李宏毅《生成式人工智能导论》 | 第15讲-第18讲:生成的策略-影像有关的生成式AI
文章目录
- 生成策略
- 生成策略:Autoregressive Generation AR
- 生成策略:Non-autoregressive Generation NAR
- 可以加速所有语言模型生成速度的神奇外挂:Speculativ
- 影像有关的生成式AI
- 影像有关生成式AI的应用
- AI怎么产生的图片和影像
- 如何衡量影像生成的好坏
- 个人化的图像生成
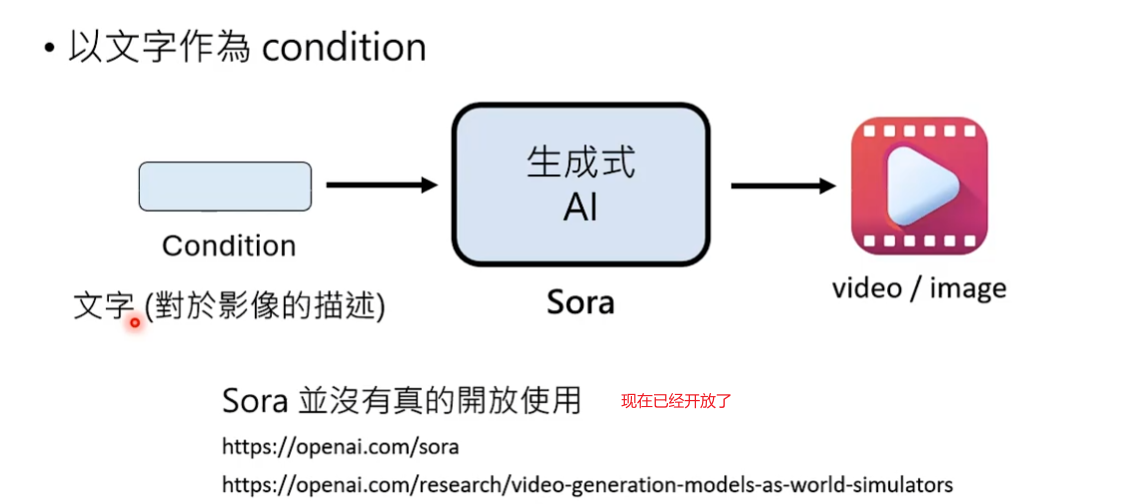
- 文字生成影片
- 经典影像生成方法
- VAE Variational Auto-encoder模型
- Flow-based 模型
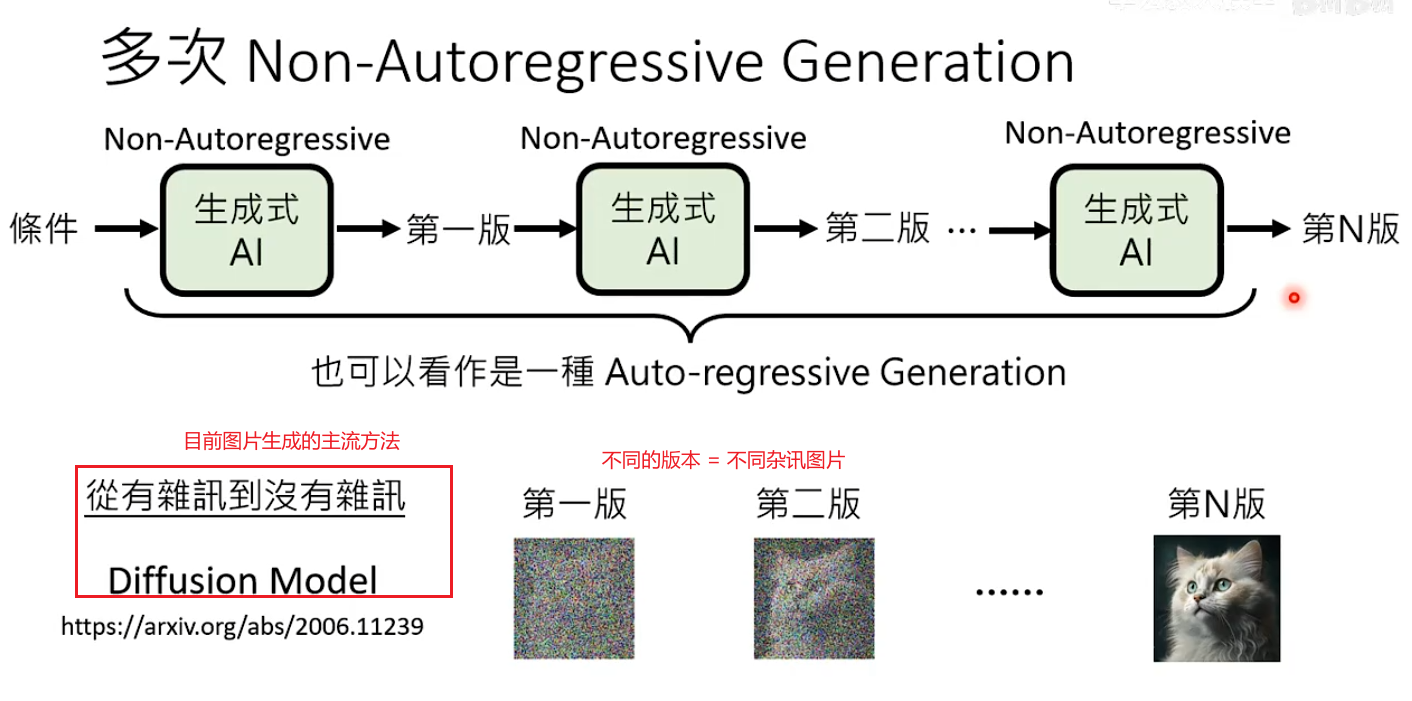
- Diffusion Model
- Generator Adversarial Network(GAN)
生成策略
生成式AI:让机器产生复杂有结构的物件,比如文字、影响、声音等。
- 文字:一句话由token组成
- 影像:由一个一个像素构成,每个像素有多少颜色取决于BPP(Bit per Pixel)。
8BPP:256色,16BPP:65536色,24BPP:1670万色
- 声音:由取样点构成,每个点有多少数值取决于取样解析度
16KHZ取样率每一秒有16000个点

生成式人工智能的本质:给定条件后,生成式AI把基本单位用正确的排序组合起来
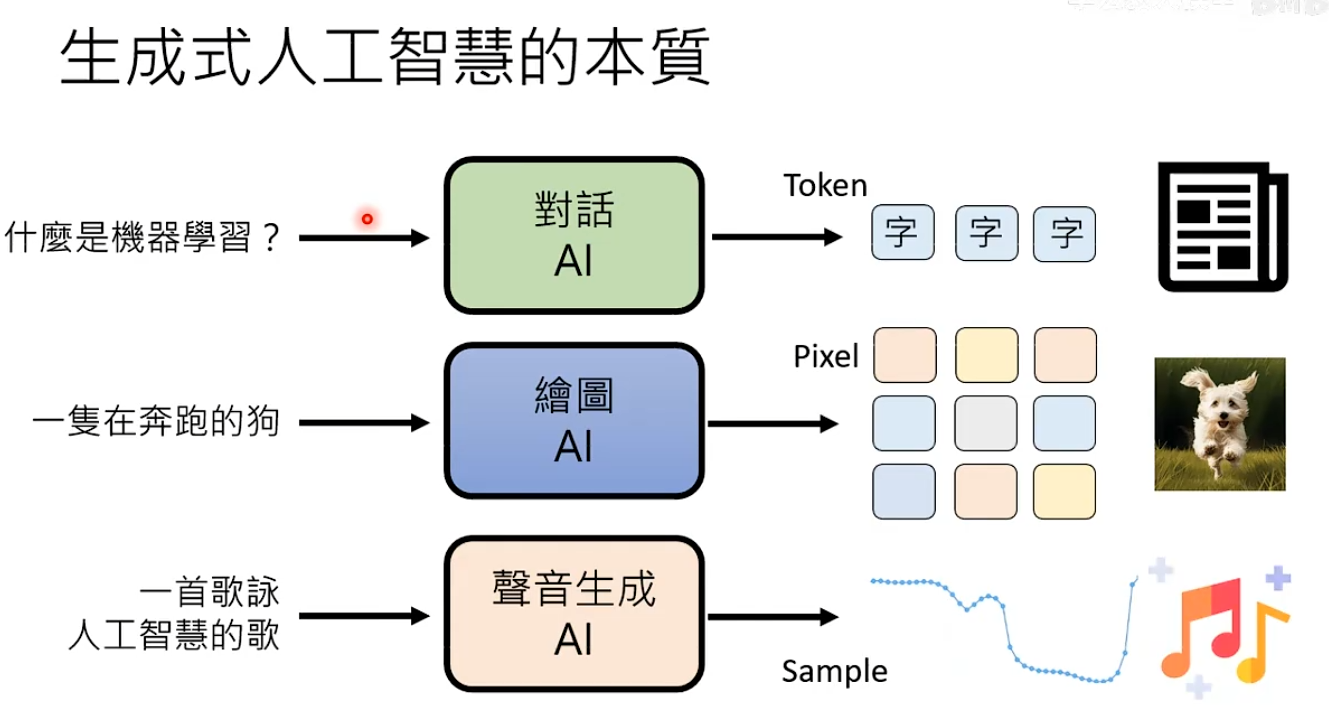
AR与NAR的总结
目前的做法是两种方法结合。
生成策略:Autoregressive Generation AR
文字接龙使用的生成策略是Autoregressive Generation,其实影像也可以进行像素接龙,声音也可以进行取样点接龙。但实际操作中,影像生成与语音生成不是采用接龙的方式。
Autoregressive Generation本质上的限制
每次产生一个基本单位时,只能按部就班生成
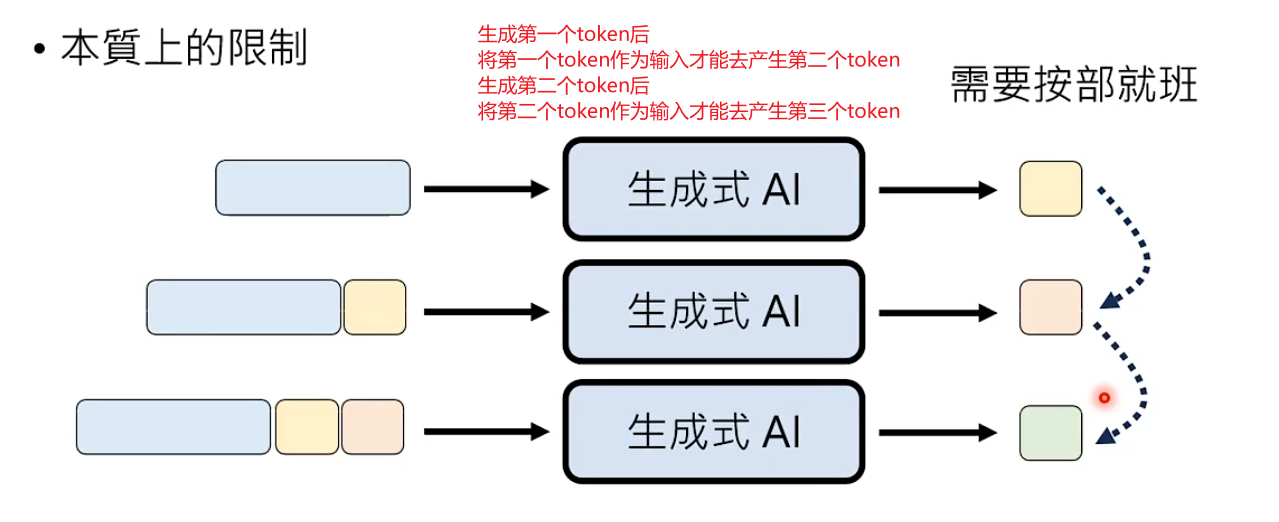
假设需要生成1024x1024解析度的图片,图片有100w个像素,那么需要做100w次像素接龙,生成成本和时间都太多了。生成语音采用这种策略也存在同样的问题。

生成策略:Non-autoregressive Generation NAR
NAR:不按部就班,一次同时生成所有基本单位,图像生成主流采用的方法。
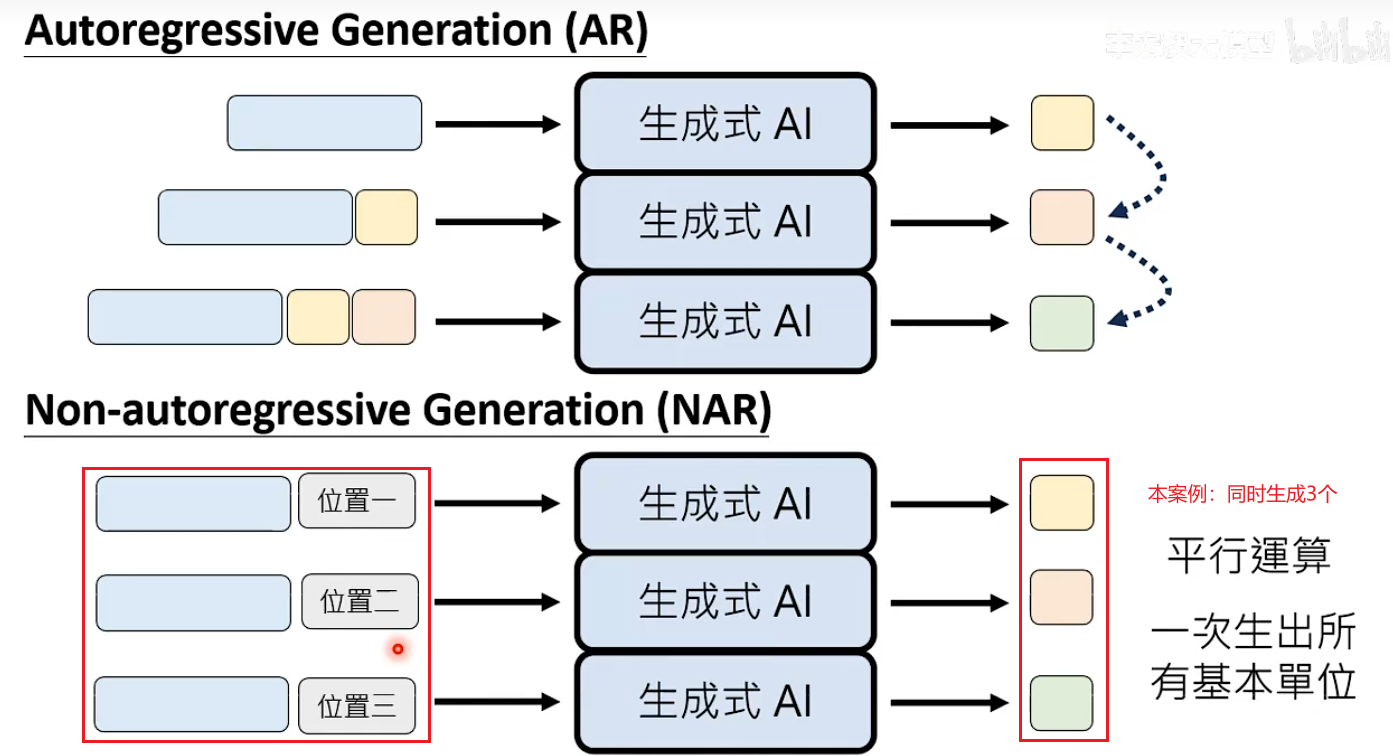
文字也可以用Non-autoregressive Generation的方式,思路是确定生成的基本单位数量。
方式1:给一个输入,让语言模型预测要自己回答的答案token数量。 - 影响生成的大小是固定的,所以就不需要实现预测。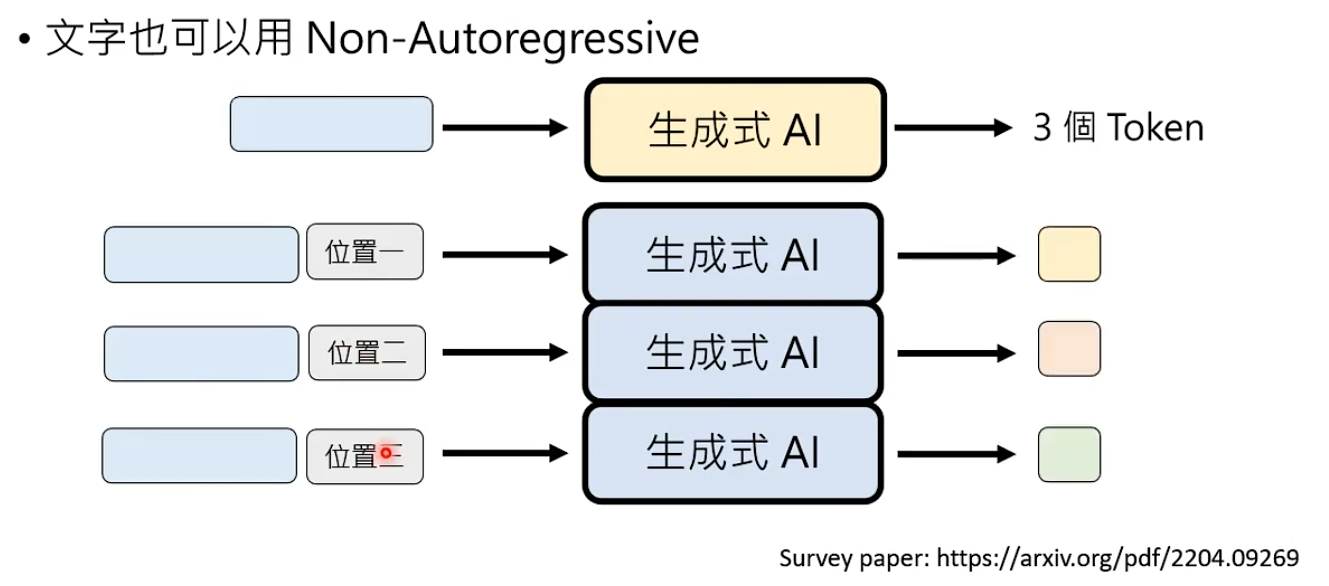
方式2:生成固定长度的答案,如果出现END这个token,那之后的答案丢掉就可以了。
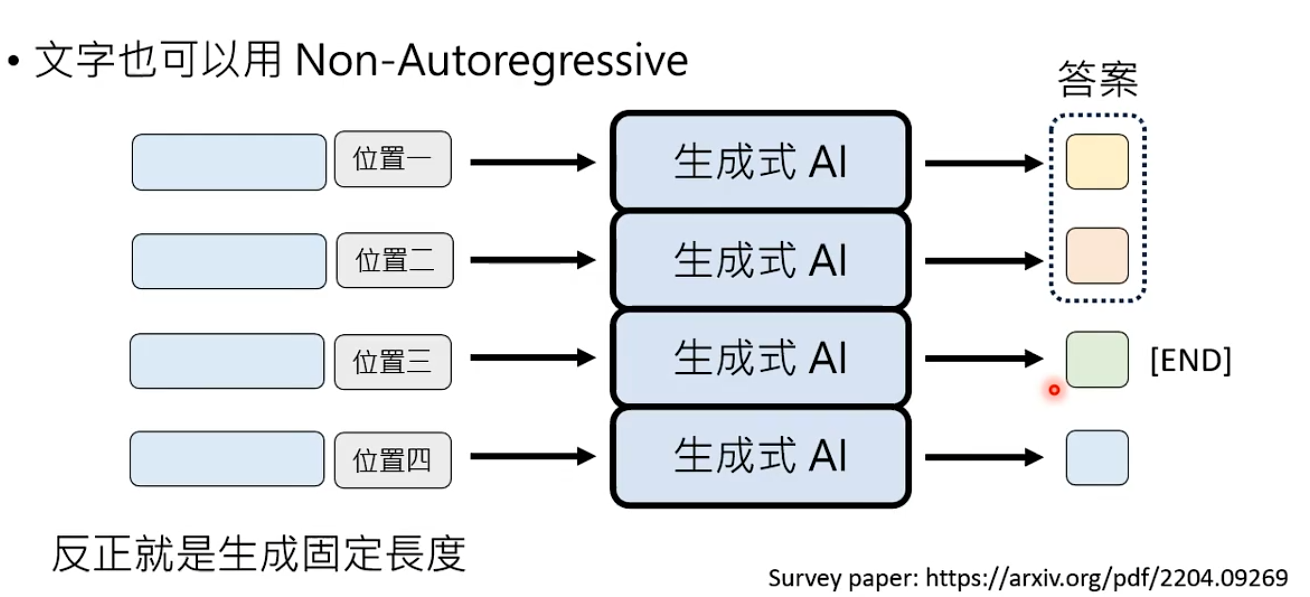
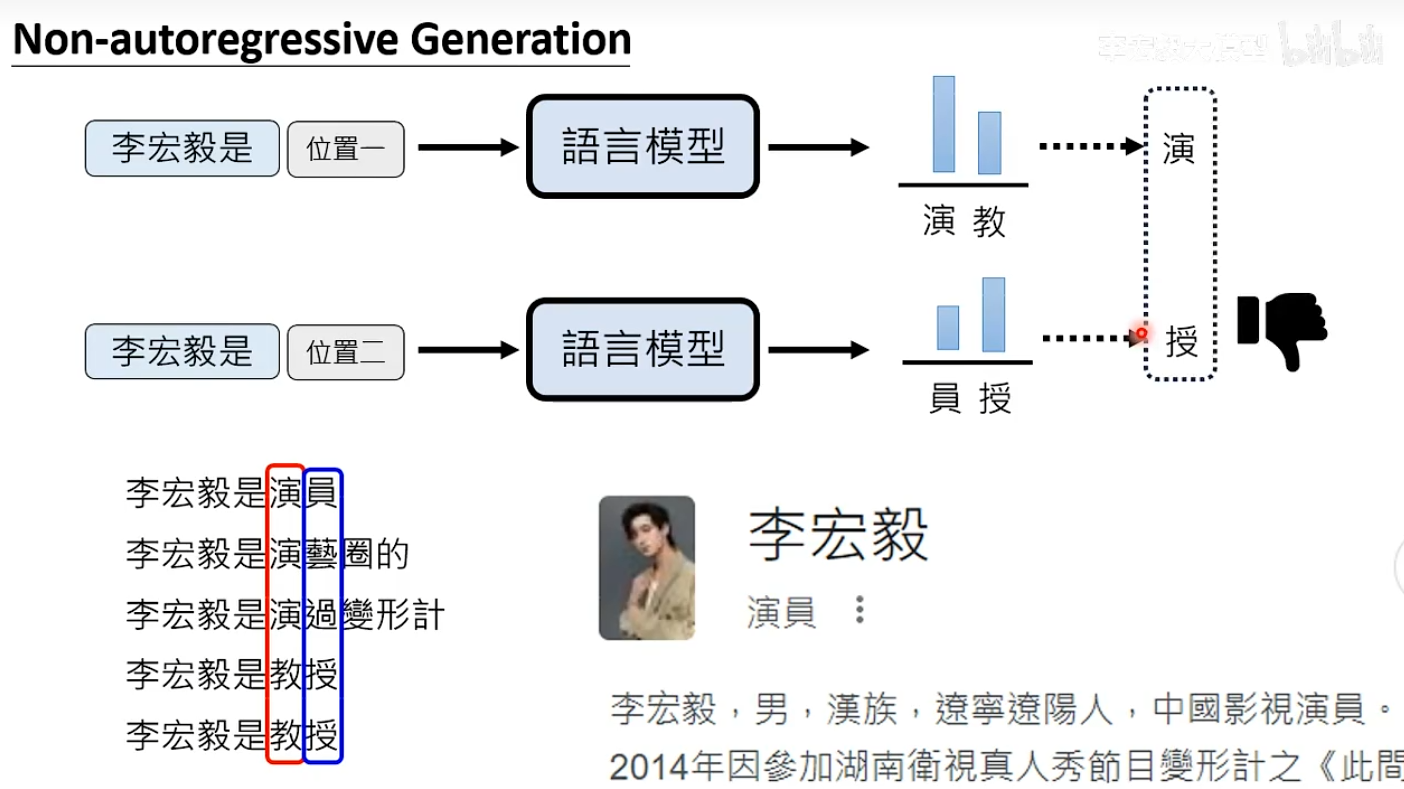
Non-Autoregressive Generation的质量存在问题
生成式AI往往需要自行脑补,给定同样的条件也会有很多可能的输出。
假设生成一个图片,每个位置的生成是独立,当生成不同位置时模型的生成思路可能是不一样。
虽然是同一个模型去生成,可能生成差不多的东西,但不能保证独立生成时想的是一模一样的。这就是早期使用NAG生成图片时,图片质量很差的原因。
这个问题被称为multi-modality problem。
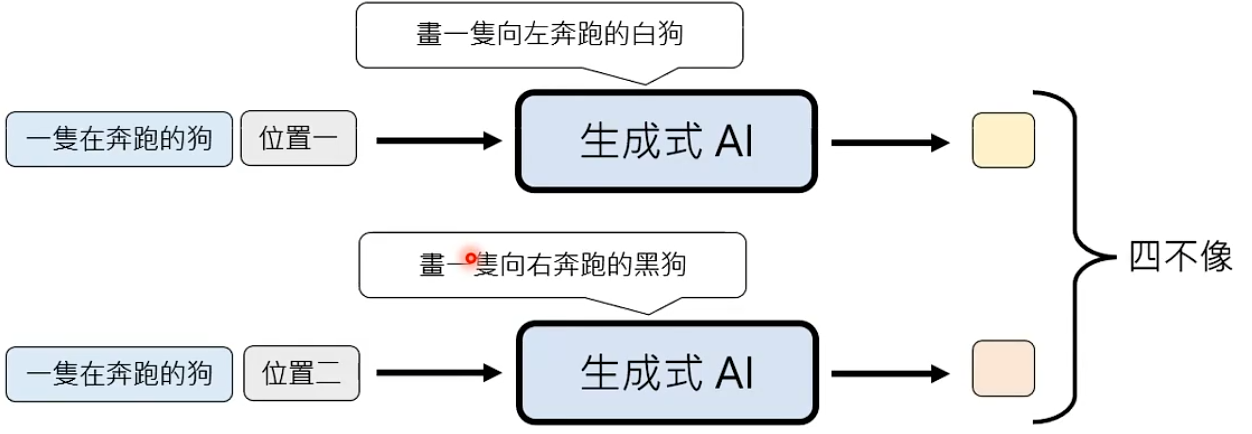
问题:虽然NAG存在multi-modality problem问题,但是不得不用其生成图片和语音。所以需要通过其他办法,解决这个问题。
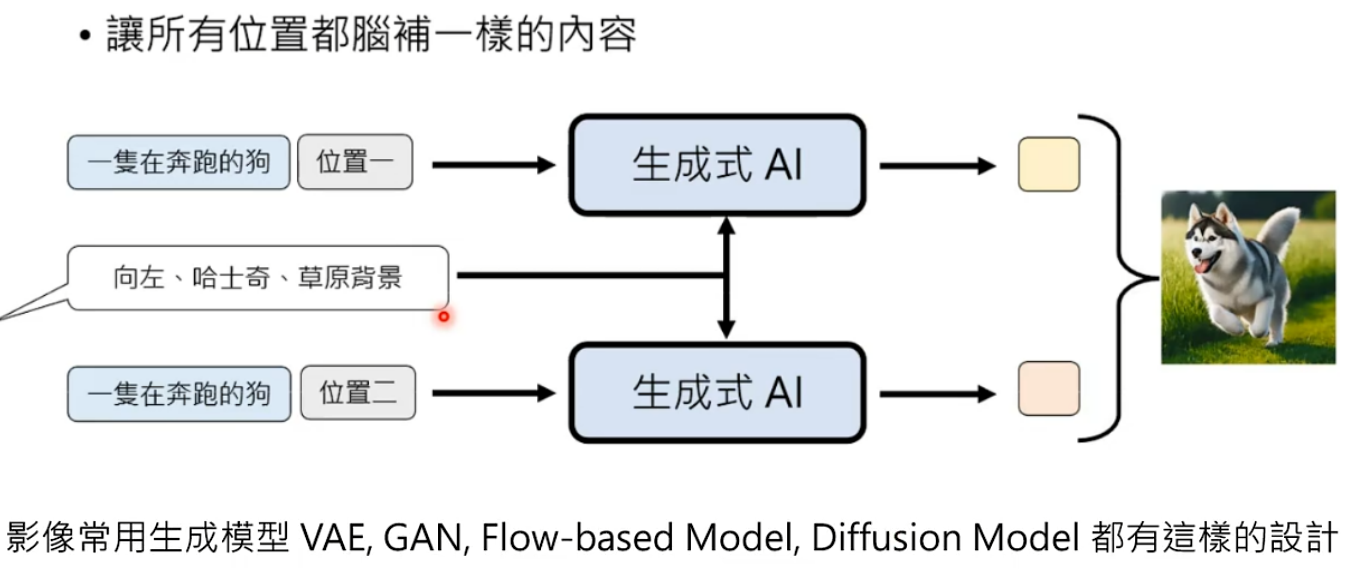
解决办法1:确定好需要脑补的东西,让所有位置都脑补一样的东西。将其作为prompt输入。
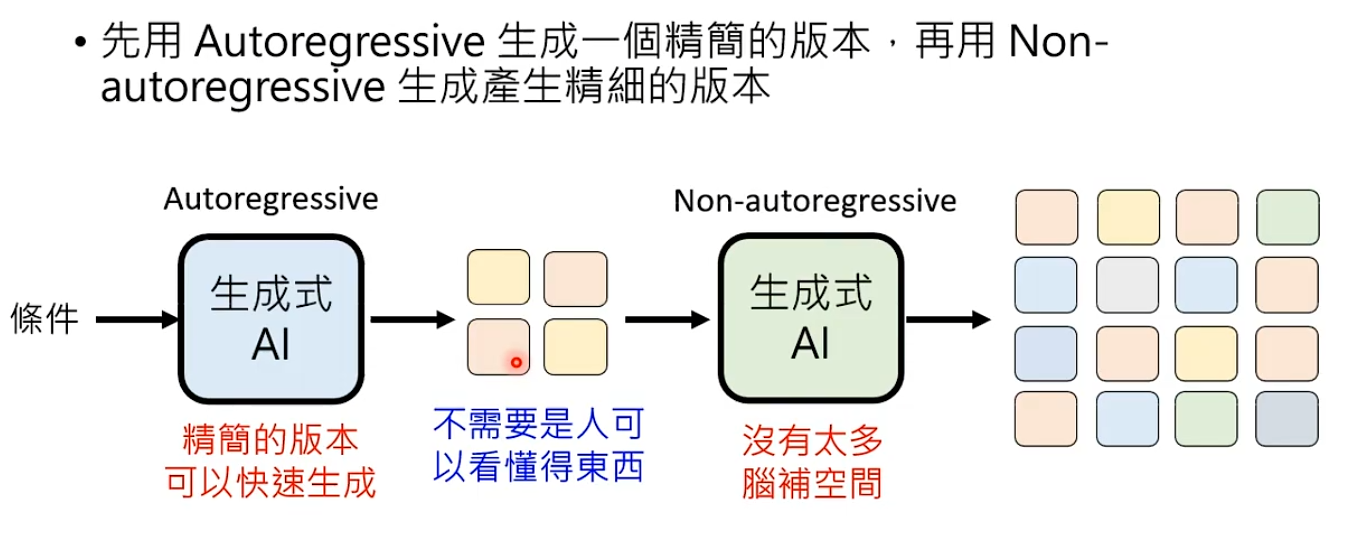
解决办法2:AR + NAR,先用Autoregressive生成一个精简版本(定大框架),再根据精简版本用NAR生成精细版本
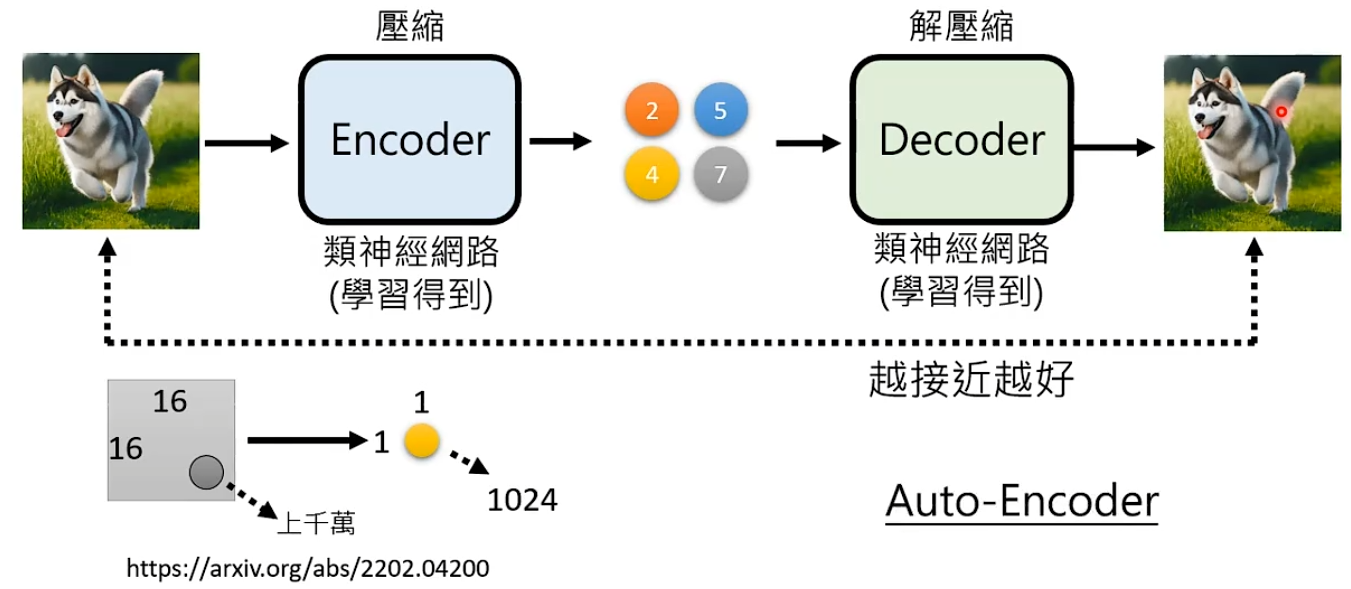
比如有一个方法叫Auto-Encoder,压缩图片之后产生压缩结果,将压缩结果解压缩可以还原图片。那么对于Autoregressive只用去学习怎么产生压缩结果。
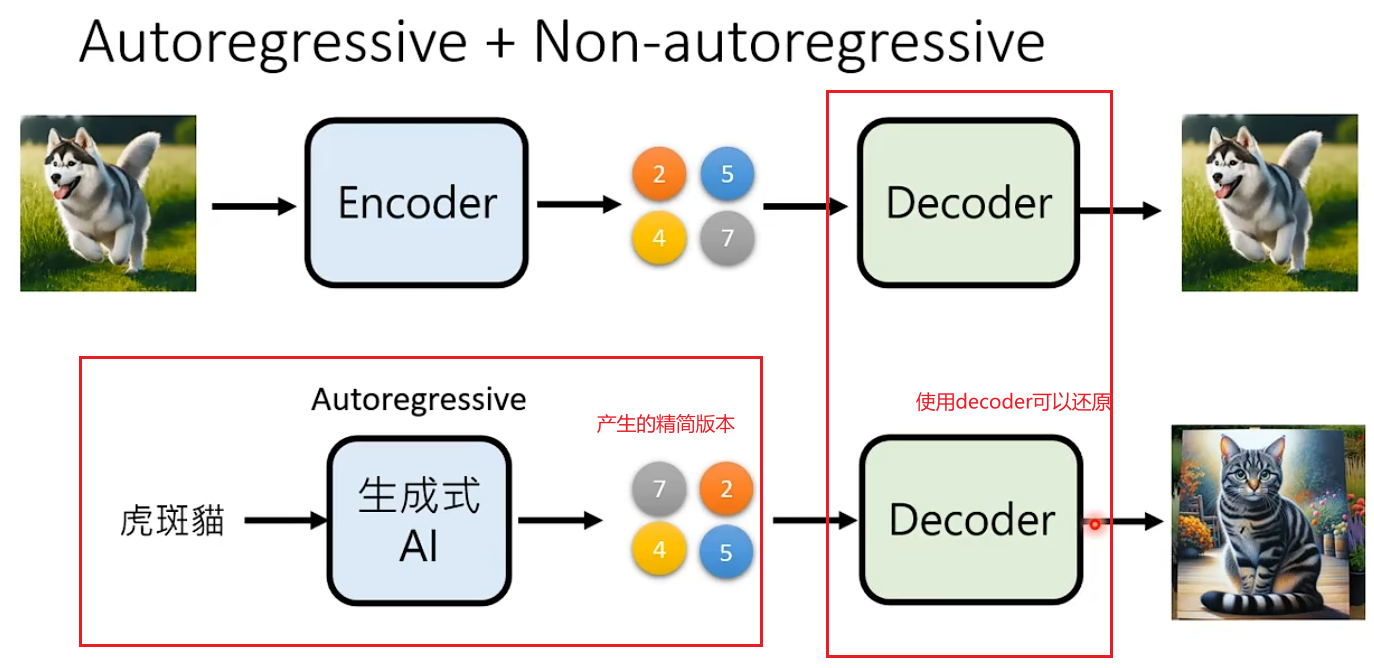
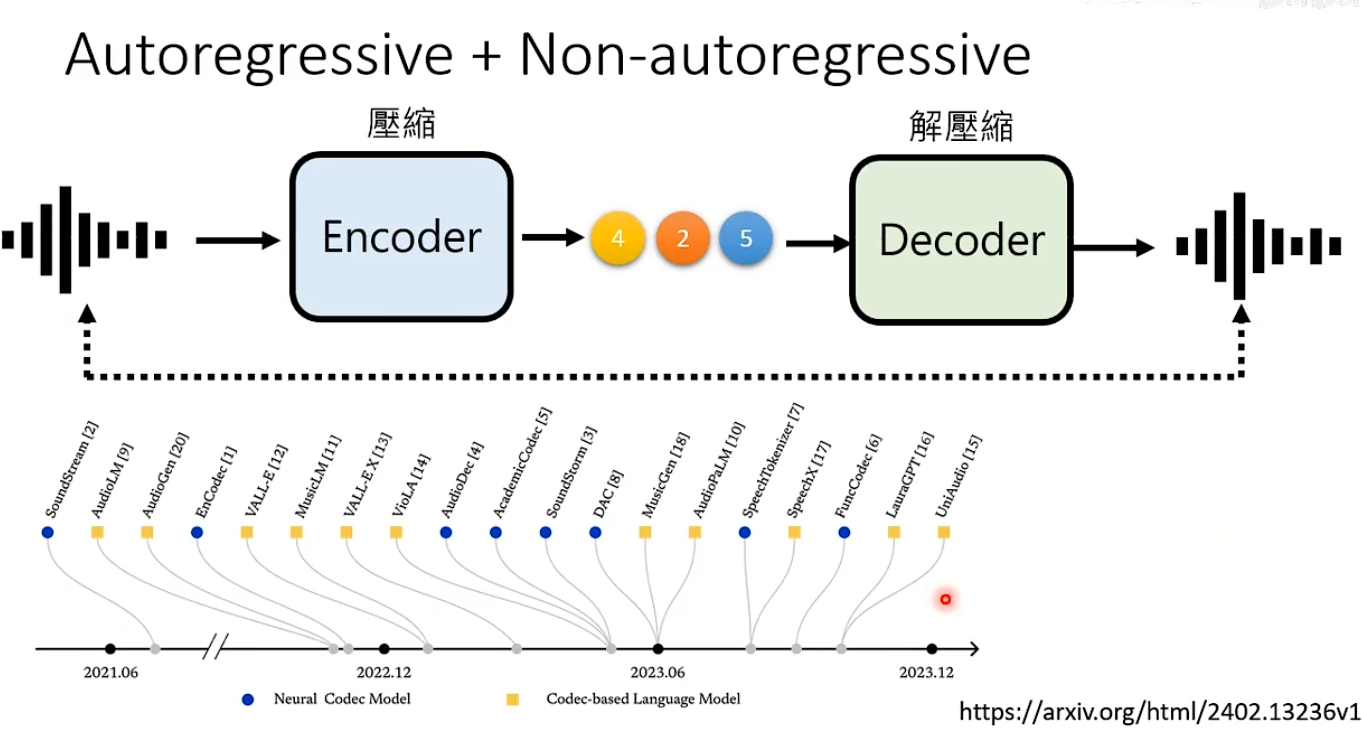
语音也可以采用同样的思路Autoregressive+Non-autoregressive
实际操作中,会采用多个NAR代替Autoregressive。
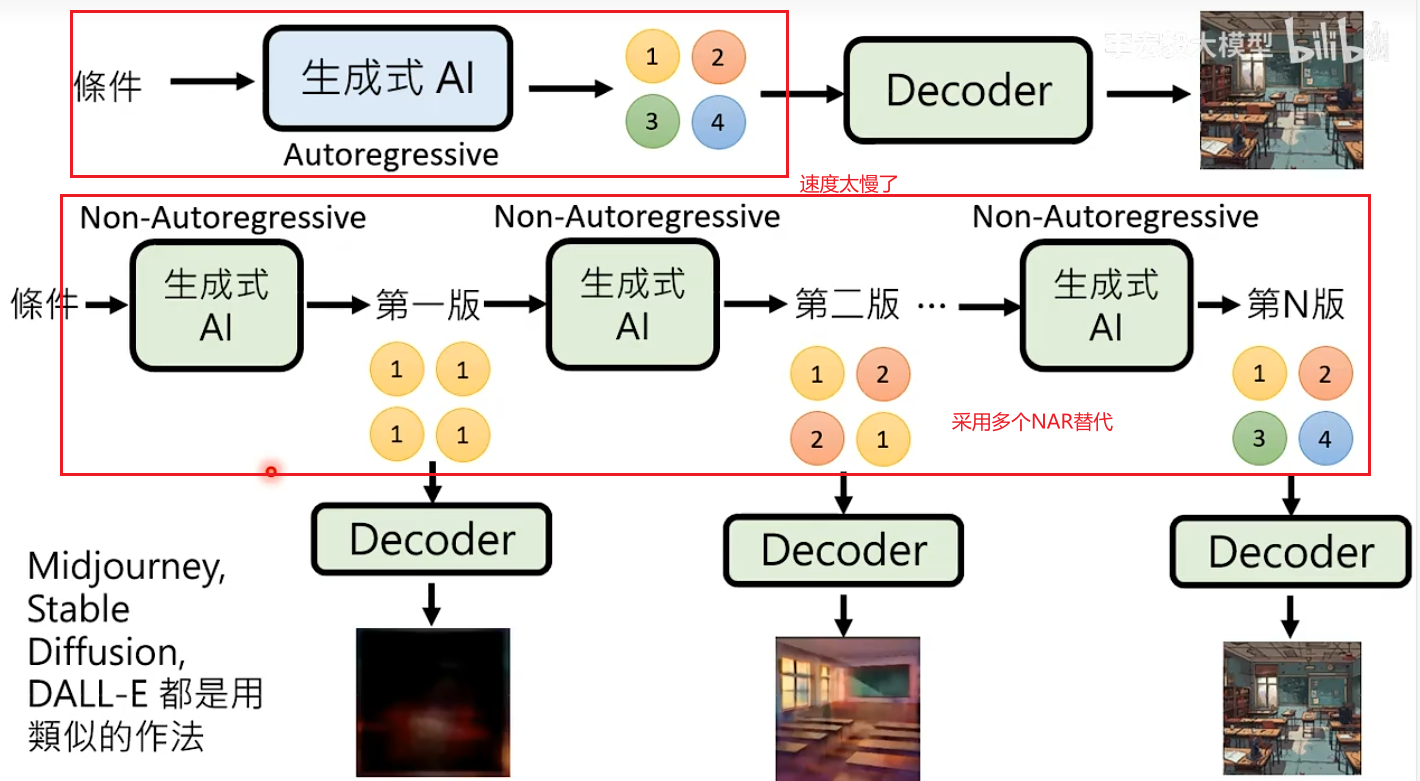
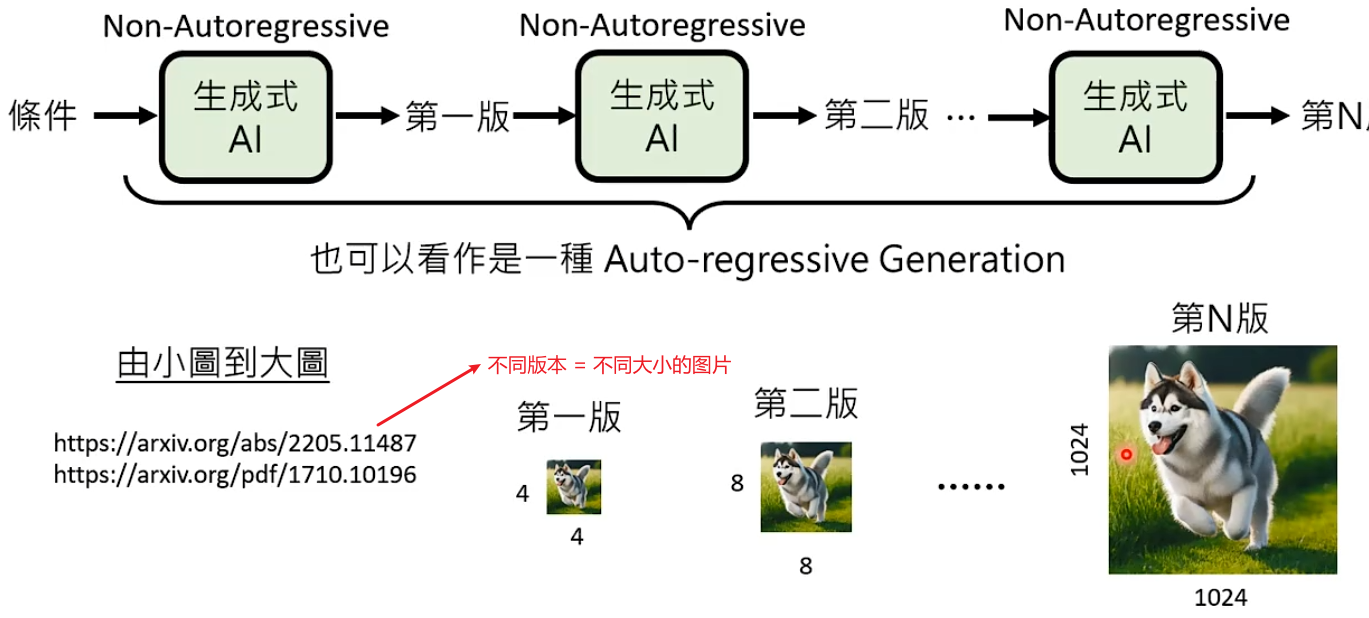
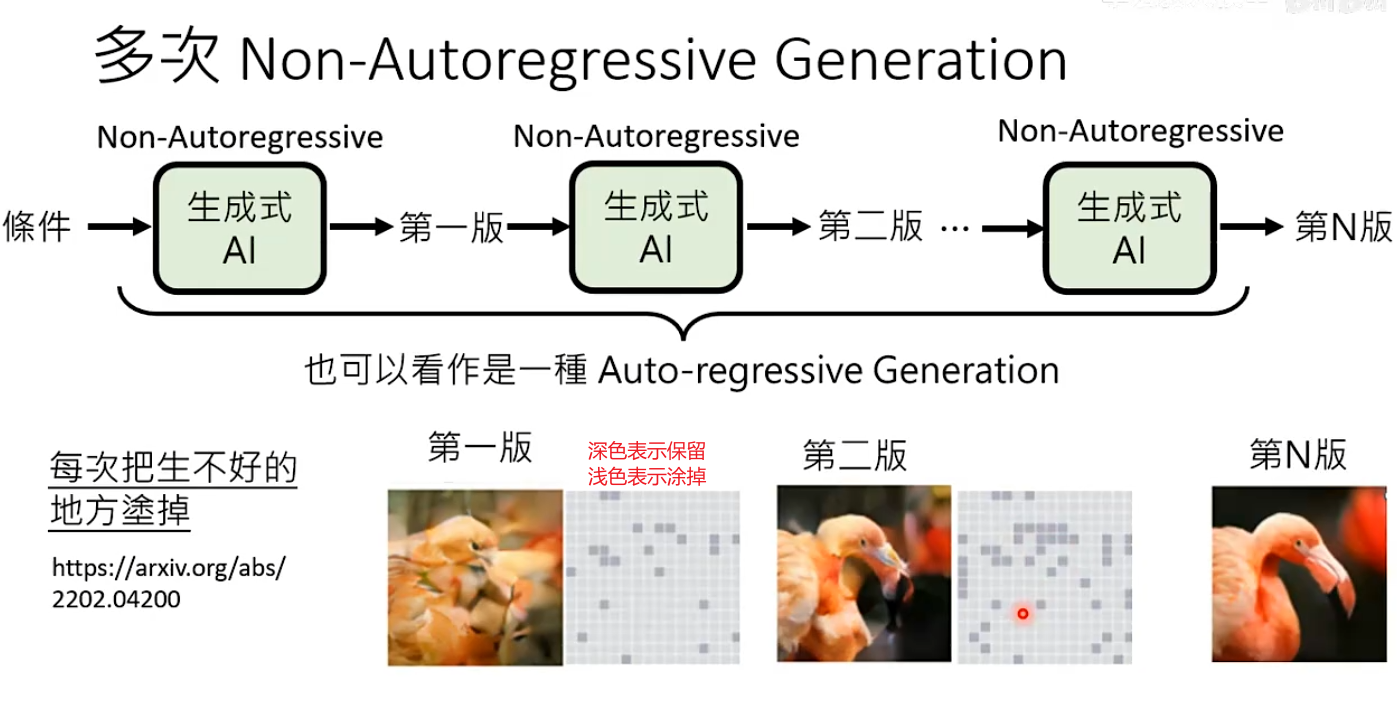
解决办法3:多次Non-Autoregressive Generation。把整个生成步骤拆分为N个阶段,每个阶段都使用NAR生成。
可以加速所有语言模型生成速度的神奇外挂:Speculativ
模型+Speculative Decoding 可以加快任何语言模型的生成速度

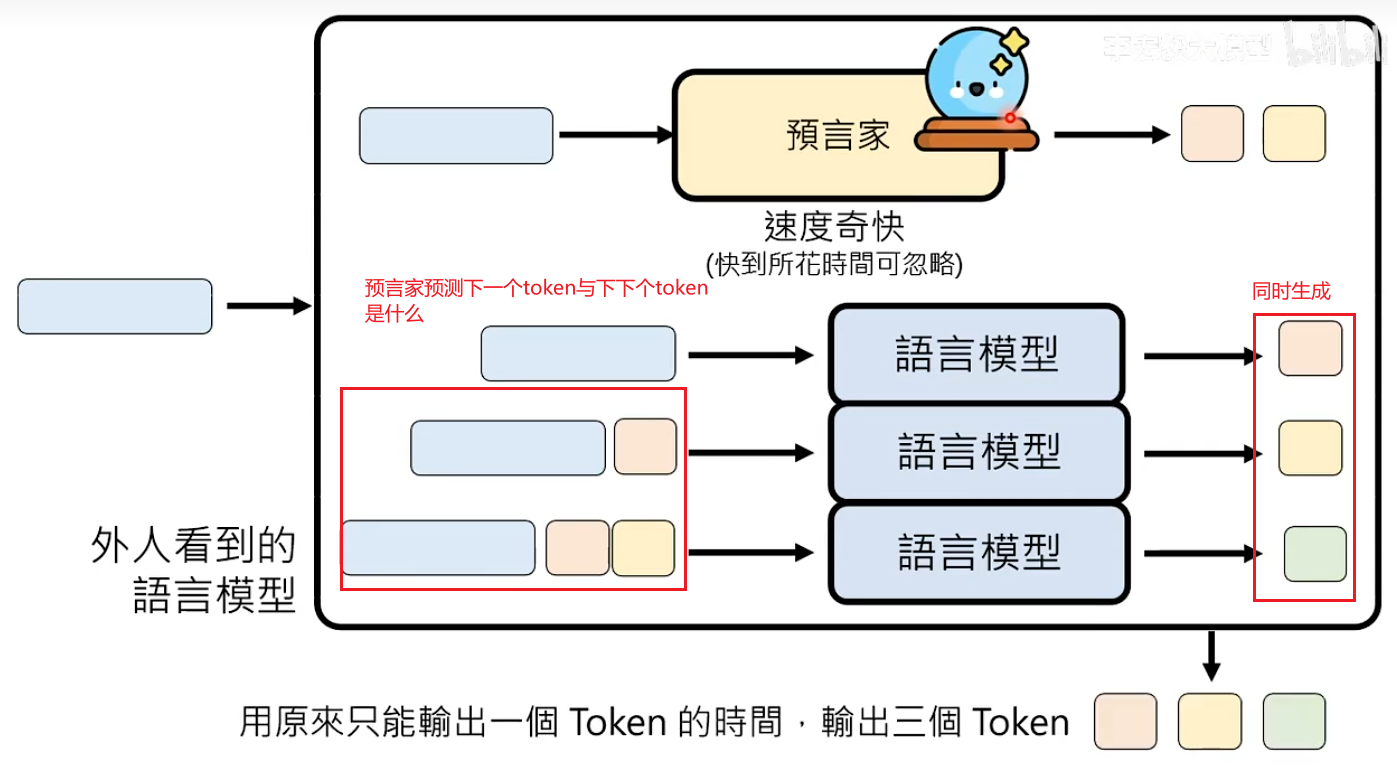
如果预言家可以准确接下来要生成的内容,那为什么不直接让预言家生成所有的token?预言家可能会犯错。
问题:如何知道预言家在哪里出错了?也就是如何发现哪一个输出的token是不可信的?
解决办法:对比 语言模型的真正输出与预言家预测
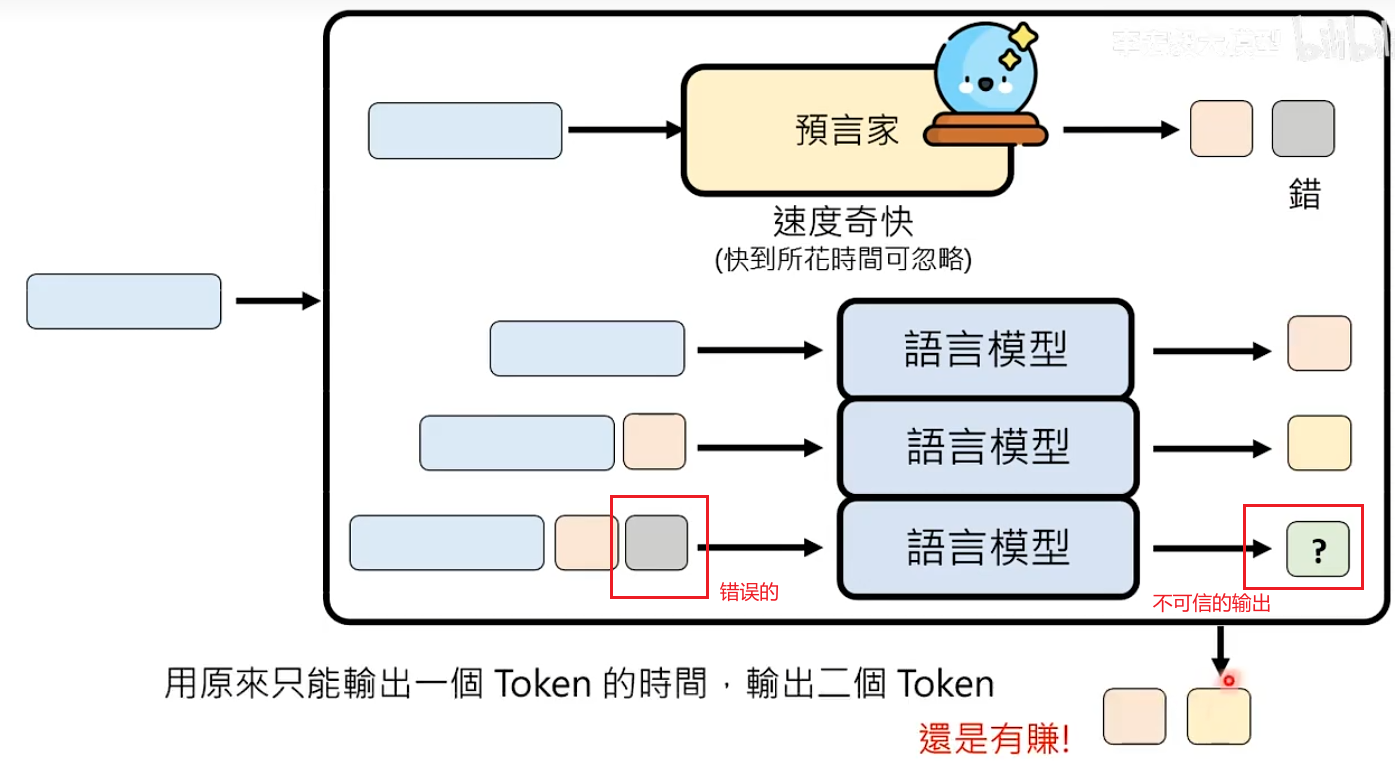
那如果预言家从第一个token就开始出错了,模型只是回到了最初的样子。虽然浪费了运算资源,但使用整个方法的本质就是通过空间换取生成时间的加速,所以假设预言家速度特别快,那么也没有浪费什么时间。
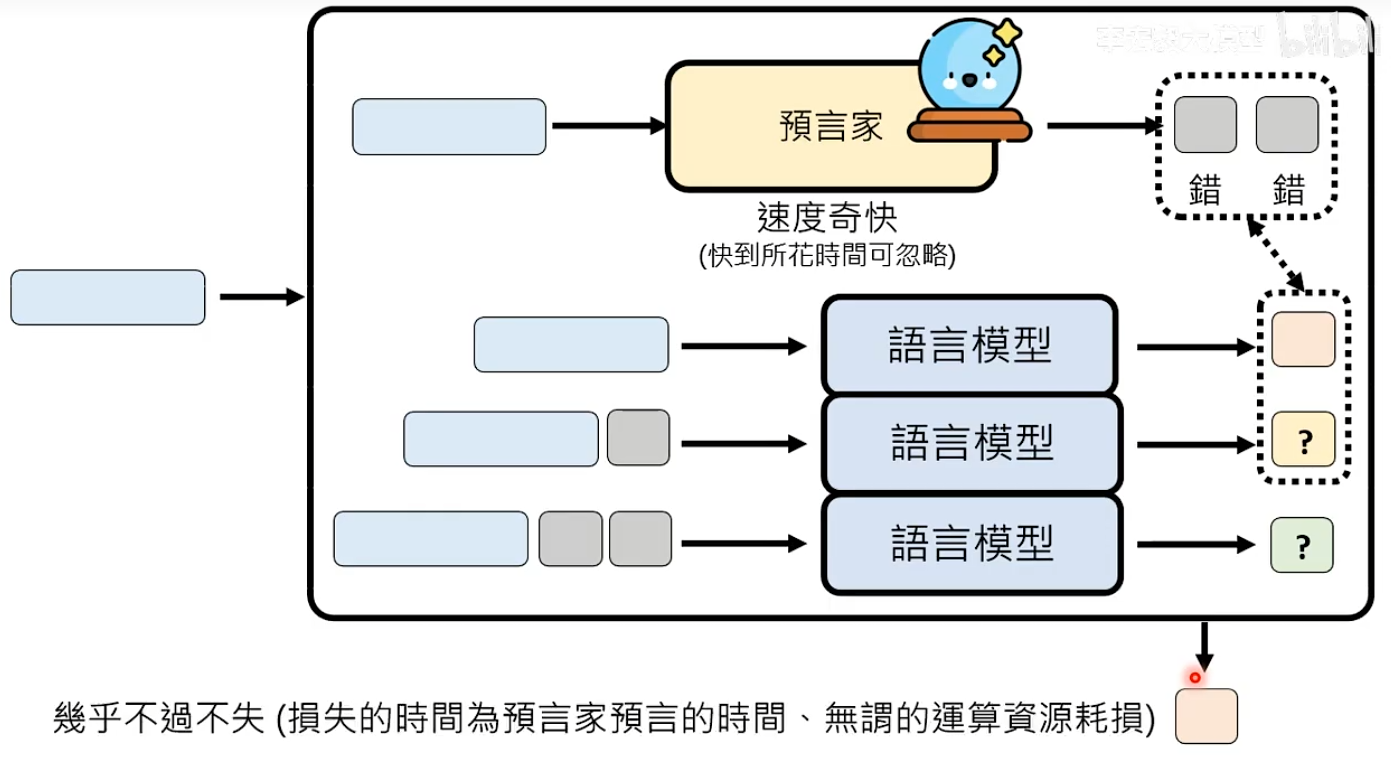
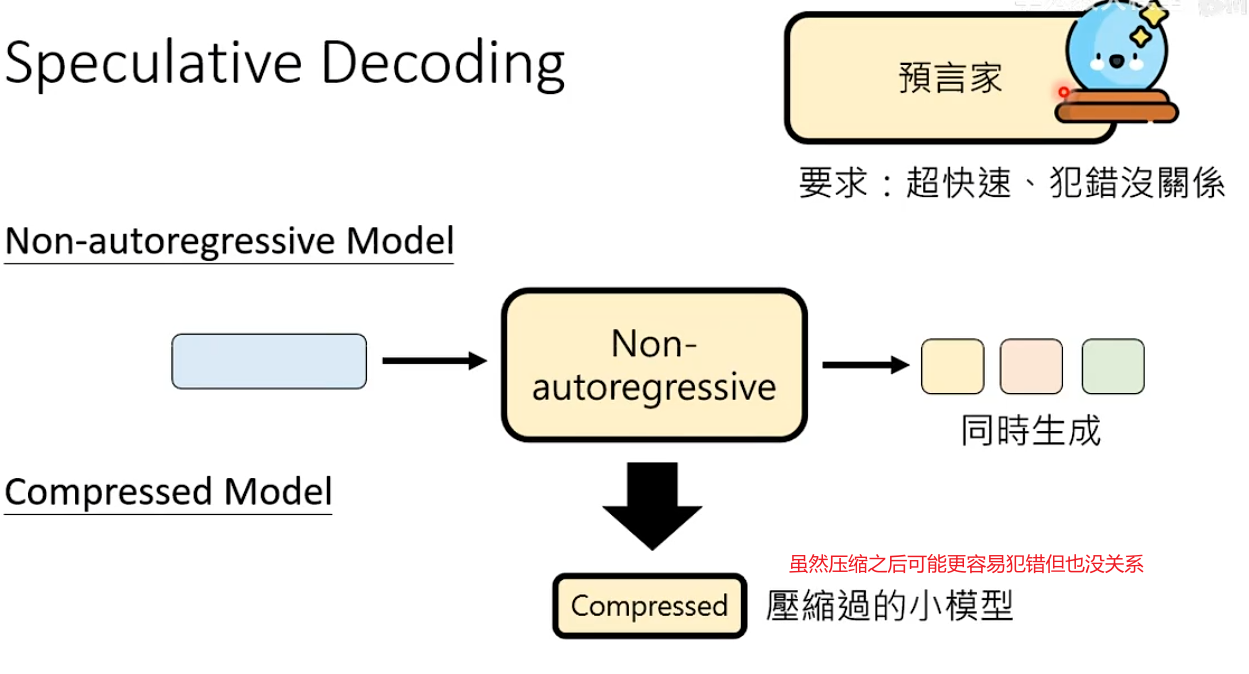
在Speculative Decoding中,Non-autoregressive Model可以担任预言家,将Non-autoregressive Model压缩过的小模型也可以做预言家。
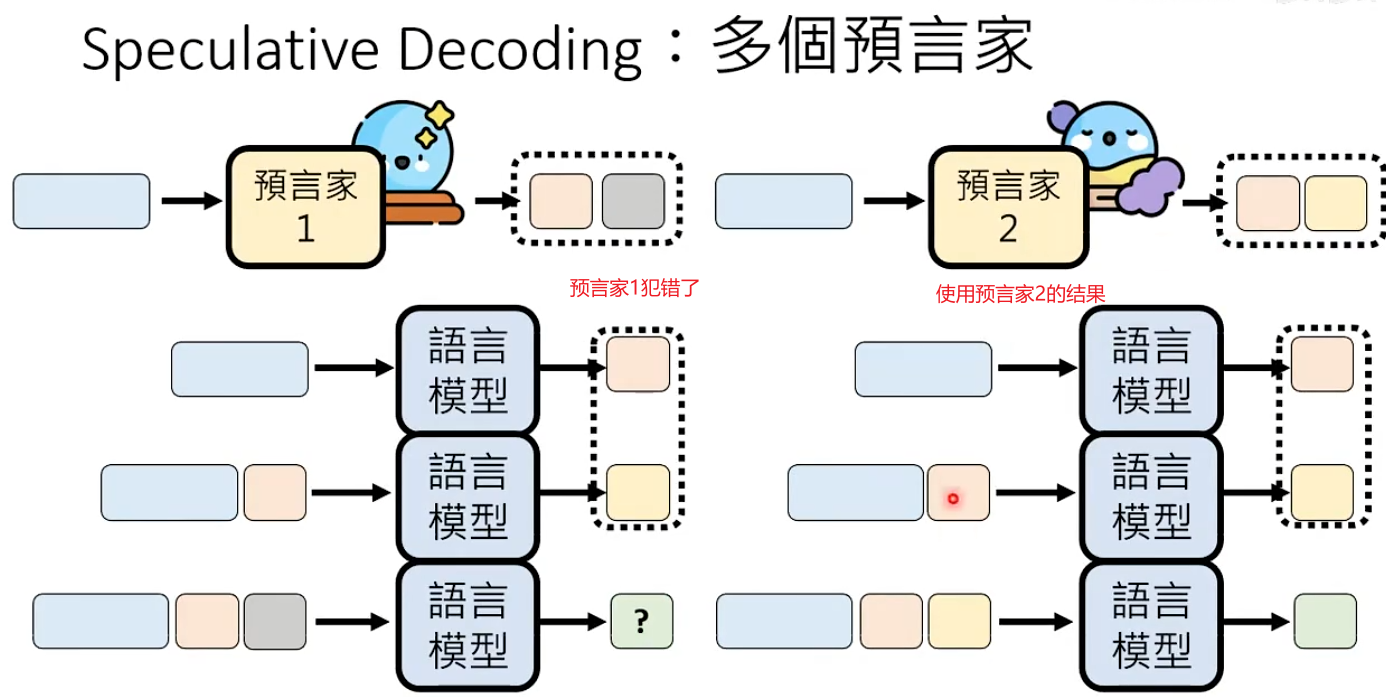
在Speculative Decoding中可以有多个预言家
影像有关的生成式AI
影像有关生成式AI的应用
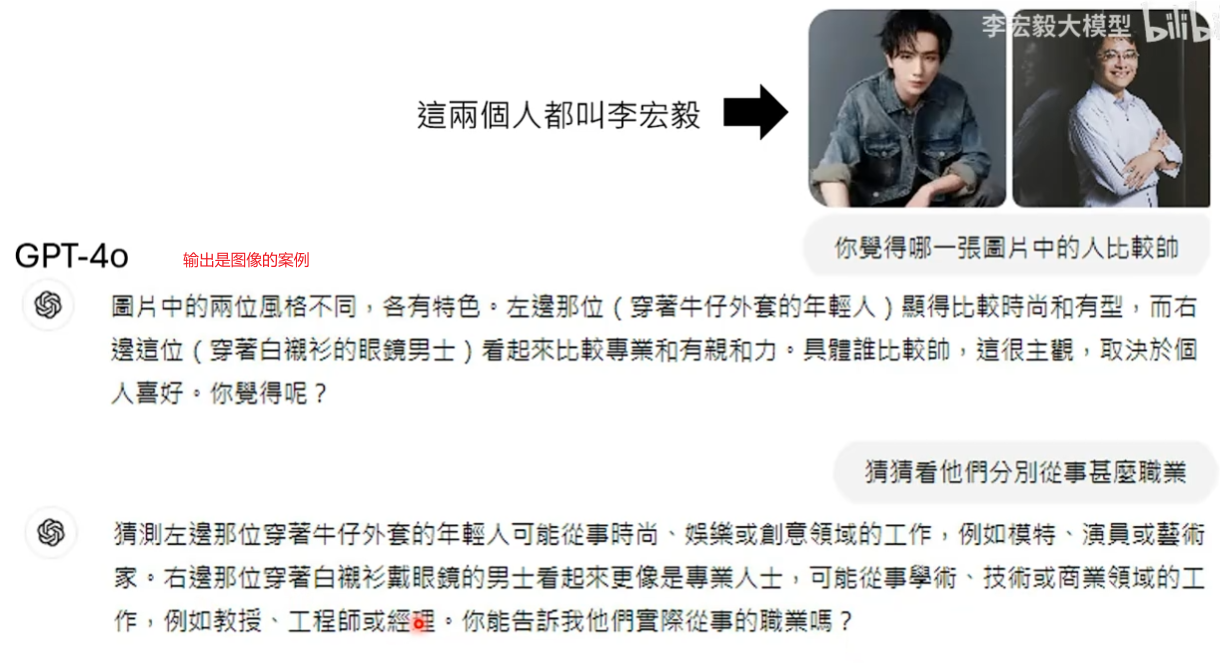
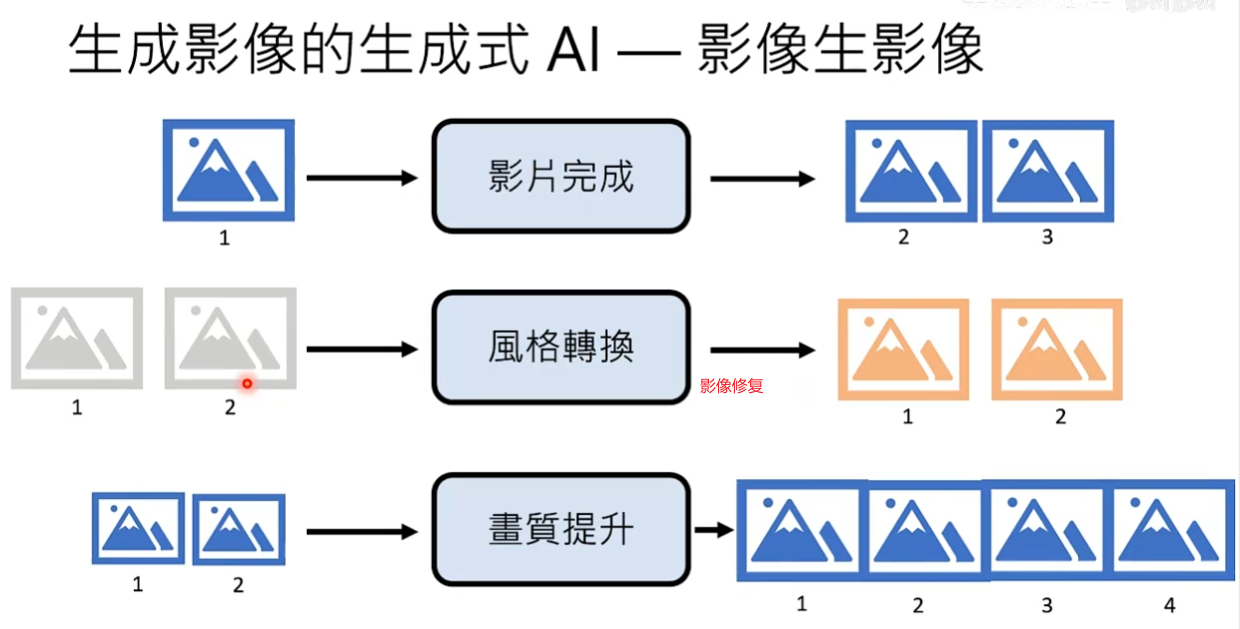
音频说的是生成式AI导论,最后生成式AI输出的是一个动图,动图里面这个人在说’生成式AI导论’ 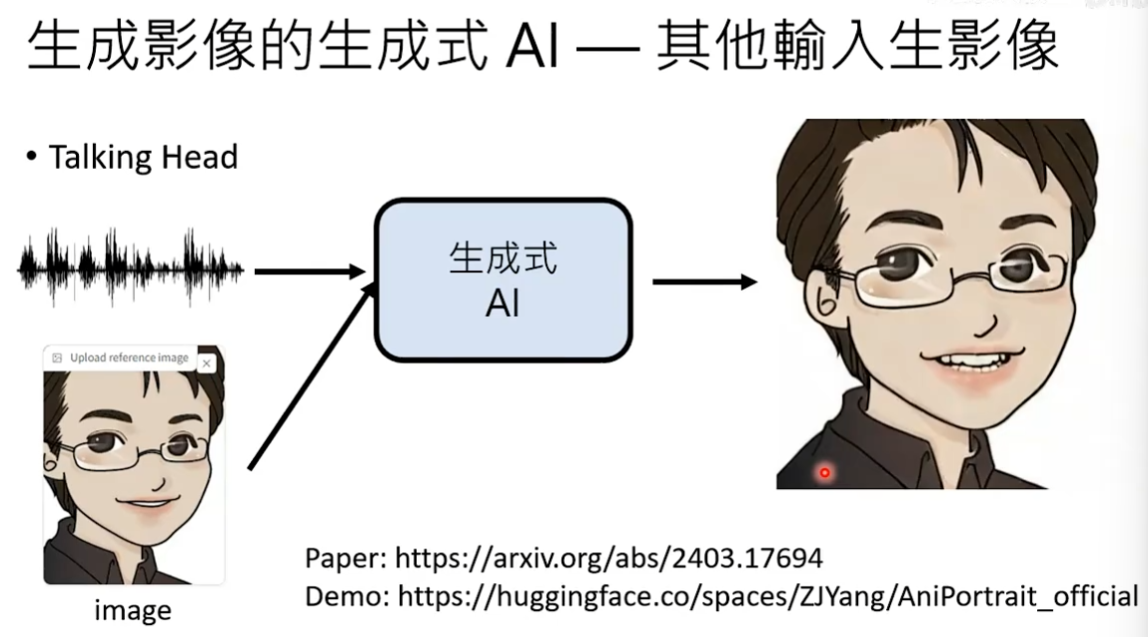
AI怎么产生的图片和影像
图片是由像素组成,像素点越多图片越清晰。影片是由一串图片组成,其中每一个图片称为frame帧,FPS Frame per second 表示每秒的帧数。
AI产生图片
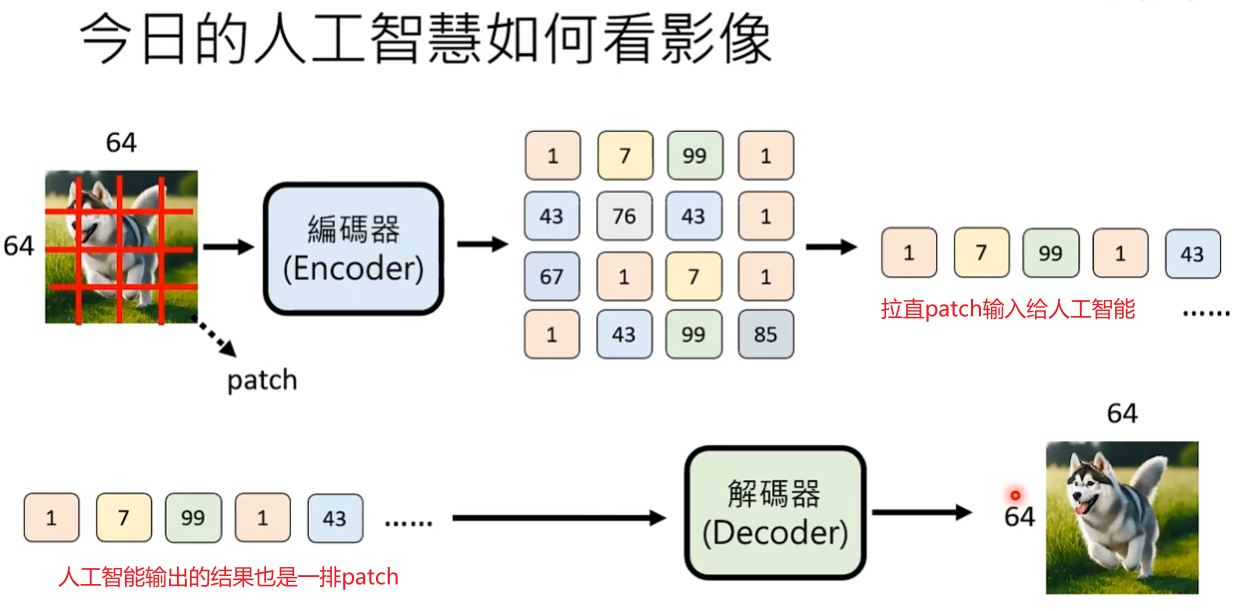
输入的图片通常生成式AI会先使用一个编码器Encoder将图片进行切割成patch,比如将6464的图片切成16个44的图片。每一个patch会进行压缩,压缩的结果(比原来更简单的表示)取决于使用的Encoder。有一种Encoder是将每一个patch用一个独特的符号表示,也有Encoder将每一个patch表示为低维度的向量。
人工智能输出结果也是产生一排的patch,通过Decoder解码器输出图片。
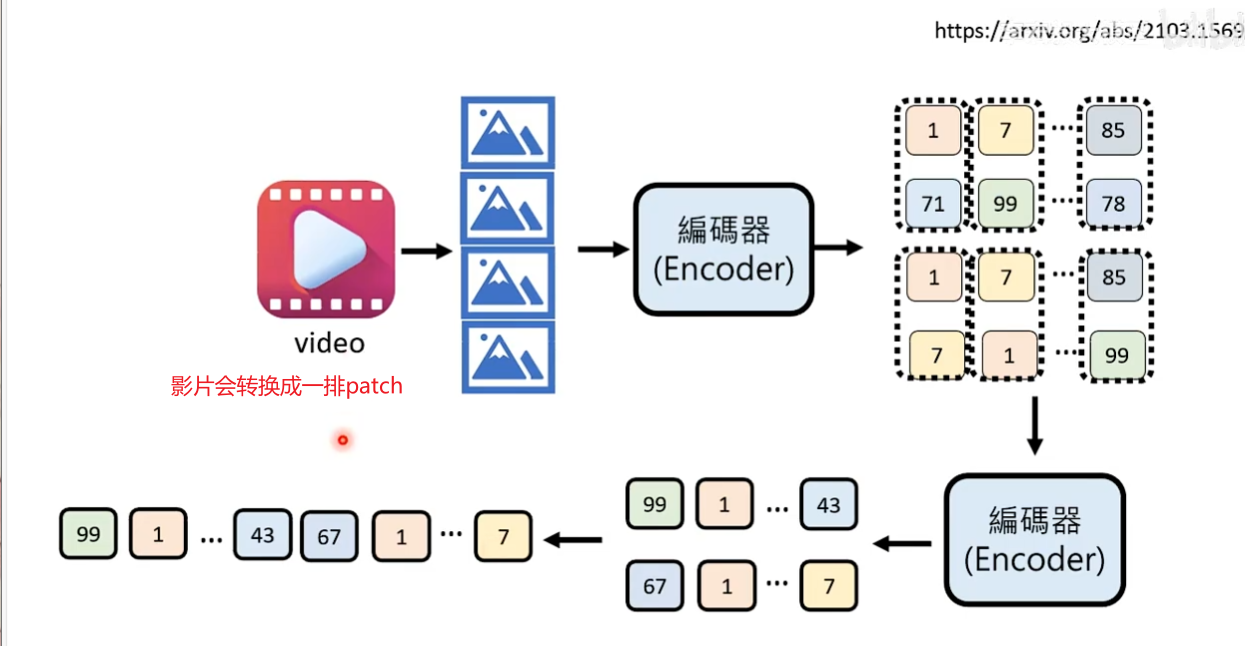
AI产生影片
影片是由一堆图片构成,影片里面的每一个图片都可以转换为一排patch。影片有时间维度,所以也可以在时间维度进行压缩(比如相邻的帧合并到一起做压缩)。影片会被转换成一排patch然后扔到人工智能。
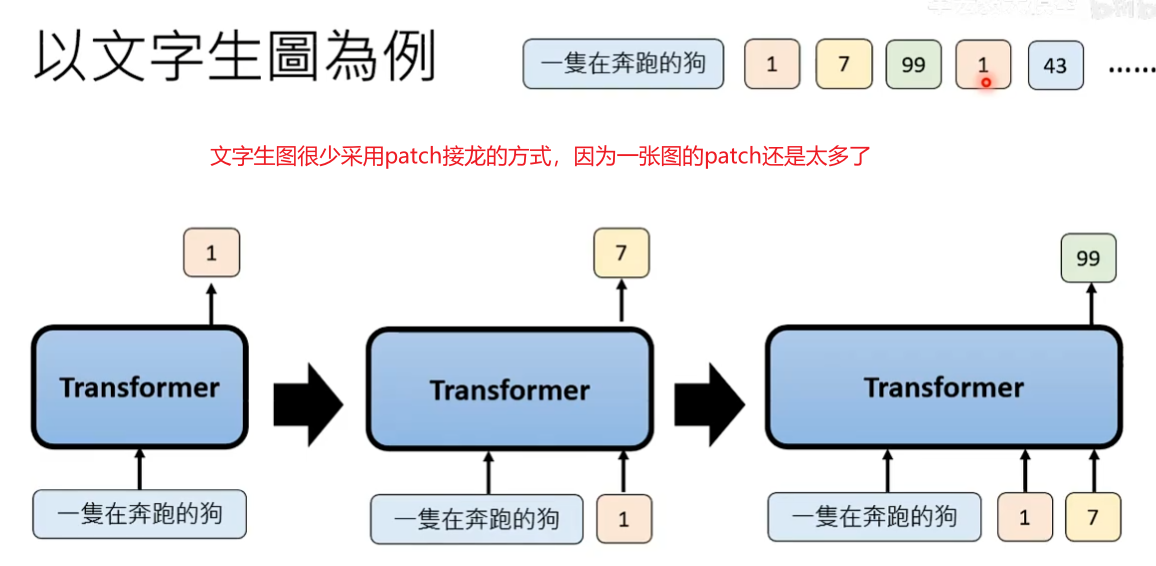
案例:以文字生图为例,讲解模型怎么被训练出来
训练资料:文字叙述+图片
开源数据集:LAION10
文字生图很少采用patch接龙的方式(Autoregressive的生成策略)
通常采用non-Autoregressive的生成策略,所有的patch同时生成
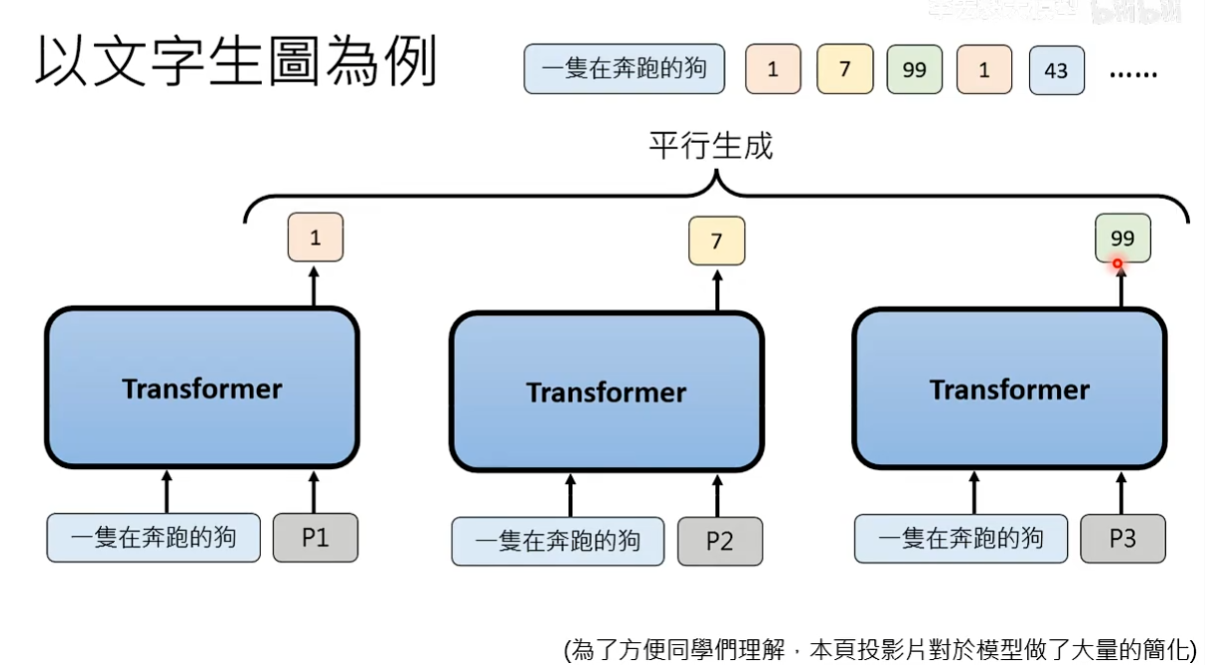
实际做法,比如要生成16个patch,会先告诉Transformer要生成patch1-patch16,Transformer同时生成16个patch。在生成某一个patch的时候,Transformer里的Attention回去参考其他patch生成的过程,patch之间有一定的关联性,但还是不能解决不同脑补的问题。
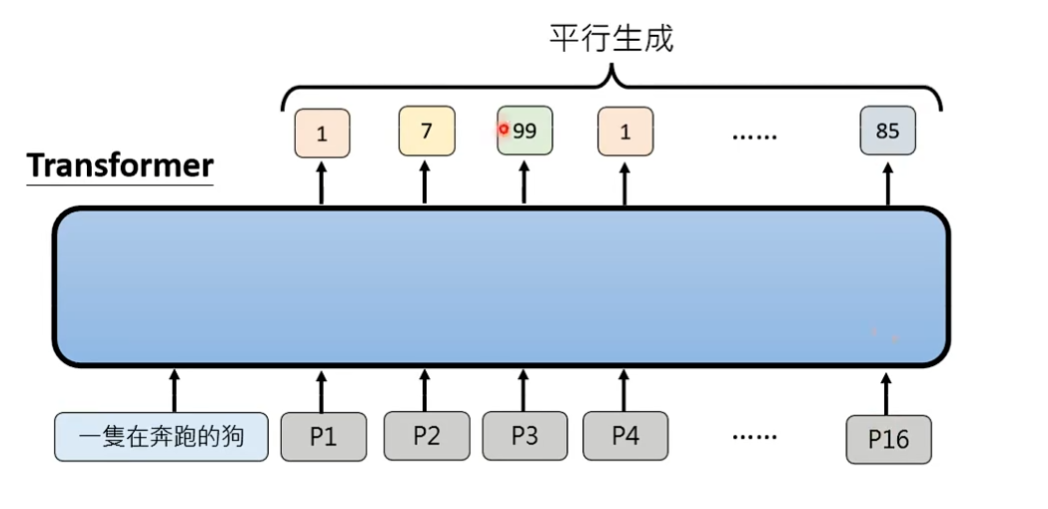
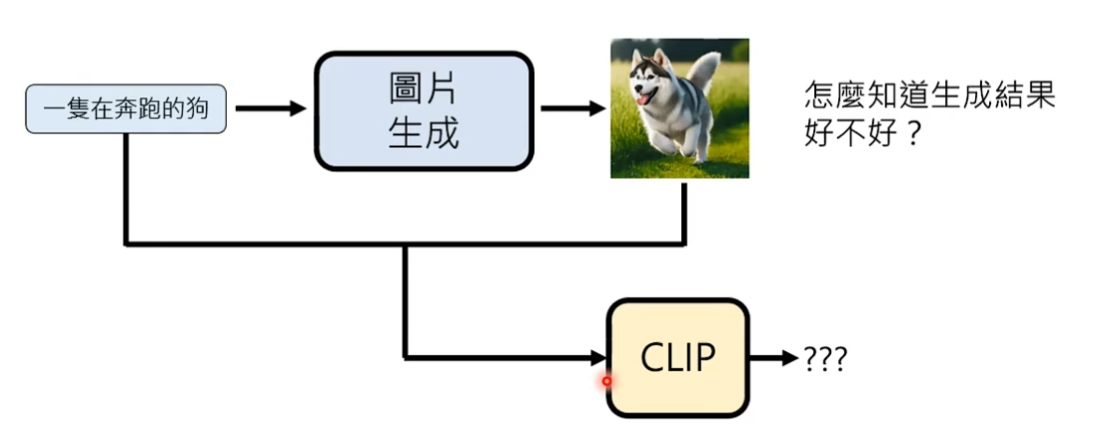
如何衡量影像生成的好坏
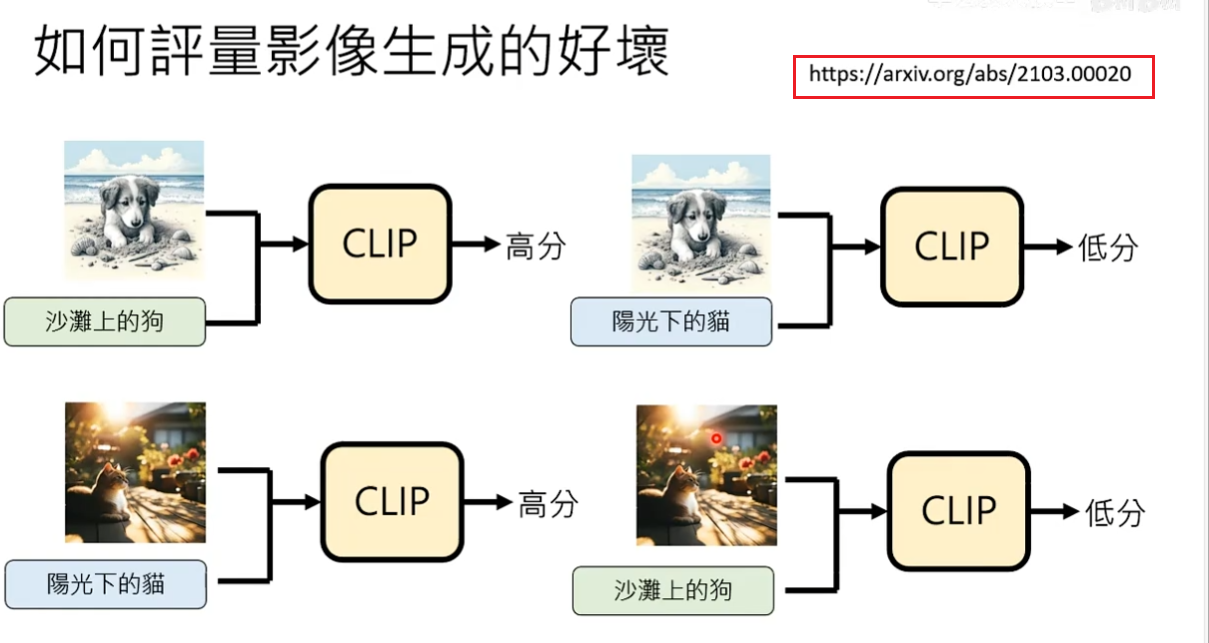
常见做法使用clip模型来评估生成结果的分数:在网络上有人收集了大量的图片及其描述文字,clip应该输出高分。如果将资料集中文字和描述文字错位配对,那么clip应该输出低分。
个人化的图像生成
图像生成式Al的难点:图片包含的超级多信息,很难一段话进行描述

假设有一个很特别的雕塑(需要客制化的对象),帮他取一个特别的名字(不要使用常用词汇,可能造成污染)。然后叫你的文字生图模型,以后讲S*你就要画出下面的图,微调文字生成模型就会认识这个客制化对象。
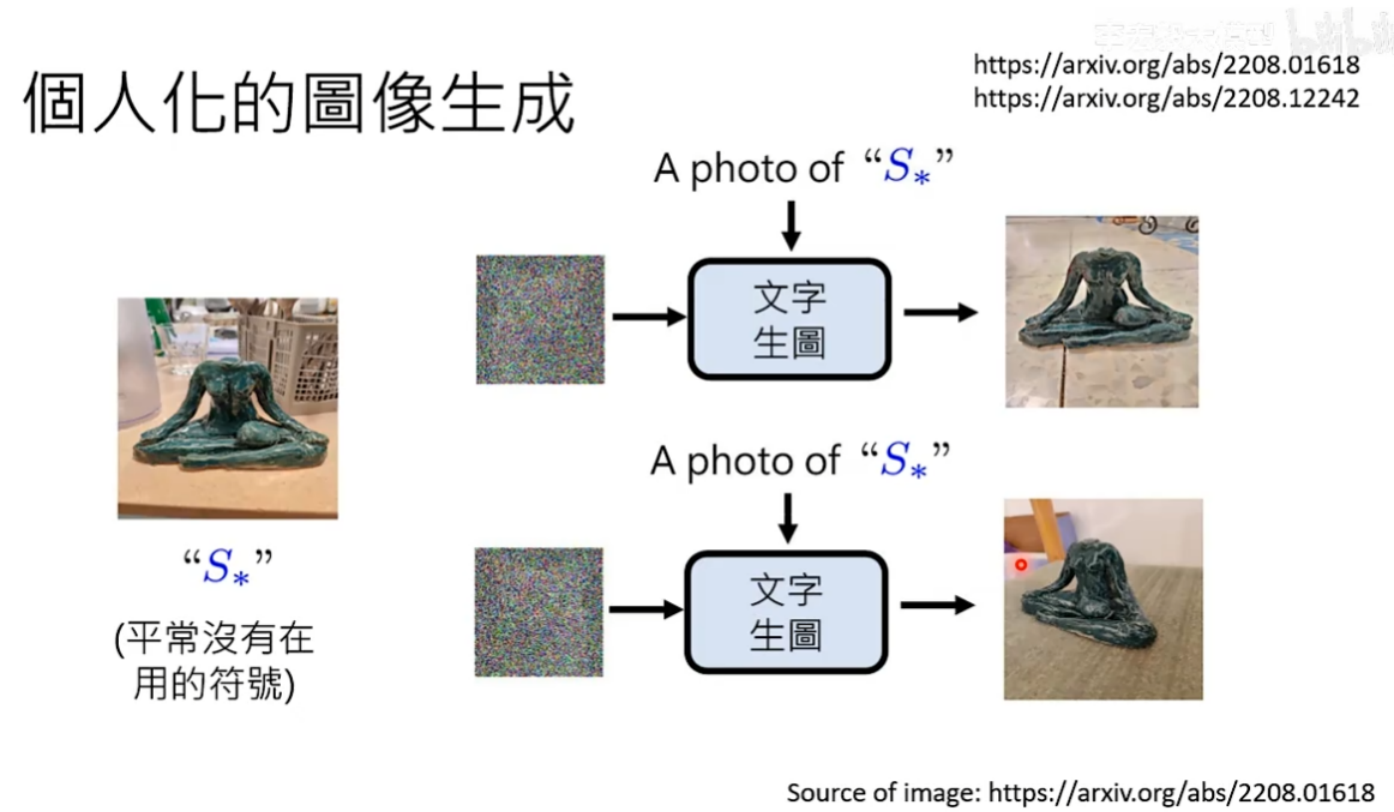
客制化的过程不需要太多图片,下面这篇论文只使用了4张图

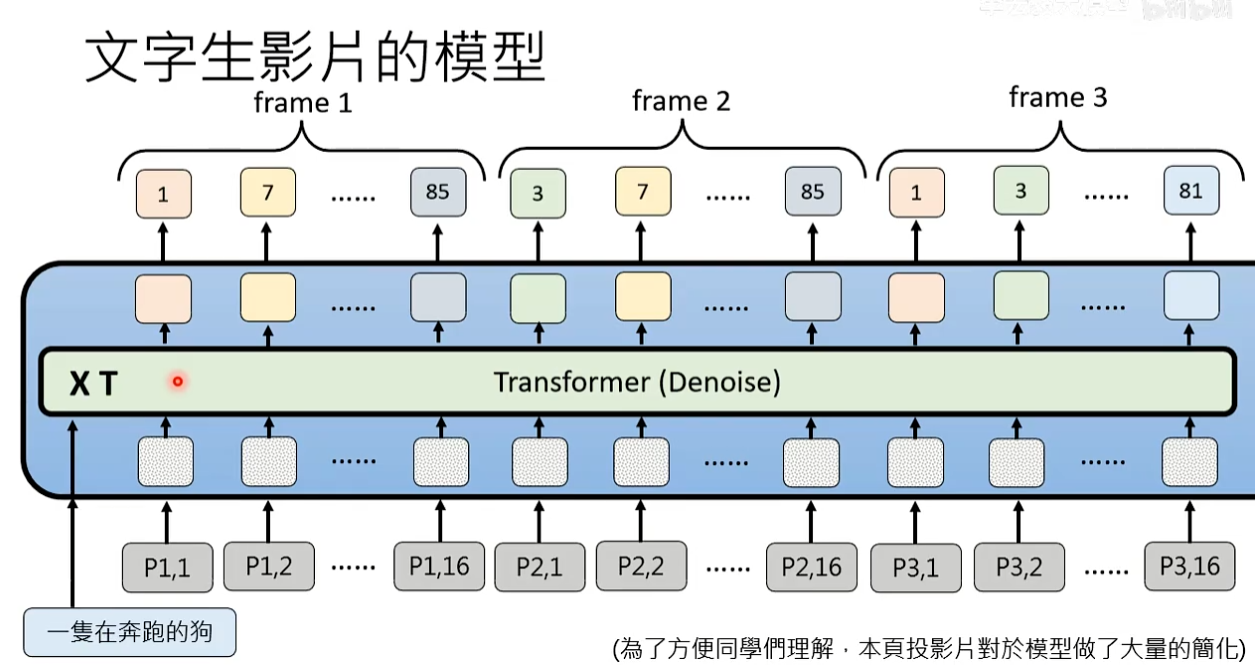
文字生成影片
文字生成影片和文字生图没有本质上的区别,文字生图就是产生一堆patch,文字生影片本质就是产生了更多的patch。
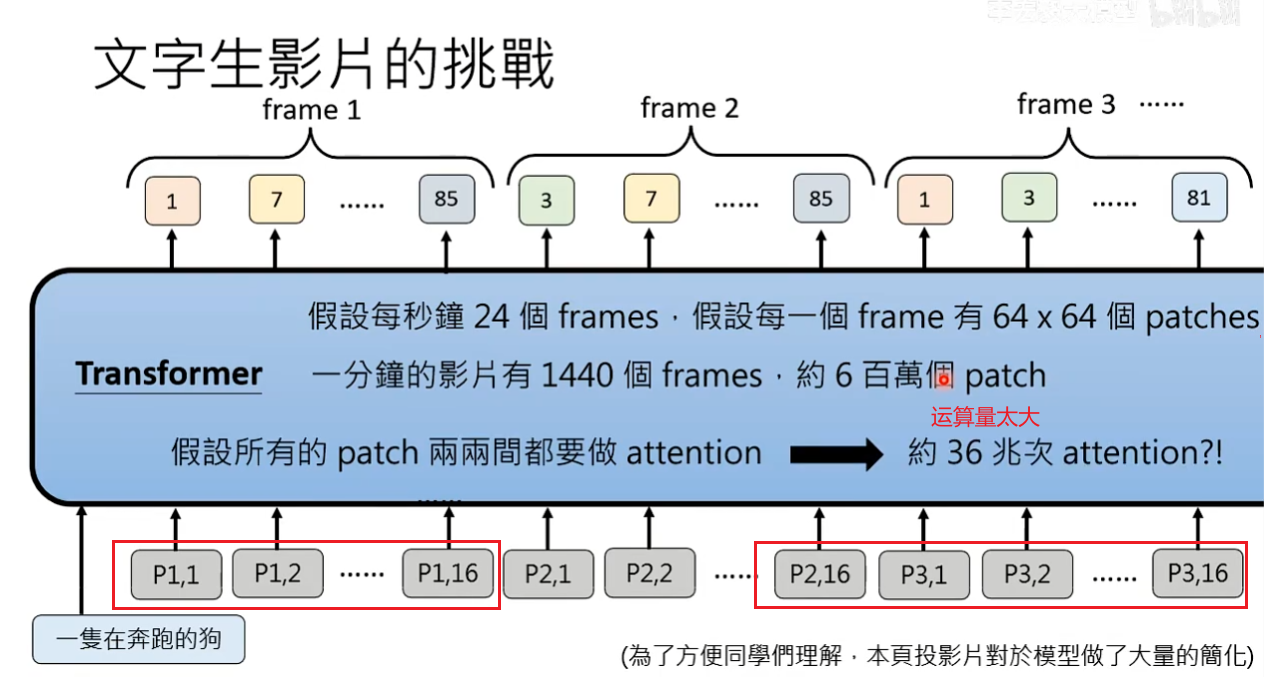
问题:文字生成影片的难点在于运算量太大了,目前研究都集中在如何减少运算量
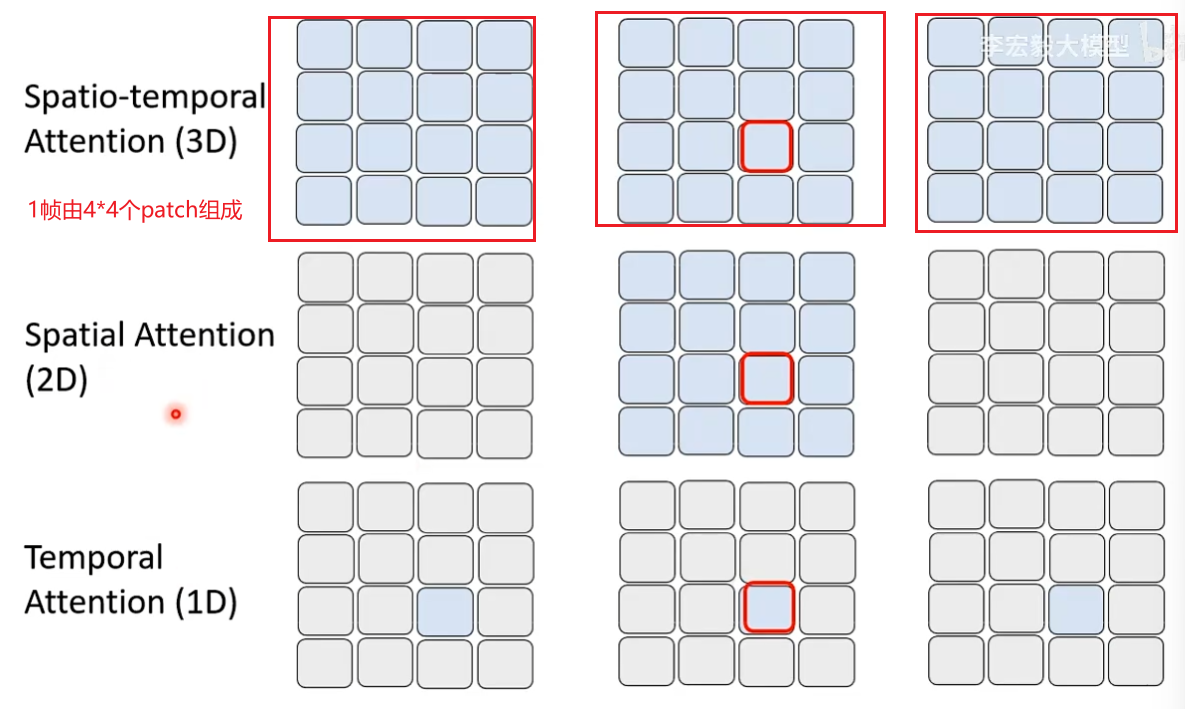
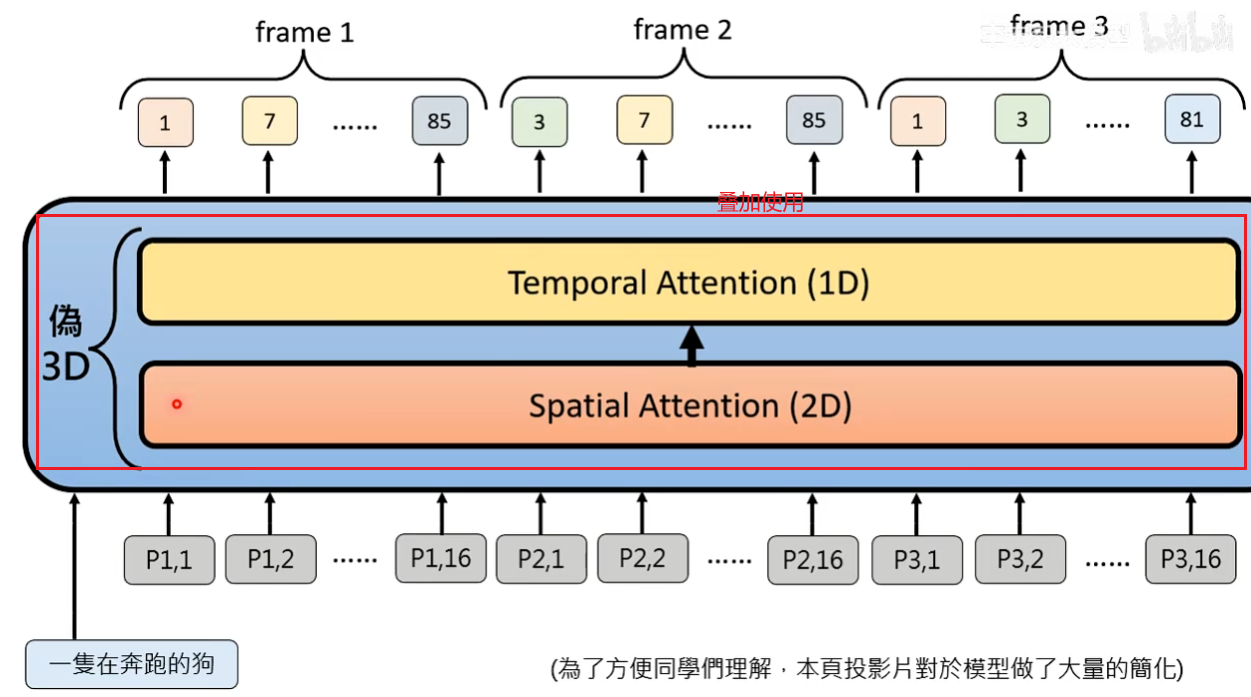
想法1:改造Attention运算,Attention目的是让patch之间有关联但没必要所有patch都做Attention
Spatio-temporal Attention():红框的patch需要做Attention时不只和同一个frame里的patch做还需要和其他frame里的patch做。
Spatial Attention(3D):每个patch只和同一个frame里的patch考虑Attention,存在问题每一帧之间可能不连贯了
Tenporal Attention(1D):不同frame的同一位置patch考虑Attention,只考虑时间维度的Attention没有考虑空间维度的Attention。

想法2:不一定一步到位生成影像,可以将生成分成多个步骤依次生成
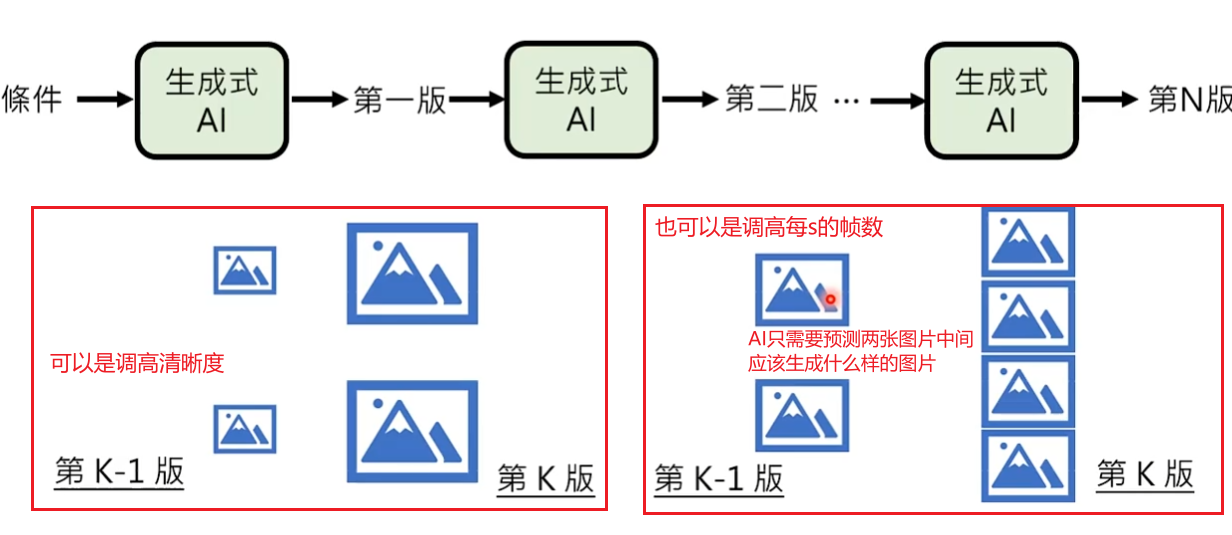
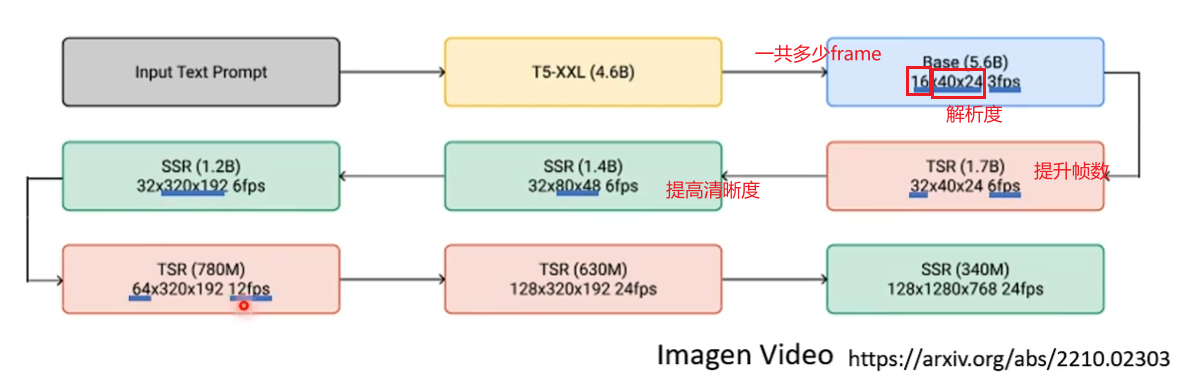
案例:Imagen Video
经典影像生成方法
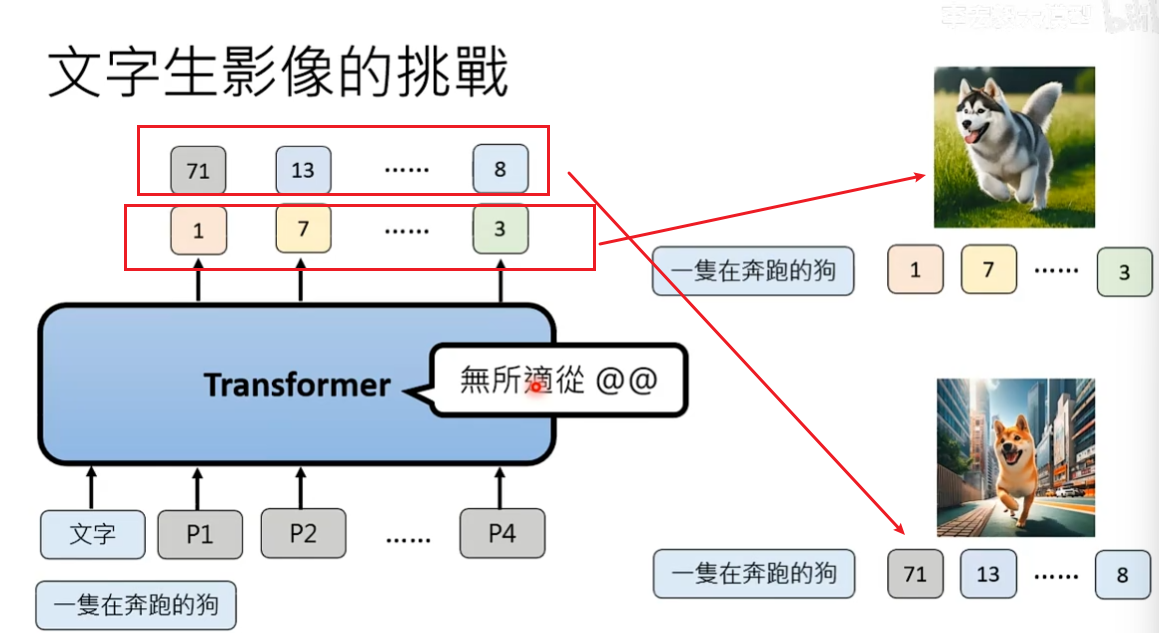
如果描述是一支奔跑的狗,我们发现对于同一个描述,有n套不同的patch与之匹配。所以在训练时,Transformer不知道听哪一个训练资料的。
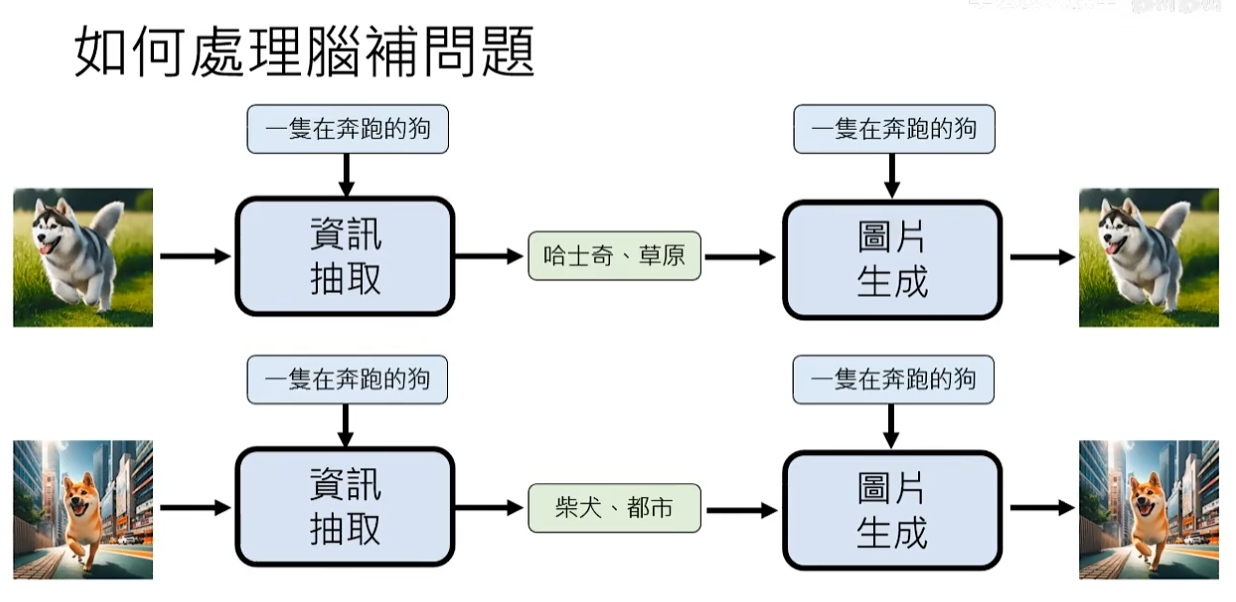
问题:如何处理脑补问题?
解决办法:添加更详细的描述信息给图片生成模型
可以训练一个信息抽取模型,将描述没有描述的东西抽取出来给图片生成模型。
问题:如何训练信息抽取
可能方法Auto-Encoder:图片生成模型和信息抽取模型可以一起被训练,信息抽取模型读训练资料的图片以及描述文字抽取文字没有提到的东西,将新抽取的信息和原来的描述一起给图片生成模型,最后产生图片。
虽然没有告诉信息抽取模型要抽取哪些信息,但两个模型最终目标都是输出的图片要与训练的图片越接近越好。
所以中间过程抽取什么不重要,也没有标准答案,我们只关注最后图片生成模型输出的图片与训练图片之间的接近程度。因此,在不需要额外标注资料的情况下,就可以训练信息抽取模型。
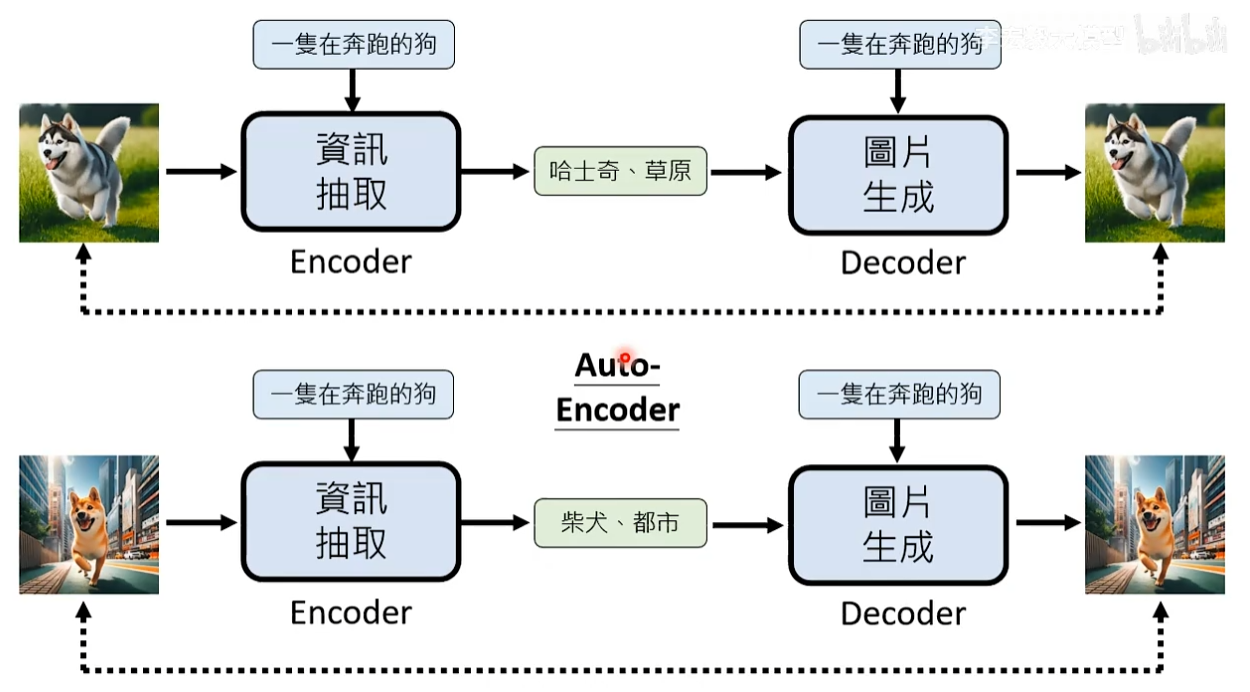
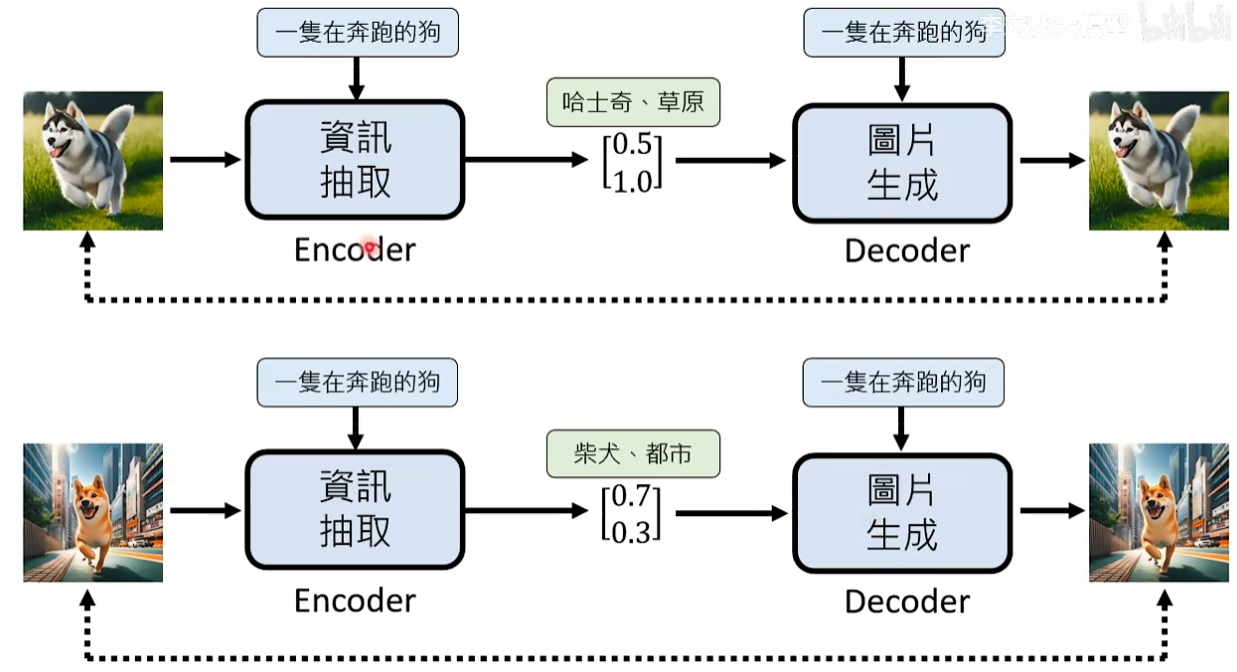
信息抽取模型的输出不需要是文字,一般向量就可以,每一个维度对应到某些特别的含义。
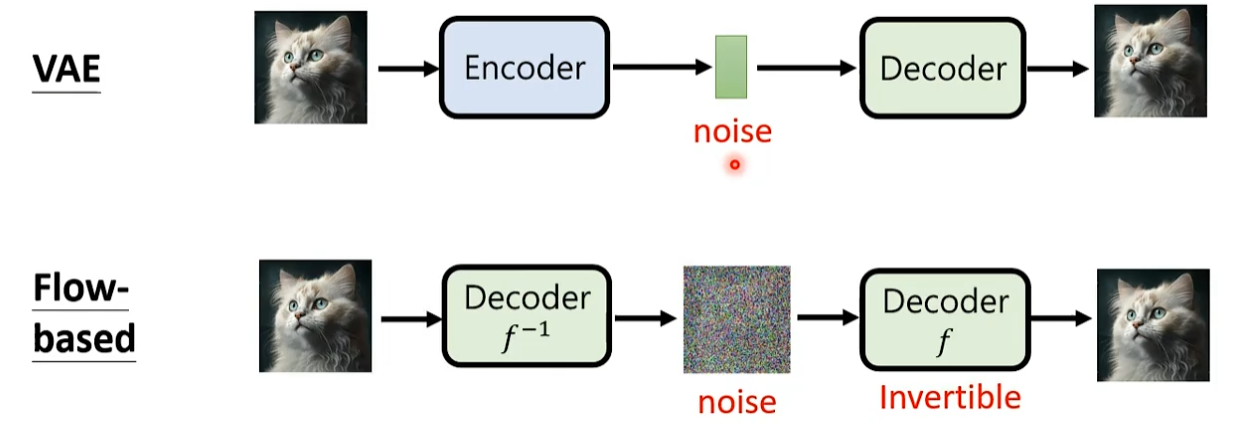
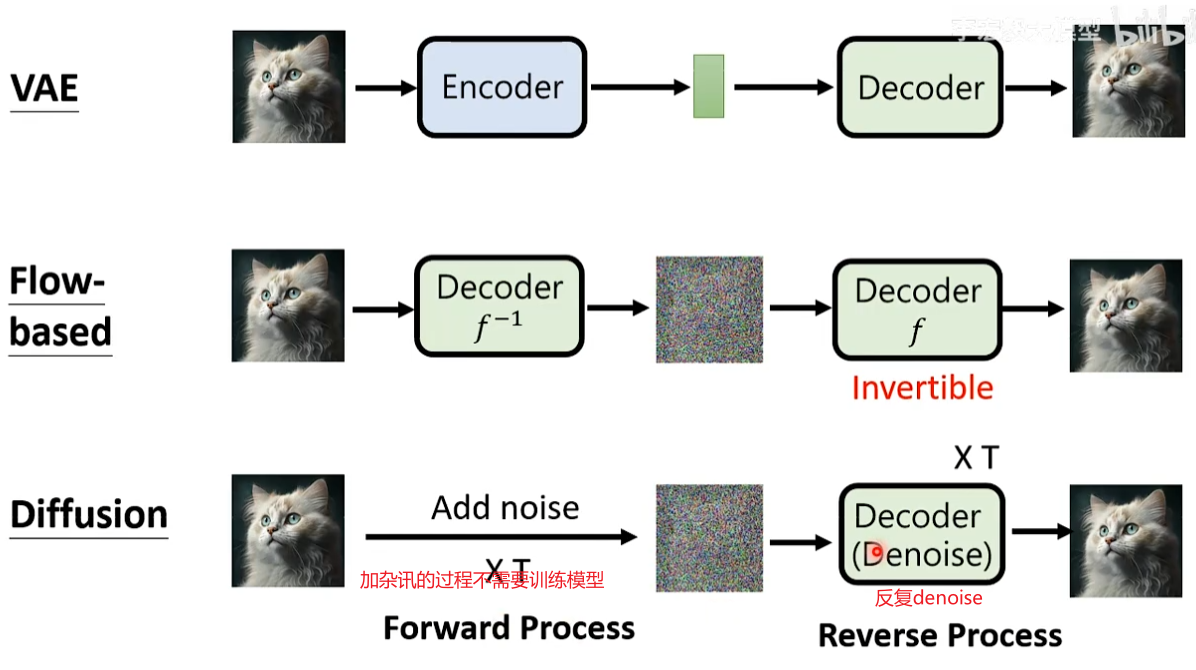
VAE Variational Auto-encoder模型
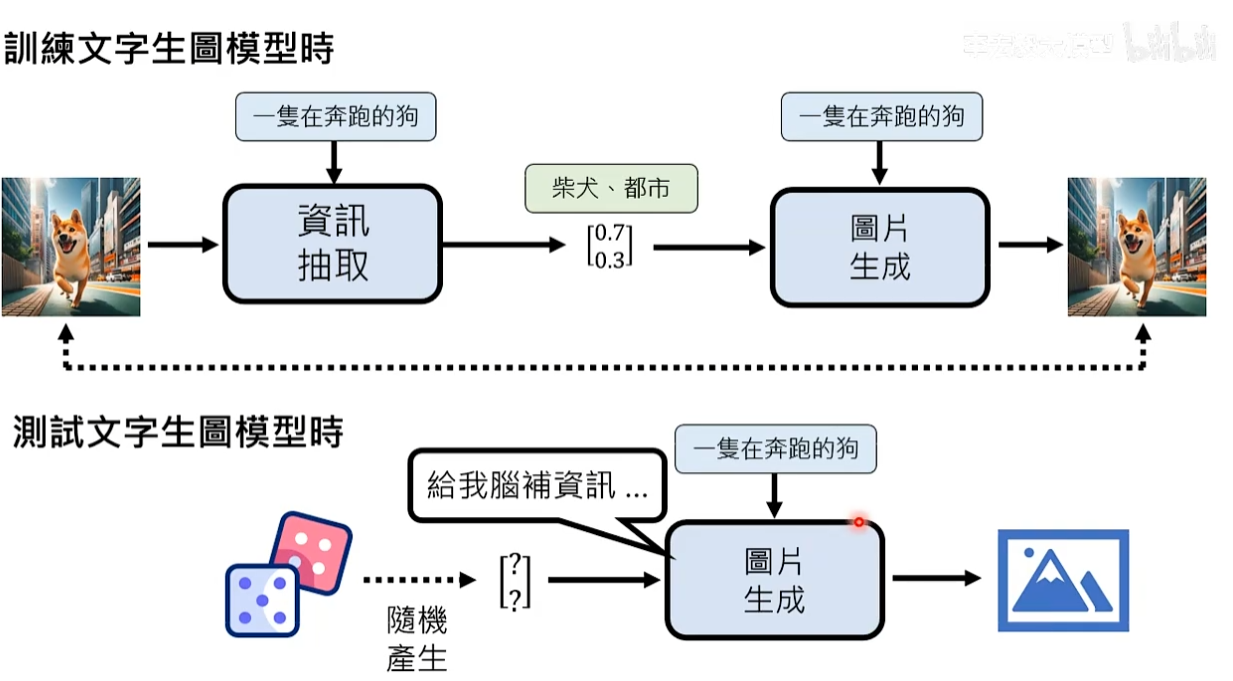
但在实际使用中,输入是一段描述,因为图片根本没有生成出来,所以我们不知道这段文字叙述没有描述的信息是什么。
我们已经知道需要脑补的信息使用某些数值表示,所以在用图片生成模型时,会通过掷骰子的方法随机产生向量中每个维度的数值(随机产生脑补信息)。
Flow-based 模型
这个模型和VAE模型非常像,不同的地方在于VAE需要训练Encoder从图片抽取信息和Decoder利用信息产生图。因为Encoder和Decoder做的事情相反,所以Flow-based模型认为只需要训练Decoder就可以了。训练的Decoder一定要invertible有反函数,反函数做的事情和Decoder相反。
一般将decoder拿来脑补的信息叫做noise,也就是Encoder抽取出来的信息。
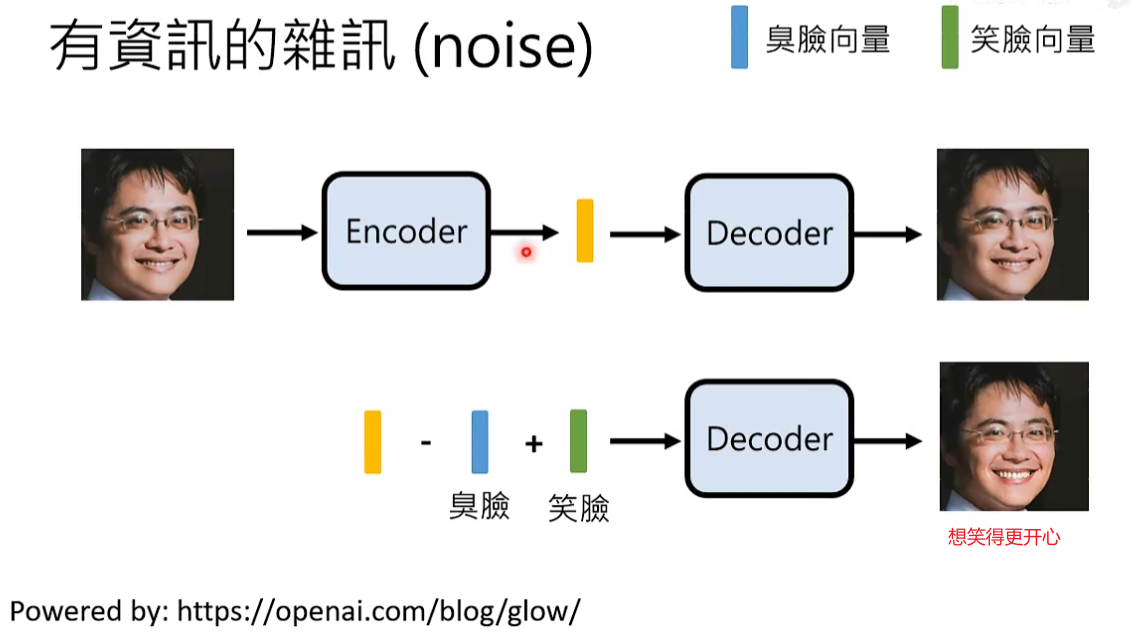
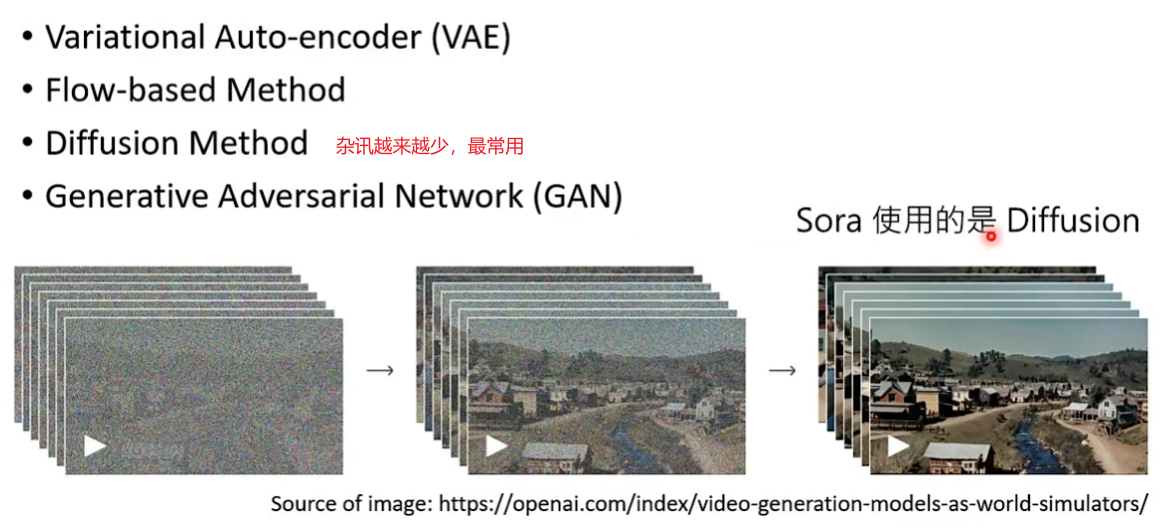
Diffusion Model
decoder做的事情也是输入一个noise加上原来的描述生成一个图片。
Diffusion Model会反复的使用一个decoder,每一次decoder只会去除杂讯这一件事情。
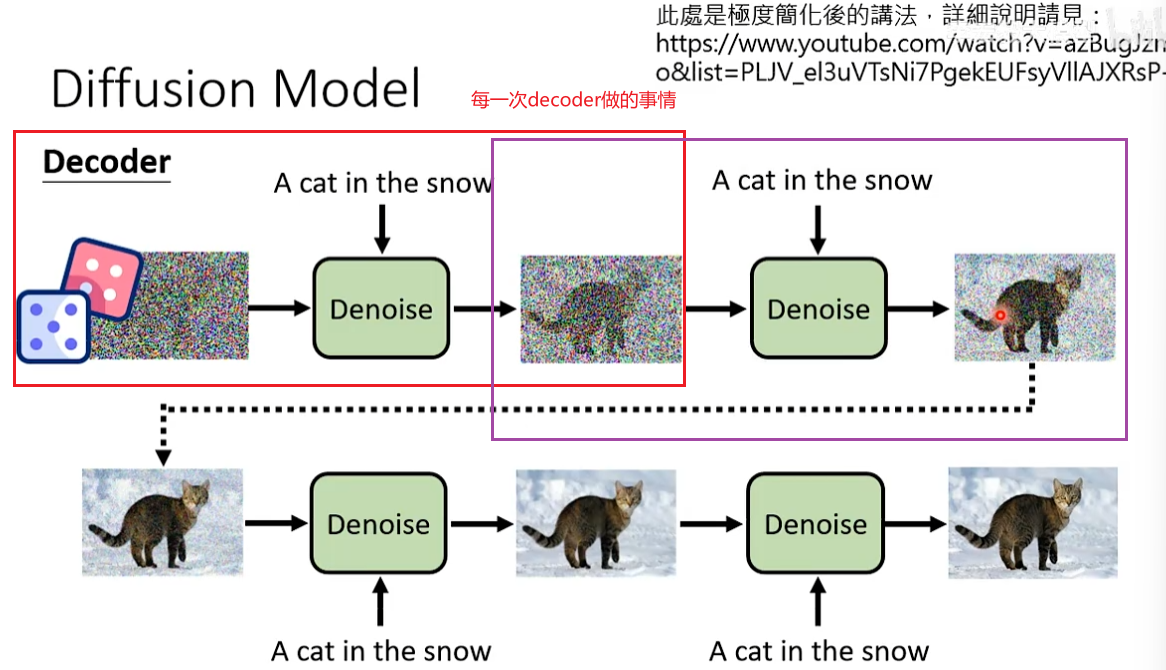
问题:denoise这个模组要怎么去除杂讯?
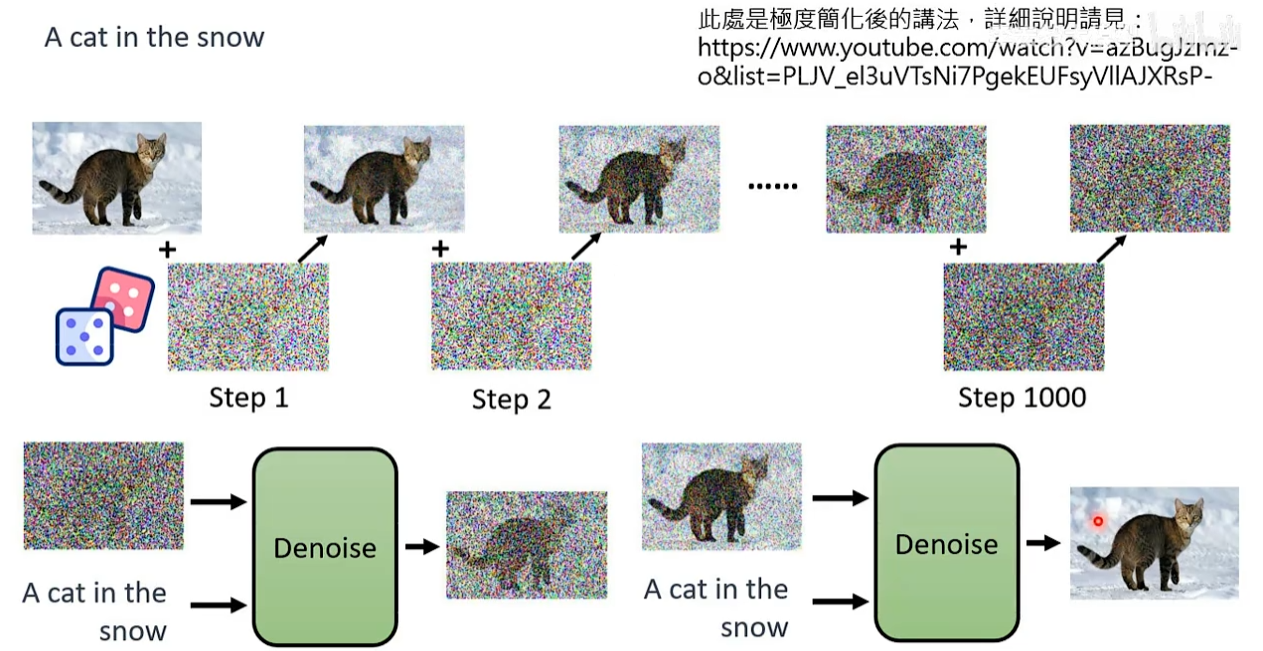
**解决办法:**可以自己制造杂讯,通过加杂讯的操作就可以获得有杂讯和没有杂讯的图片,就可以训练Denoise model了。
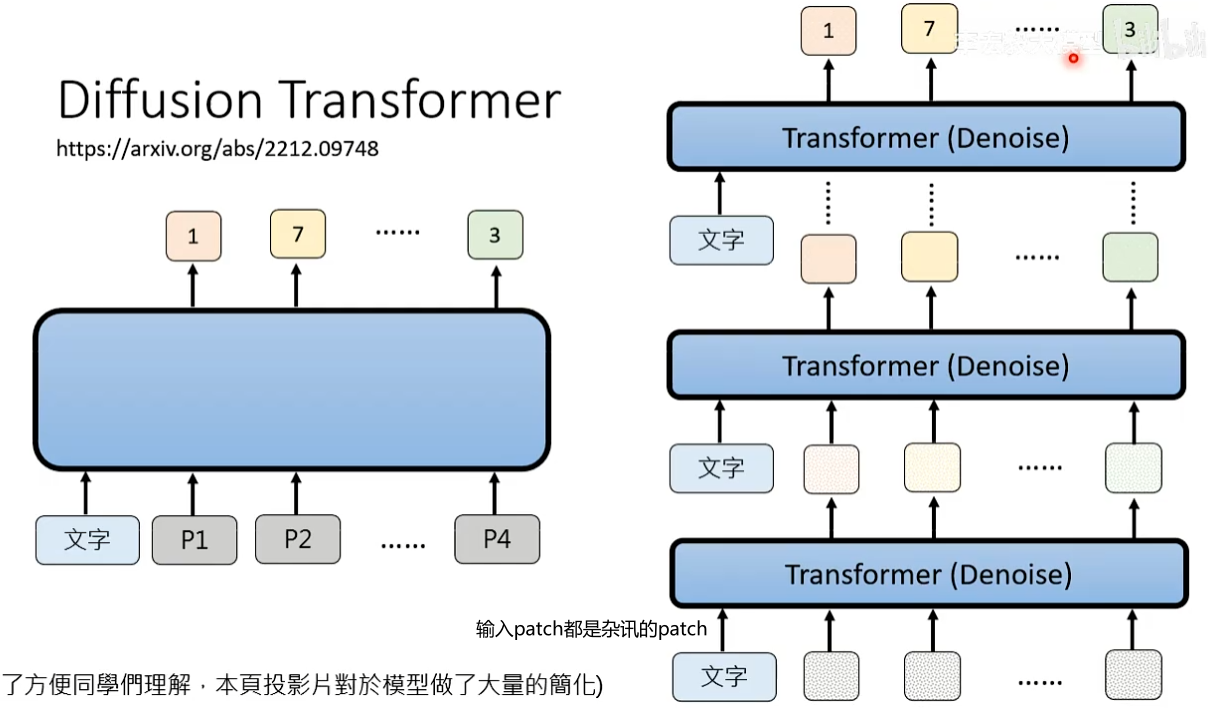
Denoise model里类神经网络的架构也是Transformer,这里用的是同一个Transformer。影片也是同样的架构
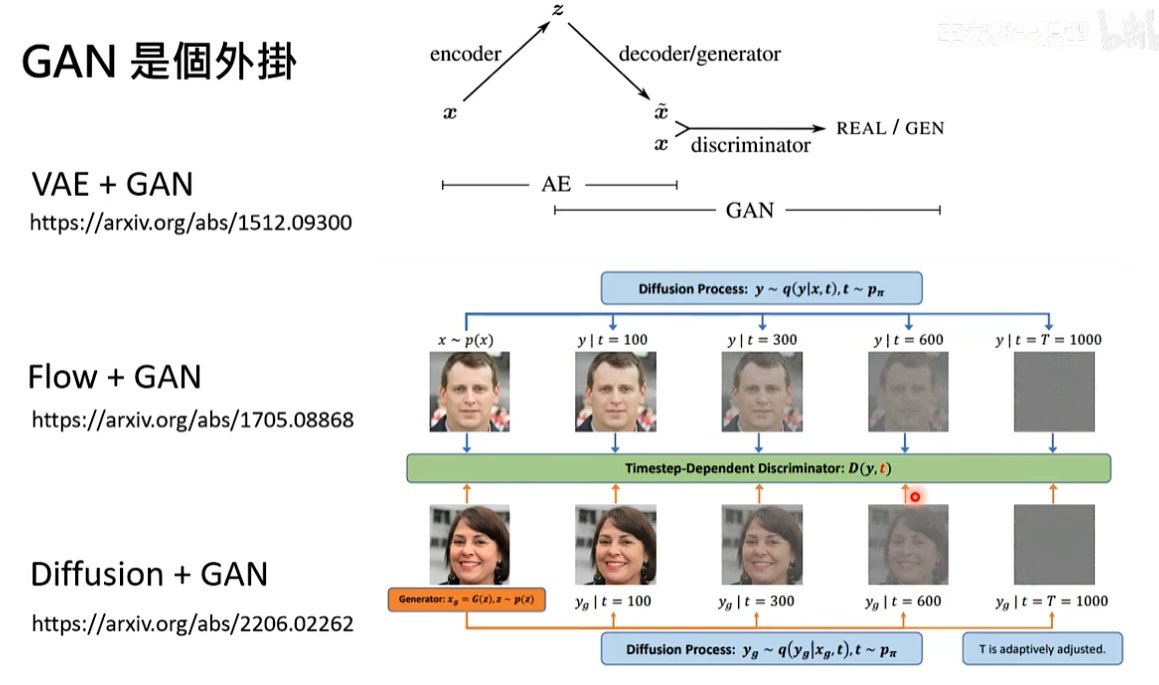
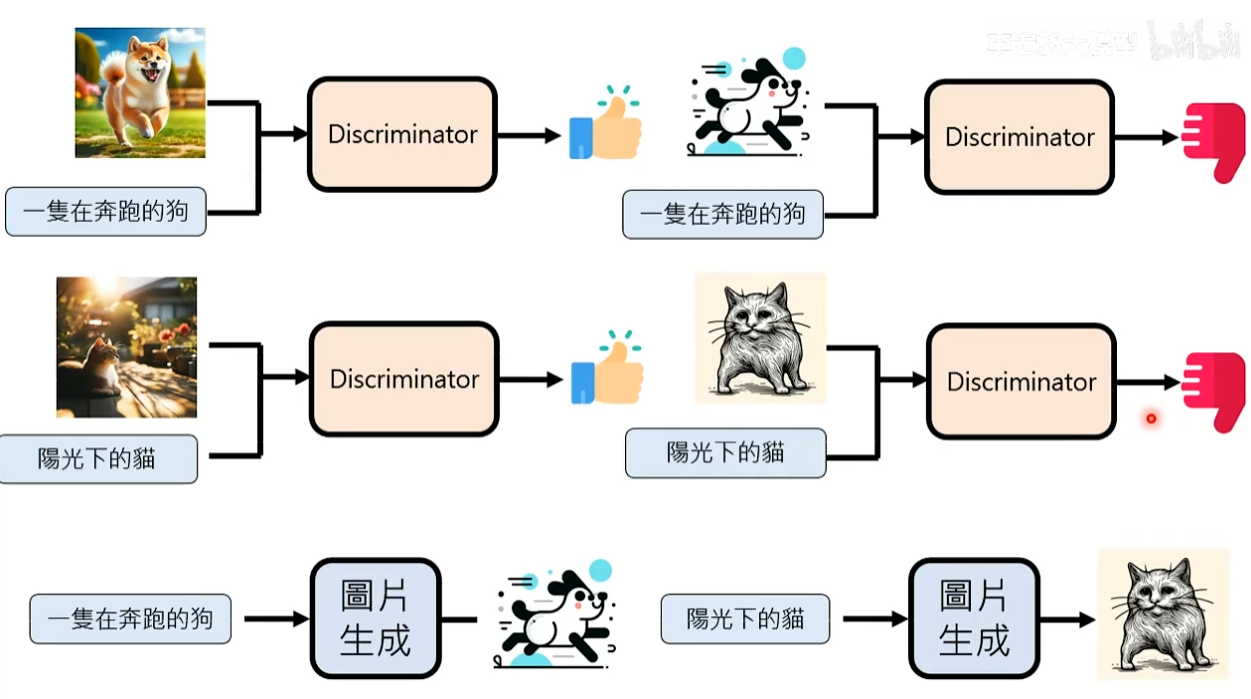
Generator Adversarial Network(GAN)
思路:不用真正的图片来教模型,训练出另一个模型先理解奔跑的狗应该长什么样子再来教图片生成模型。
在GAN训练一个和clip一个一模一样的模型叫做discriminator,评价图片和文字的匹配度。
discriminator在训练时还需要有坏例子,假设有一个图片生成模型先生成图片,比如抽象的猫、三只脚的狗。然后把这个不好的图+正确的描述给discriminator让其输出负面结果。
Generator 模型不去跟真正的图片学习,而是跟discriminator学习。不断调整模型参数去产生新的图片,目标是新的图片在discriminator模型上得到正面的评价。通过图片学习的话,同样的文字会对应不同的答案。跟discriminator学习的话,只要Generator根据描述产生一个张图片,discriminator只会产生好或不好两种答案。
在实际过程中discriminator和Generator会交替训练,先有Generator,然后利用Generator去训练discriminator,训练好discriminator后又反过来训练Generator。
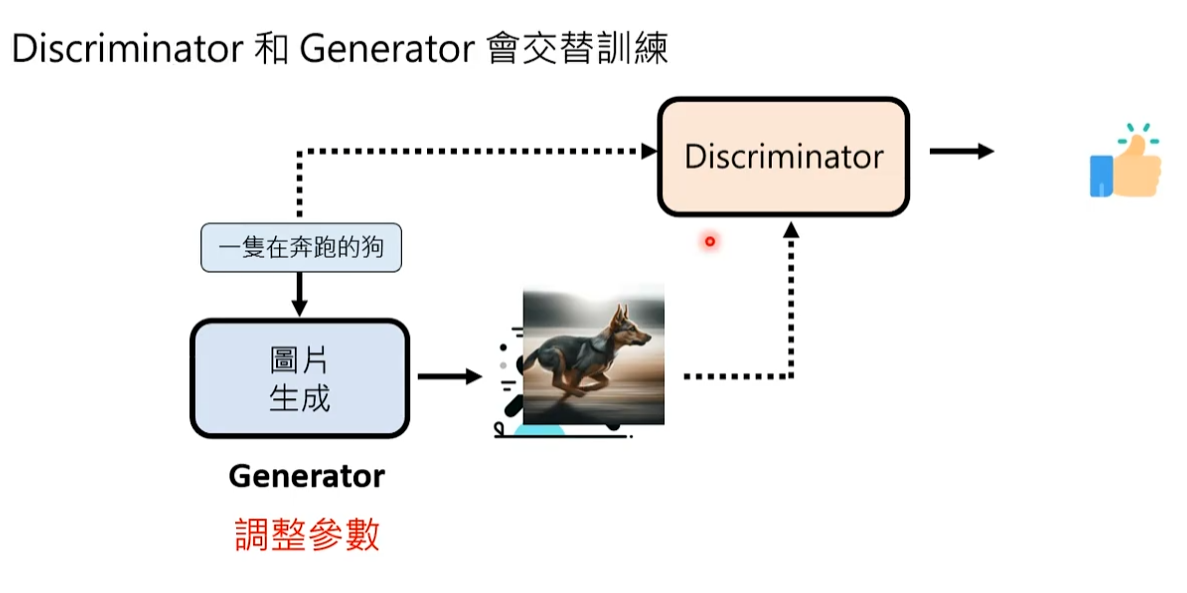
问题:对于GAN这个模型,还需不需要输入noise?noise的作用是额外的信息来帮助模型脑补。
回答:在文字生图的场景中,有discriminator实际上是不需要noise