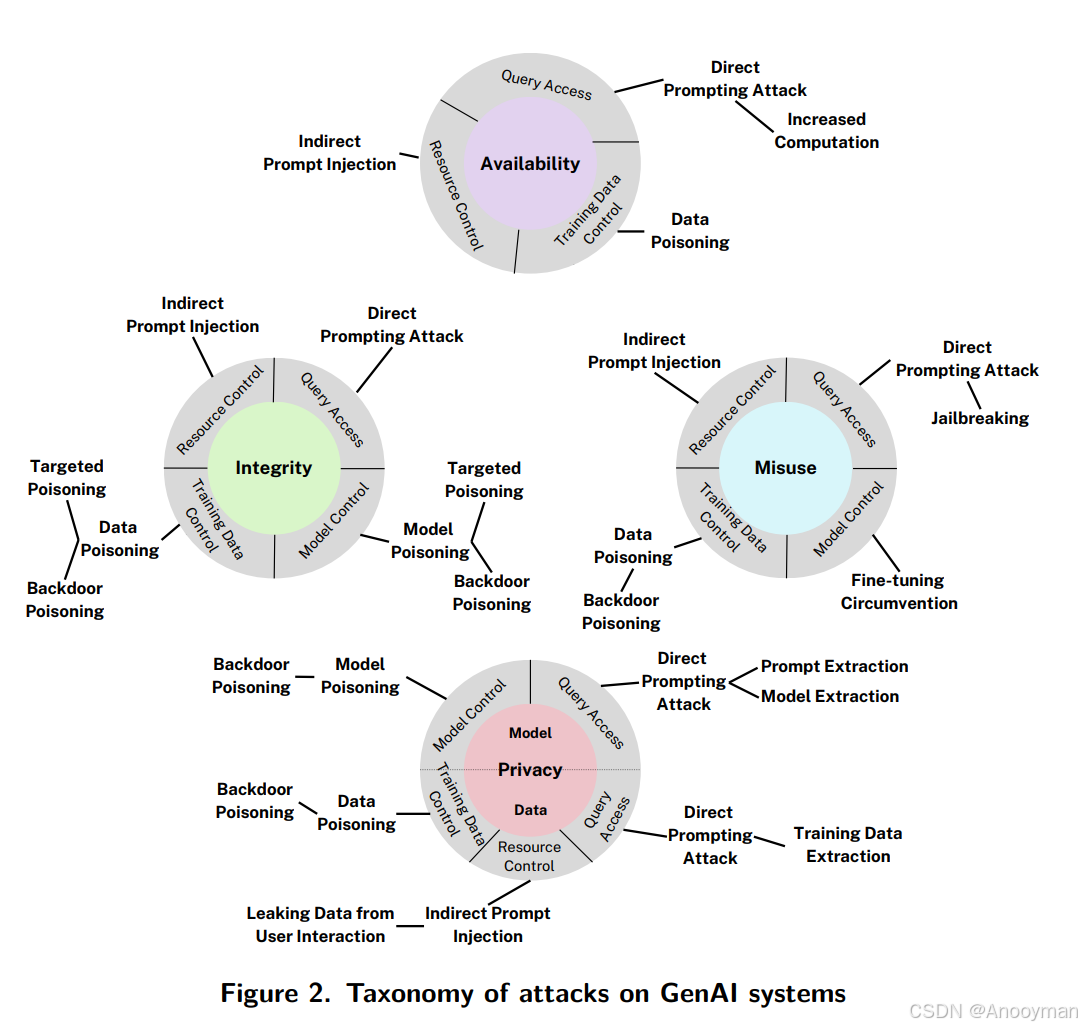
GenAI攻击的分类基础
-
攻击首先根据攻击者试图破坏的系统属性进行分类,主要包括:
- 可用性(Availability):让系统无法正常工作或拒绝服务。
- 完整性(Integrity):篡改或干扰系统输出的正确性与可靠性。
- 隐私(Privacy):泄露或窃取敏感数据与系统内部信息。
- 误用(Misuse):特有于GenAI,指攻击者绕过系统输出的限制,实现“越狱”(jailbreak)等违规用途。
-
攻击类型与攻击目标之间有重叠与交互,同一种攻击方法可能针对多个目标。
具体攻击类型及说明
-
可用性类攻击(Availability):
- 间接提示注入(Indirect prompt injection):通过外部数据源影响模型行为。
- 直接提示注入(Direct prompting attack):直接通过prompt操控模型。
- 增加计算负载(Increased computation):使系统耗尽资源。
- 数据投毒(Data poisoning):在训练数据中植入恶意数据。
- 查询访问(Query access):通过大量查询扰乱服务。
-
完整性类攻击(Integrity):
- 间接/直接提示注入
- 定向数据投毒(Targeted poisoning):针对特定任务或数据进行投毒。
- 模型投毒(Model poisoning)/后门投毒(Backdoor poisoning):篡改模型参数或植入后门。
-
隐私类攻击(Privacy):
- 后门/模型/数据投毒
- 资源控制(Resource control):通过资源操控获取隐私信息。
- 用户交互数据泄漏(Leaking data from user interaction)
- 间接提示注入
-
误用类攻击(Misuse):
- 间接/直接提示注入
- 越狱(Jailbreak):绕过安全限制输出受限内容。
- 微调规避(Fine-tuning circumvention):通过再次微调恢复被压制的有害能力。
- Prompt/模型/训练数据提取
- 直接/后门投毒
3.1.1.攻击阶段与攻击者能力
攻击可按所针对的学习阶段(如训练阶段或推理阶段)、攻击者的知识与访问能力进一步细分。
- 训练阶段常见攻击有数据投毒和模型投毒,尤其因为GenAI常用大规模、来源复杂的公开数据,易被植入恶意样本。第三方模型的微调和集成也带来新的投毒风险。
-
- 数据投毒攻击(Data Poisoning Attacks)
- GenAI模型往往需要大规模、多来源的数据,这带来了较大的攻击面。攻击者可以通过在训练数据中插入恶意构造的数据点(如购买数据集相关域名并替换为恶意内容)来实施投毒。
- 数据投毒不仅影响预训练阶段,也可能影响指令微调、强化学习等后续训练阶段。这些阶段的数据可能来自大量参与者,进一步扩大了攻击面。
- 数据投毒可导致模型行为被攻击者控制,如植入后门(特定词语触发越狱),或通过定向投毒让模型在某些查询下输出错误/有害内容。只需占据数据集很小比例即可产生显著影响。例如,代码生成模型被投毒后可能会建议不安全的代码。
- 模型投毒攻击(Model Poisoning Attacks)
- 开发者常用第三方预训练模型,攻击者可提供恶意设计的预训练模型,在参数中植入后门或定向投毒。
- 恶意后门可能在下游用户微调或安全训练后仍然存留,难以彻底移除。
- 攻击者能力与攻击方式
- 攻击者可通过对模型参数的控制(如公开微调API或开放的模型权重)进行模型投毒或绕过安全机制。
- 攻击者对模型的了解程度不同,可分为白盒(完全了解模型)、黑盒(几乎不了解)和灰盒攻击。
- 资源控制方面,攻击者还可以修改模型在运行时会接触的外部资源(如网页、文档),进行间接提示注入(Indirect Prompt Injection)。
- 供应链相关风险
- GenAI开发涉及依赖第三方数据、模型、插件等,传统软件供应链的漏洞同样适用于AI系统。
- 需要综合考虑整个攻击面,包括数据、模型供应链、软件、网络和存储系统的安全。
-
- 推理阶段(部署阶段)则重点关注提示注入、间接提示注入、输出操控、Agent劫持等。
-
- 直接提示注入(Direct Prompt Injection)
- 攻击者通过输入恶意构造的提示(prompt),覆盖或绕过系统预设的系统提示(system prompt)或安全限制,引导模型生成违规、有害或敏感内容(如jailbreak攻击)。
- 攻击者还可以尝试提取系统提示内容(prompt extraction),以窃取或逆向分析应用安全策略。
-
- 间接提示注入(Indirect Prompt Injection)
- 在RAG(检索增强生成)、Chatbot等应用中,模型会动态地从外部资源(如网页、数据库、文档等)获取上下文信息。
- 攻击者可通过篡改这些外部数据源,注入恶意内容,使模型在推理时被“间接”操控,导致输出不安全的内容、泄露隐私或错误操作。
-
- 输出利用与下游风险
- 模型生成的输出可能被直接用于自动化处理(如网页生成、自动指令、API调用等)。
- 攻击者可诱导模型输出特定格式或内容,触发下游系统的异常行为,造成可用性、完整性、隐私等多方面风险。
-
- Agent劫持与安全风险
- LLM-based Agent(代理)会反复处理模型输出、输入,实现自动化任务。
- 攻击者可通过输入恶意数据或利用上下文,诱导Agent执行危害性操作(如调用敏感API、发送数据、执行未授权指令等),造成安全隐患。
-
3.1.2. 攻击者目标与动机(Attacker Goals and Objectives)
攻击者针对生成式AI(GenAI)系统的目标主要包括以下几类:
- 可用性破坏(Availability Breakdown)
- 攻击者试图让GenAI系统无法正常服务,影响其可用性。(原文未完整展开)
- 完整性破坏(Integrity Violation)
- 攻击者干预GenAI系统,使其偏离预期目标,输出符合攻击者意图的结果。
- 由于用户和企业依赖GenAI系统进行研究、生产力提升等任务,这类攻击可能导致用户对系统的信任被利用,造成更大危害。
- 隐私泄露(Privacy Compromise)
- 攻击者试图获取GenAI系统中的受限或专有信息,如模型训练数据、权重、架构,或模型访问到的敏感知识库(如RAG应用中的数据)。
- 攻击可能发生在训练或推理阶段,包括通过间接提示注入(Indirect Prompt Injection)泄露上下文中的用户信息,或通过模型提取(Model Extraction)获取模型内部信息。
- 恶意用途使能(Misuse Enablement)
- 攻击者旨在绕过GenAI系统所有者施加的技术限制(如系统提示、RLHF安全对齐),使系统生成可能对他人造成危害的输出。
- 技术限制措施因模型不同而异,但绕过手法常见于各种模型和不同类型的滥用场景,因此可归类为AML攻击的一部分。
3.1.3. 攻击者能力(Attacker Capabilities)
AML攻击可根据攻击者对GenAI模型或系统输入的控制能力进行分类,主要包括:
- 训练数据控制(Training Data Control)
- 攻击者可插入或修改部分训练样本,实现对训练数据的控制。这种能力用于数据投毒攻击(Data Poisoning Attacks)。
- 查询访问(Query Access)
- 许多GenAI模型和应用作为服务开放给互联网用户,攻击者可通过精心设计的查询触发特定行为或窃取信息。此能力用于提示注入(Prompt Injection)、提示提取(Prompt Extraction)、模型提取(Model Extraction)等攻击。攻击者可调整生成参数(如温度、logit bias)或利用多样化的生成结果。
- 资源控制(Resource Control)
- 攻击者可修改GenAI模型在运行时会读取的外部资源(如文档、网页),实现间接提示注入攻击(Indirect Prompt Injection)。
- 模型控制(Model Control)
- 攻击者能修改模型参数(如通过公开微调API或开放模型权重),实施模型投毒(Model Poisoning)或绕过安全干预(Fine-tuning Circumvention)。
- 攻击者知识水平
- 攻击者对模型了解的程度不同,从完全知晓模型权重(白盒攻击)、几乎不了解(黑盒攻击),到介于两者之间(灰盒攻击)。
3.2 供应链攻击与缓解(Supply Chain Attacks and Mitigations)
人工智能(AI)作为软件系统,继承了传统软件供应链的许多漏洞,如对第三方依赖的依赖性。AI开发又引入了新的依赖类型,包括数据收集、第三方模型集成、插件集成等。供应链风险管理需结合传统软件供应链治理方法和AI特有的风险缓解措施,如利用可信来源和溯源信息。有些攻击依赖于机器学习系统特定的统计和数据特性,属于对抗性机器学习(AML)范畴。
3.2.1 数据投毒攻击(Data Poisoning Attacks)
数据投毒是指攻击者在训练数据中插入精心设计的恶意样本,影响模型行为。对于GenAI,公开大规模数据集和微调/强化学习数据都可能成为投毒目标。只需极少量恶意数据就可能让模型产生后门或在特定“触发词”下输出异常内容,如越狱(jailbreak)、不安全代码、特定虚假信息等。
3.2.2 模型投毒攻击(Model Poisoning Attacks)
模型投毒主要发生在依赖第三方预训练模型时。攻击者可在公开模型中植入后门,诱使下游开发者集成这些模型。即使后续进行微调或安全增强,后门仍可能存留,从而危害最终产品的安全性和可信度。
3.2.3 缓解措施(Mitigations)
缓解GenAI供应链风险,需要强化对数据和模型来源的验证与溯源,采用可信渠道。应综合考虑数据、模型、工具和网络等全链路的风险管理,并结合传统软件供应链治理方法与AI特有的防护措施。
3.3 直接提示攻击与缓解措施(Direct Prompting Attacks and Mitigations)
3.3.1 攻击技术
- 直接提示攻击是指攻击者作为系统主要用户,通过与模型交互的查询输入实现攻击目的。
- 攻击目标包括:绕过模型安全限制(如实现“越狱”Jailbreak)、隐私泄露、完整性破坏(如操纵工具使用或API调用)。
- 攻击手段分为三大类:
- 基于优化的方法:通过设计攻击目标函数,使用梯度或其他搜索方法生成能诱导特定行为的输入;如通用对抗触发器,可迁移到其它模型。
- 手动方法:
- 针对竞争目标的攻击方法包括:前缀注入、拒绝抑制、语气/风格注入、角色扮演等,通过利用模型在能力与安全目标间的冲突实现攻击。
- 针对不匹配泛化攻击的方法包括:特殊编码(base64)、字符变换(ROT13、1337speak)、词语变换(同义词替换、拆分)、提示级变换(小语种翻译)等,使输入避开安全训练分布。
- 自动化红队测试:利用攻击模型、目标模型和判别器自动生成并优化攻击提示,如Crescendo攻击利用多轮对话逐步引导模型越狱。
3.3.2 信息提取
攻击者可利用模型输出提取训练数据中的敏感信息(如PII)、上下文中的隐私内容、系统提示(Prompt Stealing)及模型结构信息(Model Extraction)。
3.3.3 缓解措施
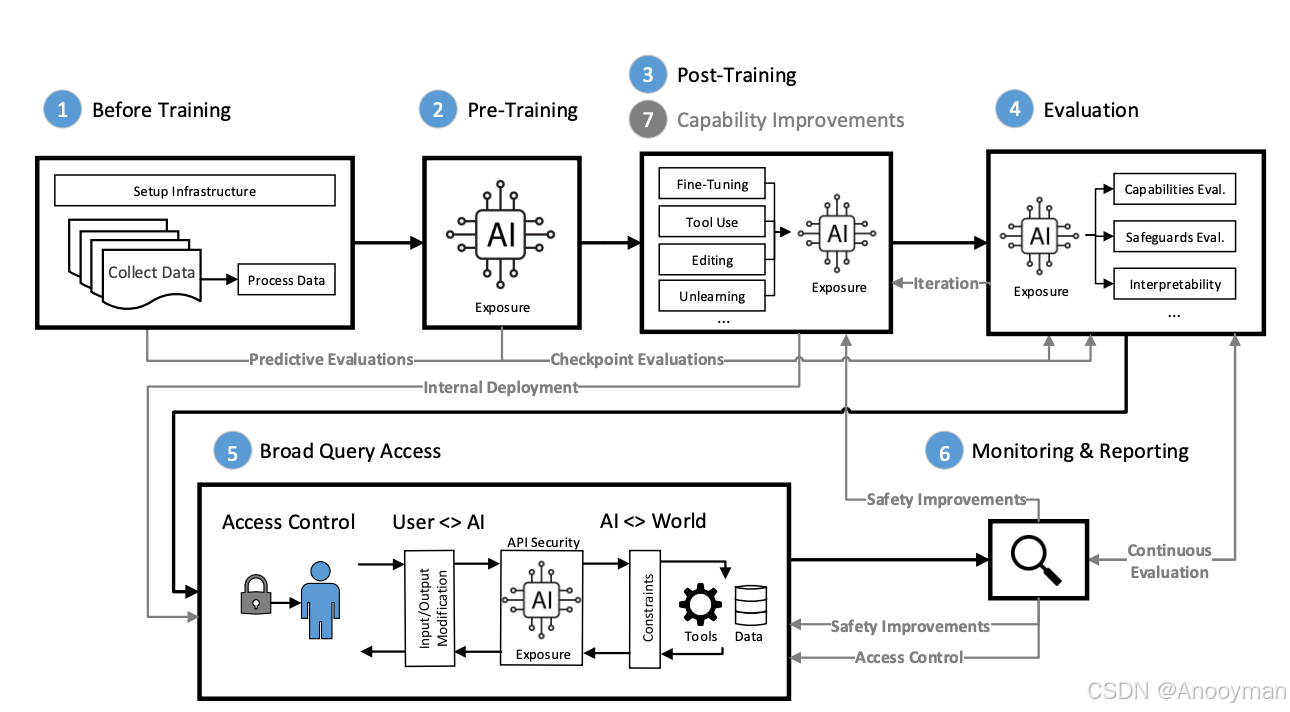
- 训练阶段干预:在预训练、后训练阶段引入安全训练、对抗训练等提升模型对恶意提示的鲁棒性。
- 评估阶段干预:自动化漏洞评估、红队测试、漏洞赏金等措施及时发现和修复模型脆弱点。
- 部署阶段干预:
- 明确区分系统指令与用户输入(如用XML标签封装用户输入);
- 检测并中止有害交互;
- 检测提示窃取;
- 输入修改(如同义改写、重分词);
- 多提示输出聚合(如SmoothLLM);
- 用户行为监控与响应(如封禁恶意用户);
- 限制用户可控参数、查询次数等。
- 间接措施:
- 训练数据净化(training data filtering/cleansing):在模型训练前,审查和清理训练数据,去除潜在的有害内容或敏感信息,减少模型学习到不当响应的机会。
- 模型“遗忘”技术(machine unlearning/forgetting):通过技术手段让模型“忘记”特定类型的知识或样本,针对后门、敏感信息等进行“擦除”,以降低模型被攻击时泄漏信息的风险,但当前这类技术仍处于研究阶段,实际应用效果有限。
- 数据水印(data watermarking):在训练数据或模型输出中嵌入水印,帮助追溯数据来源,检测模型输出是否受到攻击者操控,或在模型泄露时进行溯源。
- 上下文限制与分层(context restriction & compartmentalization):通过限制模型每次可访问的上下文范围,或对不同类型的数据、功能进行隔离,减少单次攻击带来的影响范围。
- 外部监控与响应机制(external monitoring & response):部署外部安全监控系统,实时检测和阻断异常行为或可疑攻击流量。
3.4 间接提示注入攻击及其缓解措施
3.4.1 可用性攻击
- 攻击者通过操控外部资源,注入提示导致模型服务不可用或者特定功能被阻断。
- 具体手法包括:
- 让模型执行耗时任务(如请求模型循环执行某操作),拖慢响应速度。
- 禁用特定API(如让联网聊天机器人无法调用搜索API)。
- 干扰输出格式(如用同形异义符替换文本、添加特殊token导致输出为空)。
3.4.2 完整性攻击
- 攻击者通过恶意资源,使模型生成偏离正常行为、有利于攻击者目标的结果。
- 手法包括:
- “越狱”攻击,将恶意指令替换系统提示;
- 自动化执行触发器(如Neural Exec),可穿透多阶段RAG流程;
- 知识库投毒(如PoisonedRAG、Phantom),通过插入恶意文档影响检索结果;
- 隐藏注入(如在不可见区域、Base64编码、分阶段注入);
- 自传播攻击(如利用邮件客户端模型传播恶意邮件)。
3.4.3 隐私攻击
- 攻击者诱导模型泄露用户隐私或敏感数据。
- 手法包括:
- 利用模型访问权限,将用户邮件转发到攻击者邮箱或通过特定URL泄露数据;
- 诱导用户主动泄露信息,再通过模型将信息传递给攻击者。利用如markdown图片渲染等特性进行数据外传。
3.4.4 缓解措施
- 训练阶段:微调特定任务模型、训练模型遵循分层信任关系。
- 检测与防御:开发检测间接提示注入的方法,采用LLM驱动的防御方案。
- 输入处理:过滤第三方数据中的指令、设计区分可信/不可信数据的提示、引导模型忽略不可信数据中的指令。
- 其他措施:采用多模型分权、仅通过严格接口访问不可信数据源,加强用户及开发者教育,提升对间接提示注入风险的认知。
目前缓解手段尚不能完全防御所有攻击场景,建议系统设计时默认存在提示注入风险。
3.5 安全智能体(Security of Agents)
随着LLM驱动的智能体在自动化任务、工具调用、API集成等领域的广泛应用,其安全风险显著增加。攻击者不仅可以通过输入诱导智能体执行未授权操作,还能利用环境中的有害内容、间接注入等方式影响智能体行为。 由于智能体具备自动决策和行动能力,一旦被攻陷,可能造成更大范围的安全、隐私和完整性威胁。因此,智能体的安全评估和防护成为生成式AI安全领域的研究重点之一。
3.6 对抗性机器学习漏洞评测基准(Benchmarks for AML Vulnerabilities)
标准化的漏洞评测基准有助于系统性识别和比较不同模型在面对多种攻击(如提示注入、数据投毒等)时的脆弱性。 当前,相关研究和社区已经建立了一系列测试集、自动化红队工具和评测框架,用于检测模型在安全属性、鲁棒性等方面的表现。这些基准和工具为开发者和研究者提供了有效的评估手段,推动了生成式AI系统安全性的持续提升。
Key Challenges and Discussion
4.1 AML(对抗性机器学习)中的关键挑战
-
多属性权衡问题
- AI系统的可信赖性涉及多个属性(如可解释性、对抗鲁棒性、隐私、公平性等),这些属性之间存在难以兼得的权衡。例如,单纯优化准确率往往会降低对抗鲁棒性和公平性,反之亦然。
- 最优权衡通常以“帕累托最优(Pareto optimality)”方式存在,即无法提升某一属性而不牺牲另一属性。实际应用中,组织需结合自身需求和场景,决定优先关注哪些属性。
-
对抗鲁棒性的理论局限
- 由于攻击手段多样,完全鲁棒的机器学习系统在理论上通常难以实现,现有的防御措施大都依赖经验方法,缺乏通用、完备的理论保障。
- 检测模型是否正遭受攻击本身就是一个难题,检测对抗样本与实现鲁棒分类等价,理论上难以彻底解决。分布外(OOD)输入检测也面临理论上的不可能结果。
-
评估难题
- 目前针对逃逸攻击和投毒攻击的防御缺乏统一、可靠的基准,导致研究结果难以直接比较。
- 有效的防御措施不仅要对已知攻击有效,还要能抵御未知攻击。新防御方法应在“对抗性”环境下测试,且多属性需同时评估,而非孤立评判。
- 多属性权衡进一步加大了评估成本,使得不同防御方案难以直接优劣对比。
4.2 讨论
-
规模挑战
- 大模型和大数据集的使用成为趋势,多模态生成式AI系统对数据量需求更高。数据源分散,缺乏统一管理,带来新的安全边界和数据投毒风险。
- 开源数据投毒工具的出现,使大规模投毒攻击风险增加。数据/模型净化、加密溯源等措施有一定帮助,但对复杂模型与多模态数据的适用性和效果仍有待研究。
-
供应链挑战
- 新型攻击日益难以检测,模型中植入特定后门(如信息论不可检测的特洛伊攻击)使供应链风险加剧。对开源依赖项的攻击尤需警惕。
- 现有检测和溯源技术(如TrojAI项目)正积极研发,但完全防范仍有难度。
-
多模态模型
- 虽然多模态模型性能提升,但信息冗余不一定带来更强鲁棒性。单一模态的扰动依旧可显著影响整体模型。仅针对单模态扰动的防御通常不够,且多模态组合攻击风险提升。
-
量化模型
- 模型量化(如8位、4位整数)有助于边缘部署,但会引入新的对抗性脆弱点。量化误差会放大攻击影响,甚至可能让原本安全的模型在量化后变得可被攻击。
- 目前GenAI领域对量化影响的系统性研究仍较少,需持续监控部署模型的行为。
-
风险管理与决策
- 组织如何在对抗性风险和防御有效性存在局限的情况下做出开发和应用决策,成为重要议题。
- 一些开发者已将对抗性测试纳入模型上线前的评估流程,NIST等机构也出台了相关指导和风险评估框架。
-
AML与AI系统其他特性关系
- AI系统的安全不仅仅依赖AML防御,还应结合传统安全开发最佳实践。需进一步明确AML与AI安全、可信等其他系统属性之间的关系。
- AML既不是AI安全的唯一方面,也不是其子集,与AI安全、AI可信等目标的结合与风险管理仍是持续研究的重点。
关键名词解释
- adversarial example(对抗样本):指能够诱使模型在部署时产生错误分类或错误行为的经过修改的测试样本。
- adversarial machine learning(对抗性机器学习):指利用机器学习系统的统计和数据特性进行攻击的方法。
- attribute inference attacks(属性推断攻击):攻击者基于部分已知信息推断训练数据中的敏感属性。
- backdoor pattern(后门模式):通过特定变换或插入触发模型被攻击者控制的行为。
- data poisoning(数据投毒):攻击者控制部分训练数据,对模型训练过程造成影响。
- deployment stage(部署阶段):模型被集成到实际应用或通过API向终端用户开放的阶段。
- federated learning(联邦学习):在不汇集原始数据的情况下,多个数据源协同训练全局模型。 - fine-tuning(微调):对预训练模型进行特定任务或领域的再训练。
- membership-inference attack(成员推断攻击):判断特定数据是否被用于模型训练的攻击方式。
- model extraction(模型提取):攻击者获取模型结构或参数的攻击。
- multimodal models(多模态模型):能够处理和关联多种感知通道(如视觉、触觉)信息的模型。
- prompt injection(提示注入):通过拼接不可信输入影响生成式AI系统行为的攻击。
- training data extraction(训练数据提取):攻击者通过特定输入诱使生成模型泄露训练数据。
- trojan(特洛伊/后门):难以检测、可被特定信号激活以造成恶意行为的模型修改。
- unsupervised learning(无监督学习):模型在无标签数据上学习的方式,如聚类等。