JVM讲解
一、JVM所处的位置
JVM是JRE中的一个组件。它是运行在操作系统结构之上的。然后所有的Java程序都会运行在JVM上。
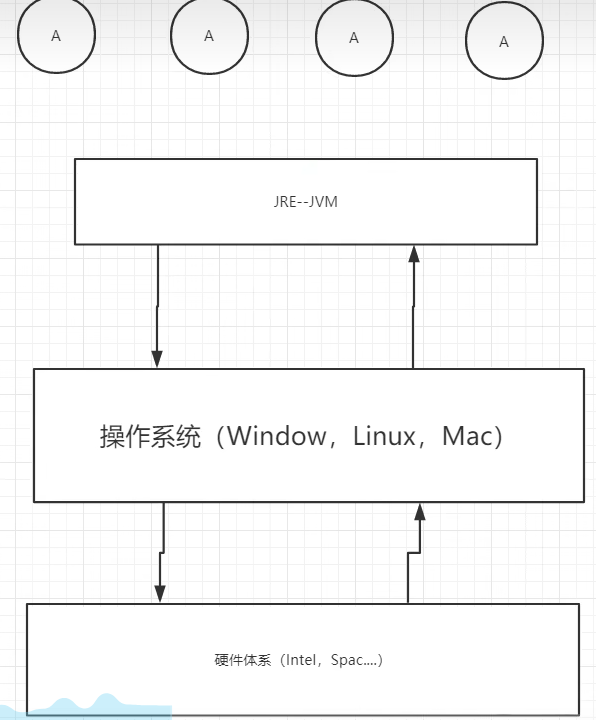
二、JVM的体系结构
在整个Java程序的执行过程中,java文件需要先进行编译,编译成.class文件之后再通过类加载器加载到数据区去执行。JVM就会开辟一片运行时的数据区,里面有方法区、Java栈、本地方法栈、Java堆、程序计数器等。
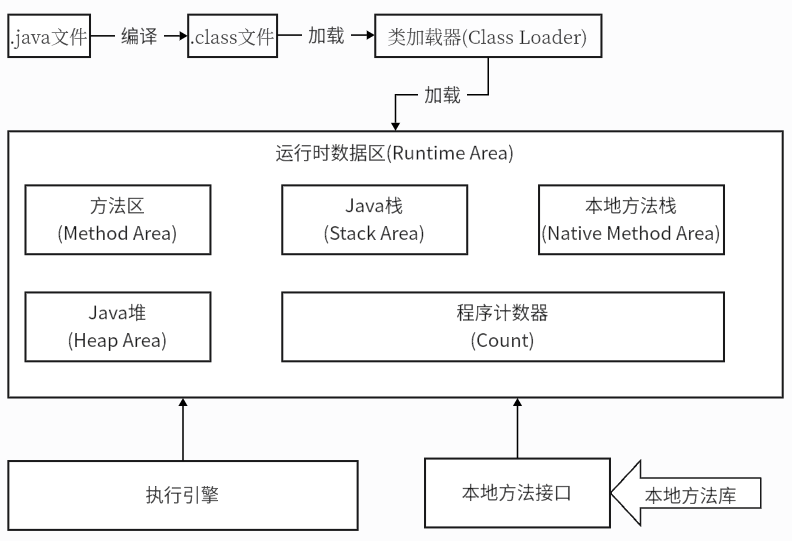
在JVM中,Java栈、本地方法栈、程序计数器这些地方都是没有垃圾存在的。能存在垃圾的地方就是方法区(方法区就是特殊的堆)和Java堆所在的地方。所以99%的JVM调优其实都是对于方法区和Java堆的调优。更为详细的图片如下:
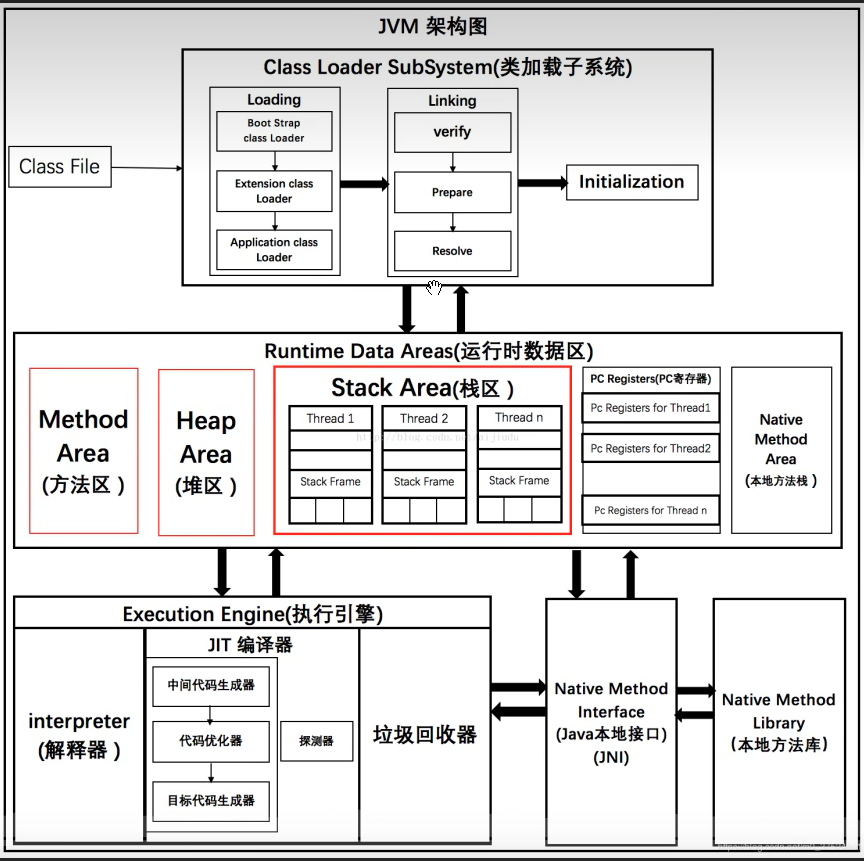
三、类加载器与双亲委派机制
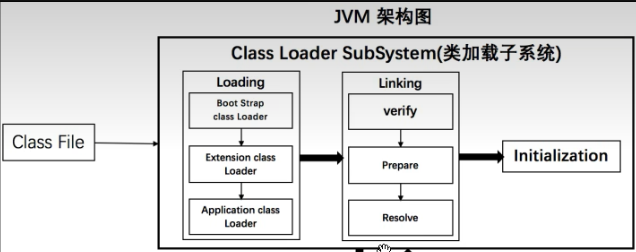
对于代码中要加载的类,或者说要进行实例化的类。提交过来的时候是先交给Applicatiion Class Loader(应用程序类加载器),但是并不一定是由这一个加载器来进行类的加载的。因为这里涉及一个双亲委派机制,就是应用程序加载器会先层层向上找,先找到他的父类加载器--扩展类加载器(Extention Class Loader),然后扩展类加载器再找他的父类加载器--根加载器(Root Class Loader),然后由根加载器去找它是否有这个类,如果他有就由他来加载这个类,如果没有就向下找扩展类加载器,看扩展类加载器中是否有这个类,如果还没有继续继续向下,最终才是由应用程序类加载器来进行类的加载的。
问题:为什么不直接由应用程序类加载器进行类的加载呢?而是先经过双亲委派机制之后才对类进行加载呢?
1、可以避免重复加载类的问题。不同的应用程序类加载器即使加载的是相同的类,在JVM虚拟机中也会被视作为不同的类。尤其是对这些程序可以共用的类(公共类如:java.lang.Object),如果由两个应用程序类加载器进行加载,就会在虚拟机上存在两个不同的类。
2、可以避免安全性问题:如果一个恶意类加载器加载了一个伪造的java.lang.String类,很可能会导致程序的运行过程被篡改,从而造成安全问题。所以核心的类都要由根类加载器进行加载,避免出现认为篡改加载类的问题。
3、保证类的加载层次清晰:Java类加载器形成了一个层次架构,启动类加载器加载核心库,扩展类加载器加载扩展库,应用程序类加载器加载应用程序的类。双亲委派机制保证了类加载的层次分明。
四、沙箱安全机制
Java的安全模型核心就是沙箱机制。沙箱的功能是限制程序的运行范围,将不同的程序限制在虚拟机(JVM)的特定范围中运行,只能使用这个范围中规定的系统资源(包括CPU、内存、文件系统、网络等)。
Java的执行程序分为本地代码和远程代码两种。在初始的Java版本中,本地代码可以访问本地的一切资源。远程代码一定要通过沙箱机制来制定其安全策略,不能任由远程代码来访问自己本地的系统资源。但是在随着Java版本的升级,允许远程代码可以有更多的权限来访问系统资源,所以安全机制做过很多次的升级,现在的版本就是不论本地代码或是远程代码都可以使用沙箱机制然后去设定安全策略。
五、Native关键字
凡是带了Native关键字的,都说明是Java的作用范围达不到了,也就是说用这个关键字的方法的执行都不是执行的Java库中的方法,而是其他的C、C++的库。使用了Native关键字的方法会进入本地方法栈,本地方法栈的方法会去调用本地方法接口(Java Native Interface),通过该接口去调用对应的方法库中的方法。
出现这个Native关键字的原因是在Java诞生之处,C、C++盛行,Java语言为了立足,必须要能够兼容C、C++语言的使用。因此他就在JVM中开辟了一个本地方法栈(Native Method Stack),用于专门的存储要执行的其他语言的库方法的地址。但是随着计算机语言的不断发展,Java的使用越来越多,现在其实已经很少见使用Native来调用其他语言库的方法了。
(Native涉及了JVM组件中的本地方法栈、本地方法接口、本地方法库)
六、程序寄存器
每个线程都有一个程序计数器,这是线程私有的。程序计数器中的内容就是一个指针,指向即将要执行的指令的地址。
七、方法区
方法区中的数据被所有的线程共享。静态变量(static)、常量(final)、类信息(构造方法、接口定义)、运行时的常量池等都是存在方法区中的。
八、Java栈
Java栈的原理很简单:“先进后出”。
可在栈中存储的数据有:
1、局部变量。包括方法的参数和方法体中定义的变量。
2、对象的引用。存储的是对应的地址值而不是对象本身值。
3、操作数和中间结果。等等
九、Java堆
一个JVM中只有一个堆内存,堆内存的大小是可以调节的。在之前,堆内存从大方面包含了三个方面:新生区、养老区、永久区。但是随着堆内存的发展,永久区已经变成了“元空间”,但是其实元空间所占的内存并没有算在JVM占用的内存中的,而是算在了占用的是本地内存空间。但是我们在讨论堆内存区的时候依然将其和JVM中的内存区一块讨论。所以现在的内存区总体上分为了三个部分:新生区、养老区、元空间。其中新生区会再次被划分为伊甸园区、幸存区0区、幸存区1区。整体过程就是将数据层层上移,在清理堆内存时,如果数据还有用,就会层层将数据上移,从伊甸园区移至幸存区0区、幸存区1区、再向上至养老区、元空间。在伊甸园区所占用的空间满的时候,会调用一次轻GC,然后将不用的数据清理掉,依然在使用的上移至幸存区中。然后在养老区内存也满的时候会调用重GC进行垃圾回收。当重GC都无法清理出内存给进程使用的时候就会报OOM错误了,也就是内存溢出。
另外还需要注意,方法区是特殊的堆,它其实是存在于元空间中的。
十、垃圾回收(GC)
垃圾回收(GC)分为两类:轻GC和重GC,作用的内存分区是:伊甸园区、幸存者0区、幸存者1区(前三又统称为新生代)、养老分区(养老代)。这几个区用的GC类型也是不一样的,一般来说新生代的分区用的是轻GC,养老代的分区用的是重GC。
GC算法有:引用计数法、标记清除法、标记压缩法、复制算法。
1、引用计数法
为每一个对象都进行计数,每用一次这个对象就会增加一次计数。当内存满了要进行垃圾回收时,选择计数最少得对象进行清除。
2、复制算法
复制算法就是将内存空间按容量分为两块。当其中一块内存用完的时候,将其中还存活着的对象复制到另外一块上面,然后使用过的这一块内存清理掉,下次使用那一半块的内存。
3、标记-清除算法
该算法分为了标记和清除两个阶段。标记阶段就是把所有的活动对象都加上标记的过程;清除阶段就是将没有做上标记的对象回收的过程。
4、标记-压缩算法
标记-压缩算是针对于标记-清除算法的一个改进吧,标记-清除算法在清除完之后会留下很多的内存碎片。而标记-压缩算法就是针对这种情况,对内存对象进行一个扫描然后在将其往一片区域聚合,从而较少内存碎片的出现。