Netty ChannelPipeline和ChannelHandler详解
Netty的ChannelPipeline和ChannelHandler机制类似于Servlet和Filter过滤器,这类拦截器实际上是职责链模式的一种变形,主要是为了方便事件的拦截和用户业务逻辑的定制。
ChannelPipeline功能说明
ChannelPipeline是ChannelHandler的容器,它负责ChannelHandler的管理和事件拦截与调度。
ChannelPipeline的事件处理
一个消息被ChannelPipeline的ChannelHandler链拦截和处理的全过程:
- 底层的
SocketChannelRead()方法读取ByteBuf,触发ChannelRead事件,由I/O线程NioEventLoop调用ChannelPipeline的fireChannelRead(Object msg)方法,将消息(ByteBuf)传输到ChannelPipeline中。 - 消息依次被
HeadHandler、ChannelHandlerl、ChannelHandler2.….TailHandler拦截和处理,在这个过程中,任何ChannelHandler都可以中断当前的流程,结束消息的传递。 - 调用
ChannelHandlerContext的write方法发送消息,消息从TailHandler开始,途经ChannelHandlerN,…,ChannelHandlerl、HeadHandler,最终被添加到消息发送缓冲区中等待刷新和发送,在此过程中也可以中断消息的传递,例如当编码失败时,就需要中断流程,构造异常的Future返回。

Netty中的事件分为inbound事件和outbound事件。inbound事件通常由I/O线程触发,例如TCP链路建立事件、链路关闭事件、读事件、异常通知事件等,它对应上图的左半部分。
触发inbound事件的方法如下:
ChannelHandlerContext.fireChannelRegistered():Channel注册事件;ChannelHandlerContext.fireChannelActive():TCP链路建立成功,Channel激活事件;ChannelHandlerContext.fireChannelRead(Object):读事件;ChannelHandlerContext.fireChannelReadComplete():读操作完成通知事件;ChannelHandlerContext.fireExceptionCaught(Throwable):异常通知事件;ChannelHandlerContext.fireUserEventTriggered(Object):用户自定义事件;ChannelHandlerContext.fireChannelWritabilityChanged():Channel的可写状态变化通知事件:ChannelHandlerContext.fireChannellnactive():TCP连接关闭,链路不可用通知事件。
Outbound事件通常是由用户主动发起的网络I/O操作,例如用户发起的连接操作、绑定操作、消息发送等操作,它对应图的右半部分。
触发outbound事件的方法如下:
ChannelHandlerContext.bind(SocketAddress,ChannelPromise):绑定本地地址事件;ChannelHandlerContext.connect(SocketAddress,SocketAddress,ChannelPromise):连接服务端事件;ChannelHandlerContext.write(Object,ChannelPromise):发送事件;ChannelHandlerContext.flush():刷新事件;ChannelHandlerContext.read():读事件;ChannelHandlerContext.disconnect(ChannelPromise):断开连接事件:ChannelHandlerContext.close(ChannelPromise):关闭当前Channel事件。
自定义拦截器
ChannelPipeline通过ChannelHandler接口来实现事件的拦截和处理,由于ChannelHandler中的事件种类繁多,不同的ChannelHandler可能只需要关心其中的某一个或者几个事件,所以,通常ChannelHandler只需要继承ChannelHandlerAdapter类覆盖自已关心的方法即可。
事实上,用户不需要自己创建pipeline,因为使用ServerBootstrap或者Bootstrap启动服务端或者客户端时,Netty会为每个Channel连接创建一个独立的pipeline。对于使用者而言,只需要将自定义的拦截器加入到pipeline中即可。
ChannelPipeline源码分析
ChannelPipeline的代码相对比较简单,它实际上是一个ChannelHandler的容器,内部维护了一个ChannelHandler的链表和迭代器,可以方便地实现ChannelHandler查找、添加、替换和删除。
ChannelPipeline的类继承关系图:
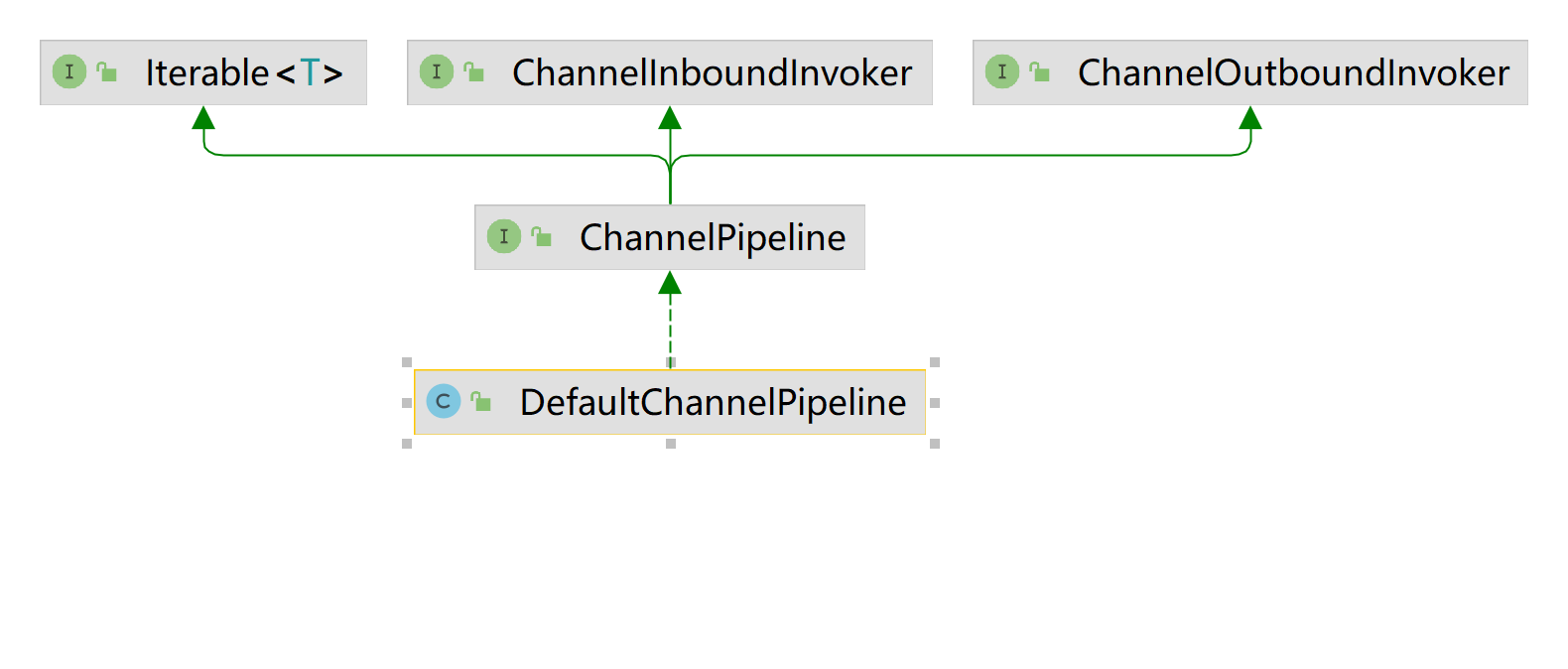
通过ChannelInboundInvoker和ChannelOutboundInvoker 接口定义inbound和outbound 事件。
public interface ChannelInboundInvoker {ChannelInboundInvoker fireChannelRegistered();ChannelInboundInvoker fireChannelUnregistered();ChannelInboundInvoker fireChannelActive();ChannelInboundInvoker fireChannelInactive();ChannelInboundInvoker fireExceptionCaught(Throwable cause);ChannelInboundInvoker fireUserEventTriggered(Object event);ChannelInboundInvoker fireChannelRead(Object msg);ChannelInboundInvoker fireChannelReadComplete();ChannelInboundInvoker fireChannelWritabilityChanged();
}
public interface ChannelOutboundInvoker {ChannelFuture bind(SocketAddress localAddress);ChannelFuture connect(SocketAddress remoteAddress);ChannelFuture connect(SocketAddress remoteAddress, SocketAddress localAddress);ChannelFuture disconnect();ChannelFuture close();ChannelFuture deregister();ChannelFuture bind(SocketAddress localAddress, ChannelPromise promise);ChannelFuture connect(SocketAddress remoteAddress, ChannelPromise promise);ChannelFuture connect(SocketAddress remoteAddress, SocketAddress localAddress, ChannelPromise promise);ChannelFuture disconnect(ChannelPromise promise);ChannelFuture close(ChannelPromise promise);ChannelFuture deregister(ChannelPromise promise);ChannelOutboundInvoker read();ChannelFuture write(Object msg);ChannelFuture write(Object msg, ChannelPromise promise);ChannelOutboundInvoker flush();ChannelFuture writeAndFlush(Object msg, ChannelPromise promise);ChannelFuture writeAndFlush(Object msg);ChannelPromise newPromise();ChannelProgressivePromise newProgressivePromise();ChannelFuture newSucceededFuture();ChannelFuture newFailedFuture(Throwable cause);ChannelPromise voidPromise();
}ChannelPipeline 继承ChannelInboundInvoker、ChannelOutboundInvoker、Iterable,扩展了一些能力:
public interface ChannelPipelineextends ChannelInboundInvoker, ChannelOutboundInvoker, Iterable<Entry<String, ChannelHandler>> {//容器操作ChannelPipeline addFirst(String name, ChannelHandler handler);ChannelPipeline addFirst(EventExecutorGroup group, String name, ChannelHandler handler);ChannelPipeline addLast(String name, ChannelHandler handler);ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler);ChannelPipeline addBefore(String baseName, String name, ChannelHandler handler);ChannelPipeline addBefore(EventExecutorGroup group, String baseName, String name, ChannelHandler handler);ChannelPipeline addAfter(String baseName, String name, ChannelHandler handler);ChannelPipeline addAfter(EventExecutorGroup group, String baseName, String name, ChannelHandler handler);ChannelPipeline addFirst(ChannelHandler... handlers);ChannelPipeline addFirst(EventExecutorGroup group, ChannelHandler... handlers);ChannelPipeline addLast(ChannelHandler... handlers);ChannelPipeline addLast(EventExecutorGroup group, ChannelHandler... handlers);ChannelPipeline remove(ChannelHandler handler);ChannelHandler remove(String name);<T extends ChannelHandler> T remove(Class<T> handlerType);ChannelHandler removeFirst();ChannelHandler removeLast();ChannelPipeline replace(ChannelHandler oldHandler, String newName, ChannelHandler newHandler);ChannelHandler replace(String oldName, String newName, ChannelHandler newHandler);<T extends ChannelHandler> T replace(Class<T> oldHandlerType, String newName,ChannelHandler newHandler);ChannelHandler first();ChannelHandlerContext firstContext();ChannelHandler last();ChannelHandlerContext lastContext();ChannelHandler get(String name);<T extends ChannelHandler> T get(Class<T> handlerType);ChannelHandlerContext context(ChannelHandler handler);ChannelHandlerContext context(String name);ChannelHandlerContext context(Class<? extends ChannelHandler> handlerType);Channel channel();List<String> names();Map<String, ChannelHandler> toMap();//下面的是 inbound 和outbound 事件,返回的是ChannelPipeline,覆盖父接口。@OverrideChannelPipeline fireChannelRegistered();@OverrideChannelPipeline fireChannelUnregistered();@OverrideChannelPipeline fireChannelActive();@OverrideChannelPipeline fireChannelInactive();@OverrideChannelPipeline fireExceptionCaught(Throwable cause);@OverrideChannelPipeline fireUserEventTriggered(Object event);@OverrideChannelPipeline fireChannelRead(Object msg);@OverrideChannelPipeline fireChannelReadComplete();@OverrideChannelPipeline fireChannelWritabilityChanged();@OverrideChannelPipeline flush();
}
DefaultChannelPipeline
字段
//代表 ChannelPipeline 的头部上下文,是 HeadContext 类型的实例。HeadContext 实现了 ChannelOutboundHandler 和 ChannelInboundHandler 接口,主要负责处理出站操作和传播入站事件。final AbstractChannelHandlerContext head;
//代表 ChannelPipeline 的尾部上下文,是 TailContext 类型的实例。TailContext 实现了 ChannelInboundHandler 接口,用于处理未被其他处理器处理的入站事件。final AbstractChannelHandlerContext tail;
//关联的 Channel 对象,DefaultChannelPipeline 与该 Channel 绑定,处理该 Channel 的事件和操作。private final Channel channel;
//表示一个已经成功完成的 ChannelFuture 对象,用于在需要返回成功结果的场景中复用。private final ChannelFuture succeededFuture;
//一个 VoidChannelPromise 对象,用于表示不需要返回结果的异步操作的承诺。private final VoidChannelPromise voidPromise;
//一个布尔标志,通过 ResourceLeakDetector.isEnabled() 方法获取当前资源泄漏检测功能是否启用的状态。该标志用于在操作数据时决定是否进行资源泄漏检测。private final boolean touch = ResourceLeakDetector.isEnabled();
//一个映射,用于存储 EventExecutorGroup 与其对应的 EventExecutor 实例。其作用是为每个 EventExecutorGroup 固定一个 EventExecutor,确保同一 Channel 的事件由同一个 EventExecutor 处理。private Map<EventExecutorGroup, EventExecutor> childExecutors;
//:MessageSizeEstimator.Handle 类型的句柄,用于估计消息的大小private volatile MessageSizeEstimator.Handle estimatorHandle;
//一个布尔标志,初始值为 true,表示 Channel 首次注册。当 Channel 完成首次注册后,该标志会被设置为 false,且之后不会再改变。private boolean firstRegistration = true;
// PendingHandlerCallback 链表的头节点。在 Channel 未注册时添加的处理器,其 handlerAdded 或 handlerRemoved 回调会被添加到该链表中,待 Channel 注册完成后通过 callHandlerAddedForAllHandlers() 方法统一处理。private PendingHandlerCallback pendingHandlerCallbackHead;//一个布尔标志,用于表示 Channel 是否已经注册到 EventLoop 上。一旦 Channel 注册成功,该标志会被设置为 true,且之后不会再改变。private boolean registered;
这些成员变量共同维护了 DefaultChannelPipeline 的状态和行为,包括管道的结构、关联的通道、资源管理、事件处理以及处理器回调等方面。
ChannelHandlerContext
ChannelHandlerContext 是一个核心组件,它充当 ChannelHandler(处理器)与 ChannelPipeline(管道)之间的上下文桥梁,负责在 Pipeline 中协调数据流、事件传播和 Handler 之间的交互。
ChannelHandlerContext的类继承关系图如下:

ChannelHandlerContext接口继承ChannelInboundInvoker、ChannelOutboundInvoker接口,并扩展了几个方法。
public interface ChannelHandlerContext extends AttributeMap, ChannelInboundInvoker, ChannelOutboundInvoker {//返回与当前 ChannelHandlerContext 绑定的 Channel 对象Channel channel();//返回用于执行任意任务的 EventExecutor 对象EventExecutor executor();//返回 ChannelHandlerContext 的唯一名称。该名称是在 ChannelHandler 被添加到 ChannelPipeline 时指定的String name();//返回与当前 ChannelHandlerContext 绑定的 ChannelHandler 对象。ChannelHandler 负责处理入站和出站事件。ChannelHandler handler();//如果与当前 ChannelHandlerContext 关联的 ChannelHandler 已从 ChannelPipeline 中移除,则返回 true,否则返回 false。需要注意,该方法仅应在 EventLoop 内部调用。boolean isRemoved();}
AbstractChannelHandlerContext
abstract class AbstractChannelHandlerContext implements ChannelHandlerContext, ResourceLeakHint {volatile AbstractChannelHandlerContext next;volatile AbstractChannelHandlerContext prev;private final DefaultChannelPipeline pipeline;private final String name;private final boolean ordered;private final int executionMask;final EventExecutor executor;private ChannelFuture succeededFuture;private Tasks invokeTasks;private volatile int handlerState = INIT;@Overridepublic EventExecutor executor() {if (executor == null) {return channel().eventLoop();} else {return executor;}}//实例方法@Overridepublic ChannelHandlerContext fireChannelActive() {//查找ACTIVEinvokeChannelActive(findContextInbound(MASK_CHANNEL_ACTIVE));return this;}//静态方法。static void invokeChannelActive(final AbstractChannelHandlerContext next) {EventExecutor executor = next.executor();if (executor.inEventLoop()) {next.invokeChannelActive();} else {executor.execute(new Runnable() {@Overridepublic void run() {next.invokeChannelActive();}});}}
//找到第一个private AbstractChannelHandlerContext findContextInbound(int mask) {AbstractChannelHandlerContext ctx = this;EventExecutor currentExecutor = executor();do {ctx = ctx.next;} while (skipContext(ctx, currentExecutor, mask, MASK_ONLY_INBOUND));return ctx;}
}
DefaultChannelHandlerContext
final class DefaultChannelHandlerContext extends AbstractChannelHandlerContext {private final ChannelHandler handler;DefaultChannelHandlerContext(DefaultChannelPipeline pipeline, EventExecutor executor, String name, ChannelHandler handler) {super(pipeline, executor, name, handler.getClass());this.handler = handler;}@Overridepublic ChannelHandler handler() {return handler;}
}
TailContext、HeadContext
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {}
final class HeadContext extends AbstractChannelHandlerContextimplements ChannelOutboundHandler, ChannelInboundHandler {private final Unsafe unsafe;
}
为什么 TailContext 不继承 ChannelOutboundHandler?
TailContext的定位是 “兜底处理器”,专注于处理入站事件的“未消费”情况(如异常、消息丢弃)。- 出站操作(如写数据、连接关闭)的发起和执行应由 Pipeline 的头部(
HeadContext)统一管理,避免职责分散。 - 出站操作(Outbound) 的发起方向是从 Pipeline 的尾部向头部传播(例如
channel.write()从 Tail 开始,但实际由 Head 执行)。 TailContext本身不执行出站操作,而是通过调用ctx.write()将操作反向传播到 Pipeline 的头部(HeadContext),由HeadContext调用底层传输层完成操作。- 如果
TailContext也继承ChannelOutboundHandler,会导致出站操作在 Tail 和 Head 之间重复处理,破坏 Netty 的分层设计。
总结:
在 Netty 的架构设计中,所有实际的 I/O 操作(如读字节、写字节、连接建立/关闭等)最终都是由
HeadContext调用底层传输层(如SocketChannel)完成的。TailContext仅负责处理入站事件的“未消费”情况(如异常、消息丢弃),不参与任何实际的 I/O 操作。
ChannelPipeline的inbound事件
当发生某个1/O事件的时候,例如链路建立、链路关闭、读取操作完成等,都会产生一个事件,事件在pipeline中得到传播和处理,它是事件处理的总入口。由于网络I/O相关的事件有限,因此Netty对这些事件进行了统一抽象,Netty自身和用户的ChannelHandler会对感兴趣的事件进行拦截和处理。
pipeline中以fireXXX命名的方法都是从I/O线程流向用户业务Handler的inbound事件,它们的实现因功能而异,但是处理步骤类似,总结如下。
(1)调用HeadHandler对应的fireXXX方法;
(2)执行事件相关的逻辑操作。
ChannelPipeline的outbound事件
由用户线程或者代码发起的I/O操作被称为outbound事件,事实上inbound和outbound是Netty自身根据事件在pipeline中的流向抽象出来的术语,在其他NIO框架中并没有这个概念。
ChannelHandlerContext 在 ChannelHandler 和 ChannelPipeline 中的衔接机制
ChannelHandlerContext 是 Netty 中连接 ChannelHandler 与 ChannelPipeline 的核心桥梁,负责事件传递、Handler 管理和上下文交互。其工作原理可从以下方面详细解析:
一、创建过程
-
Pipeline 初始化时绑定 Handler
当通过pipeline.addLast(handler)添加 Handler 时,Netty 会:-
创建一个
DefaultChannelHandlerContext实例,关联该 Handler -
将
Context插入到Pipeline的双向链表中(按添加顺序形成链表结构)
-
-
Context 创建时的关键操作
-
绑定所属的
Channel和EventLoop -
记录 Handler 的类型(
Inbound/Outbound) -
在 Pipeline 中维护前后节点的引用(形成双向链表)
-
二、消息流转机制
-
Inbound事件(上行事件)流转
当 I/O 线程产生事件时(如channelRead):-
从
Pipeline头部开始遍历Context链 -
找到支持该事件的第一个
InboundHandler -
调用其相应方法(如
channelRead) -
通过
Context将事件传递给下一个 Handler
-
-
Outbound事件(下行事件)流转
当应用调用 write 等操作时:-
从 Pipeline 尾部开始反向遍历
Context链 -
找到支持该事件的第一个
OutboundHandler -
调用其相应方法(如 write)
-
通过 Context 将事件传递给前一个 Handler
-
-
事件传递的关键方法
-
fireChannelRead():触发下一个 InboundHandler 的 channelRead -
write():触发下一个 OutboundHandler 的 write -
ctx.pipeline().fireXXX():从当前 Context 开始重新触发事件
-
[EventLoop线程]│▼
[HeadContext] (绑定 HeadHandler 内部类)│▼ (调用 fireChannelRead())
[Context1: ByteToMessageDecoder] (绑定 DecoderHandler)│ → 实际调用: decoderHandler.channelRead(ctx, msg)▼ (调用 fireChannelRead())
[Context2: BusinessHandler] (绑定 BusinessHandler)│ → 实际调用: businessHandler.channelRead(ctx, msg)▼ (调用 write())
[Context3: MessageToByteEncoder] (绑定 EncoderHandler)│ → 实际调用: encoderHandler.write(ctx, msg, promise)▼ (调用 write())
[TailContext] (绑定 TailHandler 内部类)│▼ (调用 Channel 的 I/O 方法)
ChannelHandler功能说明
ChannelHandler类似于Servlet的Filter过滤器,负责对I/O事件或者1/O操作进行拦截和处理,它可以选择性地拦截和处理自已感兴趣的事件,也可以透传和终止事件的传递。
基于ChannelHandler接口,用户可以方便地进行业务逻辑定制,例如打印日志、统一封装异常信息、性能统计和消息编解码等。
ChannelHandler支持注解,目前支持的注解有两种。
Sharable:多个ChannelPipeline共用同一个ChannelHandler;Skip:被Skip注解的方法不会被调用,直接被忽略。
ChannelHandlerAdapter
Netty提供了ChannelHandlerAdapter基类,它的所有接口实现都是事件透传,如果用户ChannelHandler关心某个事件,只需要覆盖ChannelHandlerAdapter对应的方法即可,对于不关心的,可以直接继承使用父类的方法,这样子类的代码就会非常简洁和清晰。
类继承图

-
ChannelOutboundHandlerAdapter
出站处理器适配器,拦截或自定义 Channel 写出操作(如数据发送、连接关闭等)。 -
ChannelInboundHandlerAdapter
入站处理器适配器,拦截或自定义 Channel 读取、连接事件(如数据接收、连接建立)。 -
MessageToMessageDecoder
将一种消息类型解码为另一种(如对象转换),用于业务层协议转换。 -
ByteToMessageDecoder
将字节流解码为消息对象,处理 TCP 粘包/拆包(需继承实现decode()方法)。 -
MessageToByteEncoder
将消息对象编码为字节流,用于网络传输前的数据转换(如对象序列化)。 -
MessageToMessageEncoder
将一种消息类型编码为另一种(如协议转换),适用于不同消息格式间的转换。 -
StringDecoder
将 ByteBuf 解码为字符串(默认 UTF-8),用于文本协议解析(如 HTTP、Redis)。 -
StringEncoder
将字符串编码为 ByteBuf(默认 UTF-8),将文本数据转换为字节流发送到网络。 -
FixedLengthFrameDecoder
按固定长度拆分 ByteBuf,解决粘包问题(适用于定长协议,如每帧 1024 字节)。 -
LengthFieldBasedFrameDecoder
根据长度字段动态拆分 ByteBuf,支持变长协议(如 Dubbo、gRPC 的头部长度字段)。 -
DelimiterBasedFrameDecoder
按分隔符(如\n)拆分 ByteBuf,适用于文本协议(如 Redis、HTTP 行协议)。
源码分析
MessageToByteEncoder
是个抽象类,主要是写POJO到byte,由子类实现decode方法,把字节写入到ByteBuf
/*** 重写父类的 write 方法,用于处理出站消息的编码和写入操作。* 该方法会检查消息是否可以被当前编码器处理,如果可以则进行编码,否则将消息传递给下一个处理器。* * @param ctx 当前编码器所属的 ChannelHandlerContext* @param msg 待处理的出站消息* @param promise 用于异步操作的 ChannelPromise* @throws Exception 编码过程中可能抛出的异常*/@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {// 用于存储编码后的字节缓冲区,初始化为 nullByteBuf buf = null;try {// 检查当前消息是否可以被当前编码器处理if (acceptOutboundMessage(msg)) {// 将消息强制转换为泛型类型 I@SuppressWarnings("unchecked")I cast = (I) msg;// 分配一个字节缓冲区用于存储编码后的消息buf = allocateBuffer(ctx, cast, preferDirect);try {// 调用抽象方法 encode 对消息进行编码,将结果写入 buf 中encode(ctx, cast, buf);} finally {// 释放原始消息的引用计数,防止内存泄漏ReferenceCountUtil.release(cast);}// 检查编码后的缓冲区是否有可读数据if (buf.isReadable()) {// 如果有可读数据,将缓冲区写入 ChannelPipeline 中,并传递 promisectx.write(buf, promise);} else {// 如果没有可读数据,释放缓冲区buf.release();// 写入一个空的字节缓冲区,并传递 promisectx.write(Unpooled.EMPTY_BUFFER, promise);}// 将 buf 置为 null,避免后续重复释放buf = null;} else {// 如果消息不能被当前编码器处理,将消息传递给下一个 ChannelOutboundHandlerctx.write(msg, promise);}} catch (EncoderException e) {// 如果捕获到 EncoderException,直接抛出throw e;} catch (Throwable e) {// 如果捕获到其他异常,将其包装为 EncoderException 后抛出throw new EncoderException(e);} finally {// 确保在异常情况下也能释放缓冲区,防止内存泄漏if (buf != null) {buf.release();}}}protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
MessageToMessageEncoder
是个抽象类,主要是POJO转换,由子类实现decode方法,把转换后的对象写入到CodecOutputList
@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {CodecOutputList out = null;try {if (acceptOutboundMessage(msg)) {out = CodecOutputList.newInstance();@SuppressWarnings("unchecked")I cast = (I) msg;try {encode(ctx, cast, out);} finally {ReferenceCountUtil.release(cast);}if (out.isEmpty()) {throw new EncoderException(StringUtil.simpleClassName(this) + " must produce at least one message.");}} else {ctx.write(msg, promise);}} catch (EncoderException e) {throw e;} catch (Throwable t) {throw new EncoderException(t);} finally {if (out != null) {try {final int sizeMinusOne = out.size() - 1;if (sizeMinusOne == 0) {ctx.write(out.getUnsafe(0), promise);} else if (sizeMinusOne > 0) {// Check if we can use a voidPromise for our extra writes to reduce GC-Pressure// See https://github.com/netty/netty/issues/2525if (promise == ctx.voidPromise()) {writeVoidPromise(ctx, out);} else {writePromiseCombiner(ctx, out, promise);}}} finally {out.recycle();}}}}
CodecOutputList 是 Netty 内部用于高效存储解码结果的容器类,*核心设计目标是优化高频、小数据量的解码场景*(如 TCP 粘包拆包时的消息分段处理)
ByteToMessageDecoder
/*** 处理接收到的入站消息。如果消息是 ByteBuf 类型,则进行累积和解码操作;* 否则,将消息传递给下一个 ChannelInboundHandler。* * @param ctx 当前处理器所属的 ChannelHandlerContext* @param msg 接收到的入站消息* @throws Exception 处理过程中可能抛出的异常*/@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {// 检查接收到的消息是否为 ByteBuf 类型if (msg instanceof ByteBuf) {// 创建一个新的 CodecOutputList 实例,用于存储解码后的消息CodecOutputList out = CodecOutputList.newInstance();try {// 判断是否为第一次累积,即累积缓冲区是否为空first = cumulation == null;// 使用累积器(Cumulator)将新的 ByteBuf 累积到已有的累积缓冲区中// 如果是第一次累积,则使用空的 ByteBuf 作为初始累积缓冲区cumulation = cumulator.cumulate(ctx.alloc(),first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);// 调用 callDecode 方法进行解码操作,将解码后的消息添加到 out 列表中callDecode(ctx, cumulation, out);} catch (DecoderException e) {// 若捕获到 DecoderException,直接抛出throw e;} catch (Exception e) {// 若捕获到其他异常,将其包装为 DecoderException 后抛出throw new DecoderException(e);} finally {try {// 检查累积缓冲区是否不为空且没有可读字节if (cumulation != null && !cumulation.isReadable()) {// 重置读取次数numReads = 0;// 释放累积缓冲区的资源cumulation.release();// 将累积缓冲区置为 nullcumulation = null;} else if (++numReads >= discardAfterReads) {// 若读取次数达到设定的阈值,尝试丢弃一些已读字节,避免内存溢出// 参考:https://github.com/netty/netty/issues/4275numReads = 0;// 调用 discardSomeReadBytes 方法丢弃部分已读字节discardSomeReadBytes();}// 获取解码后消息列表的大小int size = out.size();// 标记是否有新的消息插入到 out 列表中firedChannelRead |= out.insertSinceRecycled();// 将解码后的消息传递给下一个 ChannelInboundHandlerfireChannelRead(ctx, out, size);} finally {// 回收 CodecOutputList 实例out.recycle();}}} else {// 若消息不是 ByteBuf 类型,将消息传递给下一个 ChannelInboundHandlerctx.fireChannelRead(msg);}}/*** 当一个读取操作完成时,此方法会被调用。它主要负责重置读取计数、丢弃已读字节、* 根据条件触发新的读取操作,并将读取完成事件传播到下一个处理器。* * @param ctx 当前处理器所属的 ChannelHandlerContext* @throws Exception 操作过程中可能抛出的异常*/@Overridepublic void channelReadComplete(ChannelHandlerContext ctx) throws Exception {// 重置读取计数为 0,以便下一次读取操作重新计数numReads = 0;// 尝试丢弃累积缓冲区中已读的字节,释放内存空间discardSomeReadBytes();// 检查是否没有触发过 channelRead 事件,并且当前 Channel 的自动读取功能已关闭if (!firedChannelRead && !ctx.channel().config().isAutoRead()) {// 如果满足条件,则手动触发一次读取操作,以获取更多数据ctx.read();}// 将 firedChannelRead 标志重置为 false,表示下一次读取操作还未触发 channelRead 事件firedChannelRead = false;// 将读取完成事件传播到 ChannelPipeline 中的下一个 ChannelInboundHandlerctx.fireChannelReadComplete();}/*** 持续调用解码方法,直到输入的 ByteBuf 没有可读字节,或者满足特定的退出条件。* 该方法会在每次解码后检查处理器是否被移除,并将解码后的消息传递到 ChannelPipeline 中。* * @param ctx 当前解码器所属的 ChannelHandlerContext* @param in 包含待解码数据的 ByteBuf* @param out 用于存储解码后消息的列表*/protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {try {// 当输入的 ByteBuf 还有可读字节时,持续进行解码操作while (in.isReadable()) {// 记录解码前输出列表的大小int outSize = out.size();// 如果输出列表中有解码后的消息if (outSize > 0) {// 将解码后的消息传递到 ChannelPipeline 中的下一个处理器fireChannelRead(ctx, out, outSize);// 清空输出列表,准备下一次解码out.clear();// 检查当前处理器是否已从 ChannelPipeline 中移除// 如果已移除,继续操作缓冲区可能不安全,因此跳出循环// 参考:https://github.com/netty/netty/issues/4635if (ctx.isRemoved()) {break;}// 重置输出列表大小为 0outSize = 0;}// 记录解码前输入 ByteBuf 的可读字节数int oldInputLength = in.readableBytes();// 调用带有移除重入保护的解码方法进行解码decodeRemovalReentryProtection(ctx, in, out);// 再次检查当前处理器是否已从 ChannelPipeline 中移除// 如果已移除,继续操作缓冲区可能不安全,因此跳出循环// 参考:https://github.com/netty/netty/issues/1664if (ctx.isRemoved()) {break;}// 如果解码前后输出列表的大小没有变化if (outSize == out.size()) {// 若解码前后输入 ByteBuf 的可读字节数也没有变化,说明没有进行解码操作,跳出循环if (oldInputLength == in.readableBytes()) {break;} else {// 若可读字节数有变化,继续下一次解码循环continue;}}// 如果解码前后输入 ByteBuf 的可读字节数没有变化,但却解码出了消息,抛出异常if (oldInputLength == in.readableBytes()) {throw new DecoderException(StringUtil.simpleClassName(getClass()) +".decode() did not read anything but decoded a message.");}// 如果设置了单次解码模式,解码一次后就跳出循环if (isSingleDecode()) {break;}}} catch (DecoderException e) {// 若捕获到 DecoderException,直接抛出throw e;} catch (Exception cause) {// 若捕获到其他异常,将其包装为 DecoderException 后抛出throw new DecoderException(cause);}}public static final Cumulator MERGE_CUMULATOR = new Cumulator() {@Overridepublic ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {if (!cumulation.isReadable() && in.isContiguous()) {// If cumulation is empty and input buffer is contiguous, use it directlycumulation.release();return in;}try {final int required = in.readableBytes();// 检查容量是否足够if (required > cumulation.maxWritableBytes() ||(required > cumulation.maxFastWritableBytes() && cumulation.refCnt() > 1) ||cumulation.isReadOnly()) {// Expand cumulation (by replacing it) under the following conditions:// - cumulation cannot be resized to accommodate the additional data// - cumulation can be expanded with a reallocation operation to accommodate but the buffer is// assumed to be shared (e.g. refCnt() > 1) and the reallocation may not be safe.return expandCumulation(alloc, cumulation, in);}//写入数据cumulation.writeBytes(in, in.readerIndex(), required);in.readerIndex(in.writerIndex());return cumulation;} finally {//释放原来的数据in.release();}}};
设计理念
ByteToMessageDecoder 是 Netty 中用于将字节流解码为消息对象的核心抽象类,其设计目标是高效处理 TCP 粘包/拆包问题,同时兼顾性能与灵活性。以下是其核心设计理念:
1. 解决 TCP 粘包/拆包的核心机制
TCP 是面向字节流的协议,发送方写入的数据可能被合并为一个或多个 TCP 段到达接收方,导致粘包(多次发送的数据被合并读取)或拆包(一次发送的数据被拆分为多次读取)。ByteToMessageDecoder 通过以下方式解决:
- 累积字节缓冲区(Cumulation):
继承自ByteToMessageDecoder的解码器会维护一个内部的ByteBuf(称为cumulation),持续累积未处理完的字节,直到满足解码条件(如足够长度、特定分隔符等)。 - 解码时机控制:
在channelRead方法中,解码器会将新读取的ByteBuf合并到cumulation,但不会立即解码,而是等待后续调用(如下一次channelRead或channelIdle),确保有足够数据可供解码。
2. 解码逻辑的抽象与扩展
通过抽象方法 decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out),将解码过程交给子类实现,提供极强的灵活性:
- 子类定制解码规则:
子类(如FixedLengthFrameDecoder、LengthFieldBasedFrameDecoder)需实现decode()方法,定义如何从ByteBuf中提取完整消息(如按固定长度、长度字段、分隔符等)。 - 支持多消息解码:
decode()方法可多次调用(每次channelRead触发时),每次解码出 0 或多个消息,解码出的消息会被添加到List<Object> out中,最终由 Netty 统一传递给下一个 Handler。
3. 内存与性能优化设计
-
避免字节拷贝:
直接操作
ByteBuf的引用,不复制字节数据,减少内存开销(如slice()、duplicate()等零拷贝技术)。 -
动态缓冲区管理:
cumulation缓冲区会根据需要动态扩容(类似ArrayList),但通过预分配初始容量(默认 256 字节)和智能合并策略(如consolidateIfNeeded())减少扩容次数。 -
减少事件触发次数:
解码出的多个消息会被批量提交到out列表,最终通过一次fireChannelRead()事件传递给下游 Handler,避免频繁触发事件导致的上下文切换开销。
4. 状态管理与安全性
- 解码状态机支持:
复杂解码协议(如自定义二进制协议)可能需要维护状态(如“已读取头部”“等待数据体”)。ByteToMessageDecoder允许子类通过成员变量记录状态,并在多次decode()调用间保持状态一致性。 - 内存泄漏防护:
内置ReferenceCountUtil.release()机制,若解码过程中未正确释放ByteBuf引用,Netty 会抛出LeakDetectionException,帮助开发者定位问题。
5. 与 Netty 架构的深度集成
- 与 EventLoop 协作:
解码过程在 Netty 的 EventLoop 线程中执行,确保线程安全,避免多线程竞争cumulation缓冲区。 - 与 Pipeline 协同:
解码后的消息通过fireChannelRead()传递给下一个 Handler,形成完整的 Pipeline 处理链(如解码 → 业务逻辑 → 编码 → 发送)。
MessageToMessageDecoder
没有什么特殊操作,就是进行类型处理。
@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {CodecOutputList out = CodecOutputList.newInstance();try {if (acceptInboundMessage(msg)) {@SuppressWarnings("unchecked")I cast = (I) msg;try {decode(ctx, cast, out);} finally {ReferenceCountUtil.release(cast);}} else {out.add(msg);}} catch (DecoderException e) {throw e;} catch (Exception e) {throw new DecoderException(e);} finally {try {int size = out.size();for (int i = 0; i < size; i++) {ctx.fireChannelRead(out.getUnsafe(i));}} finally {out.recycle();}}}StringEncoder
@Overrideprotected void encode(ChannelHandlerContext ctx, CharSequence msg, List<Object> out) throws Exception {if (msg.length() == 0) {return;}out.add(ByteBufUtil.encodeString(ctx.alloc(), CharBuffer.wrap(msg), charset));}
StringDecoder
@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception {out.add(msg.toString(charset));}
FixedLengthFrameDecoder
@Overrideprotected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {Object decoded = decode(ctx, in);if (decoded != null) {out.add(decoded);}}protected Object decode(@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {if (in.readableBytes() < frameLength) {return null;} else {return in.readRetainedSlice(frameLength);}}
LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder 是 Netty 中用于基于长度字段解码变长消息的核心解码器,适用于复杂协议(如 Dubbo、gRPC)。其实现原理可拆解为以下关键模块:
核心设计目标
- 解决 TCP 粘包/拆包:通过消息头中的长度字段定位消息边界。
- 支持变长消息:消息体长度可动态变化(如 HTTP Body、Protobuf 数据)。
- 高性能解析:减少内存拷贝,高效处理字节流。
关键参数解析
构造函数通常包含以下参数:
| 参数 | 作用 | 典型值 |
|---|---|---|
maxFrameLength | 单帧最大长度 | 1MB(防止内存溢出) |
lengthFieldOffset | 长度字段在消息头中的偏移量 | 如 0(紧邻消息头起始位置) |
lengthFieldLength | 长度字段的字节长度 | 4(int)、8(long) |
lengthAdjustment | 长度字段值与实际消息长度的补偿值 | 如 frameLength - lengthFieldLength - 额外头部长度 |
initialBytesToStrip | 解码后跳过的字节数(通常跳过长度字段) | 如 4(跳过长度字段本身) |
消息结构模型
假设协议格式如下(示例):
+--------+--------+--------+--------+--------+
| 长度字段(4B) | 额外头部(2B) | 实际消息体(NB) |
+--------+--------+--------+--------+--------+
- 长度字段值:存储
实际消息体长度(如N)。 - 补偿值计算:
lengthAdjustment = -(lengthFieldLength + 额外头部长度)
(若长度字段后紧跟 2B 额外头部,则lengthAdjustment = -6)
核心解码流程
步骤 1:读取长度字段
- 从
cumulation缓冲区中读取lengthFieldOffset指定位置开始的lengthFieldLength字节,解析为整型frameLength(如int或long)。 - 边界检查:
- 若
frameLength > maxFrameLength,抛出TooLongFrameException。
- 若
步骤 2:计算实际消息长度
- 公式:
actualFrameLength = frameLength + lengthAdjustment + initialBytesToStrip
(补偿值用于对齐实际消息体的起始位置)
步骤 3:验证缓冲区数据完整性
- 检查
cumulation.readableBytes()是否 ≥actualFrameLength:- 若不足:等待更多数据到达,暂不拆分。
- 若足够:进入拆分流程。
步骤 4:拆分消息
- 从
cumulation中截取actualFrameLength字节作为一条完整消息。 - 更新
readerIndex到消息末尾的下一个字节,丢弃已处理数据。 - 若
initialBytesToStrip > 0,跳过指定字节数(如跳过长度字段本身)。
关键源码逻辑
/*** 根据长度字段对输入的 ByteBuf 进行解码,提取出完整的帧。* * @param ctx 当前解码器所属的 ChannelHandlerContext* @param in 包含待解码数据的 ByteBuf* @return 解码后的帧对象,如果没有找到完整的帧则返回 null* @throws Exception 解码过程中可能抛出的异常*/protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {// 如果当前处于丢弃过长帧的状态,则调用相应方法处理if (discardingTooLongFrame) {discardingTooLongFrame(in);}// 若可读字节数小于长度字段结束偏移量,说明数据不完整,无法解码,返回 nullif (in.readableBytes() < lengthFieldEndOffset) {return null;}// 计算实际长度字段的偏移量,即 readerIndex 加上长度字段的起始偏移量int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;// 从 ByteBuf 中读取未调整的帧长度long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);// 若读取的帧长度为负数,说明数据损坏,抛出异常if (frameLength < 0) {failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset);}// 对帧长度进行调整,加上长度补偿值和长度字段结束偏移量frameLength += lengthAdjustment + lengthFieldEndOffset;// 若调整后的帧长度小于长度字段结束偏移量,说明数据损坏,抛出异常if (frameLength < lengthFieldEndOffset) {failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset);}// 若调整后的帧长度超过最大帧长度,处理过长帧并返回 nullif (frameLength > maxFrameLength) {exceededFrameLength(in, frameLength);return null;}// 将帧长度转换为 int 类型,由于之前已检查小于 maxFrameLength,不会溢出int frameLengthInt = (int) frameLength;// 若可读字节数小于帧长度,说明数据不完整,无法解码,返回 nullif (in.readableBytes() < frameLengthInt) {return null;}// 若需要跳过的初始字节数大于帧长度,说明数据损坏,抛出异常if (initialBytesToStrip > frameLengthInt) {failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip);}// 跳过指定数量的初始字节in.skipBytes(initialBytesToStrip);// 提取帧// 记录当前的 readerIndexint readerIndex = in.readerIndex();// 计算实际的帧长度,即调整后的帧长度减去需要跳过的初始字节数int actualFrameLength = frameLengthInt - initialBytesToStrip;// 从 ByteBuf 中提取实际的帧ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);// 更新 readerIndex 到帧的末尾in.readerIndex(readerIndex + actualFrameLength);return frame;}
DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder 是 Netty 中用于****按分隔符拆分字节流****的解码器,核心解决 TCP 粘包/拆包问题。其实现原理可归纳为以下关键点:
*1. 核心设计目标*
-
*按分隔符拆分*:根据预设的分隔符(如
\n、\r\n或自定义字节数组)将字节流拆分为完整消息。 -
动态缓冲区管理:累积未处理字节,直到检测到分隔符才触发拆分。
-
*零拷贝优化*:尽可能复用
ByteBuf引用,避免内存复制。
/*** 根据分隔符对输入的 ByteBuf 进行解码,提取出完整的帧。* * @param ctx 当前解码器所属的 ChannelHandlerContext* @param buffer 包含待解码数据的 ByteBuf* @return 解码后的帧对象,如果没有找到完整的帧则返回 null* @throws Exception 解码过程中可能抛出的异常*/protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {// 如果使用的是基于行的解码器(即分隔符为 \n 和 \r\n),则直接调用行解码器进行解码if (lineBasedDecoder != null) {return lineBasedDecoder.decode(ctx, buffer);}// 尝试所有分隔符,选择能产生最短帧的分隔符// 初始化最短帧长度为 Integer 的最大值int minFrameLength = Integer.MAX_VALUE;// 初始化最短帧对应的分隔符为 nullByteBuf minDelim = null;// 遍历所有分隔符for (ByteBuf delim: delimiters) {// 查找当前分隔符在 buffer 中的位置int frameLength = indexOf(buffer, delim);// 如果找到分隔符,并且该分隔符产生的帧长度小于当前最短帧长度if (frameLength >= 0 && frameLength < minFrameLength) {// 更新最短帧长度minFrameLength = frameLength;// 更新最短帧对应的分隔符minDelim = delim;}}// 如果找到了合适的分隔符if (minDelim != null) {// 获取最短分隔符的长度int minDelimLength = minDelim.capacity();ByteBuf frame;// 如果正在丢弃过长的帧if (discardingTooLongFrame) {// 刚刚完成丢弃一个非常大的帧,回到初始状态discardingTooLongFrame = false;// 跳过当前帧和分隔符的字节buffer.skipBytes(minFrameLength + minDelimLength);// 获取之前记录的过长帧的长度int tooLongFrameLength = this.tooLongFrameLength;// 重置过长帧长度为 0this.tooLongFrameLength = 0;// 如果 failFast 为 false,则在丢弃完整个过长帧后抛出异常if (!failFast) {fail(tooLongFrameLength);}return null;}// 如果最短帧长度超过了最大帧长度if (minFrameLength > maxFrameLength) {// 丢弃当前读取的帧buffer.skipBytes(minFrameLength + minDelimLength);// 抛出帧过长异常fail(minFrameLength);return null;}// 如果需要去除分隔符if (stripDelimiter) {// 读取并保留帧内容,不包含分隔符frame = buffer.readRetainedSlice(minFrameLength);// 跳过分隔符的字节buffer.skipBytes(minDelimLength);} else {// 读取并保留帧内容,包含分隔符frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);}return frame;} else {// 如果没有找到分隔符// 如果当前没有处于丢弃过长帧的状态if (!discardingTooLongFrame) {// 如果 buffer 中的可读字节数超过了最大帧长度if (buffer.readableBytes() > maxFrameLength) {// 开始丢弃 buffer 中的内容,直到找到分隔符tooLongFrameLength = buffer.readableBytes();// 跳过 buffer 中所有可读字节buffer.skipBytes(buffer.readableBytes());// 标记为正在丢弃过长帧discardingTooLongFrame = true;// 如果 failFast 为 true,立即抛出帧过长异常if (failFast) {fail(tooLongFrameLength);}}} else {// 仍然在丢弃 buffer 中的内容,因为还没有找到分隔符tooLongFrameLength += buffer.readableBytes();// 跳过 buffer 中所有可读字节buffer.skipBytes(buffer.readableBytes());}return null;}}