C/C++开发,无可避免的多线程(篇六).线程池封装类
一、线程池概念
线程池是一种多线程处理方式,它包含一个线程工作队列和一个任务队列。当有任务需要处理时,线程池会从线程工作队列中取出一个空闲线程来处理任务,如果线程工作队列中没有空闲线程,则任务会被放入任务队列中等待处理。当线程处理完任务后,它会返回线程工作队列中等待下一个任务的到来。线程池的好处是可以避免频繁创建和销毁线程,提高程序的效率和稳定性。
在c++中,所谓的任务队列就是一个双端队列,采用先进先出的原则,而任务则是一些系列的功能函数。所谓线程工作队列,就是一组线程,这些线程通常采用容器管理起来。
线程池可以应用于需要频繁创建和销毁线程的场景,例如网络服务器、数据库连接池等。通过线程池,可以提高线程的复用率,减少线程创建和销毁的开销,从而提高系统的性能和稳定性。同时,线程池还可以控制并发线程的数量,避免系统资源被过度占用,保证系统的可靠性和可用性。
线程池一般可以提高程序的效率,尤其是具有延时等待、复杂交互、共享线程等情况,因为它可以避免频繁地创建和销毁线程,从而减少了系统开销。同时,线程池还可以控制线程的数量,避免线程数量过多导致系统资源的浪费。在使用线程池时,需要注意线程安全问题,例如共享变量的访问、线程间的同步等。可以通过加锁、使用原子操作等方式来保证线程安全。但是有时候采用线程池是个不明智的举动,例如那些可以连续执行,无需等待,延时的纯计算场景。
二、任务队列设计
通常任务队列就是将一个个任务(即函数对象或函数指针)装载进一个队列内,然后各个线程从该队列中取出任务执行。任务进入队列遵循先进先出原则,当然复杂的可以给任务执行优先级,进入队列时按优先级排序。另外为了队列跨线程使用的安全,需要通过互斥变量来约束。
创建taskqueue.h和taskqueue.cpp源文件,在taskqueue.h创建一个TaskQueue类模板,其内置一个std::deque容器和一个std::mutex互斥锁及一些辅助变量,提供任务入列、出列、大小及空队列判断等成员函数,内容如下:
#ifndef _TASK_QUEUE_H_
#define _TASK_QUEUE_H_
/************************************************************************Copyright 2023-03-06, pyfree**File Name : taskqueue.h*File Mark : *Summary : *任务数据队列类,线程安全**Current Version : 1.00*Author : pyfree*FinishDate :**Replace Version :*Author :*FinishDate :************************************************************************/
#include <queue>
#include <mutex>
#include <string>template <typename T>
class TaskQueue
{
public:TaskQueue(std::string desc = "taskqueue_for_threadsafe");~TaskQueue();///*** 获取队列大小* @return {int } 队列大小*/size_t size();/*** 判定队列是否为空* @return {bool } 是否为空队列*/bool empty();/*** 获取队列头元素* @param it {T&} 头元素* @return {bool } 是否成功*/bool get_front(T &it);/*** 删除元素* @return {bool } 是否成功*/bool pop_front();/*** 获取队列头元素,并从队列终删除* @param it {T&} 头元素* @return {bool } 是否成功*/bool pop_front(T &it);/*** 从队列头开始逐步获取多个元素,并剔除* @param its {queue<T>&} 获取到的元素集* @param sizel {int} 一次获取多少个* @return {bool } 至少获取一个元素以上则成功*/bool get_queue(std::queue<T> &its,unsigned int sizel=5);/*** 从队列尾部添加元素* @param it {T} 被添加元素* @return {void } 无返回*/void add_back(T it);/*** 从队列头部添加元素* @param it {T} 被添加元素* @return {void } 无返回*/void add_front(T it);/*** 清空元素* @return {void }*/void clear();/*** 重置容器元素大小限制* @param sizel {unsigned int} 容器限制长度* @return {void }*/void reQSize(unsigned int sizel);
private:TaskQueue& operator=(const TaskQueue&) {return this;};void over_log(bool addfront_flag);
protected:std::string queue_desc;
private:/点集转发//协议解析结果缓存std::deque<T> cache_queue; //队列容器std::mutex m_Mutex; //线程锁,c++11unsigned int QSize; //队列大小约束,超出是会从队列头剔除旧数据腾出空位在对末添加数据int queue_overS; //队列溢出次数计数
};#include "taskqueue.cpp"#endif //_TASK_QUEUE_H_
由于这一个类模板,因此要遵循类模板声明定义分离一些规则,因此在头文件结尾添加了#include "taskqueue.cpp"(PS,本专栏的无可避免的模板编程实践(篇一)课题2.4节讲述过原因)。模板还定义了容器队列长度约束,防止容器一直添加内容而无线程处理的异常情况出现,并会打印容器溢出日志信息。类模板的TaskQueue定义放置在taskqueue.cpp实现,由于头文件结尾添加了#include "taskqueue.cpp",其实相当于是在头文件实现,这样分离只是为了统一排版。
#include "taskqueue.h"#include <stdio.h>template <typename T>
TaskQueue<T>::TaskQueue(std::string desc): queue_desc(desc), QSize(100), queue_overS(0)
{};template <typename T>
TaskQueue<T>::~TaskQueue()
{}
//
template <typename T>
size_t TaskQueue<T>::size()
{std::unique_lock<std::mutex> lock(m_Mutex);return cache_queue.size();
}template <typename T>
bool TaskQueue<T>::empty()
{std::unique_lock<std::mutex> lock(m_Mutex); return cache_queue.empty();
}template <typename T>
bool TaskQueue<T>::get_front(T &it)
{std::unique_lock<std::mutex> lock(m_Mutex);bool ret = !cache_queue.empty();if (ret) { it = cache_queue.front(); }return ret;
}template <typename T>
bool TaskQueue<T>::pop_front()
{std::unique_lock<std::mutex> lock(m_Mutex);bool ret = !cache_queue.empty();if (ret) { cache_queue.pop_front();}return ret;
}template <typename T>
bool TaskQueue<T>::pop_front(T &it)
{std::unique_lock<std::mutex> lock(m_Mutex);bool ret = !cache_queue.empty();if (ret) {it = cache_queue.front();cache_queue.pop_front();}return ret;
};template <typename T>
bool TaskQueue<T>::get_queue(std::queue<T> &its,unsigned int sizel)
{std::unique_lock<std::mutex> lock(m_Mutex);while (!cache_queue.empty()){its.push(cache_queue.front());cache_queue.pop_front();if (its.size() >= sizel){break;}}return !its.empty();
};template <typename T>
void TaskQueue<T>::add_back(T it)
{{std::unique_lock<std::mutex> lock(m_Mutex);if (cache_queue.size() > QSize) {queue_overS++;cache_queue.pop_front();}cache_queue.push_back(it);} over_log(false);
}template <typename T>
void TaskQueue<T>::add_front(T it)
{{std::unique_lock<std::mutex> lock(m_Mutex);if (cache_queue.size() > QSize) {queue_overS++;cache_queue.pop_front();}cache_queue.push_front(it);}over_log(true);
}template <typename T>
void TaskQueue<T>::clear()
{std::unique_lock<std::mutex> lock(m_Mutex);cache_queue.clear();queue_overS = 0;
}template <typename T>
void TaskQueue<T>::over_log(bool addfront_flag)
{if (queue_overS >= 10) {//每溢出10次,报告一次if(addfront_flag)printf("add item to queue %s at first,but the size of TaskQueue is up to limmit size: %d.\n", queue_desc.c_str(), QSize);elseprintf("add item to queue %s at end,but the size of TaskQueue is up to limmit size: %d.\n", queue_desc.c_str(), QSize); queue_overS = 0;}
}template <typename T>
void TaskQueue<T>::reQSize(unsigned int sizel)
{QSize = sizel;
}
其实一直跟着本人博客的应该很好理解这些代码,毕竟数据队列在前面将TCP/Socket通信开发实战案例博文内就讲述过,这里很类似,只是做了一些调整而已。
三、线程池类设计
线程池的设计,首选它包含一个任务队列,然后包括一组任务线程,这组线程采用std::vector来装载管理,任务线程是用来执行任务的。简单来说就是从任务队列取出任务,把活干了。
#ifndef _THREAD_EPOLL_H_
#define _THREAD_EPOLL_H_
#include "taskqueue.h"#include <functional>
#include <thread>
#include <future>class ThreadPool
{
public:ThreadPool(const int n_threads = 5); //线程池显式构造函数,默认创建及初始化5个线程~ThreadPool();void init(); // 初始化线程池void close(); // 等待正执行任务完成并关闭线程池void setTaskQSize(unsigned int sizel);// 提交一个任务(function)给线程池做异步处理template <typename F, typename... Args>auto addTask(F &&f, Args &&...args) -> std::future<decltype(f(args...))>;//指定auto返回值格式std::future<>friend class ThreadWorker; //友元线程工作类
private:ThreadPool(const ThreadPool &) = delete;ThreadPool(ThreadPool &&) = delete;ThreadPool &operator=(const ThreadPool &) = delete;ThreadPool &operator=(ThreadPool &&) = delete;
private:bool m_running; // 线程池是否处于运行态势TaskQueue<std::function<void()> > m_taskqueue; // 任务队列,跨线程安全std::vector<std::thread> m_threads; // 作业线程队列std::mutex m_conditional_mutex; // 线程休眠锁互斥变量std::condition_variable m_conditional_lock; // 线程环境锁,可以让线程处于休眠或者唤醒状态
};class ThreadWorker // 工作类线程
{
private:int m_id; // 工作idThreadPool *m_pool; // 所属线程池
public:ThreadWorker(ThreadPool *pool, const int id);// 构造函数void operator()(); // 重载()操作
};
#include "thread_pool.cpp" //有模板成员函数存在
#endif //_THREAD_EPOLL_H_
由于addTask函数是成员函数模板,因此同样在头文件末尾添加#include "thread_pool.cpp"。
下来就是实现线程池的重头戏了,其中最关键的就是添加任务进入队列的addTask函数,因为我们的任务队列元素是一个函数对象,采用的是通用多态函数包装器std::function类模板包裹的void()函数对象。而往线程池添加任务是各种函数及参数集。通过转发调用包装器std::bind函数模板,将传入函数及参数集转为函数对象,再由类模板 std::packaged_task包装可调用 (Callable) 目标函数,即std::bind函数模板绑定转换后的函数对象。最后采用std::make_shared函数模板将函数包装为 std::shared_ptr实例,随即将该实例通过lambda表达式的函数包装器,最终转换为满足可复制构造 (CopyConstructible) 和可复制赋值 (CopyAssignable)的函数对象void()加入任务队列。
thread_pool.cpp
#include "thread_pool.h"
//ThreadPool类
// 线程池构造函数
ThreadPool::ThreadPool(const int n_threads): m_threads(std::vector<std::thread>(n_threads)), m_running(false)
{
}ThreadPool::~ThreadPool()
{close();std::unique_lock<std::mutex> lock(m_conditional_mutex);m_taskqueue.clear();m_threads.clear();
}
//
void ThreadPool::init()
{for (int i = 0; i < m_threads.size(); ++i){m_threads.at(i) = std::thread(ThreadWorker(this, i)); // 分配工作线程}m_running = true;
}
//
void ThreadPool::close()
{m_running = false;m_conditional_lock.notify_all(); // 通知,唤醒所有工作线程for (int i = 0; i < m_threads.size(); ++i){if (m_threads.at(i).joinable()) // 判断线程是否在等待{m_threads.at(i).join(); // 将线程加入到等待队列}}
}void ThreadPool::setTaskQSize(unsigned int sizel)
{std::unique_lock<std::mutex> lock(m_conditional_mutex);m_taskqueue.reQSize(sizel);
}
// 关键函数
template <typename F, typename... Args>
auto ThreadPool::addTask(F &&f, Args &&...args) -> std::future<decltype(f(args...))>
{// 采用std::bind绑定函数f及形参集args...创建函数对象(decltype获取函数对象类型)std::function<decltype(f(args...))()> func = std::bind(std::forward<F>(f), std::forward<Args>(args)...); /*以 args-func 为 <T> 的构造函数参数列表,构造 T 类型对象并将它包装于 std::shared_ptr,*T是类模板 std::packaged_task 包装的可调用 (Callable) 目标函数,即std::bind绑定的f(arg...)*可移动的共享互斥体所有权包装,封装到共享指针中,支持复制构造,并隐藏了函数参数集*/auto task_ptr = std::make_shared<std::packaged_task<decltype(f(args...))()> >(func);//再次包装,构建一个lambda表达式的函数包装器,满足可复制构造 (CopyConstructible) 和可复制赋值 (CopyAssignable)的函数对象void()std::function<void()> warpper_func = [task_ptr](){(*task_ptr)();};m_taskqueue.add_back(warpper_func); // 队列通用安全封包函数,并压入安全队列m_conditional_lock.notify_one(); // 唤醒一个等待中的线程return task_ptr->get_future(); // 返回先前注册的任务指针,task_ptr类型为std::packaged_task
}
//ThreadWorker类
// 构造函数
ThreadWorker::ThreadWorker(ThreadPool *pool, const int id) : m_pool(pool), m_id(id)
{
}
// 重载()操作
void ThreadWorker::operator()()
{std::function<void()> func; // 定义基础函数类funcbool result = false; // 是否成功从队列中取出元素while (m_pool->m_running){{//锁脱离作用域解锁// 为线程环境加锁,互访问工作线程的休眠和唤醒std::unique_lock<std::mutex> lock(m_pool->m_conditional_mutex);if (m_pool->m_taskqueue.empty()) // 如果任务队列为空,阻塞当前线程{m_pool->m_conditional_lock.wait(lock); // 等待条件变量通知,开启线程}result = m_pool->m_taskqueue.pop_front(func); // 取出任务队列中的首元素}if (result) func(); // 如果成功取出,执行工作函数}
}
上述代码可以看到,创建的线程是以工作分配管理线程类ThreadWorker的operator操作函数(这个知识点可以参考本主题篇四的博文)为线程功能函数来实现线程循环体的,就是不断从任务队列中获取到任务,干活。
四、线程池应用测试
上面代码就设计了一个基本的线程池了,下来就调用问题。
创建test.h和test.cpp源文件,直接上代码,如下。有两个函数:函数threadPool_test顾名思义就是测试线程池的,main_doit用来测试纯主线程执行同等任务的效率;return_variance函数就带返回值的线程功能函数(即工作任务),out_variance函数是返回值为void,但是返回信息是通过参数引用传递的线程功能函数:
//test.h
#ifndef _TEST_H_
#define _TEST_H_void threadPool_test();
void main_doit();#endif //_TEST_H_
//test.cpp
#include <iostream>
#include <math.h>
#include <random>
#include <chrono>
#include <unistd.h> //usleep
#include "thread_pool.h"const unsigned int sizel = 100000;
auto end_poll = std::chrono::system_clock::now();double return_variance(int min, int max)
{if(min>max) return 0.0;int size = (max-min+1);double sum = ((double)(min+max)*size)/2.0;double mean = sum/size;// 求方差double variance = 0.0;for (int i = min ; i <= max ; i++){variance = variance + pow(i-mean,2);}variance = variance/size;// std::cout<<mean<<" \n"; // 均值// std::cout<<variance<<" \n"; // 方差//usleep(10); //让任务等待一下...//测试线程池执行效率使用,只能大概,毕竟先进先出if((min+1)==sizel) end_poll = std::chrono::system_clock::now(); return variance;
};void out_variance(double &out,int min, int max)
{out = return_variance(min,max);
};void main_doit()
{//测试主线程自己执行任务时,间隔时间// 提交方差操作,总共100个auto start = std::chrono::system_clock::now();for (size_t i = 0; i < sizel; i++){return_variance(i,i+rand()/sizel);}auto end = std::chrono::system_clock::now();std::chrono::duration<double> diff = end-start;std::cout << "main product and consum diff.count() = " << diff.count() << "\n";//主线程生成加执行一条龙
}
//
void threadPool_test()
{//测试线程池执行任务时,主线程经历间隔时间// 创建10个线程的线程池ThreadPool pool(10);pool.setTaskQSize(sizel);//重设队列大小限制,防止溢出// 初始化线程池pool.init();// 提交方差操作,总共100个auto start = std::chrono::system_clock::now();for (size_t i = 0; i < sizel; i++){pool.addTask(return_variance, i, i+rand()/sizel);}auto end = std::chrono::system_clock::now();std::chrono::duration<double> diff = end-start;start = std::chrono::system_clock::now();//生产完成时刻std::cout << "main product diff.count() = " << diff.count() << "\n";//主线程生成任务//取得返回值测试(任务结果)pool.setTaskQSize(100);//重新设回容器大小限制// 使用ref传递的输出参数提交函数double output_ref;auto future1 = pool.addTask(out_variance, std::ref(output_ref), 9, 99);// 等待操作输出完成future1.get();std::cout << "[9,99] variance is equals to " << output_ref << std::endl;// 使用return参数提交函数auto future2 = pool.addTask(return_variance, 8, 88);// 等待乘法输出完成double variance = future2.get();std::cout << "[8,88] variance is equals to " << variance << std::endl;// 关闭线程池pool.close();diff = end_poll-start;//线程池执行任务时间间隔std::cout << "main consum diff.count() = " << diff.count() << "\n";//线程池执行任务
}另外可以通过线程池的addTask返回对象(std::future)实现对函数返回值的获取,std::future的知识点见本课题的篇二的“3.6 线程辅助-Future”。
在main.cpp源文件内,调用者两个函数来测试:
#include "test.h"int main(int argc, char* argv[])
{threadPool_test();main_doit();return 0;
}编译及测试g++ main.cpp test.cpp -o test.exe -std=c++11,运行测程序:
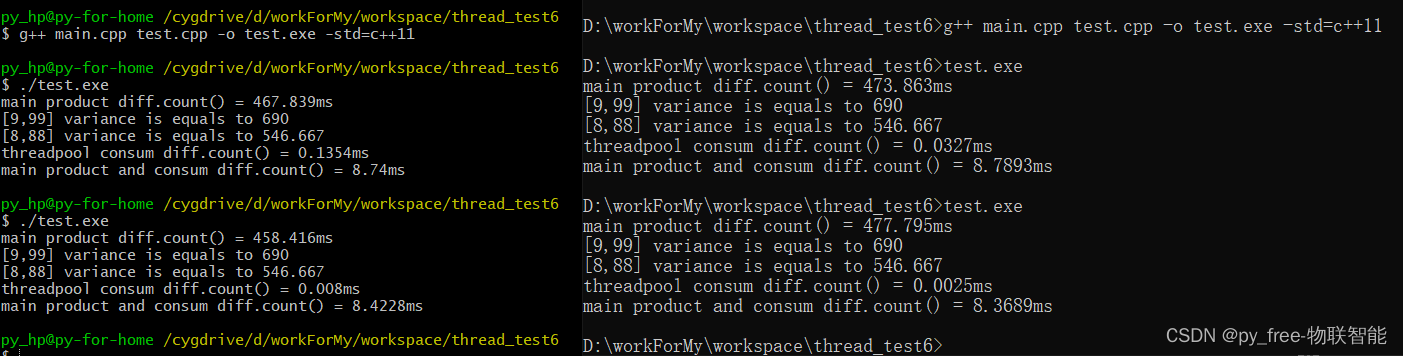 是不是很惊讶,多线程怎么还比主线程单独执行这些同等任务更高效。正如前面所说的,主线程向线程池添加任务是通过一些列转换的,目的就是为了适应各个功能函数转换为统一的函数对象,但是这样就增加了很多计算成本,以及线程锁的使用,各个线程进行了资源竞争,效率当然就差了。尤其还是这种纯粹计算、连续执行、无延时要求无等待要求的功能函数。
是不是很惊讶,多线程怎么还比主线程单独执行这些同等任务更高效。正如前面所说的,主线程向线程池添加任务是通过一些列转换的,目的就是为了适应各个功能函数转换为统一的函数对象,但是这样就增加了很多计算成本,以及线程锁的使用,各个线程进行了资源竞争,效率当然就差了。尤其还是这种纯粹计算、连续执行、无延时要求无等待要求的功能函数。
这就涉及到多线程编程最核心的问题了资源竞争。CPU有多核,可以同时执行多个线程是没有问题的。但是控制台(资源)却只有一个,同时只能有一个线程拥有这个唯一的控制台,将数字输出。大多情况下,程序可能只分配了一个CPU内核在运算(本例子任务对资源的诉求是没满足系统多核调度的判定),各个线程只是每次运行任务是抢占CPU的一段运行时间而已,各个线程之间(包括主线程)相互抢夺及切换要耗费大量时间,当然就没有单个主线程运行来得快。
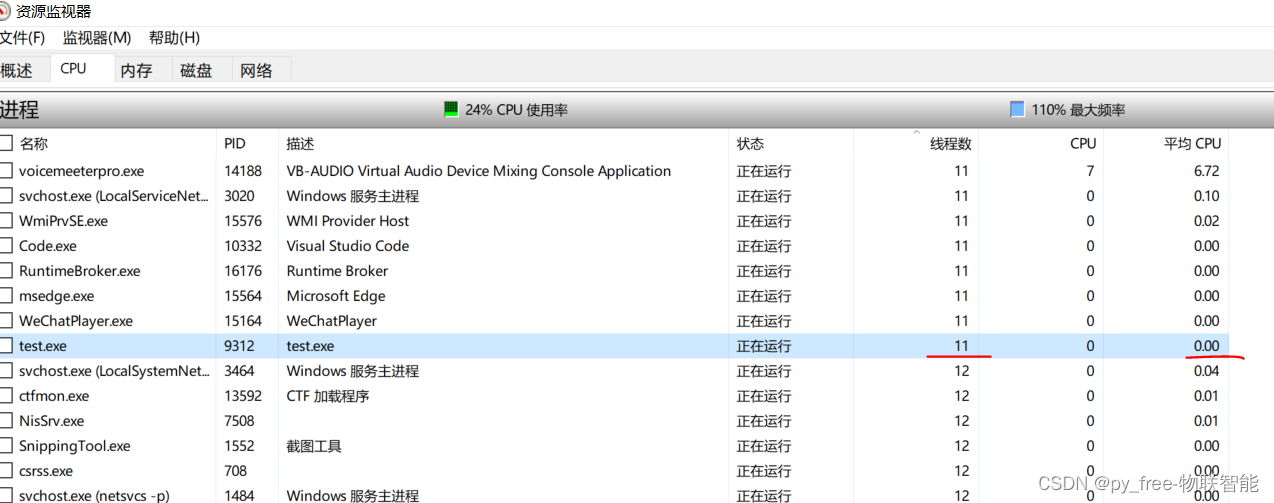
为此,又在关闭线程池前,加入了一句等待:
std::this_thread::sleep_for(std::chrono::seconds(100)); //等待,防止线程池没完成就退出了
// 关闭线程池
pool.close();重新编译测试,去资源监测器查看,的确创建了10个子线程,只是CPU使用压力太小,无法促使系统做出更多CPU资源的倾斜分配。
所有我们在开篇时就指出,线程池可以应用于需要频繁创建和销毁线程的场景,例如网络服务器、数据库连接池等,这些场景才是它们的主战场。
当然说到,在多CPU多核情况下,让各个线程运行在各个不同的CPU的内核上,和控制台线程(主线程)齐驱并驾,这就是多核并行,这就另外一个主题了。