SPSS数据文件的建立与管理
SPSS定义变量:
在SPSS中输入数据前先要定义变量,即对变量的名称、类型、宽度等进行定义,如图所示。下面主要介绍变量名称、变量类型、变量标签、变量值标签、缺失值、测量尺度、角色的定义。
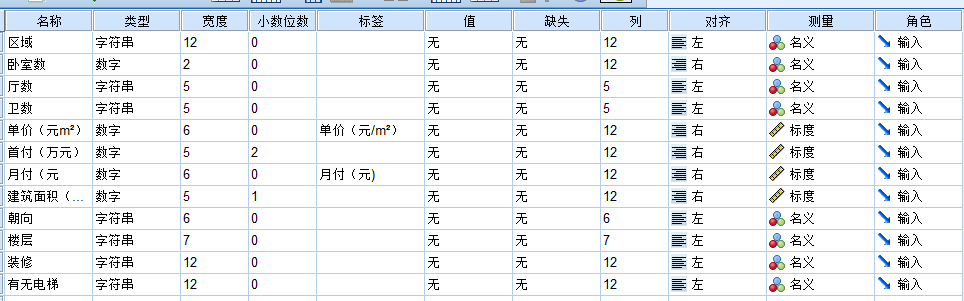
1. 变量名称
变量名称也叫变量名,是访问和分析变量的唯一标识。在定义SPSS数据结构时应先给出每列变量的变量名。变量的命名规则如下。
(1)变量名最好与其代表的数据含义相对应,同一个数据文件中每个变量名必须具有唯一性。 (2)首字符应以英文字母或汉字开头,后面可以跟除“!”“?”“*”之外的字母或数字,最后一个字符不能是下划线、圆点。
(3)系统保留字(如ALL、BY、AND、NOT、OR等)不能作为变量名。
(4)当英文字母作为变量名时,系统不区分大小写字母。
(5)SPSS有默认的变量名。当没有为变量命名时,会以字母“VAR”开头,后面补足5位数字,如VAR00001、VAR00012等。
2. 变量类型
| 变量类型 | 说明 |
| 数字 | 标准的数值型,默认宽度为8位,小数位数为两位。当宽度大于8位时,SPSS将自动按照科学计数法显示变量值 |
| 逗 | 加逗号的数值型,从个位数开始每3位以一个逗号分隔,默认的列宽是8,小数位宽为2,逗号所占的位数包含在总位数之内,如5,432.23 |
| 点 | 加点的数值型,从个位数开始每3位以一个圆点分割,以逗号作为整数和小数部分的分隔符,默认列宽为8,小数位宽为2,如5.432,23 |
| 科学计数法 | 在数据编辑器窗口中以指数形式显示。例如,150用科学计数法表示为1.5E+02,其中E表示以10为底,+02表示正的2次方。又如,0.002用科学计数法表示为2.0E-03,-03表示负的3次方 |
| 美元符号型 | 表示货币数据,其在数据前加符号“$” |
| 日期型 | 用户可从系统提供的多种日期显示形式中选择自己需要的形式。例如,mm/dd/yy形式,则2030年8月15日显示为08/15/30 |
| 字符型 | 用户可定义字符长度以便输入字符。如职工号码、姓名、地址等变量都可以定义为字符型变量。字符型变量的默认显示宽度为8个字符,不能够进行算术运算 |
3. 变量标签
变量标签又叫变量名称标签,是对变量名称含义的进一步解释说明。变量标签可长达120个字符,而变量名称不能超过8个字符,当8个字符不足以表示变量的含义时,可利用变量标签做详细的说明。通常如果当变量名称已经是中文,则变量标签可省略。
在SPSS数据编辑器的视图窗口中,在【标签】列相应的位置单击,可进行变量标签的设置。
4. 变量值标签
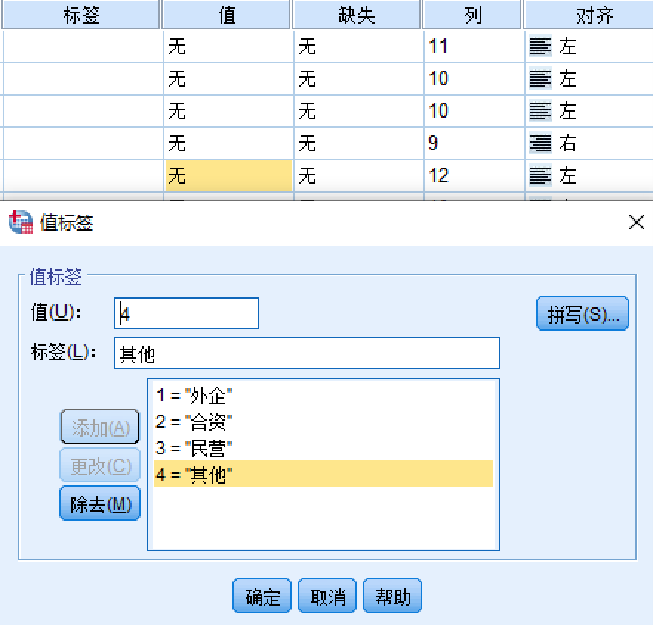
变量值标签简称值,是对变量每一个可能取值的进一步描述,对定性变量尤为重要。
在SPSS数据编辑器的视图窗口中,在【值】列相应的位置单击,会弹出“值标签”对话框,如图2.2所示。在该对话框的【值(U)】文本框输入变量值,在【标签(L)】文本框输入变量值标签,并单击【添加(A)】、【更改(C)】或者【除去(M)】按钮。
5. 缺失值
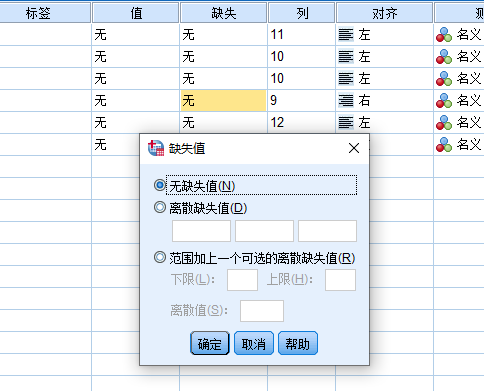
存在明显错误的数据明显不合理的数据或漏填的数据项在统计学上称为缺失值或不完全数据。SPSS有两类缺失值:系统缺失值和用户缺失值。在数据显示栏中,任何空的数字单元都被认为是系统缺失值,数值型用圆点表示,字符型用空格表示。
由特殊原因造成的信息缺失值,称为用户缺失值。在SPSS数据编辑器的视图窗口中,在【缺失】列相应的位置单击,会弹出“缺失值”对话框。对于字符或定量变量,用户缺失值可以是1~3个特定的离散值;对一个定量变量,用户缺失值可以是一个连续的闭区间并同时附加一个区间以外的离散值。
6.测量
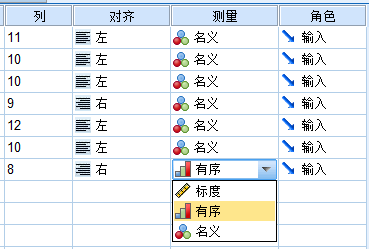
测量即测量尺度,是对不同种类的数据,依据变量尺度所划分的类别。统计学依据测量尺度,将变量划分为定性变量、定量变量、定序变量。
在SPSS数据编辑器的视图窗口中,在【测量】列相应的位置单击,会出现测量尺度定义下拉菜单,可以在该下拉菜单下选择合适的测量尺度。
7. 角色
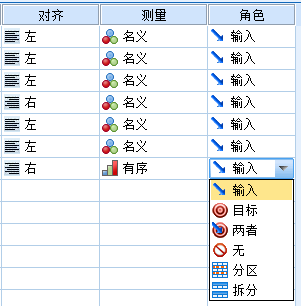
变量角色是指变量在模型建立时所扮演的角色,变量角色不同,其作用也不同。
模型建立时,有些变量用于解释其他变量,称为解释变量或自变量,SPSS称之为输入变量,承担“输入”角色;有的变量是被其他变量解释的,称为被解释变量或因变量,SPSS称之为目标变量,承担“目标”角色;在某些分析中,变量需要承担双重角色,既是输入变量,又是输出变量,SPSS称之为“两者”;有时候有的变量仅仅是一种标识,不会放入模型,记为“无”;有的变量用作样本的划分依据,将样本划分为训练集、测试集和验证集,记为“分区”;有的定性变量可作为数据的拆分依据,将样本集拆分为几个部分,记为“拆分”。
SPSS数据的录入
第一步:启动SPSS时,在启动对话框中选择【新数据集】选项,打开一个空数据编辑器窗口;若数据编辑器窗口中已有数据集,但又需要建立新的数据文件,可以在菜单栏中选择【文件(F)】→【新建(N)】→【数据(D)】,新建数据编辑器窗口“无标题2[数据集1]-IBM SPSS Statistics数据编辑器”。
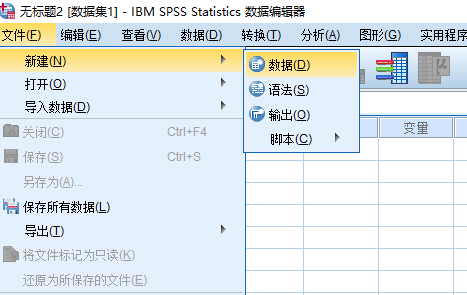
第二步:单击数据编辑器窗口左下角的【变量视图】按钮,切换到变量视图窗口,根据要录入的数据定义变量属性。
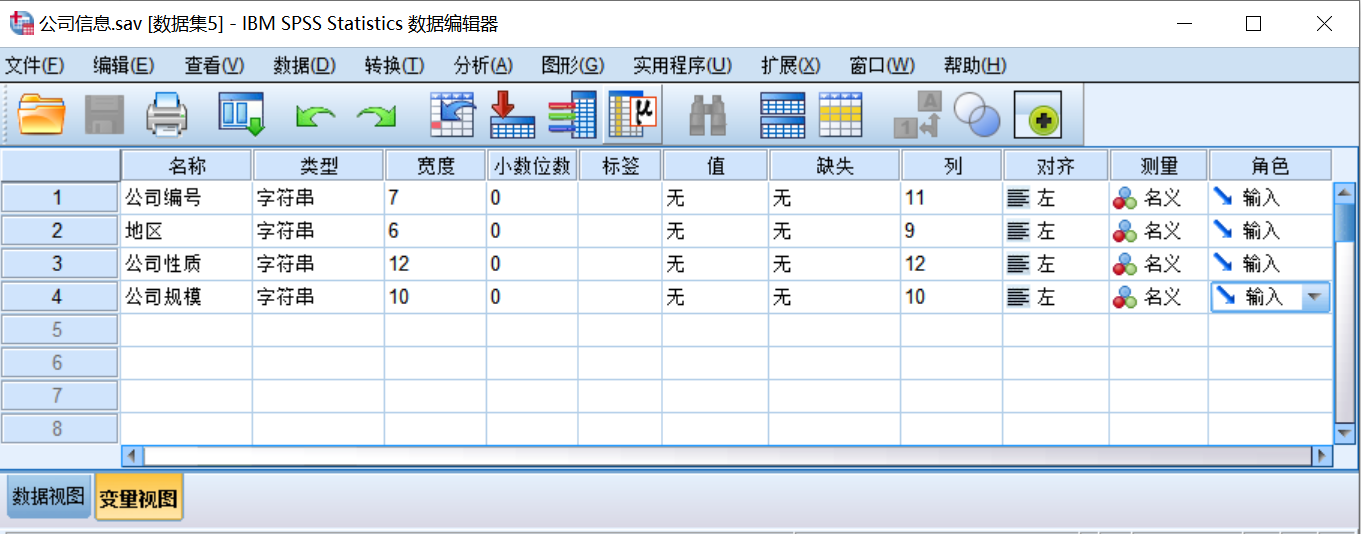
第三步:在左下角单击【数据视图】按钮,就可以直接在SPSS数据编辑器窗口里以电子表格的方式直接录入数据,建立SPSS文件,录入样例如图所示。
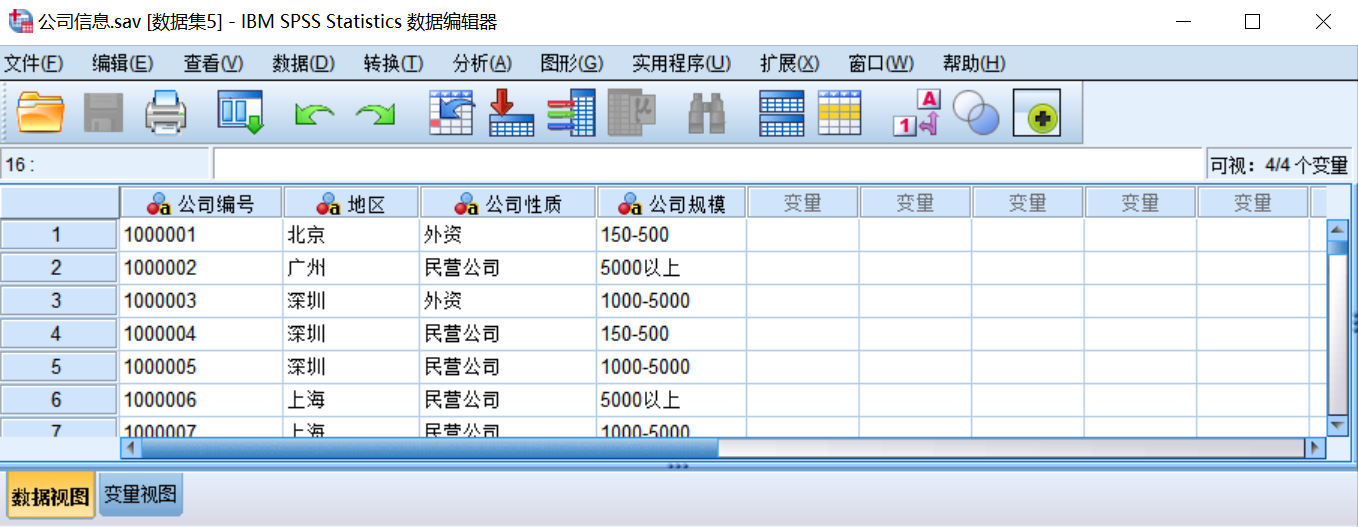
在录入时需要遵守相应的格式要求,其基本原则为:在数据视图窗口下,每一行代表一个个案的所有变量的取值;每一列代表一个变量的所有取值。
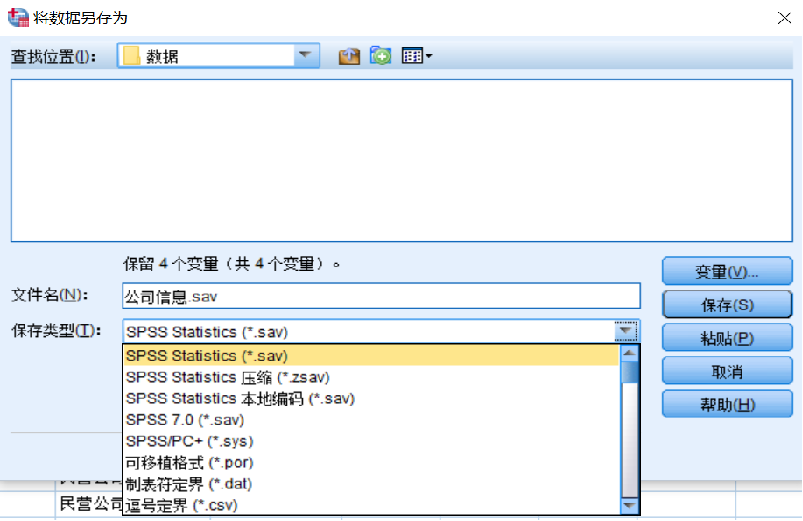
第四步:在菜单栏中选择【文件(F)】→【另存为(A)】,会弹出“将数据另存为”对话框,如图所示,在该对话框中选择保存数据文件的位置;填写数据文件的【文件名(N)】,如“公司信息.sav”;【保存类型(T)】选择【SPSS Statistics(*.sav)】;单击【保存(S)】按钮,则完成建立SPSS默认的数据文件。
导入其他类型的数据文件
1.使用Excel向导读入Excel文件
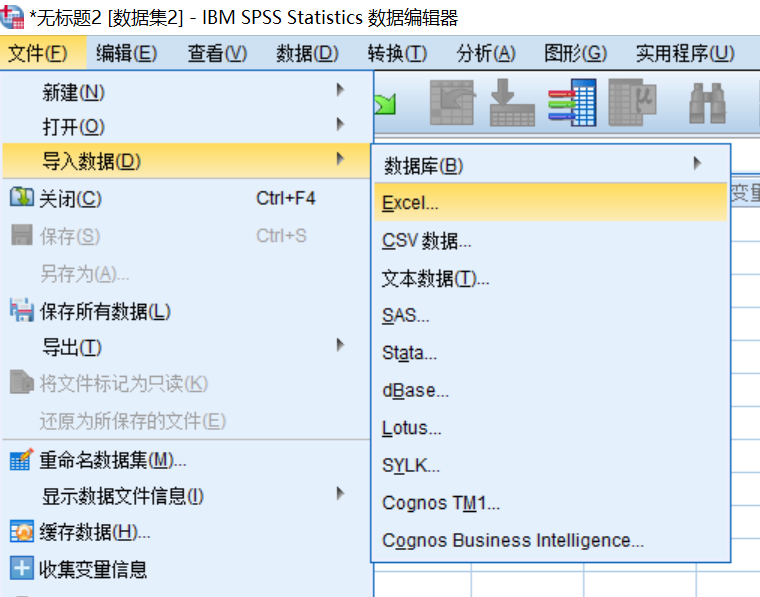
第一步:启动SPSS,在菜单栏中选择【文件(F)】→【导入数据(D)】→【Excel】,将弹出“打开数据”对话框,在该对话框中选择数据所在的路径,选择文件“招聘数据.xlsx”,如图所示,单击【打开(O)】。
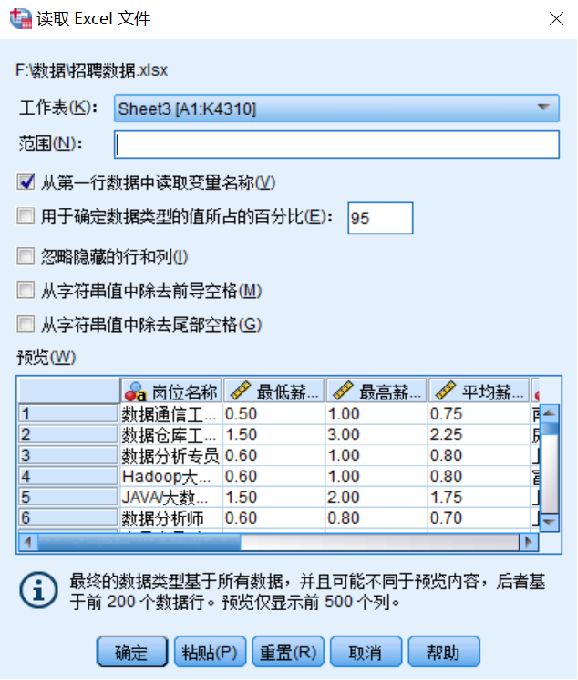
第二步:设置读取Excel文件的格式,如图所示;如果Excel工作表上第一行为变量名,则需要勾选【从第一行数据中读取变量名称】,单击【确定】按钮。这时候就完成了Excel文件的导入,但一般会根据实际情况在变量视图窗口对变量定义进行调整。
2.使用文本向导导入文本文件
第一步:启动SPSS,在菜单栏中选择【文件(F)】→【导入数据(D)】→【文本数据(T)】,将弹出“打开数据”对话框,根据数据所在的路径,选择文件“招聘数据.txt”,如图,并单击【打开(O)】按钮。
第二步:在“文本导入向导-第1/6步”对话框中,需要观察文本文件与预定义的格式是否匹配,如果不匹配,则需要设置文本导入格式,如图所示,单击【下一步(N)】按钮。
第五步:在弹出的“文本导入向导-定界,第4/6步”对话框中,指定文本文件中数据项之间的定界符,如图所示,定界符可以是制表符、逗号、空格、分号或者其他符号,单击【下一步(N)】按钮。
第六步:随后出现的两个对话框采用默认设置,主要用于指定各变量的变量名和类型。 到此为止,完成了对文本文件的导入操作。接下来,可以对导入的数据进行必要的加工或处理,并保存为SPSS格式文件。
SPSS数据合并

1 字段合并
字段合并的实质是将两个数据文件按照个案对应进行左右对接,因此字段合并也叫横向合并、变量合并。
第一步:准备好需要合并的数据文件,注意要进行字段合并的两个SPSS数据文件的个案数量必须完全一致。这两个数据文件均有3922个个案,数据文件“公司信息.sav”有4个变量,包括公司编号、地区、公司性质、公司规模,如图2.17所示;数据文件“招聘信息.sav”有7个变量,包括公司编号、岗位名称、最低薪资、最高薪资、经验要求、学历要求、招聘人数,如图所示。
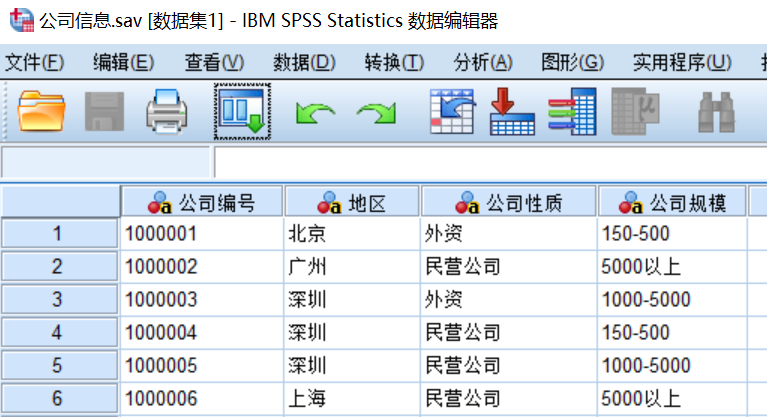
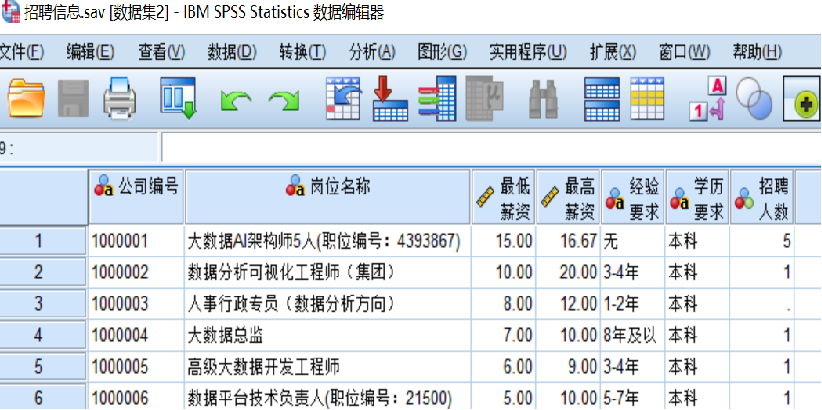
第二步:打开数据文件“公司信息.sav”,如图所示,在菜单栏中选择【数据(D)】→【合并文件(G)】→【添加变量(V)】。
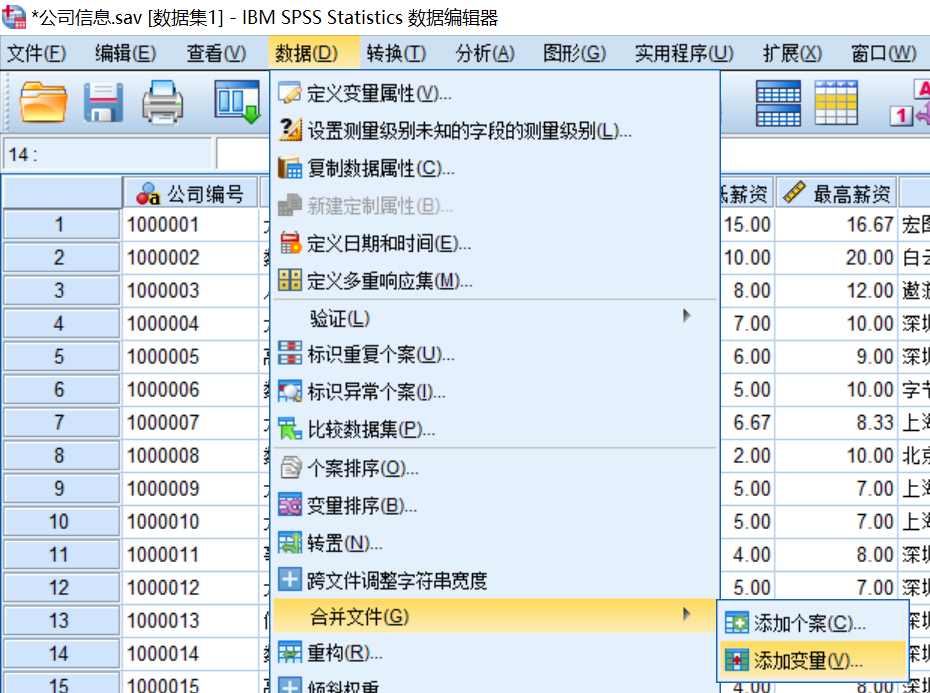
第三步:在弹出的“变量添加至 公司信息.sav[数据集1]”对话框中,选择需要新增变量的数据文件,即选择数据文件“招聘信息.sav[数据集2]”,如图所示,单击【继续(C)】按钮。
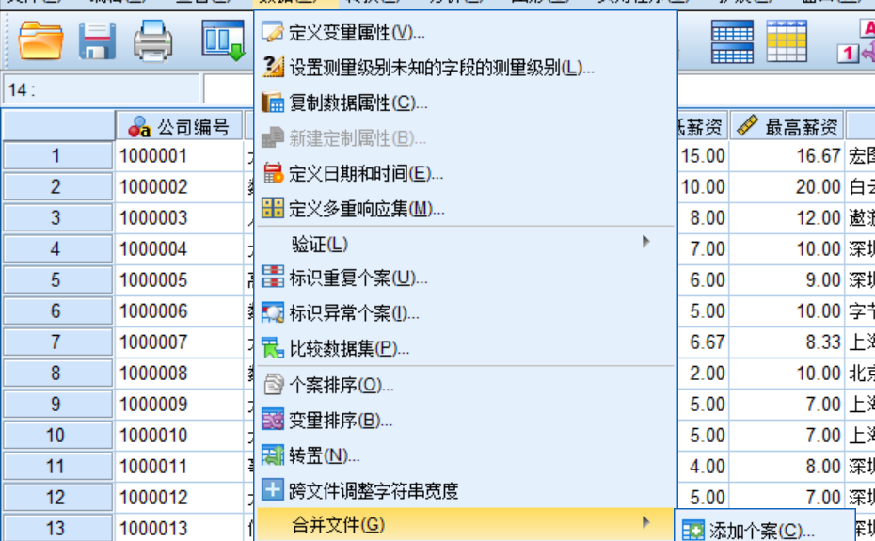
第四步:在弹出的“变量添加自 数据集2”对话框中设置合并方式。合并方法有以下3种,【基于文件顺序的一对一合并(O)】是按照文件顺序依次合并;【基于键值的一对一合并(N)】是以“键变量”形式进行一对一合并;【基于键值的一对多合并(M)】是以“键变量”形式进行一对多合并。此案例中,两个数据文件有一个共同变量——公司编号,因此,选择第二种合并方法,如图所示,单击【确定】按钮。

第五步:文件确认,数据文件“公司信息.sav”在原数据文件的基础上新增了岗位名称、最低薪资、最高薪资、经验要求、学历要求、招聘人数6个变量,完成了数据的字段合并,如图所示。
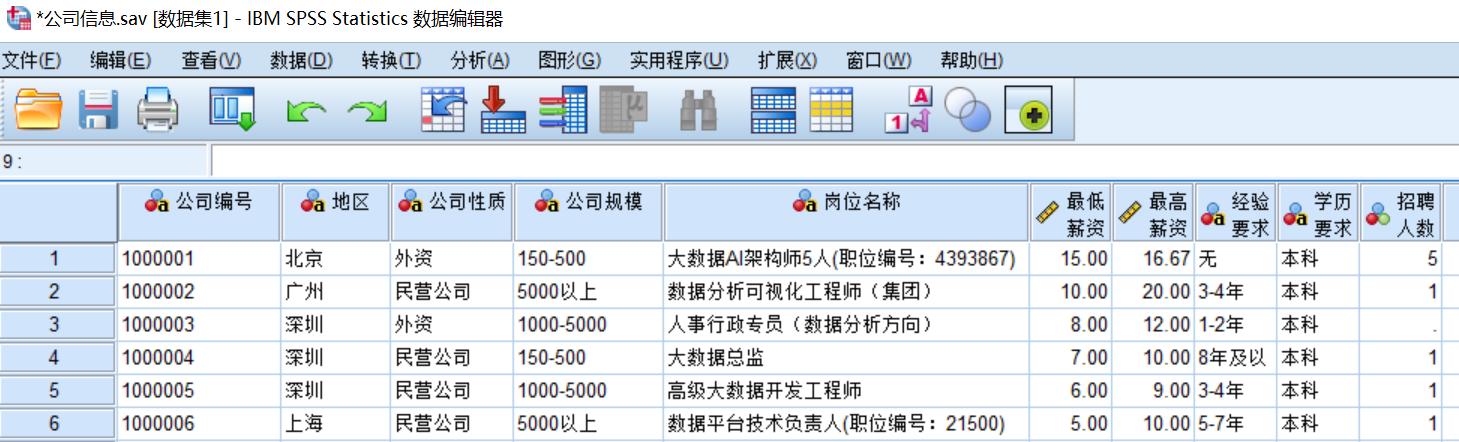
2 个案合并
个案合并的实质是将两个数据文件按照变量对应进行上下对接,因此也叫纵向合并、记录合并。
第一步:准备好需要合并的数据文件,注意,个案合并的SPSS数据文件的变量数量必须完全一致。两个数据文件均包含9个变量,如图所示。
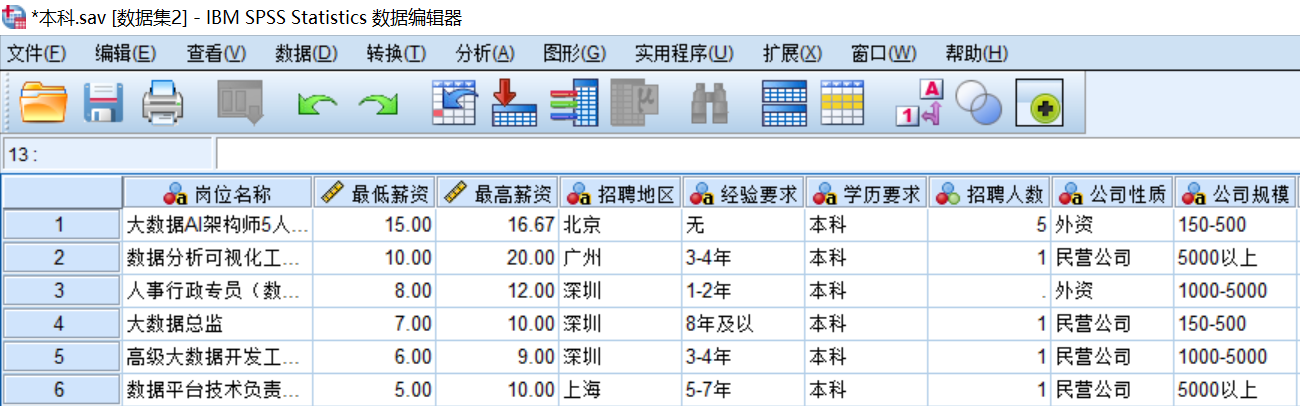
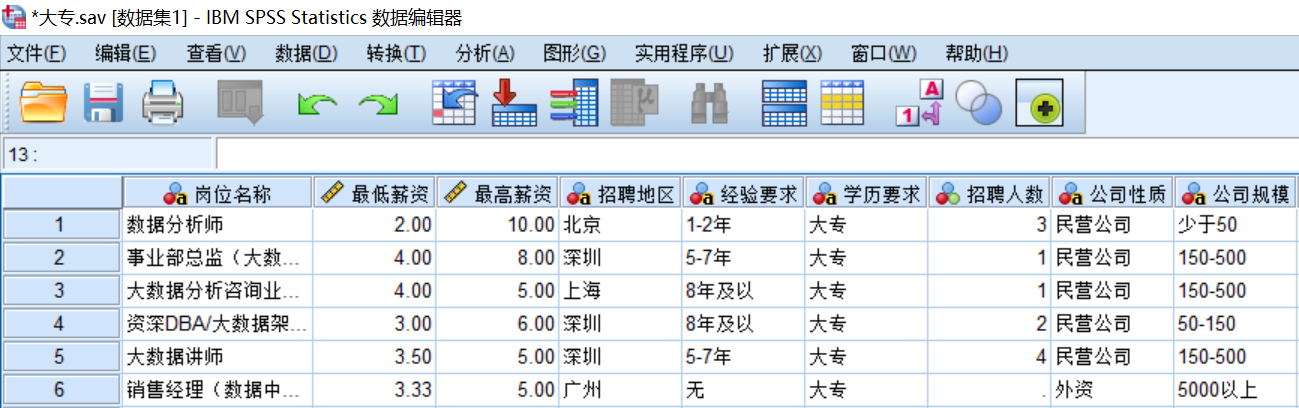
第二步:在菜单栏中选择【数据(D)】→【合并文件(G)】→【添加个案(C)】,如图所示。
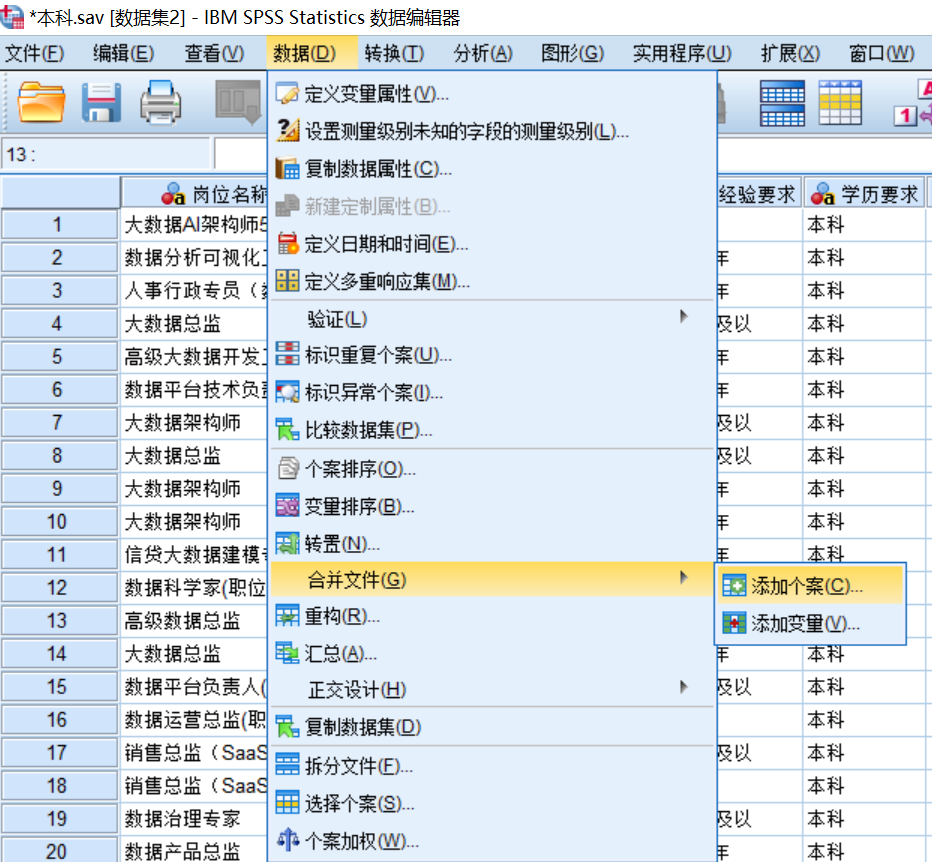
第三步:在弹出的“添加个案至 本科.sav[数据集2]”对话框中,选择需要合并的文件,选择文件“大专.sav[数据集3]” ,如图所示,单击【继续(C)】按钮。如果待合并的数据文件尚未读入SPSS中,则选择【外部SPSS Statistics数据文件】进行设置。
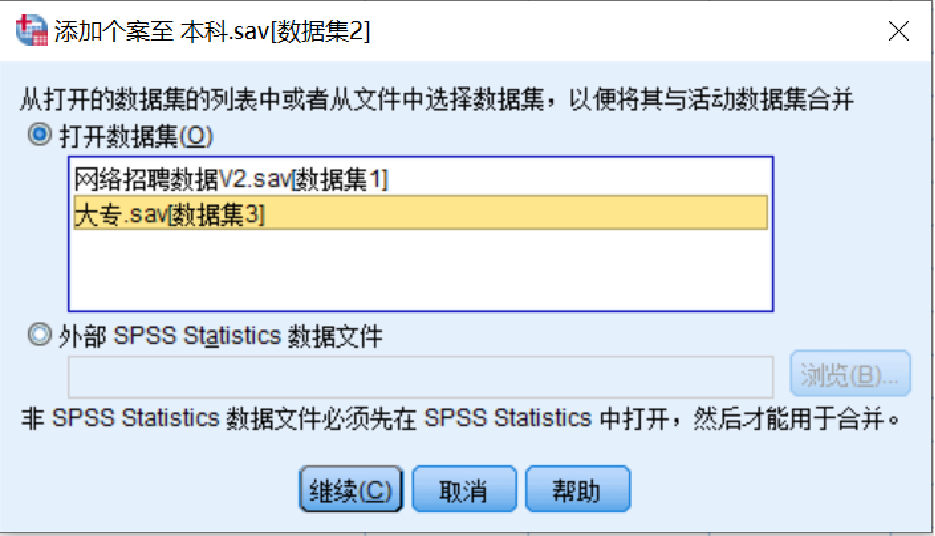
第四步:在弹出的“添加个案自 数据集3”对话框中,【新的活动数据集中的变量(V)】框内会显示两个数据文件中的同名变量,SPSS默认它们具有相同的数据含义,并将它们作为合并后新数据文件中的变量。如果不接受这种默认,可以按箭头按钮将它们移至【非成对变量(V)】框内。此处采用默认设置,如图所示,单击【确定】按钮,完成数据的个案合并。
第五步:数据编辑器里已经将所有本科及大专招聘数据,文件合并完成,如图所示.
SPSS数据拆分
1 拆分文件
拆分文件的具体操作步骤如下。 第一步:在SPSS菜单栏中选择【数据(D)】→【拆分文件(F)】,弹出“拆分文件”对话框。
第二步:在“拆分文件”对话框中,选择拆分变量到【分组依据(G)】框内,文件拆分后会使后面的分组统计产生不同格式的结果。其中【分析所有个案,不创建组(A)】实际上并未实现拆分文件;【比较组(C)】将分组统计结果输出到同一张表格里,方便不同组之间进行对比;【按组来组织输出】将分组统计结果分别输出到不同的表格中,通常选择【比较组(C)】。
第三步:如果数据编辑器窗口中的数据已经事先按指定的拆分变量进行排序,则选择【文件已排序(F)】,可提高拆分效率;否则选择【将分组变量进行文件排序(S)】。此处以“学历要求”为分组依据,以比较组的形式进行结果展示,如图所示。
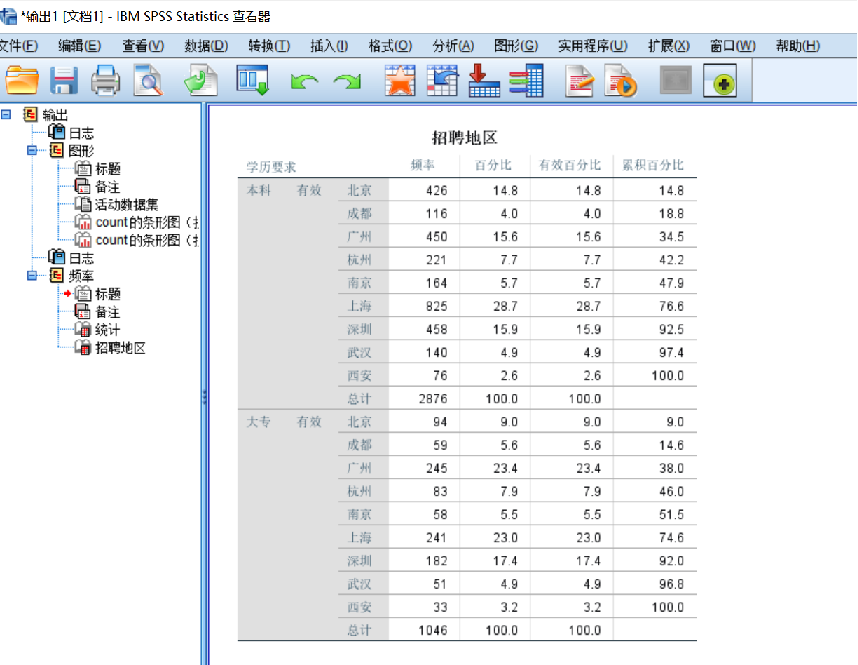
第四步:拆分文件完成后,再对数据进行基本分析时,结果将根据第三步的分组依据进行展示。如图所示,此处按照“学历要求”分组展示了招聘地区的频率分布。
拆分为文件的具体操作步骤如下。 第一步:在SPSS菜单栏中选择【数据(D)】→【拆分为文件】,弹出“将数据集拆分为单独的文件”对话框,如图所示。
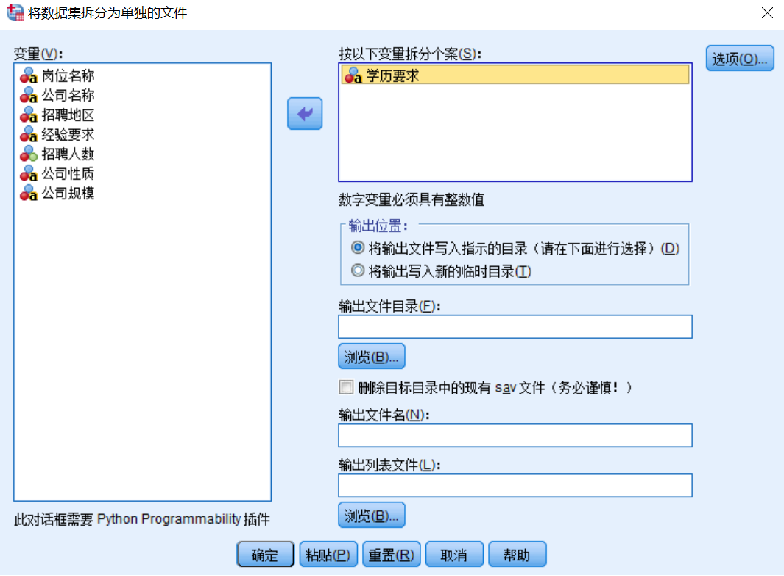
第二步:在“将数据集拆分为单独的文件”对话框中,选择拆分依据,此处选择定性变量“学历要求”进行数据拆分,单击【确定】按钮。
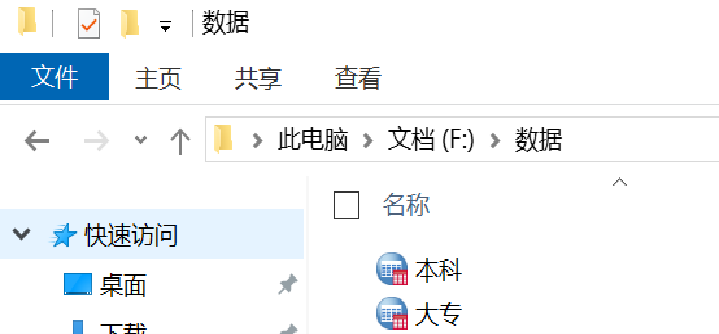
第三步:打开计算机本地文件夹,可以发现已经依据“学历要求”将数据文件“网络招聘数据.sav”拆分为两个文件“本科.sav”和“大专.sav”,如图所示。
以下是通俗易懂的SPSS数据文件建立与管理指南,适合零基础学习:
一、SPSS数据文件基础
SPSS数据文件以.sav为扩展名,类似Excel表格,但专为统计分析设计。每行代表一个个案(如一个人、一个样本),每列代表一个变量(如年龄、性别、分数)。
二、建立数据文件的步骤
1. 打开SPSS,选择数据视图
- 启动SPSS后,默认进入数据视图(Data View),这里像Excel一样输入数据。
- 底部标签切换:
- 数据视图:输入数据。
- 变量视图:定义变量属性(名称、类型、标签等)。
2. 在变量视图中定义变量
在输入数据前,必须先定义变量属性(否则SPSS不知道如何处理数据)。点击底部变量视图标签:
- 名称(Name):变量名(如
age、gender),不能有空格或特殊符号。 - 类型(Type):
- 数值型(Numeric):默认,用于数字(如年龄、分数)。
- 字符串型(String):用于文本(如姓名、地址)。
- 日期型(Date):记录日期。
- 宽度(Width):变量占用的字符数(数值型默认8,字符串型需手动设置)。
- 小数(Decimals):小数位数(如年龄设为0,分数设为2)。
- 标签(Label):变量的详细说明(如“年龄(岁)”、“性别(1=男, 2=女)”)。
- 值(Values):为分类变量定义代码(如性别:1=男,2=女)。
- 缺失值(Missing):定义哪些值代表缺失(如-99、空白)。
3. 在数据视图中输入数据
切换回数据视图,按变量定义输入数据:
- 每列对应一个变量,每行对应一个样本。
- 分类变量输入代码(如性别输入1或2),数值变量直接输入数字。
4. 保存数据文件
- 点击菜单栏 文件 → 保存(或按
Ctrl+S)。 - 选择保存路径,文件名用英文(避免中文乱码),扩展名
.sav。
三、数据管理操作
1. 插入/删除变量或个案
- 插入变量:右键点击列标题 → 插入变量。
- 删除变量:右键点击列标题 → 清除。
- 插入个案:右键点击行号 → 插入个案。
- 删除个案:选中行 → 按
Delete键。
2. 数据排序
- 点击菜单栏 数据 → 排序个案。
- 选择排序变量(如按年龄升序),点击确定。
3. 数据筛选
- 点击菜单栏 数据 → 选择个案。
- 选择筛选条件(如“年龄>18”),点击确定(仅显示符合条件的个案)。
4. 数据拆分
- 点击菜单栏 数据 → 拆分文件。
- 按分组变量拆分(如按性别分组分析),便于对比不同组数据。
5. 数据合并
- 纵向合并(增加个案):
- 点击 数据 → 合并文件 → 添加个案。
- 选择另一个
.sav文件,匹配变量后合并。
- 横向合并(增加变量):
- 点击 数据 → 合并文件 → 添加变量。
- 确保两个文件有共同标识变量(如ID),按标识合并。
6. 数据转置
- 点击菜单栏 数据 → 转置。
- 将行转为列(如将多个测量时间点的变量转为长格式)。
7. 数据导出
- 点击 文件 → 导出,可保存为Excel(
.xlsx)、CSV(.csv)等格式。
四、实用技巧
- 变量命名规范:
- 简短且有意义(如
income而非var1)。 - 避免空格和特殊符号(用下划线
_代替空格)。
- 简短且有意义(如
- 值标签:
- 为分类变量添加值标签(如1=男,2=女),分析时直接显示文字而非数字。
- 备份数据:
- 定期保存并备份
.sav文件,避免数据丢失。
- 定期保存并备份
- 检查数据:
- 使用 分析 → 描述统计 → 描述 查看变量基本统计量,检查异常值。
五、示例:建立一个学生成绩数据集
- 变量视图:
name(字符串,宽度8):学生姓名。gender(数值,值标签:1=男,2=女):性别。age(数值):年龄。score(数值):数学成绩。
- 数据视图:
- 输入3名学生数据:
name gender age score 张三 1 18 85 李四 2 19 90 王五 1 17 78
- 输入3名学生数据:
- 保存文件:命名为
students.sav。
六、常见问题
- Q:变量名输入错误怎么办?
A:在变量视图中直接修改名称,数据视图会自动更新。 - Q:如何批量修改数据?
A:使用 转换 → 计算变量 或 转换 → 重新编码。 - Q:SPSS卡死或未响应?
A:关闭其他程序,或重启SPSS后重新打开文件。
总结
SPSS数据文件以.sav格式存储,建立时需先在变量视图定义变量属性(名称、类型、标签等),再到数据视图按列输入数据,每行代表一个样本。管理操作包括插入/删除变量或个案、排序、筛选、拆分、合并(纵向增个案、横向增变量)及转置等,可通过菜单栏“数据”选项完成。实用技巧有规范命名变量、添加值标签、定期备份数据。掌握这些基础操作后,能高效完成数据录入、整理与预处理,为后续统计分析打下坚实基础,适合零基础快速上手。