可以写进简历的kafka优化-----吞吐量提升一倍的方法
冲突
在看到项目工程里kafka 生产端配置的batch.size为500,而实际业务数据平均有1K大小的时候;我有点懵了。是的,这里矛盾了;莫非之前的作者认为这个batch.size是发送的条数,而不是kafka生产端内存缓存记录的大小? 实际业务数据有1K大小;那么正式环境的生产端岂不是没有用到kafka缓存池带来的好处。
最近也正在了解并解读kafka生产端源码,被kafka的设计所折服时;恼人的现实和美好的理论存在巨大的矛盾, 引起了我的怀疑和推测。怎么办?先和技术领导沟通下吧。
在请教过技术领导为什么这里设置为500时,获得了一个非预期的回答:“这个项目已经稳定运行5年了,也没什么问题呀”; 想必大家也遇到过类似的情况吧~~
想要说服领导,更改这个不是最优的设置,需要拿出更多的证据。如何去做了?
求证之路
为了验证batch.size 为500不是最优的(其实是为了验证kafka发送端用缓存池还是不用缓存池的区别)。写了两个对比不超过10行代码的kafka生产端代码。
第一个case是:发送固定100W消息量。对比batch 500B 和16K 两者的耗时,GC次数,GC耗时等的对比
第二个case是:在固定时间内。对比batch 500B和16K两者发送消息量,GC次数,GC耗时等的对比
当然msg大小为业务大小固定1KB。
具体代码如下
case1: 发送固定100W消息量,耗时,GC等信息对比
java 发送端代码
long begin = System.currentTimeMillis();
for(int j=1000;j>0;j--){for(int i=0;i<1000;i++){kafkaProducerTest.send(topic,msg);}kafkaProducerTest.flush();//每发送1000次,sleep 500毫秒try {Thread.sleep(500);} catch (InterruptedException e) {throw new RuntimeException(e);}
}
long end = System.currentTimeMillis();
log.info("cast time:" + (end-begin));
监控工具: jstat
使用了JVM 原生的GC 监控工具对GC次数和耗时进行监控
命令如下
jstat -gcutil pid 1000
输出:主要是看YGC,YGCT,FGC,FGCT,GCT
统计结果

为了减小误差,每个batch.size,都测试了两遍,取平均值做为底数。
从统计结果可看到
- 使用了缓存池,比不使用,耗时减少了64.51%。(这里减了500*1000,是为了减少sleep(500)的影响),吞吐量也就提高了一倍
- 使用了缓存池,比不使用,GC次数降低了27%,GC耗时减少了39%
数据还蛮符合事先猜测:吞吐量,GC次数,GC耗时;在使用了缓存池后都比不使用要优异
case2 持续3分钟,两者发送消息量的统计,GC等信息统计
java代码
long maxTime = 3 * 60 * 1000l;while (true){for(int i=0;i<1000;i++){kafkaProducerTest.send(topic,msg);}count ++;kafkaProducerTest.flush();//发送1000条,sleep 10毫秒try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}//只跑maxTimeif(System.currentTimeMillis() - begin > maxTime){break;}
}
log.info("count:" + count);
统计结果
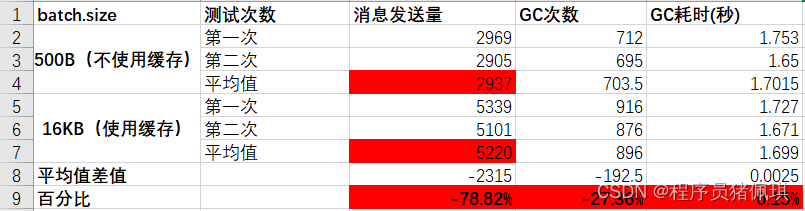
从统计结果可看到
- 使用了缓存池,比不使用缓冲池;消息发送量提高了78%。即在相同时间内,使用缓冲池,能提高1倍以上的吞吐量
- 使用了缓存池,比不使用缓冲池;GC次数大概提高了27%,而GC耗时基本相同。
总结
从上面的统计来看,如果想要提高发送消息吞吐量,请尽量使用缓存池。你的项目中,真的使用了缓存池吗?
曾经解读过kafka生产端内存模型的设计;以及由kafka内存池模型设计,联想到多年前初学java时的认知。始终感觉有点偏向理论,这篇算出一个对之前理论性设计的论证,实际实践后的数据证据吧。如果要用一句话来总结这次的感悟和行动,想借用陆游的一句大家都很熟悉的绝句来描述:纸上得来终觉浅,绝知此事要躬行。
参考资料:
https://blog.csdn.net/chenhcao628/article/details/108038172 《jstat -gcuti命令分析 》
https://juejin.cn/post/7259300929026916409 《读kafka生产端源码,窥kafka设计之道(下)》
https://juejin.cn/post/7259300929026916409 《java内存管理 美好的期望与现实的残酷》
《深入理解Kafka:核心设计与实践原理》
《kafka源码》