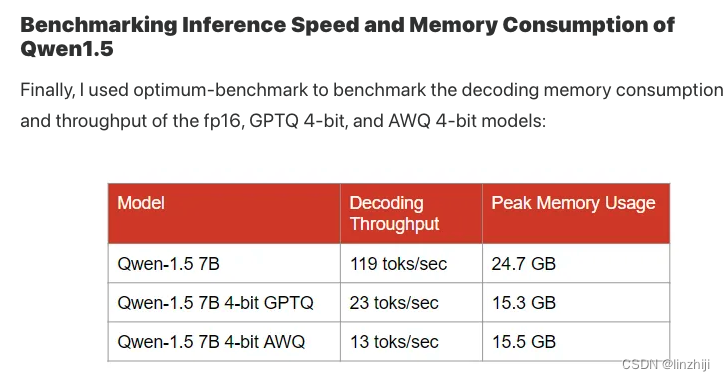
大语言模型量化方法对比:GPTQ、GGUF、AWQ 包括显存和速度
GPTQ: Post-Training Quantization for GPT Models
GPTQ是一种4位量化的训练后量化(PTQ)方法,主要关注GPU推理和性能。
该方法背后的思想是,尝试通过最小化该权重的均方误差将所有权重压缩到4位。在推理过程中,它将动态地将其权重去量化为float16,以提高性能,同时保持低内
gptq 常用4bit 8bit量化
GGUF:GPT-Generated Unified Format
GGUF(以前称为GGML)是一种量化方法,允许用户使用CPU来运行LLM,但也可以将其某些层加载到GPU以提高速度。
虽然使用CPU进行推理通常比使用GPU慢,但对于那些在CPU或苹果设备上运行模型的人来说,这是一种非常好的格式。
AWQ: Activation-aware Weight Quantization
AWQ(激活感知权重量化),它是一种类似于GPTQ的量化方法。AWQ和GPTQ作为方法有几个不同之处,但最重要的是AWQ假设并非所有权重对LLM的性能都同等重要。
也就是说在量化过程中会跳过一小部分权重,这有助于减轻量化损失。所以他们的论文提到了与GPTQ相比的可以由显著加速,同时保持了相似的,有时甚至更好的性能
awq 一种模型量化 常用4bit量化 精度比同级gptq高一些
以千问qwen 7B 为例,显卡A4000 16G显存
Qwen/Qwen1.5-7B-Chat
# modeIdOrPath="Qwen/Qwen1.5-14B-Chat-GPTQ-Int4"
modeIdOrPath="Qwen/Qwen1.5-7B-Chat"
# modeIdOrPath="Qwen/Qwen1.5-7B-Chat-AWQ" # the quantized model
# modeIdOrPath="Qwen/Qwen1.5-7B-Chat-GPTQ-Int8"
fType=torch.bfloat16
model = AutoModelForCausalLM.from_pretrained(modeIdOrPath,torch_dtype=fType,device_map='auto',# attn_implementation="flash_attention_2"
)初始加载显存占用 17G

http请求 翻译中文:Trump was always bothered by how Trump Tower fell 41 feet short of the General Motors building two blocks north.

平均速度 2-3秒
请求后显存占用18G左右

Qwen/Qwen1.5-7B-Chat 增加 flash_attention_2
model = AutoModelForCausalLM.from_pretrained(modeIdOrPath,torch_dtype=fType,device_map='auto',attn_implementation="flash_attention_2"
)初始显存占用 17G

速度还是2-3秒,没有明显变化

Qwen/Qwen1.5-7B-Chat-GPTQ-Int8
初始显存占用 11G

平均时间间隔 15 秒,比非量化模型慢了不少

跑了几个请求后,显存占用 12.7G

参考:
大语言模型量化方法对比:GPTQ、GGUF、AWQ - 知乎
https://kaitchup.substack.com/p/fine-tuning-and-quantization-of-qwen15