机器学习笔记之生成模型综述(四)概率图模型 vs 神经网络
机器学习笔记之生成模型综述——概率图模型vs神经网络
- 引言
- 回顾:概率图模型与前馈神经网络
- 贝叶斯网络 VS\text{VS}VS 神经网络
- 表示层面观察两者区别
- 推断、学习层面观察两者区别
引言
本节将介绍概率图模型与神经网络之间的关联关系和各自特点。
回顾:概率图模型与前馈神经网络
在概率图模型——背景中介绍过,概率图模型不是某一个具体模型,而是一种图结构的统称。而这个图(Graph\text{Graph}Graph)是描述概率模型P(X)\mathcal P(\mathcal X)P(X)内各特征之间关系的一种工具。
也就是说,概率图模型就是 概率模型/概率分布/概率密度函数P(X)\mathcal P(\mathcal X)P(X)的表示(Representation\text{Representation}Representation)。
在前馈神经网络——背景中介绍过,它的核心是通用逼近定理(Universal Approximation Theorem\text{Universal Approximation Theorem}Universal Approximation Theorem),基于该思想,将神经网络视作一个函数逼近器:大于等于一层隐藏层的神经网络可以逼近任意连续函数。
这里的‘神经网络’是指未经修饰的‘前馈神经网络’(Feed-Forward Neural Network\text{Feed-Forward Neural Network}Feed-Forward Neural Network)从‘前馈神经网络’的角度观察,它的任务就是对需要的复杂函数进行拟合,仅此而已。与概率分布没有关联关系。
以前馈神经网络处理亦或分类问题为例,其对应的计算图结构表示如下:
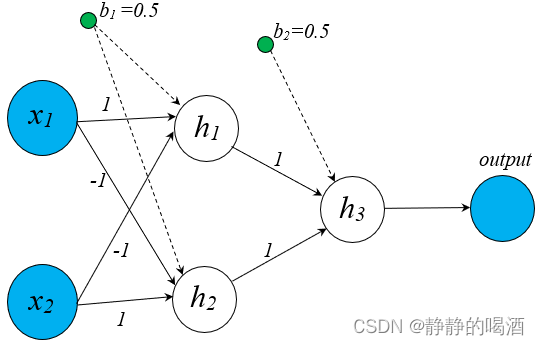
可以看出,这个输出结果output\text{output}output它仅是一个实数,它仅是从计算图结构中通过计算得到的结果而已,并没有概率方面的约束。
因而,但从概率的角度观察,概率图、神经网络是两个独立的概念。但从广义连结主义的角度观察,它们之间确实存在关联关系:
这里为了描述‘神经网络’与概率图结构的各自特点,将关注方向放在贝叶斯网络(Bayessian Network)(\text{Bayessian Network})(Bayessian Network)上,如玻尔兹曼机这种'既属于概率图模型,也属于神经网络'的结构,并不在关注之内。
- 例如玻尔兹曼机为代表的无向图模型。在随机变量结点参数学习的过程中,通常使用马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,MCMC\text{Markov Chain Monte Carlo,MCMC}Markov Chain Monte Carlo,MCMC)、变分推断(Variational Inference,VI\text{Variational Inference,VI}Variational Inference,VI)这种方式进行求解。针对这种基于随机采样对模型参数近似求解的结构,被称为随机神经网络(Stochastic Neural Network\text{Stochastic Neural Network}Stochastic Neural Network)。
- 相反,通过计算图来实现模型参数的精确求解,如前馈神经网络以及其变种结构如卷积神经网络(Convolutional Neural Networks, CNN\text{Convolutional Neural Networks, CNN}Convolutional Neural Networks, CNN),循环神经网络(Recurrent Neural Network, RNN\text{Recurrent Neural Network, RNN}Recurrent Neural Network, RNN)等等,被称之为确定性神经网络(Deterministic Neural Network\text{Deterministic Neural Network}Deterministic Neural Network)。
贝叶斯网络 VS\text{VS}VS 神经网络
这里依然从表示(Representation\text{Representation}Representation)、推断(Inference\text{Inference}Inference)、学习(Learning\text{Learning}Learning)三个角度对贝叶斯网络与神经网络之间进行比较:
这里的‘神经网络’具体指‘确定性神经网络’;‘概率图模型’具体指‘贝叶斯网络’。
从概率图与计算图的角度观察,概率图描述的是模型本身;而计算图仅构建了一个函数逼近的计算流程,计算图自身没有建模意义。但可以像生成对抗网络一样,将计算图本身看作一个复杂函数,进行建模。
表示层面观察两者区别
在介绍之前,我们介绍过Sigmoid\text{Sigmoid}Sigmoid信念网络,虽然它是一个典型的有向图模型,但它依然是通过醒眠算法(Wake-Sleep Algorithm\text{Wake-Sleep Algorithm}Wake-Sleep Algorithm)——通过采样的方式对模型参数进行近似学习。因此它也是一个随机神经网络,不在考虑之内。
贝叶斯网络的特点有:浅层、稀疏化、结构化。
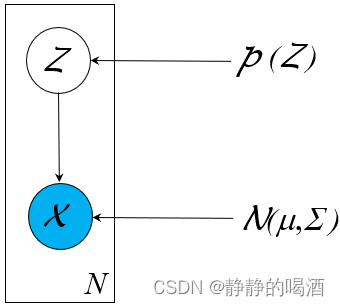
‘稀疏化’具体是通过人为的一系列条件独立性假设来约束结点之间的连接关系,主要是为了简化运算。如朴素贝叶斯分类器中的‘朴素贝叶斯假设’;隐马尔可夫模型中的‘齐次马尔可夫假设’与‘观测独立性假设’都属于使概率图结构稀疏化的假设。‘浅层’是指计算结点没有堆叠现象。与生成模型综述中介绍的‘深度生成模型’有少许区别。深度生成模型中的计算结点指的就是随机变量(隐变量、观测变量);而这里的计算结点有可能是随机变量结点,也可能是神经网络中的神经元结点。‘结构化’是指针对某种具体任务,人为地设置成某种特定结构的格式。例如高斯混合模型,它被设置成这种结构去处理聚类任务:
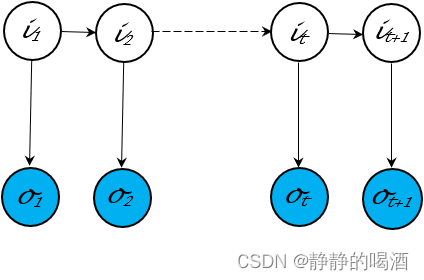
再例如隐马尔可夫模型,这种概率图结构被设计处理状态序列预测问题:
与之相对的,神经网络的特点:深层、稠密。
这里的‘深层’是指神经网络中隐藏层的数量。针对逼近函数的复杂程度,可以通过增加隐藏层的方式对输入特征进行更深层次地学习;
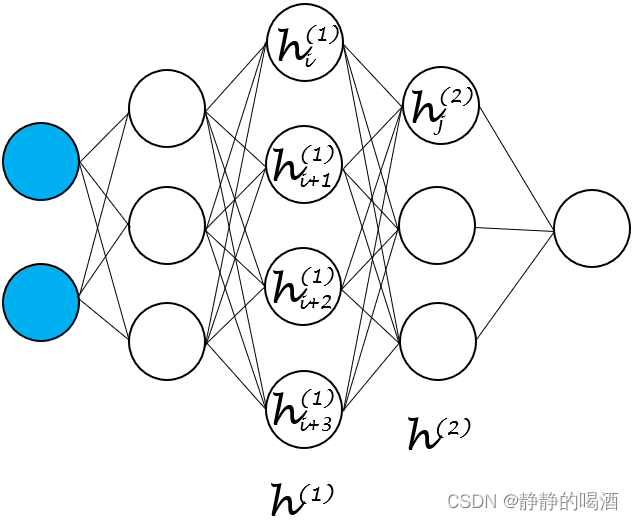
‘稠密’是指层与层神经元结点之间的关联关系是随意的,未被条件独立性约束的。
并且神经网络中的节点指的是计算图(Computational Graph\text{Computational Graph}Computational Graph)中的计算结点,相比于随机变量结点,如隐变量结点。我们并没有给计算节点针对图结构赋予相应的实际意义。
或者说,神经网络中的隐藏层单元是否有解释性并不重要,无论是哪种前馈神经网络,隐藏层单元的意义就只有‘逼近复杂函数过程中的一个环节’而已。
层与层之间关联关系表示如下(以上述h(2)h^{(2)}h(2)层计算节点hj(2)h_j^{(2)}hj(2)为例):
通过h(1)h^{(1)}h(1)层中的hi(1),hi+1(i),hi+2(1),hi+3(1)h_{i}^{(1)},h_{i+1}^{(i)},h_{i+2}^{(1)},h_{i+3}^{(1)}hi(1),hi+1(i),hi+2(1),hi+3(1)与对应权重参数的线性组合后关于激活函数Sign\text{Sign}Sign的映射结果,b(1)b^{(1)}b(1)表示h(1)h^{(1)}h(1)层对应的偏置信息。
hj(2)=Sign([W(1)]Th(1)+b(1))=Sign([Wi(1)]Thi(1)+[Wi+1(1)]Thi+1(1)+[Wi+2(1)]Thi+2(1)+[Wi+3(1)]Thi+3(1)+b(1))\begin{aligned} h_j^{(2)} & = \text{Sign}\left([\mathcal W^{(1)}]^T h^{(1)} + b^{(1)}\right) \\ & = \text{Sign} \left([\mathcal W_i^{(1)}]^Th_i^{(1)} + [\mathcal W_{i+1}^{(1)}]^Th_{i+1}^{(1)} + [\mathcal W_{i+2}^{(1)}]^Th_{i+2}^{(1)} + [\mathcal W_{i+3}^{(1)}]^Th_{i+3}^{(1)} + b^{(1)}\right) \end{aligned}hj(2)=Sign([W(1)]Th(1)+b(1))=Sign([Wi(1)]Thi(1)+[Wi+1(1)]Thi+1(1)+[Wi+2(1)]Thi+2(1)+[Wi+3(1)]Thi+3(1)+b(1))
基于上述描述,可以看出,关于贝叶斯网络概率图结构中结点之间的关联关系(有向边)是可解释的(Meaningful\text{Meaningful}Meaningful):而这个解释就是基于某随机变量结点条件下,其他结点发生的条件概率。如齐次马尔可夫假设,观测独立性假设:
无论是观测变量结点,还是隐变量结点,在建模过程中均基于实际任务赋予了物理意义。
{P(it+1∣it,⋯,i1,o1,⋯,ot)=P(it+1∣it)P(ot∣it,⋯,i1,ot−1,⋯,o1)=P(ot∣it)\begin{cases} \mathcal P(i_{t+1} \mid i_t,\cdots,i_1,o_1,\cdots,o_t) = \mathcal P(i_{t+1} \mid i_t)\\ \mathcal P(o_t \mid i_t,\cdots,i_1,o_{t-1},\cdots,o_1) = \mathcal P(o_t \mid i_t) \end{cases}{P(it+1∣it,⋯,i1,o1,⋯,ot)=P(it+1∣it)P(ot∣it,⋯,i1,ot−1,⋯,o1)=P(ot∣it)
推断、学习层面观察两者区别
如果是概率图模型,它的推断方式多种多样。在概率图模型——推断基本介绍中提到过,推断本质上就是 基于给定的模型参数,对随机变量的概率进行求解。
- 这里的随机变量指的可能是观测变量,也可能是隐变量;
- 这里的概率指的可能是边缘概率,也可能是条件概率,也可能是联合概率(概率密度函数)。
推断选择的方式也根据随机变量的性质(复杂程度:随机变量离散/连续;概率分布:简单/复杂)可进行选择。常见的推断方式有如下几种:
- 精确推断:如变量消去法(Variable Elimination,VE\text{Variable Elimination,VE}Variable Elimination,VE)。其本质上是基于概率图结构对无效的条件概率进行消除,从而达到简化运算的目的。例如某贝叶斯网络表示如下:
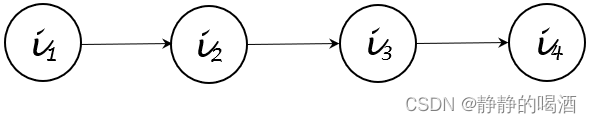
根据其拓扑排序顺序,可将上述概率图i4i_4i4结点的边缘概率分布P(i4)\mathcal P(i_4)P(i4)化简为如下形式:
原始方法与变量消去法之间进行对比。
{Original Method: P(i4)=∑i1,i2,i3P(i1,i2,i3,i4)=∑i1,i2,i3P(i1)⋅P(i2∣i1)⋅P(i3∣i2)⋅P(i4∣i3)VE Method: P(i4)=∑i1,i2,i3P(i1,i2,i3,i4)=∑i3P(i4∣i3)⋅∑i2P(i3∣i2)⋅∑i1P(i2∣i1)⋅P(i1)\begin{cases} \text{Original Method: }\begin{aligned}\mathcal P(i_4) &= \sum_{i_1,i_2,i_3} \mathcal P(i_1,i_2,i_3,i_4) \\ & = \sum_{i_1,i_2,i_3} \mathcal P(i_1) \cdot \mathcal P(i_2 \mid i_1) \cdot \mathcal P(i_3 \mid i_2) \cdot \mathcal P(i_4 \mid i_3) \end{aligned} \\ \text{VE Method: } \quad \quad \begin{aligned} \mathcal P(i_4) & = \sum_{i_1,i_2,i_3} \mathcal P(i_1,i_2,i_3,i_4) \\ & = \sum_{i_3} \mathcal P(i_4 \mid i_3) \cdot \sum_{i_2} \mathcal P(i_3 \mid i_2) \cdot \sum_{i_1} \mathcal P(i_2 \mid i_1) \cdot \mathcal P(i_1) \end{aligned} \end{cases}⎩⎨⎧Original Method: P(i4)=i1,i2,i3∑P(i1,i2,i3,i4)=i1,i2,i3∑P(i1)⋅P(i2∣i1)⋅P(i3∣i2)⋅P(i4∣i3)VE Method: P(i4)=i1,i2,i3∑P(i1,i2,i3,i4)=i3∑P(i4∣i3)⋅i2∑P(i3∣i2)⋅i1∑P(i2∣i1)⋅P(i1)
同理,精确推断还有基于前向后向算法逻辑的信念传播(Belief Propagation,BP)方法。 - 近似推断(Approximate Inference\text{Approximate Inference}Approximate Inference):针对随机变量结点的概率无法准确求解/求解代价极大。最典型的依然是因隐变量Z\mathcal ZZ维度过高产生的 积分难问题:
P(X)=∫z1⋯∫zKP(X∣Z)⋅P(Z)dz1,⋯,zK\begin{aligned} \mathcal P(\mathcal X) = \int_{z_1} \cdots\int_{z_{\mathcal K}} \mathcal P(\mathcal X \mid \mathcal Z) \cdot \mathcal P(\mathcal Z) dz_1,\cdots,z_{\mathcal K} \end{aligned}P(X)=∫z1⋯∫zKP(X∣Z)⋅P(Z)dz1,⋯,zK
对应采样方法如变分推断(Variational Inference,VI\text{Variational Inference,VI}Variational Inference,VI),以及基于采样方式的随机性近似方法:马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,MCMC\text{Markov Chain Monte Carlo,MCMC}Markov Chain Monte Carlo,MCMC)。
从学习层面观察,由于是基于概率分布,因而关于模型参数学习的底层方法是极大似然估计(Maximum Likelihood Estimatation,MLE\text{Maximum Likelihood Estimatation,MLE}Maximum Likelihood Estimatation,MLE)。
当然,这仅是常规的学习思路。其他方法例如以生成对抗网络(Generative Adversarial Networks,GAN\text{Generative Adversarial Networks,GAN}Generative Adversarial Networks,GAN)为代表的对抗学习等。
例如高斯混合模型、隐马尔可夫模型中使用的EM\text{EM}EM算法,它们都是极大似然估计的衍生方法。
而神经网络中不存在推断一说。
- 隐藏层神经元结点产生的中间值仅仅表示一个实数,连基本的概率意义都没有。自然不会出现隐藏层关于某神经元结点的概率这种描述。
- 和上述的前馈神经网络处理 亦或问题 一样,一旦权重W\mathcal WW、偏置信息bbb给定的条件下,给定一个输入,那么神经网络中所有隐藏层结点结果均被固定,不存在不确定的分布一说。
关于神经网络的学习任务相比于概率图模型单调一些。其核心是梯度下降方法(Gradient Descent,GD\text{Gradient Descent,GD}Gradient Descent,GD)。
无论是随机梯度下降(Stochastic Gradient Descent,SGD\text{Stochastic Gradient Descent,SGD}Stochastic Gradient Descent,SGD),批量梯度下降(Batch Gradient Descent,BGD\text{Batch Gradient Descent,BGD}Batch Gradient Descent,BGD),RMSProp\text{RMSProp}RMSProp,Adagrad\text{Adagrad}Adagrad,Adam\text{Adam}Adam算法,其底层逻辑均属于梯度下降方法。详细可参阅这篇文章,非常感谢。传送门
如果神经网络内隐藏层数量较多,梯度求解过程复杂,则引入反向传播算法(Backward Propagation,BP\text{Backward Propagation,BP}Backward Propagation,BP)
需要注意的是,反向传播算法只是一种‘高效的求导方法’,这种方法仅是在每次迭代过程中将梯度传递给各个隐藏层神经元的权重信息中,它本身并不是参数学习方法。
相关参考:
【pytorch】3.0 优化器BGD、SGD、MSGD、Momentum、Adagrad、RMSPprop、Adam
生成模型5-概率图VS神经网络