从线性回归到神经网络到自注意力机制 —— 激活函数与参数的演进
在人工智能的发展历程中,线性回归 是最基础的模型,而 神经网络 则是现代大模型的核心。二者的联系和演进过程,能帮助我们更好地理解为什么大模型能“记住知识”和“推理”。
- 线性回归的起点
线性回归公式为:
y=w⋅x+b
x:输入特征(如身高)
y:预测结果(如体重)
w, b:参数,代表模型学习到的规律
这是一个一维映射,输入多少,输出多少,但它的能力有限。
- 多元线性回归
如果有多个输入特征,就成了 多元一次方程:
y=w1x1+w2x2+…+wnxn+b
比如预测房价:
𝑥1:面积
x2:地段评分
x3:房龄
输出:房价
这仍然是“线性”的,无法处理复杂的非线性关系。
这仍然是“线性”的,无法处理复杂的非线性关系。
- 激活函数的引入
为了让模型能拟合非线性模式,我们需要 激活函数,比如 Sigmoid:
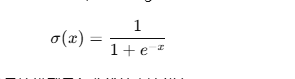
它能把线性输出压缩到 (0,1) 区间,并且让模型具备非线性表达能力。
比如:根据成绩预测“是否录取”,Sigmoid 就能把结果转化为概率。
- 从神经元到神经网络
一个神经元公式:
h=f(w⋅x+b)
其中 f 就是激活函数。
多个神经元堆叠,就形成了隐藏层。比如:
输入层:784 个节点(28×28 图像)
隐藏层 1:128 个神经元 + ReLU
隐藏层 2:64 个神经元 + ReLU
输出层:10 个神经元 + Softmax
这样,网络就能学习到复杂的规律,从简单的像素预测,到识别“这是 3 还是 8”。
为什么大模型能理解上下文 —— Self-Attention 机制详解
现代大语言模型(LLM)如 GPT、LLaMA、ChatGLM 等,都基于 Transformer 架构,其核心就是 Self-Attention 机制。这是模型能够“读懂上下文”的关键。
- Self-Attention 的直觉
在一句话里,每个词都和上下文其他词存在联系。
比如句子:
“我去银行存钱”
这里“银行”更可能指金融机构。
而在:
“我在河边的银行散步”
这里“银行”指的是河岸。
模型要做的就是:根据上下文,判断词与词之间的重要性。
- Q, K, V 的来源
对于输入的每个词向量(Embedding),模型会生成三个向量:
Query (Q):我要查什么?
Key (K):我能提供什么信息?
Value (V):我的内容是什么?
这三个向量由训练好的 权重矩阵 生成,因此是 模型参数的一部分。
- Attention 计算公式
Attention 的核心公式是:
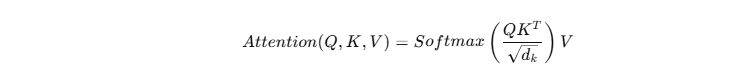
解释:
QKT:计算词与词的相关性(点积)
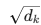
:归一化,防止数值过大
Softmax:转化为概率权重
乘以 V:得到加权后的信息
- 举个案例
输入句子:
“The cat sat on the mat”
当模型预测“sat”时,Q 会和上下文的 K 计算相关性:
“cat” 的 K 与 “sat” 高度相关 → 权重高
“mat” 的 K 相关性弱 → 权重低
最终,模型把更多注意力分配给“cat”,从而理解句子结构。
- 为什么能预测下一个词
通过多层堆叠,Attention 能让每个词都“看到”全局上下文。结合大规模数据训练,模型学会:
高频模式(语言语法)
长程依赖(前后文逻辑)
知识记忆(事实性信息)
这就是为什么大模型能一边理解上下文,一边预测下一个合理的词。