【Redis】解码Redis中hash类型:理解基础命令,以及内部编码方式和使用场景
📚️前言
🌟🌟🌟精彩读导
本次我们将全面剖析Redis的核心技术要点,包括其丰富的数据类型体系、高效的编码方式以及秒级响应的性能奥秘。对于渴望深入理解Redis底层机制的技术爱好者,这是一次难得的学习机会!
🔍 推荐扩展阅读
想了解更多数据库技术干货?欢迎访问小编的CSDN技术博客: 👉GGBondlctrl-CSDN博客 👈 (持续更新分布式系统、中间件等深度技术文章)
💖 读者互动
您的每一个👍点赞、⭐收藏和✏️评论,都是我们持续输出优质技术内容的强大动力!期待在评论区看到您的见解~


目录
📚️前言
📚️1.hash类型基础认识
📚️2.基础命令
🚀2.1hset & hmset
🚀2.2hget & hmget
🚀2.3hexists
🚀2.4hdel
🚀2.5hkeys
🚀2.6hvals
🚀2.7hgetall
🚀2.8hlen & hstrlen
🚀2.9hsetnx
🚀2.10hincrby & hincrbyfloat
📚️3.hash的编码方式
🚀3.1ziplist 与hashtable
🚀3.2listpack
📚️4. hash类型的使用场景
🚀4.1作为缓存
🚀4.2哈希类型和关系型数据库

📚️1.hash类型基础认识
如图下所示:

在Redis的哈希类型数据结构中,数据存储采用了一种嵌套的键值结构,称为field-value对,这与Redis整体架构中的key-value对需要明确区分。这里的value特指field对应的具体值,而非外层键key对应的值。
这种双层映射结构的具体表现为:
- 第一层是key-value结构,其中key是哈希表在Redis中的唯一标识符
- 第二层是field-value结构,存在于每个哈希表内部
field:相当于哈希表中的字段名
value:该字段对应的具体数据值
📚️2.基础命令
🚀2.1hset & hmset
hset key field value field2 value2这里要具体说明一下,其实这两个关键命令是效果是一样的,没有什么本质的区别;都可以实现设置一个或者多个键值对;
小编的演示如下:

很显然发现,返回就是成功设置的键值对的个数~~~
🚀2.2hget & hmget
hget key field
hmget key field field2 field3即一次获取对应key中field键的值,或者一次获取对饮key中多个field的值
演示如下所示:

🚀2.3hexists
判断hash中是否存在指定的值
hexists key field即获取对应key中键field对应的值value是否是存在的,若不存在就直接返回0,存在就返回1

注意:这里是不支持多个field的查找的,只能一个一个进行判断field对应的值是否是存在的;
🚀2.4hdel
del删除key,hdel删除field,可以指定多个
hdel key field1 field2 field3返回的值就是成功删除的个数;
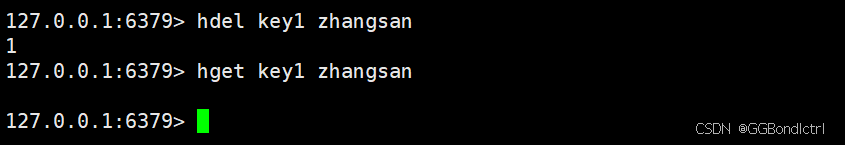
🚀2.5hkeys
获取hash中所有的字段,即所有的field(键)
hkeys key遍历所有的hash,这里的时间复杂度就是O(N);这里的N随着表示不同,对应的值也是不一样的

🚀2.6hvals
获取hash中所有的value;与hkeys相对
hvals key上述获取field或者value,如果此时hash表中内容非常大,那么很有可能会阻塞我们的redis服务器

🚀2.7hgetall
所有的key以及value都会获取得到
hgetall key
🚀2.8hlen & hstrlen
hlen key
hstrlen key field
获取hash的长度,即键值对的个数,演示如下所示:

第二个命令就是获取指定field对应的value的长度,单位是字节

🚀2.9hsetnx
hsetnx key field value
不存在就进行设置,若存在则不进行设置,这里和我们字符串中的setnx是差不多一致的;

🚀2.10hincrby & hincrbyfloat
hincrby可以加减整数
hincrbyfloat:可以加减小数
hincrby key field 10
很明显,这里需要我们的value的值为内部编码一个整型,而不是字符串类型

好啦,关于hash类型的命令大概就是这些,大家可以按照命令,自己尝试尝试~~~
📚️3.hash的编码方式
🚀3.1ziplist 与hashtable
ziplist即压缩列表,这里小编之前已经讲解过了,这里就是为了节省空间,但是代价就是进行读写元素的速度比较慢,如果元素比较少,那么这里的读取速度影响就是不大的
hashtable表示普通的hash表,可能会浪费一定的空间,例如hash是一个数组,数组上有一些位置上是没有元素的,但是这里的读取速度是比较快的
元素个数比较少:ziplist
元素个数比较多:hashtable
注意:每个value的长度都比较短,ziplist,如果某个value的长度太长了,也会转变化为hashtable
配置项:
hash-max -ziplist-entries配置元素个数(默认512个)
hash-max-ziplist-value来进行配置value的阈长度(默认64字节)
位置:cd /etc/redis下的redis.conf文件中

这里为啥进行编码判断的时候,显示的不是上述两种呢???那就是更新后的内部编码了
🚀3.2listpack
定位: Redis 设计的、ziplist 的替代者。
核心设计: 紧凑的连续内存存储。
最大亮点: 解决了 ziplist 的级联更新问题,通过在每个 entry 末尾存储自身长度(backlen)并倒序编码来实现。
- 优点:
- 内存占用小、紧凑。
- 插入/删除操作复杂度稳定(O(1) 或 O(M),局部影响,无连锁反应)。
- 良好的内存局部性(CPU缓存友好)。
ListPack 成功继承了 ziplist 的紧凑空间优势并解决了其级联更新的问题。Redis 巧妙地利用 ListPack 作为小集合的一种极其节省内存的存储格式(牺牲了 O(1) 查找以换取空间),并在数据增长时自动切换到 hashtable 以提供 O(1) 查找性能。
ListPack 的“读取”: ListPack 支持的快速操作是正向或反向的迭代(遍历),得益于其 backlen 的设计(O(1) 跳到下一个或上一个 entry 的起始位置)。但这种迭代是针对顺序访问优化的,不是针对随机查找某个特定元素优化的。
这里说明:listpack是ziplist的优化,但是查找的时间复杂度还是O(N),不是hashtable与ziplist的结合,这里小编前面一篇文章写错了,这里纠正一下
太长的情况下还是:hashtable的编码方式

📚️4. hash类型的使用场景
🚀4.1作为缓存
有以下表:

转化为redis的表示方式:

当然这里string也是可以完成的,但是如果只修改其中一个field,就需要读出整个json解析为对象后,进行修改之后,再次转化为json;
使用string类型进行表示:
优点: 操作简单存储效率 (对于整体存取)。 支持原子操作incr,支持数据过期ttl,灵活性 (存储格式)(json,自定义二进制...)
缺点:本身的序列化和反序列化需要一定开销,同时如果总是操作个别属性则不灵活
而使用hash的方式比较简单了
hash的表示方式
优点:简单。直观,灵活;尤其是在针对信息的局部变更或者获取操作
缺点:需要控制哈希在ziplist和hashtable两种内部编码转化,可能会造成内存的较大消耗
🚀4.2哈希类型和关系型数据库
哈希类型是稀疏的,而关系型数据库就是完全结构化的例如,哈希类型每个键都有不同的field,但是,关系型数据库一旦添加新的列,所有行都要为它设置值,即时为null

关系型数据库可以做复杂的关系查询,redis去模拟关系型复杂查询,会导致维护成本过高,甚至基本不可能
问题:为啥不使用uid作为我们的key,而是重新设置一个key呢?

如果不存其实也是可以的;但是,在代码编写中,一般都会把uid在value中再存一份,后续在编写相关代码来说,使用起来更加方便
🌅🌅🌅~~~~最后希望与诸君共勉,共同进步!!!

💪💪💪以上就是本期内容了, 感兴趣的话,就关注小编吧。
😊😊 期待你的关注~~