python爬虫--小白篇【selenium自动爬取文件】
一、问题描述
在学习或工作中需要爬取文件资源时,由于文件数量太多,手动单个下载文件效率低,操作麻烦,采用selenium框架自动爬取文件数据是不二选择。如需要爬取下面网站中包含的全部pdf文件,并将其转为Markdown格式。
 二、解决办法
二、解决办法
首先查看网页的源代码,定位到具体的pdf文件下载链接:
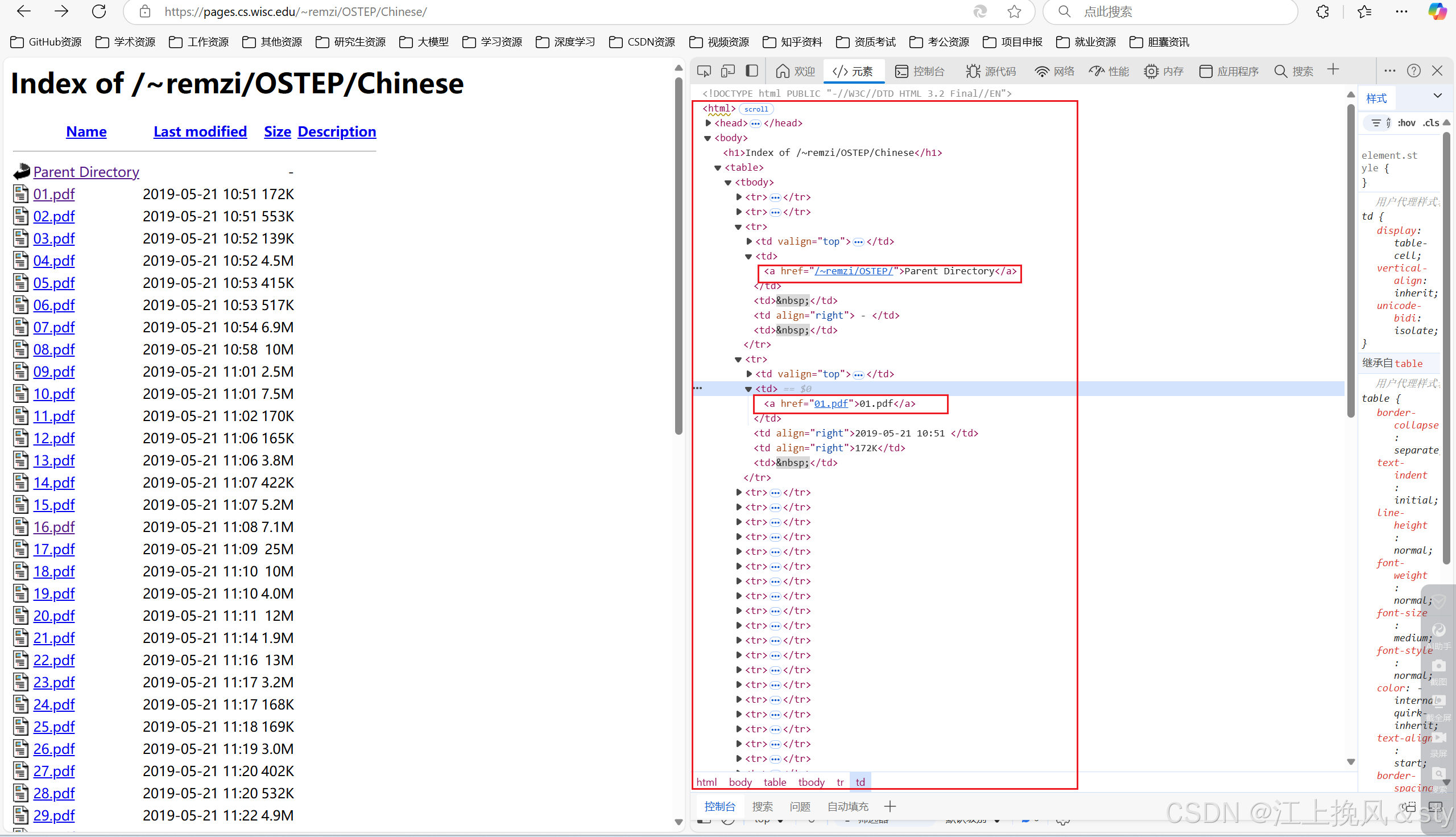
编写脚本,自动爬取网页pdf文件资源:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import timedownload_dir = r"D:\ProjectCode\Spider\StudySpider08\PDF" # 设置下载目录
# 设置Selenium WebDriver
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
options = Options()
options.add_experimental_option("prefs", {"download.default_directory": download_dir, # 设置默认下载路径"download.prompt_for_download": False, # 禁用下载前的确认对话框"download.directory_upgrade": True,"plugins.always_open_pdf_externally": True # 禁用PDF预览,直接下载
})driver = webdriver.Edge(service=service, options=options)# 目标网页URL
url = "https://pages.cs.wisc.edu/~remzi/OSTEP/Chinese/"# 使用get方法打开网页
driver.get(url)
driver.maximize_window()
time.sleep(2)# 等待页面加载完成
WebDriverWait(driver, 20).until(EC.presence_of_all_elements_located((By.XPATH, "/html/body/table/tbody/tr[68]/td[4]")))pdf_links = driver.find_elements(By.XPATH, "/html/body/table/tbody/tr/td[2]/a") # Adjusted XPathfor index, link in enumerate(pdf_links):if index == 16:continue # 跳过第一个链接if link.is_displayed(): # 检查元素是否可见href = link.get_attribute('href') # 获取PDF链接print(href)driver.execute_script("window.open('');") # 在新标签页打开链接driver.switch_to.window(driver.window_handles[-1]) # 切换到新标签页driver.get(href) # 获取PDF链接time.sleep(5) # 等待PDF下载完成driver.close() # 关闭新标签页driver.switch_to.window(driver.window_handles[0]) # 切换回原标签页# 关闭浏览器
driver.quit()下载得到全部的pdf文件并保存到本地:
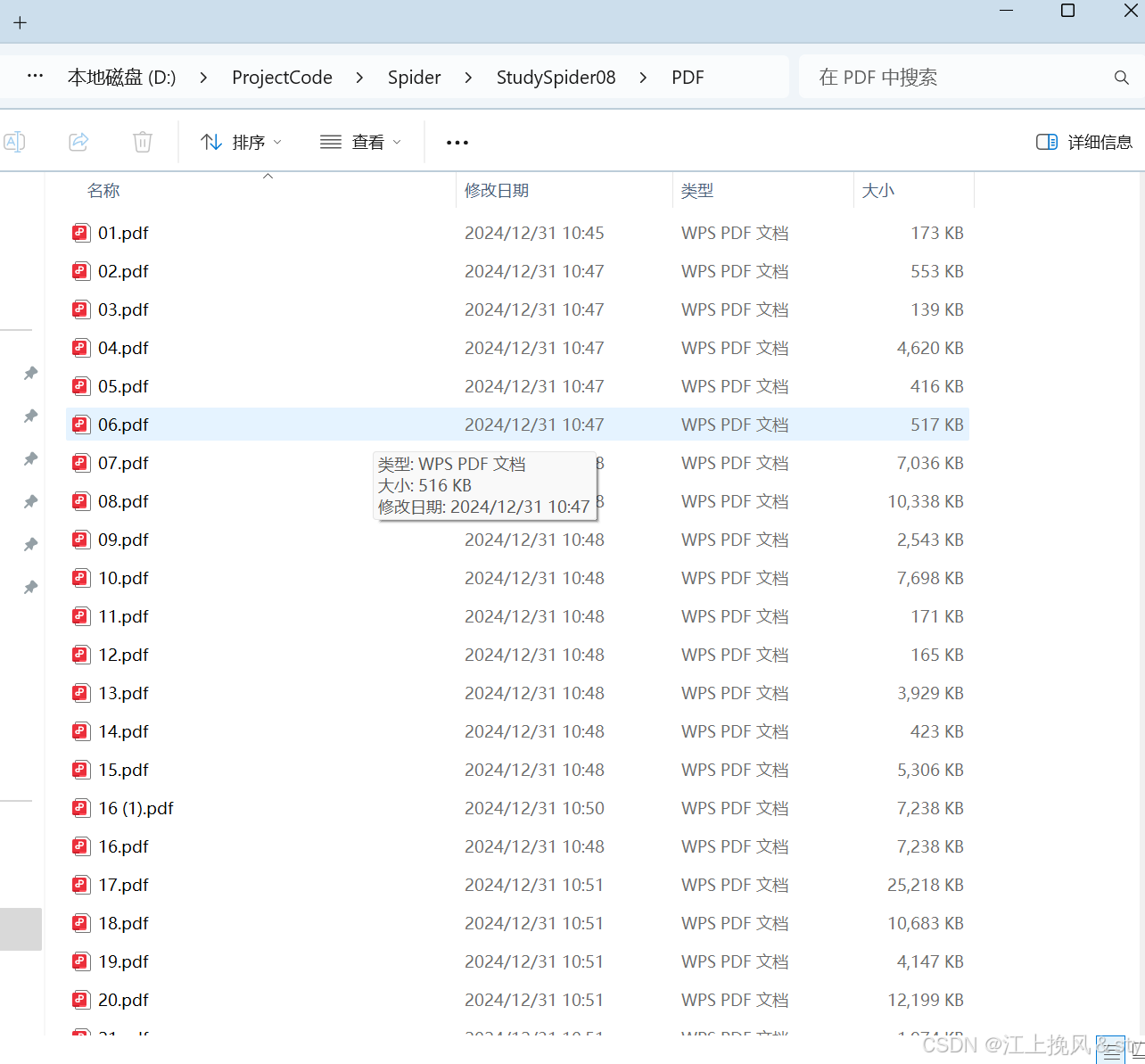
将本地保存的pdf文件全部转为Markdown格式:
# 首先先安装pdfminer.six库
pip install pdfminer.six"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :pdf2md
@Time :2024/12/31 10:38
@Motto:一直努力,一直奋进,保持平常心"""
import os
from pdfminer.high_level import extract_text# 定义包含PDF文件的文件夹路径
pdf_folder_path = 'D:\ProjectCode\Spider\StudySpider08\PDF'
# 定义输出Markdown文件的文件夹路径
md_folder_path = 'D:\ProjectCode\Spider\StudySpider08\MD'# 确保Markdown文件夹存在
if not os.path.exists(md_folder_path):os.makedirs(md_folder_path)# 遍历文件夹中的所有文件
for filename in os.listdir(pdf_folder_path):if filename.lower().endswith('.pdf'):# 构建PDF文件的完整路径pdf_path = os.path.join(pdf_folder_path, filename)# 构建Markdown文件的完整路径md_filename = os.path.splitext(filename)[0] + '.md'md_path = os.path.join(md_folder_path, md_filename)# 提取PDF文件中的文本text = extract_text(pdf_path)# 将提取的文本保存为Markdown文件with open(md_path, 'w', encoding='utf-8') as md_file:md_file.write(text)print(f"{md_filename}已转成功!")print("PDF to Markdown conversion is complete.")得到转换后的MD格式文件:
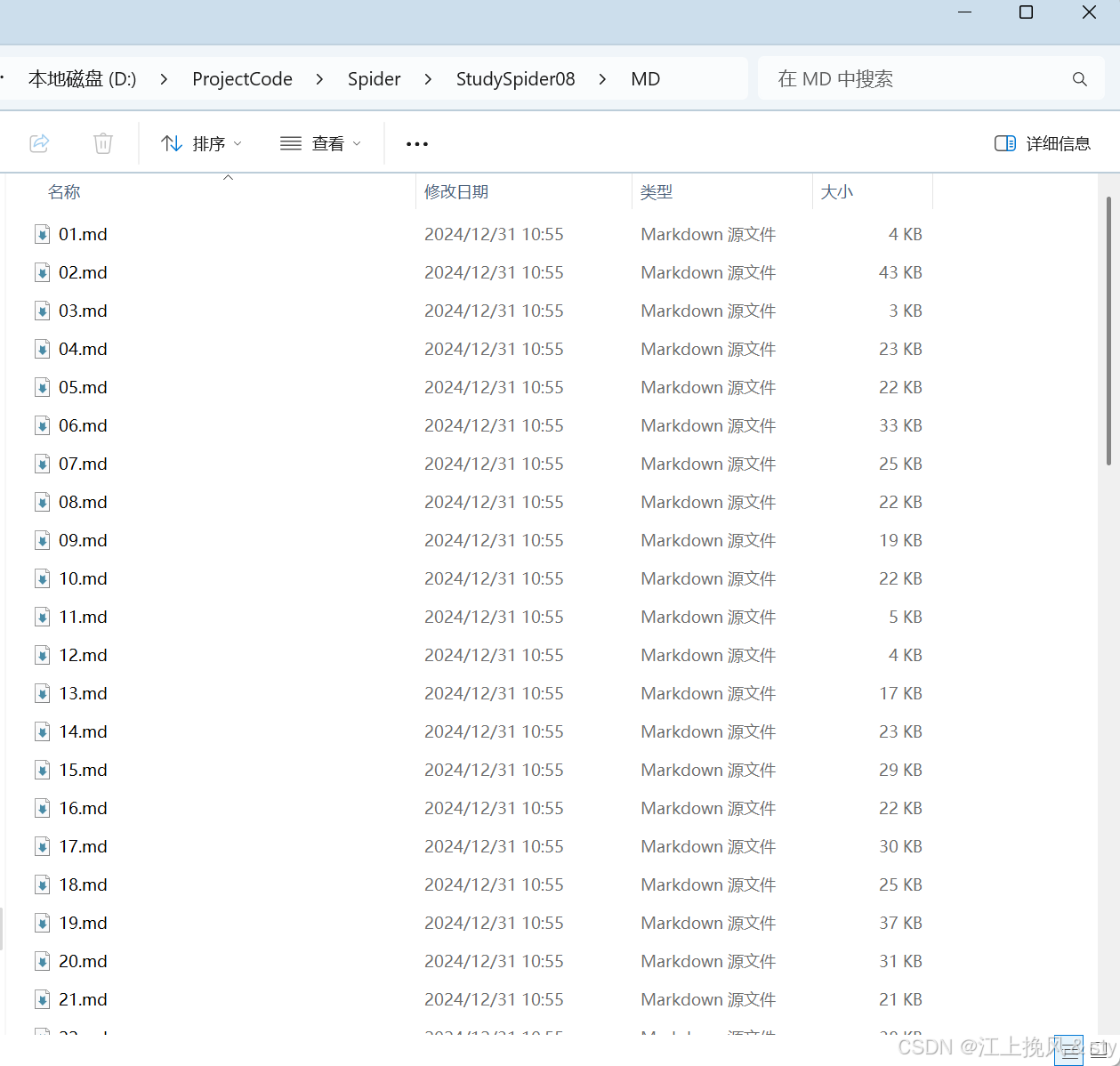
原本觉得效率不是很高,想采用多线程的方式提升效率,但结果表明效率也没提升多少。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.edge.options import Options
import time
from concurrent.futures import ThreadPoolExecutor# 定义下载PDF文件的函数
def download_pdf(index, link, driver_options, download_dir):service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')driver = webdriver.Edge(service=service, options=driver_options)# 目标网页URLurl = link.get_attribute('href')# 使用get方法打开网页driver.get(url)driver.maximize_window()time.sleep(2)# 等待页面加载完成WebDriverWait(driver, 20).until(EC.presence_of_all_elements_located((By.TAG_NAME, "body")))# 等待PDF下载完成time.sleep(5) # 这里可能需要根据实际情况调整等待时间# 关闭浏览器driver.quit()# 设置下载目录
download_dir = r"D:\ProjectCode\Spider\StudySpider08\PDF"
# 设置Selenium WebDriver
options = Options()
options.add_experimental_option("prefs", {"download.default_directory": download_dir, # 设置默认下载路径"download.prompt_for_download": False, # 禁用下载前的确认对话框"download.directory_upgrade": True,"plugins.always_open_pdf_externally": True # 禁用PDF预览,直接下载
})# 目标网页URL
url = "https://pages.cs.wisc.edu/~remzi/OSTEP/Chinese/"# 使用get方法打开网页
driver = webdriver.Edge(service=Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe'), options=options)
driver.get(url)
driver.maximize_window()
time.sleep(2)# 等待页面加载完成
WebDriverWait(driver, 20).until(EC.presence_of_all_elements_located((By.XPATH, "/html/body/table/tbody/tr[68]/td[4]")))pdf_links = driver.find_elements(By.XPATH, "/html/body/table/tbody/tr/td[2]/a") # Adjusted XPath# 创建一个包含四个线程的线程池
with ThreadPoolExecutor(max_workers=4) as executor:for index, link in enumerate(pdf_links):if index == 0:continue # 跳过第一个链接if link.is_displayed(): # 检查元素是否可见executor.submit(download_pdf, index, link, options, download_dir)# 关闭浏览器
driver.quit()print("所有PDF文件下载完成。")