Day13_【DataFrame数据组合merge连接】【案例】
概述
在使用concat连接数据时,涉及到了参数join(join = 'inner',join = 'outer')
数据库中可以依据共有数据把两个或者多个数据表组合起来,即join操作
DataFrame 也可以实现类似数据库的join操作
Pandas可以通过pd.join命令组合数据,
也可以通过pd.merge命令组合数据
merge更灵活,如果想依据行索引来合并DataFrame可以考虑使用join函数
配置PyCharm 连接 Sqlite, 步骤类似于: PyCharm连接MySQL
import sqlite3# 1. 创建连接对象, 关联: Sqlite文件.
con = sqlite3.connect('data/chinook.db')
# 2. 读取SQL表数据, 参1: SQL语句, 参2: 连接对象
tracks = pd.read_sql_query('select * from tracks', con)
# track: 歌曲表
# 3. 查看数据.
tracks.head()# 4. read_sql_query()函数, 从数据库中读取表, 参1: SQL语句, 参2: 连接对象.
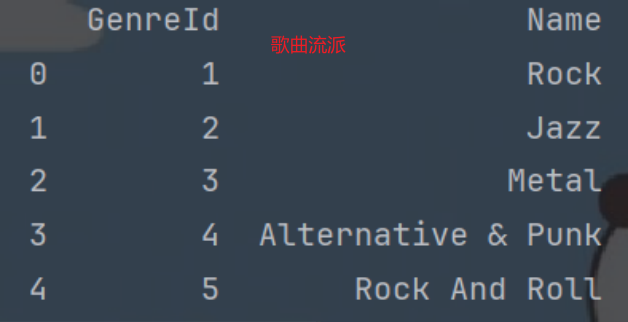
genres = pd.read_sql_query('select * from genres', con)
#genre:(歌曲流派)歌曲类别表
genres.head() # 数据介绍, 列1: 风格id, 列2: 风格名(爵士乐, 金属...)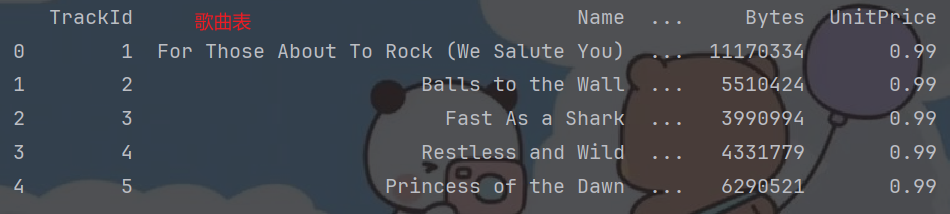
# 5. 从track表(歌曲表)提取部分数据, 使其不含重复的'GenreID'值
tracks_subset = tracks.loc[[0, 62, 76, 98, 110, 193, 204, 281, 322, 359], ]
print(tracks_subset)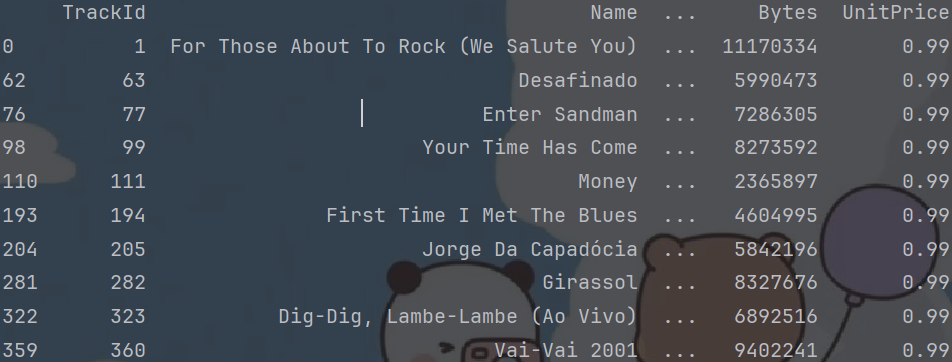
# 歌曲分类表.merge(歌曲表子集的 歌曲id, 分类id, 歌曲时长) on表示关联字段, how表示连接方式# inner 类似于SQL的 内连接, 即: 交集.
df1 = genres_df.merge(tracks_subset[["TrackId", "GenreId", "Milliseconds"]], on="GenreId", how="inner")# left 类似于SQL的 左外连接, 即: 左表的全集 + 交集.
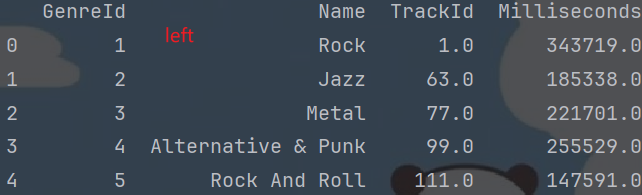
df2 = genres_df.merge(tracks_subset[["TrackId", "GenreId", "Milliseconds"]], on="GenreId", how="left")# right 类似于SQL的 右外连接, 即: 右表的全集 + 交集.
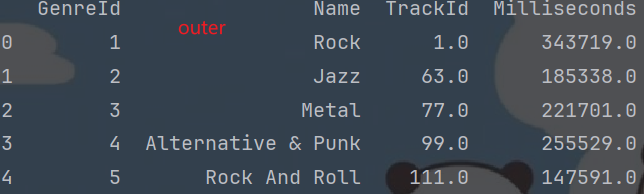
df3 = genres_df.merge(tracks_subset[["TrackId", "GenreId", "Milliseconds"]], on="GenreId", how="right")# outer 类似于SQL的 满外连接, 即: 左表的全集 + 右表全集 + 交集.
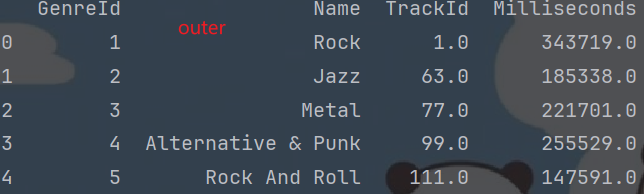
df4 = genres_df.merge(tracks_subset[["TrackId", "GenreId", "Milliseconds"]], on="GenreId", how="outer")print(df1.head())
print(df2.head())
print(df3.head())
print(df4.head())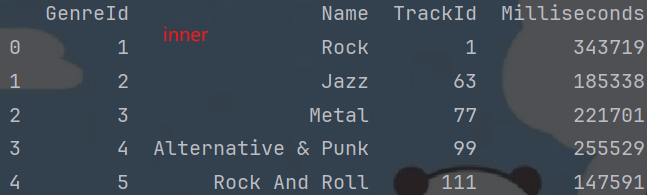
如果两张表有相同的列名, 则会分别给其加上 _x, _y的后缀, 来源于: merge()函数自带参数: suffixes
on 连接的字段, 如果左右两张表 连接的字段名字相同直接使用 on='关联字段名'
如果名字不同, left_on 写左表字段, right_on 写右表字段.
连接之后, 两张表中如果有相同名字的字段, 默认会加上后缀 默认值 x, _y
suffixes:(" x", "_ y")
df5 = genres_df.merge(tracks_subset[['TrackId', 'Name', 'GenreId', 'Milliseconds']], on='GenreId', how='inner')
# 查看 df5 的列名(合并后的结果)
print("\ndf5 列名:")
print(df5.columns.tolist())
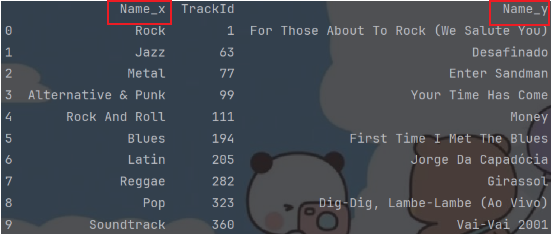
print(df5[['Name_x', 'TrackId', 'Name_y']])
【案例1】计算每种类型音乐的 平均时长
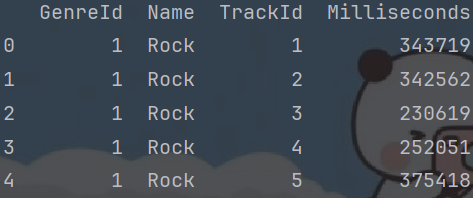
1: 将歌曲表tracks和歌曲类别表genres关联到一起
genres_track_df = genres_df.merge(tracks_df[["TrackId", "GenreId", "Milliseconds"]], on="GenreId", how="left")
print(genres_track_df.head())
2: 对关联后的结果进行分组,计算每个类型下歌曲的平均时长
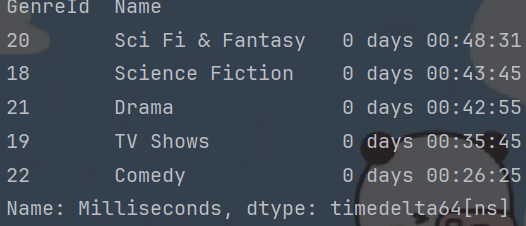
avg_series = genres_track_df.groupby(["GenreId", "Name"])["Milliseconds"].mean()
print(type(avg_series)) # series
print(avg_series.head())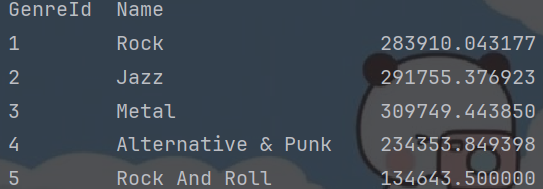
基于上述的数据,转换成日期格式
转换函数:pd.to_timedelta( )
格式:pd.to_timedelta(数据, unit='单位')
单位:s:秒,ms:毫秒,us:微秒,ns:纳秒
# 先将毫秒转换成秒
# dt.floor() 这里是截断意思,s表示秒,将毫秒截断为秒
rs1 = pd.to_timedelta(avg_series, unit="ms").dt.floor("s").sort_values(ascending=False)
print(rs1.head())