nvidia最新论文:小型语言模型是代理人工智能的未来

- 本文提出小型语言模型(SLM)因其足够强大的能力、更高的操作适用性和更优的经济性,将成为Agentic AI的未来。
- 代理系统多数任务为重复且特定,SLM在推理效率、微调灵活性和边缘部署上优势明显,且能更好地与代理交互行为对齐。
- 作者倡导采用异构代理系统,默认使用SLM并按需调用LLM,并提出了将现有LLM代理转换为SLM代理的具体算法,以促进AI资源的高效利用。
该论文提出,在代理 AI (Agentic AI) 系统中,小型语言模型 (Small Language Models, SLMs) 是未来的发展方向。尽管大型语言模型 (Large Language Models, LLMs) 因其接近人类的表现和通用对话能力而备受赞誉,但代理 AI 系统中的许多应用场景要求语言模型重复执行少量专业任务,且变化不大。
论文的核心观点是:SLMs 对于代理系统中的许多调用来说,已经足够强大 (V1)、本质上更适合 (V2),并且必然更经济 (V3),因此是代理 AI 的未来。
核心方法论和技术细节阐述
论文通过详细论证来支持其立场,主要围绕以下几个方面:
-
能力与效用 (V1):
- SLM 的能力提升(论点 A1):过去几年,SLMs 的能力显著提升。尽管语言模型缩放定律依然成立,但模型大小与能力之间的曲线变得越来越陡峭,意味着新型 SLMs 的能力已非常接近甚至超越了之前的大型模型。
- 例如,Microsoft Phi-2 (2.7B) 在常识推理和代码生成方面与 30B 模型不相上下,速度快约 15 倍。Phi-3 small (7B) 在语言理解、常识推理和代码生成方面达到了与 70B 同代模型相当的水平。NVIDIA Nemotron-H 系列 (2/4.8/9B) 的混合 Mamba-Transformer 模型在指令遵循和代码生成精度上可与 30B 密集型 LLMs 媲美,而推理 FLOPs 仅为其一个量级的分数。
- 通过推理时期的增强技术,如自洽性(self-consistency)、验证器反馈(verifier feedback)或工具增强(tool augmentation),SLMs 的推理能力可以进一步提升。例如,Toolformer (6.7B) 通过 API 使用可超越 GPT-3 (175B);1-3B 模型通过结构化推理可在数学问题上与 30B+ LLMs 匹敌。
- 这表明,在现代训练、Prompt 和代理增强技术下,能力约束并非源于参数数量,而是源于具体的任务需求。
- SLM 的能力提升(论点 A1):过去几年,SLMs 的能力显著提升。尽管语言模型缩放定律依然成立,但模型大小与能力之间的曲线变得越来越陡峭,意味着新型 SLMs 的能力已非常接近甚至超越了之前的大型模型。
-
经济性与效率 (V3):
- SLM 的经济性(论点 A2):SLMs 在成本效率、适应性和部署灵活性方面具有显著优势。
- 推理效率:服务一个 7B 的 SLM 比服务一个 70-175B 的 LLM 便宜 10-30 倍(在延迟、能耗和 FLOPs 方面)。这意味着可以实现大规模实时代理响应。例如,NVIDIA Dynamo 等推理操作系统已明确支持云端和边缘部署中的高吞吐、低延迟 SLM 推理。
- 微调敏捷性:SLMs 的参数高效(如 LoRA \cite{30} 和 DoRA \cite{40})和全参数微调仅需数小时 GPU 时间,使得行为的添加、修复或专业化可在夜间完成,而非数周。
- 边缘部署:ChatRTX \cite{55} 等设备端推理系统展示了 SLMs 在消费级 GPU 上的本地执行能力,实现了实时、离线且具有更强数据控制的代理推理。
- 参数利用率:LLMs 虽然参数庞大,但大部分信号通过这些系统时是稀疏的,单次输入仅激活一小部分参数。而 SLMs 的这种行为似乎更为缓和,这表明 SLMs 可能通过更少比例的参数对推理成本做出贡献而对输出没有实质性影响,从而从根本上更高效。
- 模块化系统设计:将代理智能“乐高化”——通过添加小型、专业化的专家模型进行扩展,而非扩展单一的巨型模型——可以构建更便宜、更易调试、更易部署且更符合真实世界代理操作多样性的系统。
- SLM 的经济性(论点 A2):SLMs 在成本效率、适应性和部署灵活性方面具有显著优势。
-
操作适应性与灵活性 (V2):
- SLM 的操作灵活性(论点 A3):由于其小尺寸和较低的预训练与微调成本,SLMs 在代理系统中具有更大的操作灵活性。
- 可以更经济、更实用地训练、适应和部署多个专业化专家模型,以应对不同的代理例程。这种效率实现了快速迭代和适应,以满足不断变化的用户需求。
- 促进代理的民主化:更多个人和组织能够参与语言模型开发,从而使代理群体代表更多元化的视角和社会需求,减少系统性偏见,鼓励竞争和创新。
- 代理应用对语言模型功能的约束(论点 A4):AI 代理本质上是一个高度受指令和外部编排的语言模型网关。通用的 LLM 虽然强大,但在代理系统中,其通过精心编写的 Prompt 和上下文管理,被限制在极小的技能范围内。因此,针对特定 Prompt 适当微调的 SLM 足以胜任,并带来更高的效率和灵活性。
- 代理交互需要严格的行为对齐(论点 A5):典型的 AI 代理与代码频繁交互,无论是通过语言模型工具调用还是返回待解析的输出。生成的工具调用和输出必须符合工具参数的顺序、类型和性质以及调用语言模型的代码的严格格式要求。SLM 可以通过低成本的后训练或额外微调来强制采用单一格式,从而优于通用 LLM。
- 代理系统的异构性(论点 A6):代理系统天然支持选择不同模型进行操作。一个语言模型本身可以作为另一个语言模型调用的工具。代理代码在调用语言模型时,原则上可以选择任何语言模型。这种异构性为引入 SLMs 提供了自然途径,例如,根代理可以使用 LLM,而从属语言模型可以使用 SLM。
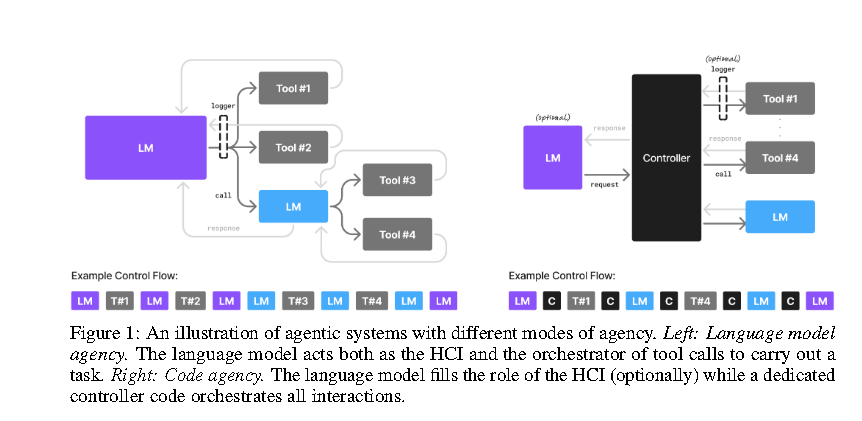
- 代理交互是未来改进的数据来源(论点 A7):代理过程中的工具和语言模型调用,伴随着聚焦于窄功能的 Prompt,本身就是未来改进的天然数据来源。通过在工具/模型调用接口处设置监听器(logger in Figure 1),可以收集专业化指令数据,用于未来微调专家 SLM,从而降低后续调用的成本。
- SLM 的操作灵活性(论点 A3):由于其小尺寸和较低的预训练与微调成本,SLMs 在代理系统中具有更大的操作灵活性。
反驳替代观点
论文也讨论并反驳了一些替代观点:
- LLM 通用模型在通用语言理解上始终有优势(AV1):论文反驳称,主流缩放定律研究假设模型架构保持不变,而 SLM 的最新工作表明不同模型尺寸应考虑不同架构。此外,SLMs 的灵活性允许为特定任务进行微调,且推理时的计算扩展(test-time compute scaling)更为经济,从而达到所需的可靠性水平。对于“语义中枢”的说法,论文认为高级代理系统旨在将复杂问题分解为简单的子任务,此时任何通用的抽象理解效用不大。
- LLM 推理因集中化而更便宜(AV2):论文承认规模经济的挑战,但指出推理调度和大型推理系统模块化的最新进展(如 NVIDIA Dynamo \cite{21})提供了前所未有的灵活性,并且推理基础设施的设置成本呈持续下降趋势。
SLM 普及的障碍与解决方案
论文还分析了 SLM 普及的障碍:
- B1 集中式 LLM 推理基础设施的巨额前期投资:行业已在此方面投入大量资本和工具。
- B2 SLM 训练、设计和评估中通用基准的使用:许多 SLM 研发工作仍沿袭 LLM 设计思路,关注通用基准,而非代理实用性。
- B3 缺乏公众认知度:SLMs 缺乏 LLMs 那样的市场营销和媒体关注。
论文认为这些障碍是实际操作层面的,而非 SLM 技术本身的根本缺陷,且随着技术进步和经济效益的显现,这些障碍有望被克服。
LLM 到 SLM 的代理转换算法
最后,论文提出了一个 LLM 到 SLM 的代理转换算法,包括:
- 安全收集使用数据(S1):记录非 HCI 代理调用,捕捉输入 Prompt、输出响应、工具调用内容和延迟指标。
- 数据整理和过滤(S2):收集足够数据后,移除敏感信息。
- 任务聚类(S3):对收集到的 Prompt 和代理动作进行无监督聚类,以识别重复模式,定义 SLM 专业化的候选任务。
- SLM 选择(S4):为每个识别出的任务选择一个或多个 SLM 候选模型,依据其能力、性能、许可和部署足迹。
- 专业 SLM 微调(S5):为每个任务和选定的 SLM 候选模型准备任务特定数据集,并进行微调(可使用 PEFT 技术如 LoRA \cite{31} 或 QLoRA \cite{17})。有时也可考虑知识蒸馏。
- 迭代和优化(S6):定期用新数据重新训练 SLMs 和路由器模型,形成持续改进循环。
论文最后呼吁业界对 SLMs 在代理 AI 中的作用进行更广泛的讨论和批判性评估,以期降低 AI 部署成本并促进可持续发展。