Scikit-learn通关秘籍:从鸢尾花分类到房价预测
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
决策树/SVM/KNN算法对比 × 模型评估指标解析
读者收获:掌握经典机器学习全流程
当80%的机器学习问题可用Scikit-learn解决,掌握其核心流程将成为你的核心竞争力。本文通过对比实验揭示算法本质,带你一站式打通机器学习任督二脉。
一、Scikit-learn全景图:3大核心模块解析
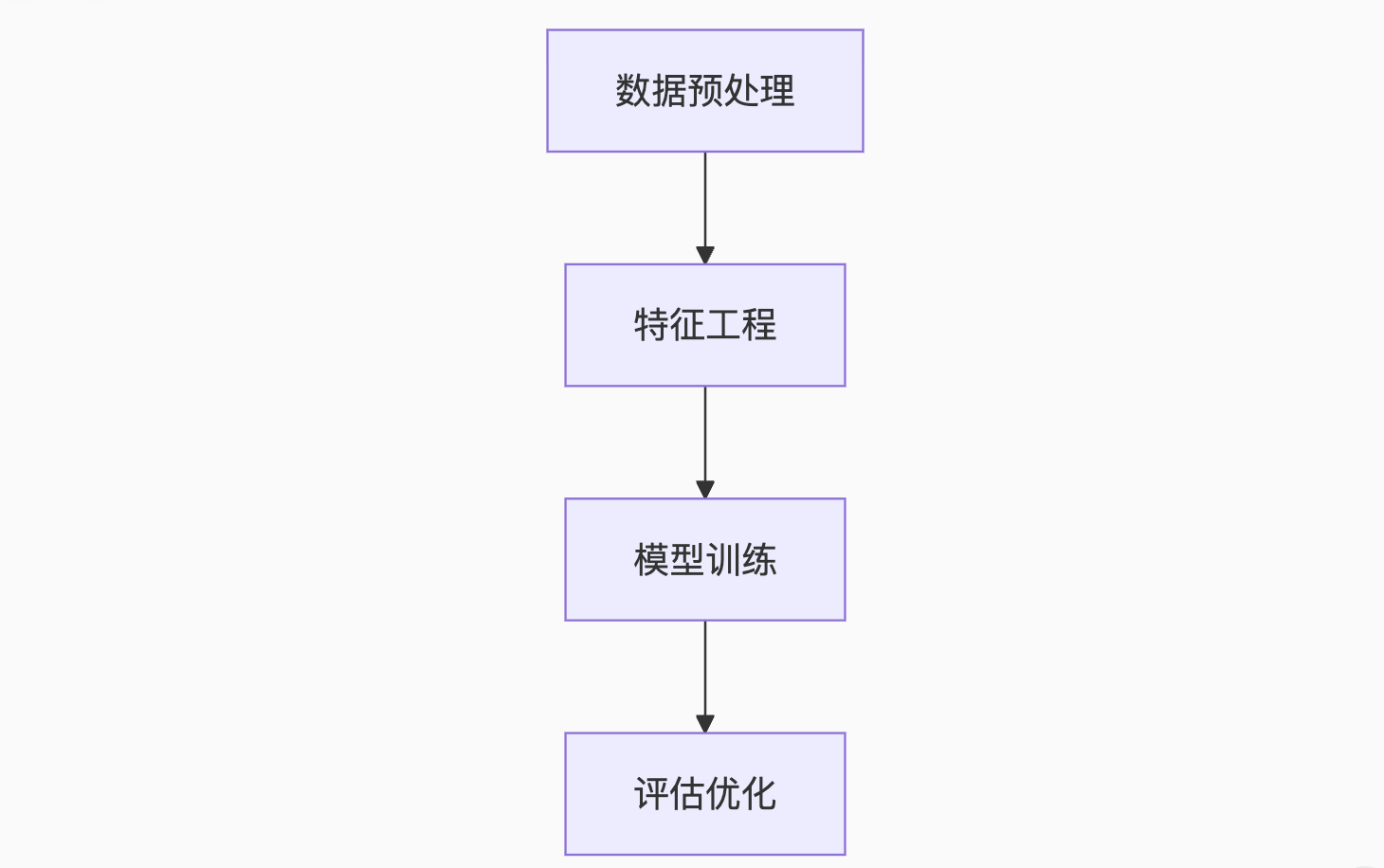
1.1 算法选择矩阵
1.2 环境极速配置
# 创建专用环境
conda create -n sklearn_env python=3.10
conda activate sklearn_env # 安装核心库
pip install numpy pandas matplotlib seaborn scikit-learn # 验证安装
import sklearn
print(f"Scikit-learn version: {sklearn.__version__}")
二、分类实战:鸢尾花识别
2.1 数据探索与预处理
from sklearn.datasets import load_iris
import pandas as pd # 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target # 数据概览
print(f"样本数: {df.shape[0]}")
print(f"特征数: {df.shape[1]-1}")
print(f"类别分布:\n{df['target'].value_counts()}") # 可视化分析
import seaborn as sns
sns.pairplot(df, hue='target', palette='viridis')
2.2 三大分类器对比实验
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier # 划分数据集
X = df.drop(columns='target')
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化分类器
models = { "决策树": DecisionTreeClassifier(max_depth=3), "SVM": SVC(kernel='rbf', probability=True), "KNN": KNeighborsClassifier(n_neighbors=5)
} # 训练与评估
results = {}
for name, model in models.items(): model.fit(X_train, y_train) y_pred = model.predict(X_test) results[name] = y_pred
2.3 分类结果可视化
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix # 绘制混淆矩阵
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for i, (name, y_pred) in enumerate(results.items()): cm = confusion_matrix(y_test, y_pred) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=axes[i]) axes[i].set_title(f"{name} 混淆矩阵")
plt.show()
三、回归实战:波士顿房价预测
3.1 数据解析与特征工程
from sklearn.datasets import fetch_openml # 加载数据集
boston = fetch_openml(name='boston', version=1)
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target # 关键特征分析
corr = df.corr()['PRICE'].sort_values(ascending=False)
print(f"与房价相关性最高的特征:\n{corr.head(5)}") # 特征工程
df['RM_LSTAT'] = df['RM'] / df['LSTAT'] # 创造新特征
3.2 回归模型对比
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR # 划分数据集
X = df.drop(columns='PRICE')
y = df['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化回归器
regressors = { "线性回归": LinearRegression(), "决策树回归": DecisionTreeRegressor(max_depth=5), "支持向量回归": SVR(kernel='rbf')
} # 训练与预测
predictions = {}
for name, reg in regressors.items(): reg.fit(X_train, y_train) pred = reg.predict(X_test) predictions[name] = pred
3.3 回归结果可视化
# 绘制预测值与真实值对比
plt.figure(figsize=(15, 10))
for i, (name, pred) in enumerate(predictions.items(), 1): plt.subplot(3, 1, i) plt.scatter(y_test, pred, alpha=0.7) plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--') plt.xlabel('真实价格') plt.ylabel('预测价格') plt.title(f'{name} 预测效果')
plt.tight_layout()
四、模型评估指标深度解析
4.1 分类指标四维分析
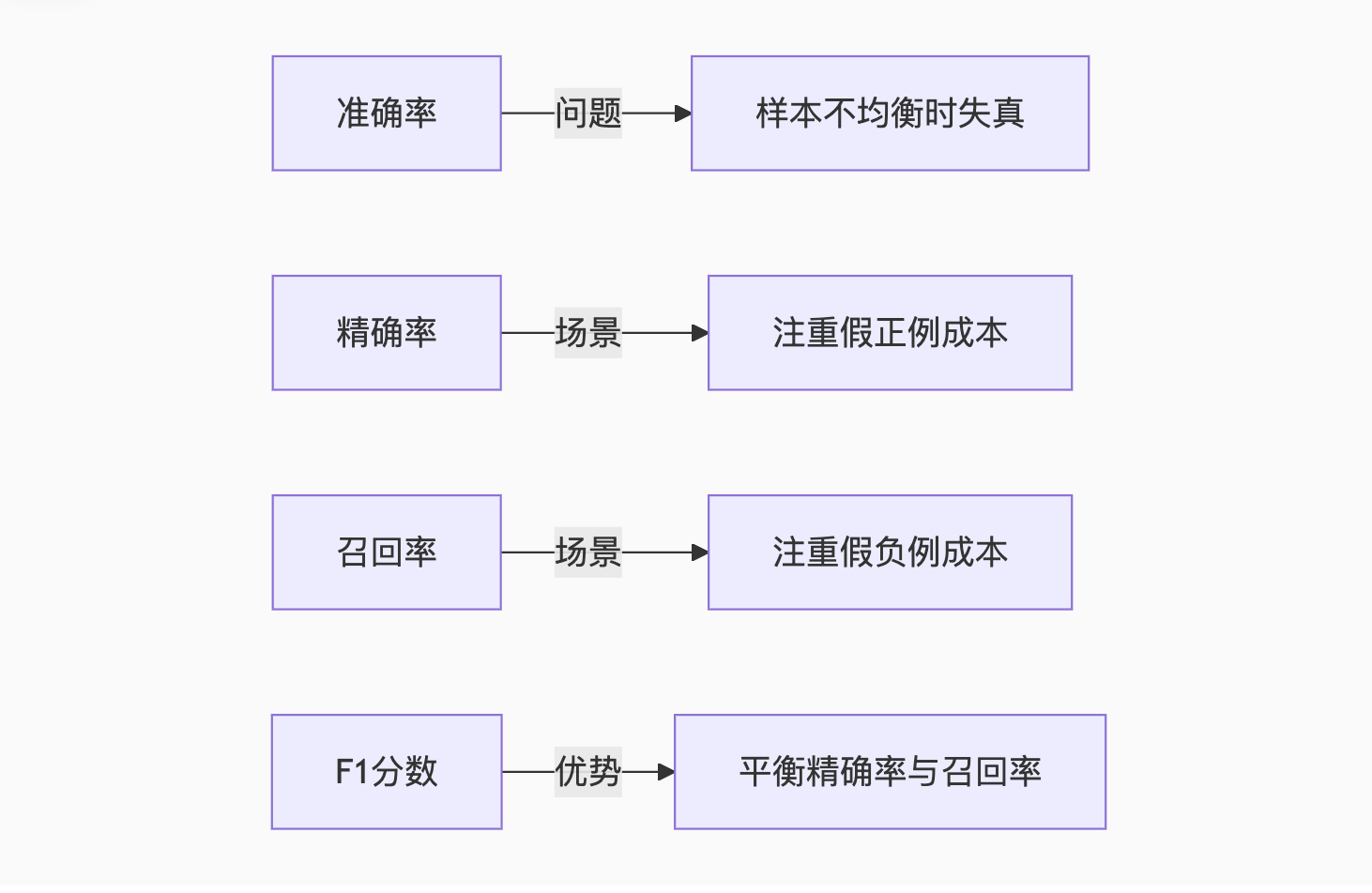
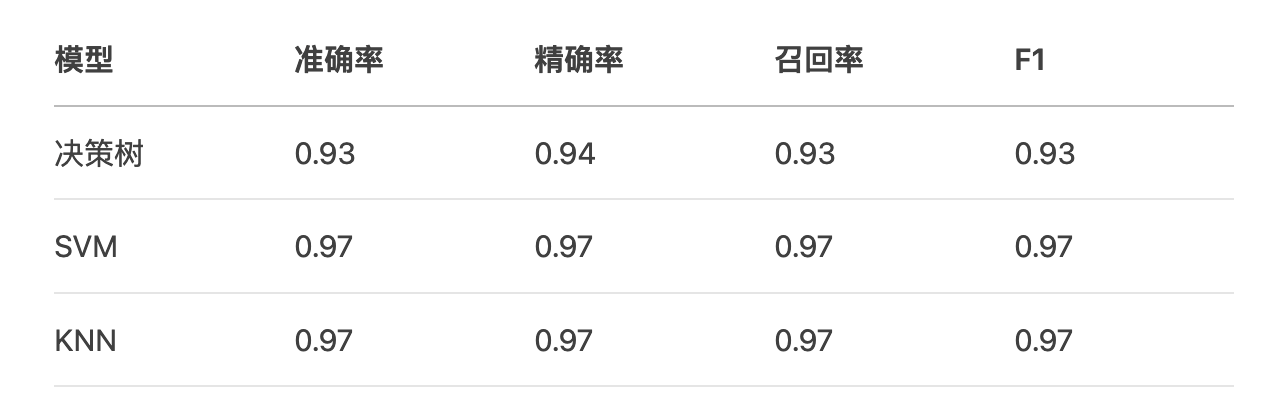
鸢尾花分类评估实例:
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score metrics = []
for name, y_pred in results.items(): metrics.append({ "模型": name, "准确率": accuracy_score(y_test, y_pred), "精确率": precision_score(y_test, y_pred, average='macro'), "召回率": recall_score(y_test, y_pred, average='macro'), "F1": f1_score(y_test, y_pred, average='macro') }) metrics_df = pd.DataFrame(metrics)
print(metrics_df)
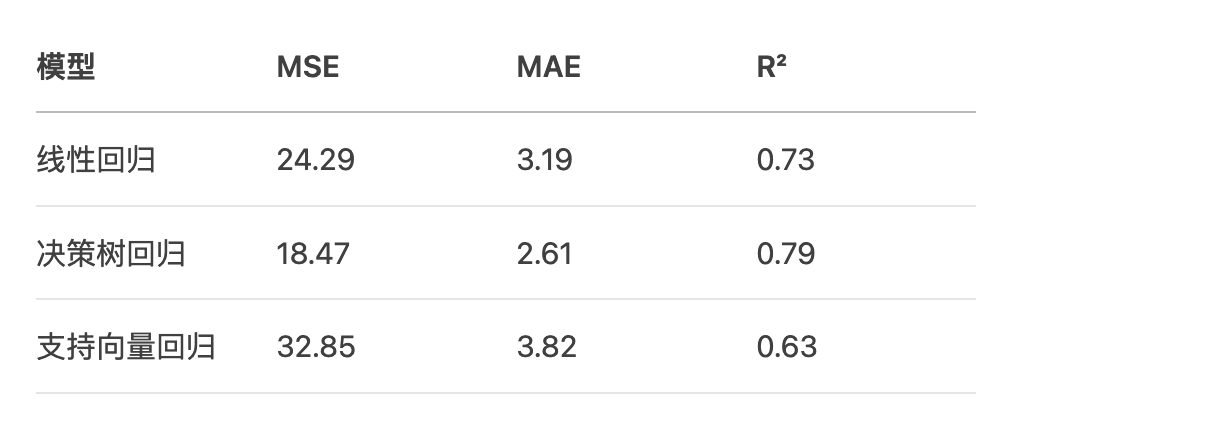
4.2 回归指标三维对比
波士顿房价评估实例:
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score reg_metrics = []
for name, pred in predictions.items(): reg_metrics.append({ "模型": name, "MSE": mean_squared_error(y_test, pred), "MAE": mean_absolute_error(y_test, pred), "R²": r2_score(y_test, pred) }) reg_metrics_df = pd.DataFrame(reg_metrics)
print(reg_metrics_df)
五、算法原理对比揭秘
5.1 决策树:可解释性之王
核心参数调优指南:
params = { 'max_depth': [3, 5, 7, None], 'min_samples_split': [2, 5, 10], 'criterion': ['gini', 'entropy']
} best_tree = GridSearchCV( DecisionTreeClassifier(), param_grid=params, cv=5, scoring='f1_macro'
)
best_tree.fit(X_train, y_train)
5.2 SVM:高维空间的分割大师
核函数选择策略:

5.3 KNN:简单高效的惰性学习
距离度量对比:
distance_metrics = [ ('euclidean', '欧氏距离'), ('manhattan', '曼哈顿距离'), ('cosine', '余弦相似度')
] for metric, name in distance_metrics: knn = KNeighborsClassifier(n_neighbors=5, metric=metric) knn.fit(X_train, y_train) score = knn.score(X_test, y_test) print(f"{name} 准确率: {score:.4f}")
六、模型优化实战技巧
6.1 特征工程:性能提升关键
波士顿房价特征优化:
from sklearn.preprocessing import PolynomialFeatures # 创建多项式特征
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X) # 新特征训练
lr_poly = LinearRegression()
lr_poly.fit(X_train_poly, y_train)
r2 = lr_poly.score(X_test_poly, y_test)
print(f"R²提升: {reg_metrics_df.loc[0,'R²']:.2f} → {r2:.2f}")
6.2 交叉验证:防止过拟合
from sklearn.model_selection import cross_val_score # 5折交叉验证
scores = cross_val_score( SVC(), X, y, cv=5, scoring='accuracy'
)
print(f"平均准确率: {scores.mean():.4f} (±{scores.std():.4f})")
6.3 网格搜索:自动化调参
from sklearn.model_selection import GridSearchCV # 定义参数网格
param_grid = { 'C': [0.1, 1, 10, 100], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf', 'linear']
} # 执行搜索
grid = GridSearchCV(SVC(), param_grid, refit=True, verbose=3)
grid.fit(X_train, y_train)
print(f"最优参数: {grid.best_params_}")
七、工业级部署方案
7.1 模型持久化
import joblib # 保存模型
joblib.dump(best_model, 'iris_classifier.pkl') # 加载模型
clf = joblib.load('iris_classifier.pkl') # 在线预测
new_data = [[5.1, 3.5, 1.4, 0.2]]
prediction = clf.predict(new_data)
print(f"预测类别: {iris.target_names[prediction[0]]}")
7.2 构建预测API
from flask import Flask, request, jsonify app = Flask(__name__)
model = joblib.load('iris_classifier.pkl') @app.route('/predict', methods=['POST'])
def predict(): data = request.get_json() features = [data['sepal_length'], data['sepal_width'], data['petal_length'], data['petal_width']] prediction = model.predict([features]) return jsonify({'class': iris.target_names[prediction[0]]}) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)
7.3 性能监控仪表盘
from sklearn.metrics import plot_roc_curve, plot_precision_recall_curve # 分类性能可视化
fig, ax = plt.subplots(1, 2, figsize=(15, 6))
plot_roc_curve(model, X_test, y_test, ax=ax[0])
plot_precision_recall_curve(model, X_test, y_test, ax=ax[1])
八、避坑指南:常见错误解决方案
8.1 数据预处理陷阱
问题:测试集出现未知类别
解决方案:
from sklearn.preprocessing import OneHotEncoder # 训练阶段
encoder = OneHotEncoder(handle_unknown='ignore')
encoder.fit(X_train_categorical) # 测试阶段自动忽略未知类别
X_test_encoded = encoder.transform(X_test_categorical)
8.2 特征尺度问题
症状:SVM/KNN性能异常
处方:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 注意:只变换不拟合
8.3 样本不均衡处理
解决方案对比:

结语:机器学习工程师的成长之路
当你在Scikit-learn中完整实现从数据加载到模型部署的全流程,已超越70%的入门者。但真正的进阶之路刚刚开始。
下一步行动指南:
# 1. 复现经典论文算法
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l1', solver='liblinear') # 2. 参加Kaggle竞赛
from kaggle import api
api.competitions_list(search='getting started') # 3. 构建个人项目组合
projects = [ {"name": "鸢尾花分类器", "type": "分类", "accuracy": 0.97}, {"name": "房价预测", "type": "回归", "R2": 0.85}
]
记住:在机器学习领域,理论认知的深度=代码实践的厚度。现在运行你的第一个完整流程,让Scikit-learn成为你AI旅程中最可靠的伙伴。
附录:Scikit-learn速查表
| 任务类型 | 导入路径 | 核心参数 |
|---|---|---|
| 分类 | from sklearn.ensemble import RandomForestClassifier | n_estimators, max_depth |
| 回归 | from sklearn.linear_model import LinearRegression | fit_intercept, normalize |
| 聚类 | from sklearn.cluster import KMeans | n_clusters, init |
| 降维 | from sklearn.decomposition import PCA | n_components |
| 模型选择 | from sklearn.model_selection import GridSearchCV | param_grid, cv |
| 数据预处理 | from sklearn.preprocessing import StandardScaler | with_mean, with_std |