Puppeteer入门实践
环境
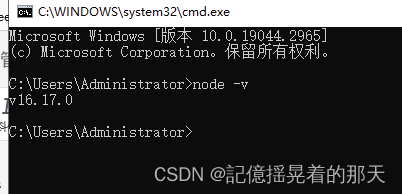
1、安装nodejs
官网:https://nodejs.org/zh-cn
下载安装好nodejs只后
验证:node -v 出现版本号表示安装成功,否则需要配置环境变量
2、创建node项目并初始化
随便新建一个文件夹
进入文件夹搜索cmd回车
 执行
执行npm init -y
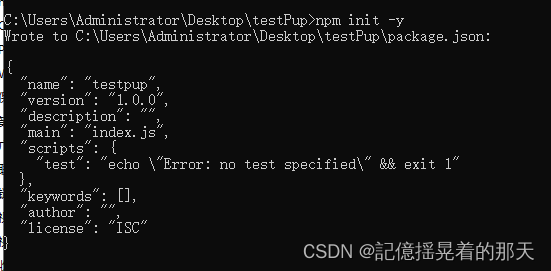
安装依赖
使用vscode或webStorm打开项目,我这里使用WebStorm进行演示 安装puppeteer依赖
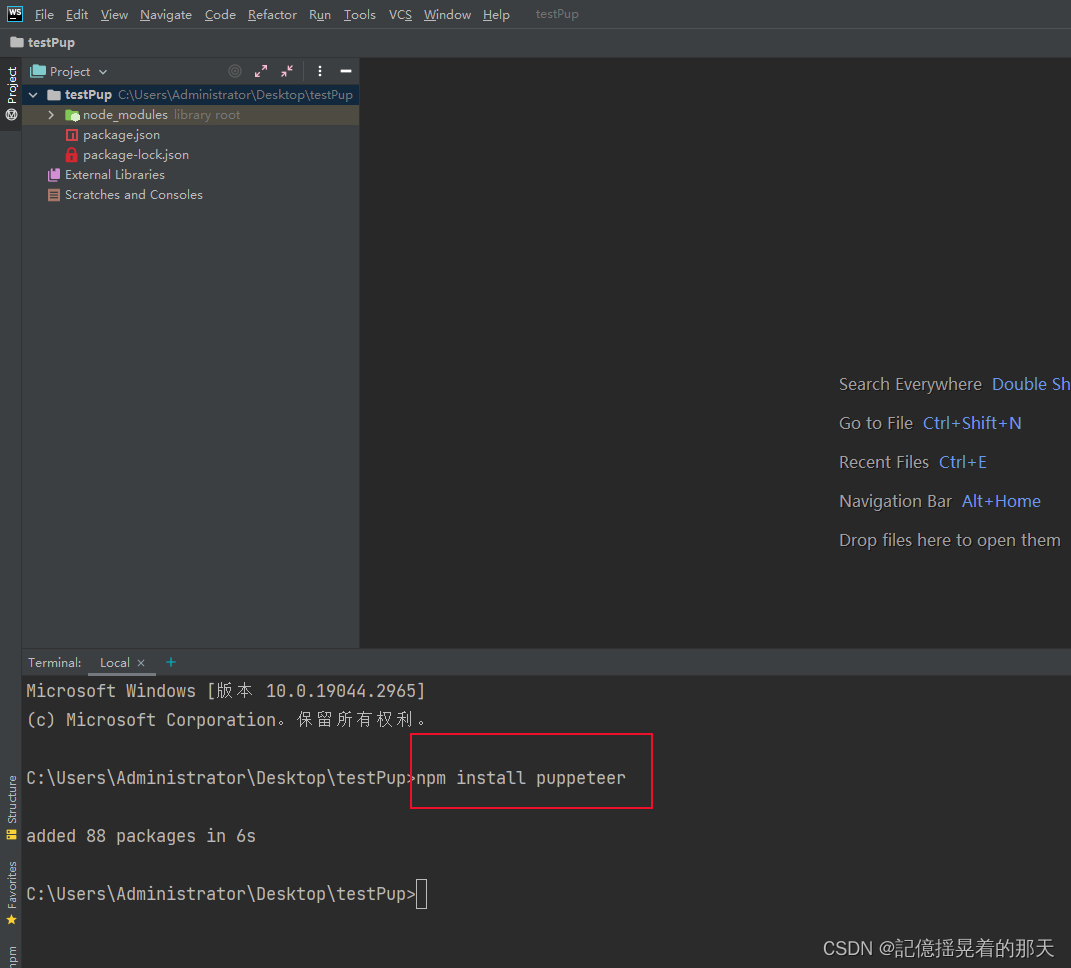
安装puppeteer依赖npm install puppeteer
随便新建一个test.js
中文文档:https://puppeteer.bootcss.com/
粘贴文档中的例子看下环境是否有问题
const puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch();const page = await browser.newPage();await page.goto('https://example.com');await page.screenshot({path: 'example.png'});await browser.close();
})();
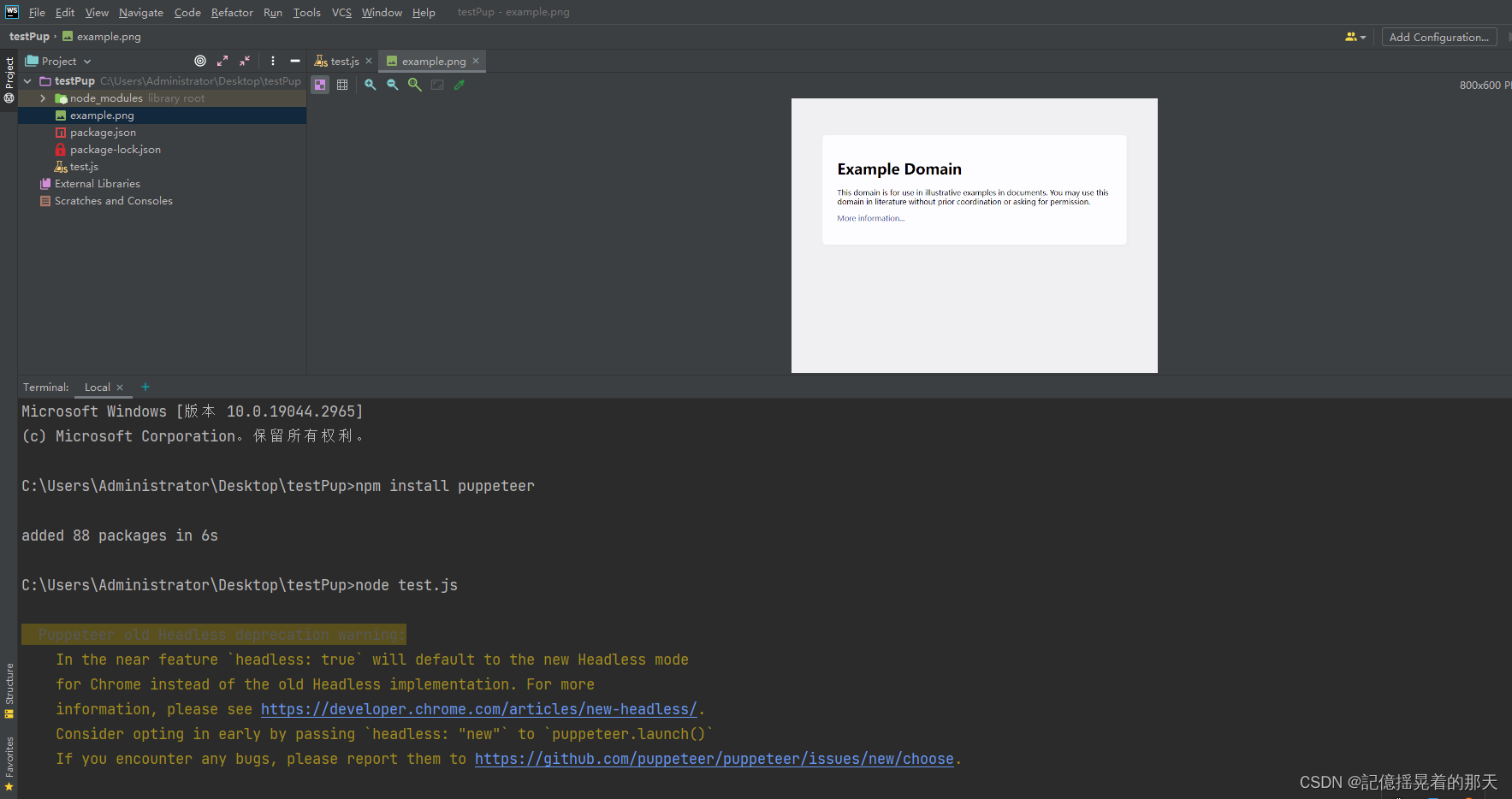
运行node ./test.js,成功截图
选择器
浏览器:谷歌浏览器
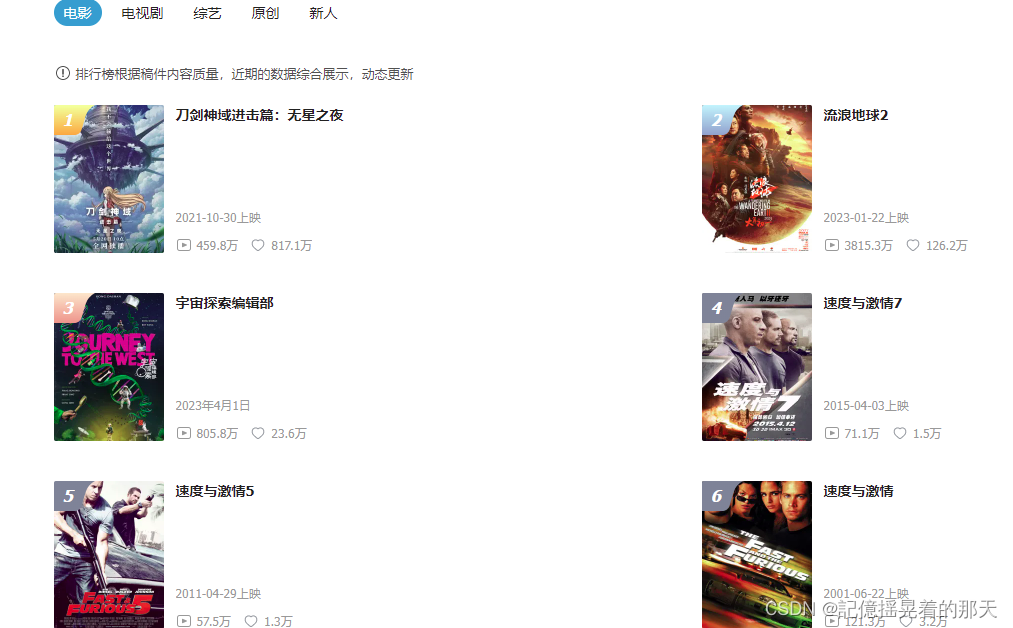
本次实践抓取B站热播榜top100的电影信息https://www.bilibili.com/movie/?spm_id_from=333.1007.0.0
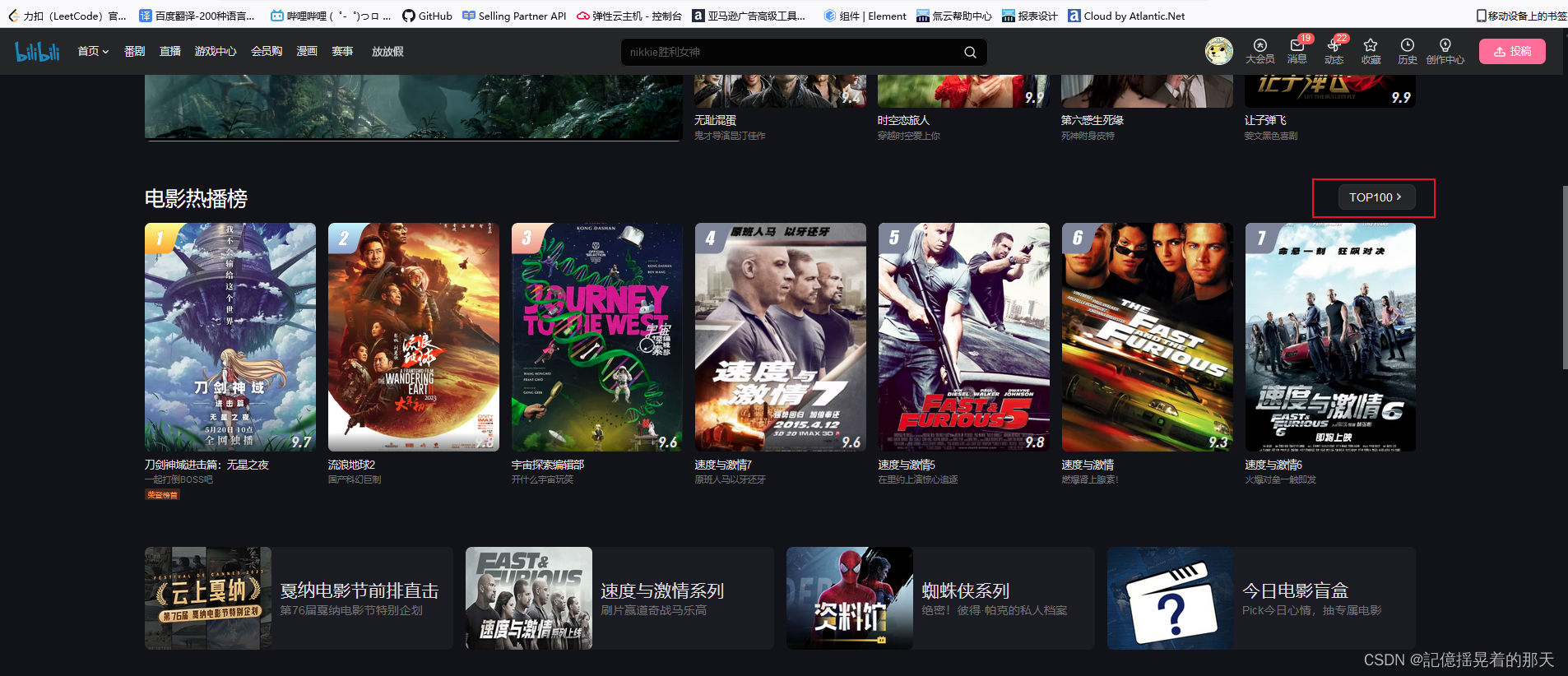 点击进入top100,进来后的url :
点击进入top100,进来后的url : https://www.bilibili.com/v/popular/rank/movie/?from_spmid=666.7.hotlist.more
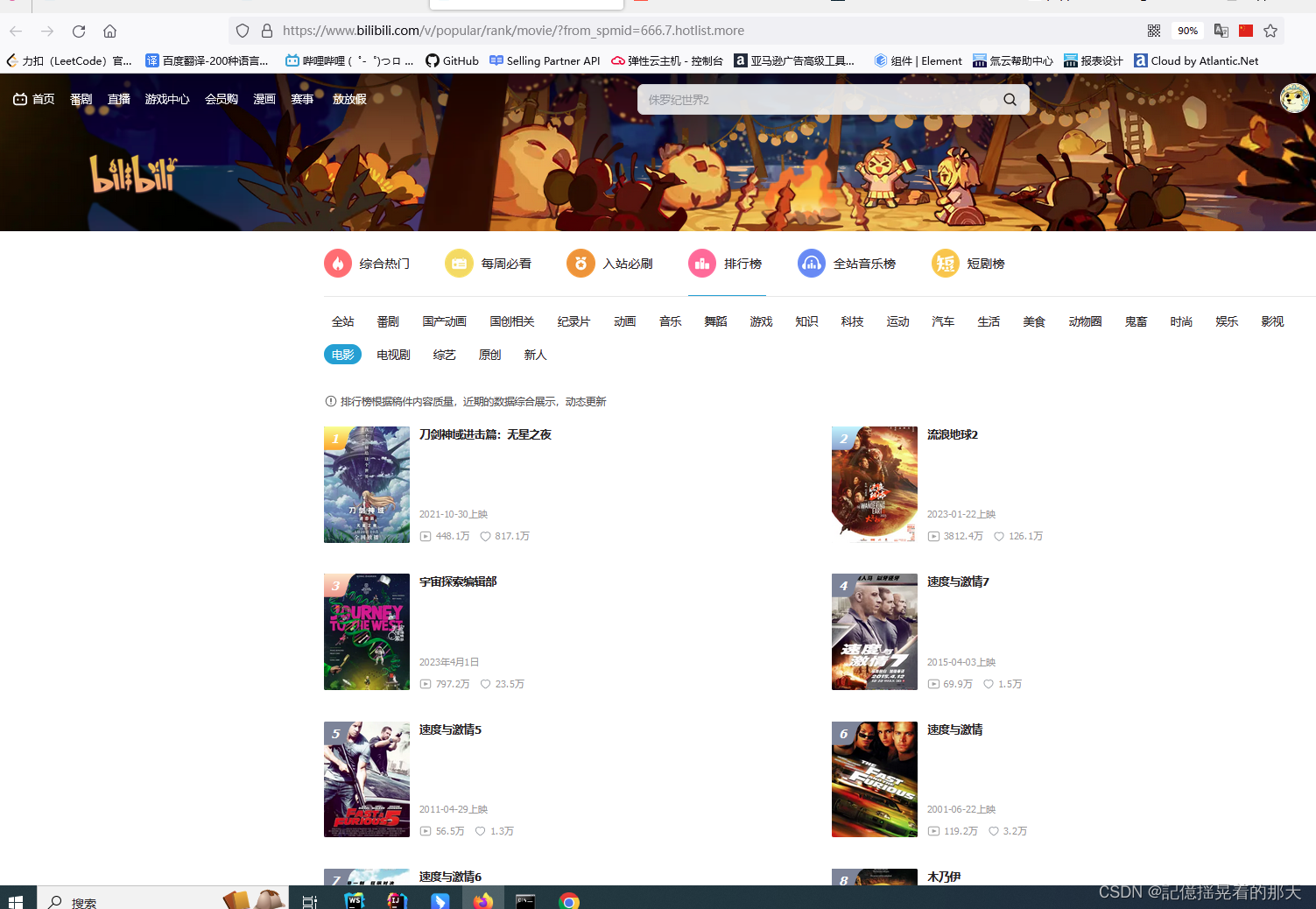
右击排行第一的影片,点击检查
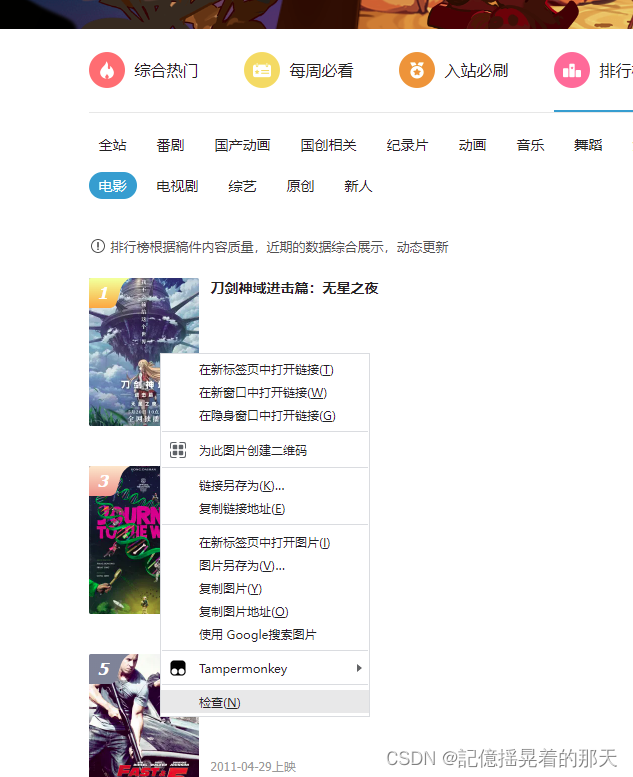
可以看到右边的代码和左边的界面上阴影部分是对应的
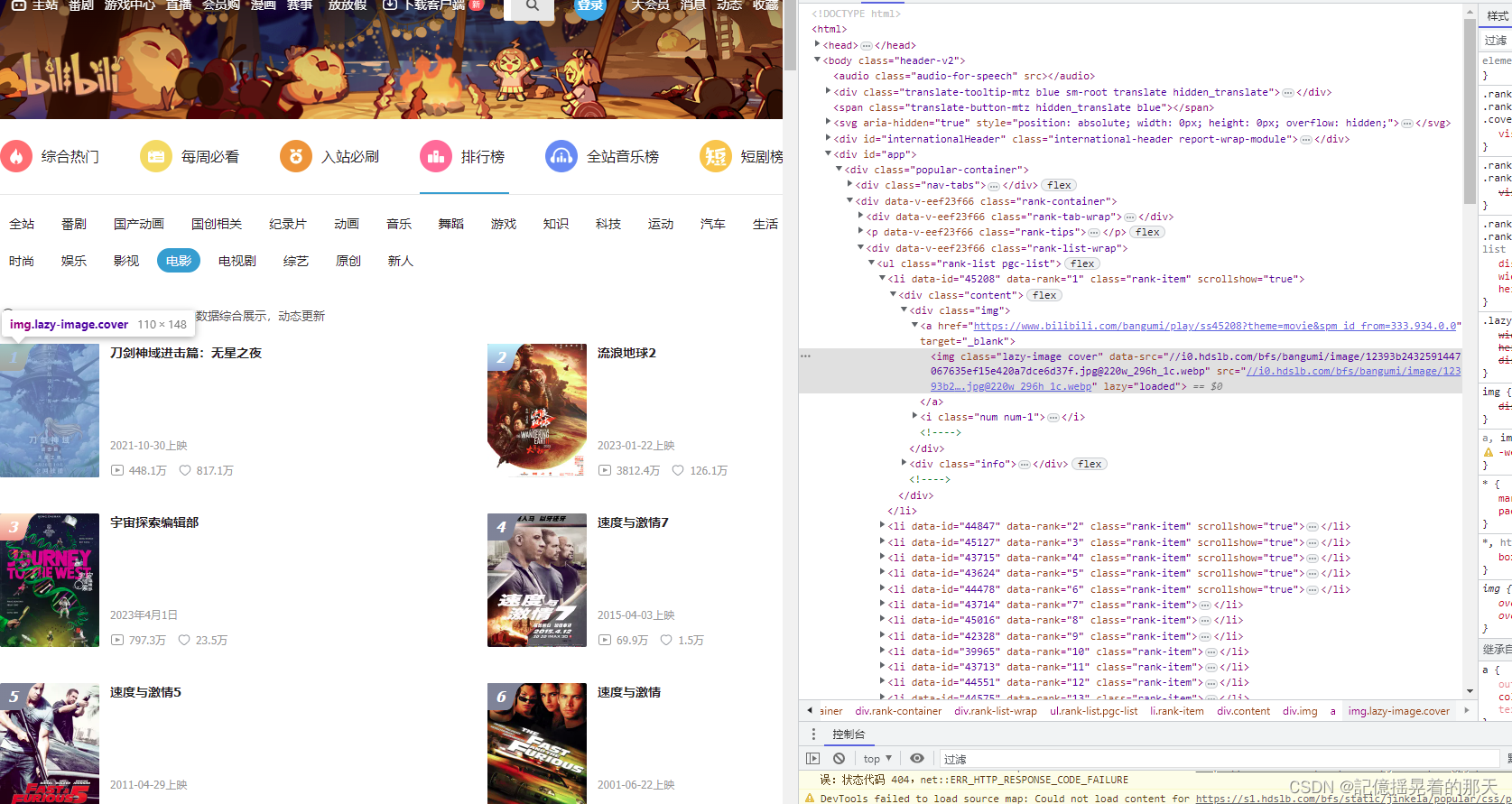 我们需要找到一块区域包含所有top100的元素标签
我们需要找到一块区域包含所有top100的元素标签
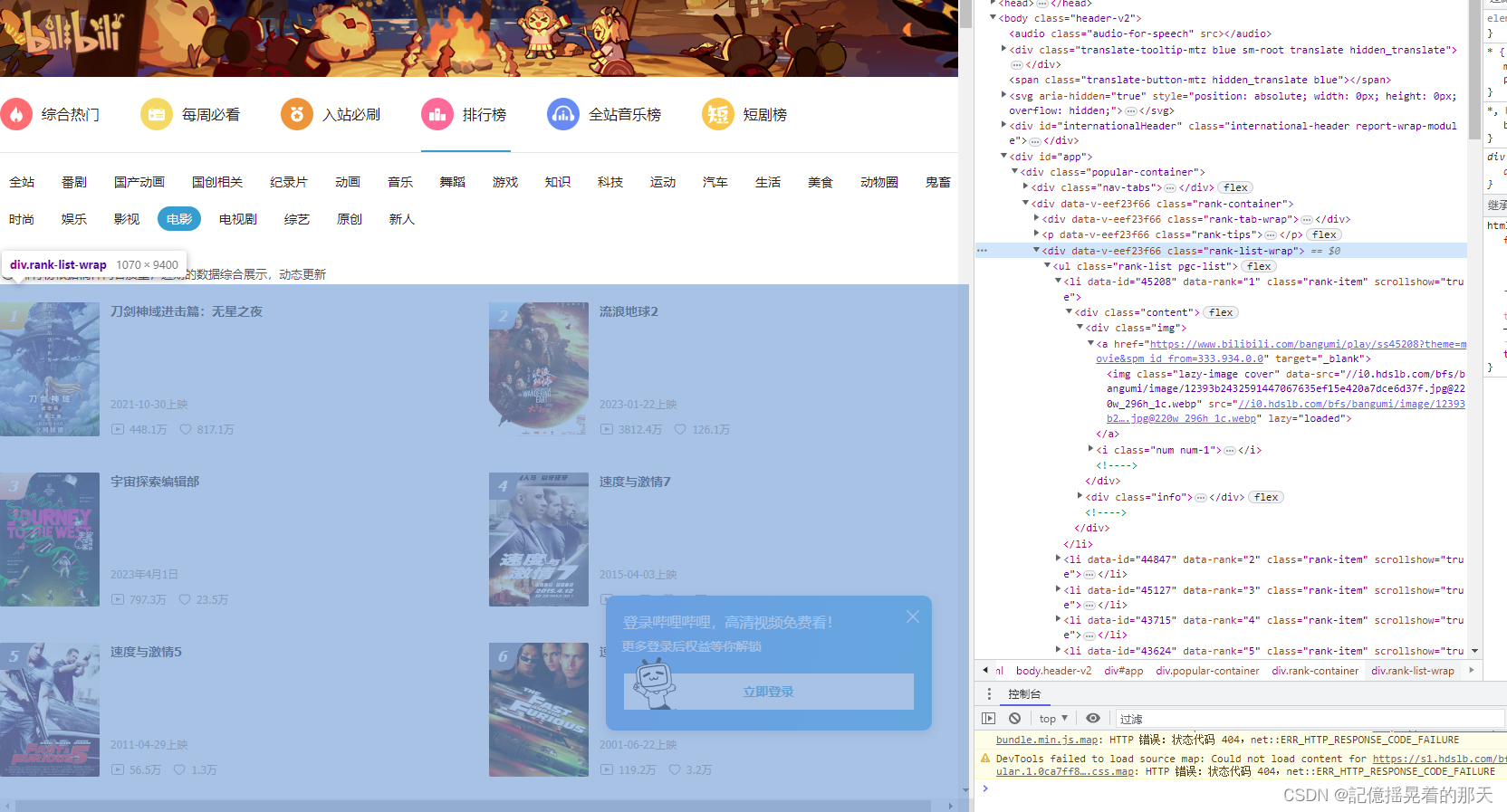 右键元素 -> 复制 -> 复制选择器
右键元素 -> 复制 -> 复制选择器
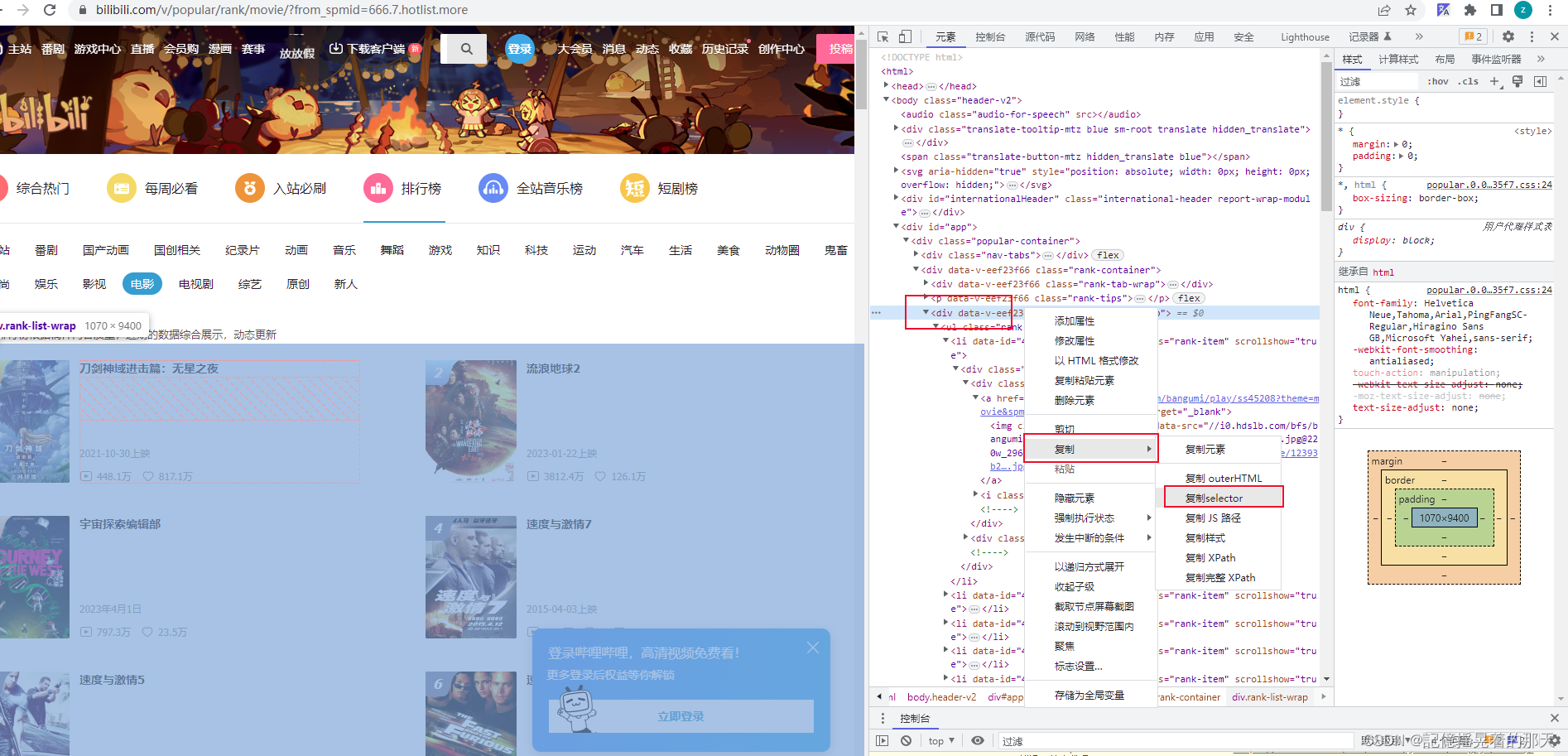
打开控制台
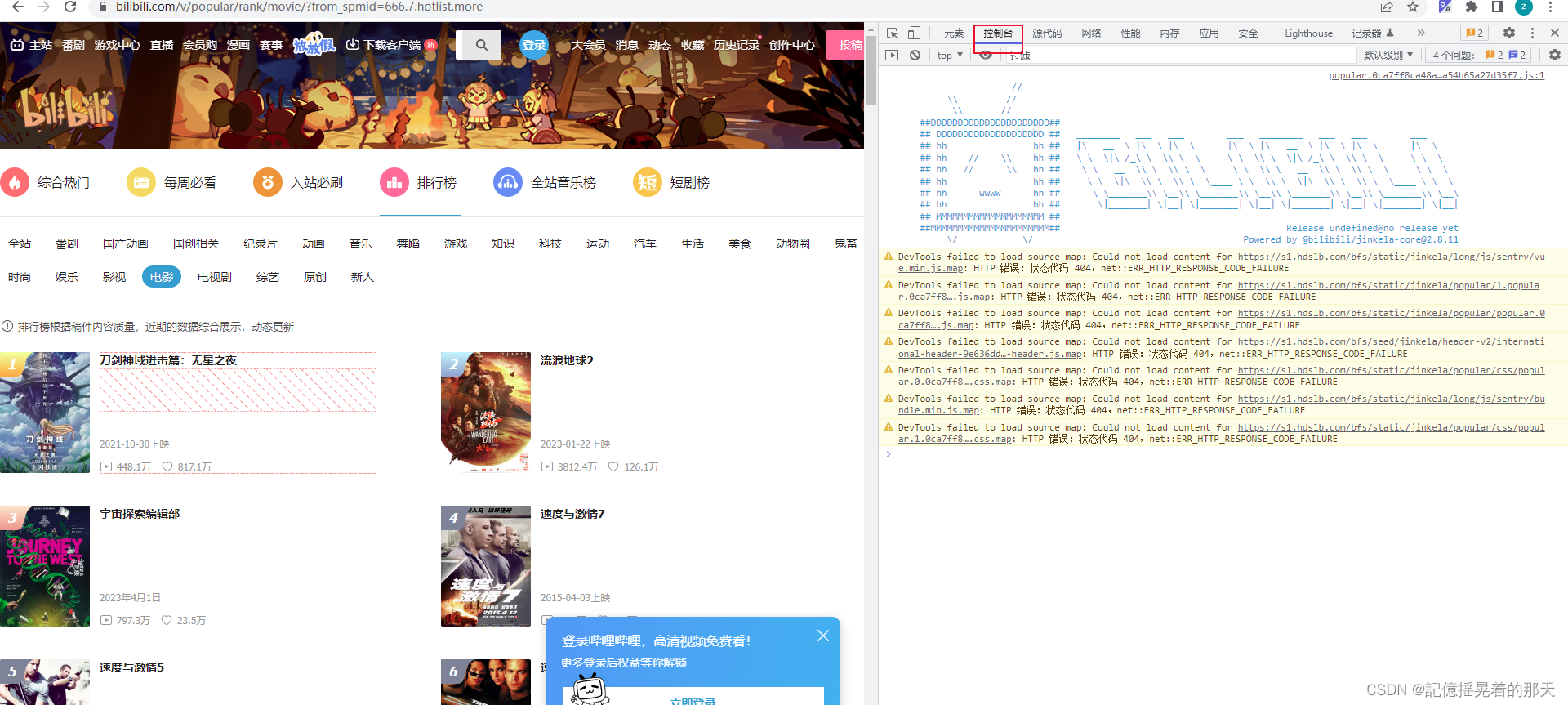 在控制台输入
在控制台输入$$('粘贴前面复制的选择器'),在这里输入$$('#app > div > div.rank-container > div.rank-list-wrap')回车
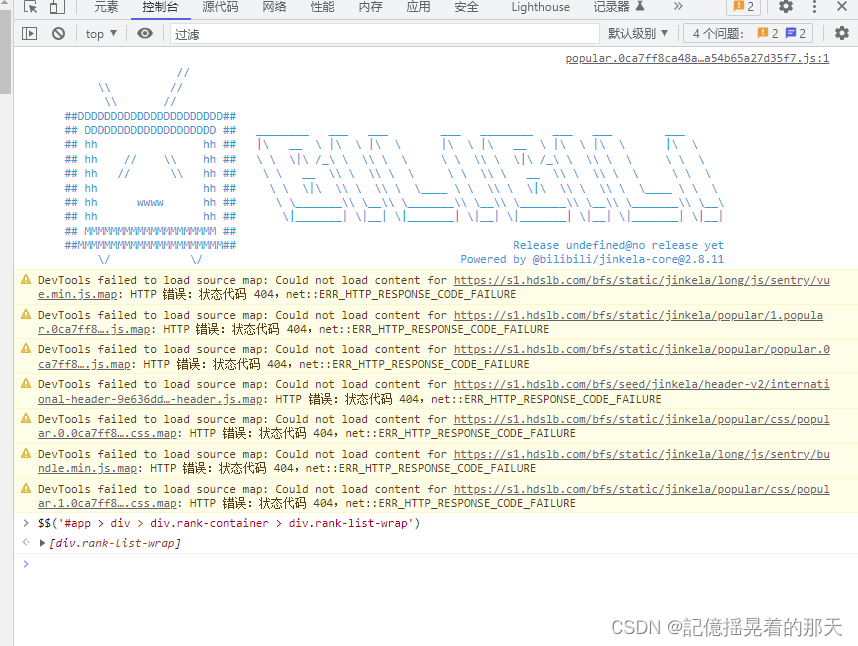 OK,现在拿到了div,这个标签下面包含了top100,接下来我们需要层层递进。
OK,现在拿到了div,这个标签下面包含了top100,接下来我们需要层层递进。
观察元素可以发现,div下面的ul是top100,ul下面的li是每一个影片
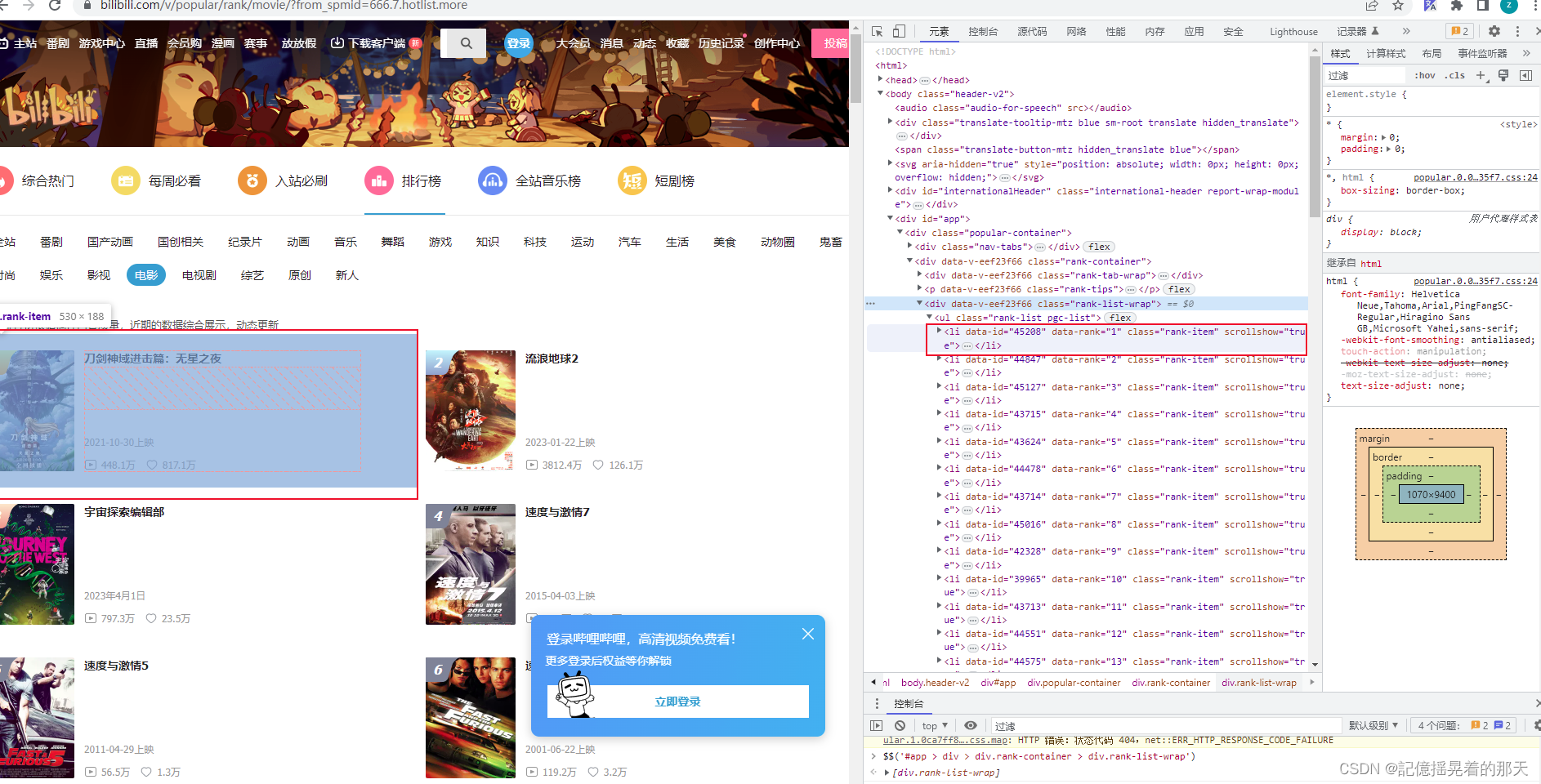 在控制台递进到li,使用
在控制台递进到li,使用>表示递进
可以看到我们在原先的选择器后面加上> ul > li就递进到了每个top,现在top100拿到了,接下来获取top里面的数据了
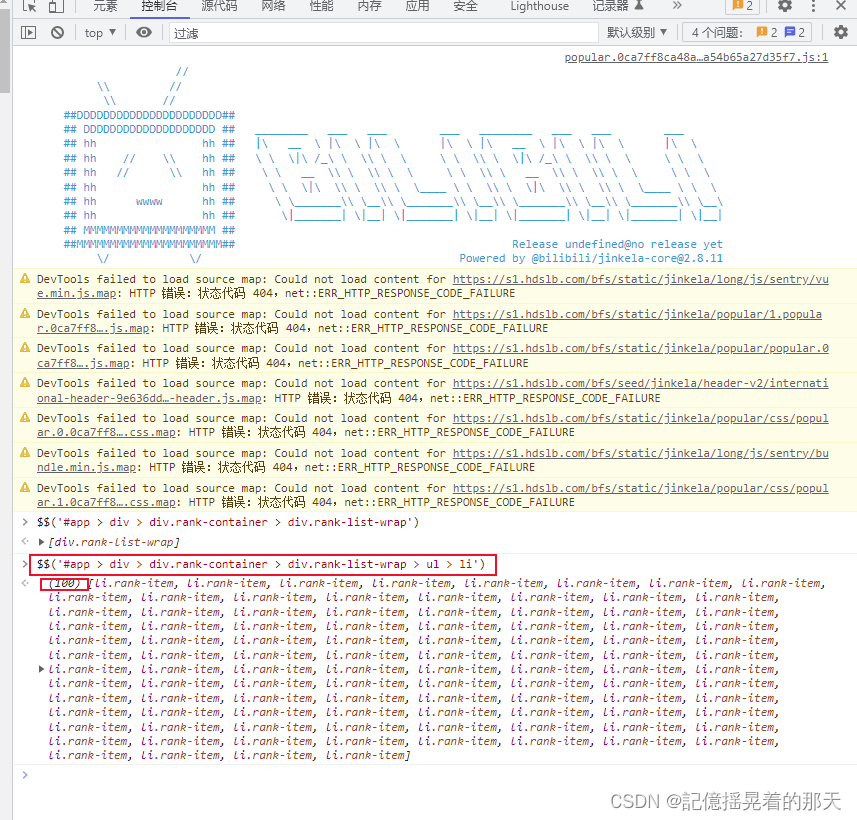 随便点开一个li看一下我们需要的信息在哪个属性里面
随便点开一个li看一下我们需要的信息在哪个属性里面
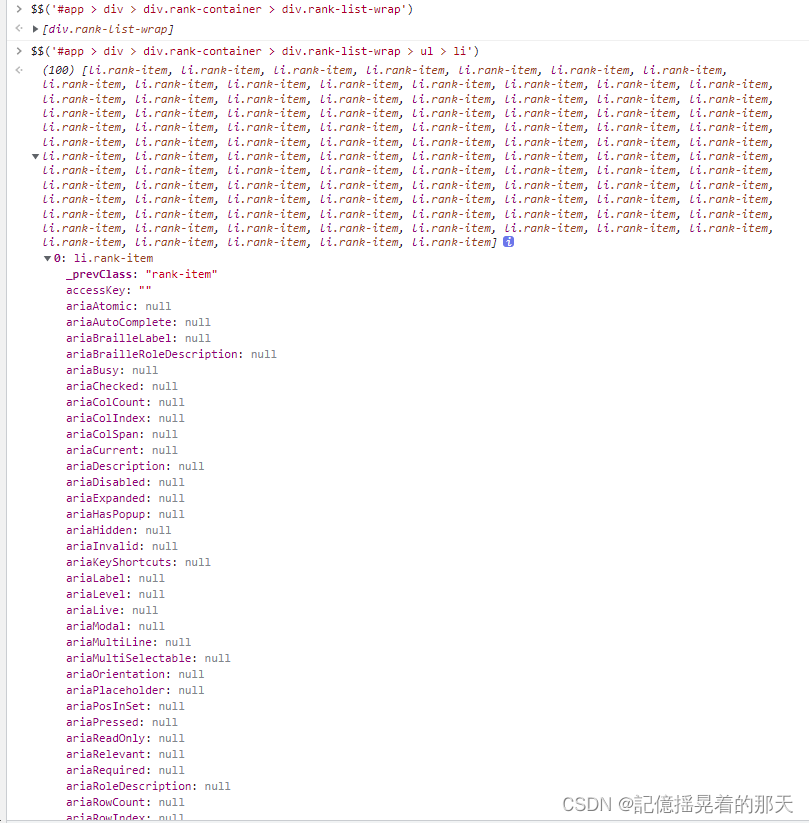 可以看到视频播放链接在innerHTML,标题、播放量和点赞量在innerText
可以看到视频播放链接在innerHTML,标题、播放量和点赞量在innerText
 在控制台打印innerText看看效果
在控制台打印innerText看看效果$$('#app > div > div.rank-container > div.rank-list-wrap > ul > li').forEach(e => {console.log(e.innerText)})
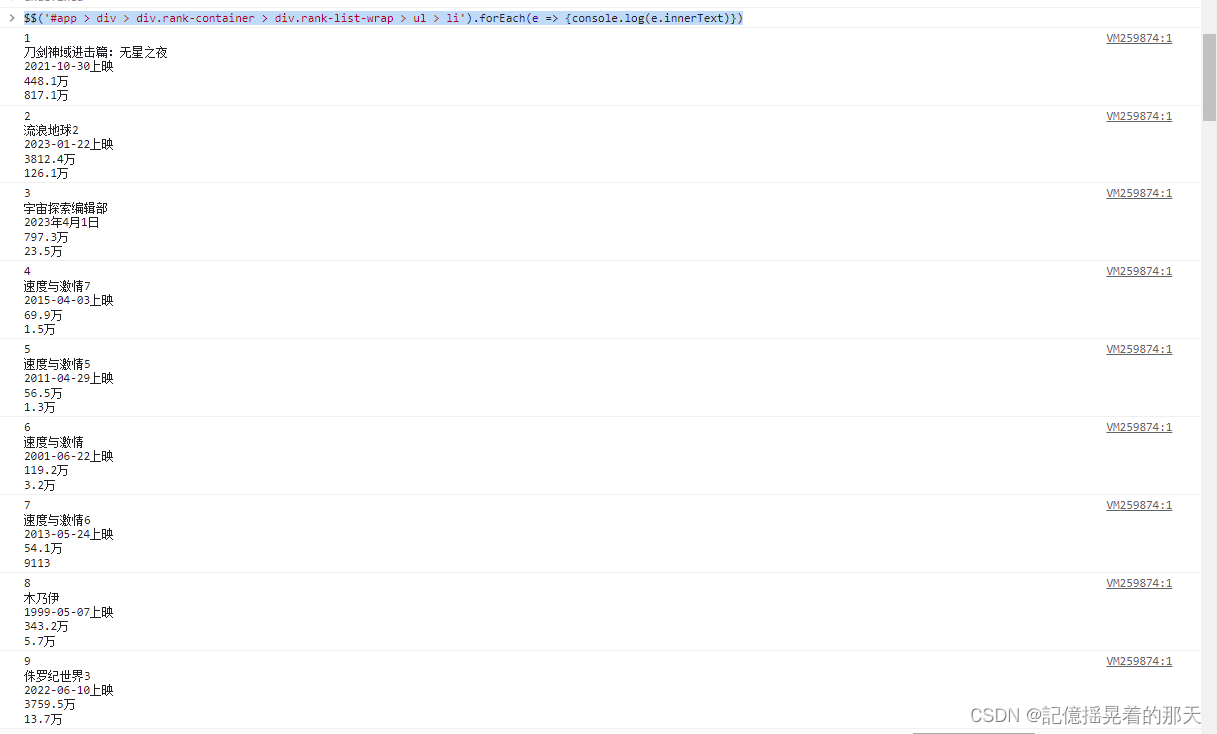
Puppeteer通过选择器获取top100数据
test.js代码
const puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch({headless: false, // 以非无头模式启动浏览器,可见浏览器窗口slowMo: 100 // 添加延迟,减慢操作速度(用于观察和调试)});const page = await browser.newPage(); // 创建一个新的页面对象await page.goto('https://www.bilibili.com/v/popular/rank/movie/?from_spmid=666.7.hotlist.more'); // 访问指定的 URL// 等待页面加载2秒钟await new Promise(resolve => setTimeout(resolve, 4000));let top100Combined = await page.$$eval('#app > div > div.rank-container > div.rank-list-wrap > ul > li', lis => {return lis.map(li => {return {innerText: li.innerText, // 获取每个<li>元素的innerText属性innerHTML: li.innerHTML // 获取每个<li>元素的innerHTML属性};});});
// 格式化数据let top100 = [];for (let top100CombinedKey in top100Combined) {const {innerText, innerHTML} = top100Combined[top100CombinedKey];// 使用正则表达式匹配电影信息let parts = innerText.split('\n');let rank = parseInt(parts[0]);let movieName = parts[1];let releaseDate = parts[2];let playCount = parseFloat(parts[3]);let likeCount = parseFloat(parts[4]);// 构造电影对象let top = {rank,movieName,releaseDate,playCount,likeCount,};// 正则表达式匹配视频播放链接let regexLink = /<a href="(\/\/www\.bilibili\.com\/bangumi\/play\/[^"]+)"/;let matchesLink = innerHTML.match(regexLink);if (matchesLink && matchesLink.length === 2) {let videoUrl = `https:${matchesLink[1]}`;top.videoUrl = videoUrl;} else {console.log("无法提取视频播放链接");}top100.push(top)}console.log(top100);await browser.close(); // 关闭浏览器实例})()运行脚本
运行此脚本
node ./test.js
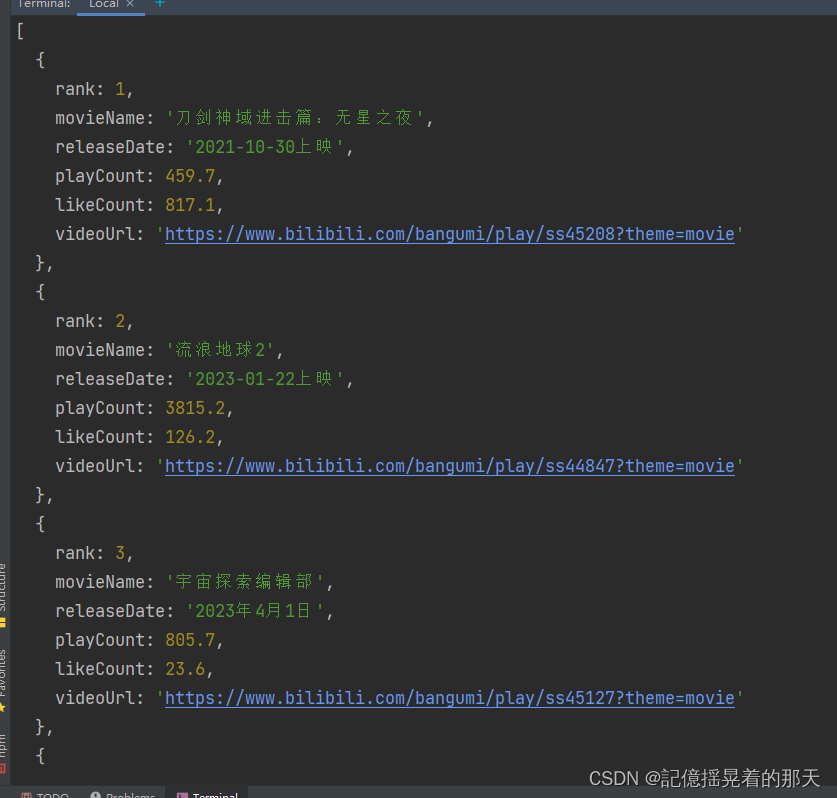 浏览器页面,可以看到数据全都抓到了
浏览器页面,可以看到数据全都抓到了