Lotus-基于大模型的查询引擎 -开源学习整理
Lotus-基于大模型的查询引擎 -开源学习整理
https://github.com/lotus-data/lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) provides a declarative programming model and an optimized query engine for serving powerful reasoning-based query pipelines over structured and unstructured data! We provide a simple and intuitive Pandas-like API, that implements semantic operators.
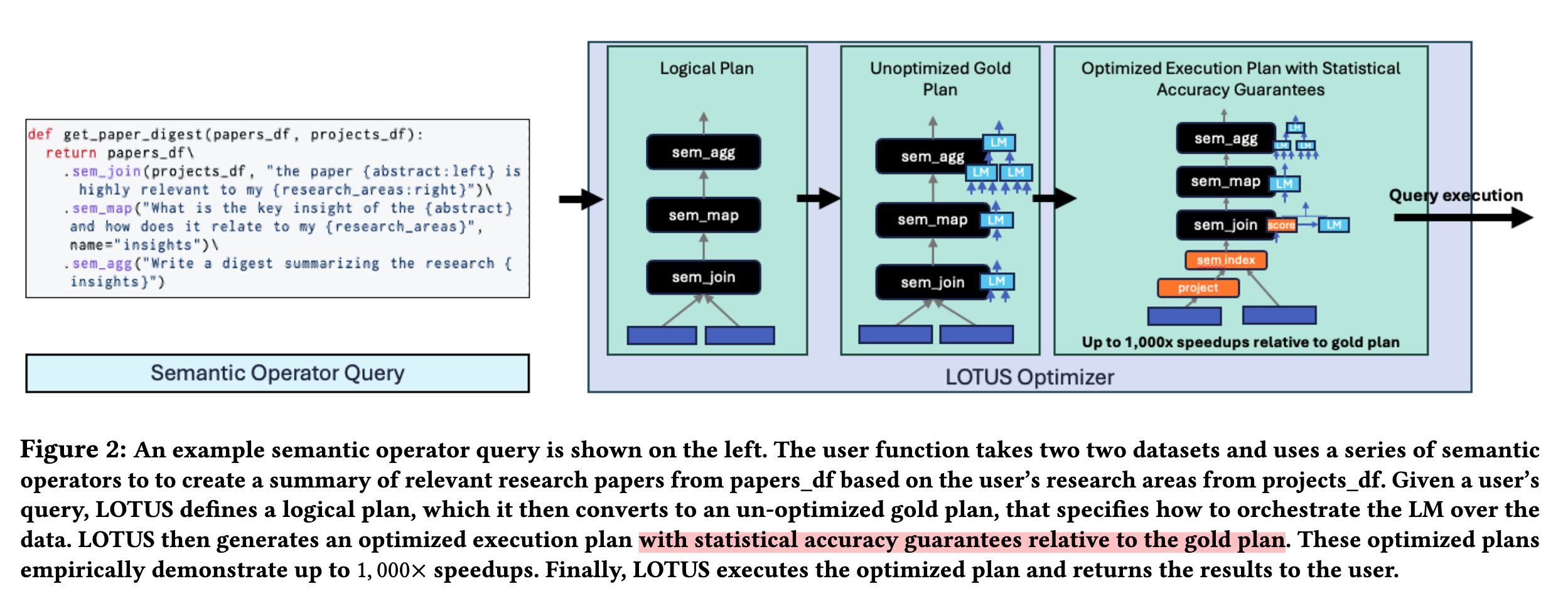
学习和理解一个类似 LOTUS 这样数据智能处理库的源码,推荐的顺序和方法如下:
1. 快速扫一遍:项目结构和README
- 通读
README.md,了解项目目标、主要功能和设计理念。 - 浏览根目录和
lotus/目录下的结构,知道每一部分大致对应什么功能。
这里跑通了一个最小示例:
import os
import pandas as pd
import lotus
from lotus.models import LM# 显式写出 OpenAI API Key(请替换为你的实际 key)
os.environ["OPENAI_API_KEY"] = "sk-pxxxx" # 注意安全,不建议在生产代码中明文写 key# 配置模型
lm = LM(model="gpt-4o-mini")
lotus.settings.configure(lm=lm)# 创建数据
courses_data = {"Course Name": ["History of the Atlantic World","Riemannian Geometry","Operating Systems","Food Science","Compilers","Intro to computer science",]
}
skills_data = {"Skill": ["Math", "Computer Science"]}
courses_df = pd.DataFrame(courses_data)
skills_df = pd.DataFrame(skills_data)# 语义 join
res = courses_df.sem_join(skills_df, "Taking {Course Name} will help me learn {Skill}")
print(res)# 打印用量
lm.print_total_usage()
2. 核心概念和高层API
- 阅读文档目录下的
core_concepts.rst,了解项目的基本原理和核心思想。 看。docs/sem_*.rst系列(如sem_map.rst、sem_join.rst),了解每个语义操作符的功能和典型调用方式
Core Concepts
LOTUS’ implements the semantic operator programming model. Semantic operators are declarative transformations over one or more datasets, parameterized by a natural langauge expression (langex) that can be implemnted by a variety of AI-based algorithms. Semantic operators seamlessly extend the relational model, operating over datasets that may contain traditional structured data as well as unstructured fields, such as free-form text or images. Because semantic operators are composable, modular and declarative, they allow you to write AI-based piplines with intuitive, high-level logic, leaving the rest of the work to the query engine! Each operator can be implmented and optimized in multiple ways, opening a rich space for execution plans, similar to relational operators.
定义了操作符
Here is a quick example of semantic operators in action:
langex = "The {abstract} suggests that LLMs efficeintly utilize long context"
filtered_df = papers_df.sem_filter(langex) --- 得到了一种控制模型的算子
With LOTUS, applications can be built by chaining togethor different semantic operators. Much like relational operators, semantic operators represent transformations over the dataset, and can be implemented and optimized under the hood. Each semantic operator is parameterized by a natural language expression. Here are some key semantic operators:
与关系操作符非常相似,语义操作符表示对数据集的转换,并且可以在底层实现和优化。每个语义操作符都由一个自然语言表达式进行参数化。
| Operator | Description |
|---|---|
| sem_map | Map each record using a natural language projection |
| sem_extract | Extract one or more attributes from each row |
| sem_filter | Keep records that match the natural language predicate |
| sem_agg | Aggregate across all records (e.g. for summarization) |
| sem_topk | Order records by the natural langauge ranking criteria |
| sem_join | Join two datasets based on a natural language predicate |
| sem_sim_join | Join two DataFrames based on semantic similarity |
| sem_search | Perform semantic search the over a text column |
3. 主入口和配置
- 打开
lotus/settings.py
了解全局配置是怎么实现的,如何设置模型、缓存等。 看lotus/__init__.py
理解包的导出和主要接口。
import lotus.models
import lotus.vector_store
from lotus.types import SerializationFormat# NOTE: Settings class is not thread-safeclass Settings:# Modelslm: lotus.models.LM | None = Nonerm: lotus.models.RM | None = None # supposed to only generate embeddings/这里paper中提到某些join操作需要用 embedding 进行相似度匹配。helper_lm: lotus.models.LM | None = Nonereranker: lotus.models.Reranker | None = Nonevs: lotus.vector_store.VS | None = None# Cache settingsenable_cache: bool = False# Serialization settingserialization_format: SerializationFormat = SerializationFormat.DEFAULT# Parallel groupby settingsparallel_groupby_max_threads: int = 8def configure(self, **kwargs):for key, value in kwargs.items():if not hasattr(self, key):raise ValueError(f"Invalid setting: {key}")setattr(self, key, value)def __str__(self):return str(vars(self))settings = Settings()
4. 大模型封装层源码
- 看
lotus/models/lm.py
理解 LLM(大模型)是如何被封装和调用的。 - 看
lotus/models/rm.py,sentence_transformers_rm.py,reranker.py
理解 RM(语义相关性模型)、Reranker(重排序器)是如何集成的。 - 如果感兴趣,也可以看
cross_encoder_reranker.py、colbertv2_rm.py等。
'''
其主要作用是:管理 LLM 的参数(模型名、温度、最大长度、速率限制等)
支持批量调用、进度展示、速率限制
自动缓存模型输出,避免重复消耗
统计用量、费用,支持用量上限
支持 logprobs(概率)等高级特性
兼容多种大模型 API(如 OpenAI、DeepSeek 等)'''import hashlib
import logging
import math
import time
import warnings
from typing import Anyimport litellm
import numpy as np
from litellm import batch_completion, completion_cost
from litellm.exceptions import AuthenticationError
from litellm.types.utils import ChatCompletionTokenLogprob, Choices, ModelResponse
from litellm.utils import token_counter
from openai._exceptions import OpenAIError
from tokenizers import Tokenizer
from tqdm import tqdmimport lotus
from lotus.cache import CacheFactory
from lotus.types import (LMOutput,LMStats,LogprobsForCascade,LogprobsForFilterCascade,LotusUsageLimitException,UsageLimit,
)logging.getLogger("LiteLLM").setLevel(logging.CRITICAL)
logging.getLogger("httpx").setLevel(logging.CRITICAL)class LM:def __init__(self,model: str = "gpt-4o-mini",temperature: float = 0.0,max_ctx_len: int = 128000,max_tokens: int = 512,max_batch_size: int = 64,rate_limit: int | None = None,tokenizer: Tokenizer | None = None,cache=None,physical_usage_limit: UsageLimit = UsageLimit(),virtual_usage_limit: UsageLimit = UsageLimit(),**kwargs: dict[str, Any],):"""Language Model class for interacting with various LLM providers.Args:model (str): Name of the model to use. Defaults to "gpt-4o-mini".temperature (float): Sampling temperature. Defaults to 0.0.max_ctx_len (int): Maximum context length in tokens. Defaults to 128000.max_tokens (int): Maximum number of tokens to generate. Defaults to 512.max_batch_size (int): Maximum batch size for concurrent requests. Defaults to 64.rate_limit (int | None): Maximum requests per minute. If set, caps max_batch_size and adds delays.tokenizer (Tokenizer | None): Custom tokenizer instance. Defaults to None.cache: Cache instance to use. Defaults to None.physical_usage_limit (UsageLimit): Physical usage limits for the model. Defaults to UsageLimit().virtual_usage_limit (UsageLimit): Virtual usage limits for the model. Defaults to UsageLimit().**kwargs: Additional keyword arguments passed to the underlying LLM API."""self.model = modelself.max_ctx_len = max_ctx_lenself.max_tokens = max_tokensself.rate_limit = rate_limitif rate_limit is not None:self._rate_limit_delay = 60 / rate_limitif max_batch_size is not None:self.max_batch_size = min(rate_limit, max_batch_size)else:self.max_batch_size = rate_limitelse:self.max_batch_size = max_batch_sizeself.tokenizer = tokenizerself.kwargs = dict(temperature=temperature, max_tokens=max_tokens, **kwargs)self.stats: LMStats = LMStats()self.physical_usage_limit = physical_usage_limitself.virtual_usage_limit = virtual_usage_limitself.cache = cache or CacheFactory.create_default_cache()def __call__(self,messages: list[list[dict[str, str]]], #[{a:q,a2:q2},{a:q,a2:q2},],[{a:q,a2:q2}]show_progress_bar: bool = True,progress_bar_desc: str = "Processing uncached messages",**kwargs: dict[str, Any],) -> LMOutput:all_kwargs = {**self.kwargs, **kwargs}# Set top_logprobs if logprobs requestedif all_kwargs.get("logprobs", False):all_kwargs.setdefault("top_logprobs", 10)if lotus.settings.enable_cache:# Check cache and separate cached and uncached messageshashed_messages = [self._hash_messages(msg, all_kwargs) for msg in messages]cached_responses = [self.cache.get(hash) for hash in hashed_messages]uncached_data = ([(msg, hash) for msg, hash, resp in zip(messages, hashed_messages, cached_responses) if resp is None]if lotus.settings.enable_cacheelse [(msg, "no-cache") for msg in messages])self.stats.cache_hits += len(messages) - len(uncached_data)# Process uncached messages in batchesuncached_responses = self._process_uncached_messages(uncached_data, all_kwargs, show_progress_bar, progress_bar_desc)# Add new responses to cache and update statsfor resp, (_, hash) in zip(uncached_responses, uncached_data):self._update_stats(resp, is_cached=False)if lotus.settings.enable_cache:self._cache_response(resp, hash)# Update virtual stats for cached responsesif lotus.settings.enable_cache:for resp in cached_responses:if resp is not None:self._update_stats(resp, is_cached=True)# Merge all responses in original order and extract outputsall_responses = (self._merge_responses(cached_responses, uncached_responses)if lotus.settings.enable_cacheelse uncached_responses)outputs = [self._get_top_choice(resp) for resp in all_responses]logprobs = ([self._get_top_choice_logprobs(resp) for resp in all_responses] if all_kwargs.get("logprobs") else None)return LMOutput(outputs=outputs, logprobs=logprobs)def _process_uncached_messages(self, uncached_data, all_kwargs, show_progress_bar, progress_bar_desc):"""Processes uncached messages in batches and returns responses."""total_calls = len(uncached_data)pbar = tqdm(total=total_calls,desc=progress_bar_desc,disable=not show_progress_bar,bar_format="{l_bar}{bar} {n}/{total} LM calls [{elapsed}<{remaining}, {rate_fmt}{postfix}]",)batch = [msg for msg, _ in uncached_data]if self.rate_limit is not None:uncached_responses = self._process_with_rate_limiting(batch, all_kwargs, pbar)else:uncached_responses = batch_completion(self.model, batch, drop_params=True, max_workers=self.max_batch_size, **all_kwargs)pbar.update(total_calls)pbar.close()return uncached_responsesdef _process_with_rate_limiting(self, batch, all_kwargs, pbar):responses = []num_batches = math.ceil(len(batch) / self.max_batch_size)min_interval_per_request = 60 / self.rate_limit # seconds per requestfor i in range(num_batches):start_time = time.time()start_idx = i * self.max_batch_sizeend_idx = min((i + 1) * self.max_batch_size, len(batch))sub_batch = batch[start_idx:end_idx]sub_responses = batch_completion(self.model, sub_batch, drop_params=True, max_workers=self.max_batch_size, **all_kwargs)responses.extend(sub_responses)pbar.update(len(sub_batch))end_time = time.time()elapsed = end_time - start_time# Calculate required delay based on number of requests in this batch# Each request should be spaced by min_interval_per_requestrequired_time_for_batch = len(sub_batch) * min_interval_per_request# Only sleep if the batch was faster than the required timeif i < num_batches - 1: # Don't sleep after the last batchto_sleep = required_time_for_batch - elapsedif to_sleep > 0:time.sleep(to_sleep)return responsesdef _cache_response(self, response, hash):"""Caches a response and updates stats if successful."""if isinstance(response, OpenAIError):raise responseself.cache.insert(hash, response)def _hash_messages(self, messages: list[dict[str, str]], kwargs: dict[str, Any]) -> str:"""Hash messages and kwargs to create a unique key for the cache"""to_hash = str(self.model) + str(messages) + str(kwargs)return hashlib.sha256(to_hash.encode()).hexdigest()def _merge_responses(self, cached_responses: list[ModelResponse | None], uncached_responses: list[ModelResponse]) -> list[ModelResponse]:"""Merge cached and uncached responses, maintaining order"""uncached_iter = iter(uncached_responses)return [resp if resp is not None else next(uncached_iter) for resp in cached_responses]def _check_usage_limit(self, usage: LMStats.TotalUsage, limit: UsageLimit, usage_type: str):"""Helper to check if usage exceeds limits"""if (usage.prompt_tokens > limit.prompt_tokens_limitor usage.completion_tokens > limit.completion_tokens_limitor usage.total_tokens > limit.total_tokens_limitor usage.total_cost > limit.total_cost_limit):raise LotusUsageLimitException(f"Usage limit exceeded. Current {usage_type} usage: {usage}, Limit: {limit}")def _update_usage_stats(self, usage: LMStats.TotalUsage, response: ModelResponse, cost: float | None):"""Helper to update usage statistics"""if hasattr(response, "usage"):usage.prompt_tokens += response.usage.prompt_tokensusage.completion_tokens += response.usage.completion_tokensusage.total_tokens += response.usage.total_tokensif cost is not None:usage.total_cost += costdef _update_stats(self, response: ModelResponse, is_cached: bool = False):if not hasattr(response, "usage"):return# Calculate cost oncetry:cost = completion_cost(completion_response=response)except litellm.exceptions.NotFoundError as e:# Sometimes the model's pricing information is not availablelotus.logger.debug(f"Error updating completion cost: {e}")cost = Noneexcept Exception as e:# Handle any other unexpected errors when calculating costlotus.logger.debug(f"Unexpected error calculating completion cost: {e}")warnings.warn("Error calculating completion cost - cost metrics will be inaccurate. Enable debug logging for details.")cost = None# Always update virtual usageself._update_usage_stats(self.stats.virtual_usage, response, cost)self._check_usage_limit(self.stats.virtual_usage, self.virtual_usage_limit, "virtual")# Only update physical usage for non-cached responsesif not is_cached:self._update_usage_stats(self.stats.physical_usage, response, cost)self._check_usage_limit(self.stats.physical_usage, self.physical_usage_limit, "physical")def _get_top_choice(self, response: ModelResponse) -> str:# Handle authentication errors and other exceptionsif isinstance(response, (AuthenticationError, OpenAIError)):raise responsechoice = response.choices[0]assert isinstance(choice, Choices)if choice.message.content is None:raise ValueError(f"No content in response: {response}")return choice.message.contentdef _get_top_choice_logprobs(self, response: ModelResponse) -> list[ChatCompletionTokenLogprob]:# Handle authentication errors and other exceptionsif isinstance(response, (AuthenticationError, OpenAIError)):raise responsechoice = response.choices[0]assert isinstance(choice, Choices)logprobs = choice.logprobs["content"]return logprobsdef format_logprobs_for_cascade(self, logprobs: list[list[ChatCompletionTokenLogprob]]) -> LogprobsForCascade:all_tokens = []all_confidences = []for resp_logprobs in logprobs:tokens = [logprob.token for logprob in resp_logprobs]confidences = [np.exp(logprob.logprob) for logprob in resp_logprobs]all_tokens.append(tokens)all_confidences.append(confidences)return LogprobsForCascade(tokens=all_tokens, confidences=all_confidences)def format_logprobs_for_filter_cascade(self, logprobs: list[list[ChatCompletionTokenLogprob]]) -> LogprobsForFilterCascade:# Get base cascade format firstbase_cascade = self.format_logprobs_for_cascade(logprobs)all_true_probs = []def get_normalized_true_prob(token_probs: dict[str, float]) -> float | None:if "True" in token_probs and "False" in token_probs:true_prob = token_probs["True"]false_prob = token_probs["False"]return true_prob / (true_prob + false_prob)return None# Get true probabilities for filter cascadefor resp_idx, response_logprobs in enumerate(logprobs):true_prob = Nonefor logprob in response_logprobs:token_probs = {top.token: np.exp(top.logprob) for top in logprob.top_logprobs}true_prob = get_normalized_true_prob(token_probs)if true_prob is not None:break# Default to 1 if "True" in tokens, 0 if notif true_prob is None:true_prob = 1 if "True" in base_cascade.tokens[resp_idx] else 0all_true_probs.append(true_prob)return LogprobsForFilterCascade(tokens=base_cascade.tokens, confidences=base_cascade.confidences, true_probs=all_true_probs)def count_tokens(self, messages: list[dict[str, str]] | str) -> int:"""Count tokens in messages using either custom tokenizer or model's default tokenizer"""if isinstance(messages, str):messages = [{"role": "user", "content": messages}]custom_tokenizer: dict[str, Any] | None = Noneif self.tokenizer:custom_tokenizer = dict(type="huggingface_tokenizer", tokenizer=self.tokenizer)return token_counter(custom_tokenizer=custom_tokenizer,model=self.model,messages=messages,)def print_total_usage(self):print("\n=== Usage Statistics ===")print("Virtual = Total usage if no caching was used")print("Physical = Actual usage with caching applied\n")print(f"Virtual Cost: ${self.stats.virtual_usage.total_cost:,.6f}")print(f"Physical Cost: ${self.stats.physical_usage.total_cost:,.6f}")print(f"Virtual Tokens: {self.stats.virtual_usage.total_tokens:,}")print(f"Physical Tokens: {self.stats.physical_usage.total_tokens:,}")print(f"Cache Hits: {self.stats.cache_hits:,}\n")def reset_stats(self):self.stats = LMStats()def reset_cache(self, max_size: int | None = None):self.cache.reset(max_size)def get_model_name(self) -> str:raw_model = self.modelif not raw_model:return ""# If a slash is present, assume the model name is after the last slash.if "/" in raw_model:candidate = raw_model.split("/")[-1]else:candidate = raw_model# If a colon is present, assume the model version is appended and remove it.if ":" in candidate:candidate = candidate.split(":")[0]return candidate.lower()def is_deepseek(self) -> bool:model_name = self.get_model_name()return model_name.startswith("deepseek-r1")
1元素是一个消息序列(对话历史)
[
{“role”: “user”, “content”: “问题…”},
{“role”: “assistant”, “content”: “上轮回答…”},
{“role”: “user”, “content”: “追问…”},]
2 hash – key:
模型名(比如 gpt-4o-mini)
完整消息内容(整个对话历史,顺序和内容都敏感)
调用参数(如 temperature, max_tokens, logprobs 等)
to_hash = str(self.model) + str(messages) + str(kwargs) return hashlib.sha256(to_hash.encode()).hexdigest()缓存流程如下:
输入是 N 个消息序列。
对每个消息,先查缓存(用上面说的 key)。
- 命中:直接返回缓存里的 response
- 未命中:会实时去 LLM 请求,并把响应写进缓存
最终输出顺序严格对应输入顺序
。合并时:
- 有缓存的用缓存 – 继续拼接到缓存的hash中
- 没缓存的用刚新生成的(并已写入缓存)hashmap
5. 核心语义操作符实现
- 打开
lotus/sem_ops/目录,重点关注常用操作:sem_map.pysem_filter.pysem_join.pysem_sim_join.pysem_agg.pysem_extract.pysem_topk.pysem_search.pysem_index.pysem_cluster_by.py、sem_dedup.py等
以 sem_map.py 为例
@pd.api.extensions.register_dataframe_accessor("sem_map")
class SemMapDataframe:"""DataFrame accessor for semantic map."""def __init__(self, pandas_obj: pd.DataFrame):self._validate(pandas_obj)self._obj = pandas_obj@staticmethoddef _validate(obj: pd.DataFrame) -> None:if not isinstance(obj, pd.DataFrame):raise AttributeError("Must be a DataFrame")@operator_cachedef __call__(self,user_instruction: str,postprocessor: Callable[[list[str], lotus.models.LM, bool], SemanticMapPostprocessOutput] = map_postprocess,return_explanations: bool = False,return_raw_outputs: bool = False,suffix: str = "_map",examples: pd.DataFrame | None = None,strategy: ReasoningStrategy | None = None,safe_mode: bool = False,progress_bar_desc: str = "Mapping",) -> pd.DataFrame:"""Applies semantic map over a dataframe.Args:user_instruction (str): The user instruction for map.postprocessor (Callable): The postprocessor for the model outputs. Defaults to map_postprocess.return_explanations (bool): Whether to return explanations. Defaults to False.return_raw_outputs (bool): Whether to return raw outputs. Defaults to False.suffix (str): The suffix for the new columns. Defaults to "_map".examples (pd.DataFrame | None): The examples dataframe. Defaults to None.strategy (str | None): The reasoning strategy. Defaults to None.Returns:pd.DataFrame: The dataframe with the new mapped columns."""if lotus.settings.lm is None:raise ValueError("The language model must be an instance of LM. Please configure a valid language model using lotus.settings.configure()")#自动提取列名col_li = lotus.nl_expression.parse_cols(user_instruction)# check that column existsfor column in col_li:if column not in self._obj.columns:raise ValueError(f"Column {column} not found in DataFrame")multimodal_data = task_instructions.df2multimodal_info(self._obj, col_li)formatted_usr_instr = lotus.nl_expression.nle2str(user_instruction, col_li)examples_multimodal_data = Noneexamples_answers = Nonecot_reasoning = Noneif examples is not None:assert "Answer" in examples.columns, "Answer must be a column in examples dataframe"examples_multimodal_data = task_instructions.df2multimodal_info(examples, col_li)examples_answers = examples["Answer"].tolist()if strategy == ReasoningStrategy.COT or strategy == ReasoningStrategy.ZS_COT:return_explanations = Truecot_reasoning = examples["Reasoning"].tolist()output = sem_map(multimodal_data,lotus.settings.lm,formatted_usr_instr,postprocessor=postprocessor,examples_multimodal_data=examples_multimodal_data,examples_answers=examples_answers,cot_reasoning=cot_reasoning,strategy=strategy,safe_mode=safe_mode,progress_bar_desc=progress_bar_desc,)new_df = self._obj.copy()new_df[suffix] = output.outputsif return_explanations:new_df["explanation" + suffix] = output.explanationsif return_raw_outputs:new_df["raw_output" + suffix] = output.raw_outputsreturn new_df可以学习的点:
注册自定义 DataFrame accessor:让 pandas 更强大、易用。
面向对象+函数式编程结合:类+静态方法+高阶函数组合。
参数默认值和类型提示:易于理解和调用。
异常处理和断言:保证输入输出可靠性。
自动化数据流处理:将AI推理结果与结构化数据天然融合。
6. 数据处理和类型扩展
- 看
lotus/types.py
了解自定义的数据类型和结构。 - 看
lotus/dtype_extensions/下的内容(如image.py),这里扩展了对图片等特殊类型的支持。
7. 数据连接器与文件抽取
- 看
lotus/data_connectors/下的connectors.py
理解外部数据源(数据库、S3等)是如何接入的。 - 看
lotus/file_extractors/下的如directory_reader.py、pptx.py
理解文件内容是如何被抽取为结构化数据的。
8. 向量存储和检索
- 浏览
lotus/vector_store/下的faiss_vs.py、qdrant_vs.py、weaviate_vs.py
理解如何与不同的向量数据库对接。
9. 缓存与工具函数
- 看
lotus/cache.py,了解如何缓存模型输出,提升效率。 - 看
lotus/utils.py,了解常用工具函数。
10. 测试和示例
- 阅读
tests/目录下的测试代码,结合examples/目录下的示例脚本,实际运行和调试。 - 推荐先跑
examples/op_examples/下的典型脚本(如map.py,filter.py,join.py),边跑边结合源码理解流程。
import pandas as pd
import os
import lotus
from lotus.models import LMos.environ["OPENAI_API_KEY"] = "skxxx" # 注意安全,不建议在生产代码中明文写 key
lm = LM(model="gpt-4o-mini")lotus.settings.configure(lm=lm)
data = {"Course Name": ["Probability and Random Processes","Optimization Methods in Engineering","Digital Design and Integrated Circuits","Computer Security",]
}
df = pd.DataFrame(data)
# user_instruction = "What is a similar course to {Course Name}. Be concise."
user_instruction = ("What is a core word (only one) in course to {Course Name}? ""Only output the course name, do not include any explanation or extra words."
)
df = df.sem_map(user_instruction)
print(df)这里本质上是对各种算子的熟悉和使用(作者将其扩展到pd): 以map为例就是对原始数据的某种投影 – “投影”就是在每一行上新生成一个(或一组)新值,通常是选取、变换、加工原有数据。
– 具体的sem_map 算子的实现
output = sem_map(multimodal_data,lotus.settings.lm,formatted_usr_instr,postprocessor=postprocessor,examples_multimodal_data=examples_multimodal_data,examples_answers=examples_answers,cot_reasoning=cot_reasoning,strategy=strategy,safe_mode=safe_mode,progress_bar_desc=progress_bar_desc,)
其实就是各种规范大模型 – 使得其能更好的聚合用户的data 和 query
再来看一个稍微复杂的例子:
import lotus
from lotus import WebSearchCorpus, web_search
from lotus.models import LM
import oslm = LM(model="gpt-4o-mini")lotus.settings.configure(lm=lm)df = web_search(WebSearchCorpus.ARXIV, "deep learning", 5)[["title", "abstract"]]
print(f"Results from Arxiv\n{df}\n\n")most_interesting_articles = df.sem_topk("Which {abstract} is most exciting?", K=1)
print(f"Most interesting article: \n{most_interesting_articles.iloc[0]}")[用户输入关键词]|v
[自动调用API/爬虫抓取搜索结果]|v
[整理成结构化数据(DataFrame)]|v
[大模型逐条“读懂”内容,智能打分/排序/筛选]|v
[输出最优推荐结果]
进阶 – 优化操作与论文对应的方法校验 - 以semantic joins为例
一、这段代码整体实现了什么?
主要功能:
高效自动化地实现“语义连接(semantic join)”——即用大模型(和embedding等轻量模型)对两个表格中的内容做“理解型匹配”,找出满足复杂语义条件的配对(比如“哪些论文摘要用到了某个数据集”)。
难点:
直接用大模型做所有配对,成本是二次方(O(n²))的;论文和代码都在优化这个问题:用embedding做“近似”,大模型只处理“难配对”,兼顾召回率和精度目标。
二、代码结构与主要逻辑
- semantic join(
sem_join)和级联优化(sem_join_cascade)
1)sem_join
- 直接对两个Series做所有配对,调用大模型判断是否满足语义条件(最贵,主要用于小数据量或无优化时)。
- 结果包括:配对结果、原始输出、解释等。
2)sem_join_cascade
- 实现了论文所述的“级联语义连接近似算法”。
- 两步走:
- 第一步:用embedding相似度(proxy)做初筛,大部分“明显的”pair直接判定(高置信度正/负);只有“难判定”的pair再扔给大模型(oracle)。
- 第二步:另一种方案是用大模型“投影”左表(map),再做embedding相似度匹配。
- 动态选择哪种proxy方案更省成本,自动学习最优阈值,保证召回率精度目标。
- 关键辅助函数
- run_sem_sim_join
- 用于embedding近似join,计算embedding相似度,校准分数。
- map_l1_to_l2
- 先用大模型把左表“映射/投影”为右表特征,再做embedding相似度join。
- join_optimizer
- 核心优化:实现论文里的“动态选择proxy算法、阈值学习”。
- 对两种proxy(sim-filter和project-sim-filter)分别学习阈值、估算大模型调用成本,自动选择最优方案。
- learn_join_cascade_threshold
-
对proxy分数采样,调用大模型oracle做label,然后学阈值,满足召回率/精度目标。
-
DataFrame accessor (
@pd.api.extensions.register_dataframe_accessor("sem_join")) -
可以直接
df1.sem_join(df2, ...),封装了所有上面逻辑,自动选择是否用级联近似、是否采样、参数配置等。
三、论文优化方案与代码实现的详细对应整理
论文原文(简化):
…我们为语义连接提供了一种近似算法,可以以概率1-δ达到召回γR和精度γP。由于嵌套循环连接的二次成本,我们不用小模型代理,而直接用embedding做proxy。我们设计了两种proxy算法并自动选择更便宜的一种:
- sim-filter:直接embedding相似度做proxy分数。
- project-sim-filter:先用LLM把左表投影成右表特征,再做embedding相似度。
对两种proxy,重要性采样后用oracle打label,分别学正/负阈值,并选成本最低方案。
代码中对应的实现:
| 论文描述 | 对应代码具体位置/函数 | 作用说明 |
|---|---|---|
| embedding做proxy近似(sim-filter) | run_sem_sim_join | 用embedding算sim分数,校准,输出proxy分数表 |
| project-sim-filter(LLM投影后做embedding) | map_l1_to_l2 + run_sem_sim_join | 先用大模型“map”左表,再做embedding join |
| 两种proxy方案都做一遍,分别采样、用LLM oracle学阈值 | join_optimizer | 对两种方案分别采样、用sem_filter打oracle label,分别learn最优阈值 |
| 动态选择成本最优的proxy方案 | join_optimizer | 比较两方案LLM调用量,选更省的那一个 |
| 重要性采样+oracle打label | learn_join_cascade_threshold | 从proxy分数采样一部分pair,用LLM做最终判定,学阈值 |
| 级联join主流程 | sem_join_cascade | 先用proxy分数高置信度pair定性,剩下的pair再全量交给LLM判定 |
| 用户接口+自动判断是否用级联近似 | SemJoinDataframe.__call__ | 自动判断数据量/目标,选择是否用级联近似join |
代码级别标注举例
-
sim-filter(embedding近似)
sf_helper_join = run_sem_sim_join(l1, l2, col1_label, col2_label) -
project-sim-filter(LLM map+embedding近似)
mapped_l1, mapped_col1_label = map_l1_to_l2(l1, col1_label, col2_label, ...) msf_helper_join = run_sem_sim_join(mapped_l1, l2, mapped_col1_label, col2_label) -
采样+oracle打label+阈值学习
sf_t_pos, sf_t_neg, sf_learn_cost = learn_join_cascade_threshold(sf_helper_join, col1_label, col2_label, ...) -
两种方案成本比较,自动选择
if sf_cost < msf_cost:# 选sim-filter方案return sf_high_conf, sf_low_conf, ... else:# 选project-sim-filter方案return msf_high_conf, msf_low_conf, ... -
完整级联join主流程
sem_join_cascade函数和SemJoinDataframe.__call__里相关调用。
四、总结
- 你论文里的“级联近似语义连接”优化算法,已完整体现在
sem_join_cascade和join_optimizer等函数里。 - 两种proxy算法(sim-filter和project-sim-filter)都被实现,并自动选成本最优方案。
- 重要性采样、oracle label、阈值学习、召回/精度控制等核心细节均可在上述函数找到。
- 最终表现为:大部分pair直接embedding判断,只有少量交给LLM,大大节省成本;方案自动选择,阈值自动学习。
推荐学习顺序总结表
| 步骤 | 路径/文件 | 目标/作用 |
|---|---|---|
| 1 | README.md | 了解整体功能和定位 |
| 2 | docs/core_concepts.rst | 掌握核心理念 |
| 3 | docs/sem_*.rst | 熟悉各语义操作符的API和用法 |
| 4 | 配置和主入口(略) | |
| 5 | lotus/models/ | 模型管理与调用 |
| 6 | lotus/sem_ops/ | 语义操作符实现 |
| 7 | lotus/types.py, dtype_extensions/ | 数据类型扩展 |
| 8 | lotus/data_connectors/, file_extractors/ | 数据/文件接入 |
| 9 | lotus/vector_store/ | 向量库对接 |
| 10 | lotus/cache.py, utils.py | 缓存和工具函数 |
| 11 | tests/, examples/ | 测试和动手实践 |
| 进阶 | lotus/sem_ops/ | 推荐配合论文第三部分一起阅读 |
学习建议
- 先从高层API和文档入手,理解整体流程。
- 多结合实际运行和调试,对照源码理解每一步。
- 遇到不懂的函数或类,先查文档再看源码实现,不要一上来就深挖细节。
- 适当画流程图和调用链,帮自己梳理复杂流程。
- 优先理解主流程和数据流,后面再关注优化细节和底层实现。