JUC之CompletableFuture【上】
文章目录
- 一、前置知识
- 1.1 同步 vs 异步
- 1.2 线程启动方式
- 1.3 Runnable 和 Future
- 1.3.1 核心区别: 功能定位不同
- 1.3.2 关联:通过 `FutureTask` 建立桥梁
- 1.3.3 FutureTask
- 1.3.4 Callable接口
- 1.3.5 结论
- 1.4 FutureTask
- 1.4.1 Future优点
- 1.4.2 Future缺点
- 1.4.3 结论
- 二、ForkJoinPool
- 2.1 核心设计思想
- 2.2 核心组件
- 2.3 基本使用步骤
- 2.4 示例代码
- 2.4.1 无返回值任务(RecursiveAction)
- 2.4.2 有返回值任务(RecursiveTask)
- 2.5 工作原理
- 2.6 关键参数配置
- 2.6.1 并行度
- 2.6.2 **公共池(Common Pool)**
- 2.7 适用场景
- 2.8 与普通线程池(ThreadPoolExecutor)的对比
- 2.9 最佳实践
- 2.10 总结
- 2.11 综合示例
- 三、CompletableFuture概述
- 3.1 概述
- 3.2 CompletionStage
- 3.2.1 核心方法分类功能
- 1. 消费前一阶段结果【无返回值】
- 2. 转换前一阶段结果(有返回值)
- 3. 执行后续操作(不依赖前一结果)
- 4. 组合两阶段
- 5. 处理异常
- 6. 其它重要方法
- 3.2.2 执行顺序图示
- 3.2.3 CompletionStage与 CompletableFuture 的关系
- 3.2.4 CompletionStage获取对象姿势
一、前置知识
1.1 同步 vs 异步
1. 同步【Synchronous】: 做完一件再做下一件
就像去餐厅点餐:
你告诉服务员 “要一份汉堡”,然后站在原地等待,直到服务员把汉堡做好递给你,你拿到后才会继续点下一份(或离开)。
在 Java 中,同步就是:
- 调用一个方法后,当前线程会阻塞等待,直到这个方法执行完、返回结果,才会继续执行后面的代码。
- 比如调用
Thread.sleep(1000)时,当前线程会暂停 1 秒,期间什么都做不了,必须等这 1 秒过去才能继续。
特点:
- 任务按顺序执行,一步完了再走下一步。
- 简单直观,但如果某个任务耗时久(比如网络请求、文件读写),会 “卡” 住整个流程。
2. 异步【Asynchronous】: 交代任务后先去忙别的
还是餐厅点餐,但这次是 “扫码点单”:
你在手机上点了汉堡,提交订单后不用站着等,可以去旁边玩手机、聊天,等汉堡做好了服务员会喊你取餐,这期间你可以做其他事
在 Java 中,异步就是:
- 调用一个方法后,当前线程不等待,直接继续执行后面的代码。
- 被调用的方法会在 “后台”(比如另一个线程)执行,完成后通过回调、通知等方式告诉你结果。
- 比如用
CompletableFuture.supplyAsync()提交一个任务,主线程不用等它执行完,可以先做别的,等任务完成后再处理结果。
特点:
- 多个任务可以 “同时” 进行(实际是线程切换实现的并发),不互相阻塞。
- 效率高,适合处理耗时操作(如网络请求、大数据计算),但代码逻辑会稍复杂(需要处理回调、结果合并等)。
一句话总结
- 同步:我调用你,必须等你做完,我才继续。(“串行” 思维)
- 异步:我调用你,不等你做完,我先去做别的,你做完了告诉我。(“并行” 思维)
异步任务的三个条件:
- 线程
- 有返回值
- 异步
1.2 线程启动方式
启动线程的唯一方式:
public synchronized void start() {}
1.3 Runnable 和 Future
1.3.1 核心区别: 功能定位不同
Runnable:仅表示一个 “可执行的任务”,没有返回值,也无法抛出受检异常(只能抛出RuntimeException)。
核心方法:void run()(无返回值)。Future:表示 “异步任务的结果容器”,用于获取异步任务的返回值、取消任务、判断任务是否完成等。
核心方法:get()(获取结果,会阻塞)、cancel()(取消任务)、isDone()(判断任务是否完成)等。
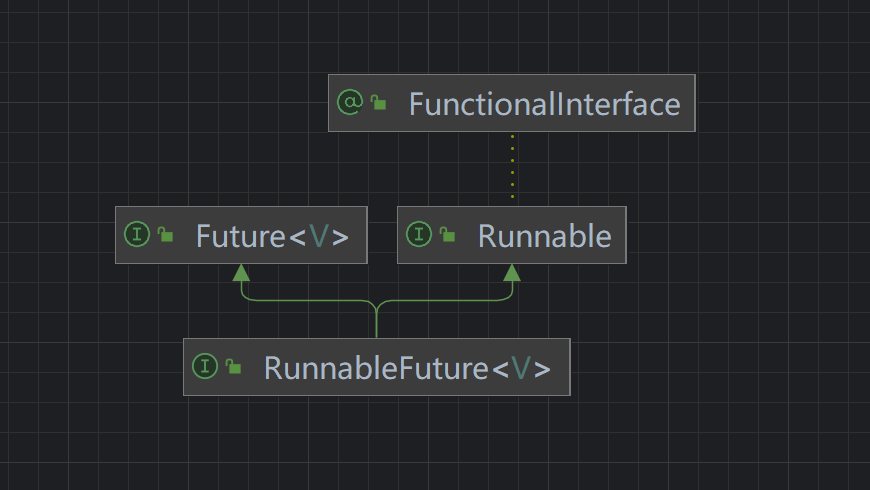
1.3.2 关联:通过 FutureTask 建立桥梁
public interface RunnableFuture<V> extends Runnable, Future<V> {/*** Sets this Future to the result of its computation* unless it has been cancelled.*/void run();
}
找到了Runnable与Future之间的关系
public Thread(Runnable target) {this(null, target, "Thread-" + nextThreadNum(), 0);
}
RunnableFuture, 实现了两个接口Runnable和Future,也就是这个接口支持异步操作,这个是由Future接口特性决定的.同时也可以通过Thread类的构造方法,传入一个RunnableFuture的接口类型的参数,用来启动线程.
1.3.3 FutureTask
private static class ThreadBoundFuture<T>extends FutureTask<T> implements Runnable {final ThreadPerTaskExecutor executor;final Thread thread;// ....
}
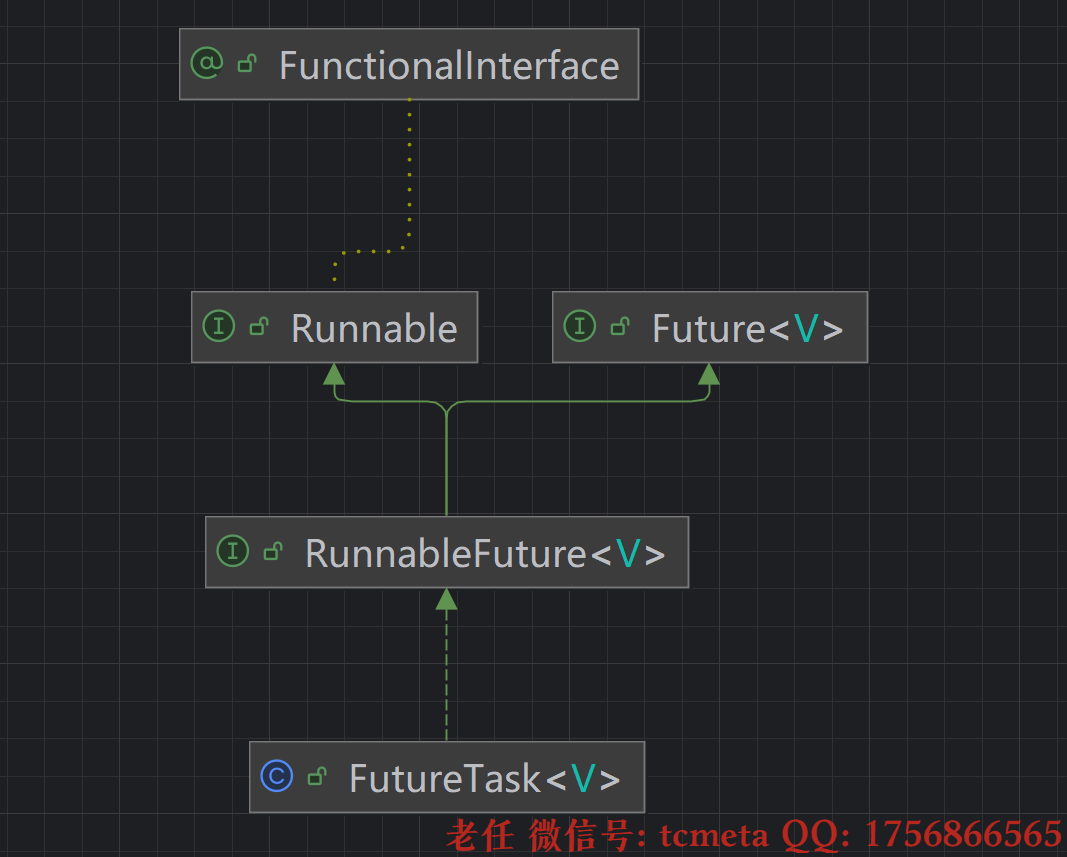
Runnable 和 Future 本身没有直接继承关系,但可以通过 FutureTask 类结合使用,实现 “有返回值的异步任务”。
FutureTask 同时实现了 Runnable 和 Future 接口,相当于一个 “适配器”:
- 它可以包装一个
Callable(带返回值的任务),也能包装Runnable(通过适配成Callable)。 - 作为
Runnable,它可以被线程(Thread)或线程池执行。 - 作为
Future,它可以获取任务的返回值、取消任务等。
public Thread(RunnableFuture<> r){}
1.3.4 Callable接口
- 作为异步编程的返回值处理
@FunctionalInterface
public interface Callable<V> {V call() throws Exception;
}
- 找到Callable接口与RunnableFuture之间的关系.
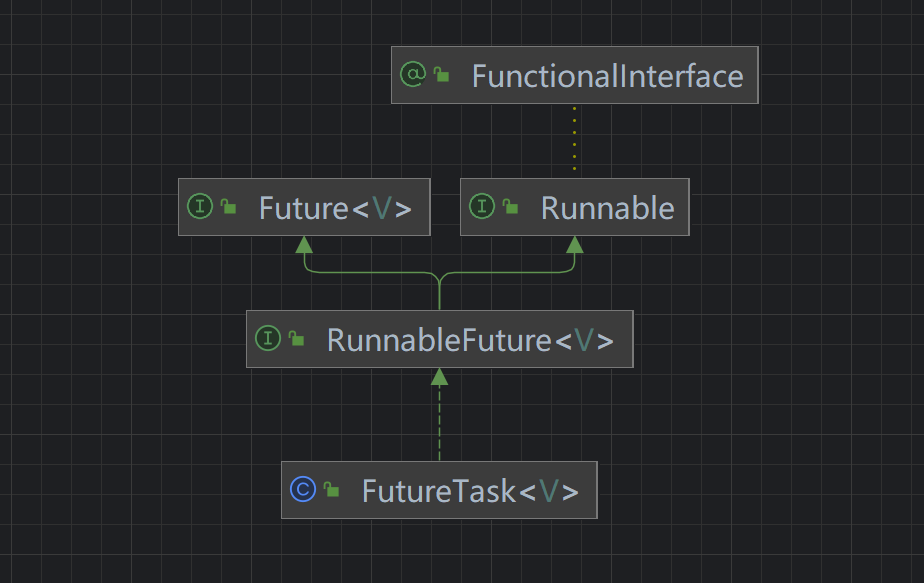
public class FutureTask<V> implements RunnableFuture<V> {public FutureTask(Callable<V> callable) {if (callable == null)throw new NullPointerException();this.callable = callable;this.state = NEW; // ensure visibility of callable}public FutureTask(Runnable runnable, V result) {this.callable = Executors.callable(runnable, result);this.state = NEW; // ensure visibility of callable}
}
1.3.5 结论
可以通过FutureTask来实现异步任务. 满足了异步任务的三个条件
- 线程
- 有返回值, 利用Callable接口
- 异步
1.4 FutureTask
一个简单的示例
package cn.tcmeta.futuretask;import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
import java.util.concurrent.TimeUnit;public class FutureTaskDemo {public static void main(String[] args) throws ExecutionException, InterruptedException {// 定义一个异步任务.FutureTask<String> task = new FutureTask<>(() -> {try {TimeUnit.MILLISECONDS.sleep(3000);}catch (Exception e){e.printStackTrace();}return "第一个异步任务哦!";});new Thread(task, "task-thread: ").start(); // 启动异步任务System.out.println(Thread.currentThread().getName() + " --> \t" + "我已经执行完成了....");System.out.println(Thread.currentThread().getName() + " --> \t" + "task返回的值是: " + task.get());}
}

1.4.1 Future优点
// Future表示异步计算的结果。提供了检查计算是否完成、
// 等待其完成以及检索计算结果的方法。结果只能在计算完成后使用方法get检索,
// 必要时阻塞,直到它准备好。取消是通过cancel方法执行的。
// 提供了额外的方法来确定任务是正常完成还是被取消。
// 一旦计算完成,就不能取消计算。如果您想使用Future来取消可取消性但不提供可用的结果,
// 您可以声明Future<?>形式的类型并返回null作为底层任务的结果
// 1.5版本新增
public interface Future<V> {boolean cancel(boolean mayInterruptIfRunning);boolean isCancelled();boolean isDone();V get() throws InterruptedException, ExecutionException;V get(long timeout, TimeUnit unit)throws InterruptedException, ExecutionException, TimeoutException;
}
Future接口「FutureTask是其实现类」,定义了操作「异步任务执行的一些方法」,如获取异步任务的执行结果,取消执行任务,判断任务是否被取消,判断任务是否执行完毕.
- 如主线程让一个子线程去执行任务,子线程在执行过程中可能比较耗时,启动子线程开始执行任务后, 主线程去做其他事情了,忙其它事情或者先执行完, 过了一会才去获取子任务的执行结果或者变更的任务状态.
- Future可以为主线程开启一个分支任务,专门为主线程处理耗时任务和复杂的业务
- Future在java5新增加的一个接口,它提供了一种「异步并行计算的功能」
- 如果主线程需要执行一个耗时的计算任务,我们就可以通过Future把这个任务放到异步线程中执行,
主线程继续处理其他任务或者先行结束,再通过Future获取计算结果.
- Future结合线程池,实现异步多任务配置,能显著的提升程序的吞吐量
- 示例代码, 感受一下异步任务.
- 同步执行任务示例代码
package cn.tcmeta.futuretask;import java.util.concurrent.TimeUnit;public class FutureTask2 {public static void main(String[] args) {syncTask();}/*** 同步执行任务*/public static void syncTask() {long start = System.currentTimeMillis();try {System.out.println(Thread.currentThread().getName() + " -- \t" + " 开始执行每一个任务");TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName() + " -- \t" + "完成第一个任务");} catch (Exception e) {e.printStackTrace();}try {System.out.println(Thread.currentThread().getName() + " -- \t" + " 开始执行每二个任务");TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName() + " -- \t" + "完成第二个任务");} catch (Exception e) {e.printStackTrace();}try {System.out.println(Thread.currentThread().getName() + " -- \t" + " 开始执行每三个任务");TimeUnit.SECONDS.sleep(4);System.out.println(Thread.currentThread().getName() + " -- \t" + "完成第三个任务");} catch (Exception e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println(Thread.currentThread().getName() + " ----- " + "代码执行共耗时: " + (end - start) + " 毫秒");}
}

- 异步执行代码
public static void asyncTask() {long start = System.currentTimeMillis();FutureTask<String> task1 = new FutureTask<>(() -> {System.out.println(Thread.currentThread().getName() + " -- \t" + " 开始执行每一个任务");TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName() + " -- \t" + "完成第一个任务");return "第一个任务执行完成!";});FutureTask<String> task2 = new FutureTask<>(() -> {System.out.println(Thread.currentThread().getName() + " -- \t" + " 开始执行每三个任务");TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName() + " -- \t" + "完成第二个任务");return "第二个任务执行完成!";});FutureTask<String> task3 = new FutureTask<>(() -> {System.out.println(Thread.currentThread().getName() + " -- \t" + " 开始执行第三个任务");TimeUnit.SECONDS.sleep(4);System.out.println(Thread.currentThread().getName() + " -- \t" + "完成第三个任务");return "第三个任务执行完成!";});// 定义线程池ExecutorService executorService = Executors.newFixedThreadPool(3);executorService.submit(task1);executorService.submit(task2);executorService.submit(task3);executorService.shutdown();long end = System.currentTimeMillis();System.out.println(Thread.currentThread().getName() + " ----- " + "代码执行共耗时: " + (end - start) + " 毫秒");}

1.4.2 Future缺点
get()方法在获取值的时候,容易发生阻塞.
package cn.tcmeta.futuretask;import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
import java.util.concurrent.TimeUnit;public class FutureTask3 {public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask<String> task = new FutureTask<>(() -> {try {TimeUnit.MILLISECONDS.sleep(3000);} catch (Exception e) {e.printStackTrace();}return "success";});new Thread(task, "task-thread: ").start();System.out.println(Thread.currentThread().getName() + " -- \t" + " 主线程已经结束了哦!");// 获取返回值, 此时不会阻塞,主线程的结束,因为主线程已经结束了昂.// 在获取值的时候,会阻塞住, 直到获取值为止.String result = task.get();System.out.println(Thread.currentThread().getName() + " -- \t" + " result: " + result);}
}

将get()放在主线程执行任务之前, 则会阻塞主线程的执行;
package cn.tcmeta.futuretask;import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
import java.util.concurrent.TimeUnit;public class FutureTask3 {public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask<String> task = new FutureTask<>(() -> {try {TimeUnit.MILLISECONDS.sleep(3000);} catch (Exception e) {e.printStackTrace();}return "success";});new Thread(task, "task-thread: ").start();String result = task.get(); // 放在这里,会阻塞住主线程System.out.println(Thread.currentThread().getName() + " -- \t" + " 主线程已经结束了哦!");// 获取返回值, 此时不会阻塞,主线程的结束,因为主线程已经结束了昂.// 在获取值的时候,会阻塞住, 直到获取值为止.// String result = task.get();System.out.println(Thread.currentThread().getName() + " -- \t" + " result: " + result);}
}

【结论】:
get方法会发生阻塞, 一般建议放在程序的最后执行, 这样避免了阻塞主线程任务.阻塞: 等待计算结果返回,否则代码不会继续向下执行.
优化策略: get方法有一个重载, 可以给出等待的时候,如果在时间内返回,则可以正常获取,如果超出了等待时间,则拉倒.
public V get(long timeout, TimeUnit unit)throws InterruptedException, ExecutionException, TimeoutException {if (unit == null)throw new NullPointerException();int s = state;if (s <= COMPLETING &&(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)throw new TimeoutException();return report(s);
}
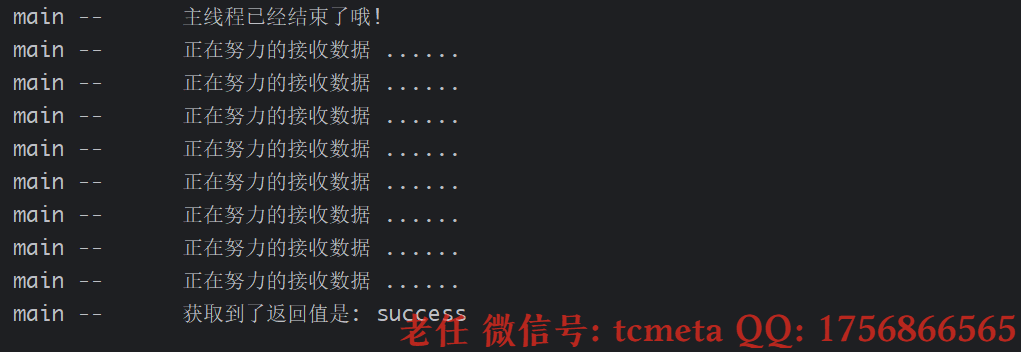
isDone()方法,监听是否执行完成,但是这种基于轮询的机制,容易造成cpu空转等待,浪费性能.一般在获取的时候,不建议直接获取,get方法非常容易造成阻塞,应该在程序当中进行判断.此时就可以使用isDone()方法进行判断.
package cn.tcmeta.futuretask;import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
import java.util.concurrent.TimeUnit;public class FutureTask4 {public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask<String> task = new FutureTask<>(() -> {try {TimeUnit.MILLISECONDS.sleep(3000);} catch (Exception e) {e.printStackTrace();}return "success";});new Thread(task, "task-thread: ").start();// 这里是主线程的任务. 必须等待, get方法返回值之后才会被执行System.out.println(Thread.currentThread().getName() + " -- \t" + " 主线程已经结束了哦!");while (true) {if (task.isDone()) {System.out.println(Thread.currentThread().getName() + " -- \t" + " 获取到了返回值是: " + task.get());break;} else {System.out.println(Thread.currentThread().getName() + " -- \t" + " 正在努力的接收数据 ......");try {TimeUnit.MILLISECONDS.sleep(400);} catch (Exception e) {e.printStackTrace();}}}}
}
1.4.3 结论
获取结果的方式不友好, 只能通过阻塞或者轮询的方式来获取返回值.
解决方案: CompletableFuture对Future的改进操作.
二、ForkJoinPool
如果在使用CompletableFuture的时候,没有显示的传入我们自己定义的线程池,则会使用默认的线程池,这个默认的线程池就是ForkJoinPool.
默认的线程池类似于守护线程,主线程退出之后,默认的线程池也随之关闭了.
ForkJoinPool 是 Java 7 引入的一种特殊线程池,位于 java.util.concurrent 包下,专为分治算法(Divide-and-Conquer) 设计。它通过 “工作窃取”(Work Stealing)机制提高多线程效率,特别适合处理可以拆分为子任务的大型计算任务。
2.1 核心设计思想
ForkJoinPool 的设计基于两个核心概念:
- 分治(Fork/Join)
- Fork:将大任务拆分为多个可独立执行的子任务(递归拆分)。
- Join:等待所有子任务完成后,合并它们的结果,得到最终结果。
- 工作窃取(Work Stealing)
每个线程都有自己的任务队列,当一个线程完成自身任务后,会主动 “窃取” 其他线程队列中的任务执行,减少线程空闲时间,提高整体效率。
2.2 核心组件
-
ForkJoinPool:线程池本身,管理工作线程和任务队列。
-
ForkJoinTask
:任务抽象类,代表可拆分的任务,有两个核心子类:
RecursiveAction:无返回值的任务(如打印、写入文件)。RecursiveTask<V>:有返回值的任务(如计算求和、排序)。
-
工作线程(Worker Threads):线程池中的线程,负责执行任务和窃取任务。
-
任务队列(Deque):每个工作线程关联一个双端队列,存储待执行的任务。
2.3 基本使用步骤
- 定义任务:继承
RecursiveAction或RecursiveTask<V>,重写compute()方法(实现任务拆分和执行逻辑)。 - 创建 ForkJoinPool:通常使用
ForkJoinPool.commonPool()(公共池)或自定义池。 - 提交任务:通过
invoke()、submit()等方法提交任务到线程池。 - 获取结果:对于有返回值的任务,通过
get()方法获取结果。
2.4 示例代码
2.4.1 无返回值任务(RecursiveAction)
package cn.tcmeta.completablefuture;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;// 打印指定范围内的数字(无返回值)
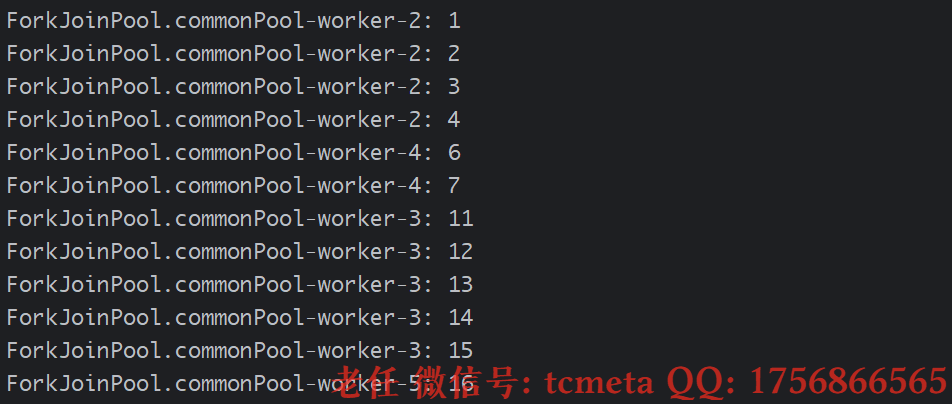
class PrintTask extends RecursiveAction {private static final int THRESHOLD = 5; // 任务拆分阈值private final int start;private final int end;public PrintTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected void compute() {// 如果任务足够小,直接执行if (end - start <= THRESHOLD) {for (int i = start; i <= end; i++) {System.out.println(Thread.currentThread().getName() + ": " + i);}} else {// 拆分任务int mid = (start + end) / 2;PrintTask leftTask = new PrintTask(start, mid);PrintTask rightTask = new PrintTask(mid + 1, end);// 执行子任务(fork() 提交子任务)leftTask.fork();rightTask.fork();// 等待子任务执行完成(join() 等待子任务执行完成)leftTask.join();rightTask.join();}}public static void main(String[] args) {// 使用公共 ForkJoinPoolForkJoinPool pool = ForkJoinPool.commonPool();// 提交任务pool.invoke(new PrintTask(1, 20));pool.shutdown();}
}
2.4.2 有返回值任务(RecursiveTask)
package cn.tcmeta.completablefuture;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;// 计算数组总和(有返回值)
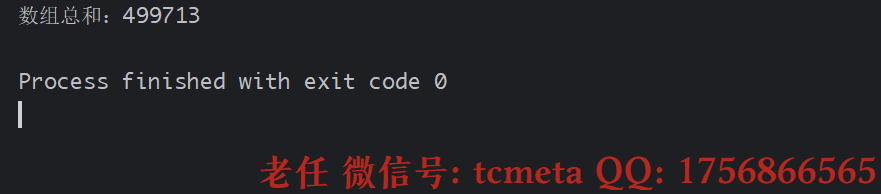
class SumTask extends RecursiveTask<Integer> {private static final int THRESHOLD = 1000; // 拆分阈值(数组长度)private final int[] array;private final int start;private final int end;public SumTask(int[] array, int start, int end) {this.array = array;this.start = start;this.end = end;}@Overrideprotected Integer compute() {int sum = 0;// 任务足够小,直接计算if (end - start <= THRESHOLD) {for (int i = start; i < end; i++) {sum += array[i];}} else {// 拆分任务int mid = (start + end) / 2;SumTask leftTask = new SumTask(array, start, mid);SumTask rightTask = new SumTask(array, mid, end);// 执行子任务leftTask.fork();rightTask.fork();// 合并结果(join() 获取子任务结果)sum = leftTask.join() + rightTask.join();}return sum;}public static void main(String[] args) {// 生成随机数组int[] array = new int[10000];for (int i = 0; i < array.length; i++) {array[i] = (int) (Math.random() * 100);}// 自定义 ForkJoinPool(并行度为 4)try (ForkJoinPool pool = new ForkJoinPool(4)) {SumTask task = new SumTask(array, 0, array.length);int result = pool.invoke(task);System.out.println("数组总和:" + result);}}
}
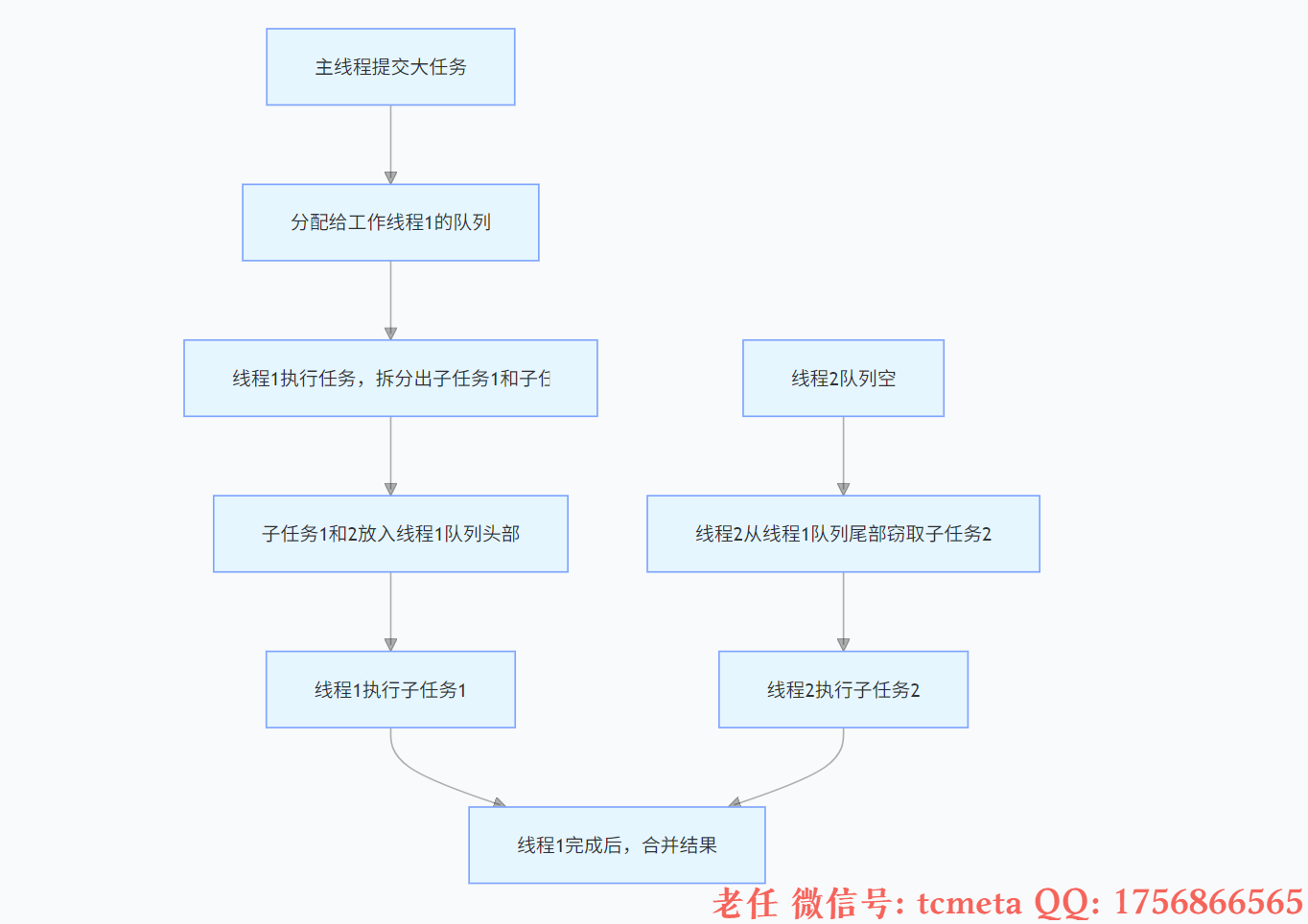
2.5 工作原理
- 任务提交:任务被提交到线程池后,会被分配给某个工作线程,放入其双端队列(Deque)的尾部。
- 任务执行:线程从自己队列的头部获取任务执行。
- 任务拆分:若任务需要拆分,子任务会被放入当前线程队列的头部。
- 工作窃取:当线程完成自身任务(队列空),会从其他线程队列的尾部窃取任务执行(避免竞争)。
这种机制最大化了线程利用率,尤其适合任务大小不均匀的场景。
2.6 关键参数配置
2.6.1 并行度
线程池的核心线程数(默认值为 Runtime.getRuntime().availableProcessors() - 1),代表最大并行执行的任务数。
- 自定义并行度:
new ForkJoinPool(4)(4 个核心线程)。 - 公共池并行度可通过 JVM 参数调整:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=4。
2.6.2 公共池(Common Pool)
ForkJoinPool.commonPool() 是一个静态的共享线程池,适合轻量级任务。但需注意:
- 公共池的线程是守护线程(Daemon Thread),主线程退出后会自动终止。
- 避免在公共池中执行阻塞任务(如 IO 操作),可能影响其他任务。
2.7 适用场景
- CPU 密集型任务:如大型计算(求和、排序、矩阵运算)、递归算法(斐波那契数列、归并排序)等,充分利用多核 CPU。
// 示例:使用 ForkJoinPool 进行归并排序
class MergeSortTask extends RecursiveTask<int[]> {private int[] array;private int start;private int end;// 实现归并排序的拆分与合并逻辑...
}
- 可拆分的任务:任务能被递归拆分为更小的子任务,且子任务可独立执行(无依赖)。
- 大数据处理:如处理大型集合、文件分片解析等。
2.8 与普通线程池(ThreadPoolExecutor)的对比
| 特性 | ForkJoinPool | ThreadPoolExecutor |
|---|---|---|
| 设计目标 | 分治任务、CPU 密集型 | 通用任务(IO 密集型、CPU 密集型) |
| 任务调度 | 工作窃取机制,效率更高 | 基于阻塞队列,无窃取机制 |
| 任务类型 | 适合可拆分的同构任务 | 适合异构任务 |
| 线程利用率 | 高(空闲线程主动窃取任务) | 中(空闲线程等待队列任务) |
| overhead(开销) | 低(任务拆分 / 合并的开销小) | 中(线程切换和调度开销) |
2.9 最佳实践
- 合理设置拆分阈值
阈值太小会导致任务拆分过多,增加调度开销;阈值太大则无法充分利用并行性。需根据任务特性测试调整(如数组求和的阈值可设为 1000~10000)。 - 避免阻塞任务
ForkJoinPool适合 CPU 密集型任务,不适合包含大量 IO 阻塞(如网络请求、文件读写)的任务,此类任务建议用ThreadPoolExecutor。 - 优先使用公共池
简单场景下优先使用ForkJoinPool.commonPool(),避免创建过多线程池。但复杂场景(如不同任务类型)需自定义线程池隔离。 - 使用 try-with-resources 关闭线程池
自定义ForkJoinPool需手动关闭,推荐使用 try-with-resources 自动释放资源:
try (ForkJoinPool pool = new ForkJoinPool(4)) {// 提交任务并执行
} // 自动调用 pool.shutdown()
- 避免任务依赖循环
子任务之间若存在循环依赖(如 A 依赖 B,B 依赖 A),会导致死锁。
2.10 总结
ForkJoinPool 是 Java 中针对分治算法优化的线程池,通过工作窃取机制实现高效的并行计算,特别适合:
- CPU 密集型、可拆分的大型任务;
- 递归式任务处理(如归并排序、大数据求和)
与普通线程池相比,它在并行任务调度上更高效,但也有适用范围限制(不适合 IO 密集型任务)。实际开发中需根据任务特性选择合适的线程池,并合理配置拆分阈值和并行度,以最大化性能。
2.11 综合示例
package cn.tcmeta.completablefuture;import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.RecursiveTask;
import java.util.stream.Collectors;public class ForkJoinDemo {public static void main(String[] args) throws Exception {// 1. 数组求和示例sumArrayExample();// 2. 文件夹搜索示例fileSearchExample();}/*** 示例1:使用ForkJoinPool计算大数组总和*/private static void sumArrayExample() {System.out.println("=== 数组求和示例 ===");// 创建一个包含100万个随机数的数组int[] largeArray = new int[1_000_000];for (int i = 0; i < largeArray.length; i++) {largeArray[i] = (int) (Math.random() * 100);}// 自定义ForkJoinPool,并行度为4try (ForkJoinPool pool = new ForkJoinPool(4)) {// 提交任务SumArrayTask sumTask = new SumArrayTask(largeArray, 0, largeArray.length);long result = pool.invoke(sumTask);System.out.println("数组总和: " + result);// 验证结果(单线程计算)long verifySum = 0;for (int num : largeArray) {verifySum += num;}System.out.println("验证总和: " + verifySum);System.out.println("结果是否一致: " + (result == verifySum));}System.out.println();}/*** 示例2:使用ForkJoinPool搜索文件夹中的特定文件*/private static void fileSearchExample() throws Exception {System.out.println("=== 文件搜索示例 ===");// 搜索当前项目中所有.java文件String searchDir = System.getProperty("user.dir");String fileExtension = ".java";try (ForkJoinPool pool = ForkJoinPool.commonPool()) {FileSearchTask searchTask = new FileSearchTask(Paths.get(searchDir), fileExtension);List<Path> result = pool.invoke(searchTask);System.out.println("找到 " + result.size() + " 个" + fileExtension + "文件:");result.stream().limit(5) // 只显示前5个结果.forEach(path -> System.out.println(" " + path));if (result.size() > 5) {System.out.println(" ... 还有" + (result.size() - 5) + "个文件未显示");}}}/*** 计算数组总和的任务(有返回值)*/static class SumArrayTask extends RecursiveTask<Long> {// 拆分阈值:当数组长度小于等于该值时,直接计算private static final int THRESHOLD = 10_000;private int[] array;private int start;private int end;public SumArrayTask(int[] array, int start, int end) {this.array = array;this.start = start;this.end = end;}@Overrideprotected Long compute() {int length = end - start;// 如果任务足够小,直接计算if (length <= THRESHOLD) {long sum = 0;for (int i = start; i < end; i++) {sum += array[i];}return sum;}// 否则拆分任务int mid = start + (end - start) / 2;SumArrayTask leftTask = new SumArrayTask(array, start, mid);SumArrayTask rightTask = new SumArrayTask(array, mid, end);// 执行左任务(同步执行当前任务的左子任务)leftTask.fork();// 递归执行右任务(当前线程直接执行右子任务,减少线程切换)long rightResult = rightTask.compute();// 获取左任务结果并合并long leftResult = leftTask.join();return leftResult + rightResult;}}/*** 搜索文件的任务(有返回值)*/static class FileSearchTask extends RecursiveTask<List<Path>> {private final Path directory;private final String fileExtension;public FileSearchTask(Path directory, String fileExtension) {this.directory = directory;this.fileExtension = fileExtension;}@Overrideprotected List<Path> compute() {List<Path> result = new ArrayList<>();try {// 列出目录中的所有文件和子目录List<Path> entries = Files.list(directory).collect(Collectors.toList());List<FileSearchTask> subTasks = new ArrayList<>();for (Path entry : entries) {if (Files.isDirectory(entry)) {// 如果是目录,创建子任务FileSearchTask task = new FileSearchTask(entry, fileExtension);subTasks.add(task);} else if (Files.isRegularFile(entry) &&entry.getFileName().toString().endsWith(fileExtension)) {// 如果是符合条件的文件,添加到结果result.add(entry);}}// 执行所有子任务for (FileSearchTask task : subTasks) {task.fork(); // 异步执行子任务}// 合并子任务结果for (FileSearchTask task : subTasks) {result.addAll(task.join());}} catch (IOException e) {// 处理目录访问异常System.err.println("无法访问目录: " + directory + ", 错误: " + e.getMessage());}return result;}}
}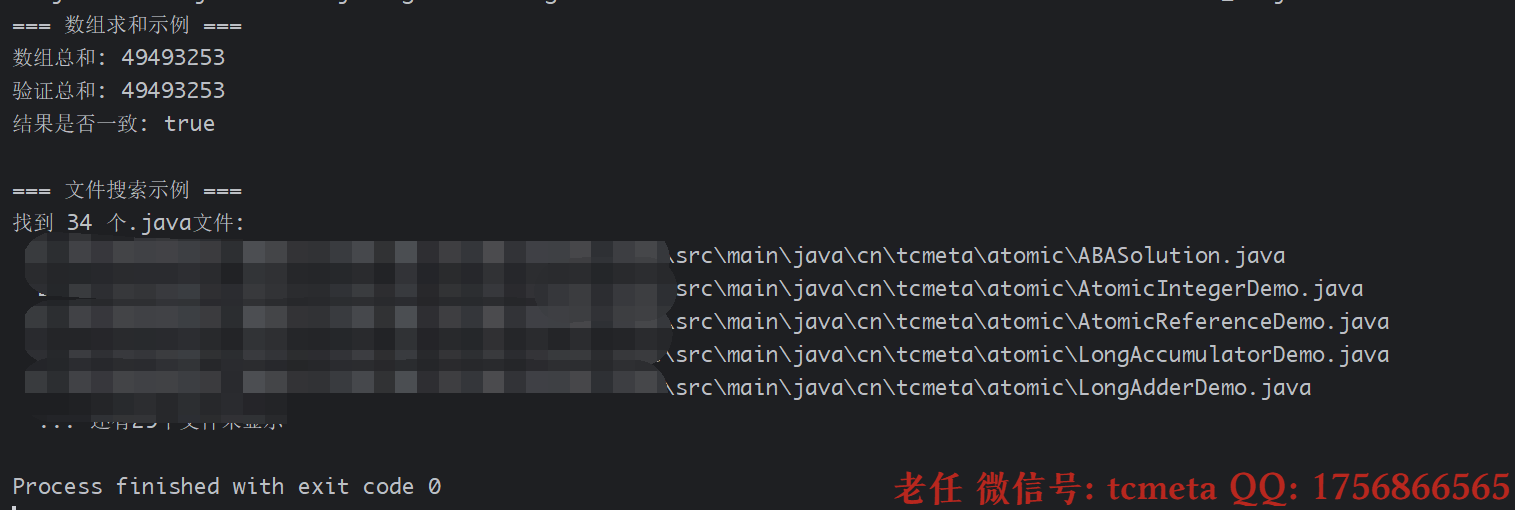
以上示例展示了 ForkJoinPool 在两种典型场景中的应用:
- 数组求和:通过递归拆分大数组为小数组,并行计算后合并结果。
- 文件搜索:递归遍历目录,并行搜索符合条件的文件。
这些示例体现了 ForkJoinPool 处理可拆分任务的优势,尤其是在数据量较大时,能显著提升处理效率。实际使用时,需根据具体任务特性调整拆分阈值和并行度,以达到最佳性能
三、CompletableFuture概述
3.1 概述
CompletableFuture 是 Java 8 引入的异步编程工具类,位于 java.util.concurrent 包下,它实现了 Future 和 CompletionStage 接口,解决了传统 Future 的局限性,提供了更强大、更灵活的异步编程能力.
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {// ....
}
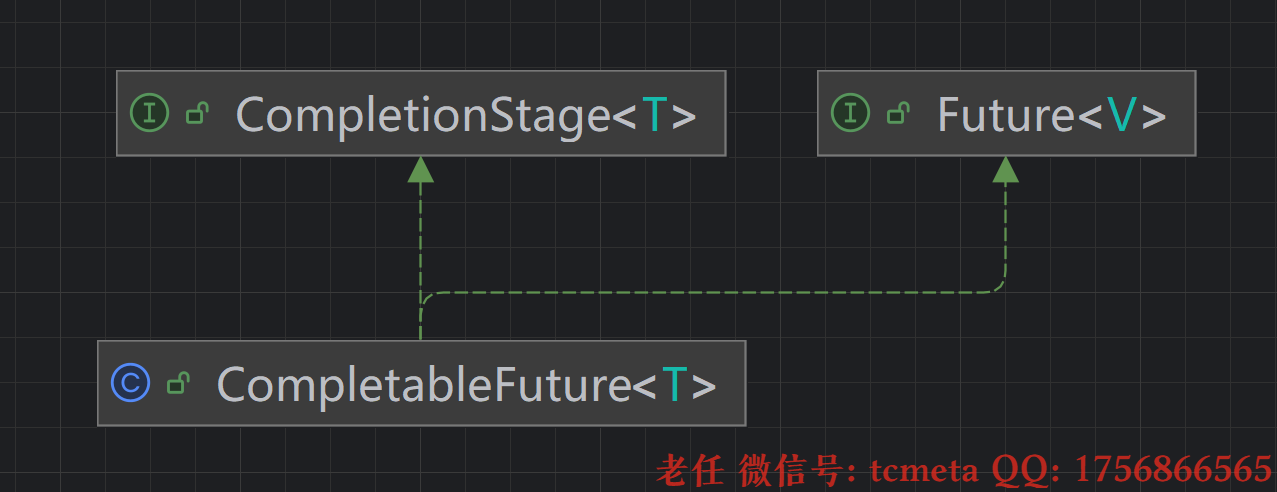
CompletionStage 是 Java 8 引入的一个接口,位于 java.util.concurrent 包下,它代表一个异步计算过程中的某个阶段。这个阶段可能是一个已经完成的操作,也可能是一个尚未完成但未来会完成的操作。CompletionStage 是 CompletableFuture 的核心接口,后者通过实现该接口提供了丰富的异步编程能力。
3.2 CompletionStage

CompletionStage 的设计基于流水线(Pipeline)思想:将一个复杂的异步操作拆分为多个阶段(Stage),每个阶段完成后可以触发下一个阶段,形成链式调用。
- 每个
CompletionStage完成后可以产生一个结果(或异常) - 一个阶段完成后,可以自动触发后续相关阶段的执行
- 多个阶段可以并行执行,也可以按依赖关系顺序执行
这种设计让异步代码的编写像同步代码一样直观,同时保持了异步操作的高效性。
3.2.1 核心方法分类功能
CompletionStage 接口定义了数十个方法,按功能可分为以下几类:
1. 消费前一阶段结果【无返回值】
这类方法接收前一阶段的结果并进行处理,自身不返回新结果(返回 CompletionStage<Void>)。
| 方法 | 功能描述 |
|---|---|
thenAccept(Consumer<? super T> action) | 当前阶段正常完成后,消费其结果(同步执行) |
thenAcceptAsync(Consumer<? super T> action) | 当前阶段正常完成后,异步消费其结果(使用默认线程池) |
thenAcceptAsync(Consumer<? super T> action, Executor executor) | 当前阶段正常完成后,异步消费其结果(使用指定线程池) |
CompletionStage<String> stage = CompletableFuture.supplyAsync(() -> "Hello");
stage.thenAccept(result -> System.out.println("处理结果: " + result)); // 同步消费
stage.thenAcceptAsync(result -> System.out.println("异步处理结果: " + result)); // 异步消费
2. 转换前一阶段结果(有返回值)
这类方法接收前一阶段的结果并进行转换,返回包含新结果的 CompletionStage。
| 方法 | 功能描述 |
|---|---|
thenApply(Function<? super T,? extends U> fn) | 当前阶段正常完成后,转换其结果(同步执行) |
thenApplyAsync(Function<? super T,? extends U> fn) | 当前阶段正常完成后,异步转换其结果(默认线程池) |
thenApplyAsync(Function<? super T,? extends U> fn, Executor executor) | 当前阶段正常完成后,异步转换其结果(指定线程池) |
CompletionStage<String> stage1 = CompletableFuture.supplyAsync(() -> "Hello");
CompletionStage<String> stage2 = stage1.thenApply(s -> s + " World"); // 同步转换
CompletionStage<String> stage3 = stage2.thenApplyAsync(String::toUpperCase); // 异步转换
stage3.thenAccept(result -> System.out.println(result)); // 输出: HELLO WORLD
3. 执行后续操作(不依赖前一结果)
这类方法不关心前一阶段的结果,仅在前一阶段完成后执行特定动作。
| 方法 | 功能描述 |
|---|---|
thenRun(Runnable action) | 当前阶段完成后,执行指定动作(同步) |
thenRunAsync(Runnable action) | 当前阶段完成后,异步执行指定动作(默认线程池) |
thenRunAsync(Runnable action, Executor executor) | 当前阶段完成后,异步执行指定动作(指定线程池) |
CompletionStage<Void> stage = CompletableFuture.runAsync(() -> {System.out.println("执行耗时操作");
});
stage.thenRun(() -> System.out.println("操作完成后的清理工作"));
4. 组合两阶段
这类方法用于组合两个 CompletionStage,当前阶段和另一个阶段都完成后才执行。
| 方法 | 功能描述 |
|---|---|
thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn) | 两个阶段都正常完成后,组合它们的结果(同步) |
thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn) | 两个阶段都正常完成后,异步组合结果(默认线程池) |
thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor) | 两个阶段都正常完成后,异步组合结果(指定线程池) |
CompletionStage<Integer> stage1 = CompletableFuture.supplyAsync(() -> 10);
CompletionStage<Integer> stage2 = CompletableFuture.supplyAsync(() -> 20);// 组合两个结果(10 + 20 = 30)
CompletionStage<Integer> combined = stage1.thenCombine(stage2, Integer::sum);
combined.thenAccept(result -> System.out.println("组合结果: " + result));
5. 处理异常
这类方法用于处理前一阶段可能出现的异常。
| 方法 | 功能描述 |
|---|---|
exceptionally(Function<Throwable,? extends T> fn) | 前一阶段异常完成时,返回一个新结果(恢复操作) |
whenComplete(BiConsumer<? super T, ? super Throwable> action) | 前一阶段完成后(无论正常或异常),执行消费操作(不改变结果) |
handle(BiFunction<? super T, Throwable, ? extends U> fn) | 前一阶段完成后(无论正常或异常),处理结果或异常并返回新结果 |
// exceptionally示例
CompletionStage<Integer> stage1 = CompletableFuture.supplyAsync(() -> {if (true) throw new RuntimeException("出错了");return 100;
}).exceptionally(ex -> {System.out.println("捕获异常: " + ex.getMessage());return -1; // 异常时返回默认值
});// handle示例
CompletionStage<String> stage2 = CompletableFuture.supplyAsync(() -> "成功结果").handle((result, ex) -> {if (ex != null) {return "处理异常: " + ex.getMessage();}return "处理结果: " + result;});
6. 其它重要方法
| 方法 | 功能描述 |
|---|---|
applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn) | 当前阶段或另一个阶段任一完成时,处理先完成的结果 |
acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action) | 当前阶段或另一个阶段任一完成时,消费先完成的结果 |
runAfterEither(CompletionStage<?> other, Runnable action) | 当前阶段或另一个阶段任一完成时,执行动作 |
runAfterBoth(CompletionStage<?> other, Runnable action) | 当前阶段和另一个阶段都完成时,执行动作 |
3.2.2 执行顺序图示
3.2.3 CompletionStage与 CompletableFuture 的关系
CompletableFuture是CompletionStage最主要的实现类CompletionStage定义了异步阶段的交互规范,CompletableFuture提供了具体实现- 所有
CompletableFuture的异步能力都基于CompletionStage的方法
可以理解为:
CompletionStage是 “接口”,定义了异步流水线的操作规范;CompletableFuture是 “实现类”,提供了具体的异步执行能力。
3.2.4 CompletionStage获取对象姿势
1. 没有返回值
public static CompletableFuture<Void> runAsync(Runnable runnable) {return asyncRunStage(ASYNC_POOL, runnable);
}public static CompletableFuture<Void> runAsync(Runnable runnable,Executor executor) {return asyncRunStage(screenExecutor(executor), runnable);
}
2. 带有返回值
ublic static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {return asyncSupplyStage(ASYNC_POOL, supplier);
}public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier,Executor executor) {return asyncSupplyStage(screenExecutor(executor), supplier);
}