tensorflow入门 自定义模型
前面说了自定义的层,接下来自定义模型,我们以下图为例子
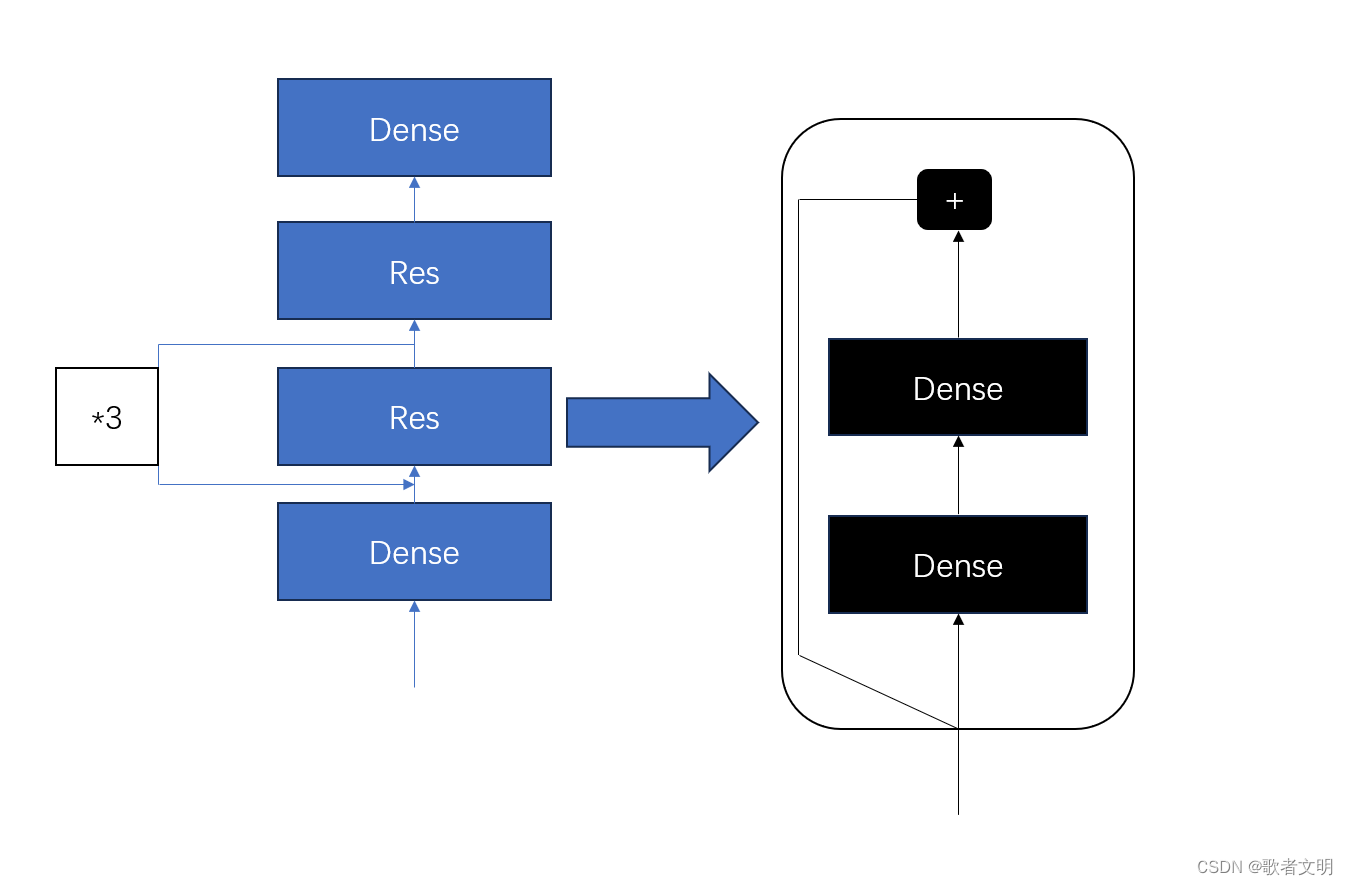
这个模型没啥意义,单纯是为了写代码实现这个模型
首先呢,我们看有几个部分,dense不需要我们实现了,我们就实现Res,为了实现那个*3,我们注意这个res可能需要多个res堆叠。
class ResBlock(keras.layers.Layer):def __init__(self, n_layers, n_neurons, **kwargs):super().__init__(**kwargs)self.hidden =[keras.layers.Dense(n_neurons,activation='elu',kernel_initializer='he_normal')for _ in range(n_layers)]def call(self, inputs):Z = inputsfor layer in self.hidden:Z = layer(Z)return inputs + Z这样我们就能实现一个可以循环的Res了,call是必须的,因为在计算的时候需要它
如果我们写得再详细一点,可能要加入built,如果需要保存和加载模型,我们需要get_congit和save_congit,总之,基本的样子就是如此。
为了防止搞错,解释以下为什么没有使用built,是为了偷懒。
下面我们构建模型的时候,会指定输入的维度,其实再通用的情况下,我们根本不知道输入的维度,built会自动推断输入维度,所有本来应该写个built的,但是睡觉时间到了。
然后我们基于上面的自定义层,实现左边的模型
def ResModel(keras.Model):def __init__(self, out, **kwargs):super().__init__(*kwargs)self.hidden1 = keras,layers,Dense(30, activation='elu', kernel_initializer='he_normal')self.block1 = ResBlock(2,10)self.block2 = ResBlock(2,20)self.out = keras,layers,Dense(out)def call(self, inputs):Z = self.hidden1(inputs)for _ in range(4):Z = self.block1(Z)Z = self.block2(Z)return self.out(Z)我觉得在此以及无需多言了。睡觉睡觉。