深度学习核心技巧与实战指南
1.Tensor
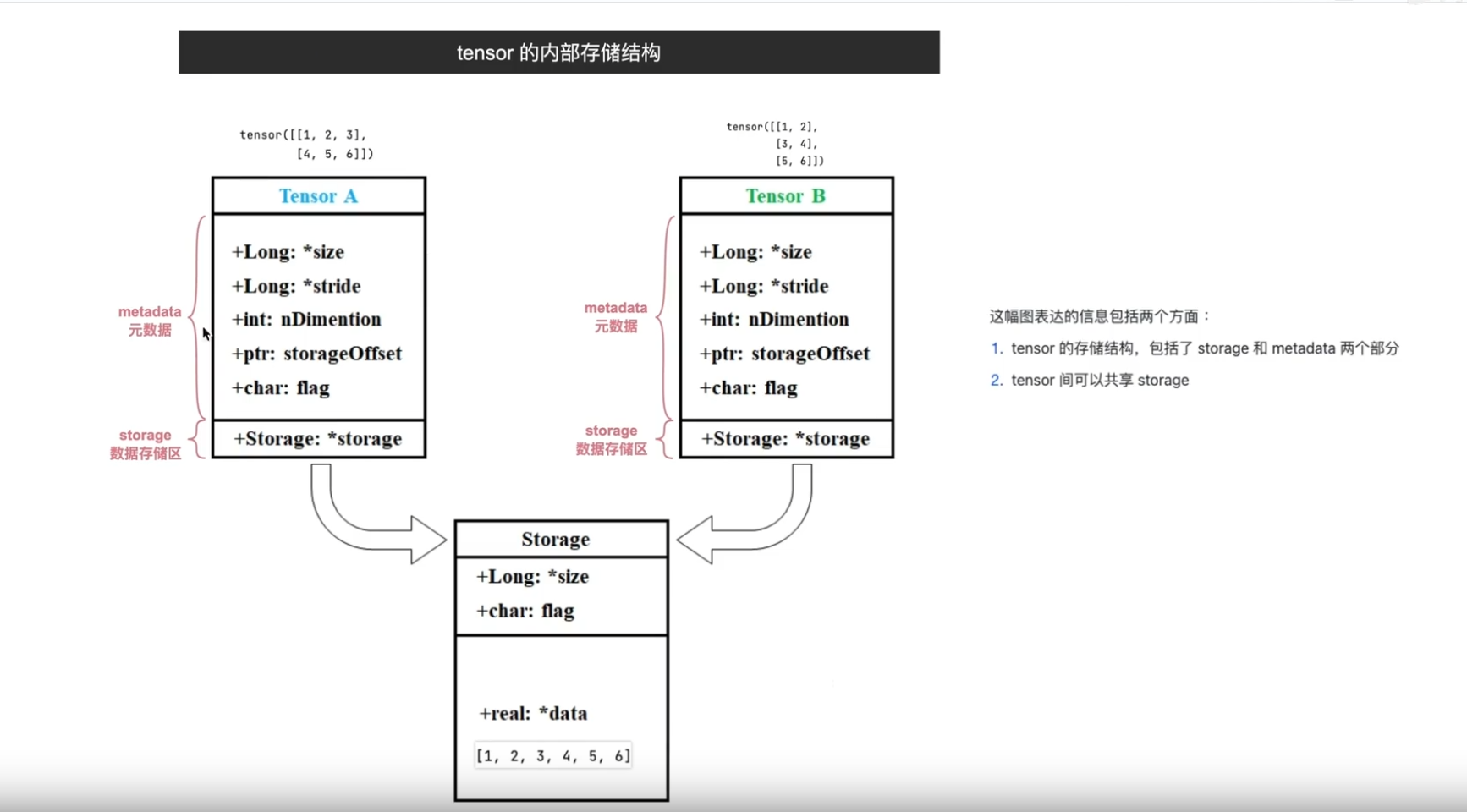
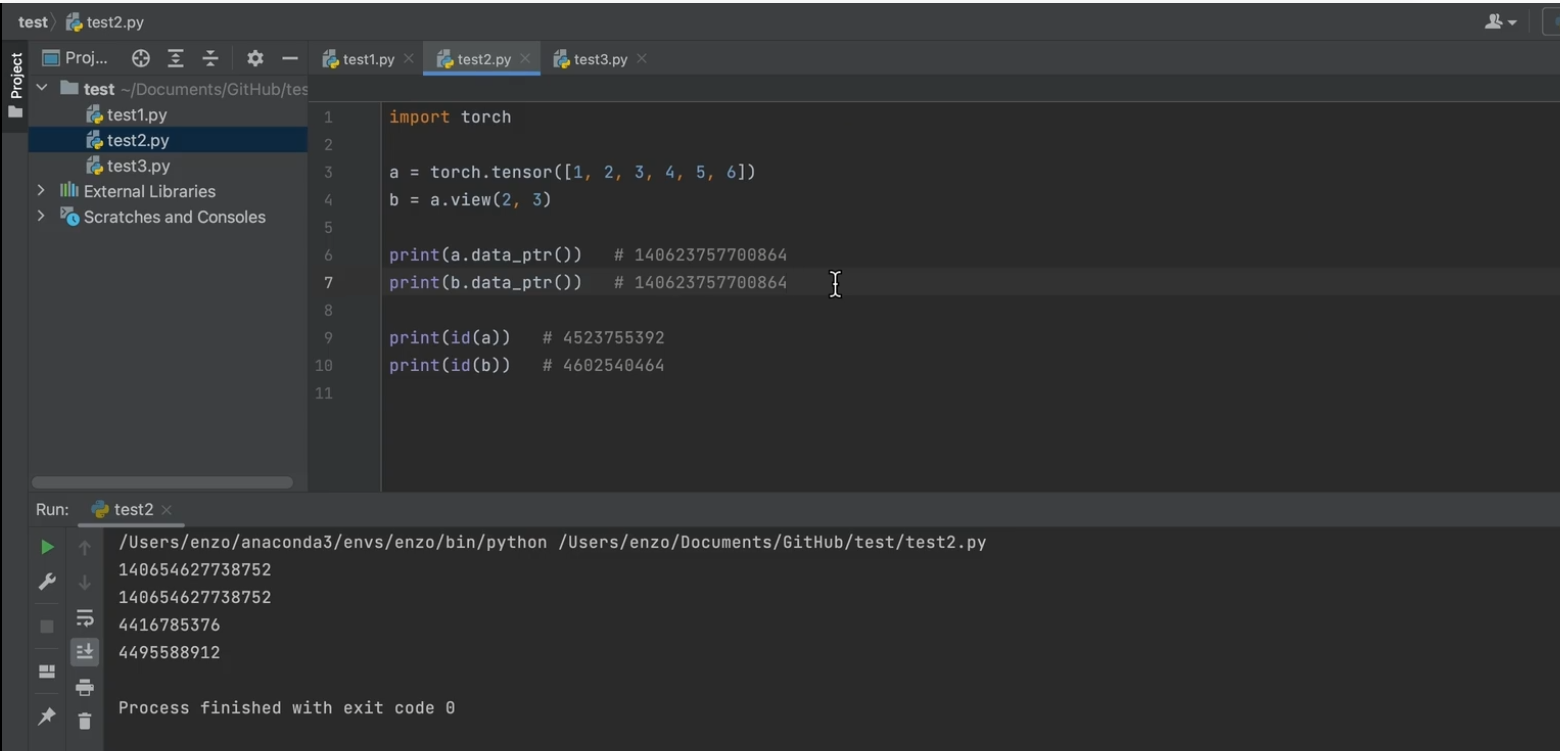
存储结构:storage(一维)和metadata
可以共享storage (DL数据量庞大, 节省内存空间
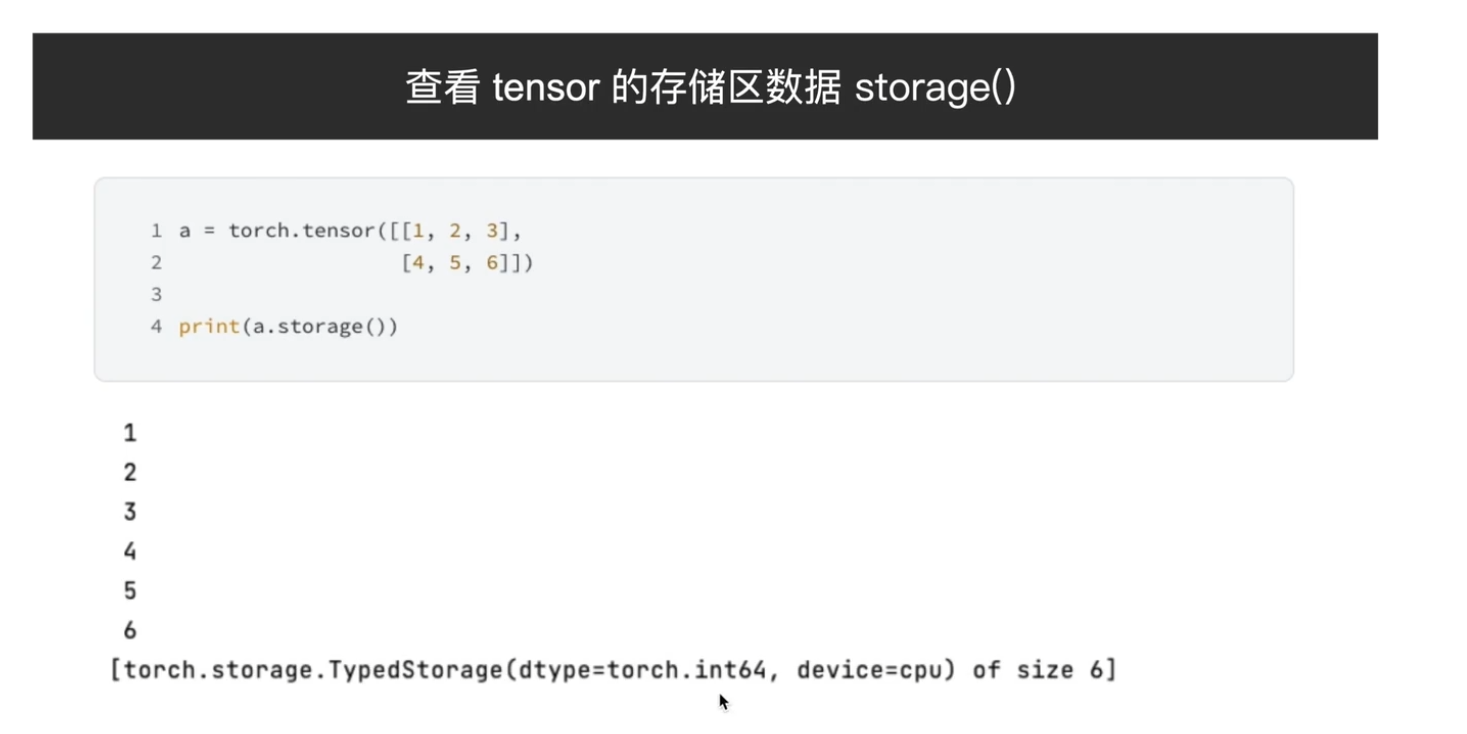
查看数据
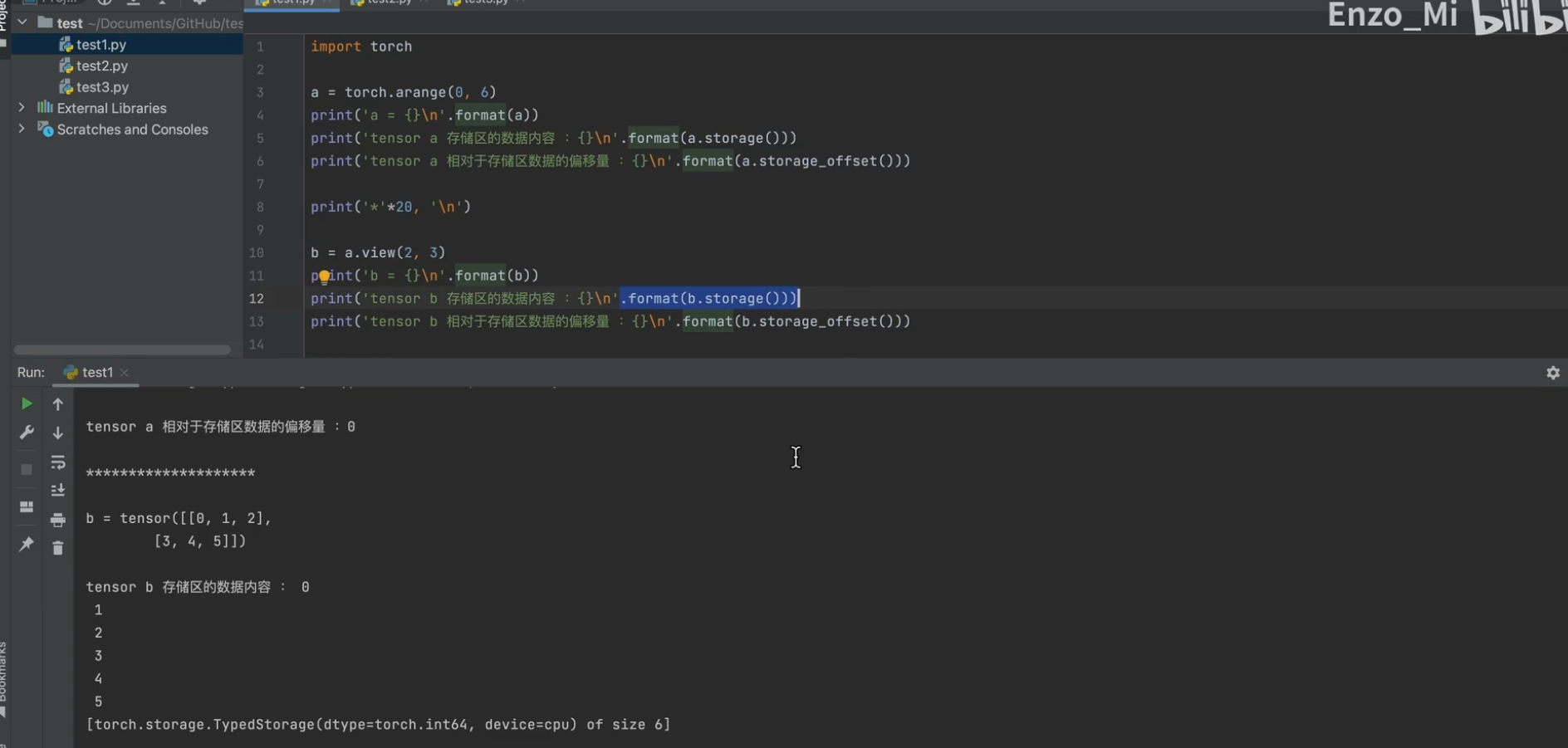
步长(根据维度 来看

偏移量

eg:

ptr指针,指向起始地址
公用存储区,两个tensor(也就是说不同size,stride等
2.argparse 模块
执行命令行参数解析
1
2.打包在函数中
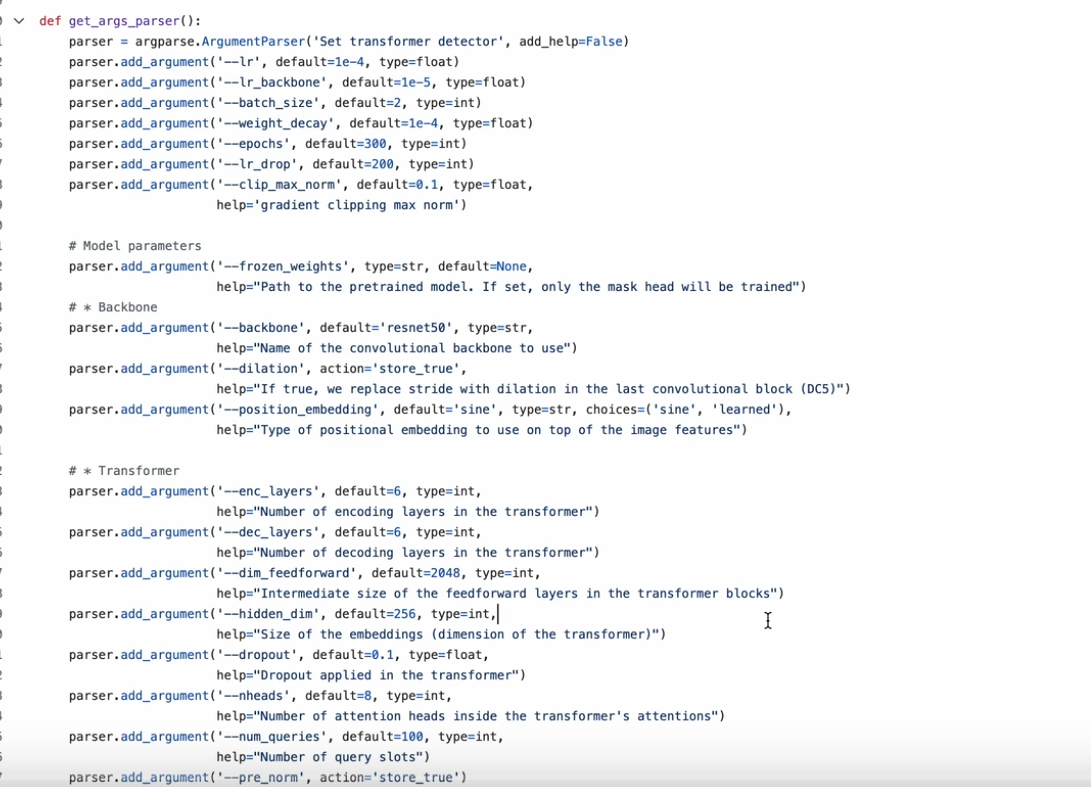
不使用(反复修改脚本,传参

使用
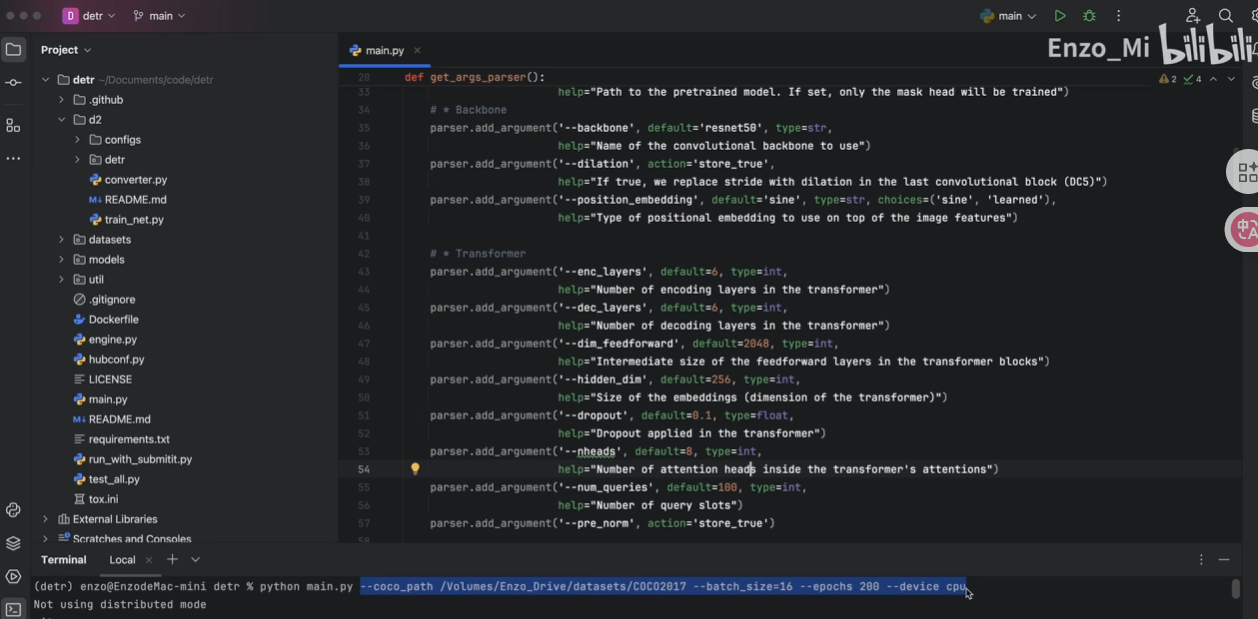
解析之后存入args对象,之后传这个对象即可
使用
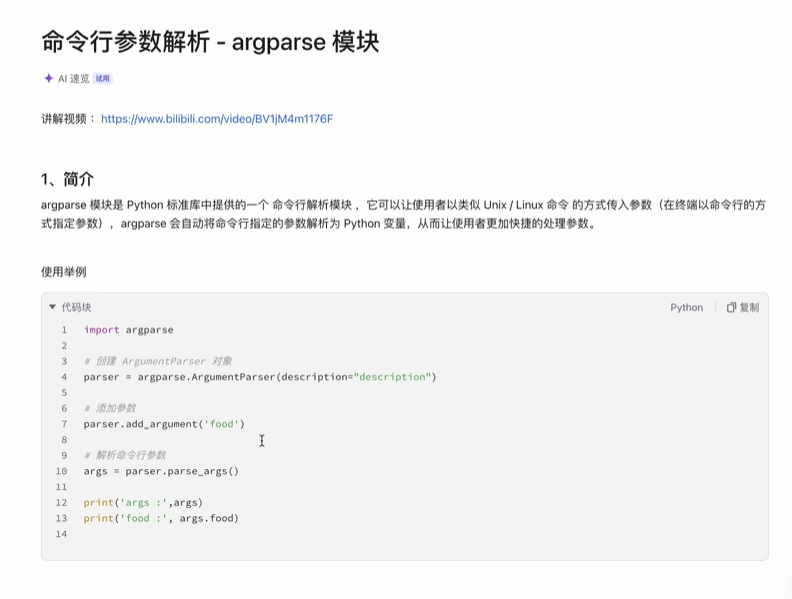
文字说明
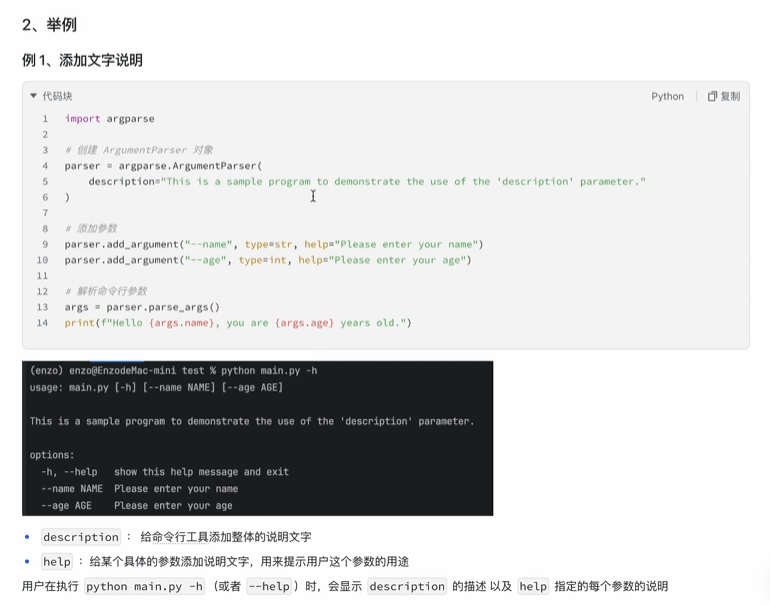
--help
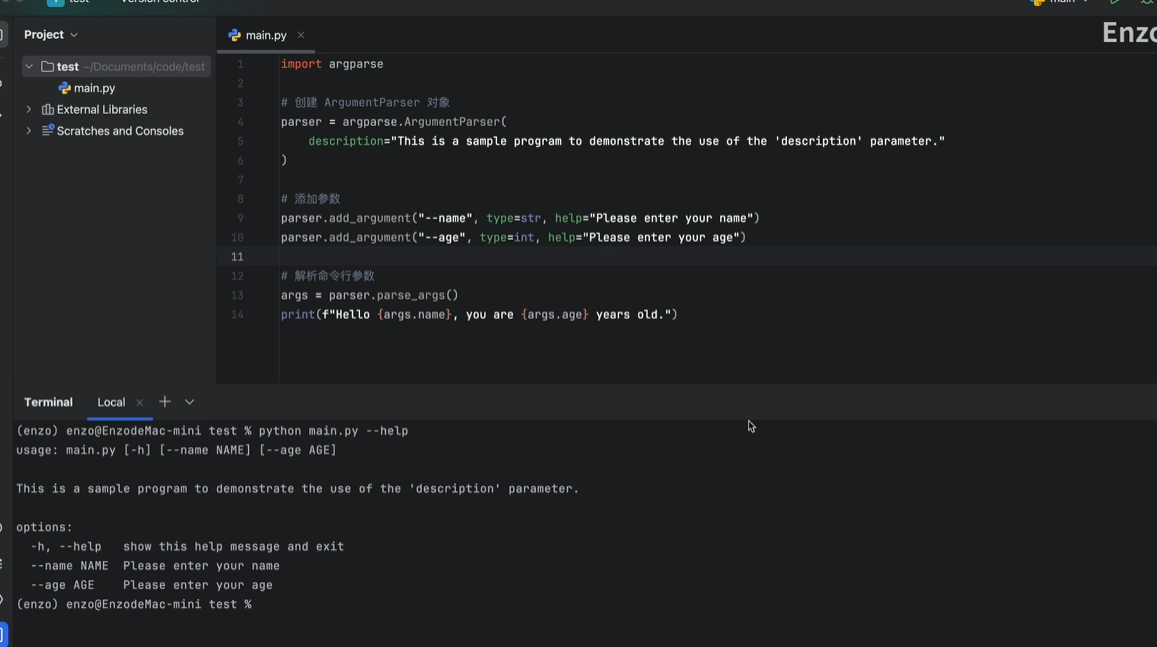
参数全称和缩写及选项
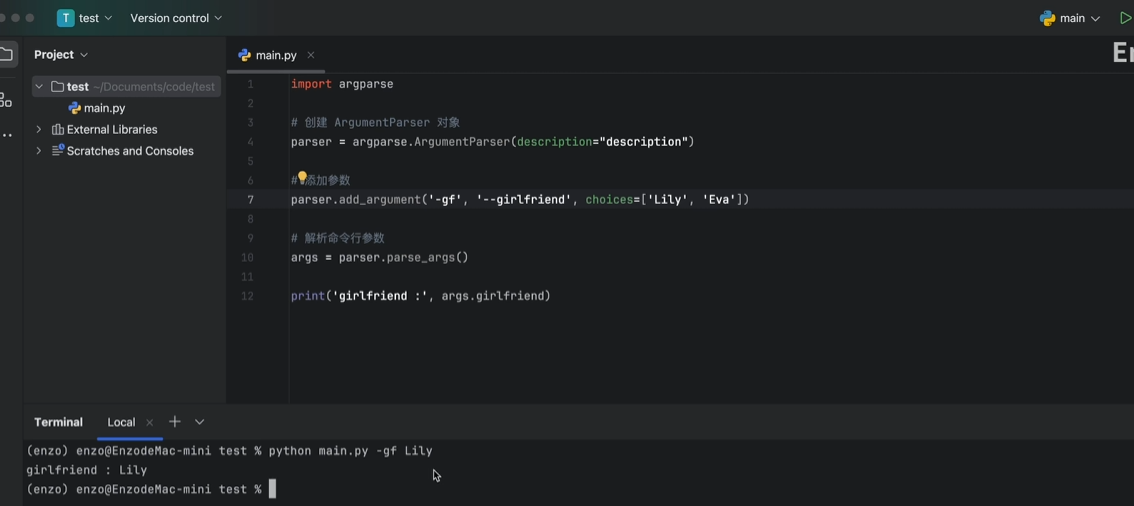
位置参数(需要按照添加参数顺序赋值)
没有默认值,必须指定参数值
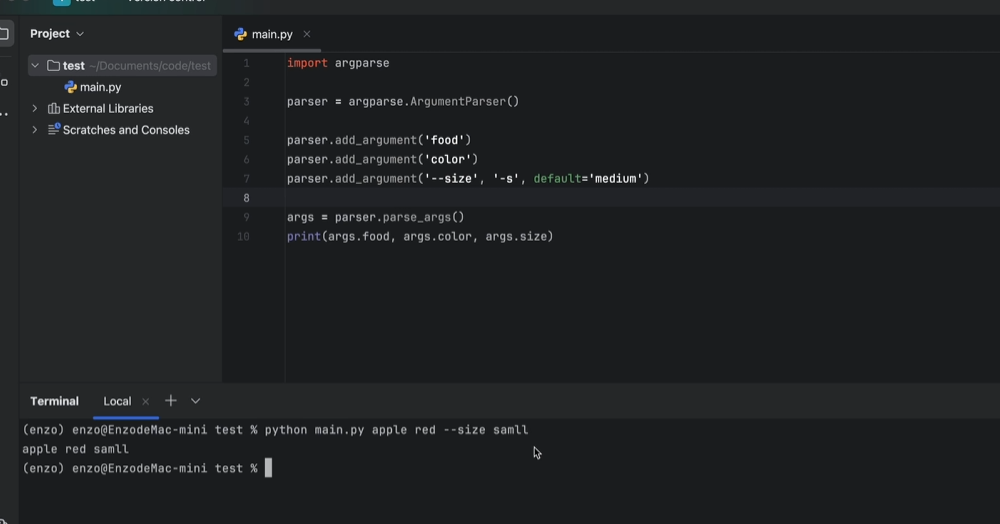
必填参数(requires=True
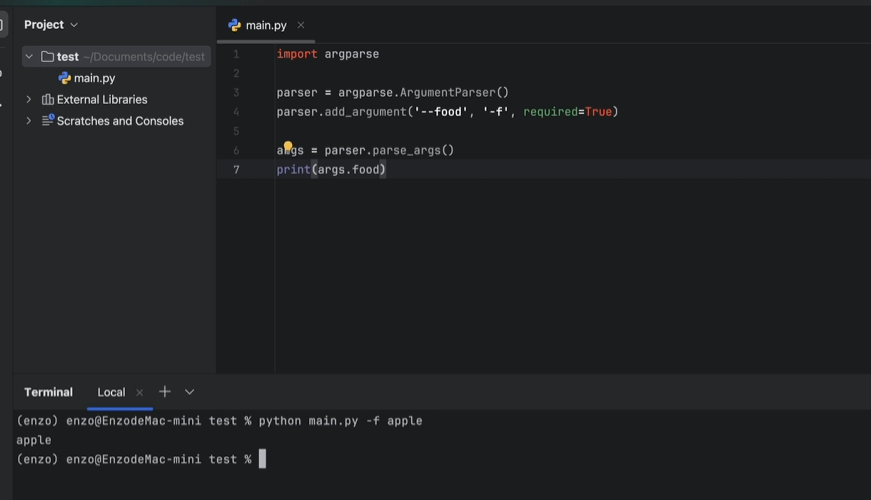
参数指定默认值和类型
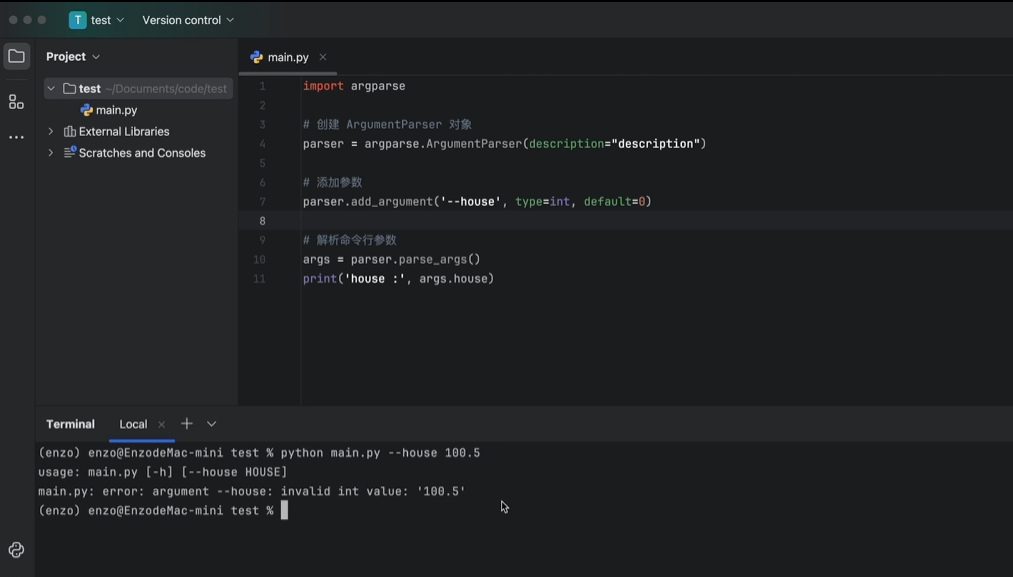
开关action (bool

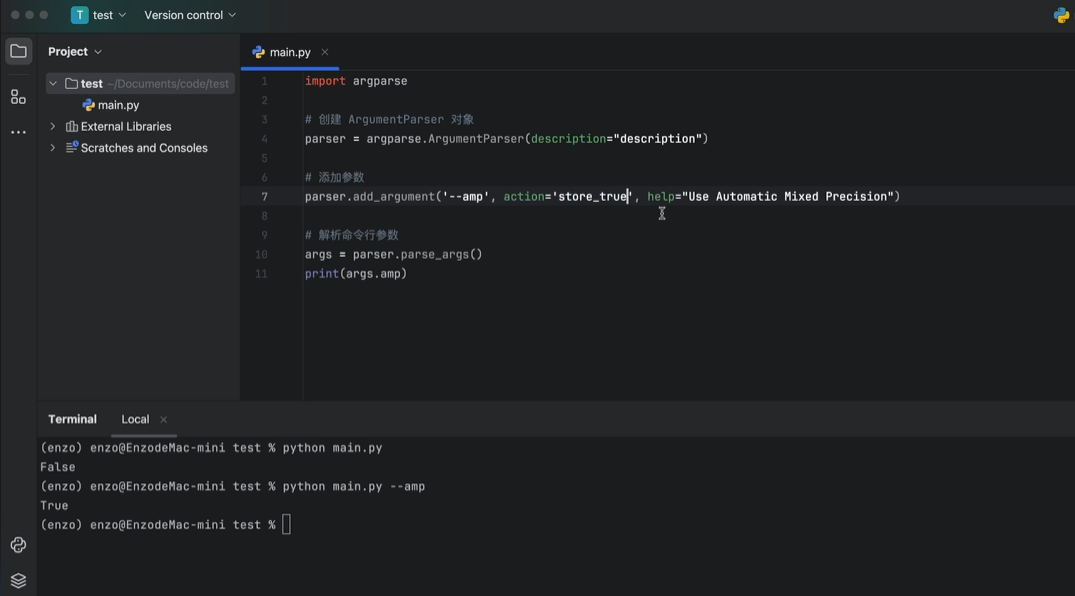
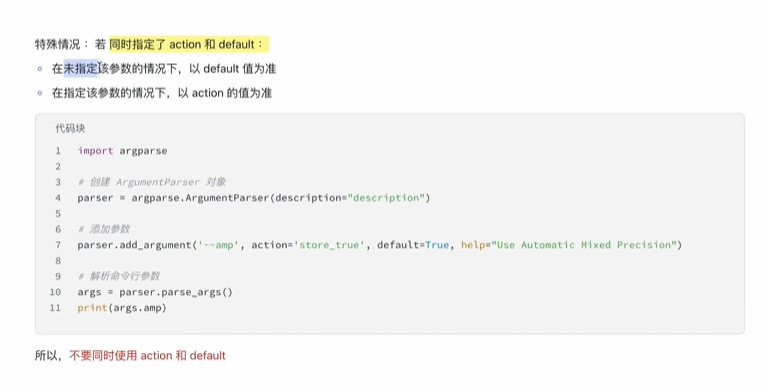
重定义变量名(dest=
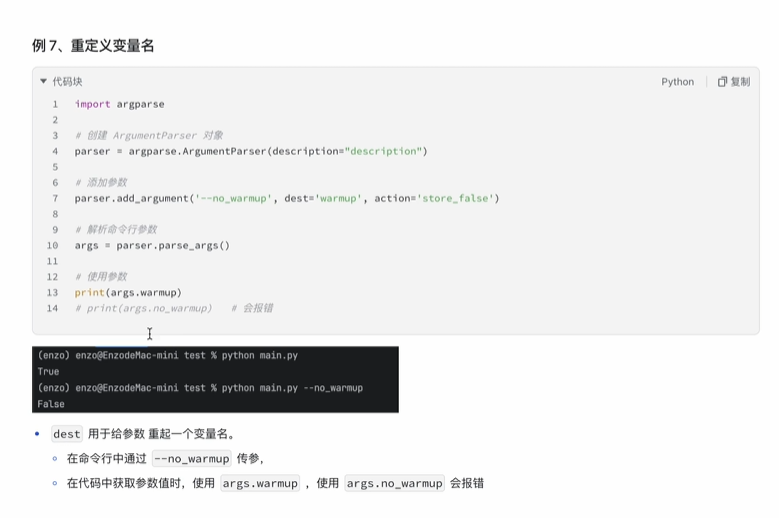
debug(带参数
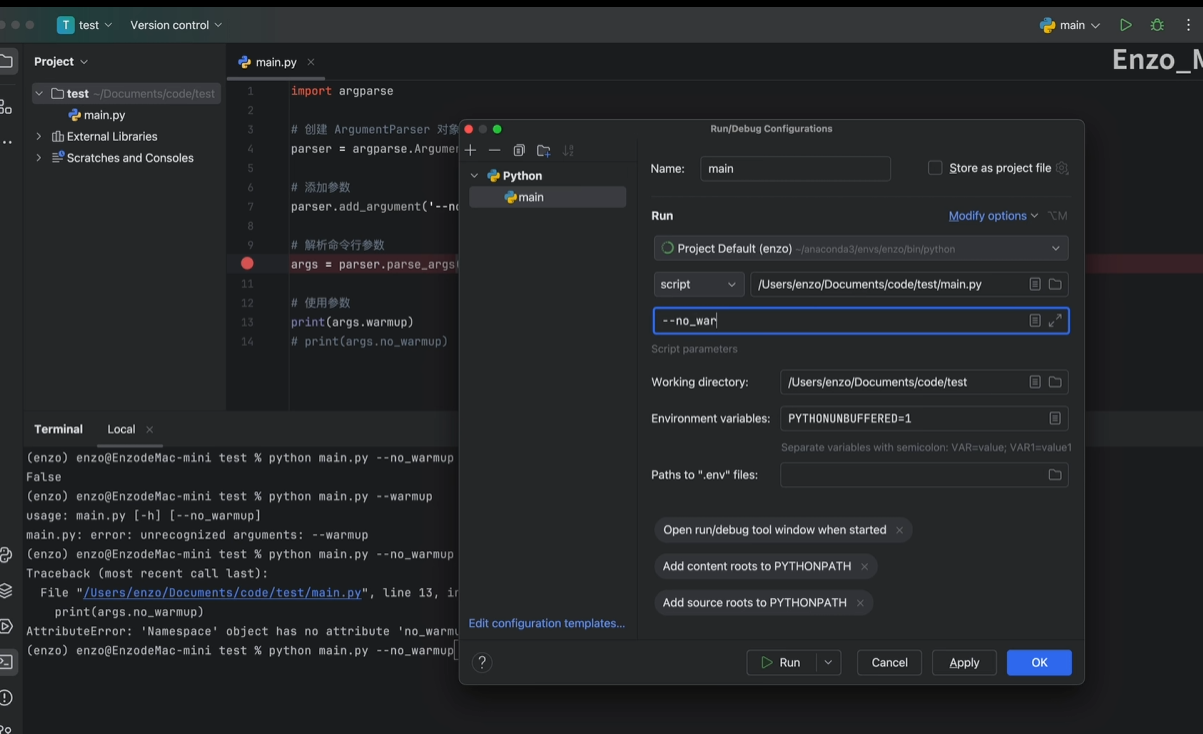
vscode中通过launch文件配置
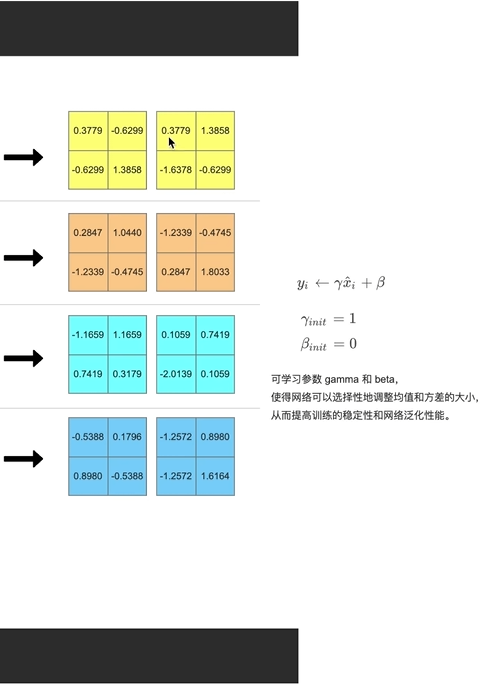
3.BN层
1.RGB三通道 分别归一化 操作


2.预处理后也做BN(考虑到计算,只对Batch 计算

3.计算过程
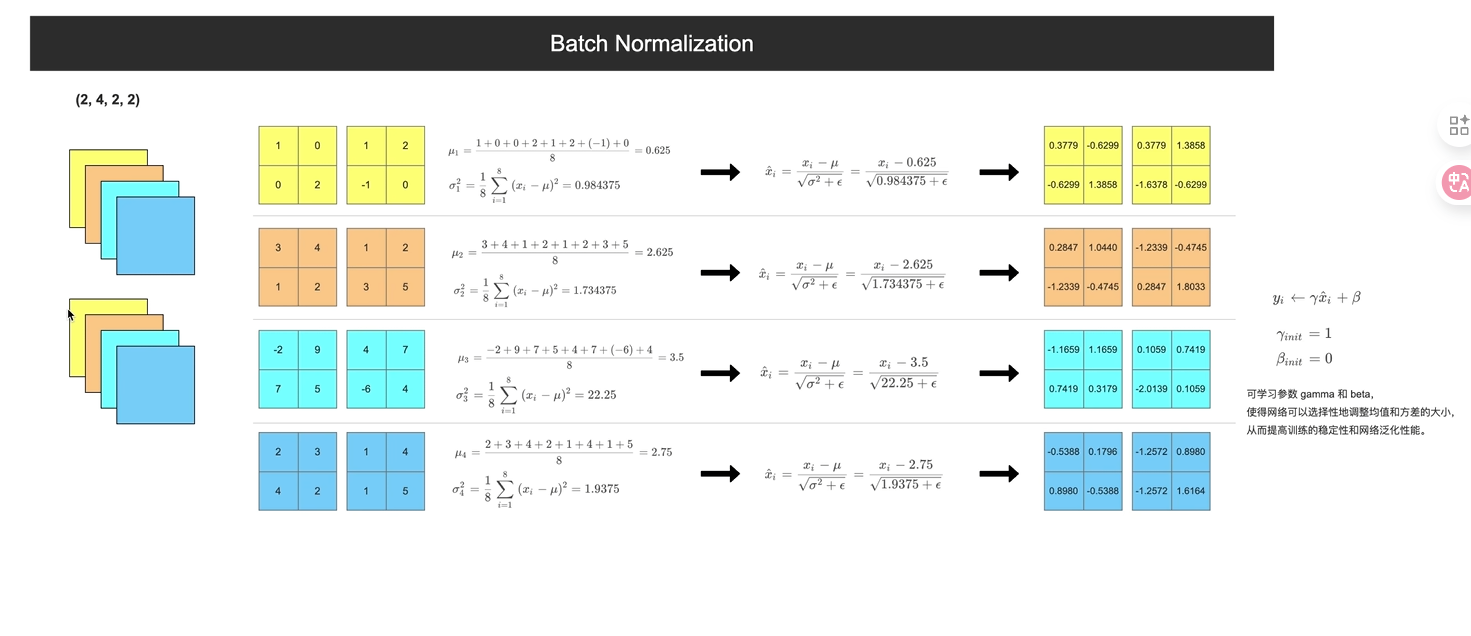
只在batchsize个样本上进行的;

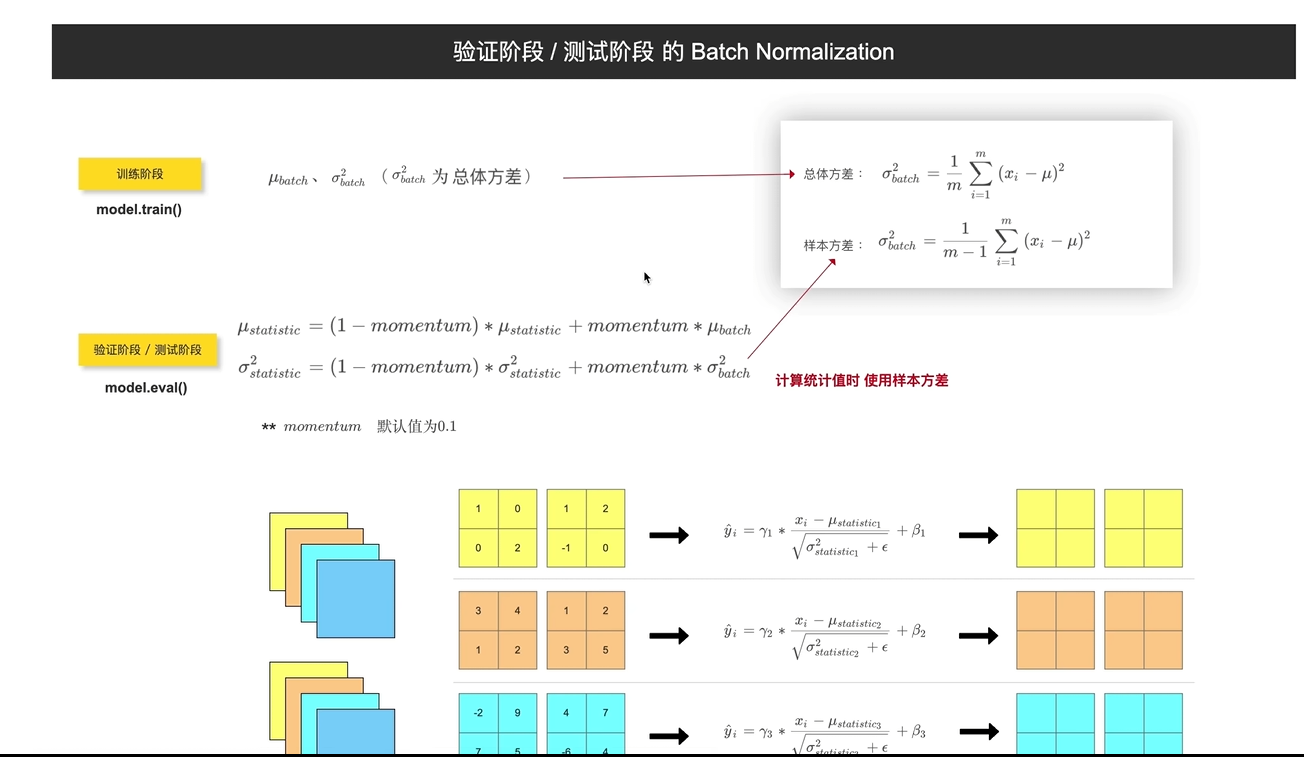
验证阶段(通常是一张而不是一个batch,利用的是训练阶段计算的全局均值和方差统计值
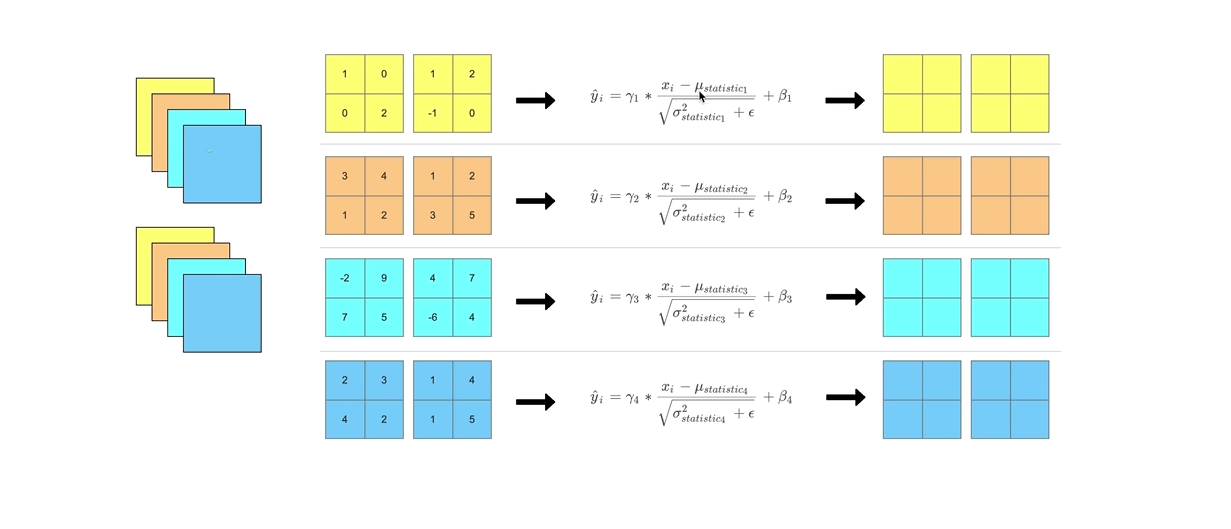
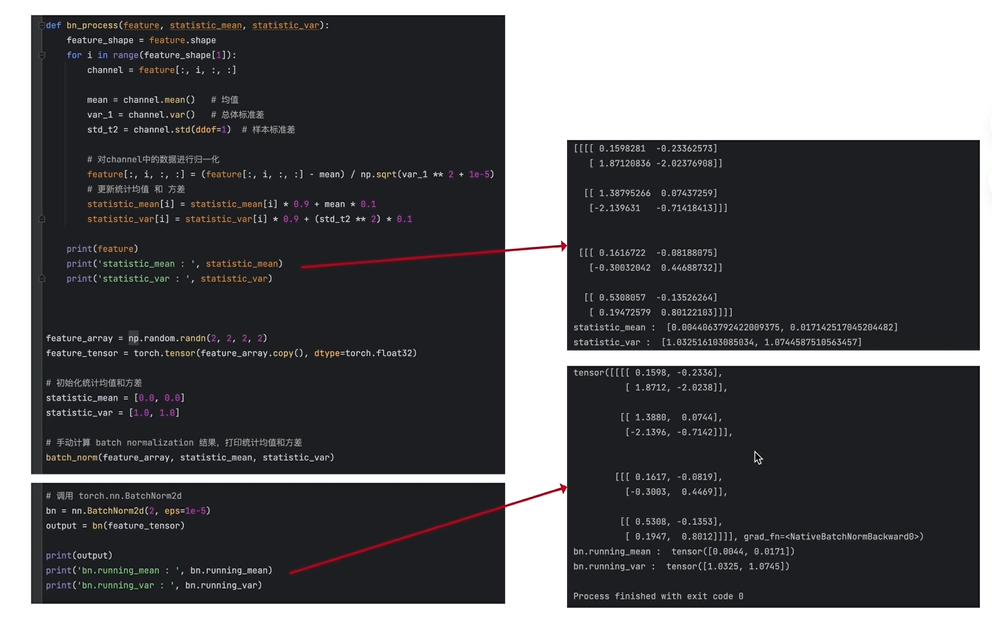
4.编程
加了BN,之前卷积的bias可以关掉

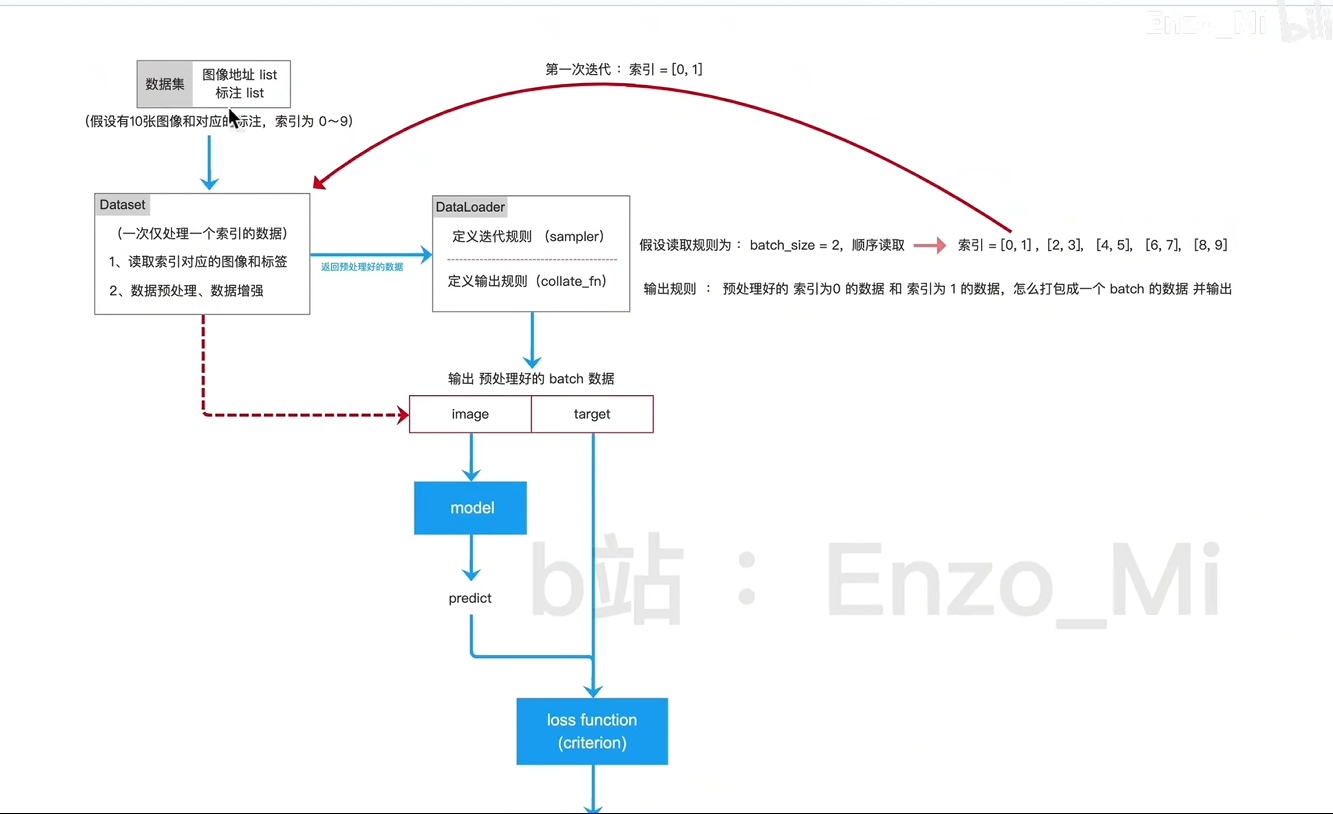
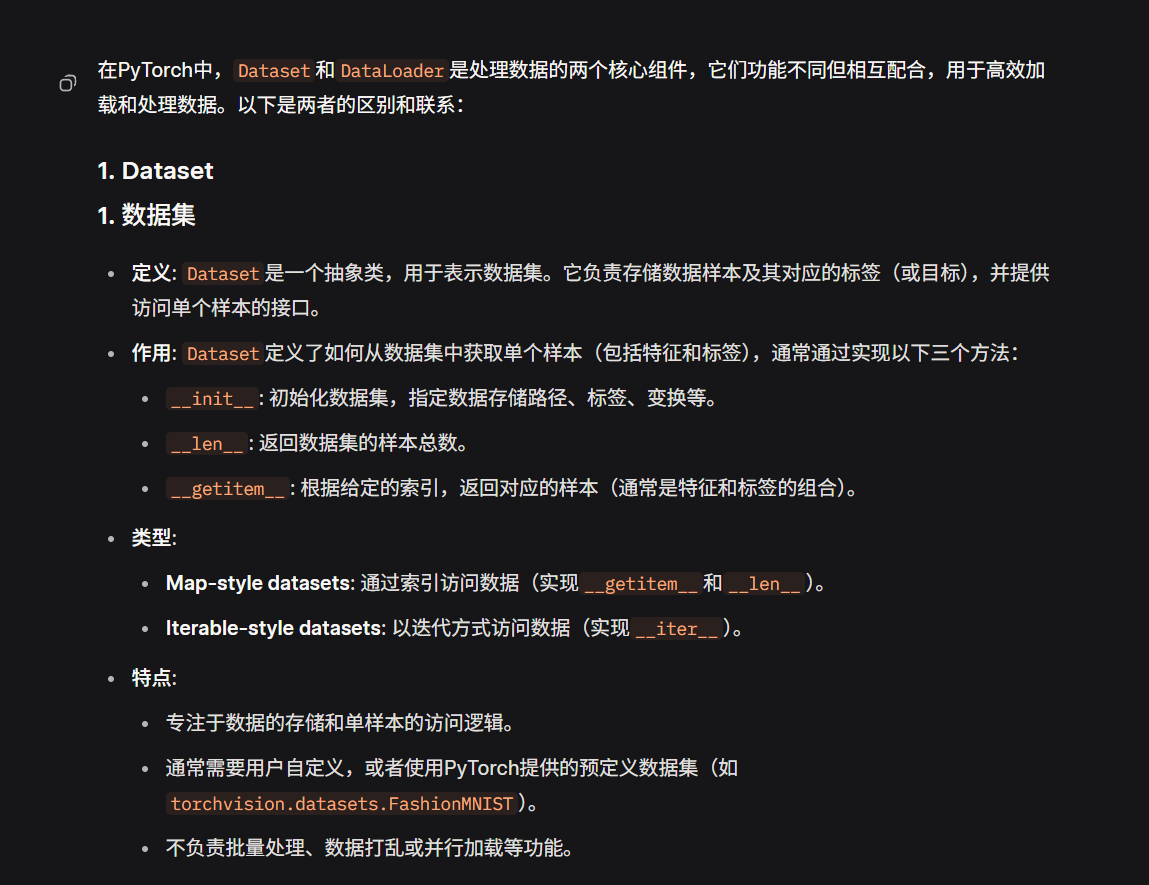
4.DataSet和DataLoader
dataset
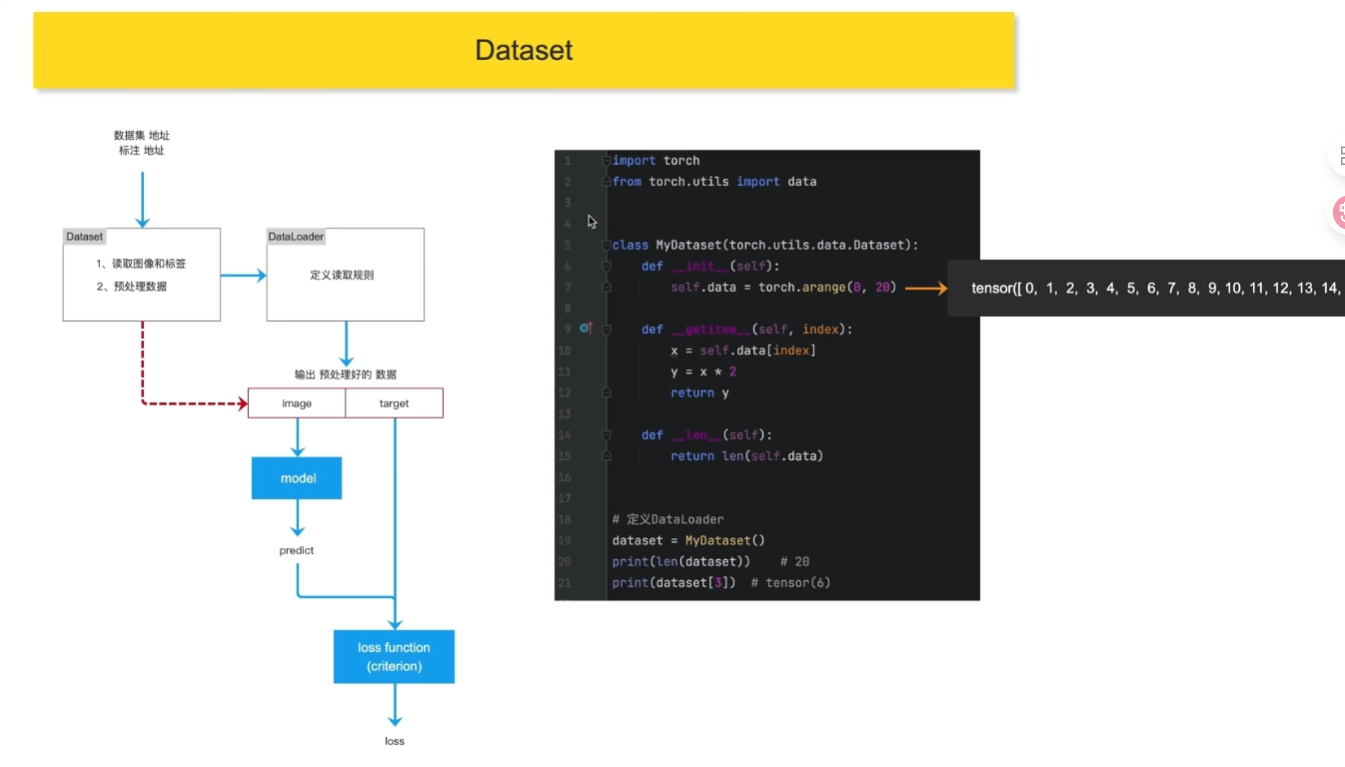
dataloader
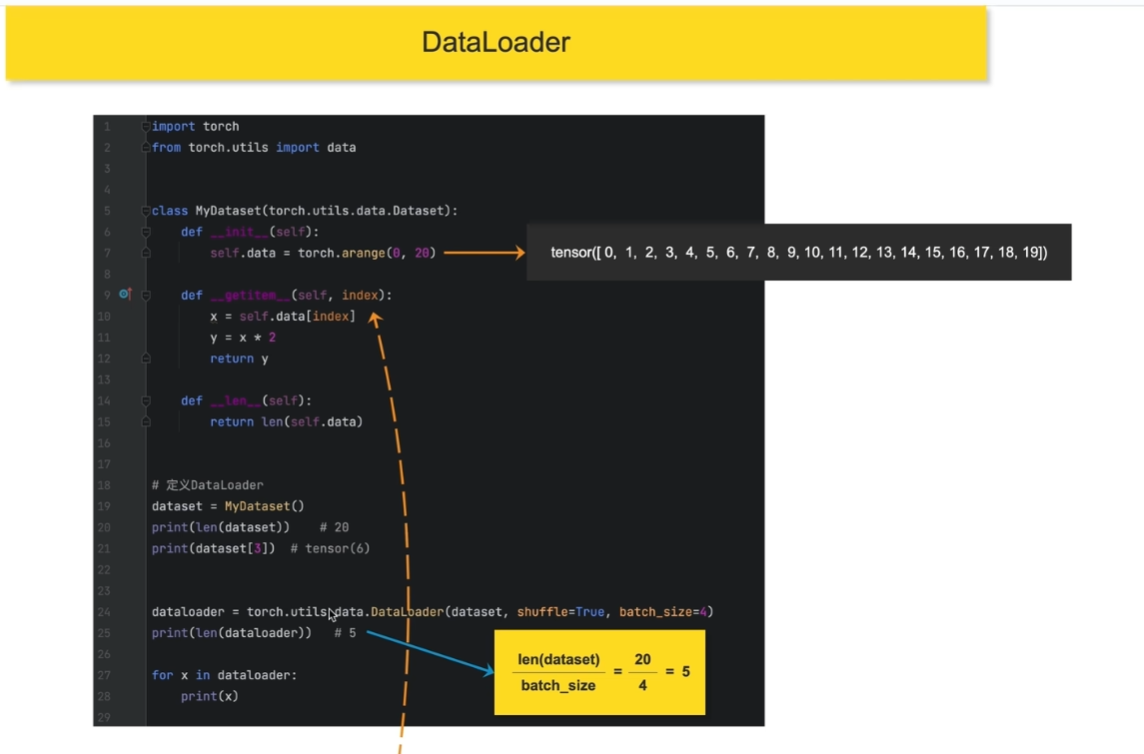
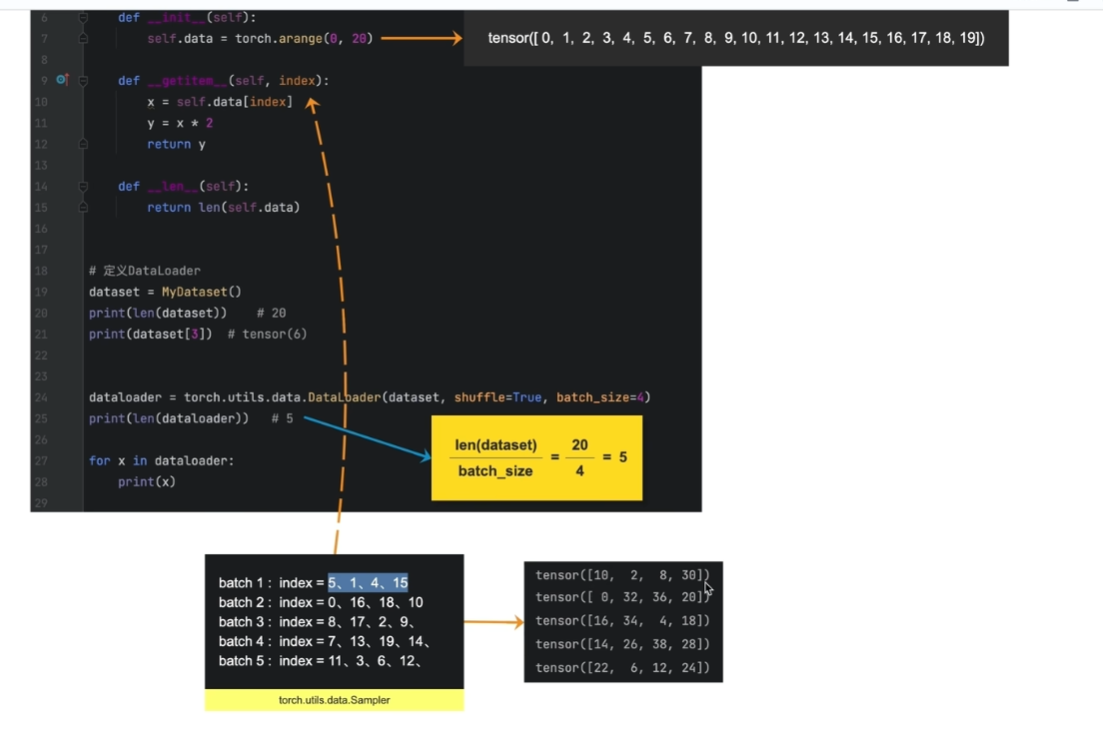
迭代出索引,找到set拿到结果
参数使用
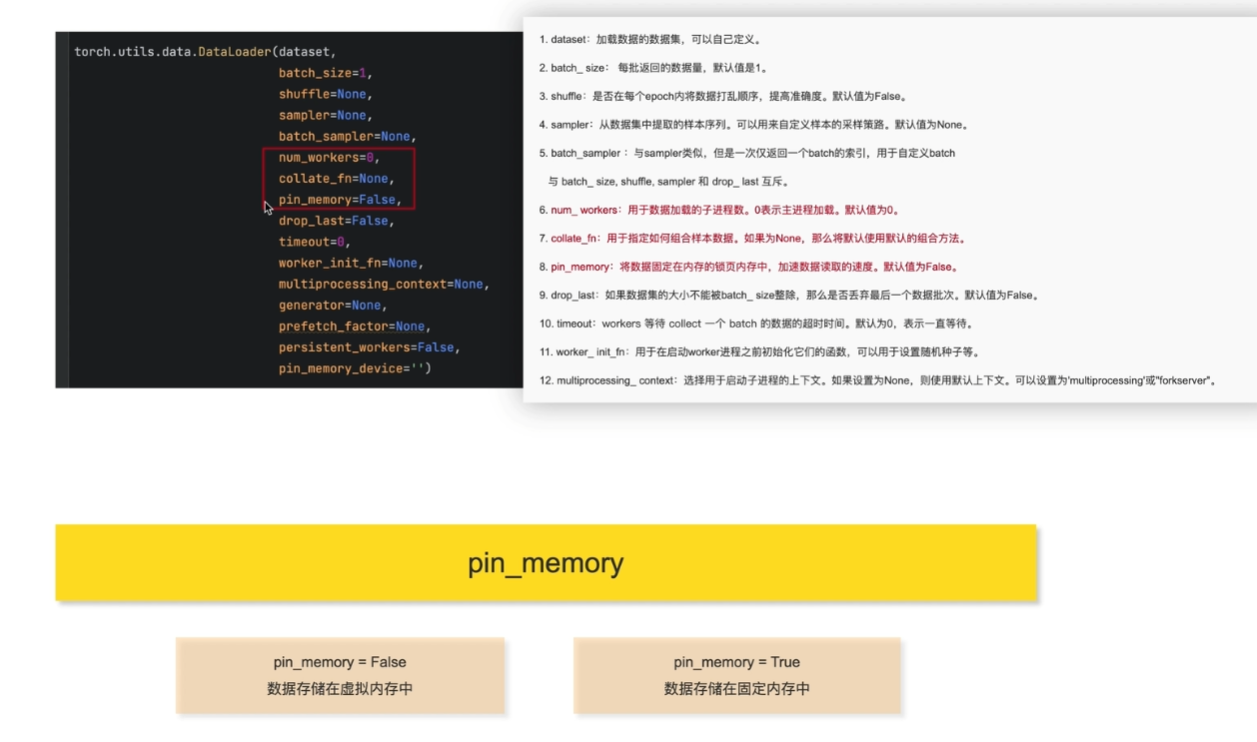
pin_momory(False就存在虚拟内存中,转存花销
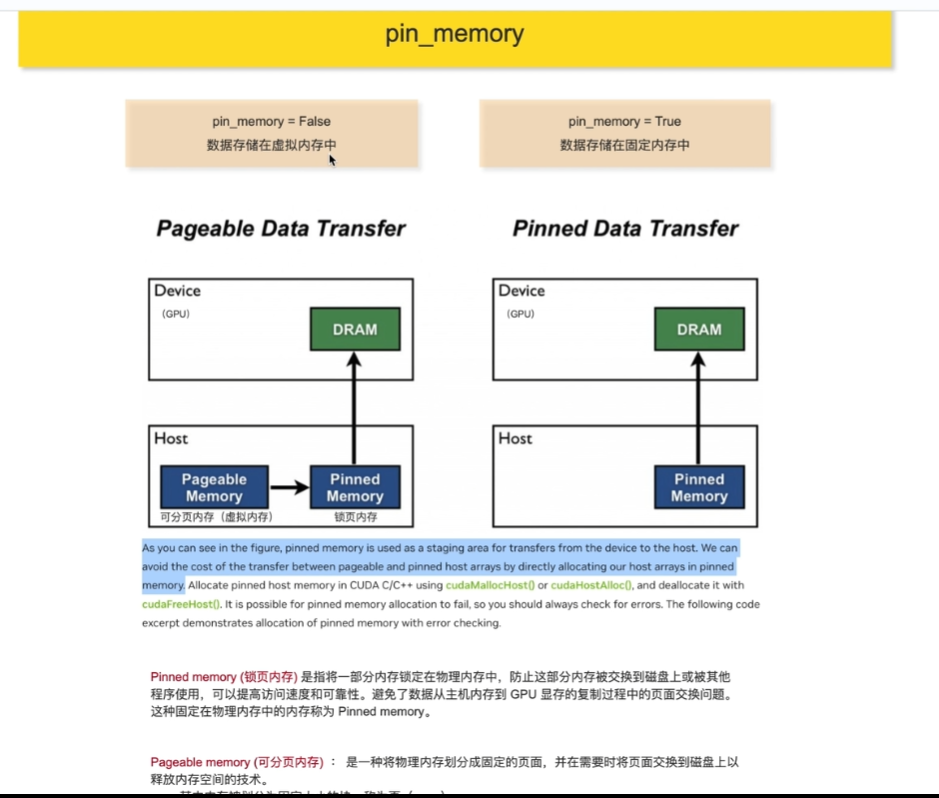
锁页内存被固定住,有效防止了页面交换问题,但会带来较大的性能开销。

num_workers(硬件配置

collate_fn
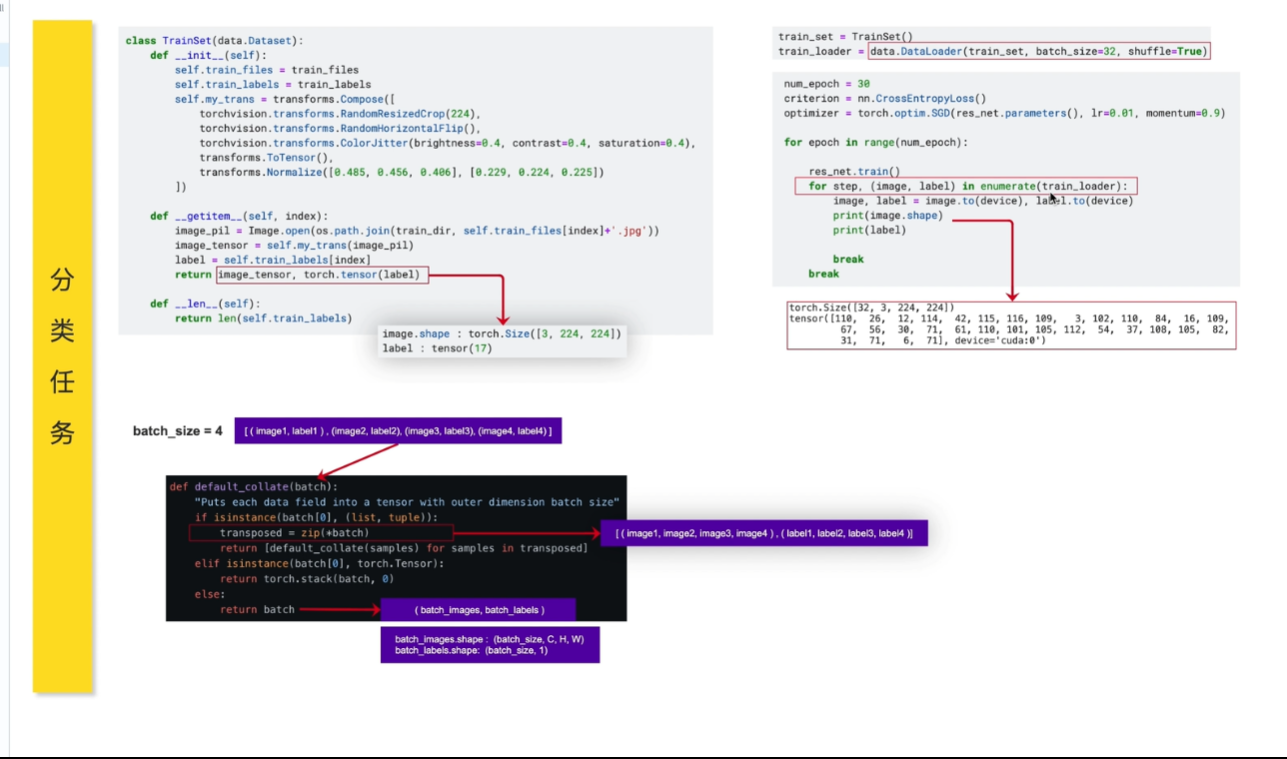
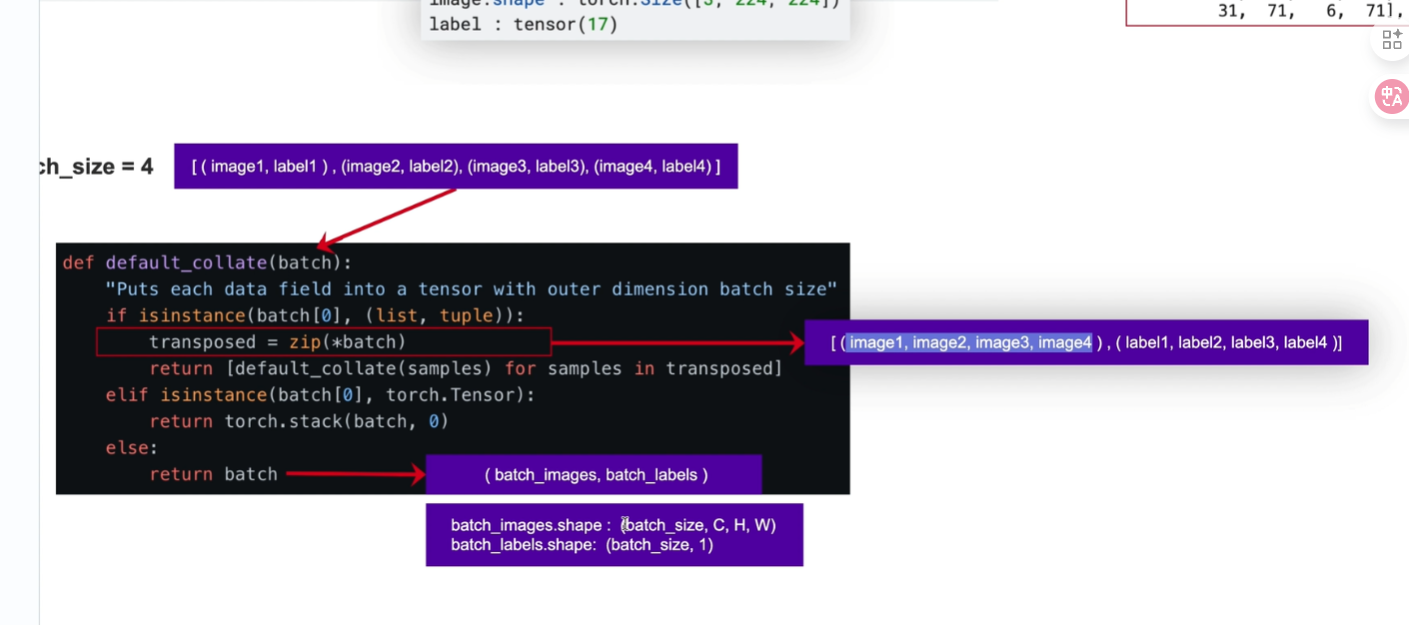
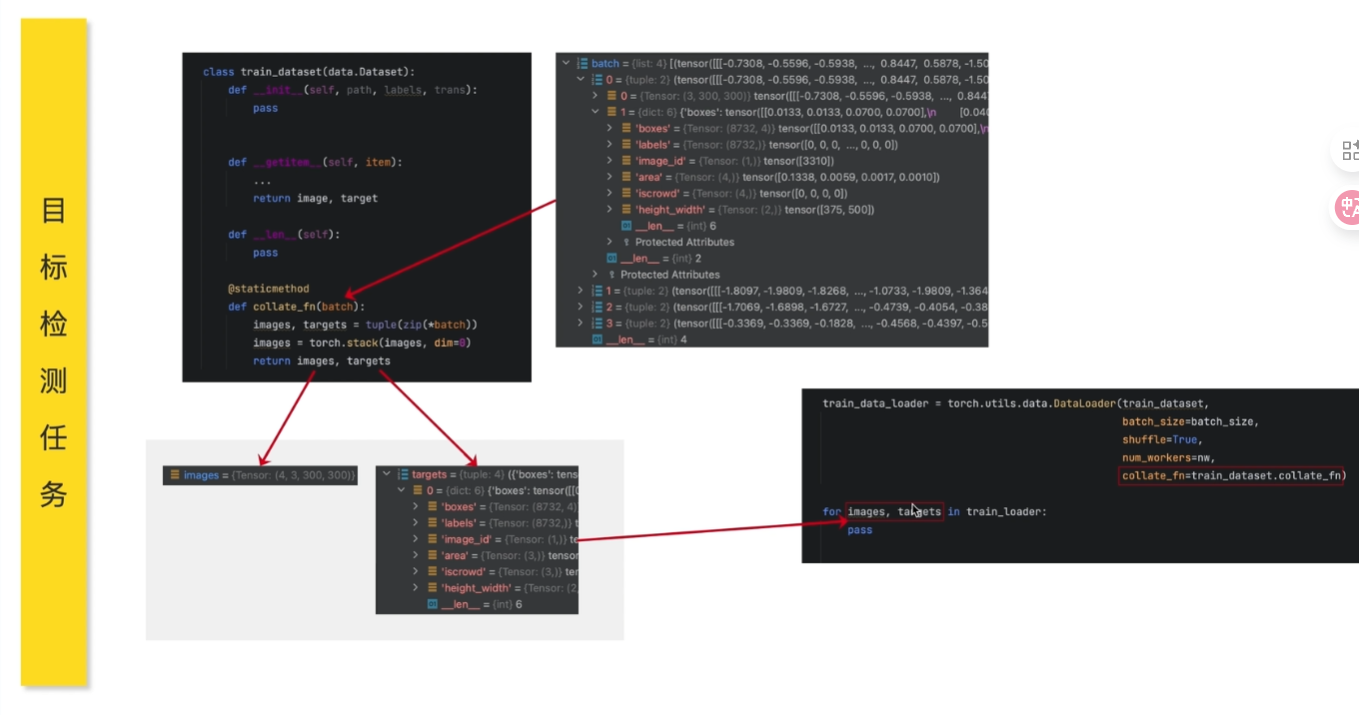
数据容器和数据加载器(按照一定规则加载数据)
from torch.utils.data import Dataset
class MyDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.labels[idx]
from torch.utils.data import DataLoader
dataset = MyDataset(data, labels)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
for batch_data, batch_labels in dataloader:# 训练模型print(batch_data.shape, batch_labels.shape)
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 定义Dataset
train_dataset = datasets.FashionMNIST(root="data",train=True,download=True,transform=transforms.ToTensor()
)# 创建DataLoader
train_dataloader = DataLoader(dataset=train_dataset,batch_size=64,shuffle=True,num_workers=4
)# 训练循环
for epoch in range(num_epochs):for images, labels in train_dataloader:# 模型训练代码print(images.shape, labels.shape) # 输出: torch.Size([64, 1, 28, 28]) torch.Size([64])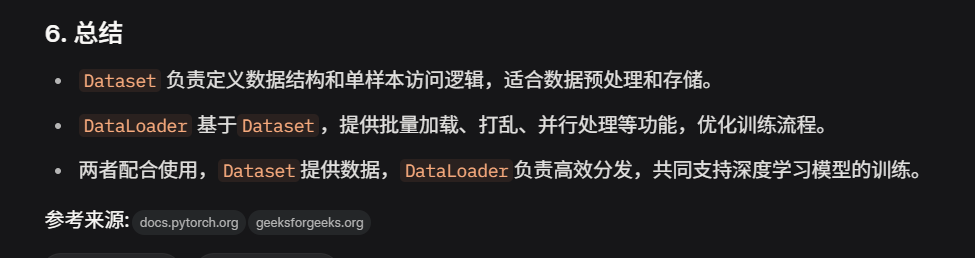
5.优化器
1




import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset# 模拟数据
X = torch.randn(100, 1) # 特征
y = 2 * X + 1 + 0.1 * torch.randn(100, 1) # 标签(加噪声)
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)# 定义模型
model = nn.Linear(1, 1)
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降# 训练循环
for epoch in range(100):for batch_X, batch_y in dataloader:# 前向传播outputs = model(batch_X)loss = criterion(outputs, batch_y)# 反向传播与优化optimizer.zero_grad() # 清空梯度loss.backward() # 计算梯度optimizer.step() # 更新参数if epoch % 10 == 0:print(f"Epoch {epoch}, Loss: {loss.item():.4f}")# 输出最终参数
print(f"Learned parameters: w = {model.weight.item():.4f}, b = {model.bias.item():.4f}")
2

缺
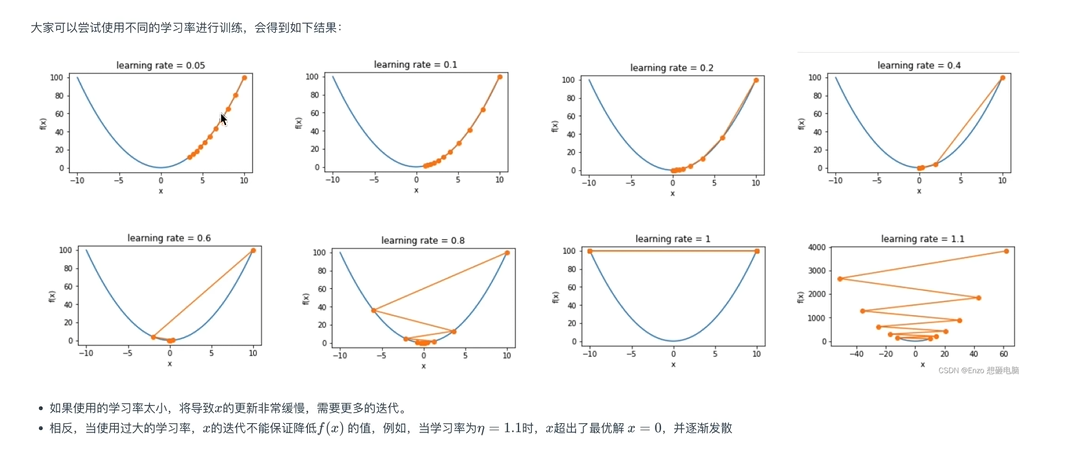


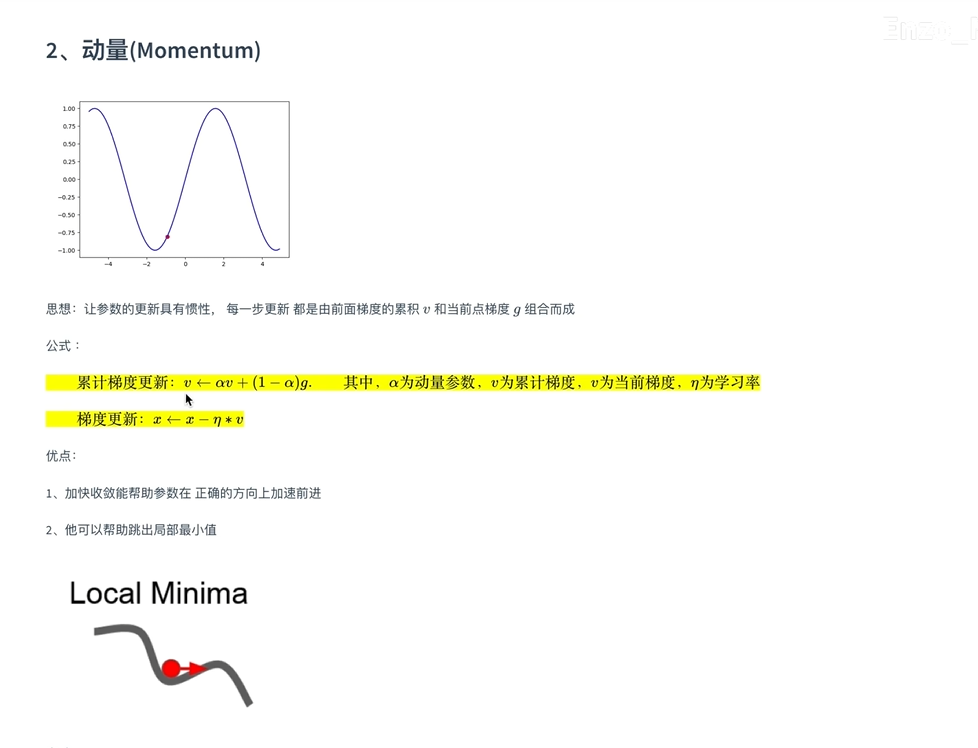
具有鲁棒性
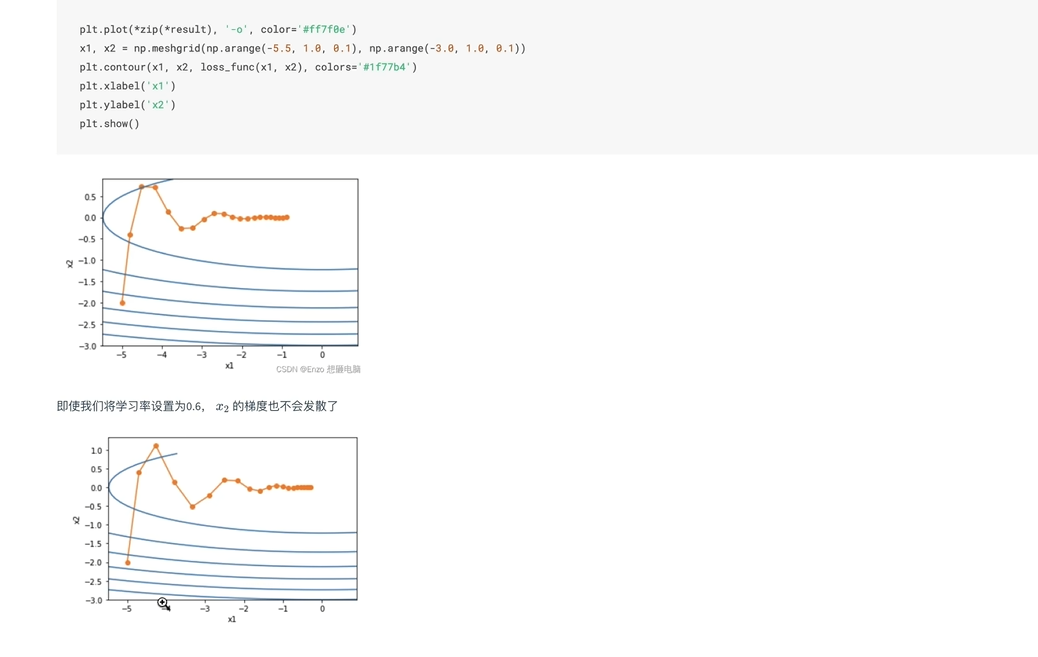

对不同参数使用不同学习率 ,梯度大的参数给较小学习率,减小步伐,避免振荡

RMS动量思想
Adam缝合
总结
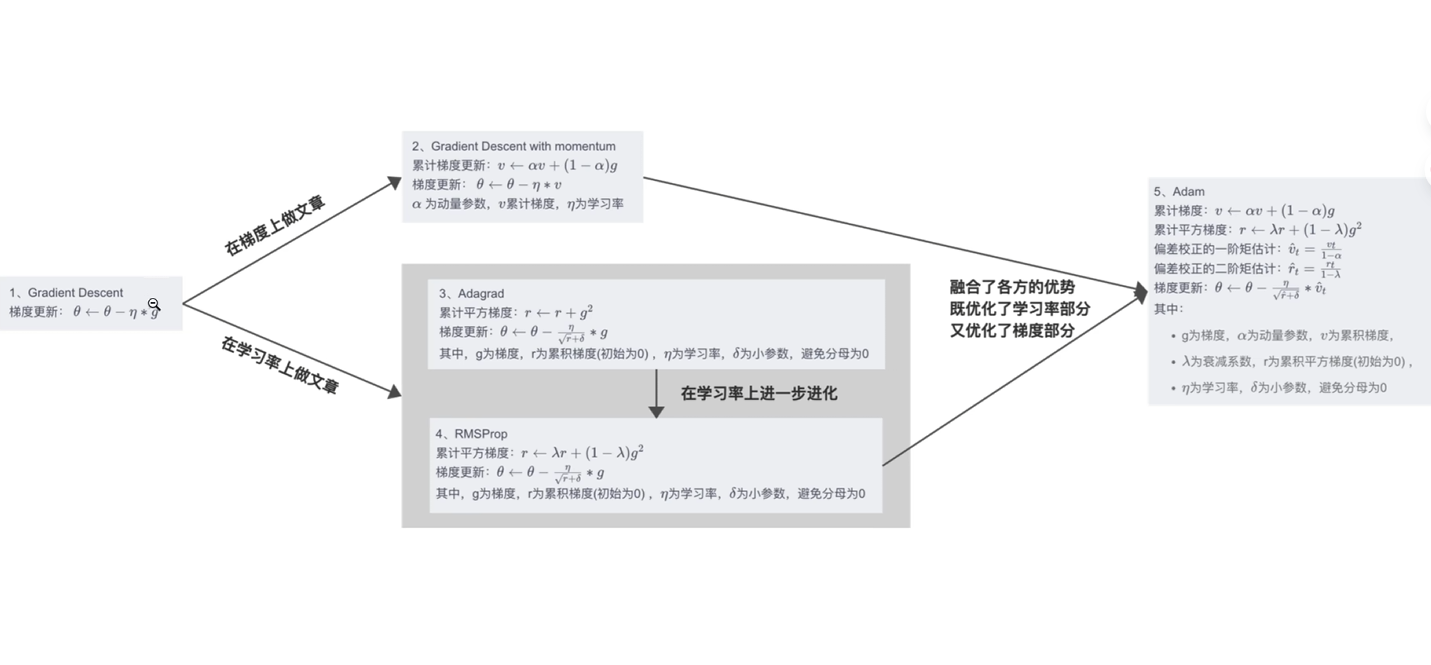
是的,梯度下降法的本质是让参数沿着损失函数下降最快的方向(梯度的反方向)更新,以逐步减小损失函数的值,最终逼近最优解。这种方法在每次迭代中选择局部最优的下降方向,是优化算法的核心思想。
6.层 增删改
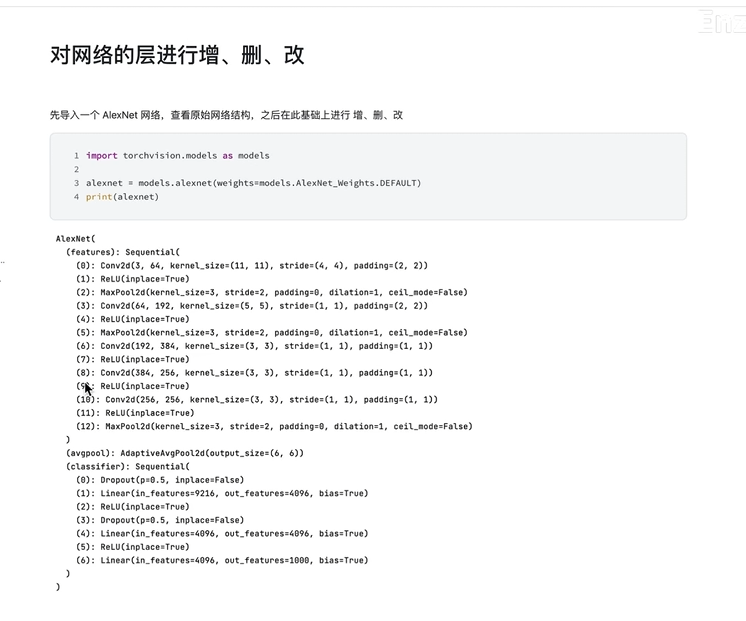
1.删除网络中的模块
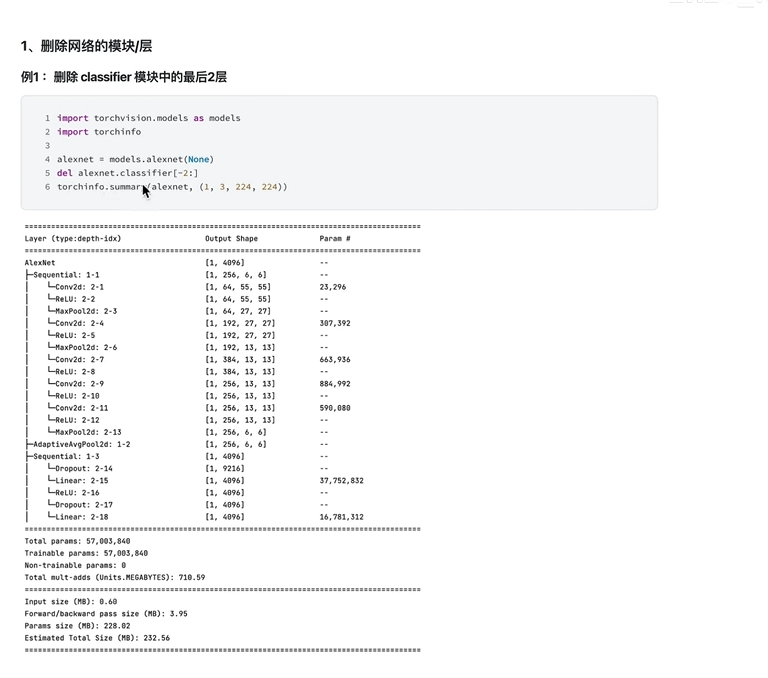
删整个模块(直接改forward模块就行
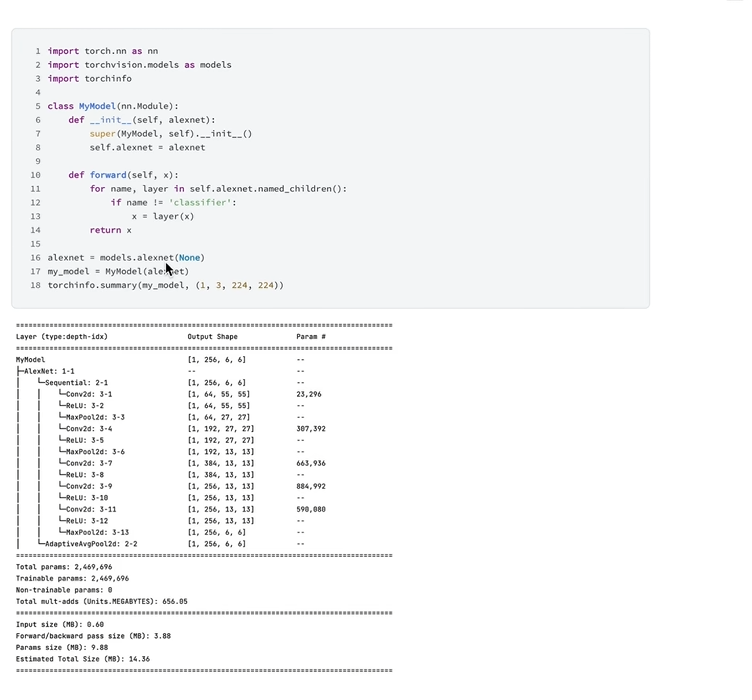
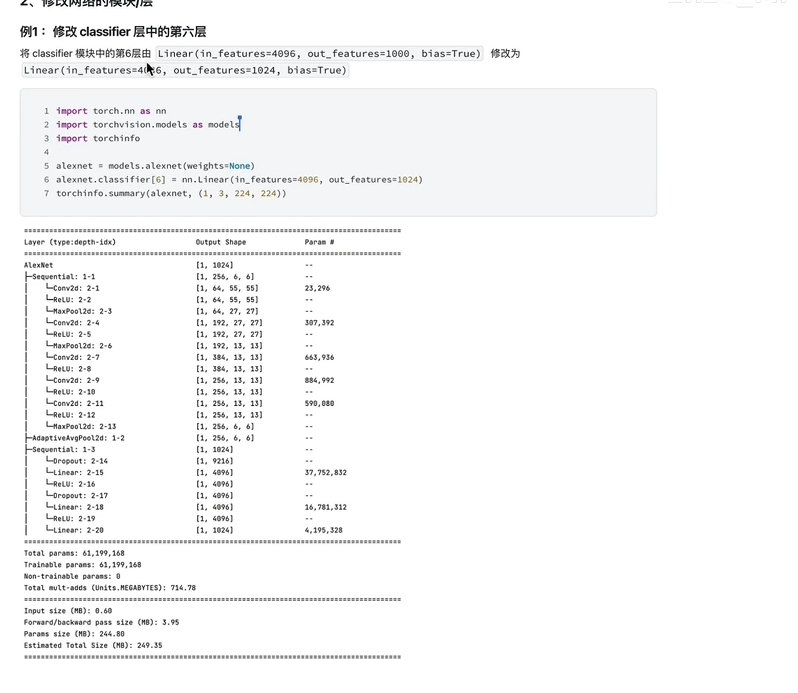
2.修改网络中的模块
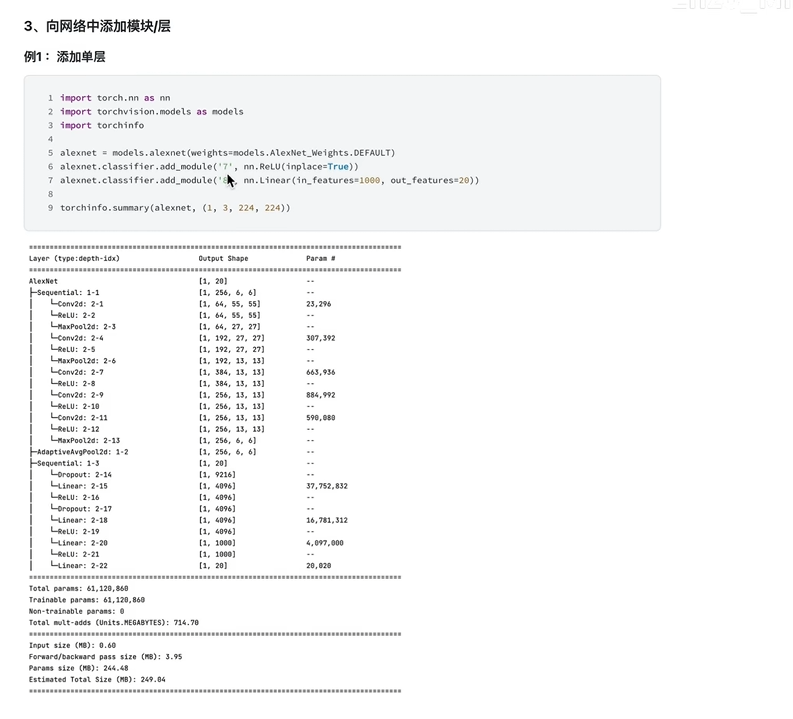
3.添加模块 add_module 追加层
添加模块
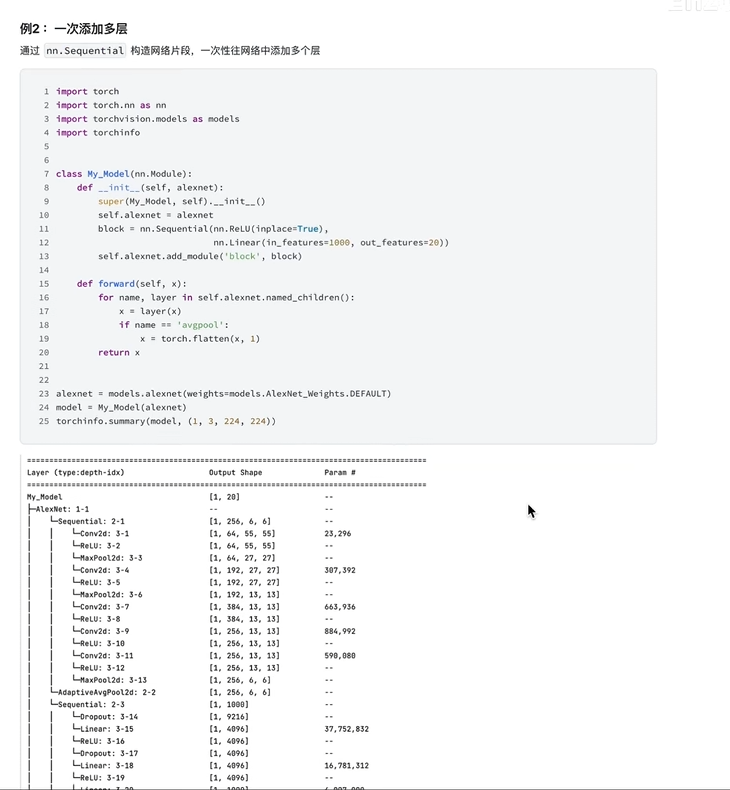
eg:

7.切换网络模式

评估阶段一般不调用backward
 8.Float32、Float16、BFloat16
8.Float32、Float16、BFloat16

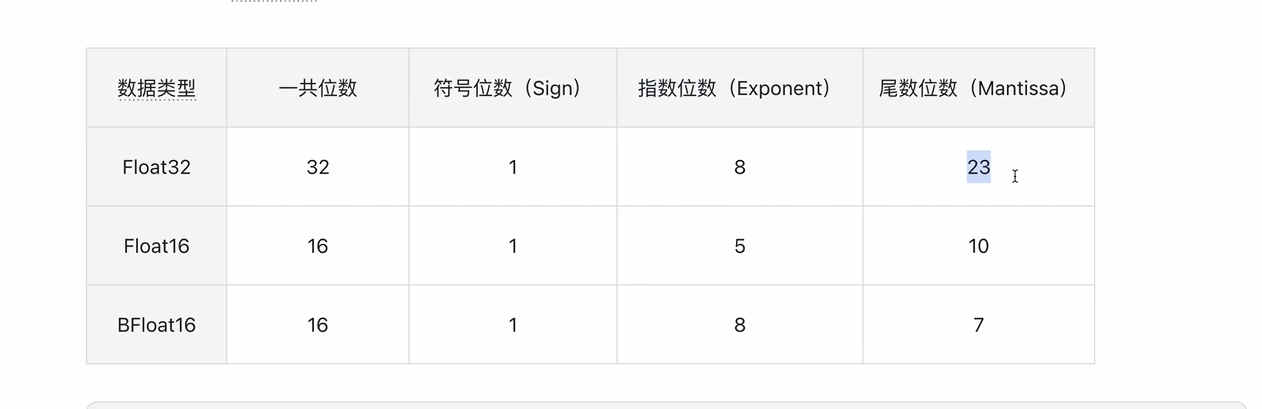
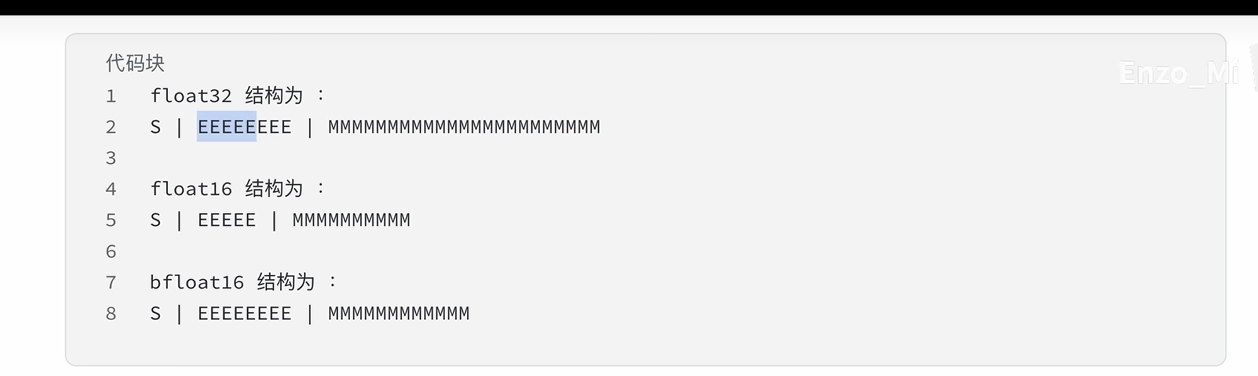

精度



Bias

数值范围和精度



混合精度



import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from torch.cuda.amp import autocast, GradScaler# 模拟数据
X = torch.randn(1000, 10).cuda()
y = torch.randn(1000, 1).cuda()
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 定义模型
model = nn.Linear(10, 1).cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 初始化 GradScaler 用于损失缩放
scaler = GradScaler()# 训练循环
for epoch in range(10):for batch_X, batch_y in dataloader:batch_X, batch_y = batch_X.cuda(), batch_y.cuda()# 前向传播使用 autocast 自动混合精度with autocast():outputs = model(batch_X)loss = criterion(outputs, batch_y)# 反向传播和优化optimizer.zero_grad() # 清空梯度scaler.scale(loss).backward() # 缩放损失并反向传播scaler.step(optimizer) # 更新权重scaler.update() # 更新缩放因子print(f"Epoch {epoch}, Loss: {loss.item():.4f}")# 输出最终参数
print(f"Learned parameters: w = {model.weight.data}, b = {model.bias.data}")


9.损失函数



概念
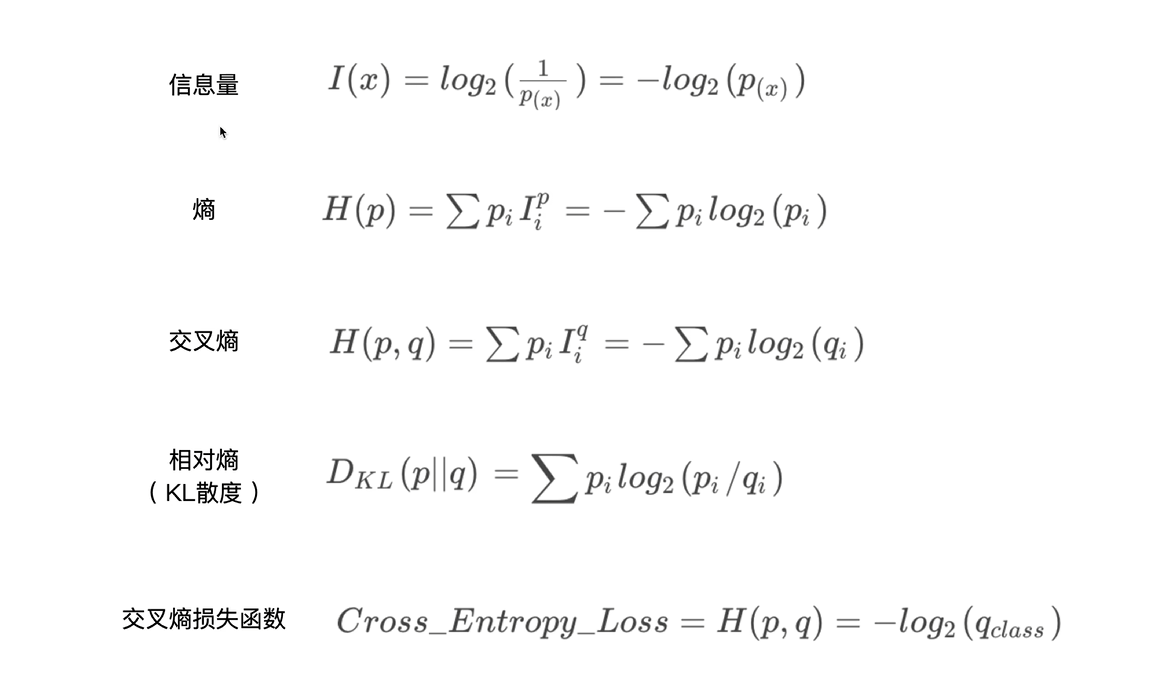
信息量


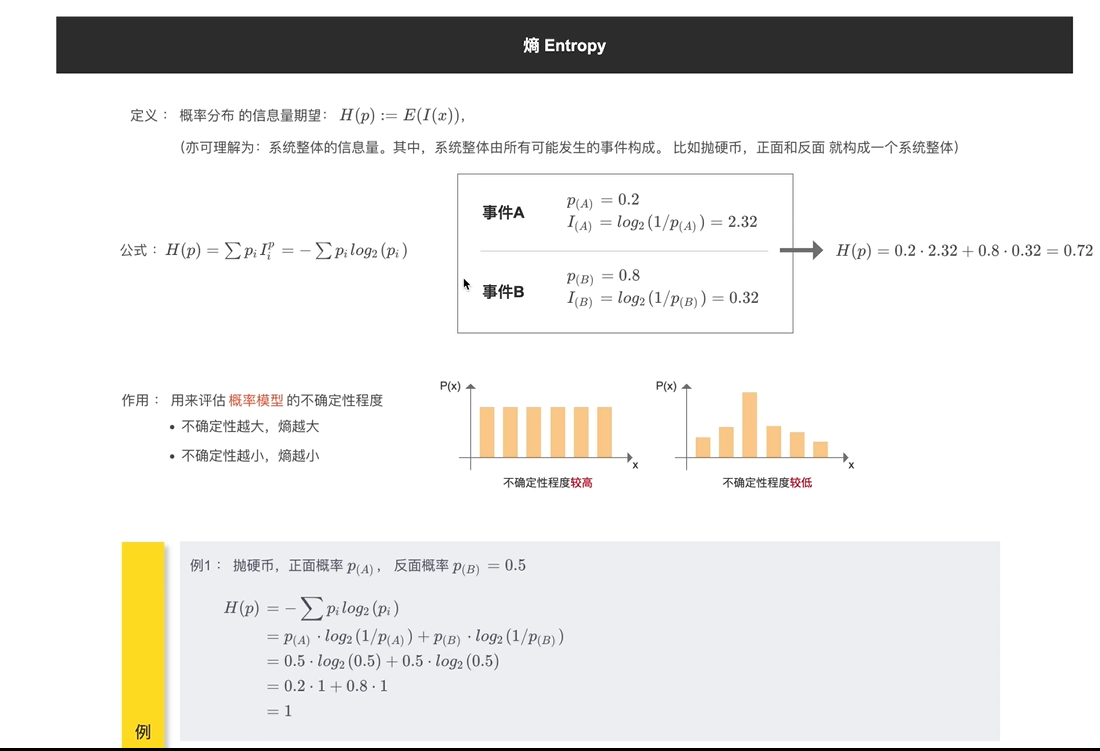
熵
概率 分布信息量期望
评估概率模型不确定性程度

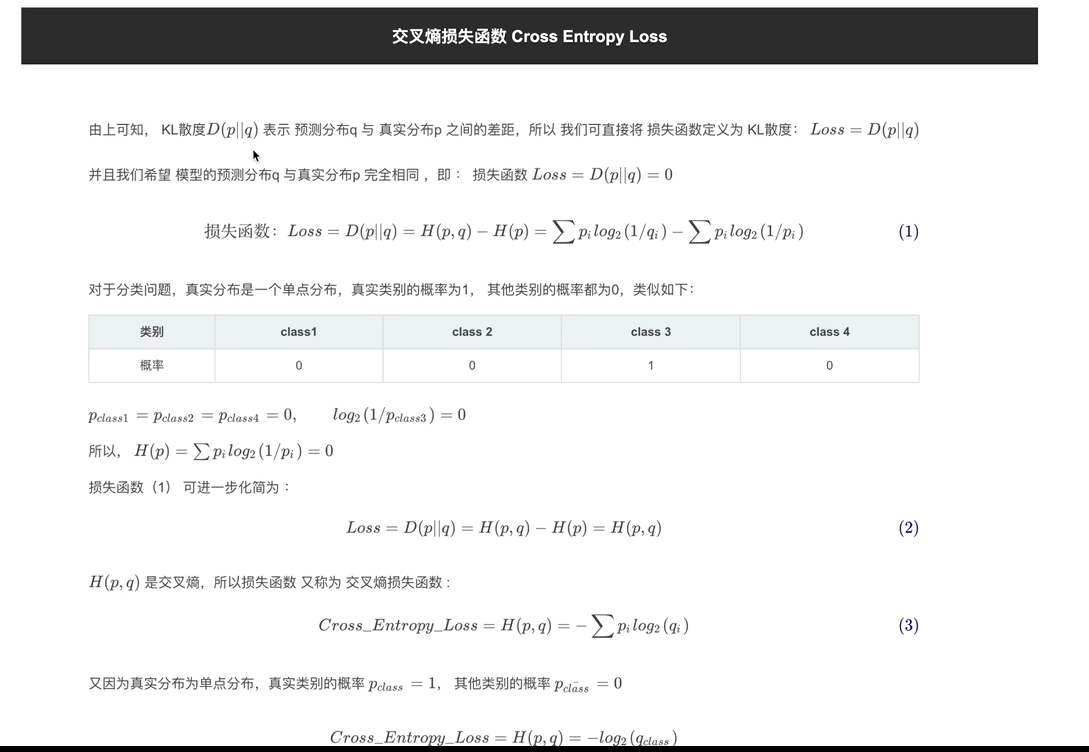
交叉熵


KL散度
分布间的差异


交叉熵损失值
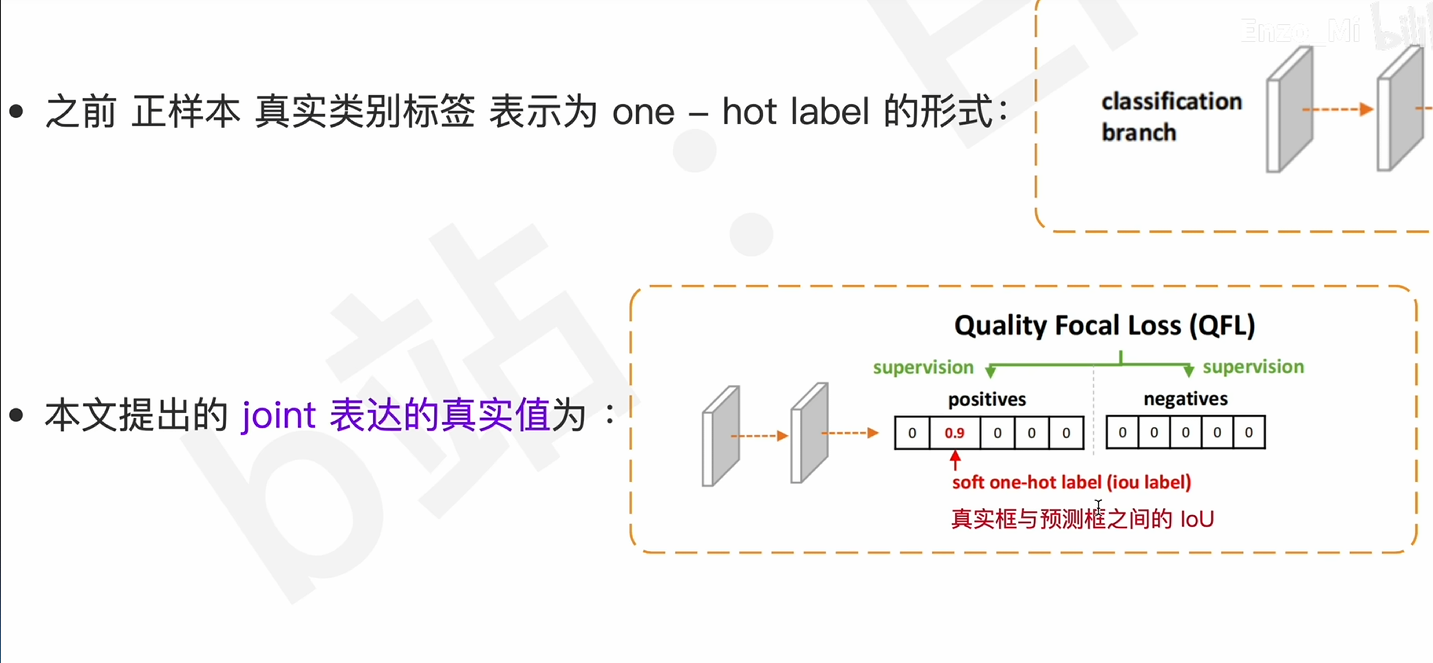
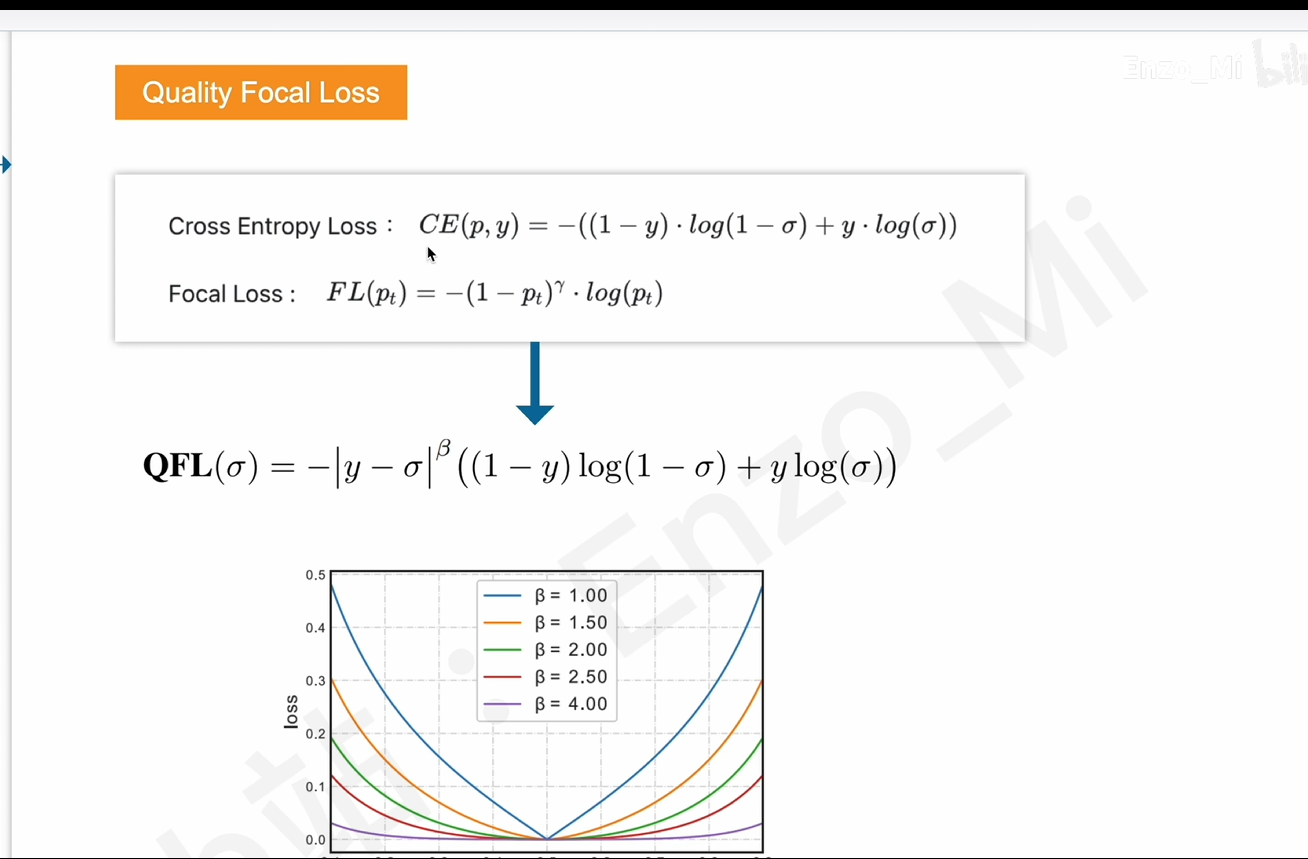
QFL损失函数


解决方案
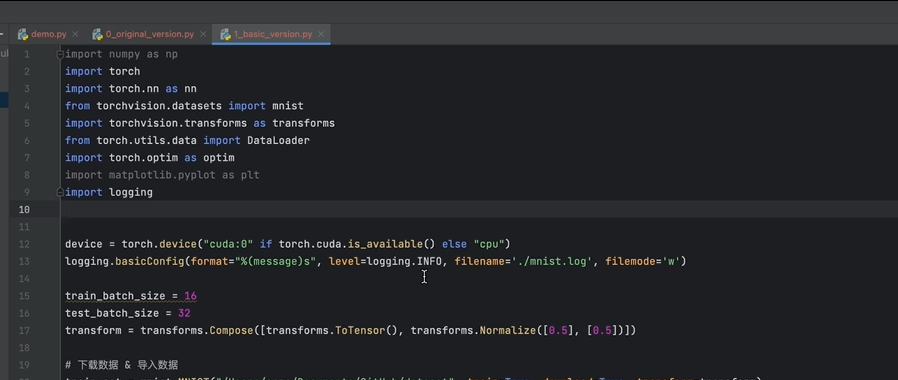
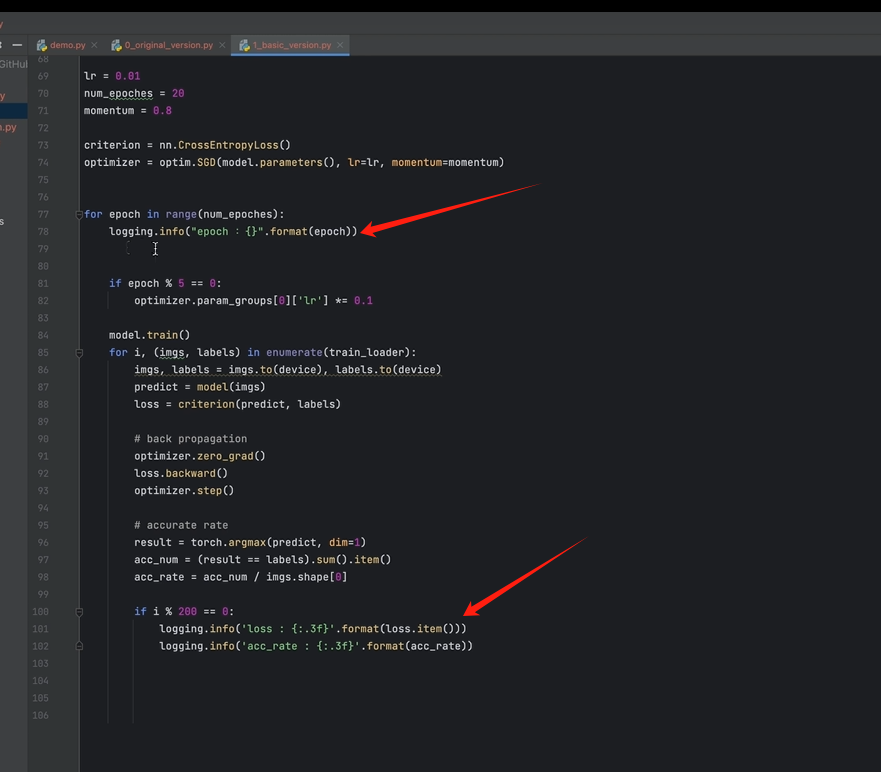
10.训练日志
logging
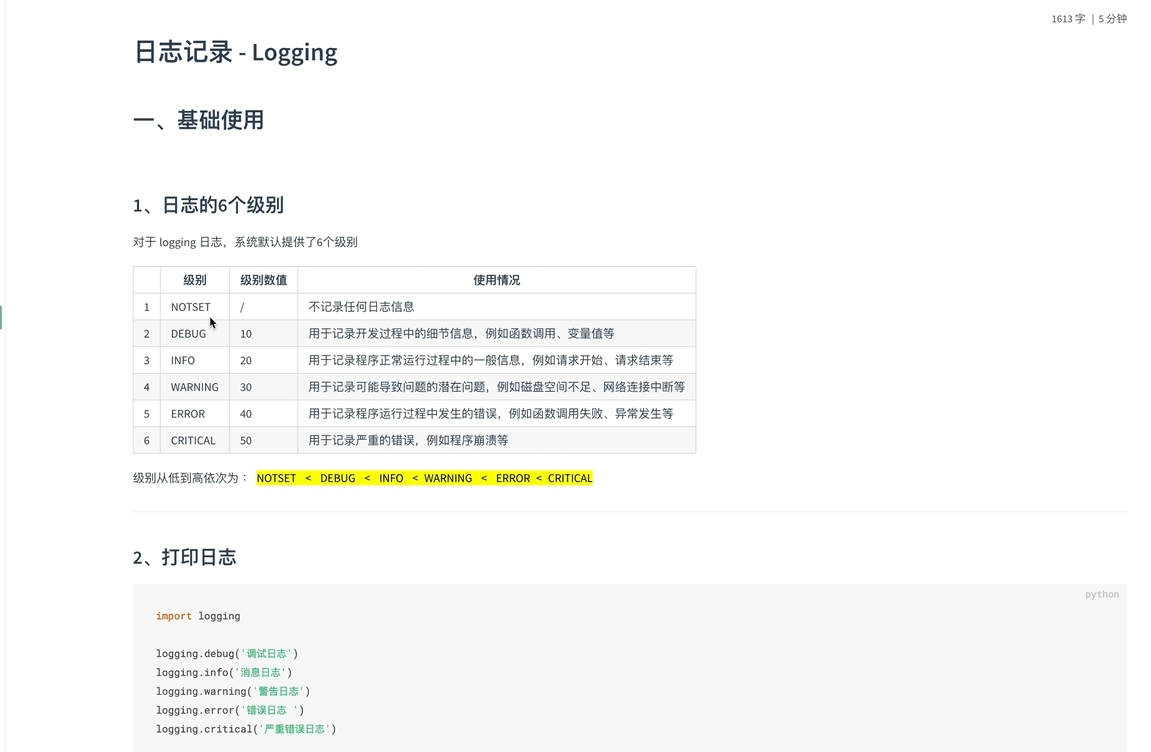
和print相似处
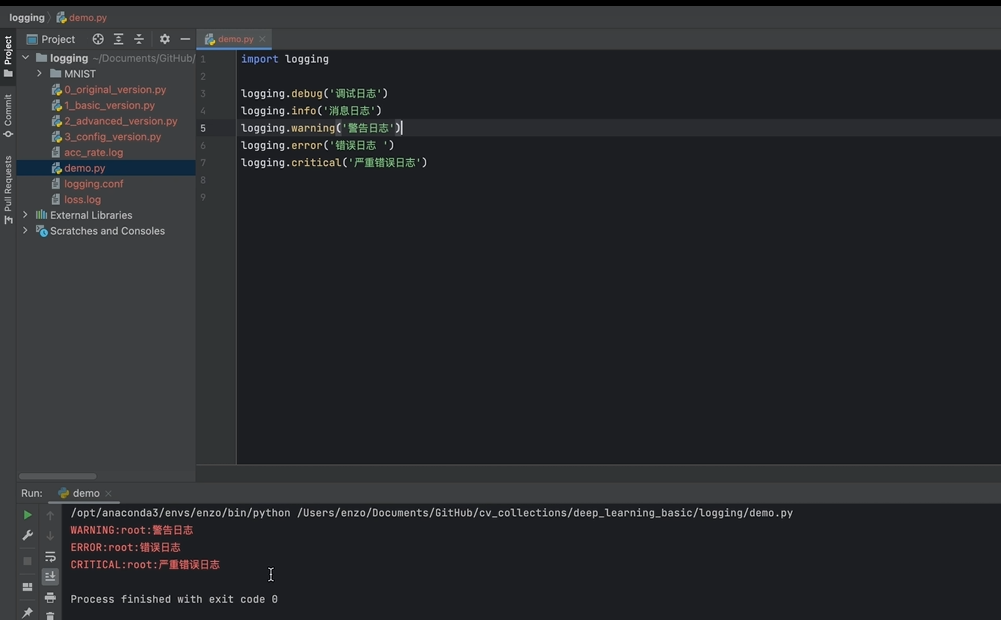
调整日志打印级别
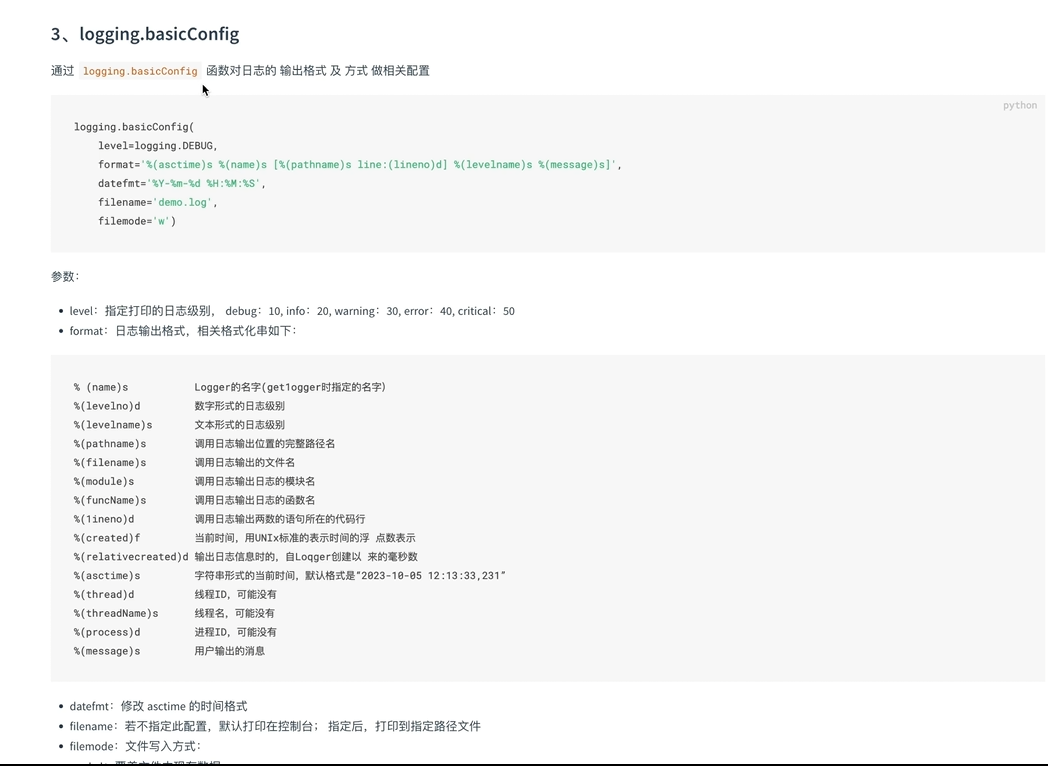
debug级别以上日志都可以打印;
可以通过调整日志输出级别,保证哪些日志可以输出;
还支持直接写入文件中;默认 追加方式;
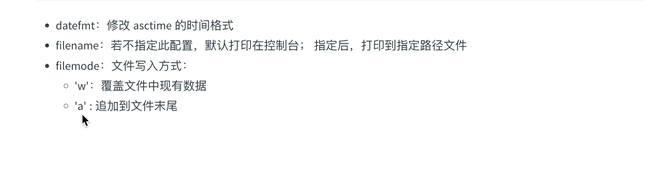
format设置格式;
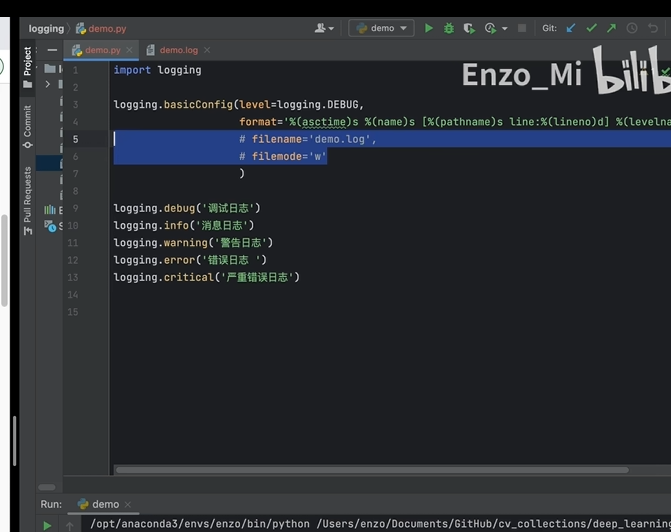
例子:
换成 logging
11.Tensorboard

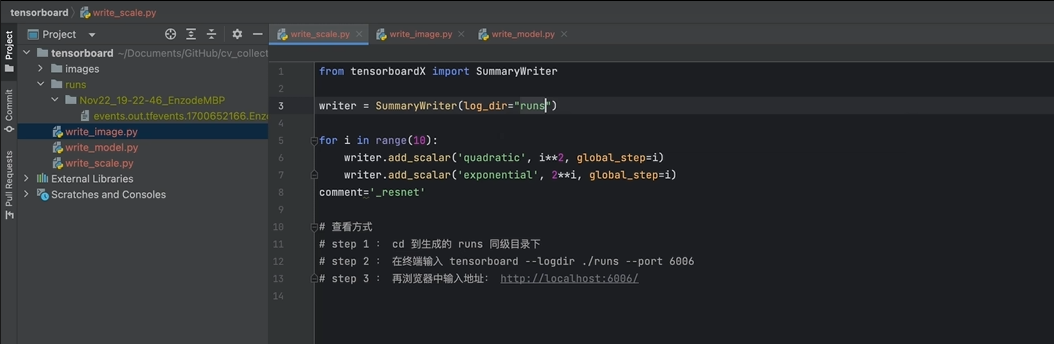
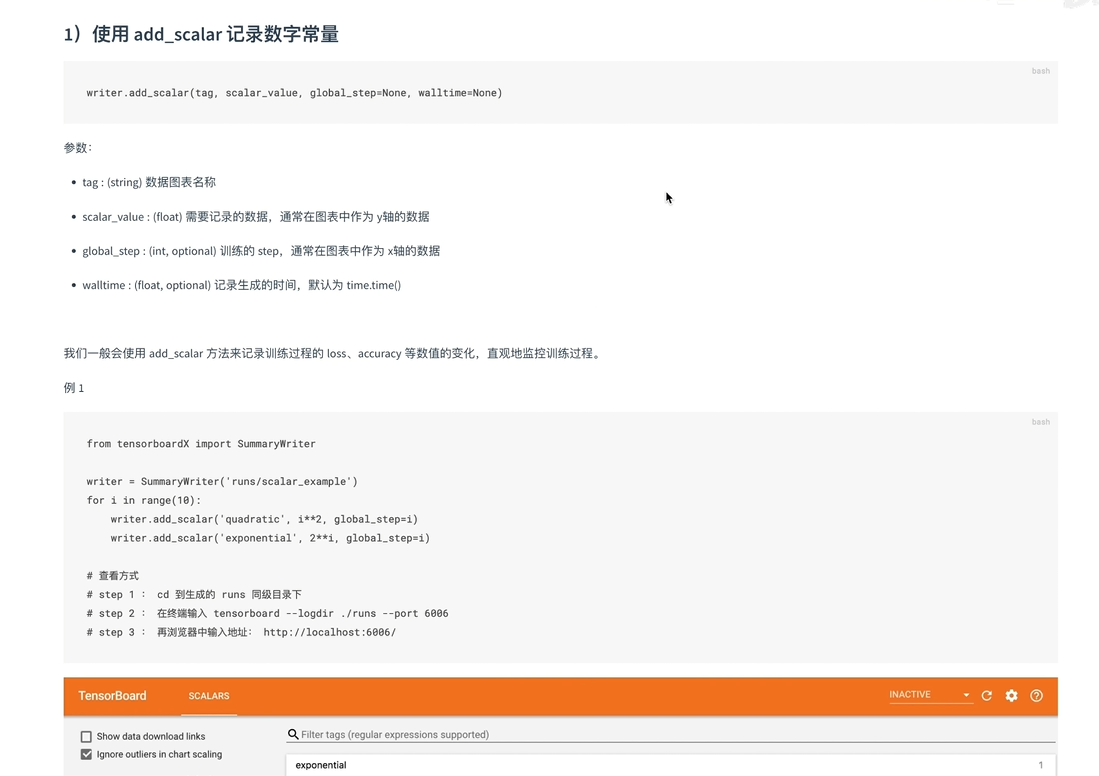
1记录训练数据指标
2查看模型结构
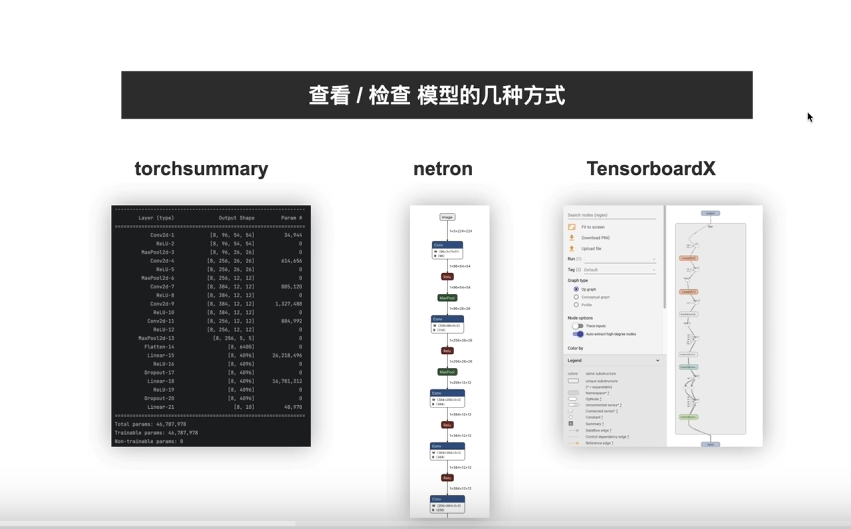
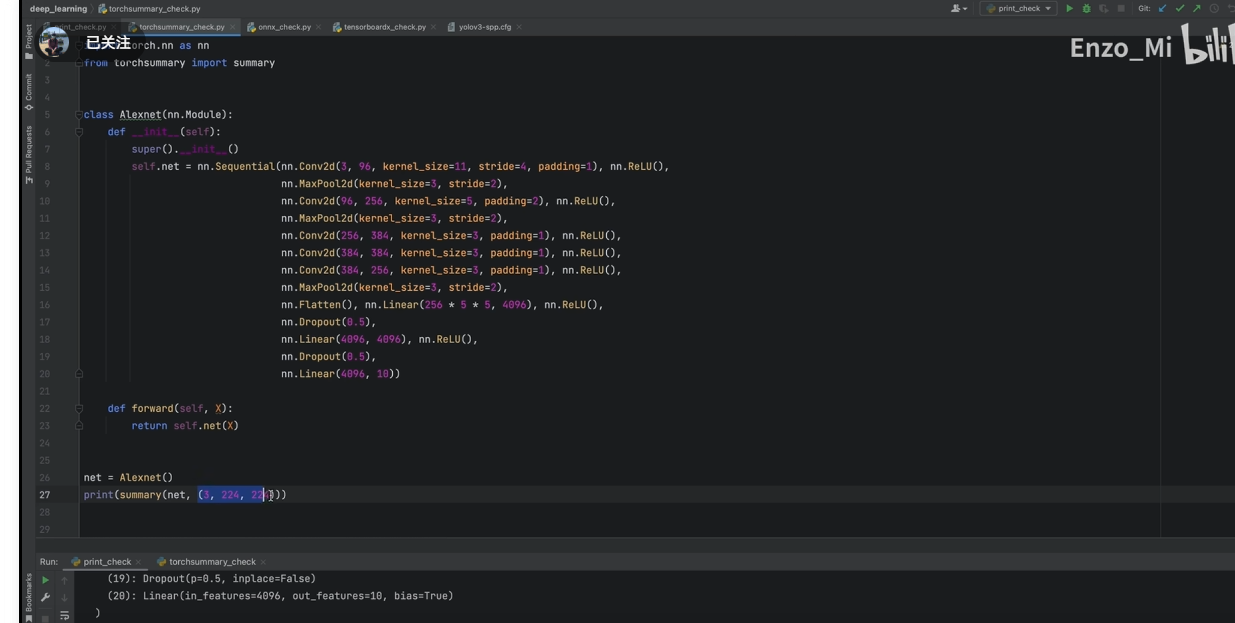
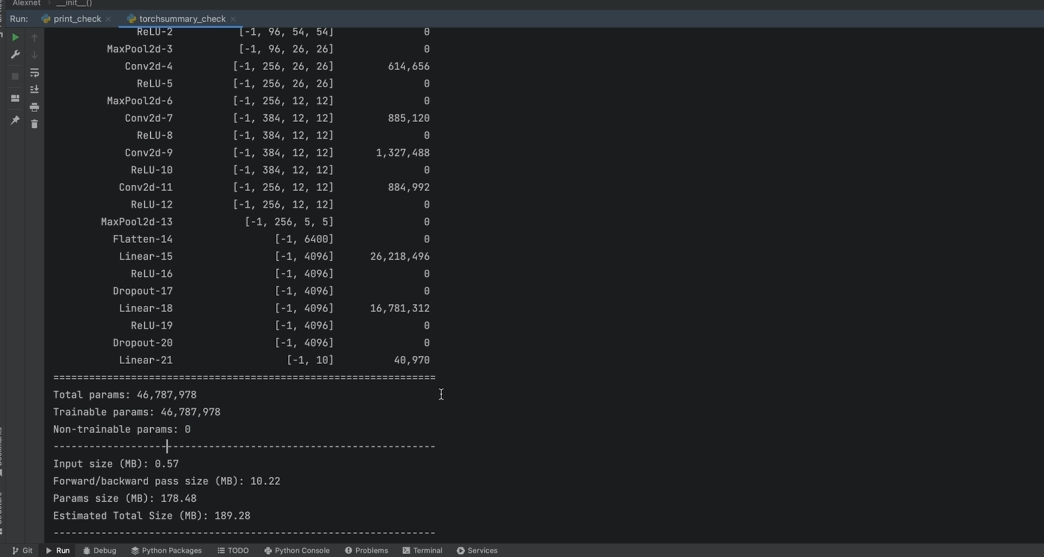
torchsummary(给尺寸直接输出 维度,可以检查模型搭建是否正确;
如果直接print(net)是无法检查网络结构是否准确;
3记录图像
12.插值方法
1最近邻插值法
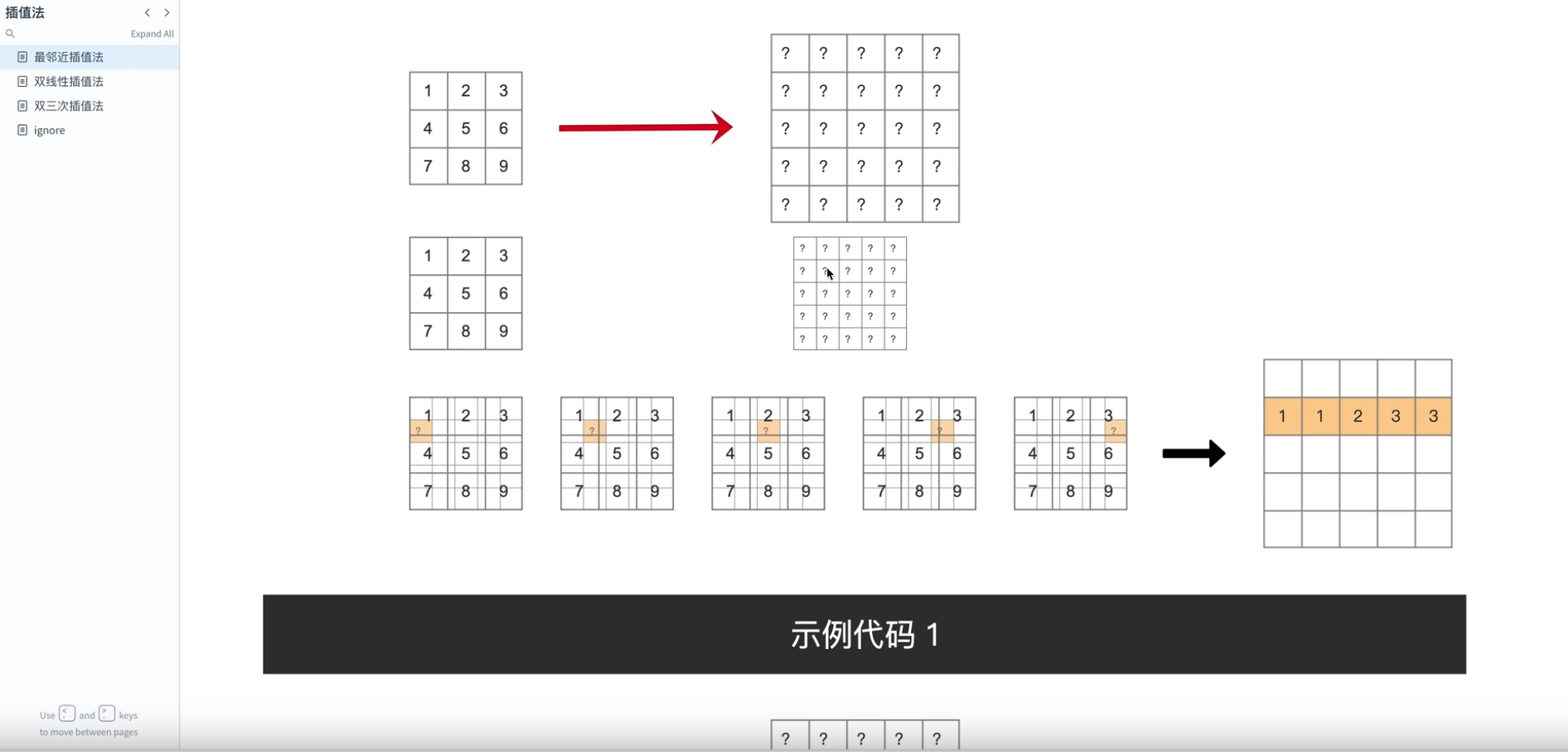
计算方法
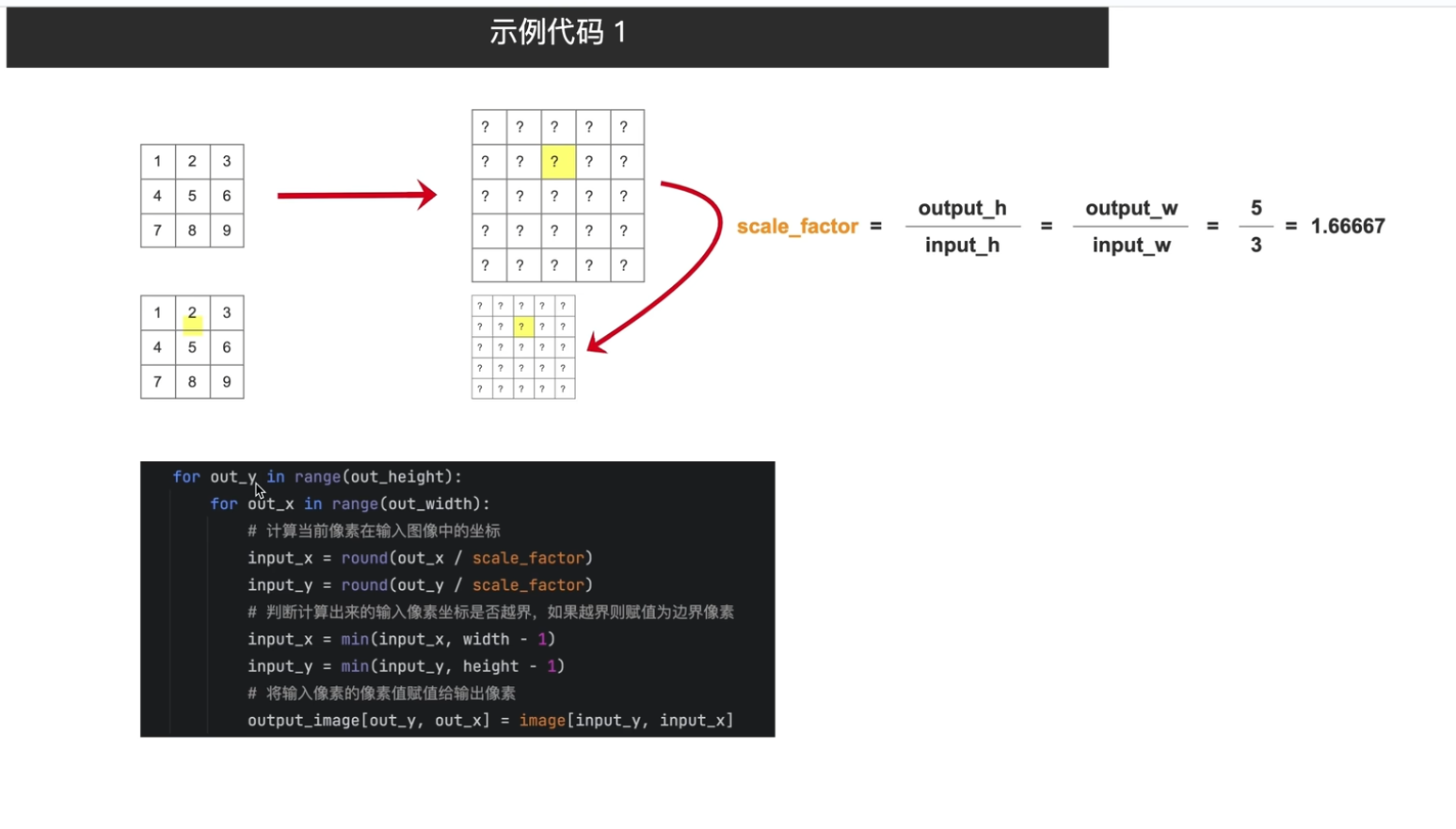
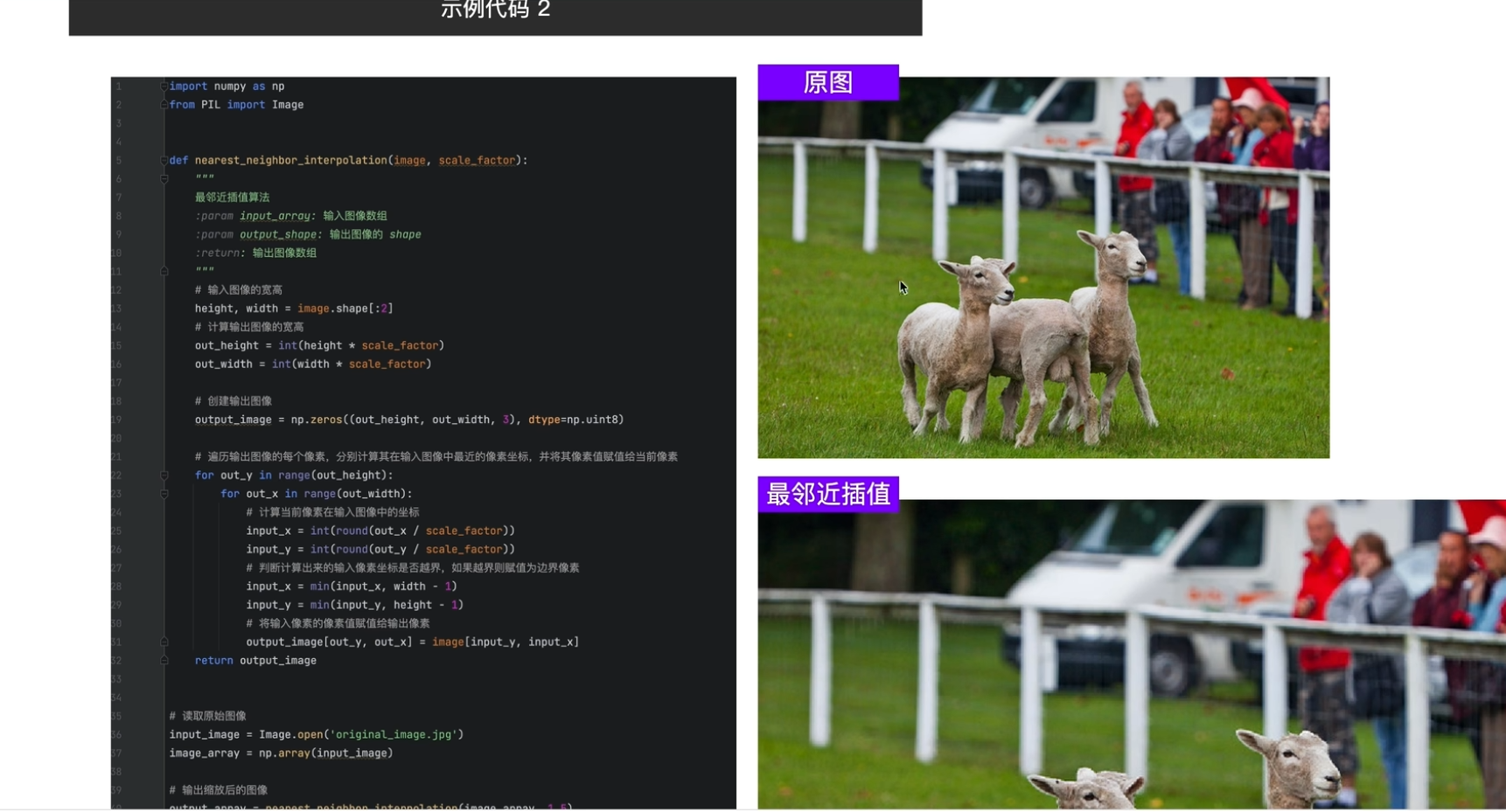
使用场景(标注的处理必须要最邻近插值
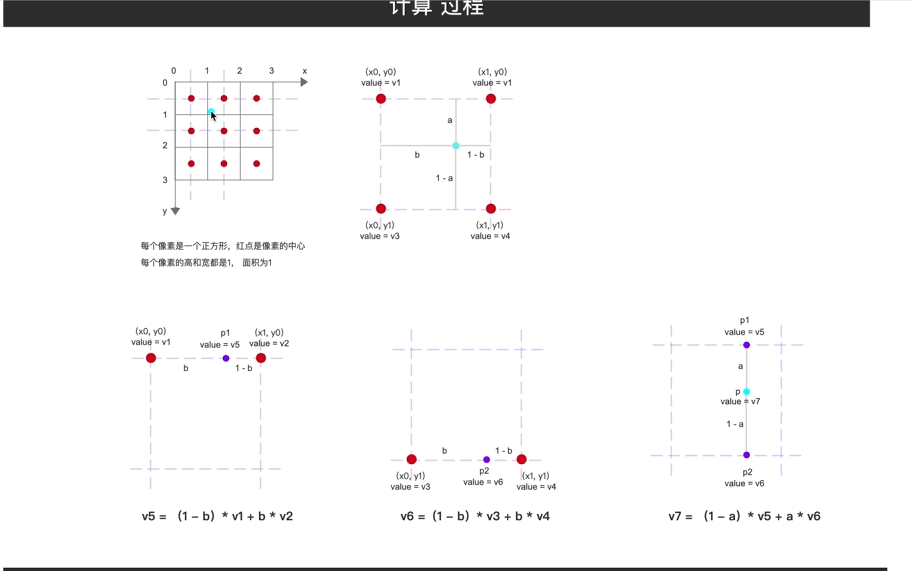
2双线性插值
角对齐和边对齐

在此对齐下,去双线性插值
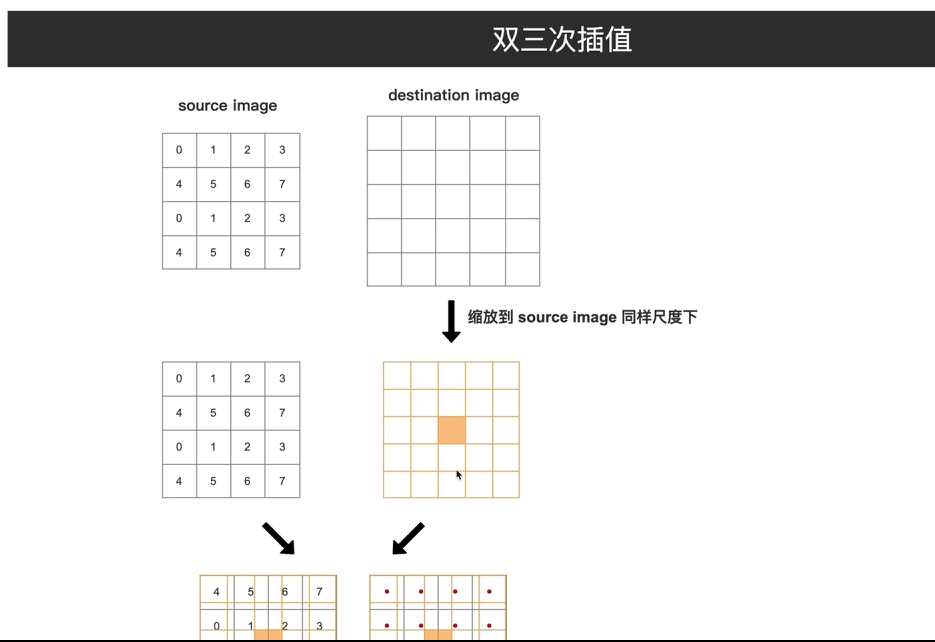
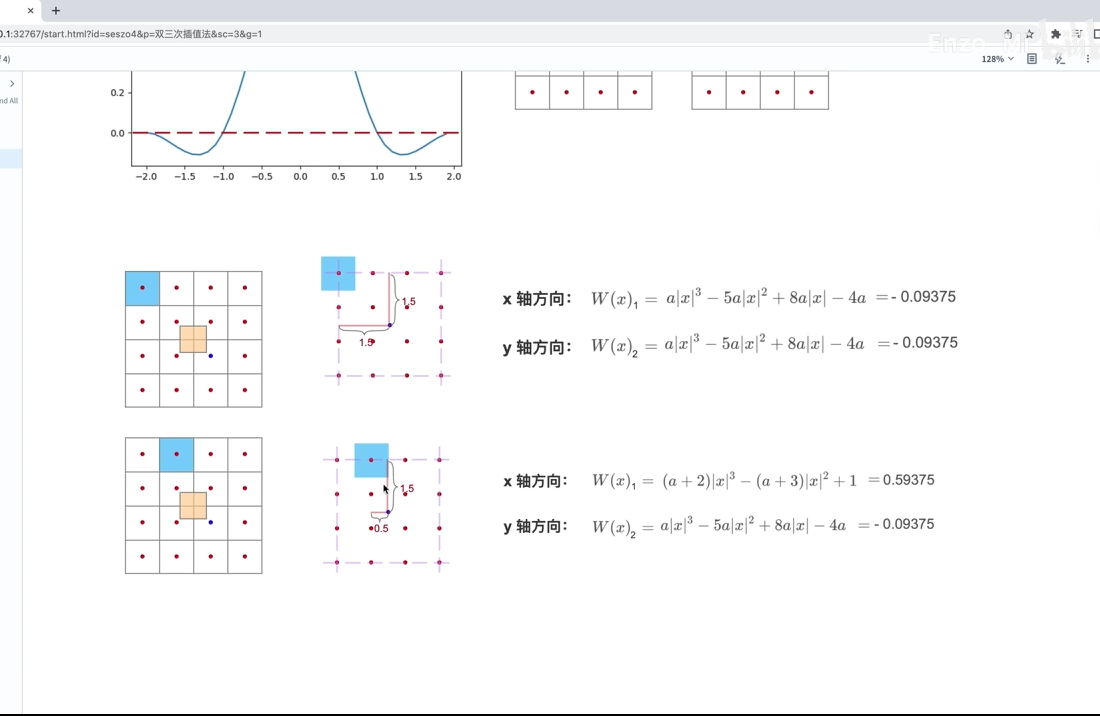
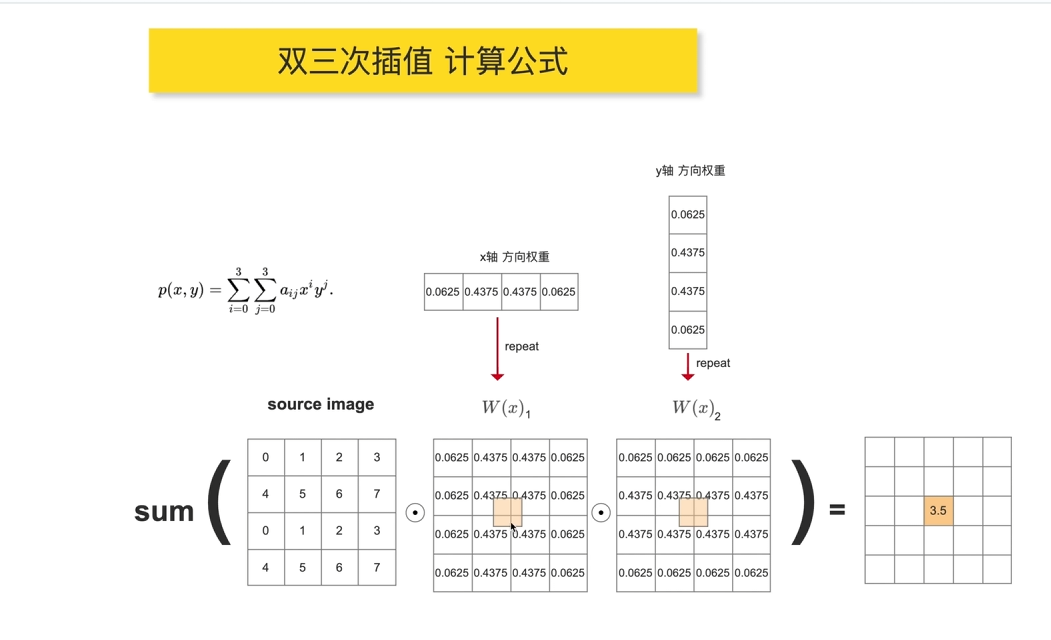
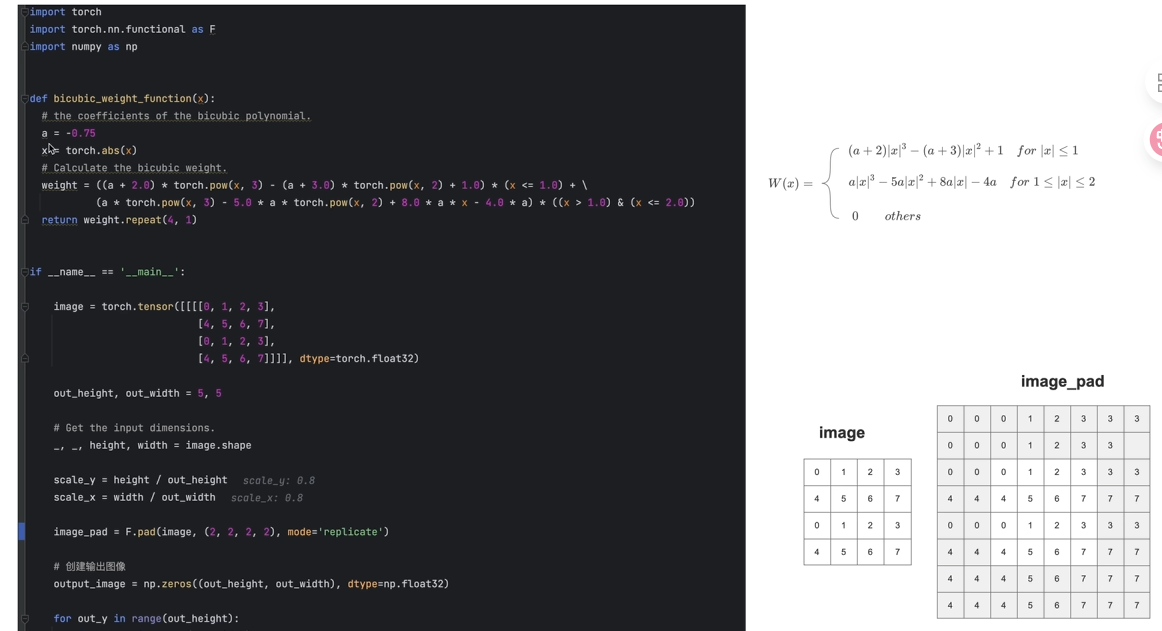
3双三次插值
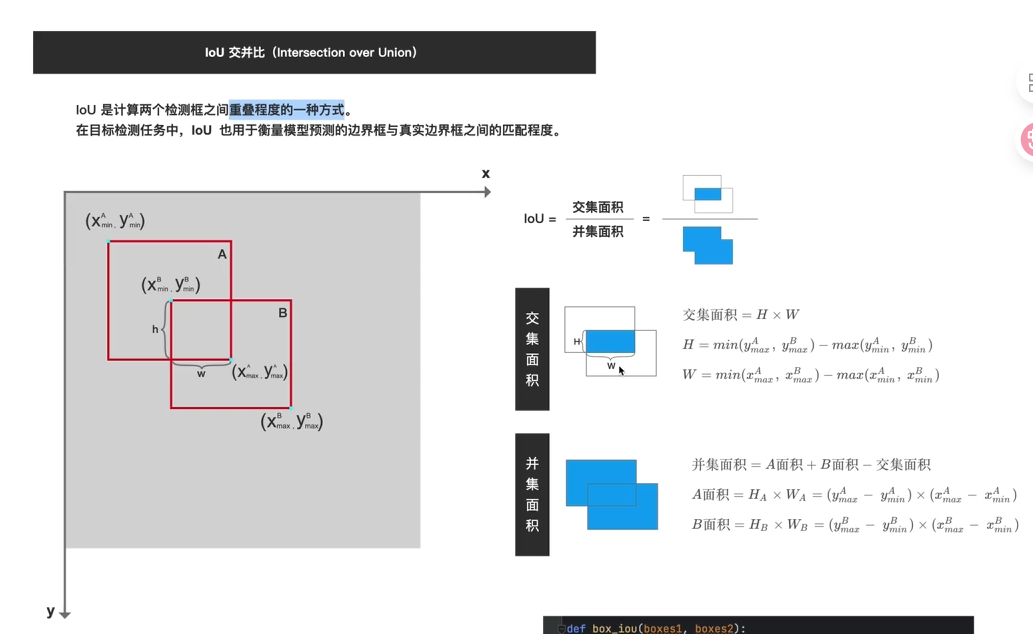
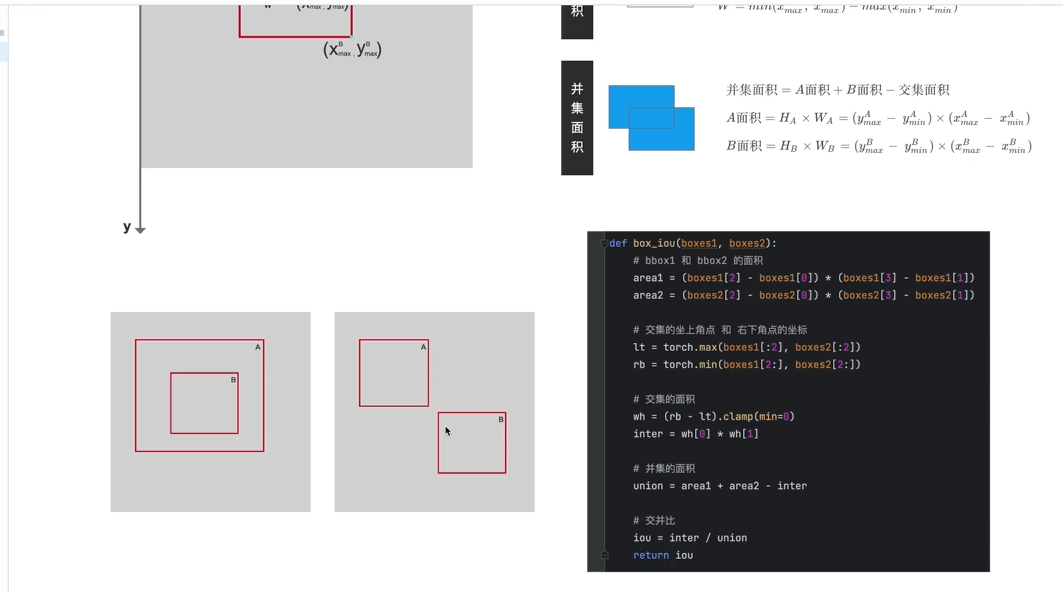
13.IoU
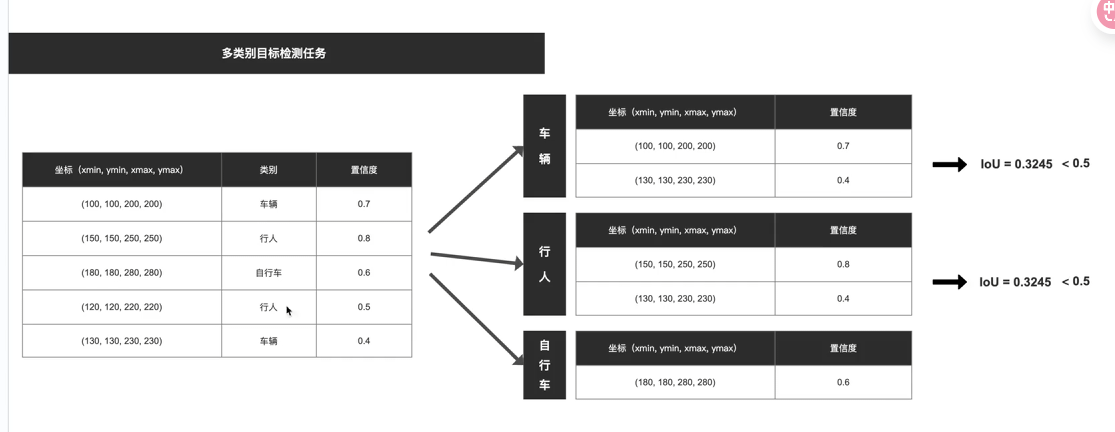
NMS
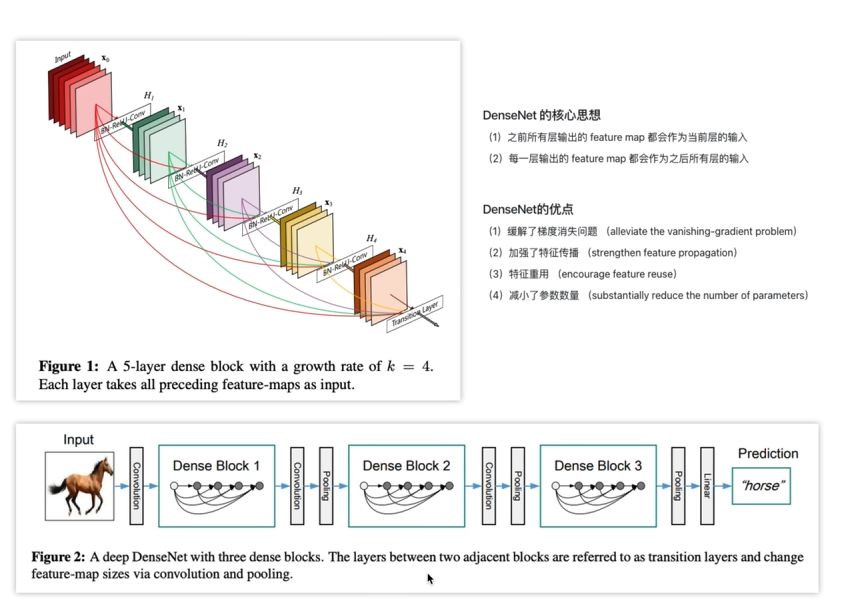
14.DenseNet
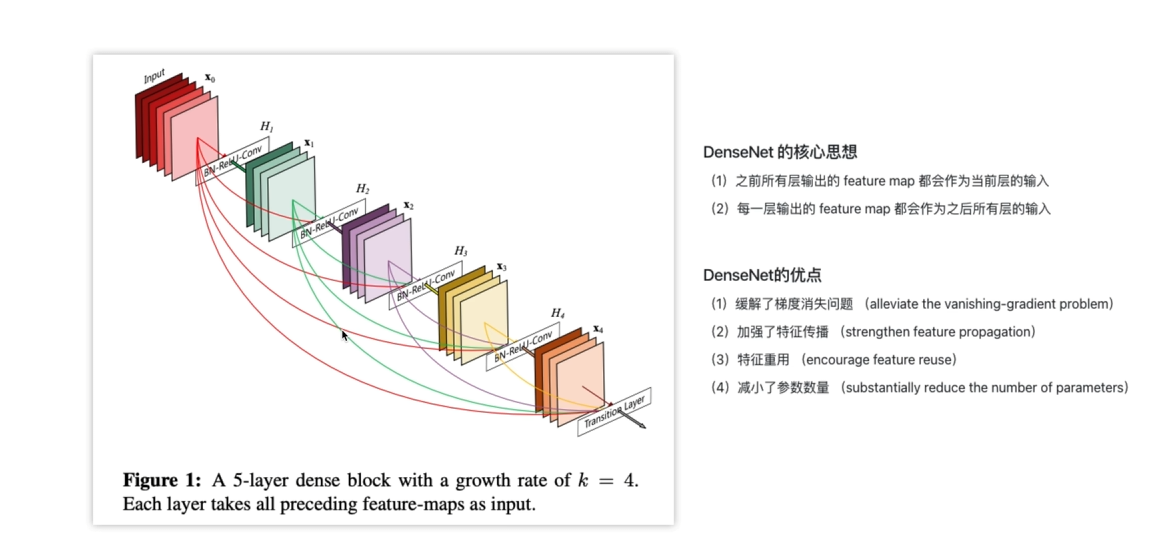
跨层链接concat;
减少参数量,如果H3输入通道是128,利用了concat那么H2输出可以是32,其余96可以由前面的层给出,这样就大大减少了参数量;
15.算力资源
免费 GPU / TPU | kaggle 项目部署_哔哩哔哩_bilibili
自己总结:Kaggle,colab,AutoDL(买)
Kaggle

1打包(已经调试完成的
2kaggle->datasets ->create
使用自己数据集的话也需要一并上传
code代码区创建项目->add Data添加项目文件
粘贴train.py
添加路径,以及将包路径改成当前路径;
-> 路径地址都需要改成kaggle路径->运行项目
GPU 前台先试运行
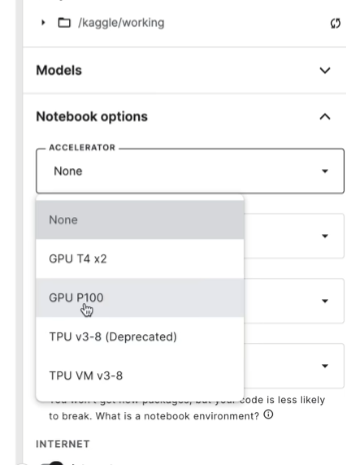
前台会掉线
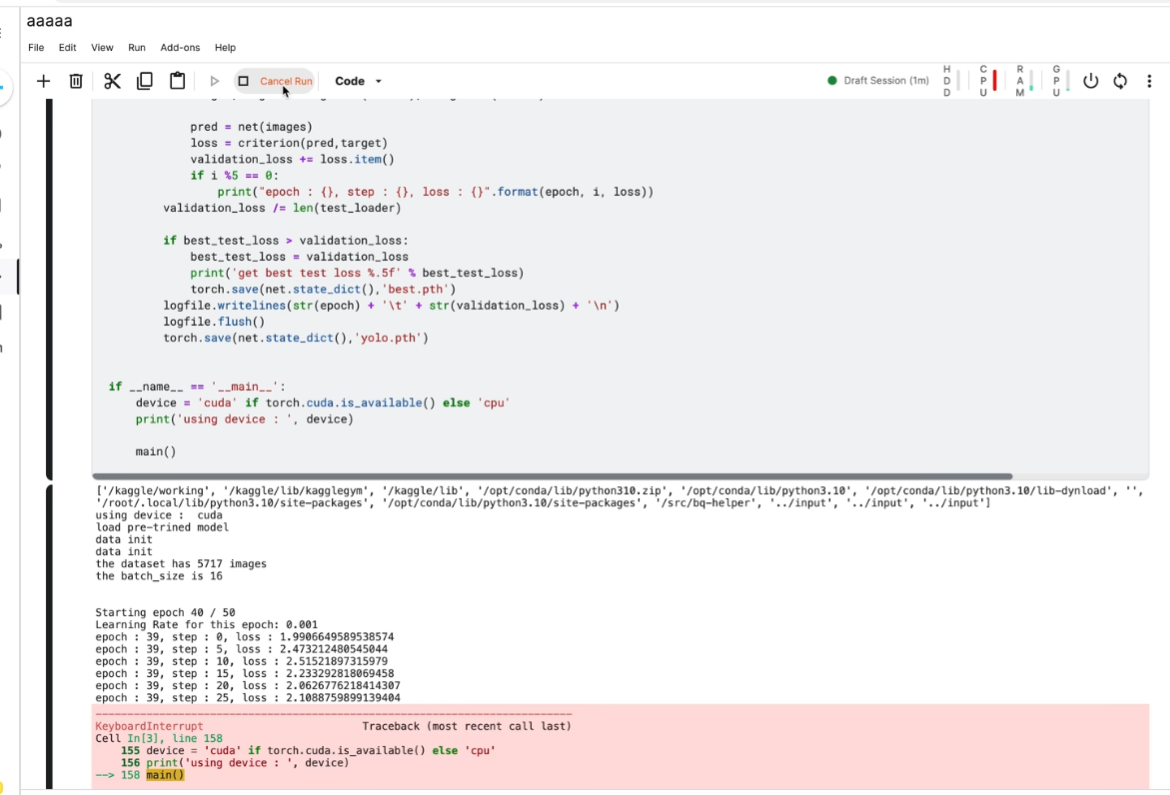
后台

后台运行
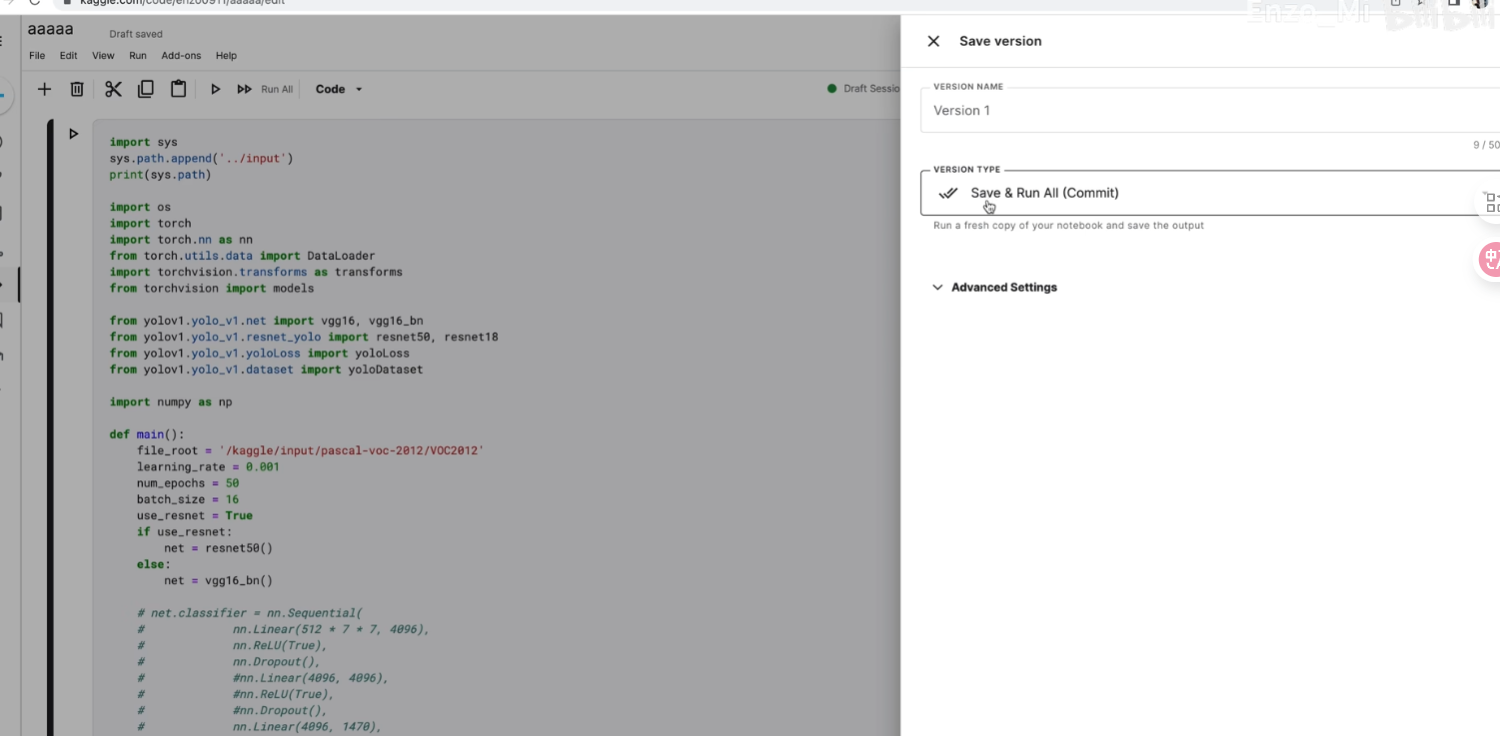
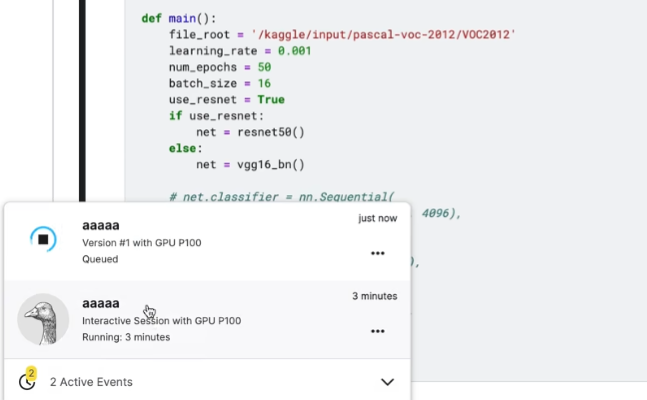
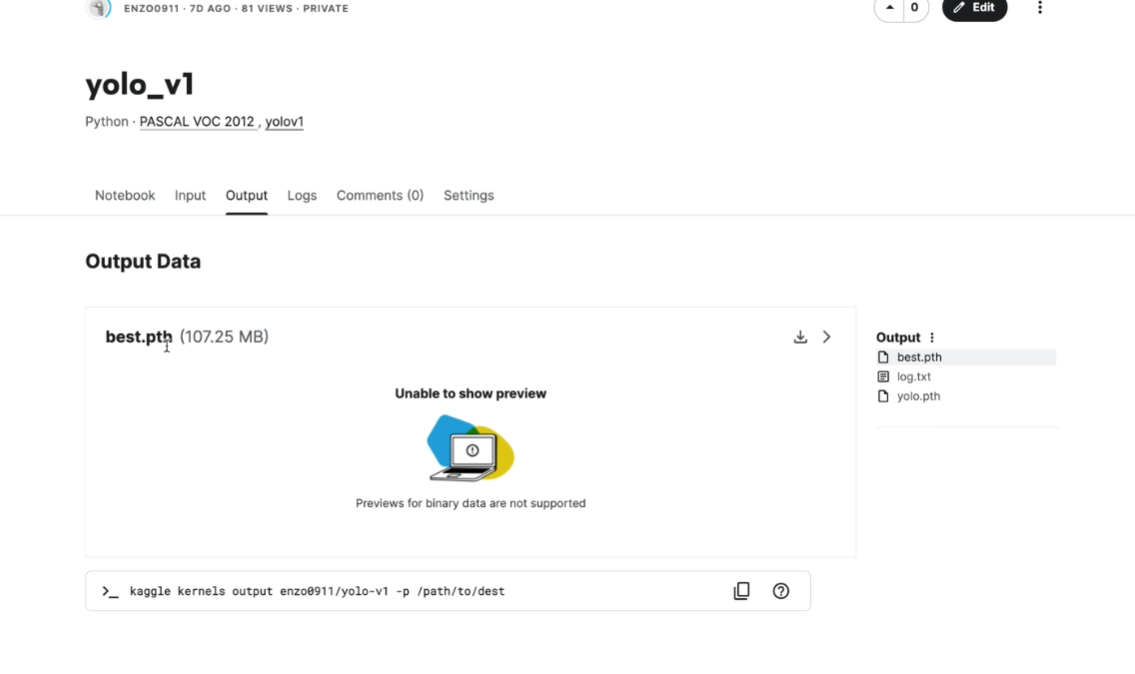
结果:
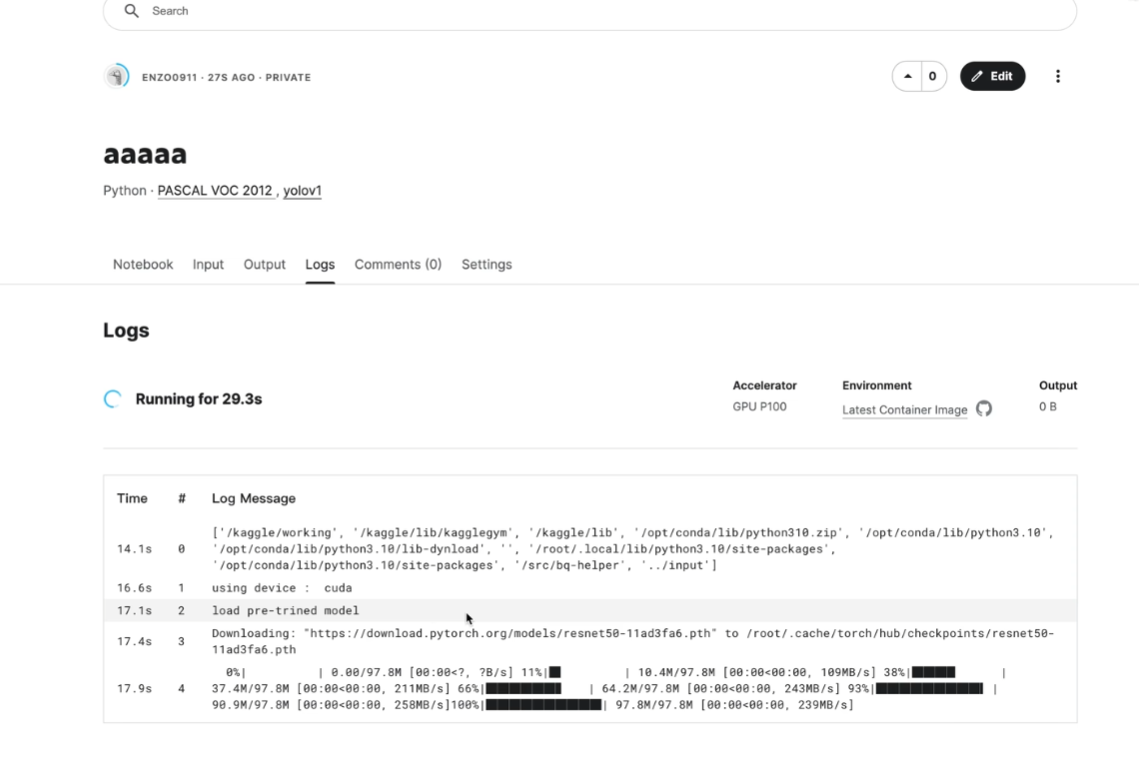
下载保存的文件