Sparse4D: 稀疏范式的端对端融合
研究背景与意义
后融合感知系统:
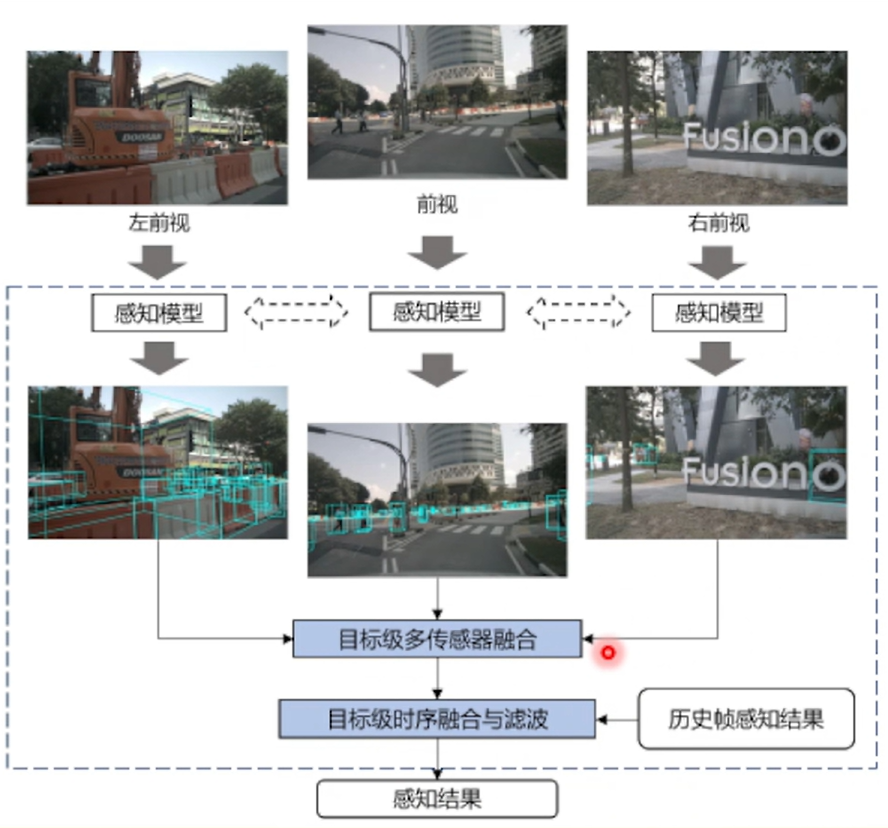
目标级时许融合与滤波,主要是卡尔曼滤波及状态估计,以及逻辑filter
后融合感知系统的不足:
1)跨视角截断case处理效果不好;
2)融合模块仅接收到结构化的感知结果,信息不够充足;
3)需要设定一些前提假设,比如感知误差分布,目标运动模型等,超参数众多,一定程度生限制了感知上限;
4)需要维护一套独立于模型以外的融合模块,增加了系统的复杂度...
把后融合感知系统放到模型里去做,
基于中融合的感知模型
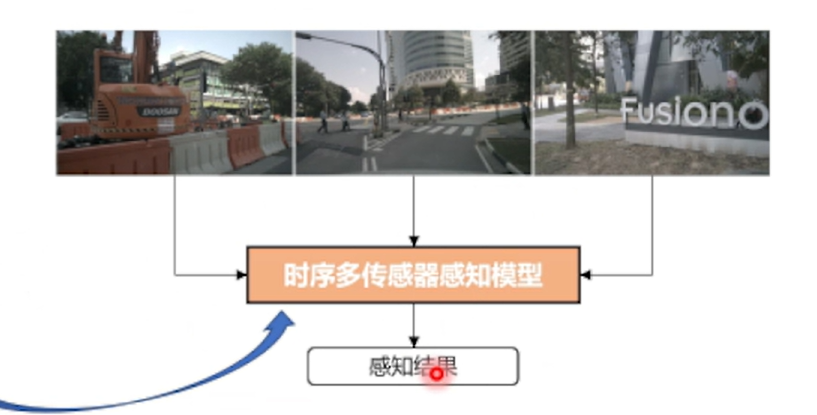
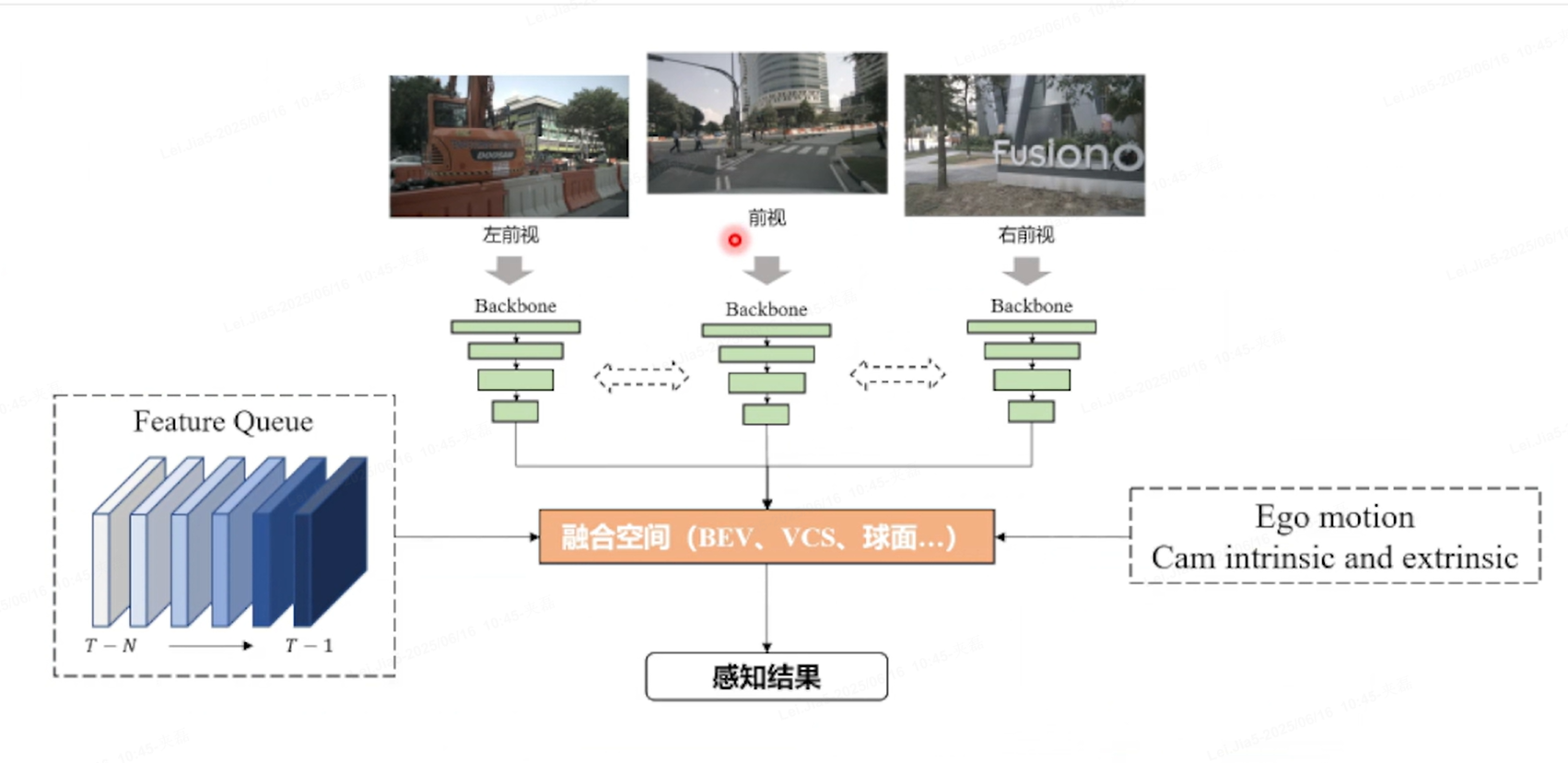
把feature投射到定义的融合空间(显示BEV,VCS,或者球面空间)得到感知结果
自从2021年AIday Tesla阐述了BEV方案后,BEVDet,BEVDepth,BEVFormer
多视角融合(BEVDet)-->时序融合(BEVDet4D)-->点云深度监督(BEVDepth)-->MVS(BEVStereo)-->长时序(SOLOFusion)-->recurrent时序(VideoBEV)
BEV劣势:限制BEV的感知范围,实际量产需要100~200m,计算复杂度比较高
密集算法是多视角3D检测的主要研究方向,这类算法使用密集特征向量进行视图变换、特征融合或边界框预测。目前,基于BEV的方法是密集算法的主要组成部分。
BEVFormer 采用可变形注意力来完成BEV特征生成和密集的时空特征融合。
BEVDet使用提升-投影操作(lift-splat operation)实现视图变换。
在BEVDet的基础上,BEVDepth 添加了显式的深度监督,显著提高了检测的精度。
BEVStereo 和 SOLOFusion 将时间立体技术引入3D检测,进一步改善了深度估计效果。
PETR 利用3D位置编码和全局交叉注意力进行特征融合,但全局交叉注意力的计算开销较大。DETR3D是稀疏方法的代表性工作之一,其基于稀疏参考点执行特征采样和融合。
Graph DETR3D 延续了DETR3D,并引入了图网络以实现更好的空间特征融合,尤其在多视角重叠区域中表现突出。
- 计算量大
从图像空间到BEV空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及BEV 特征图尺寸成正相关
- 感知范围有限
开源数据nuScenes 数据中,感知范围通常是长宽 [-50m, +50m] 的方形区域,然而在实际场景感知要求会更远,需要达到前视100~200米,都堪比lidar了。
- 感知精度和范围的平衡
BEV feature map尺寸是固定的,如果在不增加feature map尺寸的情况下,要扩大感知范围,就要增加 BEV Grid 的分辨率了,比如以前一个grid分辨率是0.50.5,就需要更粗的Grid(比如1*1),感知精度会降低。如果不改变感知精度,那就要扩大 feature map,这会增加运算量。在车上算力有限的情况下,很难实现既要感知精度高又要感知范围远。
- 2D感知任务不友好
BEV 空间可以看作是压缩了高度信息的3D空间,也会导致2D信息缺失,对于需要丰富2D特征信息分类的任务可能不是很友好,如标志牌和红绿灯检测等;
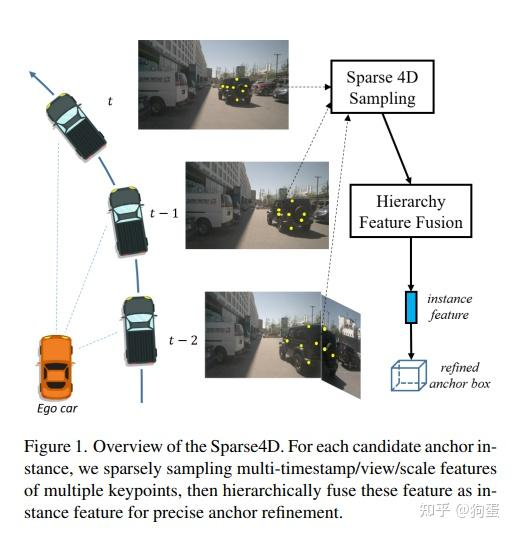
平时智驾场景所关注的动静态目标(人车、锥桶...),对于BEV空间来说是比较稀疏的。目前常用基于稠密特征的BEV方案,运算量大,其实关注有效目标并不多,浪费掉一些计算资源。与基于稠密特征BEV的方法相比,基于稀疏方法所需算力少。为了进一步推动稀疏3D检测的发展,本文通过稀疏采样和融合时空特征进行锚框的迭代优化。
Sparse4D V1:Deformable Spatial Aggregation
不基于BEV的范式引入了多视角时序组合引入,空间的融合和多帧采样的时许融合
整体架构:
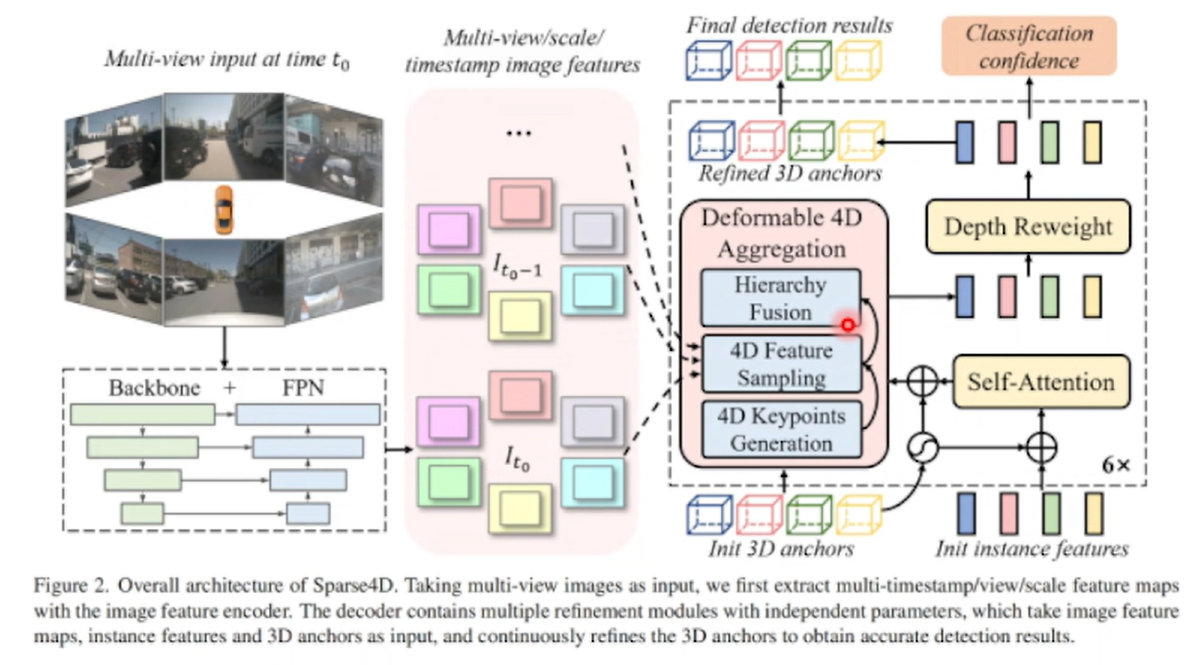
多视角进行backbone和neckbone的网络形成多视角多multiscale feature map,进行decoder(6层的transformer)把transformer的cross attention部分换成了Deformable 4D Aggregation算子(这个算子进行了空间,时序等融合)。
Instance 定义:
Anchor:待检测instance的结构化信息,比如3Dbox的[x,y,z,l,h,yaw,vx,vy,vz]
Anchor embedding:通过MLP将anchor编码为高维特征
Instance feature:来自图像特征
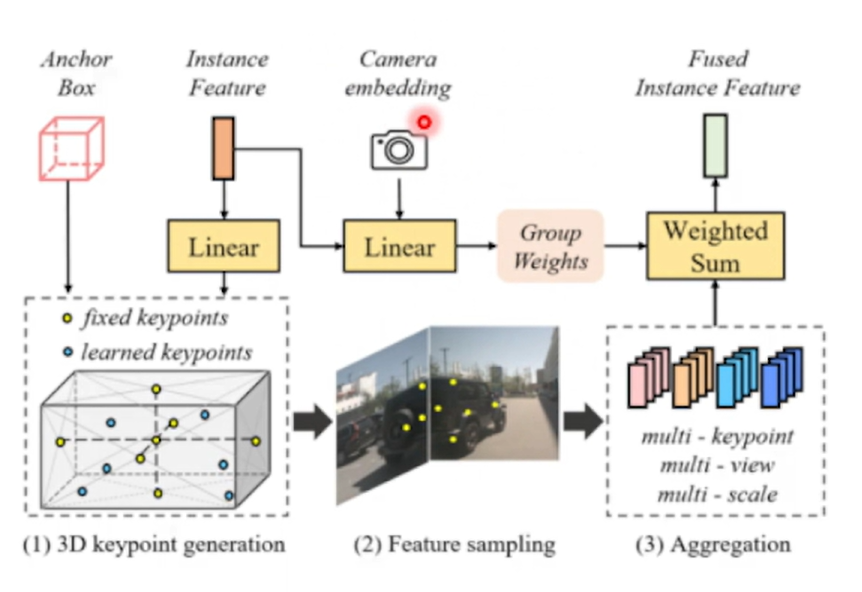
算子Deformable 4D Aggregation:
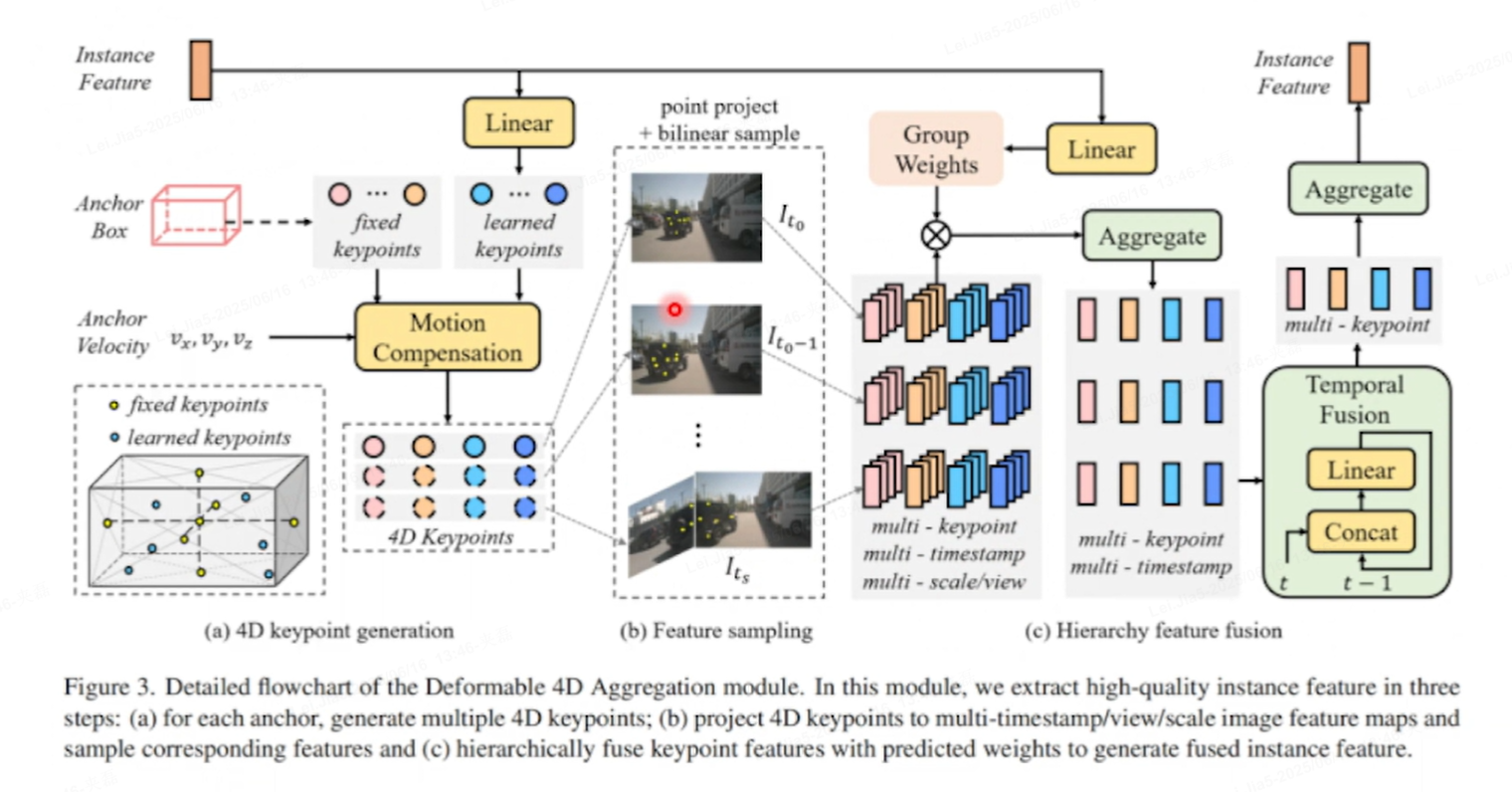
4D 关键点生成→特征采样→分层融合
A)关键点生成:
-
锚框(Anchor Box)和速度(Velocity):
-
锚框:在道路上,我们的模型预先定义了一些锚框,这些锚框是不同大小和形状的框,用于捕捉其他车辆的可能位置。例如,一个锚框可能定义为一个长方形,宽度为2米,高度为1米,表示一个小型车辆的可能大小。
-
速度:我们的自动驾驶汽车通过传感器(如雷达或激光雷达)估计前方车辆的速度。例如,我们检测到前方车辆的速度为vx=5m/s(沿x轴的水平速度)和vy=0m/s(沿y轴的垂直速度),表示车辆在水平方向上以5米/秒的速度移动,而在垂直方向上没有移动。
-
-
运动补偿(Motion Compensation):
-
由于前方车辆在移动,我们通过运动补偿模块来补偿位置偏移。例如,如果我们有一个时间间隔Δt=1s,那么我们可以通过运动补偿计算出前方车辆在下一个时间步的位置偏移为Δx=vx×Δt=5m,Δy=vy×Δt=0m。这意味着前方车辆在1秒后将向右移动5米。
-
-
4D 关键点生成(4D Keypoint Generation):
-
对于每个锚框,我们生成多个4D关键点。这些关键点不仅包括空间位置(x, y, z),还包括时间维度(t)。例如,对于一个锚框,我们可能在不同的时间步(t0,t1,t2)和不同的视角(前视图、后视图)生成多个关键点。这些关键点可能位于车辆的前部、后部、侧面等位置,以捕捉车辆的不同特征。
-
B)特征采样:
-
将4D关键点投影到多时间戳/视角/尺度的图像特征图上,并采样相应的特征。例如,我们可能有一个高分辨率的前视图图像特征图和一个低分辨率的后视图图像特征图。我们将关键点投影到这些特征图上,采样得到每个关键点对应的特征向量。这些特征向量可能包含颜色、纹理、形状等信息,用于描述车辆的外观。
C)分层关键点融合Hierarchical keypoint fusion:
- 作用:分层次融合多帧 / 多关键点的特征,用
Group Weights(分组权重)让模型自动关注重要帧 / 关键区域,最后聚合出 “精准的实例特征”。 - 流程:
- 多质量 / 多尺度处理:把采样后的特征,按不同 “质量”(比如清晰度、运动显著性 )或 “尺度”(比如大目标、小目标 )拆成多组(multi-quality/multi-scale )。
- 权重预测:用
Group Weights预测每组特征的 “重要性权重”(比如运动剧烈的帧权重高 )。 - 分层聚合:先对每组用
Linear(线性变换)调整维度,再通过Aggregate(聚合)逐层融合,最后用Temporal Fusion(时序融合)+Linear输出最终的 实例特征(用于识别、分类等任务 )。
- 举例:识别高速行驶的汽车时,“运动模糊帧” 可能权重低,“清晰抓拍帧” 权重高,分层融合后,模型更关注清晰、关键帧的特征,提升识别准确率。
>--anchor格式为[x,y,z, l, w, h, sin yaw , cos yaw ,vx, vy], refine offset为A[x,y,z, l, w, h, sin yaw , cos yaw ,vx, vy]
>--Anchor总数量为900,其[x,y,z]初始值通过k-means聚类得到,[l,w,h,sin yaw ,cos yaw,vx, vy]初始值为[1,1,1,0,1,0,0];
>--利用匈牙利算法进行gt和pred之间one2one的匹配; 与DETR用匈牙利完成检测是端对端检测模型,不需要NMS等后处理检测框
>--Loss= ,
为L1 loss,
为focal loss,
为cross entropy loss; 框的回归loss,和框的分类loss,以及框的深度loss
>--每一层decoder的输出都给予loss进行监督。
Sparse4D V2:Recurrment Temporal Fusion
递归时序融合
原先:计算复杂度和时许长度成正比,即T帧感知需要结合N帧之前的特征到T帧之间做融合
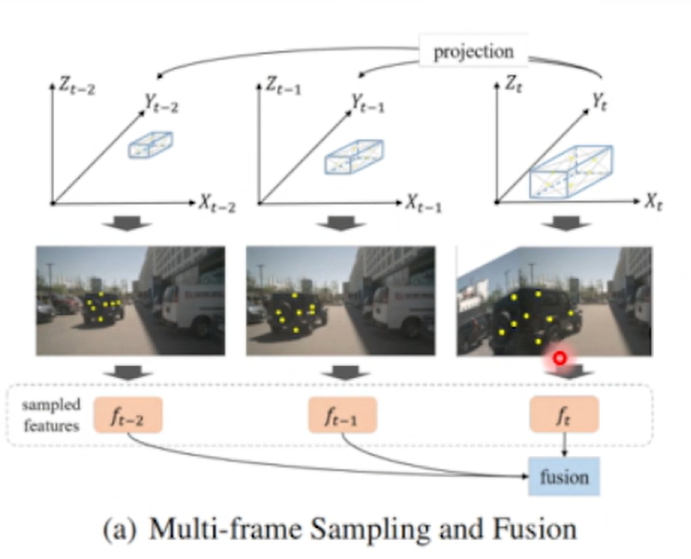
现在:需要拿上一帧的instance feature 结合当前帧feature做fusion,计算复杂度由(O)T变成(O)1
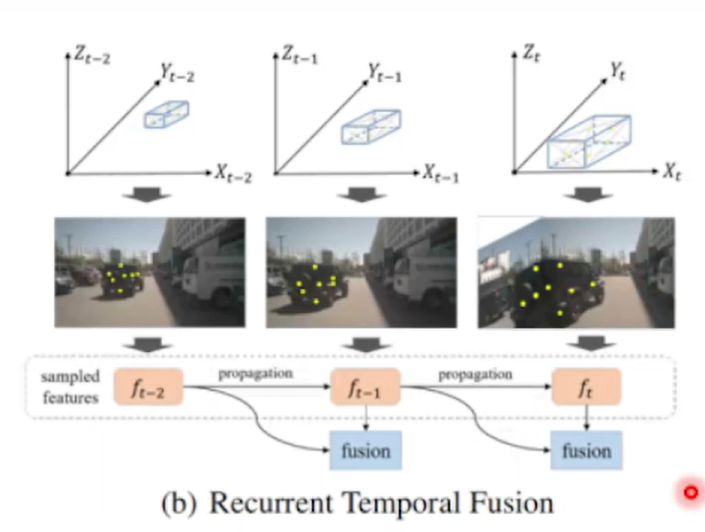
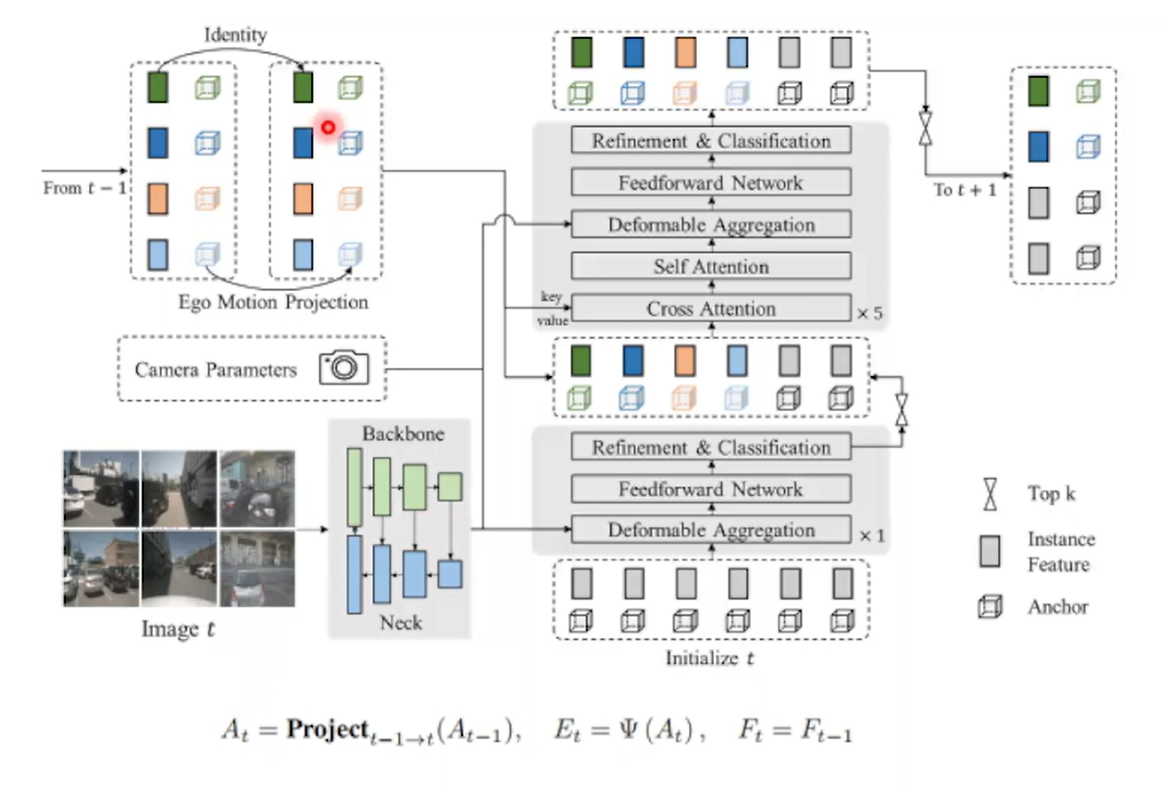
1)考虑到Ego Motion 和目标预测的速度,把T-1时刻的intance投影到当前帧T,得到时序instance初始化好的anchor,时序instance的feature对应anchor的图像特征直接在当前帧拿过来,不需要考虑变换
2)当前帧的新生目标,是无法体现在From T-1到T的投影,而是在Initialize t 重新初始化query处理历史帧没有出现的目标。
3)Intialize 过一层取Top K 再 拿历史帧的 instance,再过5层 transformer
跨帧时序关联 + 动态特征增强
时序融合模块的优化:
实例时序转换的过程,用于在时间序列数据中更新和传播锚框(anchor)及其相关特征

投影过程详细说明
-
位置更新:
[x,y,z]t=Rt−1→t([x,y,z]+dt[vx,vy,vz]t−1)+Tt−1→t-
位置 [x,y,z] 在时间步 t−1 的基础上,根据速度 [vx,vy,vz] 和时间间隔 dt 进行更新。
-
Rt−1→t 是从时间步 t−1 到 t 的旋转矩阵,用于补偿相机或传感器的旋转变化。
-
Tt−1→t 是从时间步 t−1 到 t 的平移向量,用于补偿相机或传感器的平移变化。
-
-
尺寸保持不变:
[w,l,h]t=[w,l,h]t−1-
目标的尺寸 [w,l,h] 在时间步之间保持不变。
-
-
方向更新:
[cosyaw,sinyaw,0]t=Rt−1→t[cosyaw,sinyaw,0]t−1-
方向角的正弦和余弦值通过旋转矩阵 Rt−1→t 进行更新,以反映目标的方向变化
-
可以进行扩展3D车道线keypoints做当前帧投影,2D检测简单IPM投影到当前帧
算子Deformable 4D Aggregation 效率优化
多个keypoints,多个视角,多个feature scale特征融合非常占显存,读写速度慢,做了cuda算子优化,单进程2*S

相机参数编码:
加强模型的内外参泛化性,以及模型的鲁棒性,显示相机编码,把相机内外参从VCS坐标系投影到图像坐标系的( )投影矩阵,给编码高维向量和Instance Feature 相加再过全连接层拿到attention ,这样会使得模型知道哪个attention ways对应哪个视角,增加鲁棒性
)投影矩阵,给编码高维向量和Instance Feature 相加再过全连接层拿到attention ,这样会使得模型知道哪个attention ways对应哪个视角,增加鲁棒性
稀疏范式加速收敛,加了Dense监督:
用lidar进行Depth Net进行深度监督,为了收敛快速且稳定
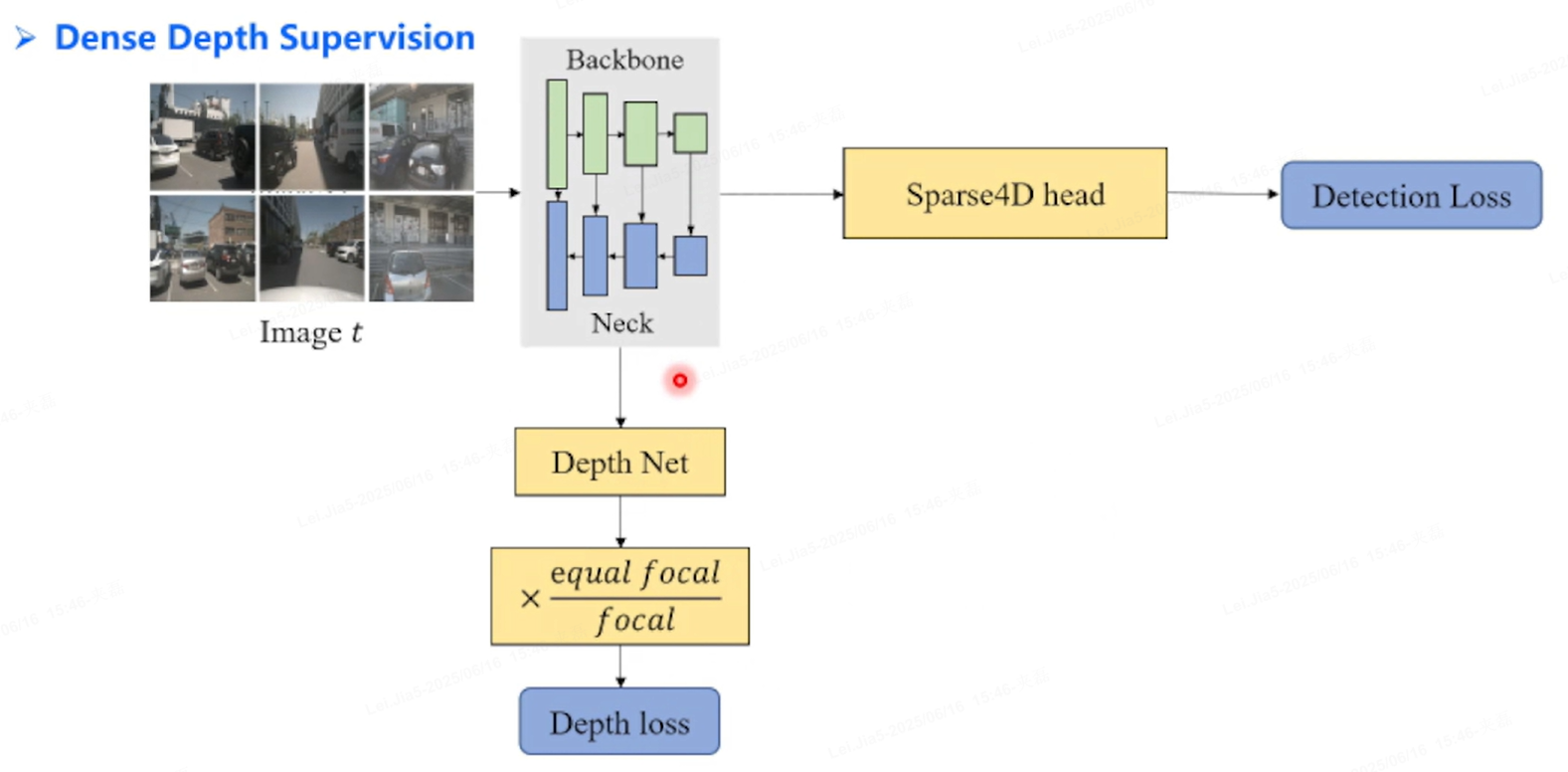
只是在training用,推理时候需要去掉,非必要但有效
DAG:Deformable Aggregation:从3D出发,通过3D点投影到视角上多个点,再融合各个点特征,
DAT :Deformable Attention:2D检测触发,未考虑多视角融合,keypoint或者refernce point都是2D,要是完成多视角融合,需要先完成各个视角单帧的帧内融合,再所有视角特征再相加,缺失多视角之间动态的attention ways,只有2D未考虑3D一致性
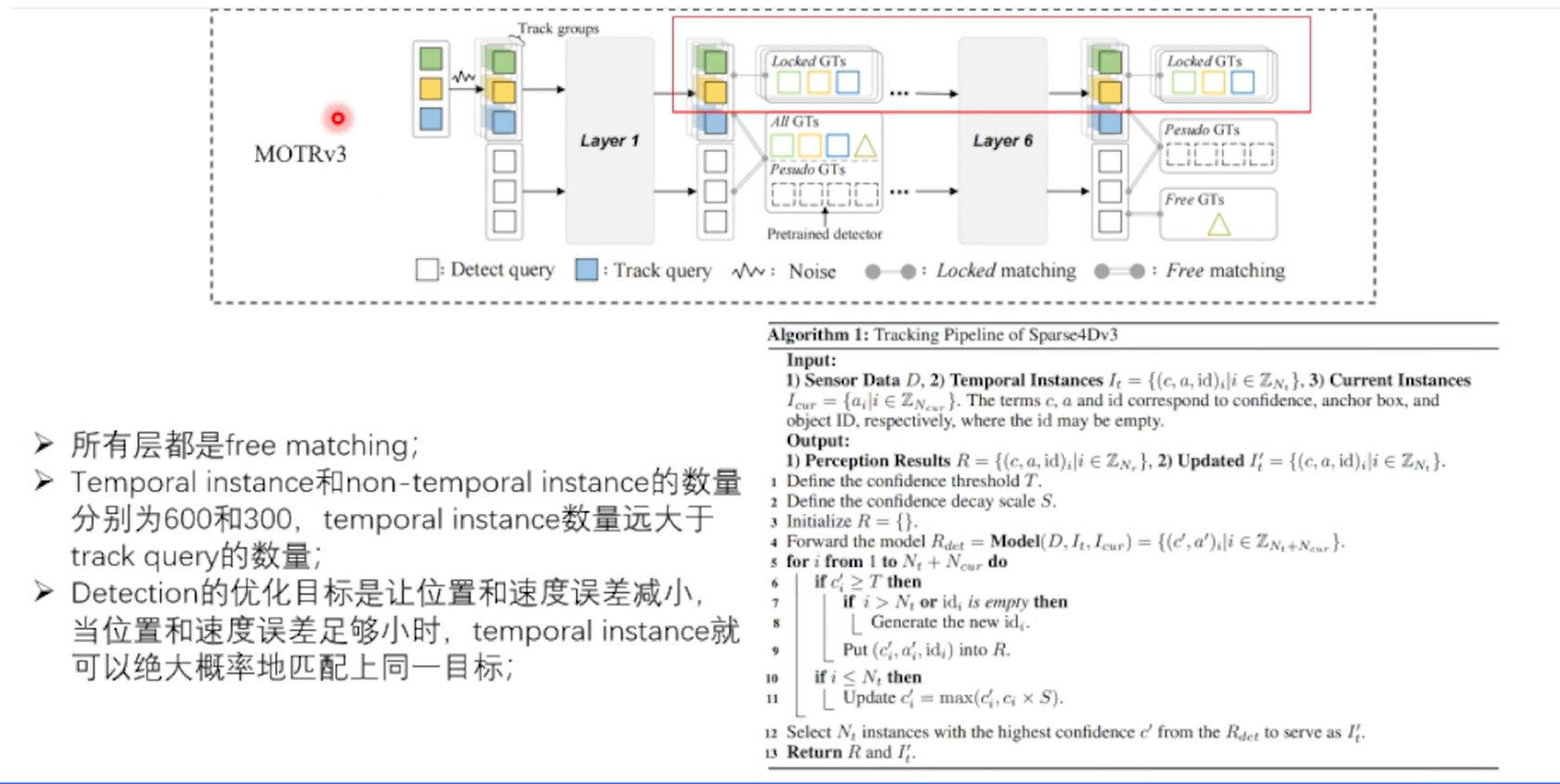
Sparse4D V3:End to End Tracking
端对端Tracking模型,拿到检测框不仅是检测结果,时序有一致性,实现了多目标跟踪(无任何操作)
提升检测性:
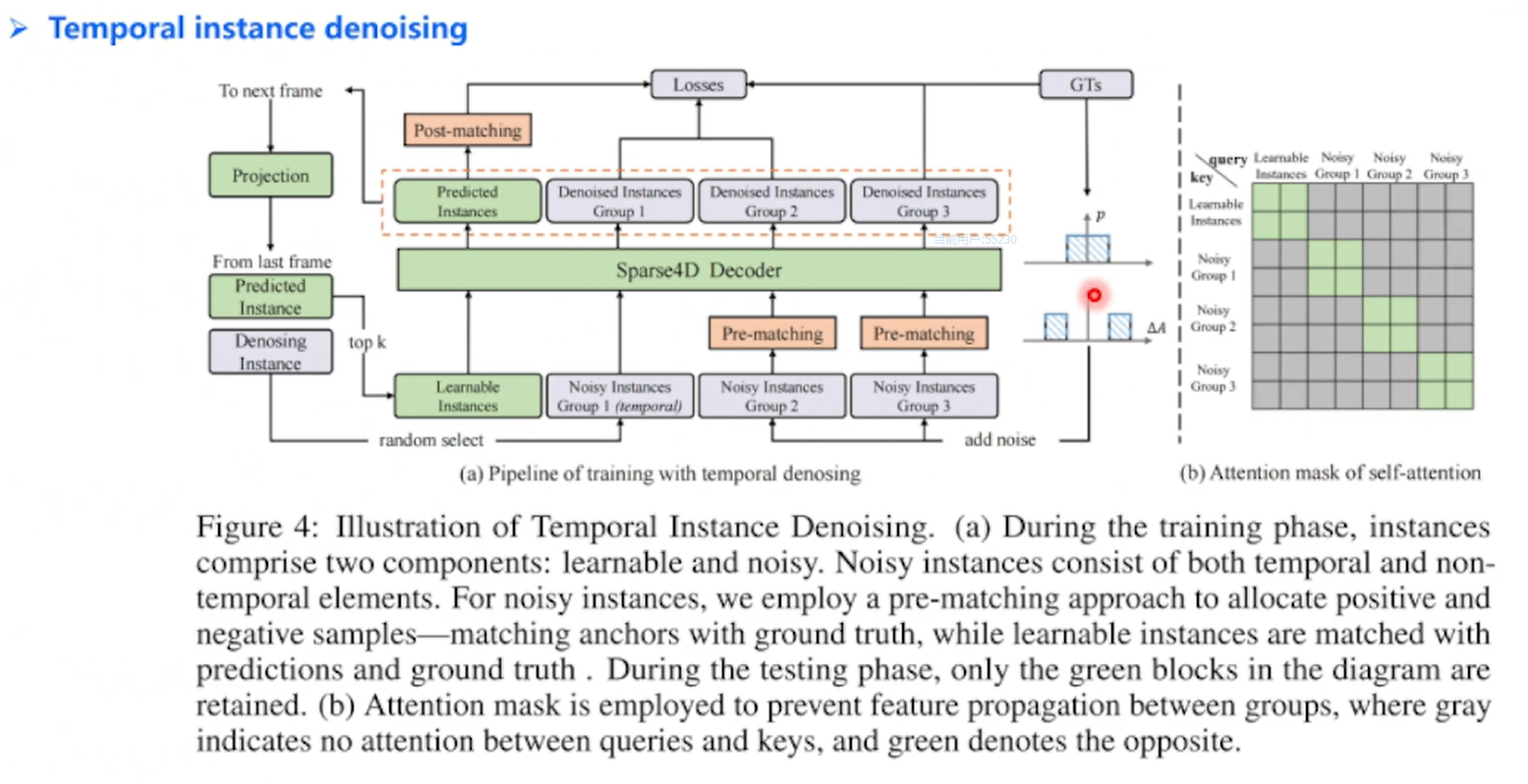
GT加上2部分噪声,带噪声的GT作为模型输入时候训练,把Noisy Instances进行训练,随机选择一组把投影到下一帧,进行时序训练,灰色框都是训练使用,绿色是推理的
通过这个流程,时间实例去噪能够有效提高模型在动态场景中的鲁棒性和准确性,减少由于噪声引起的误检和漏检。
Quality Estamation:
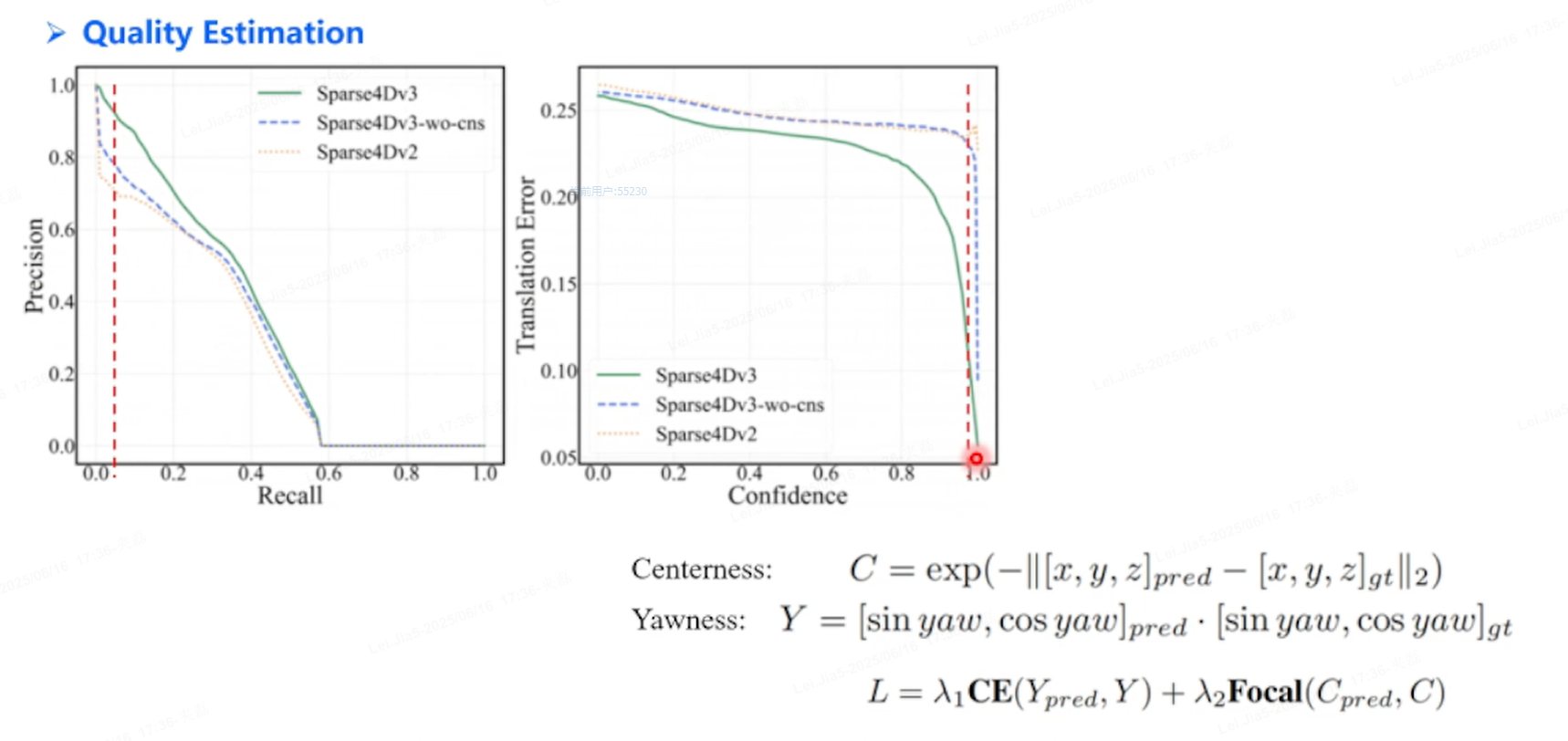
以上Yawness公式有问题,
对于3D检测进行质量估计,Centerness,Yawness
Decoupled Attention:
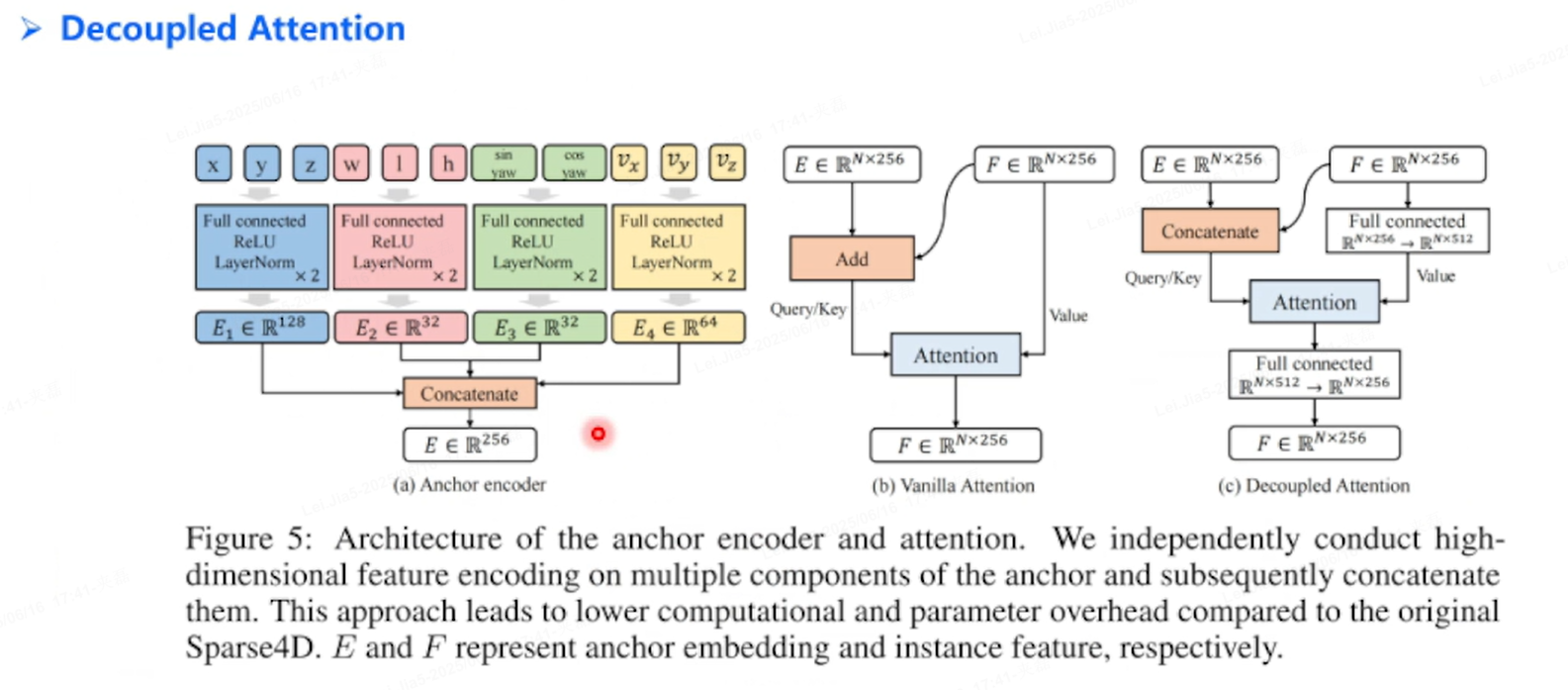
相加Add-->Concatenate 处理Instance,把所有相加改成拼接(类似condition DETR)
跟踪 (E2E)
总结与展望
总结:
>提出了一种sparse-based算法,无需生成BEV特征,即可完成多视角的空间和时序融合;
>在公开数据集达到SOTA水平,且推理速度具备优势,在高分辨率和远距离检测中,推理速度优势更加明显
>实现了端到端跟踪,训练和推理pipeline都极致的简洁。
展望:
>我们在跟踪方面的尝试是初步的,跟踪模型地性能仍有很大的提升空间。
>将Sparse4D扩展为lidar模型及多模态模型;
>在端到端跟踪的基础上,通过引入额外的下游任务,如预测和规划;
>整合额外的感知任务,比如3D车道线检测和2D检测
有点SparseDrive样子了