windows本地开发Spark[不开虚拟机]
1. windows本地安装hadoop
hadoop 官网下载 hadoop2.9.1版本
1.1 解压缩至C:\XX\XX\hadoop-2.9.1
1.2 下载动态链接库和工具库
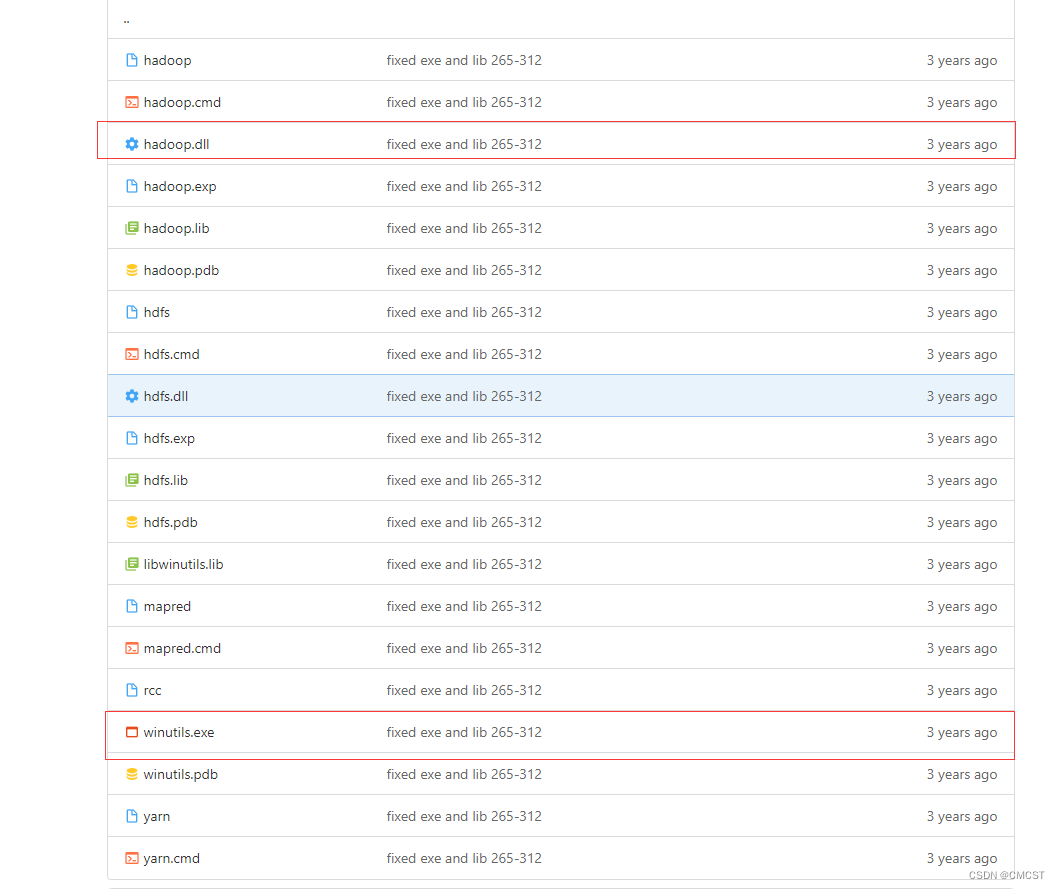
1.3 将文件winutils.exe放在目录C:\XX\XX\hadoop-2.9.1\bin下
1.4 将文件hadoop.dll放在目录C:\XX\XX\hadoop-2.9.1\bin下
1.5 将文件hadoop.dll放在目录C:\Windows\System32下
1.6 配置环境变量
| 添加方式 | 变量名 | 变量值 |
|---|---|---|
| 新建 | HADOOP_HOME | C:\XX\XX\hadoop-2.9.1 |
| 新建 | HADOOP_HOME | C:\XX\XX\hadoop-2.9.1 |
| 编辑(在Path中添加) | Path | %HADOOP_HOME%\bin |
1.7 重启计算机
2. windows本地安装scala
scala 官网下载 scala 2.12.17 版本
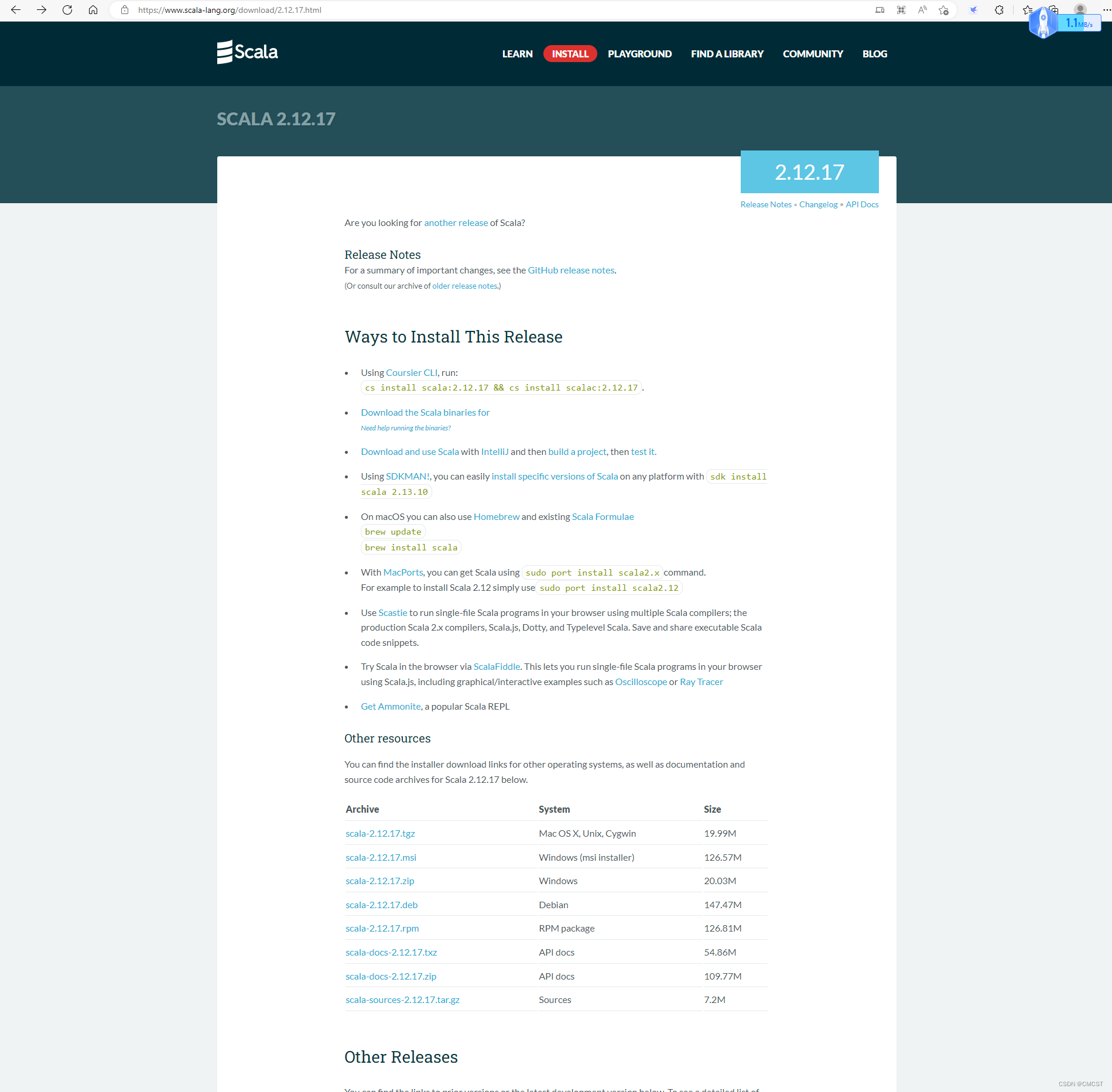
- 在上图中选择如下图所示下载
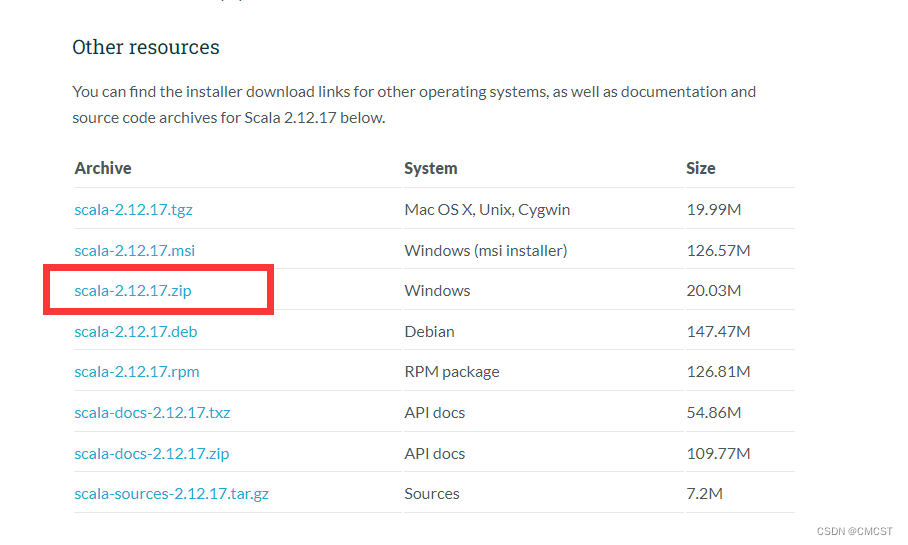
- 解压文件至 D:\Server\,并将文件夹名称由D:\Server\scala-2.12.17改为D:\Server\scala
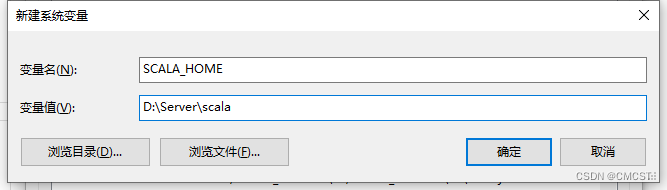
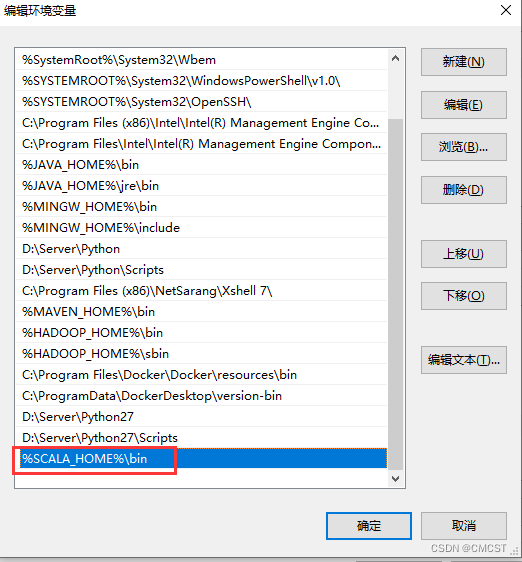
2.1 配置环境变量
| 操作方式 | 变量名 | 变量值 |
|---|---|---|
| 新建 | SCALA_HOME | D:\Server\scala |
| 添加 | Path | %SCALA_HOME%\bin |
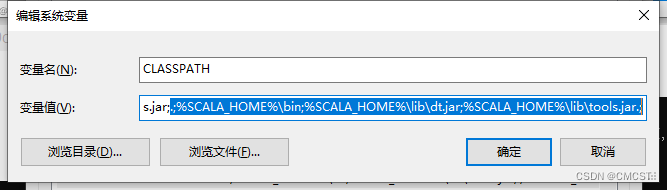
| 添加 | CLASSPATH | .;%SCALA_HOME%\bin;%SCALA_HOME%\lib\dt.jar;%SCALA_HOME%\lib\tools.jar.; |
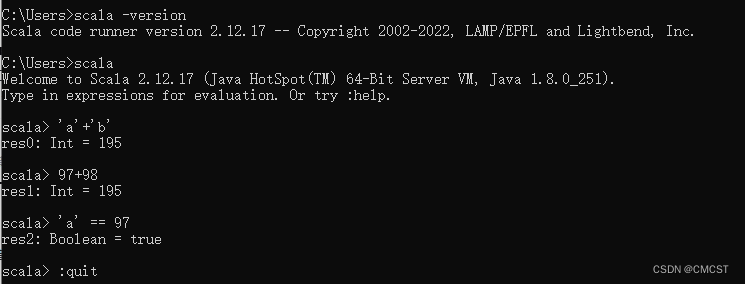
2.2 CMD初体验
3. Spark应用开发
3.1 IDEA 创建maven项目
maven安装教程
3.2 创建scala文件夹
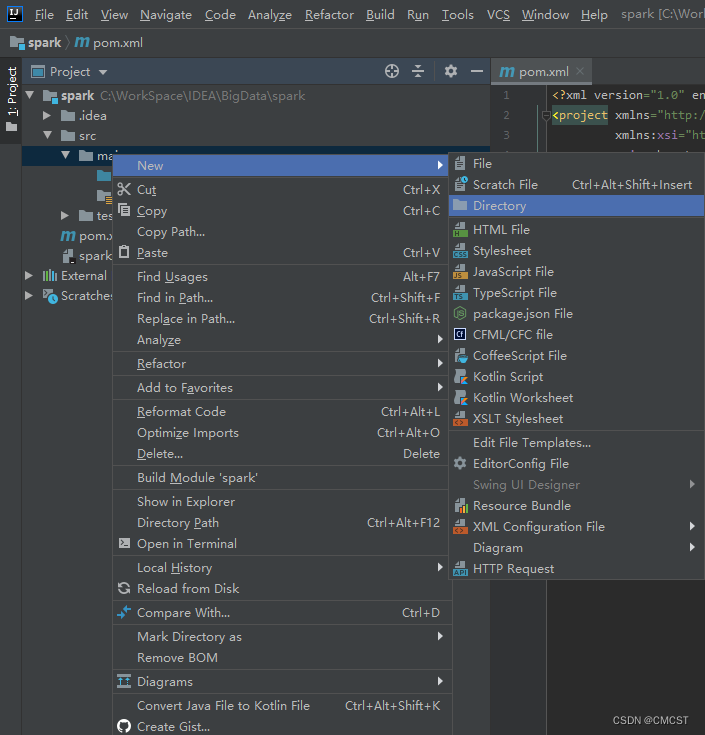
- 文件夹名为scala

- 将scala文件夹标记为源文件目录
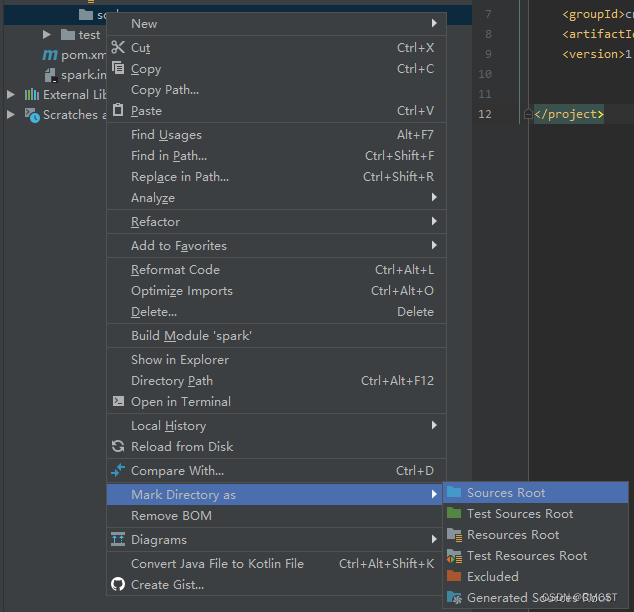
3.3 创建scala文件
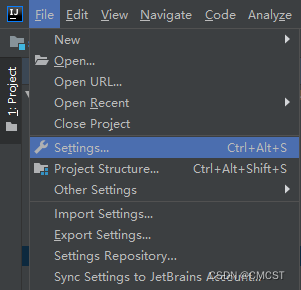
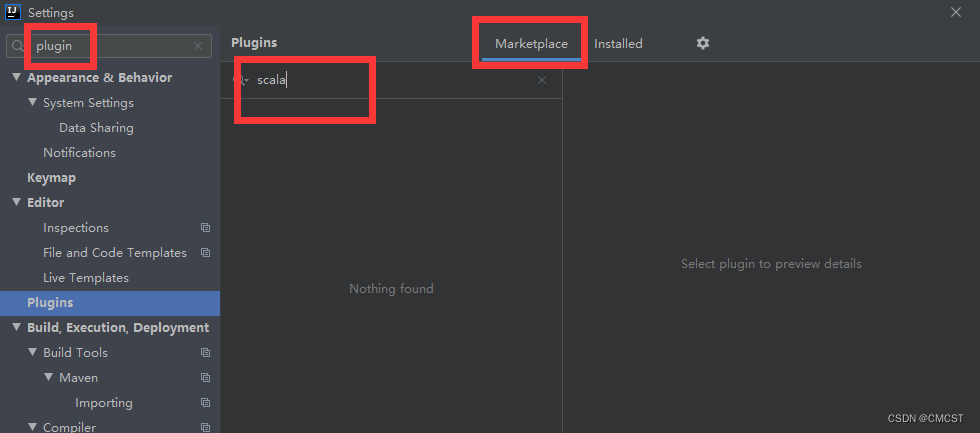
3.3.1 安装scala插件
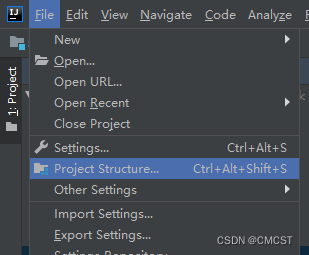
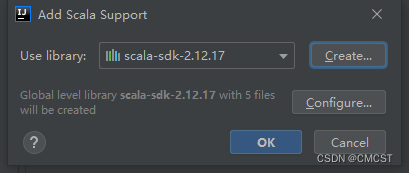
3.3.2 添加框架支持
3.3.3 修改pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.cmcst</groupId><artifactId>spark</artifactId><version>1.0</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.7</maven.compiler.source><maven.compiler.target>1.7</maven.compiler.target><hadoop.version>2.9.1</hadoop.version><scala.version>2.12.17</scala.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>2.4.8</version></dependency></dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.12.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>8</source><target>8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.4</version><configuration><archive><manifest><mainClass>cn.cmcst.spark.WordCount</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
3.3.4 创建WordCount文件
package cn.cmcst.sparkimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {if(args.length < 2){System.err.println("Usage: WordCount <input> <output>")System.exit(0)}val input = args(0)val output = args(1)val conf = new SparkConf().setAppName("WordCount").setMaster("local[3]")val sc = new SparkContext(conf)val lines = sc.textFile(input)val result = lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)result.collect().foreach(println)
// result.saveAsTextFile(output)sc.stop()}
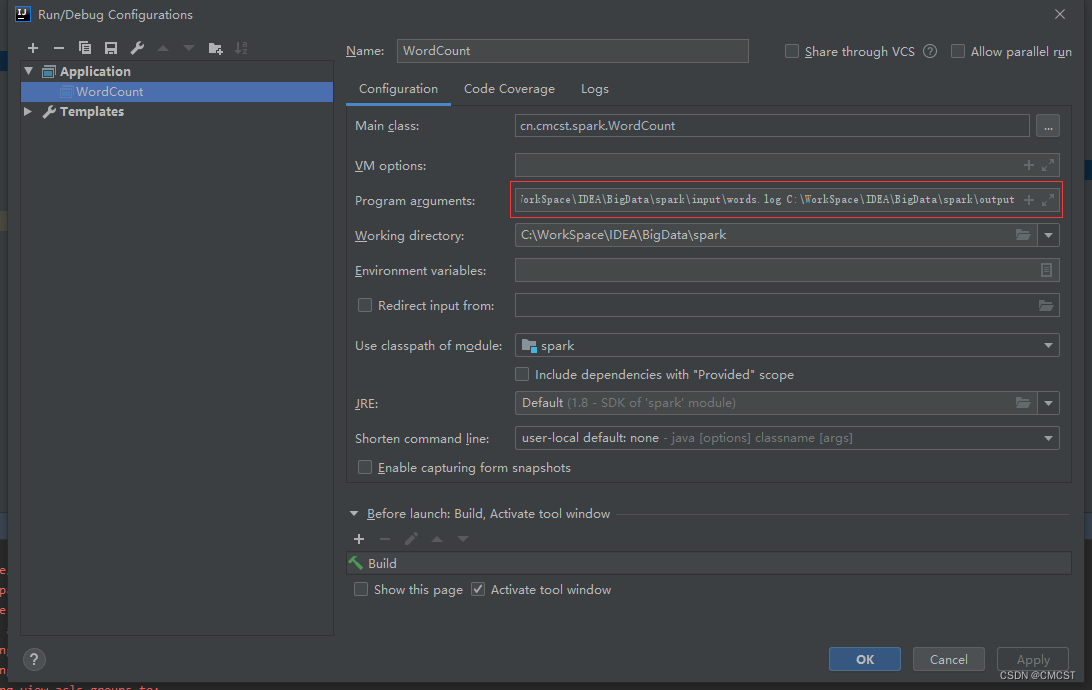
}3.3.5 IDEA中输入参数

- 红框中输入两个参数:程序中要读取文件输入目录 文件输出目录
- words.log文件内容为
flink flink flink
hadoop hadoop hadoop
spark spark spark
davinci davinci davinci
hive zookeeper sqoop mysql
hive zookeeper sqoop mysql
IDEA IDEA IDEA
2.3.6 输出结果
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
23/02/14 13:59:34 INFO SparkContext: Running Spark version 2.4.8
23/02/14 13:59:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/02/14 13:59:35 INFO SparkContext: Submitted application: WordCount
23/02/14 13:59:35 INFO SecurityManager: Changing view acls to: CMCST,root
23/02/14 13:59:35 INFO SecurityManager: Changing modify acls to: CMCST,root
23/02/14 13:59:35 INFO SecurityManager: Changing view acls groups to:
23/02/14 13:59:35 INFO SecurityManager: Changing modify acls groups to:
23/02/14 13:59:35 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(CMCST, root); groups with view permissions: Set(); users with modify permissions: Set(CMCST, root); groups with modify permissions: Set()
23/02/14 13:59:36 INFO Utils: Successfully started service 'sparkDriver' on port 9229.
23/02/14 13:59:36 INFO SparkEnv: Registering MapOutputTracker
23/02/14 13:59:36 INFO SparkEnv: Registering BlockManagerMaster
23/02/14 13:59:36 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/02/14 13:59:36 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/02/14 13:59:36 INFO DiskBlockManager: Created local directory at C:\Users\CMCST\AppData\Local\Temp\blockmgr-87f53eb9-52f3-4323-83b0-ebc53bfc2073
23/02/14 13:59:36 INFO MemoryStore: MemoryStore started with capacity 897.6 MB
23/02/14 13:59:36 INFO SparkEnv: Registering OutputCommitCoordinator
23/02/14 13:59:36 INFO Utils: Successfully started service 'SparkUI' on port 4040.
23/02/14 13:59:36 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://DESKTOP-0DK2AAM:4040
23/02/14 13:59:36 INFO Executor: Starting executor ID driver on host localhost
23/02/14 13:59:37 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 9252.
23/02/14 13:59:37 INFO NettyBlockTransferService: Server created on DESKTOP-0DK2AAM:9252
23/02/14 13:59:37 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
23/02/14 13:59:37 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO BlockManagerMasterEndpoint: Registering block manager DESKTOP-0DK2AAM:9252 with 897.6 MB RAM, BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 214.6 KB, free 897.4 MB)
23/02/14 13:59:37 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.4 KB, free 897.4 MB)
23/02/14 13:59:37 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on DESKTOP-0DK2AAM:9252 (size: 20.4 KB, free: 897.6 MB)
23/02/14 13:59:37 INFO SparkContext: Created broadcast 0 from textFile at WordCount.scala:18
23/02/14 13:59:37 INFO FileInputFormat: Total input paths to process : 1
23/02/14 13:59:38 INFO SparkContext: Starting job: collect at WordCount.scala:21
23/02/14 13:59:38 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:19) as input to shuffle 0
23/02/14 13:59:38 INFO DAGScheduler: Got job 0 (collect at WordCount.scala:21) with 2 output partitions
23/02/14 13:59:38 INFO DAGScheduler: Final stage: ResultStage 1 (collect at WordCount.scala:21)
23/02/14 13:59:38 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
23/02/14 13:59:38 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
23/02/14 13:59:38 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:19), which has no missing parents
23/02/14 13:59:38 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.8 KB, free 897.4 MB)
23/02/14 13:59:38 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 3.4 KB, free 897.4 MB)
23/02/14 13:59:38 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on DESKTOP-0DK2AAM:9252 (size: 3.4 KB, free: 897.6 MB)
23/02/14 13:59:38 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1184
23/02/14 13:59:38 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:19) (first 15 tasks are for partitions Vector(0, 1))
23/02/14 13:59:38 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
23/02/14 13:59:38 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7381 bytes)
23/02/14 13:59:38 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7381 bytes)
23/02/14 13:59:38 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
23/02/14 13:59:38 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
23/02/14 13:59:38 INFO HadoopRDD: Input split: file:/C:/WorkSpace/IDEA/BigData/spark/input/words.log:0+77
23/02/14 13:59:38 INFO HadoopRDD: Input split: file:/C:/WorkSpace/IDEA/BigData/spark/input/words.log:77+78
23/02/14 13:59:38 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1163 bytes result sent to driver
23/02/14 13:59:38 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1163 bytes result sent to driver
23/02/14 13:59:38 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 523 ms on localhost (executor driver) (1/2)
23/02/14 13:59:38 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 508 ms on localhost (executor driver) (2/2)
23/02/14 13:59:39 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
23/02/14 13:59:39 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:19) finished in 0.627 s
23/02/14 13:59:39 INFO DAGScheduler: looking for newly runnable stages
23/02/14 13:59:39 INFO DAGScheduler: running: Set()
23/02/14 13:59:39 INFO DAGScheduler: waiting: Set(ResultStage 1)
23/02/14 13:59:39 INFO DAGScheduler: failed: Set()
23/02/14 13:59:39 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:19), which has no missing parents
23/02/14 13:59:39 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 4.1 KB, free 897.4 MB)
23/02/14 13:59:39 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.5 KB, free 897.4 MB)
23/02/14 13:59:39 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on DESKTOP-0DK2AAM:9252 (size: 2.5 KB, free: 897.6 MB)
23/02/14 13:59:39 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1184
23/02/14 13:59:39 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:19) (first 15 tasks are for partitions Vector(0, 1))
23/02/14 13:59:39 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
23/02/14 13:59:39 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, localhost, executor driver, partition 0, ANY, 7141 bytes)
23/02/14 13:59:39 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, localhost, executor driver, partition 1, ANY, 7141 bytes)
23/02/14 13:59:39 INFO Executor: Running task 0.0 in stage 1.0 (TID 2)
23/02/14 13:59:39 INFO Executor: Running task 1.0 in stage 1.0 (TID 3)
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 9 ms
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 9 ms
23/02/14 13:59:39 INFO Executor: Finished task 1.0 in stage 1.0 (TID 3). 1285 bytes result sent to driver
23/02/14 13:59:39 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 1355 bytes result sent to driver
23/02/14 13:59:39 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 195 ms on localhost (executor driver) (1/2)
23/02/14 13:59:39 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 199 ms on localhost (executor driver) (2/2)
23/02/14 13:59:39 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
23/02/14 13:59:39 INFO DAGScheduler: ResultStage 1 (collect at WordCount.scala:21) finished in 0.215 s
23/02/14 13:59:39 INFO DAGScheduler: Job 0 finished: collect at WordCount.scala:21, took 1.181680 s
23/02/14 13:59:39 INFO BlockManagerInfo: Removed broadcast_1_piece0 on DESKTOP-0DK2AAM:9252 in memory (size: 3.4 KB, free: 897.6 MB)
23/02/14 13:59:39 INFO SparkUI: Stopped Spark web UI at http://DESKTOP-0DK2AAM:4040
(hive,2)
(flink,3)
(davinci,3)
(zookeeper,2)
(mysql,2)
(sqoop,2)
(spark,3)
(hadoop,3)
(IDEA,3)
23/02/14 13:59:39 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/02/14 13:59:39 INFO MemoryStore: MemoryStore cleared
23/02/14 13:59:39 INFO BlockManager: BlockManager stopped
23/02/14 13:59:39 INFO BlockManagerMaster: BlockManagerMaster stopped
23/02/14 13:59:39 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/02/14 13:59:39 INFO SparkContext: Successfully stopped SparkContext
23/02/14 13:59:39 INFO ShutdownHookManager: Shutdown hook called
23/02/14 13:59:39 INFO ShutdownHookManager: Deleting directory C:\Users\CMCST\AppData\Local\Temp\spark-3a48779f-a780-43f5-9898-d8a95cbdbcec