YOLOv11 到 C++ 落地全流程:ONNX 导出、NMS 判别与推理实战
YOLOv11 到 C++ 落地全流程:ONNX 导出、NMS 判别与推理实战
目标读者:已经使用 Ultralytics 训练好 YOLOv11 的开发者,需要将模型高效落地到 C++ 推理环境。
你将收获:
- 为什么会“满屏框”;
- 一行参数导出带 NMS的 ONNX;
- 如何在 Python/C++ 判断模型是否带 NMS;
- 输出每列的物理含义;
- vcpkg 没有 ORT 的 Config.cmake 时,如何写 CMake 兜底并跑通。
目录
- 1. 现象与本质
- 2. NMS 是什么?为什么一定要做?
- 2.1 NMS 是怎么做的(硬 NMS 伪代码)
- 2.2 一个极小数值例子
- 3. 最佳做法:导出“带 NMS”的 ONNX
- 4. 我怎么判断我的 ONNX 是否“带 NMS”?
- 4.1 Python 自检
- 4.2 C++ 自检
- 5. 输出张量的物理含义
- 6. 最小 C++ 示例(带 NMS 的 ONNX)
- 7. 如果手上只有“原始头”ONNX(84/85)怎么办?
- 8. vcpkg 无 ORT Config.cmake:CMake 兜底
- 9. 常见坑位与速查
- 10. Checklist
- 附录:NMS 变体与阈值选择
1. 现象与本质
现象:C++ 推理出现“满屏框”或“0 框”。
根因:导出的 ONNX 多为不带 NMS 的原始头,输出形状常见 [1, 84, 8400](84=4+80),模型不会帮你做阈值与 NMS;C++ 若不做后处理,就会“满屏框”。

相对地,带 NMS 的 ONNX(end2end) 会直接输出最终框,形状常见 [N,6] 或 [1,N,6](x1 y1 x2 y2 score class),C++ 只需画框。
2. NMS 是什么?为什么一定要做?
YOLO 在多尺度(如 80×80、40×40、20×20)上为每个网格点预测很多候选框。同一目标附近会出现大量位置相近、得分也不低的候选。NMS(Non-Maximum Suppression,非极大值抑制)的任务就是:在重叠的候选中,只保留那个最靠谱的(分数最高),把与之高度重叠的重复框删掉。
2.1 NMS 是怎么做的(硬 NMS 伪代码)
-
IoU(交并比):
IoU(A,B)=Area(A∩B)Area(A∪B)∈[0,1]IoU(A,B)=\frac{\text{Area}(A\cap B)}{\text{Area}(A\cup B)}\in[0,1] IoU(A,B)=Area(A∪B)Area(A∩B)∈[0,1]
-
硬 NMS 两步:
- 按置信度降序排序;
- 依次取最高分框,删除与它 IoU 大于阈值(如 0.45)的后续框。
# boxes: [N, 4] in x1y1x2y2
# scores: [N]
# thr_conf: 置信度阈值(如 0.25)
# thr_iou: NMS IoU 阈值(如 0.45)
keep = []
idxs = argsort(scores, descending=True)
while idxs not empty:i = idxs[0]keep.append(i)ious = IoU(boxes[i], boxes[idxs[1:]])idxs = idxs[1:][ious <= thr_iou]
return keep
常见做法是按类别分别做 NMS(class-wise NMS)。Ultralytics 默认如此。
2.2 一个极小数值例子
| idx | score | box(x1,y1,x2,y2) |
|---|---|---|
| 0 | 0.90 | (10,10,50,50) |
| 1 | 0.85 | (12,12,49,49) |
| 2 | 0.60 | (200,200,260,260) |
| 3 | 0.40 | (205,205,258,258) |
- 0 与 1 重叠很高 → 留 0,抑制 1
- 2 与 3 接近 → 留 2,抑制 3
最终仅保留 idx=0、idx=2 两个框
3. 最佳做法:导出“带 NMS”的 ONNX
必须从
.pt权重导出;不能在现有.onnx上“打开 NMS”。
from ultralytics import YOLOm = YOLO(r"path/to/best.pt") # 训练得到的 .pt 或 yolov8n.pt
m.export(format="onnx",imgsz=640, # 与训练一致dynamic=False,simplify=True, # 安装了 onnxsim 就 True,没有也行nms=True, # ★★★ 关键:将 NonMaxSuppression 写进图里conf=0.25, # 内置置信阈iou=0.45, # 内置 NMS IoUopset=12 # 12/13/16 均可,保持一致即可
)
导出成功后,继续下一节检查是否真的带 NMS。
4. 如何判断是否“带 NMS”
4.1 Python(最快)
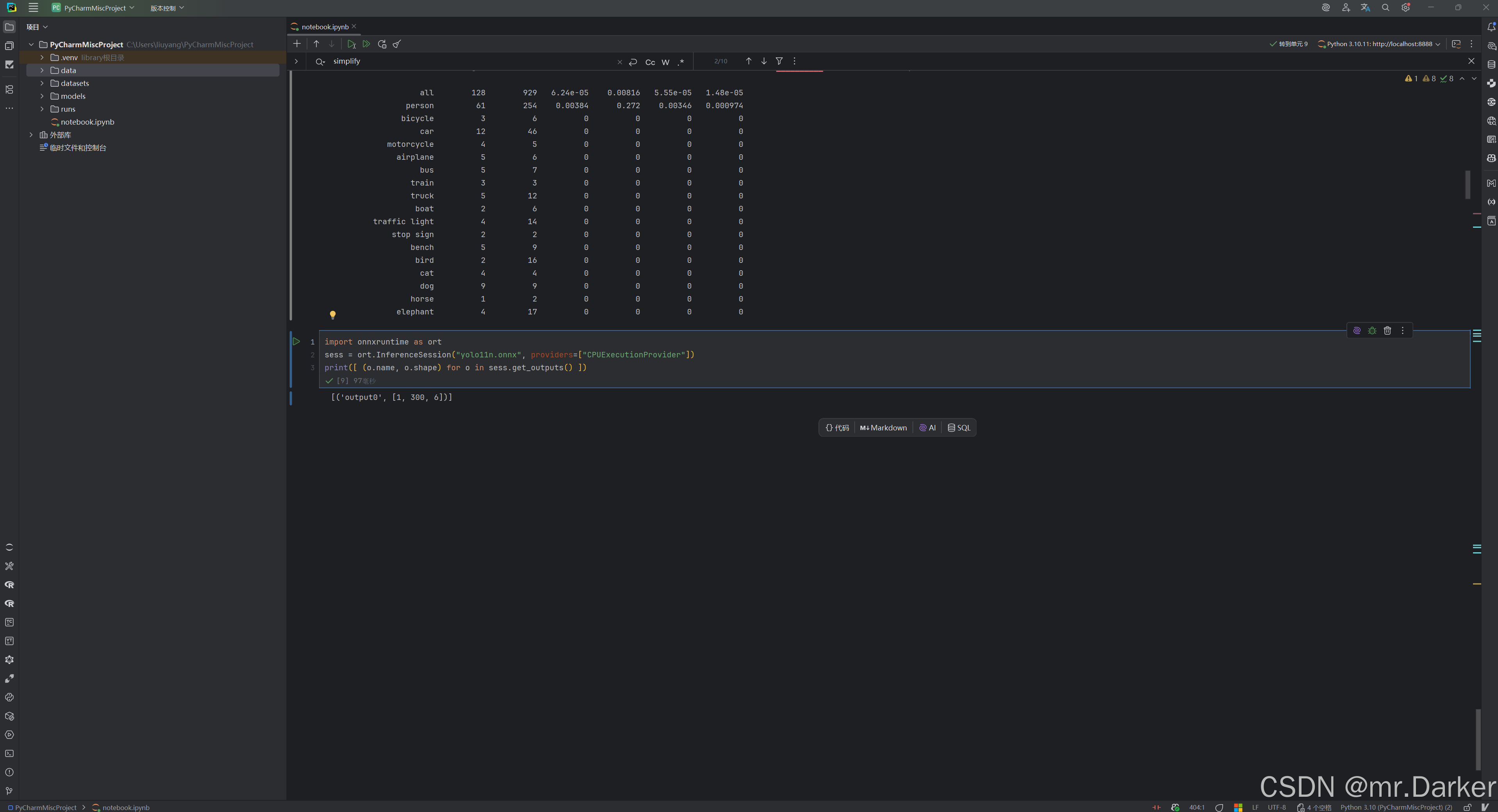
import onnxruntime as ort
sess = ort.InferenceSession("best.onnx", providers=["CPUExecutionProvider"])
print([ (o.name, o.shape) for o in sess.get_outputs() ])# 看到 [..., 6] / [..., 7] => 带 NMS
# 看到 84/85 出现在任一维 => 原始头(不带 NMS)
4.2 C++(不依赖 Python)
#include <onnxruntime_cxx_api.h>
#include <iostream>
#include <vector>
#include <filesystem>static std::string Shape2Str(const std::vector<int64_t>& v) { std::string s = "["; for (size_t i = 0; i < v.size(); ++i) { s += std::to_string(v[i]); if (i + 1 < v.size()) s += ','; } return s += ']'; }
static bool LikeNMS(const std::vector<int64_t>& shp) { return shp.size() >= 2 && (shp.back() == 6 || shp.back() == 7); }
static bool LikeRaw(const std::vector<int64_t>& shp) { for (auto d : shp) if (d == 84 || d == 85) return true; return false; }static void InspectOutputs(const Ort::Session& sess) {const size_t n = sess.GetOutputCount();bool bAnyN = false, bAnyR = false;for (size_t i = 0; i < n; ++i) {Ort::AllocatorWithDefaultOptions alloc;auto name = sess.GetOutputNameAllocated(i, alloc);auto shp = sess.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();std::cout << "out[" << i << "] " << (name ? name.get() : "(null)") << " shape=" << Shape2Str(shp) << "\n";bAnyN |= LikeNMS(shp);bAnyR |= LikeRaw(shp);}if (bAnyN) std::cout << "[detect] ✅ 带 NMS 的 end2end 输出\n";else if (bAnyR) std::cout << "[detect] ⚠️ 原始头(不带 NMS)\n";else std::cout << "[detect] ℹ️ 非常见形状,建议用 Netron 检查是否含 NonMaxSuppression\n";
}int main(int argc, char** argv) {if (argc < 2) {std::cout << "Usage:\n " << argv[0] << " <onnx_model>\n";return 0;}std::filesystem::path strOnnxPath = argv[1];if (!std::filesystem::exists(strOnnxPath)) {std::cerr << "[error] model not found: " << strOnnxPath << "\n";return -1;}try {// 1) Env + SessionOptionsOrt::Env env(ORT_LOGGING_LEVEL_WARNING, "onnx_inspect");Ort::SessionOptions opt;opt.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);std::unique_ptr<Ort::Session> sess;try {// 2) 优先尝试 GPUOrtCUDAProviderOptions stCudaOpts{};stCudaOpts.device_id = 0;opt.AppendExecutionProvider_CUDA(stCudaOpts);sess = std::make_unique<Ort::Session>(env, strOnnxPath.c_str(), opt);std::cout << "[info] provider = CUDA\n";} catch (...) {// 3) 回退到 CPUOrt::SessionOptions stOptCpu;stOptCpu.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);sess = std::make_unique<Ort::Session>(env, strOnnxPath.c_str(), stOptCpu);std::cout << "[info] provider = CPU\n";}// 4) 调用 InspectOutputsInspectOutputs(*sess);}catch (const std::exception& e) {std::cerr << "[exception] " << e.what() << "\n";return -1;}return 0;
}

5. 输出张量的物理含义
A. 带 NMS 的 ONNX(end2end)
-
常见行:
x1 y1 x2 y2 score class(, batch/id) -
坐标单位:以模型输入尺寸为基准(如 640×640)。
- 你若前处理用
resize,回写到原图:sx=origW/W, sy=origH/H,四个坐标分别乘以sx/sy即可。 - 若是 letterbox,需去 pad/scale 才能回到原图坐标。
- 你若前处理用
B. 原始头(不带 NMS)
-
形状常见:
[1, 84, 8400](或[1, 8400, 84]) -
每候选有 84 个数:前 4 为 bbox,后 80 为各类概率(通常已 sigmoid)。
-
Ultralytics 的导出中,bbox 多为中心点格式:
cx, cy, w, h(像素单位,基于输入尺寸)。 -
后处理:
class = argmax(prob[80]);score = max(prob)- 过滤
score < conf - 还原角点框:
x1=cx-w/2, y1=cy-h/2, x2=cx+w/2, y2=cy+h/2 - 按类别做 NMS(IoU≈0.45),可加 topK
- 画框/保存
想简单稳定:强烈建议导出 带 NMS 的 ONNX;否则 C++ 侧实现 NMS 会增加工程复杂度。
6. 最小 C++ 示例:带 NMS 的 ONNX
依赖:OpenCV + ONNX Runtime(CPU 或 GPU)
说明:为了极简,预处理用resize非 letterbox;先跑通,再按需替换为 letterbox。
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
#include <filesystem>
#include <iostream>
#include <algorithm>
#include <numeric>namespace fs = std::filesystem;static cv::String PathToCv(const fs::path& pPath) {
#ifdef _WIN32std::u8string u8 = pPath.u8string();return cv::String(reinterpret_cast<const char*>(u8.c_str()));
#elsereturn cv::String(pPath.string());
#endif
}struct stBox {float dX1, dY1, dX2, dY2, dScore;int nCls;
};static float IoU(const stBox& stA, const stBox& stB) {float dXX1 = std::max(stA.dX1, stB.dX1);float dYY1 = std::max(stA.dY1, stB.dY1);float dXX2 = std::min(stA.dX2, stB.dX2);float dYY2 = std::min(stA.dY2, stB.dY2);float dW = std::max(0.0f, dXX2 - dXX1);float dH = std::max(0.0f, dYY2 - dYY1);float dInter = dW * dH;float dAreaA = (stA.dX2 - stA.dX1) * (stA.dY2 - stA.dY1);float dAreaB = (stB.dX2 - stB.dX1) * (stB.dY2 - stB.dY1);float dUnion = dAreaA + dAreaB - dInter + 1e-6f;return dInter / dUnion;
}// Letterbox 等比缩放
static cv::Mat Letterbox(const cv::Mat& matImg, int nDstW, int nDstH,float& dScale, int& nPadW, int& nPadH) {int nW = matImg.cols, nH = matImg.rows;float dR = std::min(1.0f * nDstW / nW, 1.0f * nDstH / nH);int nNewW = int(std::round(nW * dR));int nNewH = int(std::round(nH * dR));dScale = dR;nPadW = nDstW - nNewW;nPadH = nDstH - nNewH;cv::Mat matResized;cv::resize(matImg, matResized, { nNewW, nNewH });cv::Mat matOut(nDstH, nDstW, matImg.type(), cv::Scalar(114, 114, 114));int nTop = nPadH / 2, nLeft = nPadW / 2;matResized.copyTo(matOut(cv::Rect(nLeft, nTop, nNewW, nNewH)));return matOut;
}static bool IsImageFile(const fs::path& pPath) {std::string strExt = pPath.extension().string();std::transform(strExt.begin(), strExt.end(), strExt.begin(), ::tolower);return strExt == ".jpg" || strExt == ".jpeg" || strExt == ".png" || strExt == ".bmp" || strExt == ".webp";
}int main(int argc, char** argv) {if (argc < 4) {std::cout << "Usage:\n " << argv[0] << " <best.onnx> <image_dir> <output_dir>\n";return 0;}fs::path strOnnxPath = argv[1];fs::path strImgDir = argv[2];fs::path strOutDir = argv[3];std::error_code ec;if (!fs::exists(strOutDir, ec)) {fs::create_directories(strOutDir, ec);}const float CONF_THRES = 0.25f;const float NMS_THRES = 0.50f;const int NMS_TOPK = 300;try {// ---------- 1) Session & Provider ----------Ort::Env hEnv(ORT_LOGGING_LEVEL_WARNING, "yolo_demo");Ort::SessionOptions stOpt;stOpt.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);stOpt.SetIntraOpNumThreads(std::max(1u, std::thread::hardware_concurrency()));stOpt.SetInterOpNumThreads(1);std::unique_ptr<Ort::Session> pSess;bool bGPU = false;try {OrtCUDAProviderOptions stCuda{};stCuda.device_id = 0;stOpt.AppendExecutionProvider_CUDA(stCuda);pSess = std::make_unique<Ort::Session>(hEnv, strOnnxPath.c_str(), stOpt);bGPU = true;std::cout << "[info] provider = CUDA\n";}catch (...) {Ort::SessionOptions stOptCpu;stOptCpu.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);stOptCpu.SetIntraOpNumThreads(std::max(1u, std::thread::hardware_concurrency()));stOptCpu.SetInterOpNumThreads(1);pSess = std::make_unique<Ort::Session>(hEnv, strOnnxPath.c_str(), stOptCpu);std::cout << "[info] provider = CPU\n";}// ---------- 2) 输入大小 & I/O 名称 ----------Ort::AllocatorWithDefaultOptions stAlloc;auto stInInfo = pSess->GetInputTypeInfo(0).GetTensorTypeAndShapeInfo();auto vInShapeTmp = stInInfo.GetShape(); // 可能含 -1int nInH = 0, nInW = 0;if (vInShapeTmp.size() == 4) {nInH = (int)vInShapeTmp[2];nInW = (int)vInShapeTmp[3];}if (nInH <= 0 || nInW <= 0) { nInH = 640; nInW = 640; } // 兜底std::vector<Ort::AllocatedStringPtr> vInNameHolders, vOutNameHolders;std::vector<const char*> vInNames, vOutNames;vInNameHolders.reserve(pSess->GetInputCount());vOutNameHolders.reserve(pSess->GetOutputCount());for (size_t i = 0; i < pSess->GetInputCount(); ++i) {vInNameHolders.emplace_back(pSess->GetInputNameAllocated(i, stAlloc));vInNames.push_back(vInNameHolders.back().get());}for (size_t i = 0; i < pSess->GetOutputCount(); ++i) {vOutNameHolders.emplace_back(pSess->GetOutputNameAllocated(i, stAlloc));vOutNames.push_back(vOutNameHolders.back().get());}// 预分配输入缓冲(循环复用)std::vector<float> vInput(3 * nInH * nInW);// ---------- 3) 预热 ----------{cv::Mat matDummy(nInH, nInW, CV_8UC3, cv::Scalar(114, 114, 114));cv::cvtColor(matDummy, matDummy, cv::COLOR_BGR2RGB);matDummy.convertTo(matDummy, CV_32F, 1.0 / 255.0);std::vector<cv::Mat> vCh(3);for (int nC = 0; nC < 3; ++nC) vCh[nC] = cv::Mat(nInH, nInW, CV_32F, vInput.data() + nC * nInH * nInW);cv::split(matDummy, vCh);std::vector<int64_t> vInShape = { 1,3,nInH,nInW };Ort::MemoryInfo stMem = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeDefault);Ort::Value stInTensor = Ort::Value::CreateTensor<float>(stMem, vInput.data(), vInput.size(), vInShape.data(), vInShape.size());pSess->Run(Ort::RunOptions{ nullptr }, vInNames.data(), &stInTensor, 1, vOutNames.data(), vOutNames.size());}// ---------- 4) 遍历图片 ----------if (!fs::exists(strImgDir, ec) || !fs::is_directory(strImgDir, ec)) {std::cerr << "[error] image_dir invalid: " << strImgDir << "\n";return -1;}for (auto it = fs::directory_iterator(strImgDir, ec); !ec && it != fs::end(it); it.increment(ec)) {if (ec) break;const auto& entry = *it;if (!entry.is_regular_file(ec)) continue;const fs::path pPath = entry.path();if (!IsImageFile(pPath)) continue;cv::Mat matImg = cv::imread(PathToCv(pPath));if (matImg.empty()) continue;// ---- 预处理 ----float dScale = 1.0f; int nPadW = 0, nPadH = 0;cv::Mat matPadded = Letterbox(matImg, nInW, nInH, dScale, nPadW, nPadH);cv::cvtColor(matPadded, matPadded, cv::COLOR_BGR2RGB);matPadded.convertTo(matPadded, CV_32F, 1.0 / 255.0);std::vector<cv::Mat> vCh(3);for (int nC = 0; nC < 3; ++nC) vCh[nC] = cv::Mat(nInH, nInW, CV_32F, vInput.data() + nC * nInH * nInW);cv::split(matPadded, vCh);std::vector<int64_t> vInShape = { 1,3,nInH,nInW };Ort::MemoryInfo stMem = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeDefault);Ort::Value stInTensor = Ort::Value::CreateTensor<float>(stMem, vInput.data(), vInput.size(), vInShape.data(), (size_t)vInShape.size());auto vOuts = pSess->Run(Ort::RunOptions{ nullptr },vInNames.data(), &stInTensor, 1,vOutNames.data(), vOutNames.size());// ---- 输出解析 ----if (vOuts.empty()) { std::cout << pPath.filename().string() << " no outputs\n"; continue; }auto& out0 = vOuts[0];auto stOutInfo = out0.GetTensorTypeAndShapeInfo();auto vShp = stOutInfo.GetShape();if (vShp.size() != 3 || vShp[2] < 6) {std::cout << "[warn] unexpected output shape for " << pPath << "\n";continue;}int nN = (int)vShp[1];const float* pdOut = out0.GetTensorData<float>();// ---- 置信度筛选 ----std::vector<stBox> vBoxes; vBoxes.reserve(nN);int nLeft = nPadW / 2, nTop = nPadH / 2;float dInv = 1.0f / dScale;for (int i = 0; i < nN; ++i) {const float* pdRow = pdOut + i * vShp[2];float dScore = pdRow[4];if (dScore < CONF_THRES) continue;float dX1 = (pdRow[0] - nLeft) * dInv;float dY1 = (pdRow[1] - nTop) * dInv;float dX2 = (pdRow[2] - nLeft) * dInv;float dY2 = (pdRow[3] - nTop) * dInv;dX1 = std::clamp(dX1, 0.0f, (float)matImg.cols - 1);dY1 = std::clamp(dY1, 0.0f, (float)matImg.rows - 1);dX2 = std::clamp(dX2, 0.0f, (float)matImg.cols - 1);dY2 = std::clamp(dY2, 0.0f, (float)matImg.rows - 1);stBox stB{ dX1,dY1,dX2,dY2,dScore,(int)pdRow[5] };if (stB.dX2 > stB.dX1 && stB.dY2 > stB.dY1) vBoxes.push_back(stB);}// ---- NMS ----std::sort(vBoxes.begin(), vBoxes.end(),[](const stBox& a, const stBox& b) { return a.dScore > b.dScore; });if ((int)vBoxes.size() > NMS_TOPK) vBoxes.resize(NMS_TOPK);std::vector<stBox> vKeep;std::vector<char> vRemoved(vBoxes.size(), 0);for (size_t i = 0; i < vBoxes.size(); ++i) {if (vRemoved[i]) continue;vKeep.push_back(vBoxes[i]);for (size_t j = i + 1; j < vBoxes.size(); ++j) {if (vRemoved[j]) continue;if (vBoxes[i].nCls != vBoxes[j].nCls) continue;if (IoU(vBoxes[i], vBoxes[j]) > NMS_THRES) vRemoved[j] = 1;}}std::cout << pPath.filename().string() << " dets=" << vKeep.size() << "\n";for (const auto& stB : vKeep) {std::cout << " box: " << stB.dX1 << "," << stB.dY1 << "," << stB.dX2 << "," << stB.dY2<< " score=" << stB.dScore << " cls=" << stB.nCls << "\n";}// 输出形状(一次)static bool bPrinted = false;if (!bPrinted) {for (size_t i = 0; i < pSess->GetOutputCount(); i++) {auto strName = pSess->GetOutputNameAllocated(i, stAlloc);auto stInfo = pSess->GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo();auto vShape = stInfo.GetShape();std::cout << "[out" << i << "] name=" << strName.get() << " shape=[";for (auto v : vShape) std::cout << v << " ";std::cout << "]\n";}bPrinted = true;}cv::Mat matVis = matImg.clone();for (const auto& stB : vKeep) {cv::rectangle(matVis, cv::Rect(cv::Point((int)stB.dX1, (int)stB.dY1),cv::Point((int)stB.dX2, (int)stB.dY2)), { 0,255,0 }, 2);char szText[64];std::snprintf(szText, sizeof(szText), "id=%d %.2f", stB.nCls, stB.dScore);cv::putText(matVis, szText, { (int)stB.dX1, (int)stB.dY1 - 5 },cv::FONT_HERSHEY_SIMPLEX, 0.5, { 0,255,0 }, 1);}fs::path strOutPath = strOutDir / pPath.filename();cv::imwrite(PathToCv(strOutPath), matVis);std::cout << "[save] " << strOutPath << "\n";}}catch (const std::exception& e) {std::cerr << "[exception] " << e.what() << "\n";return -1;}return 0;
}

使用示例
YoloOnnxBatch.exe ..\models\yolo11n.onnx ..\assets\samples ..\runs\results
..\models\yolo11n.onnx→ 模型文件..\assets\samples→ 输入图片目录..\runs\results→ 推理结果保存目录(自动创建)
程序运行后,会在 ..\runs\results 目录下生成带框的图片。
7. 如果手上只有“原始头”ONNX(84/85)怎么办?
保留“原始头”(如 \[1,84,8400])就需要在推理端做后处理:
- 将输出视为
\[C, N]或\[N, C];前 4 是cx, cy, w, h,后 80 是类别概率(多为 sigmoid); - 对每候选:
cls = argmax(80 类),score = max(prob);过滤score < conf; - 中心点框→角点框:
x1=cx-w/2, y1=cy-h/2, x2=cx+w/2, y2=cy+h/2; - 按类别做 NMS(IoU≈0.45),可加
topK截断; - 再画框/保存。
工程复杂度会提升,更推荐导出
nms=True的 ONNX。
8. vcpkg 无 ORT Config.cmake:CMake 兜底
思路:手动找到 ORT 的 头文件和库,创建一个与官方一致的
onnxruntime::onnxruntime目标,后续业务代码就能统一target_link_libraries( … onnxruntime::onnxruntime …)。
cmake_minimum_required(VERSION 4.0)
project(YoloOnnxBatch)set(CMAKE_CXX_STANDARD 20)# ============================================================
# 检查是否指定了 vcpkg toolchain(或其他 toolchain)
# - 如果没有设置,则发出警告,后续走系统路径 / 手工路径逻辑
# - 如果设置了,就打印出来,说明当前正在使用该 toolchain
# ============================================================
if(NOT CMAKE_TOOLCHAIN_FILE)message(WARNING "CMAKE_TOOLCHAIN_FILE is not set! Will try system paths or manual settings.")
else()message(STATUS "Using toolchain file: ${CMAKE_TOOLCHAIN_FILE}")
endif()# ============================================================
# 打印当前编译环境信息,便于诊断
# - Compiler : 编译器类型和版本(例如 MSVC 19.43)
# - Generator: CMake 使用的生成器(如 Ninja、Visual Studio)
# - MSVC : 是否在使用 MSVC 编译器 (1 = 是, 空 = 否)
# ============================================================
message(STATUS "Compiler: ${CMAKE_CXX_COMPILER_ID} ${CMAKE_CXX_COMPILER_VERSION}")
message(STATUS "Generator: ${CMAKE_GENERATOR}")
message(STATUS "MSVC: ${MSVC}")# 通过 vcpkg toolchain 找到 OpenCV
find_package(OpenCV REQUIRED)# ---- 手工导入 ONNX Runtime(无 Config.cmake 的兜底做法) ----
# 从 vcpkg 的变量推断 installed 目录;如果没启用 toolchain,可以手动改下面两个变量
if(NOT VCPKG_TARGET_TRIPLET)set(VCPKG_TARGET_TRIPLET "x64-windows")
endif()# VCPKG_INSTALLED_DIR 只有在启用了 toolchain 时才自动存在;否则按你的路径设置
if(NOT VCPKG_INSTALLED_DIR)# 手动指定 vcpkg 根目录(按你的实际路径改一下)set(_VCPKG_ROOT "D:/dev/vcpkg")set(VCPKG_INSTALLED_DIR "${_VCPKG_ROOT}/installed")
endif()set(_VCPKG_TRIPLET_DIR "${VCPKG_INSTALLED_DIR}/${VCPKG_TARGET_TRIPLET}")# 头文件(通常在 include/ 或 include/onnxruntime/)
find_path(ORT_INCLUDE_DIR onnxruntime_cxx_api.hHINTS"${_VCPKG_TRIPLET_DIR}/include""${_VCPKG_TRIPLET_DIR}/include/onnxruntime"NO_DEFAULT_PATH
)# 库文件:核心库 + 可能存在的 provider 库(有就连,没有就忽略)
macro(_find_ort_lib _var _name)find_library(${_var} NAMES ${_name}HINTS"${_VCPKG_TRIPLET_DIR}/lib" "${_VCPKG_TRIPLET_DIR}/debug/lib""${_VCPKG_TRIPLET_DIR}/lib/manual-link" "${_VCPKG_TRIPLET_DIR}/debug/lib/manual-link"NO_DEFAULT_PATH)
endmacro()_find_ort_lib(ORT_CORE_LIB onnxruntime) # 必有
_find_ort_lib(ORT_CXX_API_LIB onnxruntime_cxx_api) # 有的包会拆出来
_find_ort_lib(ORT_PROV_SHARED_LIB onnxruntime_providers_shared)
_find_ort_lib(ORT_PROV_CUDA_LIB onnxruntime_providers_cuda)if(NOT ORT_INCLUDE_DIR OR NOT ORT_CORE_LIB)message(FATAL_ERROR"Cannot locate ONNX Runtime headers or libraries in ${_VCPKG_TRIPLET_DIR}.\n""请确认已安装 onnxruntime-gpu:x64-windows(或相应 CPU 版)且 triplet 一致。")
endif()# 建一个与官方一致的目标名,后续如果换成 find_package 也不用改业务代码
add_library(onnxruntime::onnxruntime INTERFACE IMPORTED)set(_ORT_LINK_LIBS ${ORT_CORE_LIB})
if(ORT_CXX_API_LIB)list(APPEND _ORT_LINK_LIBS ${ORT_CXX_API_LIB})
endif()if(ORT_PROV_SHARED_LIB)list(APPEND _ORT_LINK_LIBS ${ORT_PROV_SHARED_LIB})
endif()if(ORT_PROV_CUDA_LIB)list(APPEND _ORT_LINK_LIBS ${ORT_PROV_CUDA_LIB})
endif()message(STATUS "ORT link libs: ${_ORT_LINK_LIBS}")set_target_properties(onnxruntime::onnxruntime PROPERTIESINTERFACE_INCLUDE_DIRECTORIES "${ORT_INCLUDE_DIR}"INTERFACE_LINK_LIBRARIES "${_ORT_LINK_LIBS}"
)# 源码
include_directories(${CMAKE_SOURCE_DIR}/include)
add_executable(YoloOnnxBatch main.cppYoloOnnx.cppYoloOnnx.h)target_include_directories(YoloOnnxBatch PRIVATE ${CMAKE_SOURCE_DIR}/include)
# 链接(vcpkg 导出的 ORT 目标名是 onnxruntime::onnxruntime)
target_link_libraries(YoloOnnxBatchPRIVATEonnxruntime::onnxruntime${OpenCV_LIBS}
)# Windows 编译器小优化(可选)
if(MSVC)add_definitions(-DNOMINMAX)
endif()# ---- 运行时 DLL 复制(避免 PATH 问题)----
# 把 vcpkg 的 bin/debug/bin 全拷到可执行目录(省心做法)
foreach(_bindir "${_VCPKG_TRIPLET_DIR}/bin" "${_VCPKG_TRIPLET_DIR}/debug/bin")if(EXISTS "${_bindir}")add_custom_command(TARGET YoloOnnxBatch POST_BUILDCOMMAND ${CMAKE_COMMAND} -E copy_directory "${_bindir}" "$<TARGET_FILE_DIR:YoloOnnxBatch>"VERBATIM)endif()
endforeach()
9. 常见坑位与速查
- 全是框/噪声:多半是不带 NMS又没在 C++ 做后处理;或
conf太低。 - 一个框也没有:
conf过高、预处理不一致(resize vs letterbox)、或阈值设置不当。 - OpenCV 提示
parallel_*_dll => FAILED:并行后端插件加载失败的提示,不影响推理。 - CUDA provider not available:未装
onnxruntime-gpu或 CUDA/CUDNN/驱动不匹配;ORT 会自动回退 CPU。 - Windows 中文路径:ORT 用
std::wstring构造Ort::Session;OpenCV 用std::filesystem::path的u8string()。 - 分数都 ≈0.5:多是阈值设置问题;或读取的输出是原始头,未做 NMS。
10. Checklist
- 导出是否使用
nms=True? - 输出形状是否为
[...,6] / [...,7](带 NMS)或包含84/85(原始头)? - 若是原始头,C++ 是否做了“阈值 + NMS”?
-
conf/iou是否合适(建议从0.25 / 0.45起步)? - 预处理是否与训练一致(resize vs letterbox)?
- vcpkg 下 ORT 若无 Config.cmake,是否采用了兜底 CMake?
附录:NMS 变体与阈值选择
- Hard-NMS(默认):超过 IoU 阈值直接删除。
- Soft-NMS:不删除、按 IoU 衰减分数(线性/高斯),保留更多边界情况;常用于提升召回。
- DIoU-NMS / CIoU-NMS:在 IoU 中加入中心距离/形状项,更倾向于留位置更合理的框。
- WBF(Weighted Box Fusion):融合多个重叠框为一个更稳的框(常见于多模型集成)。
阈值建议:conf≈0.25、iou≈0.45 起步;
- 提高
conf:框更少、漏检风险上升; - 提低
iou:更“严格”,框更少;提高iou:更“宽松”,可能保留相近重复框。
一句话结论:
想简单稳定、业务快速落地,直接从 .pt 导出 nms=True 的 ONNX,C++ 侧只画框即可;配合上面的 Python/C++ 判别方法 和 vcpkg CMake 兜底,整个链路就会非常顺滑。