【论文阅读】BACKDOOR FEDERATED LEARNING BY POISONING BACKDOOR-CRITICAL LAYERS
ICLR 2024
https://github.com/zhmzm/Poisoning_Backdoor-critical_Layers_Attack
现有的FL攻击与防御方法大多关注于整个模型,尚未意识到“后门关键(Backdoor-Critical, BC)层”的存在——这些层是模型中主导漏洞的小部分层。攻击BC层能够达到与攻击整个模型同等的效果,但被最新(SOTA)防御方法检测到的概率却大大降低。本文提出了一种通用的原位(in-situ)方法,从攻击者的视角识别并验证BC层。在识别出BC层的基础上,我们精心设计了一种新的后门攻击方法,能够在多种防御策略下自适应地在攻击效果和隐蔽性之间寻求根本平衡。大量实验表明,我们基于BC层感知的后门攻击能够在仅有10%恶意客户端的情况下,成功突破七种SOTA防御,并优于最新的后门攻击方法。
联邦学习后门防御
已经有多种防御方法被提出,用于检测后门攻击并减轻其影响,根据关键技术可分为三类:基于距离的防御、基于反演的防御和基于符号的防御。基于距离的防御,如FLTrust(Cao 等,2021)和FoolsGold(Fung 等,2020),通过计算本地模型之间的余弦相似度和欧氏距离来检测潜在的恶意客户端。基于反演的防御,如Zhang 等(2022a),利用触发器反演和后门消除来减轻全局模型中的后门。基于符号的防御,如RLR(Ozdayi 等,2021),检测客户端上传的本地模型更新中各参数的符号变化方向,并调整各参数的学习率以减轻后门攻击。
motivaton
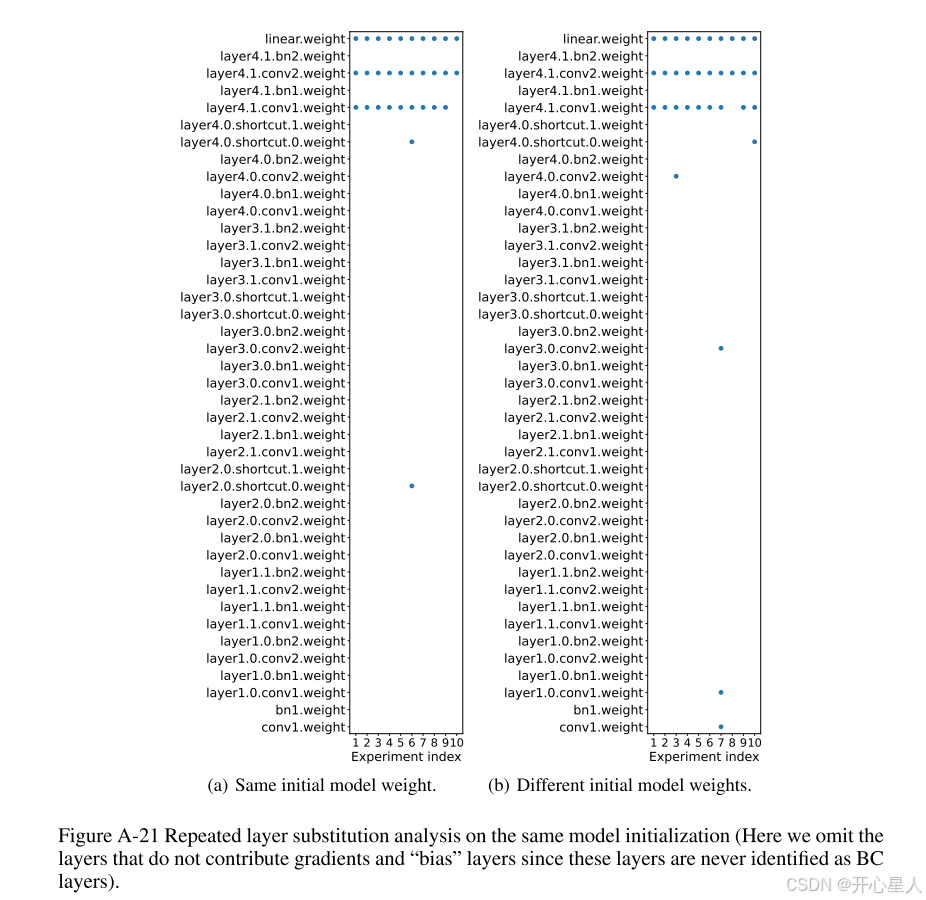
现有研究忽略了一个新的维度——后门攻击的有效性只与模型中一小部分层相关,即后门关键(Backdoor-Critical, BC)层。为了证明BC层的存在,我们首先在干净数据集上训练一个良性的五层CNN模型直到其收敛。然后,在带有触发器的污染数据上训练该良性模型的一个副本,得到一个恶意模型。我们将良性模型中的每一层替换为恶意模型中的相应层,并测量后门攻击的成功率,即识别嵌入触发器样本为目标标签的准确率。图1(a)显示,除了fc1.weight层外,恶意模型中其他层的缺失并不会降低BSR(Backdoor Success Rate,后门成功率)。图1(b)显示,只有来自恶意模型的fc1.weight层能够实现成功的后门任务。因此,我们认为,像fc1.weight这样的少数几层是后门关键层——即使缺失其中一个BC层,后门成功率也会很低。BC层作为模型的一小部分,在大型模型如ResNet18和VGG19中也可以观察到(见图A-22)。直观上,较深的层更可能是BC层,因为浅层学习的是简单、低级的特征(如边缘、纹理),而深层则将这些特征组合起来,学习更复杂的高级概念( 如物体及其组成部分)(Zeiler & Fergus, 2014;Bau 等,2017;Simonyan 等,2013)。

本文提出了一种层替换分析(Layer Substitution Analysis),这是一种通用的原位方法,通过正向和反向层替换来识别BC层。我们进一步设计了两种新的后门攻击方法:分层投毒攻击(layer-wise poisoning attack)和分层翻转攻击(layer-wise flipping attack)。这两种攻击方法利用已识别的BC层,通过精确攻击这些层,以最小的模型污染和极少的恶意客户端(如10%客户端)绕过最新的基于距离、反演和符号的防御方法。
识别后门关键(BC)层
在联邦学习(FL)环境下,每一轮都有一个全局模型,客户端可以用本地数据训练几个epoch,各客户端的模型彼此相似,因此新的全局模型是所有客户端模型的平均值(Konečný等,2016)。在这种场景下,我们有机会探索用污染数据训练的恶意模型与用干净数据训练的良性模型之间的差异。
我们认为,如果第l层(或一组L*层)对后门任务至关重要,将w_benign中的该层(或这些层)替换为w_malicious中的相应层,会导致后门任务准确率(BSR)的下降。
3.1 总览
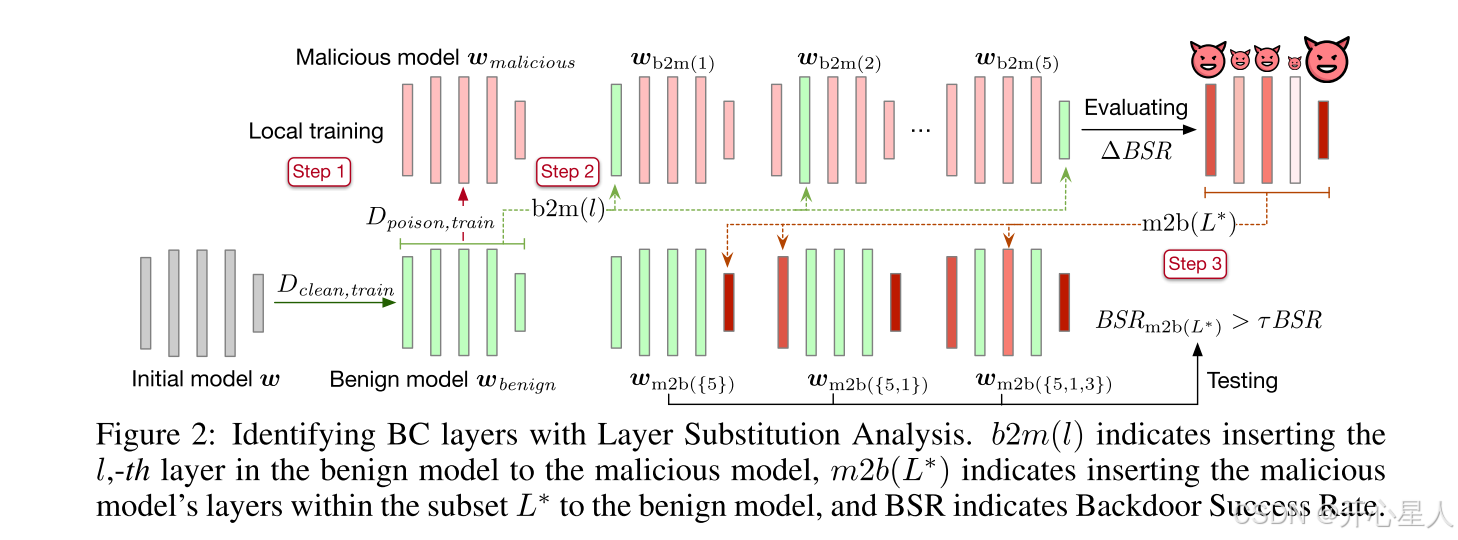
图2展示了用于为每个被攻击者控制的恶意客户端i(i∈M)识别BC层的“层替换分析”流程:
-
步骤1:用干净数据集D_clean, train训练初始模型w,获得良性模型w_benign。然后用污染数据集D_poison, train在w_benign上继续训练以收敛于后门任务,得到恶意模型w_malicious。
-
步骤2:正向层替换——将恶意模型w_malicious的第l层逐个替换为良性模型w_benign的第l层(l∈L)。然后评估更新后的恶意模型wb2m(l)的后门成功率(BSR),并与原始恶意模型w_malicious的BSR进行比较。根据BSR的变化对各层排序。
-
步骤3:按步骤2排序的层顺序进行反向层替换。逐步将恶意模型中的层复制到良性模型中,直到更新后的模型BSR达到某一阈值。被复制的层索引即为BC层集合L*。
3.2 层替换分析. (下面为本文关键点)
步骤1:本地训练
在FL环境下,恶意客户端在本地数据集上识别BC层。i号恶意客户端的本地数据集D(i)被划分为训练集D(i)_clean,train和D(i)_poison,train,以及验证集D(i)_clean,val和D(i)_poison,val。当恶意客户端i接收到全局模型w时,先在D(i)_clean,train上训练w_benign至收敛,然后在D(i)_poison,train上继续训练w_benign至收敛,得到恶意模型w_malicious。
步骤2:正向层替换
我们认为,如果某层是BC层,在恶意模型中用良性模型的该层替换,会降低恶意模型的后门任务准确率(BSR)。
良性层 → 恶意模型:我们首先观察当恶意模型的某一层被良性模型同层替换时BSR的变化。具体地,用b2m(l)表示将恶意模型的第l层替换为良性模型的第l层的过程,两个模型结构相同,均有|L|层。
如图2所示,执行b2m(l)会生成每层替换后的更新恶意模型wb2m(l)。我们用污染数据集D_poison,val评估所有wb2m(l)的BSR,通过遍历所有层l∈L,每个恶意客户端i可根据BSR的变化对各层排序,定义为:
ΔBSR_b2m(l) := BSR_malicious − BSR_b2m(l)
其中BSR_malicious为原恶意模型的BSR,BSR_b2m(l)为替换第l层后的模型BSR。按ΔBSR_b2m(l)从高到低排序后,进一步进行反向层替换以确认BC层。
步骤3:反向层替换
我们认为,如果某层是BC层,在良性模型中用恶意模型的该层替换,会提升良性模型的BSR。
恶意层→良性模型:反向层替换过程定义为m2b(L*)。与b2m(l)只替换单层不同,m2b(L*)替换一组L层。我们按ΔBSR_b2m(l)降序逐步将层加入L,并用污染数据集D_poison,val评估更新模型的BSR。图2所示,m2b(L*)迭代地将恶意模型w_malicious的L层复制到良性模型w_benign中,直到更新后的模型BSR_m2b(L)达到预设阈值τBSR_malicious(τ∈(0,1])。
具体地,比较BSR_m2b(L*)与阈值τBSR_malicious:
如果BSR_m2b(L*) < τBSR_malicious,则继续按ΔBSR_b2m(l)降序添加层到L*并更新模型,重新评估BSR。
如果BSR_m2b(L*) ≥ τBSR_malicious,则新模型已达到与恶意模型相近的BSR,停止添加。
我们认为L*中的层为BC层,因为它们同时满足:1)从恶意模型移除会降低其BSR;2)复制到良性模型会提升其BSR至与恶意模型相近。需要注意,反向层替换可识别单个BC层和BC层组合(即后门任务可由多层组合学习)。
攻击BC层
本节提出了两种基于BC层的攻击方法:分层投毒(LP)攻击和分层翻转(LF)攻击,分别针对基于距离、反演和符号的防御方法。
分层投毒(LP)攻击(有点没太看懂)
针对已识别的BC层集合L*,我们设计了LP攻击,从L*中选择BC层并精确地对这些层进行最小化修改,以绕过现有的基于距离的防御方法(Cao等,2021;Nguyen等,2021;Blanchard等,2017)。
在第t轮,FL服务器选中的恶意客户端执行正向和反向层替换,找出本轮的BC层集合L*_t。收到全局模型w_t(简记为w)后,恶意客户端i分别用本地污染数据D(i)_poison和干净数据D(i)_clean训练本地恶意模型w(i)_malicious和良性模型w(i)_benign。
我们用向量v=[v1, v2, …, vl]表示模型w(i)_benign或w(i)_malicious中选取的层的子集。如果vj=1,则良性模型w(i)_benign的第j层将被恶意模型w(i)_malicious的对应层替换。用u(i)_malicious=[u(i)_malicious,1, …, u(i)_malicious,l]表示w(i)_malicious在层空间的表示,u(i)_benign同理。
攻击者在第t轮的目标可表述为如下优化问题:
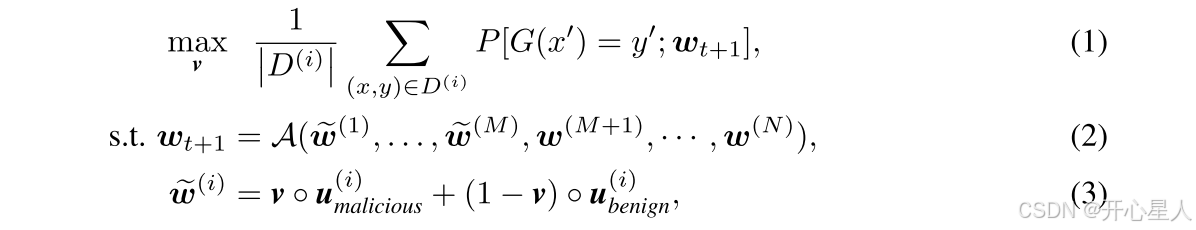
其中◦为逐元素乘法,w_{t+1}为第t+1轮的全局模型权重,A为服务器聚合函数,x′为嵌入触发器的图片,y′为目标标签,G(x)为全局模型对输入x的预测标签。A可采用K-means或HDBSCAN等聚类算法,导致无法计算梯度。
这部分没写完,具体看原论文
分层翻转(LF)攻击
当分层投毒(LP)攻击无法绕过基于符号的防御方法时,后门相关参数很可能位于“符号不一致”区域,并被反向符号的学习率所抵消。为应对这类基于符号的防御方法,我们提出了分层翻转攻击(Layer-wise Flipping attack)。该方法在防御机制对这些层应用反向学习率之前,主动对每个客户端i的BC层L*中的参数符号进行翻转,从而保持BC层的后门效果。其定义如下:
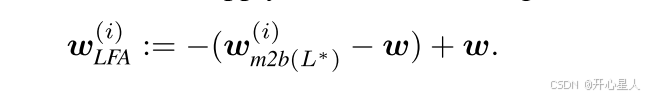
最终,FL服务器会再次翻转BC层的参数符号,从而恢复参数的原始符号,并激活注入模型的后门。由于掌握了BC层的信息,分层翻转攻击能够避免对其他无关层进行不必要的投毒,这不仅提升了主任务的准确率,还能伪装恶意更新,降低被防御方法检测的风险。
基于符号的防御机制原理:这类防御(如 RLR)会检测本地模型参数的“更新方向”(即符号),如果发现某些参数的符号和大多数客户端不一致,就会降低这些参数的学习率,甚至反向更新。
这样做的目的是抑制恶意更新,尤其是后门攻击,因为后门参数往往与正常训练的方向不一致。
直接投毒(LP攻击)会被抵消
如果攻击者直接在BC层投毒,参数方向和大部分正常客户端不一致时,服务器端会自动反向或缩小这些参数的更新幅度,导致后门效果失效。
分层翻转攻击的思路
攻击者提前将BC层的参数符号翻转(即取反),这样在服务器聚合时,服务器的防御机制会再次把这些参数符号翻转回来(因为它认为这些参数方向异常),反而恢复了原本的后门方向。
这样,后门参数逃过了防御机制的“抵消”,后门效果得以保留。
只针对BC层,隐蔽性和主任务准确率更高:只对关键层做翻转,其他层保持正常,有效减少了对主任务的干扰,也更不容易被检测到。