5. Dataloader 自定义数据集制作
1. 什么是Dataloader
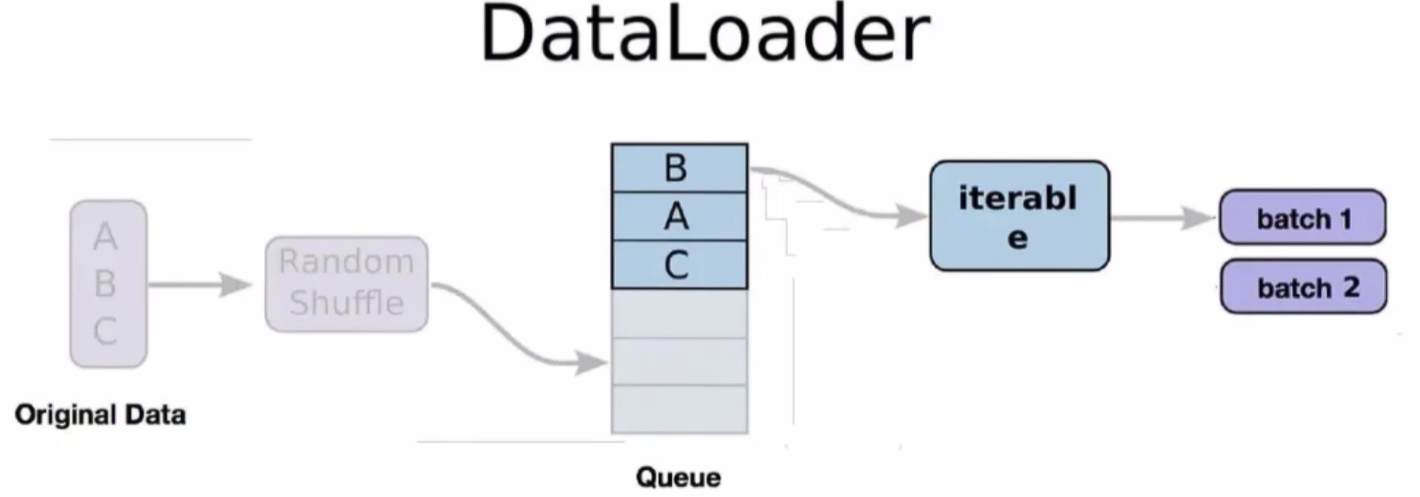
random shuffle 做一个随机打乱,一个一个 batch 从 queue 中取数据,这里需要能够快速的把数据打包好给训练器。
Dataloader 就是 pytorch 提供的一种 非常快速的供给数据 的方法。
2. 详细组成
以上节的花朵图片分类为例
2.1 读取txt文件中的路径和标签
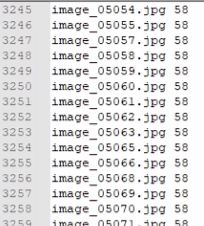 txt的部分数据
txt的部分数据

分隔符是“空格”,外部用 list 组织起来,每行都存到 list 中,最后根据 k/v 存到字典中返回。

dataloader 中需要有两个list,一个是图像路径 list,一个是标签 list。
2.2 分别把数据和标签存在list里
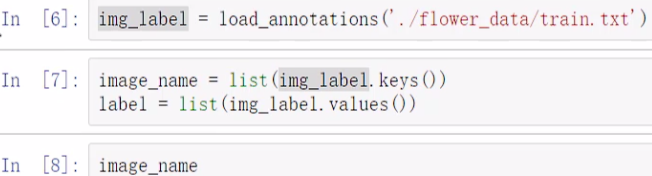
如果只有名字是找不到图片的,需要路径
2.3 设置图像数据路径

2.4 把上面几个写在一起
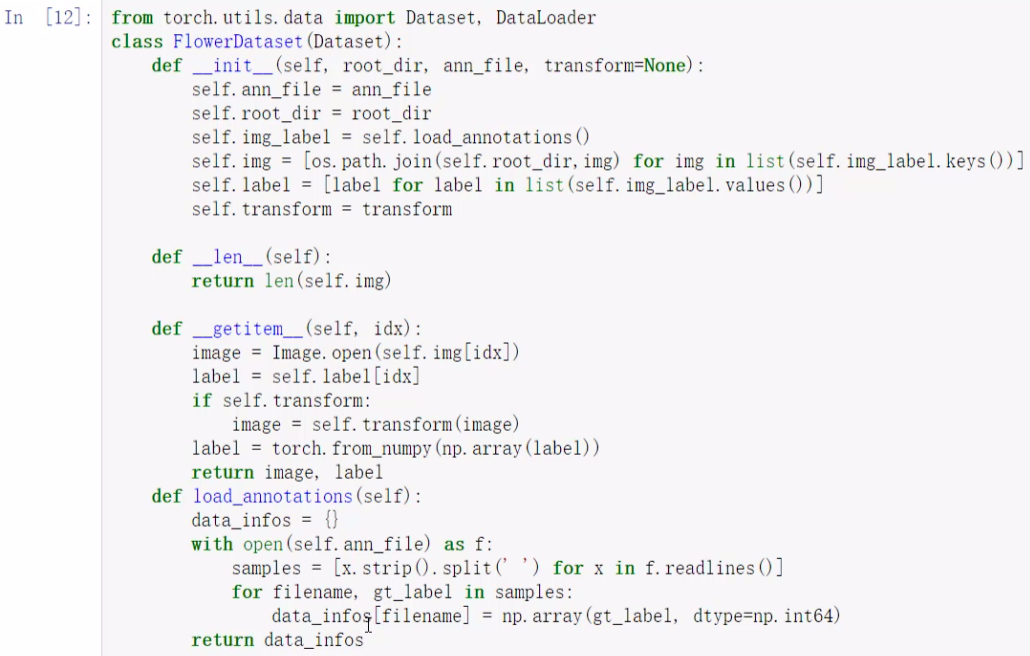
构造函数:
- 构造两个list,图像路径和标签
- transform是预处理
getitem:
他会一个一个数据处理去返回一个batch,每次调用它会传一个随机的idx,会找到idx指向的图片、标签,然后图像做个预处理(包括了转成tensor),标签直接读成tensor,然后返回。
2.5 数据预处理(transform)

这个和上节讲的差不多
3. 实例化dataloader
用torch自带的DataLoader方法实例化。
4. 先实验以下,整个数据和标签对不对的上
构造好之后这个dataloader需要进一步检查

每次 next 就会取一个batch的数据。这里取一个图片,然后看看对应的标签是什么,检查对不对。
之后的步骤和上节是一样的。只是单纯的用了我们自己定义的 dataloader