乐高小人分类项目
数据来源
LEGO Minifigures | Kaggle
建立文件目录
BASE_DIR = 'lego/star-wars-images/'
names = ['YODA', 'LUKE SKYWALKER', 'R2-D2', 'MACE WINDU', 'GENERAL GRIEVOUS'
]
tf.random.set_seed(1)# Read information about dataset
if not os.path.isdir(BASE_DIR + 'train/'):for name in names:os.makedirs(BASE_DIR + 'train/' + name)os.makedirs(BASE_DIR + 'test/' + name)os.makedirs(BASE_DIR + 'val/' + name) 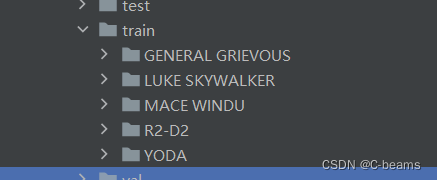
划分数据集
# Total number of classes in the dataset
orig_folders = ['0001/', '0002/', '0003/', '0004/', '0005/']
for folder_idx, folder in enumerate(orig_folders):files = os.listdir(BASE_DIR + folder)number_of_images = len([name for name in files])n_train = int((number_of_images * 0.6) + 0.5)n_valid = int((number_of_images * 0.25) + 0.5)n_test = number_of_images - n_train - n_validprint(number_of_images, n_train, n_valid, n_test)for idx, file in enumerate(files):file_name = BASE_DIR + folder + fileif idx < n_train:shutil.move(file_name, BASE_DIR + 'train/' + names[folder_idx])elif idx < n_train + n_valid:shutil.move(file_name, BASE_DIR + 'val/' + names[folder_idx])else:shutil.move(file_name, BASE_DIR + 'test/' + names[folder_idx])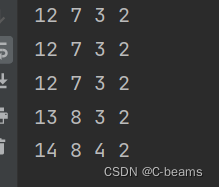
训练数据生成
train_gen = ImageDataGenerator(rescale=1./255)
val_gen = ImageDataGenerator(rescale=1./255)
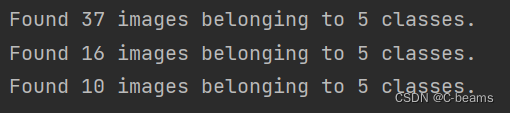
test_gen = ImageDataGenerator(rescale=1./255)train_batches = train_gen.flow_from_directory('lego/star-wars-images/train',target_size=(256, 256),class_mode='sparse',batch_size=4,shuffle=True,color_mode='rgb',classes=names,
)
查看其中一批次的样本
train_batch = train_batches[0]
test_batch = train_batches[0]
print(train_batch[0].shape)
print(train_batch[1])
print(test_batch[0].shape)
print(test_batch[1])def show(batch, pre_labels=None):plt.figure(figsize=(10, 10))for i in range(4):plt.subplot(2, 2, i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(batch[0][i], cmap=plt.cm.binary)# extra indexlbl = names[int(batch[1][i])]if pre_labels is not None:lbl += '/Pred:' + names[int(pre_labels[i])]plt.xlabel(lbl)plt.show()show(test_batch)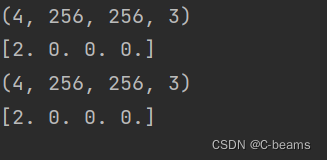

模型建立
model = keras.Sequential([layers.Conv2D(32, (3, 3), strides=(1, 1), padding='valid', activation='relu', input_shape=(256, 256, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, 3, activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(5),
])
# print(model.summary())model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer=keras.optimizers.Adam(0.001),metrics=['accuracy']
)model.fit(train_batches, validation_data=val_batches, epochs=30, verbose=2)
model.save('lego_model.h5')
绘制 loss 和 acc
# plot loss and acc
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='valid loss')
plt.grid()
plt.legend(fontsize=15)plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='train acc')
plt.plot(history.history['val_accuracy'], label='valid acc')
plt.grid()
plt.legend(fontsize=15);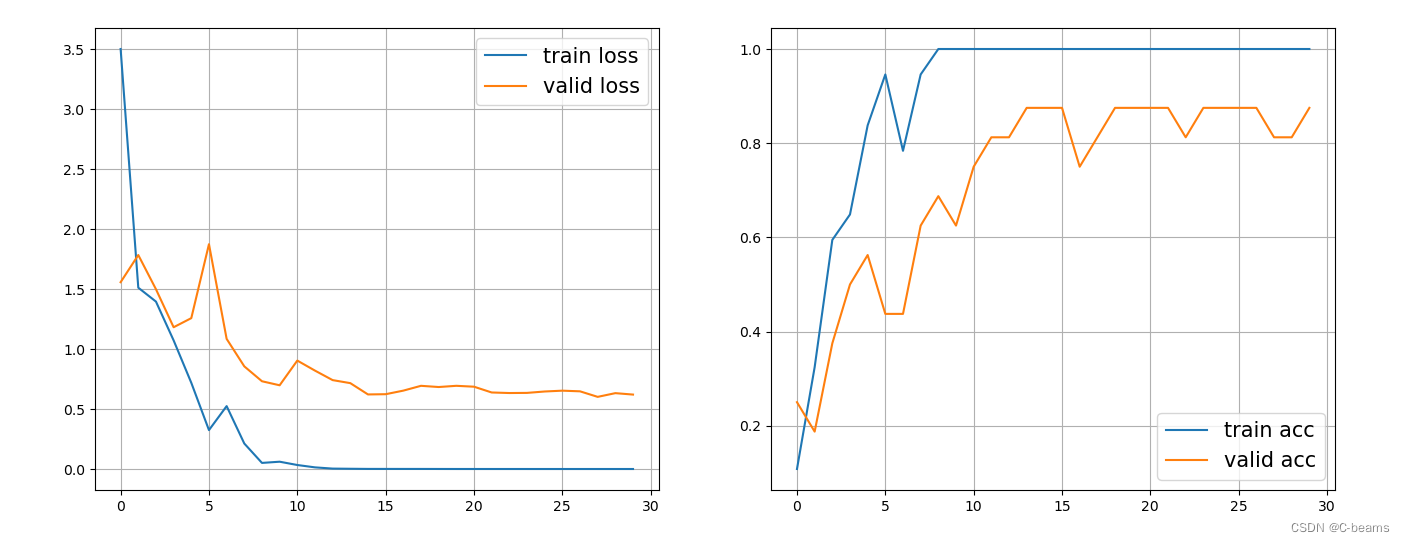
模型评估和预测
model.evaluate(test_batches, verbose=2)predictions = model.predict(test_batches)
predictions = tf.nn.softmax(predictions)
labels = np.argmax(predictions, axis=1)
print(test_batches[0][1])
print(labels[0:4])show(test_batches[0], labels[0:4])
