PyTorch数据处理工具箱详解|深入理解torchvision与torch.utils.data
在深度学习的旅程中,数据处理是构建模型前不可或缺的一环。PyTorch 提供了一系列高效、灵活的数据处理工具,帮助开发者更便捷地完成数据装载、预处理、增强等任务。本文将围绕 PyTorch 中的核心数据处理工具 torch.utils.data 与 torchvision 展开详细介绍,并帮助读者理解它们之间的关系和使用场景。
一、核心数据处理引擎:torch.utils.data
位于图4-1左侧的是 PyTorch 提供的基础数据处理模块 torch.utils.data,它为数据集的定义、迭代、采样等提供了一系列类和函数。主要包括以下四个核心类:
1. Dataset(数据集抽象基类)
Dataset是一个抽象类,所有自定义数据集都应继承此类。- 需要实现以下两个方法:
__getitem__(self, index):根据索引返回单个样本;__len__(self):返回数据集的总样本数。
- 作用:定义如何访问单个样本,是构建数据集的基础。
2. DataLoader(数据加载器)
DataLoader是一个迭代器,用于按批次(batch)加载数据。- 支持功能:
- 批量读取(batching)
- 数据打乱(shuffle)
- 并行加载(num_workers)
- 作用:将原始数据封装为可批量读取的数据流,是训练过程中的“数据管道”。
3. random_split(数据集划分工具)
- 可将一个数据集随机拆分为多个子集,如训练集、验证集和测试集。
- 保证子集之间无交集,适用于数据分割、交叉验证等场景。
- 示例:
train_dataset, val_dataset = random_split(full_dataset, [50000, 10000])
4. Sampler(采样器)
Sampler是一系列采样策略类,控制数据的读取顺序。- 常见采样器包括:
SequentialSampler:顺序采样RandomSampler:随机采样SubsetRandomSampler:从子集中随机采样WeightedRandomSampler:带权重的随机采样
- 作用:在 DataLoader 中自定义采样逻辑,提升训练灵活性。
二、视觉处理工具箱:torchvision
中间部分介绍的是 torchvision,作为 PyTorch 的视觉扩展库,它独立于 PyTorch 主库,需通过以下命令单独安装:
pip install torchvision
或使用 conda 安装
conda install torchvision
torchvision 主要包含四大类功能模块,分别用于数据集处理、模型调用、图像预处理和图像操作。
1. datasets(常用视觉数据集)
- 提供了多个标准数据集接口,如:
- MNIST(手写数字识别)
- CIFAR-10 / CIFAR-100(彩色图像分类)
- ImageNet(大规模图像分类)
- COCO(目标检测与图像描述)
- 所有数据集都继承自
torch.utils.data.Dataset,可无缝接入DataLoader。 - 优势:一键加载、统一接口、节省开发时间。
2. models(经典模型与预训练网络)
- 包含大量经典神经网络结构,如:
- AlexNet、VGG、ResNet、Inception 等
- 支持加载预训练模型(设置
pretrained=True),便于迁移学习。 - 示例:
import torchvision.models as models model = models.resnet18(pretrained=True)
3. transforms(图像变换操作)
- 提供对图像进行预处理和增强的功能。
- 支持的操作类型包括:
- 对 PIL 图像的操作(如 Resize、Crop、Normalize)
- 对 Tensor 的操作(如 ToTensor)
- 示例:
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])
4. utils(图像辅助工具)
- 提供两个实用函数:
make_grid(images, nrow=8):将多张图像拼接成一个网格图像;save_image(tensor, filename):将 Tensor 保存为图片文件。
- 常用于可视化训练结果、图像比较等。
三、整体关系图解(图4-1)
下图展示了 PyTorch 数据处理工具之间的关系:
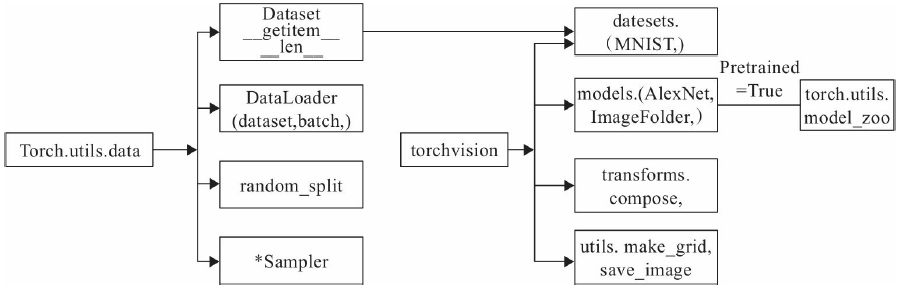
- 左侧为 torch.utils.data 提供的基础数据接口;
- 中间为 torchvision 提供的视觉专用功能;
- 右侧为用户自定义数据集或第三方数据集的接入路径;
- 整体构成了一个从数据准备到模型训练的完整流程。
四、实际应用建议与技巧
1. 数据集封装技巧:
- 自定义数据集时务必继承
Dataset,并实现__len__和__getitem__方法; - 可结合
torchvision.io或PIL读取图像数据。
2. 数据增强建议:
- 预处理过程中,应优先使用
transforms模块; - 使用
RandomHorizontalFlip、ColorJitter等增强手段提升模型泛化能力。
3. 数据加载优化:
- 使用
DataLoader时,合理设置num_workers提高加载效率; - 在训练阶段开启
shuffle=True,避免模型过拟合。
4. 模型迁移学习:
- 使用
torchvision.models中的预训练模型时,注意输入图像的归一化参数; - 可冻结部分层,仅训练顶层分类器。
5. 图像可视化技巧:
- 使用
make_grid将训练过程中的生成图像或预测图像拼接为网格; - 使用
save_image保存中间结果,便于调试与展示。
五、总结
PyTorch 的数据处理工具体系结构清晰、模块化强,为图像深度学习提供了强大的支持。其中:
- torch.utils.data 是构建数据流的基础模块;
- torchvision 是视觉任务的“瑞士军刀”,提供数据集、模型、变换和图像操作等多种功能;
- 合理使用这些工具,可以显著提升开发效率与模型性能。
掌握这些工具不仅是构建项目的基础,更是深入理解 PyTorch 生态的重要一步。希望本文能帮助你更好地理解和应用 PyTorch 的数据处理机制。