【学习】Linux 内核中的 cgroup freezer 子系统
学习文档:进程冻结技术:深入探究 Linux 内核中的 cgroup freezer 子系统 - 魅族内核团队,魅族内核团队很流弊啊。或者说做过内核冻结的大佬都很流弊。现在还在大厂的且做过内核冻结的大佬,听说年薪100w+是很正常的。也说明内核专家确实是市场稀缺高端人才,真的特别佩服哈。
一、背景介绍
cgroup 最初由 Google 工程师 Paul Menage 和 Rohit Seth 在 2006 年提出,是一种细粒度资源控制的Linux内核机制。于 2007 年合并到 Linux 内核主线中。然而 Google 原生系统直到 Android 11 或更高版本上才支持 CACHE 应用的 CPU 冻结功能。当应用切换到后台并且没有其他活动时,系统会在一定时间内通过状态判断,将进程 ID 迁移到冻结的 cgroup 节点上,实现冻结 CACHE 应用。这项功能可以减少活跃缓存应用在后台存在时所消耗的 CPU 资源,从而达到节电的目的。当应用再次切换到前台时,系统会将该应用的进程解冻,以实现快速启动。
对于后台进程冻结,有两套方案,一是 cgroup freezer,二是内核信号 signal SIGSTOP 和 SIGCONT,国内很多手机厂商其实是早于 Android 做进程冻结方案的。而使用 cgroup freezer 方案更成熟更完善,接入后其实仅仅第一步,还有 binder 的 BINDER_FREEZE 冻结,framework层还有很多需要特殊场景,如后台下载、应用中使用桌面小组件、正在播放音频等等。
cgroup中的Freezer子系统可以用来暂停或恢复控制组中的进程,主要作用如下:
1.暂停进程:冻结的进程会被暂停,其所有线程的执行将被停止,包括应用程序的主线程以及任何后台线程。
2.资源释放:冻结进程占用的资源,例如CPU、内存资源会被释放。这些资源将被系统重新分配给其他需要执行的进程或系统服务
3.功耗节省:被冻结的进程不会在后台运行,因此系统在休眠期间不会被频繁唤醒,可以节省设备的电池消耗。
4.快速恢复:冻结的进程可以快速恢复其执行状态。当需要重新激活进程时,系统可以迅速将其恢复到之前的运行状态,而无需重新启动或加载应用程序。 冻结进程并不会终止进程的执行或销毁应用程序。冻结只是暂时挂起进程,以优化资源使用。一旦系统需要再次运行该进程(例如用户重新打开应用程序或系统需要其提供服务),它会被解冻并恢复运行。
进程冻结是Android系统中重要的资源管理策略,也是目前主流手机厂商常用的后台管控策略之一,它有助于提高系统性能,同时最大限度地节省设备的资源和电量消耗。下面我们针对 cgroup freezer 的底层实现,看 Linux 内核是如何支撑 Android 的墓碑机制功能的。
二、cgroup相关组件
1. 检查cgroup 2 文件系统是否已经加载
cat /proc/filesystems | grep cgroup2

2. 挂载
可以用如下命令挂载cgroup文件系统到d目录
XPLORE_1_WT:/ # mount -t cgroup2 none dXPLORE_1_WT:/ # mount | grep cgroupnone on /dev/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)none on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime)none on /dev/cpuctl type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)none on /dev/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset,noprefix,release_agent=/sbin/cpuset_release_agent)none on /dev/memcg type cgroup (rw,nosuid,nodev,noexec,relatime,memory)none on /sys/kernel/debug type cgroup2 (rw,relatime)
系统启动后,默认system已经将cgroup v2的文件系统挂载到/sys/fs/cgroup下

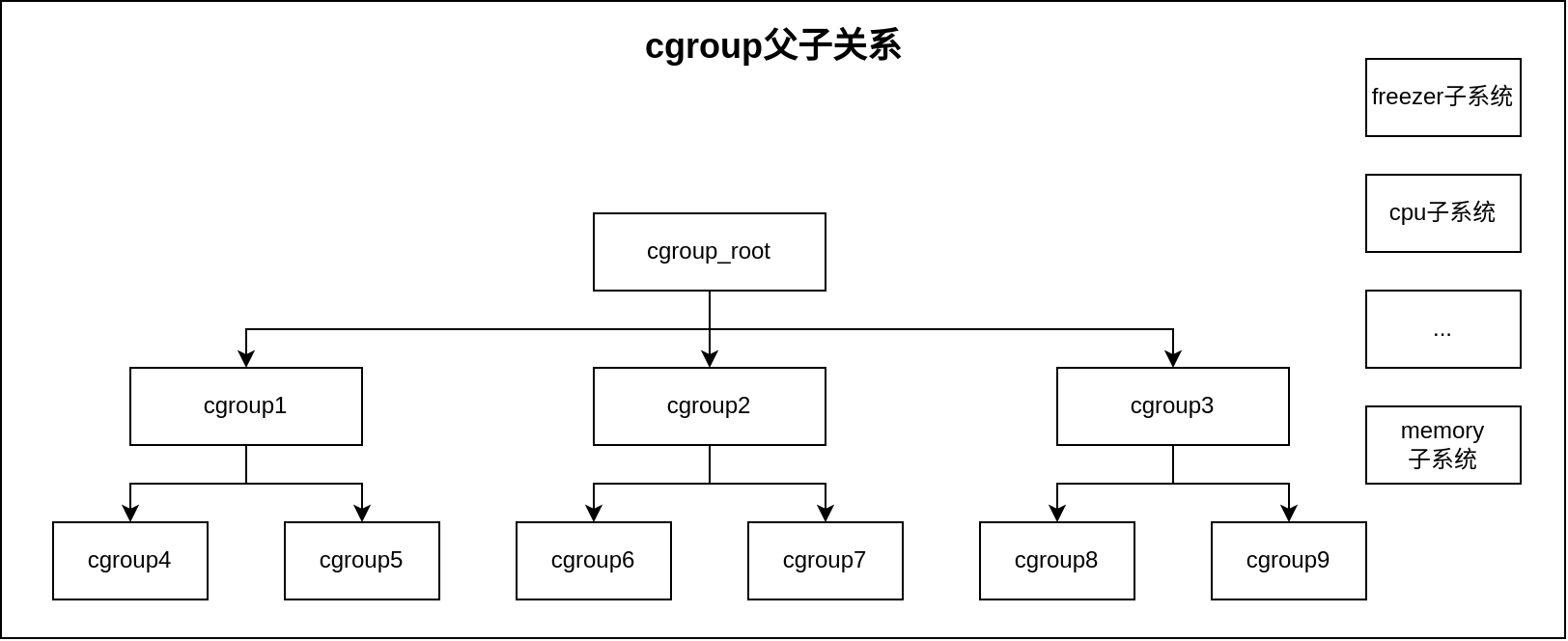
3. cgroup的父子关系
初始状态下只有一个root cgroup根节点,所有进程都归属于这个cgroup,可以使用mkdir指令创建新的子cgroup。cpu、memory、freezer等控制资源是自顶向下(top-down)分配的,只有当一个 cgroup 从 parent 获得了某种资源,它才可以继续向下分发。这意味着所有非根”cgroup.subtree_control”文件只能包含在父级的”cgroup.subtree_control”文件中启用的控制器。只有在父级cgroup中启用了控制器时,子级cgroup才能启用控制器,如果一个或多个子级已经启用了某个控制器,则不能禁用该控制器。子孙cgroup数量有限,内核中使用cgroup.max.depth和cgroup.max.descendants来限制,关系图如下:
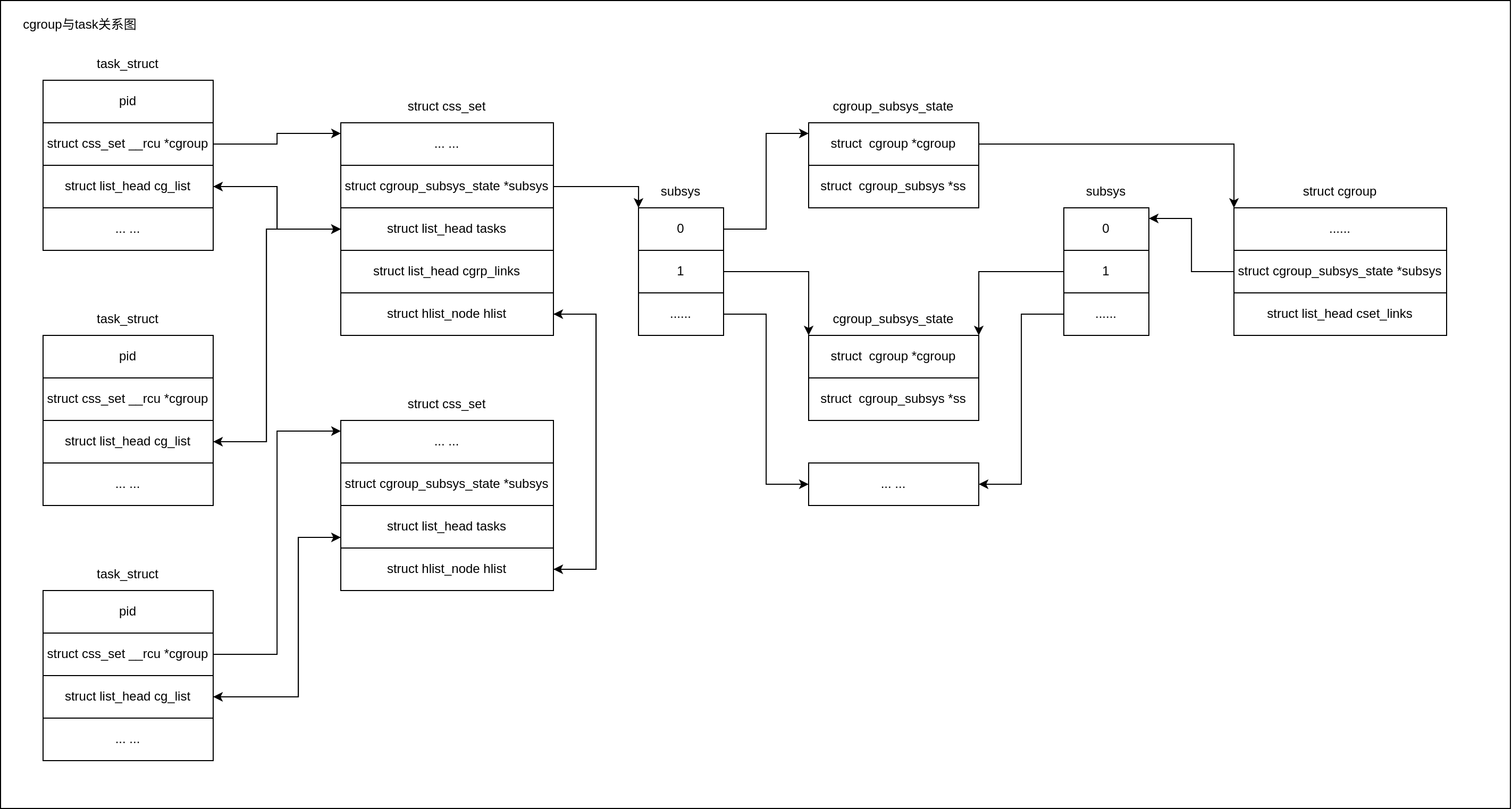
4. 进程与cgroup的关系
cgroup.procs是cgroup与task进程绑定的接口,当读取该文件时,它会逐行列出属于该cgroup的所有进程的PID。将进程的PID写入到cgroup.procs中即可将目标PID进程绑定到该cgroup。进程与cgroup是多对多的关系,一个进程可以绑定到多个cgroup中,一个cgroup可以被多个进程绑定。在kernel中进程的数据结构task_struct与cgroup有关的是如下cgroups、cg_list两个成员:
kernel-6.6/include/linux/sched.h
#ifdef CONFIG_CGROUPS // 条件编译:仅在启用内核cgroup功能时包含此部分/** Control Group info protected by css_set_lock:* 指向进程所属的cgroup子系统状态集合(css_set),* 通过RCU(Read-Copy-Update)机制保护,确保多线程安全读取。* css_set包含进程关联的所有子系统的资源控制状态(如CPU、内存等)。*/struct css_set __rcu *cgroups;/** cg_list protected by css_set_lock and tsk->alloc_lock:* 链表节点,用于将当前进程链接到所属css_set的进程列表中。* 同一css_set的所有进程通过cg_list串联,形成环形链表。* 需同时持有css_set_lock(保护cgroup全局状态)和alloc_lock(保护进程描述符)才能修改。*/struct list_head cg_list;#endif
cgroups、cg_list成员涉及到了css_set、cgroup_subsys_state、cgroup等几个关键数据结构,下面来分析这几个数据结构
4.1 css_set数据结构
task_struct中的*cgroups指针指向了一个css_set结构,而css_set是用来存储与进程相关的cgroups信息,定义如下:
include/linux/cgroup-defs.h
/** css_set 是内核中用于管理进程与 cgroup 关联的核心数据结构。* 它通过集中存储一组 cgroup_subsys_state 对象,优化了进程的资源控制效率:* 1. 节省 task_struct 空间(避免每个任务重复存储子系统状态)* 2. 加速 fork()/exit() 操作(通过引用计数批量操作整个 cgroup 集合)*/struct css_set {/** 子系统状态数组:存储当前 css_set 关联的所有子系统的状态对象。* 初始化后不可变(除 init_css_set 在启动时注册子系统外)。* 每个数组元素对应一个子系统(如 cpu_cgroup、memory_cgroup 等)。*/struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];/** 引用计数:跟踪有多少个进程或任务组使用此 css_set。* 通过 refcount_inc()/refcount_dec() 原子操作保证线程安全。*/refcount_t refcount;/** 域 cset 指针:用于支持 cgroup v2 的线程模式(threaded mode)。* - 如果是域 cgroup,指向自身;* - 如果是线程化 cgroup,指向最近的域祖先的 css_set。* 通过 dom_cset 可以访问域级别的资源统计和控制。*/struct css_set *dom_cset;/** 默认关联的 cgroup:表示此 css_set 所属的顶层 cgroup。* 在非线程模式下,dfl_cgrp 与 subsys[] 中的 cgroup 一致;* 在线程模式下,可能指向不同的层级。*/struct cgroup *dfl_cgrp;/** 内部任务计数器:记录使用此 css_set 的进程数量。* 由 css_set_lock 保护,避免并发修改导致计数错误。*/int nr_tasks;/** 任务链表:组织所有使用此 css_set 的进程。* - tasks: 正常状态的任务列表* - mg_tasks: 正在迁移的任务列表(进出此 cset)* - dying_tasks: 正在退出的任务列表* 注意:mg_tasks 和 dying_tasks 在迁移或退出期间由 cgroup_mutex 保护。*/struct list_head tasks;struct list_head mg_tasks;struct list_head dying_tasks;/** 迭代器链表:记录所有正在遍历此 css_set 的 css_task_iter 对象。* 用于安全地处理并发迭代操作。*/struct list_head task_iters;/** 扩展 cset 节点:用于默认层级(cgroup v2)的祖先关联。* 当 subsys[ssid] 指向祖先 cgroup 的 css 时,通过 e_cset_node 链表* 可以遍历所有关联到特定 cgroup 的 css_set。*/struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];/** 线程化 cset 链表:记录所有 dom_cset 指向此 css_set 的线程化 csets。* threaded_csets_node 用于将自身链接到父 css_set 的 threaded_csets 链表。*/struct list_head threaded_csets;struct list_head threaded_csets_node;/** 哈希表节点:用于将 css_set 链接到全局哈希表中(通过 css_set_table)。* 由 css_set_lock 保护,用于快速查找和去重。*/struct hlist_node hlist;/** cgroup 链接链表:通过 cgrp_cset_link 结构记录所有引用此 css_set 的 cgroup。* 由 css_set_lock 保护,用于维护 cgroup 与 css_set 的多对多关系。*/struct list_head cgrp_links;/** 迁移相关链表节点:用于处理 cgroup 迁移操作。* - mg_src_preload_node: 作为迁移源时的预加载链表* - mg_dst_preload_node: 作为迁移目标时的预加载链表* - mg_node: 通用迁移链表* 由 cgroup_mutex 保护,确保迁移操作的原子性。*/struct list_head mg_src_preload_node;struct list_head mg_dst_preload_node;struct list_head mg_node;/** 迁移上下文:当此 css_set 作为迁移源时,以下字段生效:* - mg_src_cgrp: 源 cgroup* - mg_dst_cgrp: 目标 cgroup* - mg_dst_cset: 目标 css_set* 由 cgroup_mutex 保护,避免并发迁移导致状态不一致。*/struct cgroup *mg_src_cgrp;struct cgroup *mg_dst_cgrp;struct css_set *mg_dst_cset;/** 死亡标记:表示此 css_set 是否已被标记为死亡并正在释放资源。* 迁移操作会忽略 dead 为 true 的 css_set。*/bool dead;/** RCU 回调头:用于安全地延迟释放 css_set 内存。* 通过 call_rcu() 机制确保无锁读操作不会访问已释放的内存。*/struct rcu_head rcu_head;};
多对多关系管理:
一个 css_set可以被多个进程共享(若它们的 cgroup 配置完全相同)
一个 cgroup 可以关联多个 css_set(通过 cgrp_links链表维护)
4.2 cgroup_subsys_state数据结构
每个子系统都有属于自己的资源控制统计信息结构,而且每个cgroup中都绑定一个这样的结构,这种资源控制统计信息结构就是通过 cgroup_subsys_state 结构体实现的,其定义如下:
/** 系统维护的每个子系统/每个cgroup的状态。这是控制器(子系统)操作的基础结构单元。* 标记为 "PI:" 的字段是公共且不可变的,可以直接访问而无需同步。*/struct cgroup_subsys_state {/* PI: 当前css关联的cgroup,表示此状态属于哪个cgroup */struct cgroup *cgroup;/* PI: 当前css关联的子系统,指向子系统描述符(如cpu、memory等) */struct cgroup_subsys *ss;/** 引用计数器:通过css_[try]get()增加引用,css_put()减少引用。* 使用percpu_ref实现高性能的原子操作。*/struct percpu_ref refcnt;/** 兄弟节点链表:通过sibling链接到父cgroup的children链表,* children链接当前css的子节点(形成树状结构)。*/struct list_head sibling;struct list_head children;/** 统计刷新节点:链接到cgrp->rstat_css_list,* 用于资源统计的批量更新(如内存使用量统计)。*/struct list_head rstat_css_node;/** PI: 子系统唯一ID。0未使用,根节点始终为1。* 可通过css_from_id()查找对应的css。*/int id;/* 标志位,用于表示css的状态(如CSS_ROOT表示根节点) */unsigned int flags;/** 单调递增的唯一序列号,用于对所有css定义全局顺序。* 保证所有->children链表按->serial_nr升序排列,* 支持迭代的中断和恢复。*/u64 serial_nr;/** 在线计数器:由当前css及其子css递增。* 确保父节点不会在子节点之前被下线(offline)。*/atomic_t online_cnt;/** 销毁工作项:当引用计数归零时,* 通过工作队列异步释放资源,避免阻塞上下文。*/struct work_struct destroy_work;struct rcu_work destroy_rwork; /* RCU保护的销毁工作项 *//** PI: 父css指针。放置在结构体末尾以提高缓存局部性,* 与包含此结构的子类字段相邻(如mem_cgroup等)。*/struct cgroup_subsys_state *parent;};
典型使用场景:
进程迁移:当进程在 cgroup 间移动时,通过 css_get()/css_put()更新引用计数。
资源统计:内存子系统通过 rstat_css_node汇总各 cgroup 的内存使用量
4.3 cgroup数据结构
cgroup主要用来控制进程组对各种资源的使用。
典型应用场景
容器资源限制:通过 subsys[]中的内存/CPU 子系统状态实现 Docker 容器资源配额。
进程冻结:freezer字段管理进程组冻结状态,用于容器暂停/恢复
struct cgroup {/** 自引用css:当 ->ss 为 NULL 时指向当前 cgroup 自身。* 用于统一处理 cgroup 的通用操作(如资源统计)。*/struct cgroup_subsys_state self;/* 状态标志位,使用 unsigned long 类型以支持位操作(如设置/清除标记) */unsigned long flags;/** 当前 cgroup 在层级树中的深度:* - 根 cgroup 深度为 0,每向下一层深度加 1。* - 结合 ancestors[] 可快速判断 cgroup 的继承关系。*/int level;/* 允许的最大子树深度,防止层级过深导致性能问题 */int max_depth;/** 子树统计计数器(受 cgroup_mutex 和 css_set_lock 保护):* - nr_descendants: 存活的子 cgroup 数量* - nr_dying_descendants: 被删除但仍有引用的子 cgroup 数量* - max_descendants: 允许的最大子 cgroup 数量*/int nr_descendants;int nr_dying_descendants;int max_descendants;/** 任务分布统计:* - nr_populated_csets: 关联的 css_set 数量(>0 表示有任务)* - nr_populated_domain_children: 非空域子 cgroup 数量* - nr_populated_threaded_children: 非空线程化子 cgroup 数量* - nr_threaded_children: 存活的线程化子 cgroup 数量*/int nr_populated_csets;int nr_populated_domain_children;int nr_populated_threaded_children;int nr_threaded_children;/* 内核文件系统相关 */struct kernfs_node *kn; /* 对应 kernfs 节点 */struct cgroup_file procs_file; /* "cgroup.procs" 文件句柄 */struct cgroup_file events_file; /* "cgroup.events" 文件句柄 */struct cgroup_file psi_files[NR_PSI_RESOURCES]; /* 压力状态文件 *//** 子树控制位图(16位无符号整数):* - subtree_control: 用户配置的启用子系统* - subtree_ss_mask: 实际生效的子系统(可能包含隐式启用)* - old_*: 用于临时保存配置变更前的状态*/u16 subtree_control;u16 subtree_ss_mask;u16 old_subtree_control;u16 old_subtree_ss_mask;/** 子系统状态数组:* 每个槽位存储对应子系统的 cgroup_subsys_state 指针,* 使用 RCU 机制保护并发访问。*/struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];/* 指向所属的 cgroup 层级根 */struct cgroup_root *root;/** 关联的 css_set 链表:* 通过 cgrp_cset_link 结构链接所有包含此 cgroup 任务的 css_set,* 受 css_set_lock 保护。*/struct list_head cset_links;/** 扩展 css_set 链表:* 对于默认层级,当某些子系统被禁用时,任务可能指向祖先的 css。* 此数组记录所有通过此类方式引用当前 cgroup 的 css_set。*/struct list_head e_csets[CGROUP_SUBSYS_COUNT];/** 域 cgroup 指针:* - 非线程化模式下指向自身* - 线程化模式下指向最近的域祖先* 域级别的资源消耗(非任务专属)会统计到 dom_cgrp。*/struct cgroup *dom_cgrp;struct cgroup *old_dom_cgrp; /* 线程化启用时的临时存储 *//* 每 CPU 资源统计 */struct cgroup_rstat_cpu __percpu *rstat_cpu;struct list_head rstat_css_list; /* 需要统计的 css 链表 *//* 缓存行填充,避免伪共享 */CACHELINE_PADDING(_pad_);/** 资源统计刷新链表:* 单向链表,供 cgroup_rstat_flush_locked() 批量更新统计,* 受 cgroup_rstat_lock 保护。*/struct cgroup *rstat_flush_next;/* 基础资源统计(CPU/内存等) */struct cgroup_base_stat last_bstat; /* 上次统计值 */struct cgroup_base_stat bstat; /* 当前统计值 */struct prev_cputime prev_cputime; /* CPU 时间记录 *//* PID 列表(按命名空间隔离,按需创建) */struct list_head pidlists;struct mutex pidlist_mutex; /* PID 列表操作锁 *//* 等待离线队列(用于 css 下线同步) */wait_queue_head_t offline_waitq;/* 释放代理工作项(异步执行 cgroup 清理) */struct work_struct release_agent_work;/* 压力阻塞统计 */struct psi_group *psi;/* eBPF 程序挂钩 */struct cgroup_bpf bpf;/* 阻塞计数(用于判断 cgroup 是否发生 I/O 阻塞) */atomic_t congestion_count;/* freezer 状态(用于进程冻结/解冻) */struct cgroup_freezer_state freezer;#ifdef CONFIG_BPF_SYSCALL/* eBPF 本地存储 */struct bpf_local_storage __rcu *bpf_cgrp_storage;#endif/* Android 向后兼容保留字段 */ANDROID_BACKPORT_RESERVE(1);/* 祖先数组(包含自身,动态分配) */struct cgroup *ancestors[];};
从task到其所属的cgroup之间是没有直接指针相连接的,但是task可以通过一个媒介来获取其所属的cgroup,这个媒介就是css_set和cgroup_subsys_state。通过task_struct -> cgroups -> subsys[ssid] ->cgroup即可访问到管理对应子系统的cgroup。之所以这么设计是因为获取子系统状态的操作预计会频繁发生,而且是在性能关键代码中。然而需要一个task实际的cgroup来执行的操作(尤其是task在cgroups之间迁移的操作)则并没有那么常见。task_struct中的cg_list则是用来连接使用同一个css_set的task的链表,css_set通过tasks来遍历访问此链表。
通俗来说,可以把整个设计想象成一个“班级管理系统”,其中:
1.学生(task)和班级(cgroup)的关系
每个学生(进程)不会直接记住自己属于哪个班级(cgroup),而是通过一个“学生证”(css_set)来间接关联。学生证上记录了该学生在不同科目(子系统)的“科目成绩单”(cgroup_subsys_state),而每张成绩单会标明对应的班级(如数学班、英语班等)。这样,学生只要出示学生证,就能快速查到自己在各科的班级归属。
2.为什么这么设计?
•高频操作优化:学生每天要频繁查看自己的科目成绩(如CPU、内存使用情况),但很少转班(迁移cgroup)。通过学生证直接查成绩单(task->cgroups->subsys[ssid])比每次问班主任(直接查cgroup)更快。
•资源共享:多个学生可能共享同一套科目班级配置(如都参加数学A班和英语B班),他们的学生证(css_set)会通过cg_list串成链表,像班级花名册一样方便批量管理。
3.转班(迁移)的场景
当学生要转班时(比如从数学A班转到数学C班),需要更新学生证上的数学成绩单(修改subsys[ssid]指向新班级),同时从旧班级的花名册(cg_list)移除,并加入新班级的花名册。这类操作虽然复杂,但发生频率低,对性能影响小。
总结:
就像学生证既方便日常查成绩,又支持偶尔转班一样,css_set和cgroup_subsys_state的设计平衡了高频查询和低频迁移的需求,同时避免了每个进程直接维护大量cgroup指针的开销
5. freeze子系统使用
做一个小实验:把微信冻结的实验。先top下,找到微信的pid和uid,例如pid为5221,uid为10283

PID为5212的进程状态为R【ps -Ae | grep 5212】

/sys/fs/cgroup/uid_10283/pid_5212 # echo 1 > cgroup.freeze

这个时候PID为5212的进程已经被我们的cgroup进程组给冻结掉,可以查看进程状态已经从R 切换到S

观察上面的WCHAN可以看到冻结的进程是阻塞在内核的do_freezer_trap函数中 , do_freezer_trap是cgroup freezer中最核心的函数.
后台查看5212被冻结之后,对应的进程已经不在后台运行,CPU的整体loading也降低下来。
三、cgroup freezer子系统的实现
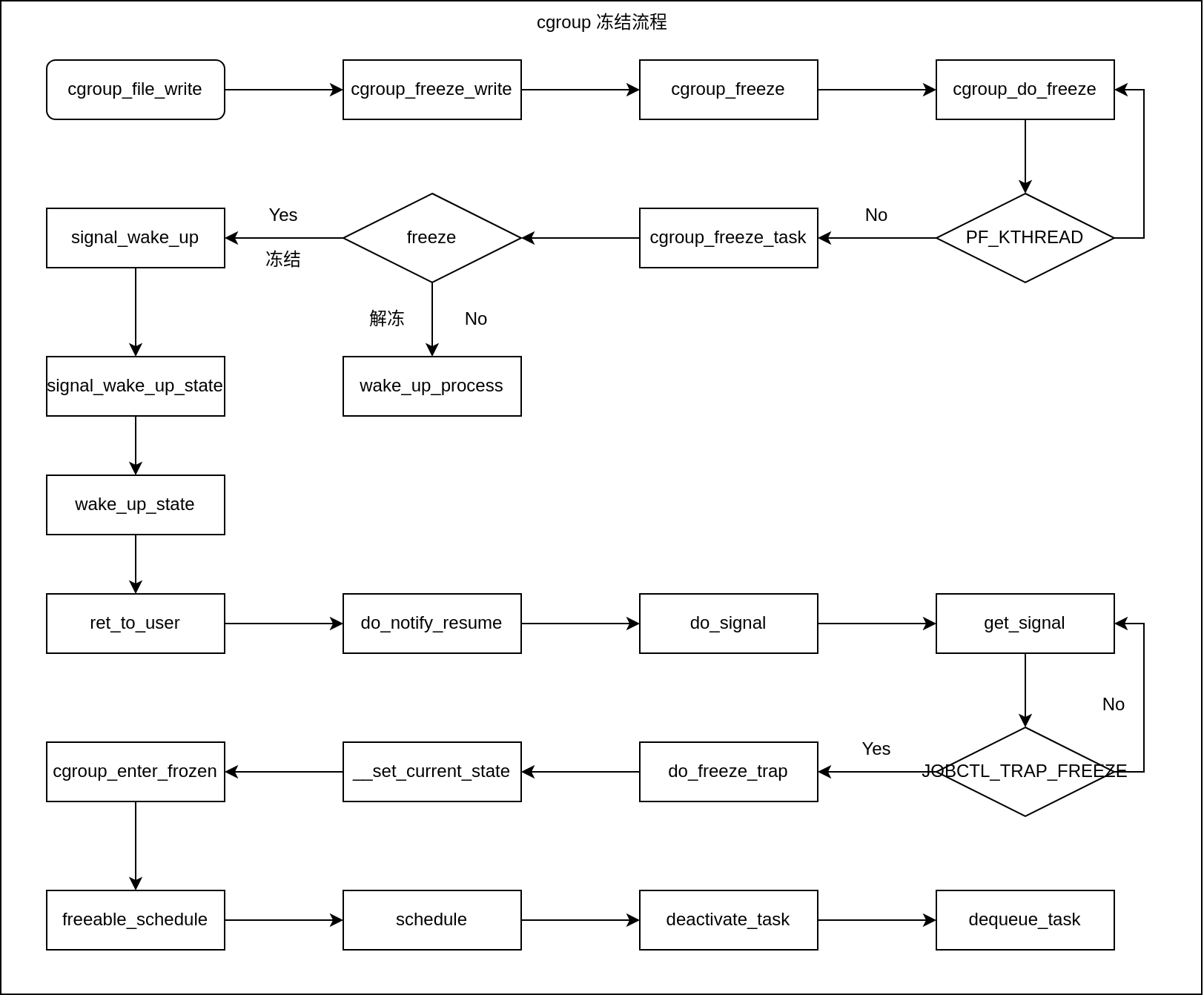
1. cgroup冻结整体流程
内核通过了一个比较巧妙的方式实现了冻结流程。它首先为该进程设置了一个信号pending标志TIF_SIGPENDING,但并不向该进程发送实际的信号,然后通过ipi唤醒该进程执行。由于ipi会进行进程内核的中断处理流程,当其处理完成后,会调用ret_to_user函数返回用户态,而该函数会调用信号处理函数检查是否有pending的中断需要处理,由于先前已经设置了信号的pending标志,因此会执行信号处理流程。在信号处理流程中检查进程冻结相关的全局变量是否设置,然后调用__set_current_state将task 设置为interrupt状态 将task 挂起,执行schedule() 让出cpu,进行上下文切换。
想象你是一个正在打游戏的玩家(用户进程),而游戏机是CPU。突然系统需要做一次大扫除(系统休眠/冻结),但直接关掉游戏机会导致存档损坏(内核死锁)。于是管理员(内核)用了以下巧妙方法:
1.设置提醒标志
管理员在你游戏手柄上悄悄贴了个"请暂停"的便利贴(设置TIF_SIGPENDING标志),但不会发出声音打扰你(不发送真实信号)。这时候你还在专注打游戏(内核态执行)。
2.温柔提醒
管理员轻拍你肩膀说"看看手柄"(通过IPI中断唤醒)。你暂停游戏去看手柄(中断处理流程),发现便利贴后决定先存档(准备返回用户态)。
3.安全暂停
在存档时(ret_to_user返回用户态前),系统检查便利贴并发现大扫除通知(冻结全局变量)。于是你主动:
•把游戏角色停在安全点(TASK_INTERRUPTIBLE状态)
•放下手柄(schedule()让出CPU)
•等大扫除结束再继续(冻结完成)
2. 设置freezer冻结与解冻
前面实验通过对cgroup目录cgroup.freeze值的修改,来完成了freezer对task限制的设置。将cgroup.freeze值置为1则该cgroup里的进程会全被freeze,置为0则会被unfreeze。这个小节来看看这个设置过程。当用户读写cgroup.freeze这个文件的时候,cgroup中调用的是cgroup_freeze_write函数,内核数据结构如下
kernel/cgroup/cgroup.c
/** cgroup 默认层级(dfl_cgrp)的核心接口文件定义* 这些文件出现在每个cgroup目录中,用于控制进程分组行为*/static struct cftype cgroup_base_files[] = {/** cgroup.procs 文件:* - 用于查看和修改属于该cgroup的进程* - 可被命名空间委托(CFTYPE_NS_DELEGATABLE)* - 关联到cgroup结构体中的procs_file字段* - 提供完整的进程管理功能:显示、遍历、迁移等*/{.name = "cgroup.procs",.flags = CFTYPE_NS_DELEGATABLE,.file_offset = offsetof(struct cgroup, procs_file),.release = cgroup_procs_release, // 文件释放时的清理函数.seq_start = cgroup_procs_start, // 开始遍历进程列表.seq_next = cgroup_procs_next, // 获取下一个进程.seq_show = cgroup_procs_show, // 显示当前进程PID.write = cgroup_procs_write, // 写入PID来迁移进程},/* 其他cgroup接口文件定义... *//** cgroup.freeze 文件:* - 用于冻结/解冻cgroup中的所有进程* - 不能在根cgroup使用(CFTYPE_NOT_ON_ROOT)* - 提供冻结状态查看和设置功能*/{.name = "cgroup.freeze",.flags = CFTYPE_NOT_ON_ROOT,.seq_show = cgroup_freeze_show, // 显示当前冻结状态.write = cgroup_freeze_write, // 写入1冻结/0解冻},/* 其他cgroup接口文件定义... */};
文件读写处理函数cgroup_freeze_write函数调用cgroup_freeze_task将cgroup中所有task的jobctl位掩码置位为JOBCTL_TRAP_FREEZE,然后将要冻结的task设置为TIF_SIGPENDIN状态,如果是解冻这里会将task中的jobctl位掩码JOBCTL_TRAP_FREEZE清除,然后执行wake_up_process将task唤醒。调用链路如下:
vfs_write|->kernfs_fop_write_iter|->cgroup_file_write|->cgroup_freeze_write|->cgroup_kn_lock_live //获得文件所在的目录的cgroup实体|->cgroup_freeze|->css_for_each_descendant_pre //循环体里对当前目录以及每个子孙目录所代表cgroup实体执行cgroup_do_freeze函数|->cgroup_do_freeze|->set_bit //将cgroup及子孙cgroup设为freeze状态|->cgroup_freeze_task|->signal_wake_up|->signal_wake_up_state|->wake_up_state|->try_to_wake_up|->kick_process //使进程陷入内核态,为返回用户态处理冻结信号做准备|->wake_up_process
这里分析几个关键的函数cgroup_freeze、cgroup_do_freeze、cgroup_freeze_task。cgroup_freeze_write会调用到cgroup_kn_lock_live获取要冻结目录的cgroup实体,然后再调到cgroup_freeze中将父cgroup的冻结状态传给各子孙cgroup, cgroup_freeze定义在kernel/cgroup/freezer.c中
/** Freeze or unfreeze the task by setting or clearing the JOBCTL_TRAP_FREEZE* jobctl bit.*/static void cgroup_freeze_task(struct task_struct *task, bool freeze){unsigned long flags;bool wake = true;/** 检查任务是否即将退出,避免对正在退出的任务进行操作* lock_task_sighand 会获取任务的 sighand 锁,防止并发修改信号处理结构*/if (!lock_task_sighand(task, &flags))return;/** 调用 vendor hook,允许厂商自定义是否唤醒任务* 主要用于 Android 等系统扩展冻结行为*/trace_android_vh_freeze_whether_wake(task, &wake);if (freeze) {/** 设置 JOBCTL_TRAP_FREEZE 标志位* 该标志会触发任务在返回用户态时进入冻结流程*/task->jobctl |= JOBCTL_TRAP_FREEZE;/** 唤醒任务处理冻结信号(若未被 vendor hook 禁用)* signal_wake_up 会设置 TIF_SIGPENDING 标志但不发送实际信号*/if (wake)signal_wake_up(task, false);} else {/* 清除冻结标志并唤醒任务 */task->jobctl &= ~JOBCTL_TRAP_FREEZE;if (wake)wake_up_process(task); // 直接唤醒任务解除冻结}/* 释放 sighand 锁 */unlock_task_sighand(task, &flags);}
cgroup_freeze中通过css_for_each_descendant_pre循环将父cgroup的freeze状态传递到各子孙cgroup中,父cgroup被freeze或者unfreeze,其目录下的子cgroup也会被freeze或者unfreeze,执行动作是在函数cgroup_do_freeze中,cgroup_do_freeze会循环遍历cgroup中的task执行cgroup_freeze_task函数做下一步的冻结/解冻操作。如果遇到内核线程则直接跳出该次循环。注意在信号的设计机制里内核线程不会收到信号,信号是针对用户线程或者进程的一种异步机制。所以在cgroup的冻结流程里没有内核线程的处理,但在suspend的冻结中有针对内核线程的处理,有兴趣的可以去看看。这里只讲cgroup中的冻结。cgroup_do_freeze实现如下:
/** Freeze or unfreeze all tasks in the given cgroup.* 冻结或解冻指定cgroup中的所有任务* @cgrp: 目标控制组* @freeze: true表示冻结,false表示解冻*/static void cgroup_do_freeze(struct cgroup *cgrp, bool freeze){struct css_task_iter it;struct task_struct *task;/* 确保调用者已持有cgroup_mutex锁 */lockdep_assert_held(&cgroup_mutex);/** 原子化更新cgroup的冻结标志位* CGRP_FREEZE标志用于跟踪整个cgroup树的冻结状态传播*/spin_lock_irq(&css_set_lock);if (freeze)set_bit(CGRP_FREEZE, &cgrp->flags); // 设置冻结标志elseclear_bit(CGRP_FREEZE, &cgrp->flags); // 清除冻结标志spin_unlock_irq(&css_set_lock);/* 记录冻结/解冻跟踪事件(用于调试) */if (freeze)TRACE_CGROUP_PATH(freeze, cgrp);elseTRACE_CGROUP_PATH(unfreeze, cgrp);/** 遍历cgroup中的所有任务* css_task_iter_start初始化迭代器,0表示从第一个任务开始*/css_task_iter_start(&cgrp->self, 0, &it);while ((task = css_task_iter_next(&it))) {/** 跳过内核线程(内核线程不支持冻结)* PF_KTHREAD标志标识内核线程*/if (task->flags & PF_KTHREAD)continue;/* 对每个用户态任务执行冻结/解冻操作 */cgroup_freeze_task(task, freeze);}css_task_iter_end(&it); // 释放迭代器资源/** 检查并更新cgroup的冻结状态:* 当所有后代cgroup都已冻结(nr_descendants == nr_frozen_descendants)时,* 调用cgroup_update_frozen更新当前cgroup的冻结状态*/spin_lock_irq(&css_set_lock);if (cgrp->nr_descendants == cgrp->freezer.nr_frozen_descendants)cgroup_update_frozen(cgrp); // 同步cgroup的冻结状态spin_unlock_irq(&css_set_lock);}
signal_wake_up会调用signal_wake_up_state先为进程设置TIF_SIGPENDING标志,表明该进程有延迟的信号要等待处理。然后再调用 wake_up_state()唤醒目标进程,如果目标进程在其他的CPU上运行,wake_up_state()将返回0,此时调用 kick_process()向该CPU发送一个处理器核间中断。当中断返回前时,直接调用do_notify_resume()处理该进程的信号。signal_wake_up_state函数实现如下:
/** Freeze or unfreeze the task by setting or clearing the JOBCTL_TRAP_FREEZE* jobctl bit.* 通过设置/清除JOBCTL_TRAP_FREEZE标志位来冻结或解冻任务* @task: 目标task_struct结构体指针* @freeze: true表示冻结,false表示解冻*/static void cgroup_freeze_task(struct task_struct *task, bool freeze){unsigned long flags;bool wake = true; // 默认需要唤醒任务处理冻结/解冻/** 如果任务正在退出(无法获取sighand锁),则放弃操作* lock_task_sighand会获取任务的信号处理锁,防止并发修改*/if (!lock_task_sighand(task, &flags))return;/** Android扩展点:允许厂商自定义是否唤醒任务* 例如后台下载/音频播放等场景可能需要特殊处理[1,6](@ref)*/trace_android_vh_freeze_whether_wake(task, &wake);if (freeze) {/** 设置冻结标志位,任务将在返回用户态时进入冻结状态* 采用延迟冻结机制避免内核态持锁时冻结导致的死锁[2](@ref)*/task->jobctl |= JOBCTL_TRAP_FREEZE;if (wake)/** 通过伪信号唤醒任务(设置TIF_SIGPENDING但不发送真实信号)* 任务会在ret_to_user路径中处理冻结请求[2,6](@ref)*/signal_wake_up(task, false);} else {/* 清除冻结标志并直接唤醒任务 */task->jobctl &= ~JOBCTL_TRAP_FREEZE;if (wake)wake_up_process(task); // 直接唤醒任务解除冻结状态}/* 释放信号处理锁 */unlock_task_sighand(task, &flags);}
根据signal_wake_up_state函数的代码逻辑,如果目标进程不在runqueue上,则wake_up_state函数会将其放在runqueue上并返回true;如果进程已经处于runqueue上了,则返回false,才会执行kick_process。下面我们来看看kick_process函数的实现:
kernel/sched/core.c
/** Notify a process about a new pending signal and wake it up if needed.* 通知进程有新信号待处理,并根据需要唤醒进程** @t: 目标进程的task_struct指针* @state: 唤醒状态掩码(如TASK_WAKEKILL或__TASK_TRACED)** 注意事项:* 1. 必须在持有t->sighand->siglock自旋锁且本地中断已关闭的上下文中调用* 2. 依赖调用前的spin_lock保证中断安全(见函数头注释)* 3. 不设置need_resched标志,因为信号处理通过->blocked机制传递*/void signal_wake_up_state(struct task_struct *t, unsigned int state){/* 验证调用环境是否持有正确的锁 */lockdep_assert_held(&t->sighand->siglock);/** 设置线程的TIF_SIGPENDING标志,表示有信号待处理* 该标志会在进程返回用户态时触发信号处理流程*/set_tsk_thread_flag(t, TIF_SIGPENDING);/** 唤醒策略说明:* 1. TASK_WAKEKILL标志会唤醒处于stopped/traced/killable状态的进程* 2. 不直接检查t->state是因为存在竞态条件(进程可能正在其他CPU上进入stopped状态)* 3. 组合使用state和TASK_INTERRUPTIBLE确保进程能正确处理致命信号** 如果wake_up_state失败(进程已在运行队列),且进程在其他CPU上运行,* 则通过kick_process发送处理器间中断强制重新调度*/if (!wake_up_state(t, state | TASK_INTERRUPTIBLE))kick_process(t);}
函数的注释已经写得很清楚,kick_process的目的就是让进程陷入内核态。而smp_send_reschedule本质就是给进程所在的核发个IPI中断,从而导致正在运行的进程被打断陷入内核态。到这里cgroup这边freeze的前置工作已经做完,所有即将进入freeze的task已经被kernel置位为JOBCTL_TRAP_FREEZE和处于TIF_SIGPENDING的状态,真正执行进程冻结挂起的操作是放在signal的信号处理这边来执行。
3. 冻结信号处理
信号真正得到执行的时机是进程执行完异常/中断/系统调用,从内核态返回到用户态的时刻,所以永远不要指望你所发送的信号能像硬件中断那般随时处理,进程信号处理只是异步通信机制,没有像真正的硬件中断那样能随时改变cpu的执行流。正常的用户进程是会频繁的在用户态和内核态之间切换的 (这种切换包括:系统调用,缺页异常,系统中断..),所以信号能很快得到执行。
前面小节已经讲过cgroup组中要被freeze的task已经将其_TIF_SIGPENDING置位。进程的_TIF_SIGPENDING置位,表明该进程有pending信号需要处理。因此会执行信号处理流程。
信号处理过程中会检查task中的freeze标志位已设置,故进程将执行关键冻结函数do_freeze_trap。调用链路如下:
exit_to_user_modeprepare_exit_to_user_modedo_notify_resume|->do_signal|->get_signal|->do_freezer_trap|->__set_current_state //进程即将进入冻结休眠,将进程设置为TASK_INTERRUPTIBLE,可以被signal唤醒|->clear_thread_flag|->cgroup_enter_frozen|->cgroup_update_frozen|->cgroup_propagate_frozen|->freezable_schedule|->schedule|->__schedule|->deactivate_task|->dequeue_task
调用栈打印:
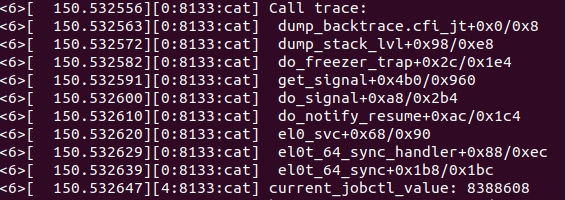
这里分析几个关键函数do_notify_resume、get_signal、do_freezer_trap、freezable_shedule。函数do_notify_resume定义在arch/arm64/kernel/signal.c中,该函数检查如果当前任务设置了标志位_TIF_SIGPENDING,则调用do_signal()处理信号,代码如下:
/** do_notify_resume - 内核在返回用户空间前的信号和事件处理入口* @regs: 保存用户态寄存器现场的结构体指针,用于信号处理时恢复上下文* @thread_flags: 线程标志位集合,指示需要处理的事件类型** 功能说明:* 1. 该函数是内核从系统调用/中断返回用户空间前的统一处理点,负责检查并处理待处理的信号(_TIF_SIGPENDING)* 和其他需要通知的事件(_TIF_NOTIFY_SIGNAL)* 2. 通过thread_flags判断处理类型,避免不必要的信号检查开销* 3. 实际信号处理由do_signal()完成,包括用户态信号处理函数的栈帧构建和触发执行** 调用上下文:* - 必须在内核态调用,通常在ret_to_user路径中(如arch/arm/kernel/entry-armv.S)* - 调用时需保证regs完整保存用户态寄存器状态(通过pt_regs结构)* - thread_flags来自当前线程的thread_info结构,由signal_wake_up()等函数设置** 关键设计:* - _TIF_SIGPENDING标志由signal_wake_up()设置,表示有待处理信号* - _TIF_NOTIFY_SIGNAL用于类似io_uring的异步事件通知(非传统信号)* - 信号处理延迟到返回用户态前执行,避免内核关键路径中的信号处理复杂性*/void do_notify_resume(struct pt_regs *regs, unsigned long thread_flags){.../** 检查线程标志位,组合判断信号和事件通知:* - _TIF_SIGPENDING: 传统信号(如SIGINT/SIGTERM)* - _TIF_NOTIFY_SIGNAL: 内核子系统事件(如io_uring完成通知)* 两者共用相同的处理路径,但实际处理逻辑在do_signal()内有区分*/if (thread_flags & (_TIF_SIGPENDING | _TIF_NOTIFY_SIGNAL))do_signal(regs); // 进入实际信号处理流程...}/** 相关机制说明:* 1. 信号传递流程:* signal_wake_up() -> set TIF_SIGPENDING -> schedule() -> ret_to_user -> do_notify_resume() -> do_signal()* 2. 安全性保障:* - 通过pt_regs严格隔离用户态/内核态寄存器状态* - 信号处理函数执行前会构建独立的用户态栈帧* 3. 性能优化:* - 仅当标志位被设置时才调用do_signal(),减少无信号时的开销* - 信号处理延迟到非关键路径(返回用户态前)*/
do_signal中调用到get_signal函数从线程私有的pending链表或者线程组共享的pending链表中,找到pending信号,如果需要投递到用户态去执行,返回1。如果没有需要投递到用户态去执行的pending信号,返回0。如果遇到需要kernel处理的信号,在该函数内部就会消化掉。get_signal实现如下:
get_signal - 内核信号处理的核心函数,负责从进程的待处理信号队列中获取下一个需要处理的信号* @ksig: 用于返回获取到的信号信息(包括信号编号、处理动作等)** 返回值:* true - 成功获取到一个需要处理的信号* false - 没有待处理的信号** 关键处理流程:* 1. 检查并处理进程状态变化通知(如CLD_CONTINUED/CLD_STOPPED)* 2. 从同步信号队列或常规队列中获取信号* 3. 根据信号处理动作(忽略/默认/自定义)决定处理方式* 4. 对致命信号执行终止进程或coredump操作*/bool get_signal(struct ksignal *ksig){/* 获取当前进程的信号处理结构 */struct sighand_struct *sighand = current->sighand;struct signal_struct *signal = current->signal;int signr;/* 清理通知类信号标志 */clear_notify_signal();/* 处理挂起的task_work(避免在信号处理过程中被中断) */if (unlikely(task_work_pending(current)))task_work_run();/* 快速检查是否有待处理信号(无锁优化) */if (!task_sigpending(current))return false;/* uprobe相关信号拦截检查 */if (unlikely(uprobe_deny_signal()))return false;/* 检查进程冻结状态(防止返回用户态时进程被冻结) */try_to_freeze();relock:/* 获取信号处理锁(禁用本地中断) */spin_lock_irq(&sighand->siglock);/** 处理子进程状态变化通知(SIGCONT/SIGSTOP等)* 当线程从停止状态恢复时,需要通知父进程*/if (unlikely(signal->flags & SIGNAL_CLD_MASK)) {int why;/* 确定通知类型:继续运行或停止 */if (signal->flags & SIGNAL_CLD_CONTINUED)why = CLD_CONTINUED;elsewhy = CLD_STOPPED;signal->flags &= ~SIGNAL_CLD_MASK;spin_unlock_irq(&sighand->siglock);/** 通知父进程状态变化:* 1. 对于普通进程,通过wait(2)通知父进程* 2. 对于被ptrace跟踪的进程,额外通知跟踪者*/read_lock(&tasklist_lock);do_notify_parent_cldstop(current, false, why);/* 处理被ptrace跟踪的情况 */if (ptrace_reparented(current->group_leader))do_notify_parent_cldstop(current->group_leader,true, why);read_unlock(&tasklist_lock);goto relock; // 重新获取锁并继续信号处理}/* 主信号处理循环 */for (;;) {struct k_sigaction *ka;enum pid_type type;/* 检查进程是否已被标记为终止状态 */if ((signal->flags & SIGNAL_GROUP_EXIT) ||signal->group_exec_task) {clear_siginfo(&ksig->info);ksig->info.si_signo = signr = SIGKILL;sigdelset(¤t->pending.signal, SIGKILL);trace_signal_deliver(SIGKILL, SEND_SIG_NOINFO,&sighand->action[SIGKILL - 1]);recalc_sigpending();goto fatal; // 跳转到终止处理}/* 处理挂起的任务停止请求 */if (unlikely(current->jobctl & JOBCTL_STOP_PENDING) &&do_signal_stop(0))goto relock;/* 处理调试陷阱和冻结陷阱 */if (unlikely(current->jobctl &(JOBCTL_TRAP_MASK | JOBCTL_TRAP_FREEZE))) {if (current->jobctl & JOBCTL_TRAP_MASK) {do_jobctl_trap();spin_unlock_irq(&sighand->siglock);} else if (current->jobctl & JOBCTL_TRAP_FREEZE)do_freezer_trap();goto relock;}/* 处理进程解冻状态 */if (unlikely(cgroup_task_frozen(current))) {spin_unlock_irq(&sighand->siglock);cgroup_leave_frozen(false);goto relock;}/** 信号获取优先级:* 1. 先获取同步信号(如SIGSEGV等由CPU异常触发的信号)* 2. 再从常规队列获取其他信号*/type = PIDTYPE_PID;signr = dequeue_synchronous_signal(&ksig->info);if (!signr)signr = dequeue_signal(current, ¤t->blocked,&ksig->info, &type);if (!signr)break; /* 没有待处理信号,返回false *//* 处理被ptrace跟踪的进程信号 */if (unlikely(current->ptrace) && (signr != SIGKILL) &&!(sighand->action[signr -1].sa.sa_flags & SA_IMMUTABLE)) {signr = ptrace_signal(signr, &ksig->info, type);if (!signr)continue;}/* 获取信号处理动作 */ka = &sighand->action[signr-1];trace_signal_deliver(signr, &ksig->info, ka);/* 处理忽略信号的情况 */if (ka->sa.sa_handler == SIG_IGN)continue;/* 处理自定义信号处理函数 */if (ka->sa.sa_handler != SIG_DFL) {ksig->ka = *ka;/* 处理一次性信号 */if (ka->sa.sa_flags & SA_ONESHOT)ka->sa.sa_handler = SIG_DFL;break; // 返回给上层处理(do_signal会调用handle_signal)}/** 以下是内核默认信号处理逻辑*//* 处理内核默认忽略的信号(如SIGWINCH) */if (sig_kernel_ignore(signr))continue;/* 处理不可杀进程的特殊情况 */if (unlikely(signal->flags & SIGNAL_UNKILLABLE) &&!sig_kernel_only(signr))continue;/* 处理停止类信号(SIGSTOP/SIGTSTP等) */if (sig_kernel_stop(signr)) {/* SIGSTOP需要特殊处理(不能被拦截) */if (signr != SIGSTOP) {spin_unlock_irq(&sighand->siglock);/* 检查进程组是否已成为孤儿 */if (is_current_pgrp_orphaned())goto relock;spin_lock_irq(&sighand->siglock);}/* 执行停止操作 */if (likely(do_signal_stop(ksig->info.si_signo))) {/* do_signal_stop会释放锁,需要重新获取 */goto relock;}continue;}fatal:/* 处理致命信号 */spin_unlock_irq(&sighand->siglock);if (unlikely(cgroup_task_frozen(current)))cgroup_leave_frozen(true);/* 标记进程已被信号终止 */current->flags |= PF_SIGNALED;/* 处理需要coredump的信号(如SIGSEGV) */if (sig_kernel_coredump(signr)) {if (print_fatal_signals)print_fatal_signal(ksig->info.si_signo);proc_coredump_connector(current);do_coredump(&ksig->info); // 生成核心转储}/* 用户工作线程特殊处理 */if (current->flags & PF_USER_WORKER)goto out;/* 执行进程退出(对于SIGKILL等信号) */do_group_exit(ksig->info.si_signo);}/* 清理并返回 */spin_unlock_irq(&sighand->siglock);out:ksig->sig = signr;/* 处理地址标签隐藏(安全特性) */if (!(ksig->ka.sa.sa_flags & SA_EXPOSE_TAGBITS))hide_si_addr_tag_bits(ksig);return ksig->sig > 0;}
在信号处理流程中检查task中的jobctl标志位是否被设置成JOBCTL_TRAP_FREEZE,条件成立则执行do_freezer_trap开始走进程挂起流程,do_freezer_trap实现如下:
/*** do_freezer_trap - 处理进程冻结陷阱** 功能说明:* 1. 将当前进程置于冻结状态(除非进程即将退出)* 2. 清除JOBCTL_TRAP_FREEZE标志位* 3. 通过cgroup_enter_frozen()进入冻结状态并调度** 上下文要求:* - 必须持有current->sighand->siglock自旋锁(函数返回前会释放)* - 必须在进程返回用户空间前调用(通常由信号处理路径触发)** 设计要点:* - 通过TASK_FREEZABLE状态组合实现安全冻结(避免内核态死锁)* - 与cgroup freezer子系统深度集成,支持进程组粒度的冻结[4,8](@ref)*/static void do_freezer_trap(void)__releases(¤t->sighand->siglock){/** 检查是否存在除JOBCTL_TRAP_FREEZE外的其他陷阱标志:* - 如果有其他待处理陷阱(如JOBCTL_TRAP_MASK),则放弃本次冻结* - 确保不会干扰其他更重要的陷阱处理(如ptrace调试陷阱)*/if ((current->jobctl & (JOBCTL_PENDING_MASK | JOBCTL_TRAP_FREEZE)) !=JOBCTL_TRAP_FREEZE) {spin_unlock_irq(¤t->sighand->siglock);return;}/** 安全冻结准备阶段:* 1. 设置TASK_INTERRUPTIBLE|TASK_FREEZABLE状态(可被信号和冻结唤醒)* 2. 清除TIF_SIGPENDING标志避免立即被信号唤醒* 3. 释放锁后通过cgroup_enter_frozen()进入冻结状态** 注:TASK_FREEZABLE是专为冻结设计的特殊状态,允许进程在冻结期间保持可中断[3,7](@ref)*/__set_current_state(TASK_INTERRUPTIBLE|TASK_FREEZABLE);clear_thread_flag(TIF_SIGPENDING);spin_unlock_irq(¤t->sighand->siglock);/* 正式进入冻结状态(关联cgroup freezer子系统) */cgroup_enter_frozen();/** 主动让出CPU,进程将在此处挂起直到被解冻* 解冻时会从此处恢复执行[5,7](@ref)*/schedule();/** 解冻后处理:* 1. 清理任务工作通知标志(TIF_NOTIFY_SIGNAL)* 2. 执行延迟的task_work(如io_uring等异步机制可能设置)** 注:调用者会负责检查是否需要重新进入冻结状态[1,5](@ref)*/clear_notify_signal();if (unlikely(task_work_pending(current)))task_work_run();}
调度函数schedule里去,schedule定义在 kernel/sched/core.c 中,在 __schedule() 中接受一个参数,该参数为 bool 型,false 表示非抢占,自愿调度,而 true 则相反。freeze中的调度是主动调度让出CPU。
/*** schedule - 内核主调度函数,负责进程/线程的上下文切换** 功能说明:* 1. 这是Linux内核的核心调度入口,通过自愿或强制调度触发(如时间片耗尽、高优先级任务唤醒)* 2. 采用嵌套调度机制:外层处理抢占控制,内层__schedule完成实际切换* 3. 通过need_resched标志实现惰性调度检查,避免不必要的上下文切换开销** 设计要点:* - 禁用内核抢占期间执行关键调度操作,防止并发问题* - 循环检查need_resched标志,确保及时响应调度请求* - 与cgroup、workqueue等子系统深度集成(通过sched_submit_work/sched_update_worker)*/asmlinkage __visible void __sched schedule(void){/* 获取当前进程的task_struct指针 */struct task_struct *tsk = current;/** 预处理阶段:* 1. 检查死锁风险(如PI锁冲突)* 2. 提交待处理的I/O插队请求(避免I/O死锁)*/sched_submit_work(tsk);/* 主调度循环:可能因need_resched标志被多次触发 */do {/* 禁用内核抢占,保护关键调度操作 */preempt_disable();/** 核心调度逻辑:* - SM_NONE表示非主动抢占场景(区别于显式调用cond_resched)* - 完成运行队列选择、上下文切换等操作*/__schedule(SM_NONE);/* 重新启用内核抢占(但不立即检查重调度标志) */sched_preempt_enable_no_resched();} while (need_resched()); /* 检查TIF_NEED_RESCHED标志,必要时重新调度 *//* 后处理阶段:更新工作线程状态(如kworker) */sched_update_worker(tsk);}EXPORT_SYMBOL(schedule); // 导出符号供内核模块使用/** 关键机制说明:* 1. 抢占控制:* - preempt_disable/enable 构成调度临界区,防止中断或其它CPU干扰* - sched_preempt_enable_no_resched 避免立即触发重复调度** 2. 调度触发场景:* - 自愿调度:阻塞系统调用、同步原语等待* - 强制调度:时间片耗尽、高优先级任务唤醒(通过设置TIF_NEED_RESCHED)** 3. 性能优化:* - __visible 确保函数可被编译器优化内联* - __sched 宏将函数代码放入专用段,便于调试器过滤调度相关调用栈** 4. SMP支持:* - 通过per-CPU运行队列(rq)实现无锁化本地调度* - __schedule内部处理负载均衡和CPU亲和性*/ [5,6](@ref)
四、最后
确定何时冻结、何时解冻、何时再冻结进程其实是一个复杂的问题,需要维护一个流程图来管理不同的场景。在本文中,我们只是简单介绍了内核冻结功能的实现逻辑。在 Android Framework 层还涉及到低内存时内存整理时解冻、dump进程信息时解冻、发送和接收广播临时解冻、持有文件锁解冻等策略。
参考:
https://juejin.cn/post/7264949719275880482
Control Group v2 — The Linux Kernel documentation
freezer for cgroup v2 [LWN.net]
原文:进程冻结技术:深入探究 Linux 内核中的 cgroup freezer 子系统 - 魅族内核团队