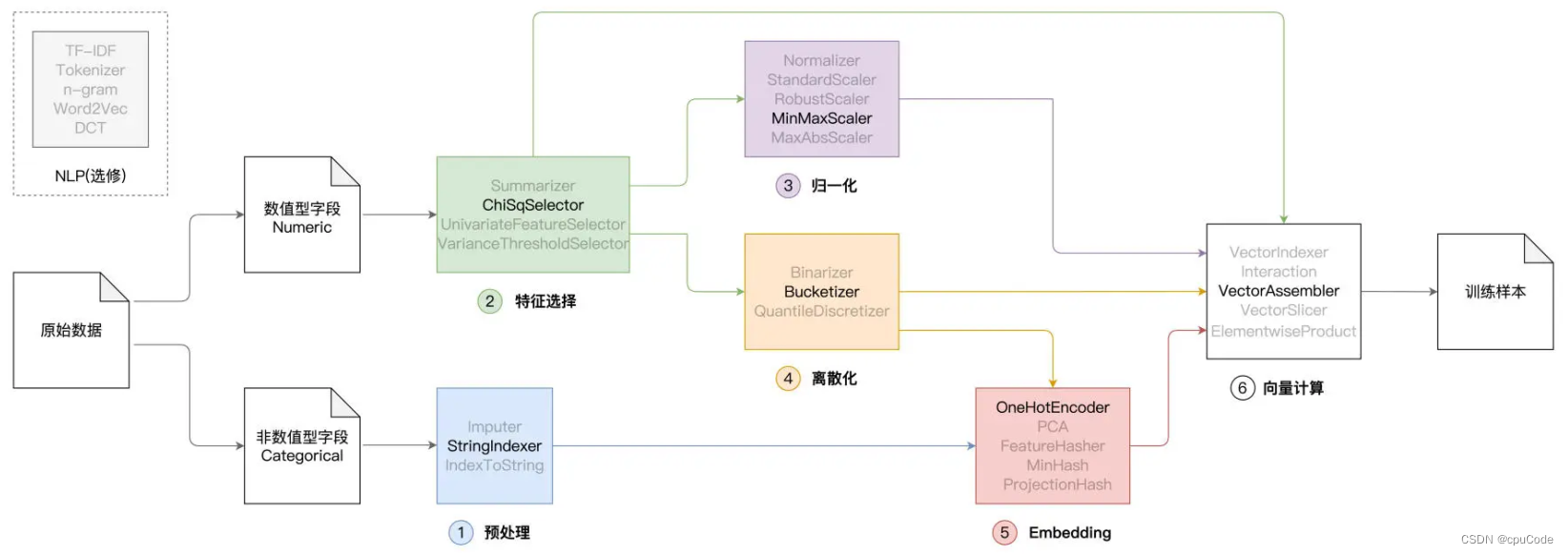
Spark MLlib 特征工程
Spark MLlib 特征工程
- 预处理
- 特征选择
- 归一化
- 离散化
- Embedding
- 向量计算
特征工程制约了模型效果 :
- 决定了模型效果的上限 , 而模型调优只是在不停地逼近上限
- 好的特征工程才能有好的模型
特征处理函数分类 :
- 预处理 : 将模型无法直接消费的数据,转为可消费的数据形式
- 特征选择 : 提取与预测标的关联度更高的特征,精简模型尺寸、提升模型泛化能力
- 归一化 : 去掉不同特征之间量纲的影响,避免因量纲不一致而导致的梯度下降震荡、模型收敛效率低下等问题
- 离散化 : 降低连续数值特征的多样性,让特征与预测标的之间建立更强的关联性
- Embedding : 将特征映射到向量空间,以向量形式刻画特征本身
- 向量计算 : 完成向量的拆分、拼接、运算,从而构建特征向量 (Feature Vectors),进而生成模型可消费的训练样本
预处理
预处理 : 把非数值字段转为数值字段
StringIndexer 作用 : 以数据列为单位,把字段中的字符串转为数值索引
- 如 : 把 GarageType 中的字符串转换为数字
StringIndexer 效果 :

StringIndexer 步骤 :
- 实例化 StringIndexer 对象
- 用 setInputCol 和 setOutputCol 指定输入列和输出列
- 用 fit 和 transform 函数,完成数据转换
读取房屋源数据并创建 DataFrame
import org.apache.spark.sql.DataFrame// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = _
val filePath: String = s"${rootPath}/train.csv"val sourceDataDF: DataFrame = spark.read.format("csv").option("header", true)
选出所有的非数值字段,并用 StringIndexer 转换
// 导入StringIndexer
import org.apache.spark.ml.feature.StringIndexer// 所有非数值型字段,即 : StringIndexer所需的“输入列”
val categoricalFields: Array[String] = Array("MSSubClass", "MSZoning", "Street");// 非数值字段对应的目标索引字段,也即StringIndexer所需的“输出列”
val indexFields: Array[String] = categoricalFields.map(_ + "Index").toArray// 将engineeringDF定义为var变量,后续所有的特征工程都作用在这个DataFrame之上
var engineeringDF: DataFrame = sourceDataDF// 核心代码:循环遍历所有非数值字段,依次定义StringIndexer,完成字符串到数值索引的转换
for ((field, indexField) <- categoricalFields.zip(indexFields)) {// 定义StringIndexer,指定输入列名、输出列名val indexer = new StringIndexer().setInputCol(field).setOutputCol(indexField)// 使用StringIndexer对原始数据做转换engineeringDF = indexer.fit(engineeringDF).transform(engineeringDF)// 删除掉原始的非数值字段列engineeringDF = engineeringDF.drop(field)
}
与 GarageType 数据列与数值索引 :
engineeringDF.select("GarageType", "GarageTypeIndex").show(3)/** 结果打印
+----------+---------------+
|GarageType|GarageTypeIndex|
+----------+---------------+
| Attchd| 0.0|
| Detchd| 1.0|
| Attchd| 0.0|
+----------+---------------+
*/
特征选择
特征选择 : 根据一定的标准,对特征字段进行选择
特征选择的标准 :
- 专家的经验初步选出特征集
- 用统计方法计算候选特征与预测标的的关联性
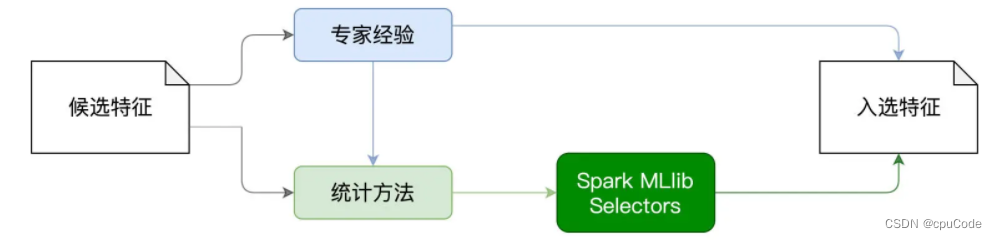
利用 ChiSqSelector 封装的统计方法是卡方检验与卡方分布
ChiSqSelector 选择数值型字段的步骤 :
- 用 VectorAssembler 创建特征向量
- 基于特征向量,用 ChiSqSelector 完成特征选择
VectorAssembler 作用 : 把多个数值列捏合为一个特征向量
- 例子 : 房屋的三个数值列 , 进行捏合成一个新的向量字段
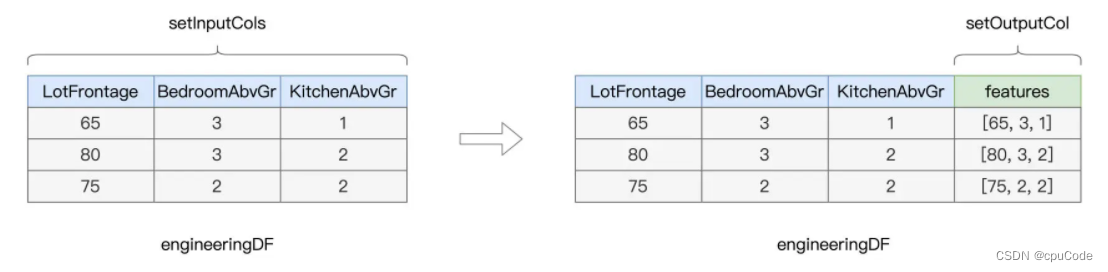
VectorAssembler 用法 :
// 所有数值型字段,共有27个
val numericFields: Array[String] = Array("LotFrontage", "LotArea", "MasVnrArea");// 预测标的字段
val labelFields: Array[String] = Array("SalePrice")import org.apache.spark.sql.types.IntegerType// 将所有数值型字段,转换为整型Int
for (field <- (numericFields ++ labelFields)) {engineeringDF = engineeringDF.withColumn(s"${field}Int",col(field).cast(IntegerType);
} import org.apache.spark.ml.feature.VectorAssembler// 所有类型为Int的数值型字段
val numericFeatures: Array[String] = numericFields.map(_ + "Int").toArray
// 定义并初始化VectorAssembler
val assembler = new VectorAssembler().setInputCols(numericFeatures).setOutputCol("features")// 在DataFrame 应用 VectorAssembler,生成特征向量字段"features"
engineeringDF = assembler.transform(engineeringDF)
基于特征向量进行特征选择
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.feature.ChiSqSelectorModel// 定义并初始化ChiSqSelector
// 挑选最影响的前 20 个特征
val selector = new ChiSqSelector().setFeaturesCol("features").setLabelCol("SalePriceInt").setNumTopFeatures(20)// 调用fit函数,在DataFrame之上完成卡方检验
val chiSquareModel = selector.fit(engineeringDF)
// 获取ChiSqSelector选取出来的入选特征集合(索引)
val indexs: Array[Int] = chiSquareModel.selectedFeaturesimport scala.collection.mutable.ArrayBufferval selectedFeatures: ArrayBuffer[String] = ArrayBuffer[String]()
// 根据特征索引值,查找数据列的原始字段名
for (index <- indexs) {selectedFeatures += numericFields(index)
}
ChiSqSelector工作流程 :
- ChiSqSelector 记录了 0/1 索引,对应 LotFrontage / BedroomAbvGr

归一化
归一化 (Normalization) 作用 : 把一组数值,统一映射到同一个值域,该值域通常是 [0, 1]
归一化的意义 :
- 当原始数据之间的量纲差异较大时,模型训练时,梯度下降不稳定、抖动较大,模型不容易收敛,从而导致训练效率较差
- 当所有特征数据都被约束到同一个值域时,模型训练的效率就会大幅提升
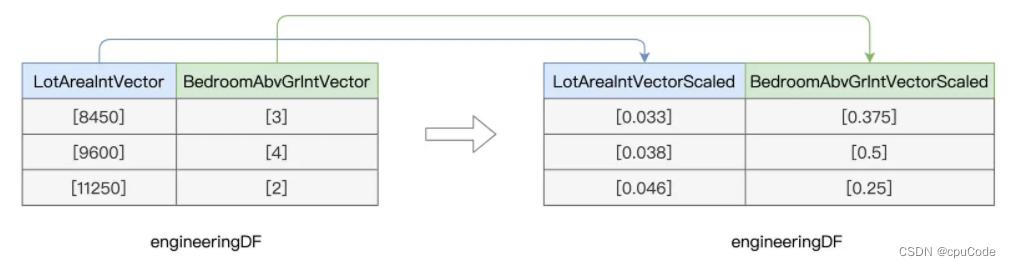
MinMaxScaler 用法 :
- 用 VectorAssembler 创建特征向量
- 基于特征向量,用 MinMaxScaler 完成归一化
// 所有类型为Int的数值型字段
// val numericFeatures: Array[String] = numericFields.map(_ + "Int").toArray// 遍历每一个数值型字段
for (field <- numericFeatures) {// 定义并初始化VectorAssemblerval assembler = new VectorAssembler().setInputCols(Array(field)).setOutputCol(s"${field}Vector")// 调用transform把每个字段由Int转换为Vector类型engineeringData = assembler.transform(engineeringData)
}import org.apache.spark.ml.feature.MinMaxScaler// 锁定所有Vector数据列
val vectorFields: Array[String] = numericFeatures.map(_ + "Vector").toArray
// 归一化后的数据列
val scaledFields: Array[String] = vectorFields.map(_ + "Scaled").toArray// 循环遍历所有Vector数据列
for (vector <- vectorFields) {// 定义并初始化MinMaxScalerval minMaxScaler = new MinMaxScaler().setInputCol(vector).setOutputCol(s"${vector}Scaled")// 使用MinMaxScaler,完成Vector数据列的归一化engineeringData = minMaxScaler.fit(engineeringData).transform(engineeringData)
}
MinMaxScaler 归一化 :
离散化
离散化作用 : 把原本连续的数值打散,降低原始数据的多样性(Cardinality)
- 如 : 居室数量 (BedroomAbvGr),包含从 1 - 8 的连续整数
离散化的意义 : 提升特征数据的区分度与内聚性,实现与预测标的产生更强的关联
BedroomAbvGr离散化 :
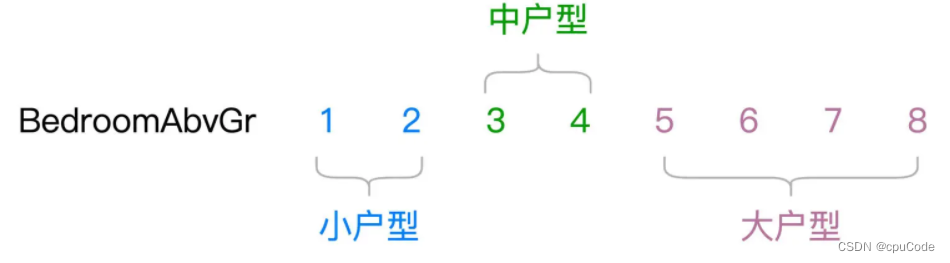
离散化的用法 :
// 原始字段
val fieldBedroom: String = "BedroomAbvGrInt"
// 包含离散化数据的目标字段
val fieldBedroomDiscrete: String = "BedroomDiscrete"// 指定离散区间,分别是[负无穷, 2]、[3, 4]和[5, 正无穷]
val splits: Array[Double] = Array(Double.NegativeInfinity, 3, 5, Double.PositiveInfinity)import org.apache.spark.ml.feature.Bucketizer// 定义并初始化Bucketizer
val bucketizer = new Bucketizer()// 指定原始列.setInputCol(fieldBedroom)// 指定目标列.setOutputCol(fieldBedroomDiscrete)// 指定离散区间.setSplits(splits)// 调用transform完成离散化转换
engineeringData = bucketizer.transform(engineeringData)
离散化前后对比 :
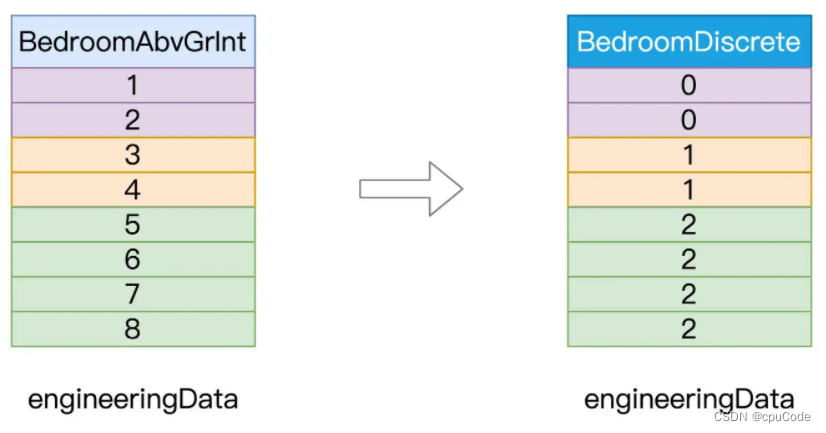
Embedding
Embedding 过程 : 把数据集合映射到向量空间,进而把数据进行向量化的过程
热独编码 (One Hot Encoding) :
- 通过 StringIndexer 把 GarageType 映射成六个数值
- 用热独编码,把每个数值都转为一个向量

把索引字段转为向量字段 :
import org.apache.spark.ml.feature.OneHotEncoder// 非数值字段对应的目标索引字段,也即StringIndexer所需的“输出列”
// val indexFields: Array[String] = categoricalFields.map(_ + "Index").toArray// 热独编码的目标字段,也即OneHotEncoder所需的“输出列”
val oheFields: Array[String] = categoricalFields.map(_ + "OHE").toArray// 循环遍历所有索引字段,对其进行热独编码
for ((indexField, oheField) <- indexFields.zip(oheFields)) {val oheEncoder = new OneHotEncoder().setInputCol(indexField).setOutputCol(oheField)engineeringData= oheEncoder.transform(engineeringData)
}
向量计算
向量计算作用 : 构建训练样本中的特征向量 (FeatureVectors)
构建特征向量 :
import org.apache.spark.ml.feature.VectorAssembler/**
入选的数值特征:selectedFeatures
归一化的数值特征:scaledFields
离散化的数值特征:fieldBedroomDiscrete
热独编码的非数值特征:oheFields
*/
val assembler = new VectorAssembler().setInputCols(selectedFeatures ++ scaledFields ++ fieldBedroomDiscrete ++ oheFields).setOutputCol("features")engineeringData = assembler.transform(engineeringData)
定义出线性回归模型 :
// 定义线性回归模型
val lr = new LinearRegression().setFeaturesCol("features").setLabelCol("SalePriceInt").setMaxIter(100)// 训练模型
val lrModel = lr.fit(engineeringData)
// 获取训练状态
val trainingSummary = lrModel.summary// 获取训练集之上的预测误差
println(s"Root Mean Squared Error (RMSE) on train data: ${trainingSummary.root}");