Redis-缓存-穿透-布隆过滤器
Redis-缓存-穿透-布隆过滤器[RedisBloom 模块]
- 1、来因宫:为啥项目要用缓存???
- 2、问题:什么现象叫缓存穿透?碰到后怎么选择?一键复原 OR 尝试拯救??
- 3、选择:放弃 OR 拯救
- 4、解题思路:如何拯救?从哪下手?
- 5、解题助手:AI助手、百度等等
- 6、工具:Redis 布隆过滤器
- 6.1、定义
- 6.2、涉及到名解释
- 6.3、代码实现
- 6.3.1、依赖
- 6.3.2、配置Redis参数
- 6.3.3、创建布隆过滤器配置类
- 6.3.4、业务实现
- 6.3.5、控制器
- 7、总结
1、来因宫:为啥项目要用缓存???
自动带入自己个的业务哈,想想哪些业务能用到~
我在这里用我实际的业务进行举例:
在APP中,【地区招录公告、新闻资讯、优惠活动】等模块,就存在周期性大批量用户进行查看,为了减轻数据库的访问压力,将数据放入到Redis缓存中。
注:
Redis 是基于内存的数据库,读写速度通常在微秒级(约 10⁻⁶秒)
传统关系型数据库(如 MySQL)基于磁盘存储,读写速度在毫秒级(约 10⁻³ 秒)
两者相差近千倍
2、问题:什么现象叫缓存穿透?碰到后怎么选择?一键复原 OR 尝试拯救??
现象描述:
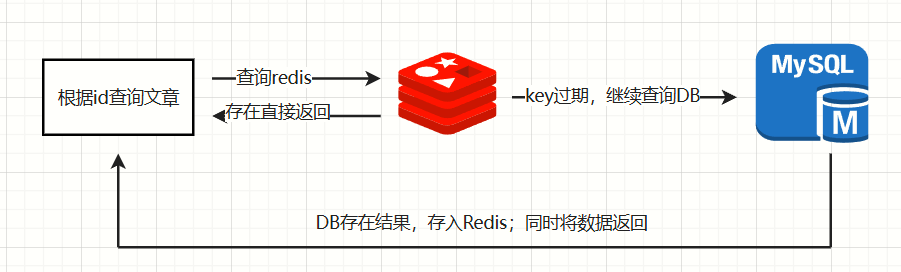
查询文章详情基本都是通过id检索,
1、程序设计首先是访问redis读取对应的缓存数据,存在就返回
2、redis不存在数据,进行数据库检索,同时将检索的的数据存入redis中,方便下次读取
3、若查询id并不存在于数据库中,频繁查询调用数据库,加重数据库压力
3、选择:放弃 OR 拯救
已知:Redis读写速度 是 传统关系型数据库 近千倍!
所以:尝试拯救一下!
4、解题思路:如何拯救?从哪下手?
分析一下:
1、redis作用失效,频繁访问数据库资源
2、先让业务不要频繁访问数据库,减少数据库压力
3、出现穿透情况,让redis重新发挥作用
4、最简单的思路,将每次查询为空的id以及null数据也存储到redis 当中,redis重新发挥作用;可以解决问题,但是有一些弊端:redis数据量可能会出现暴增!存在有人恶意访问!增加redis的压力
5、解题助手:AI助手、百度等等
1、使用AI进行问题描述,不需要知道专业名词,也能解决问题

2、知道存在问题,直接百度找解决方案
6、工具:Redis 布隆过滤器
6.1、定义
它是一个数组,索引从0开始,值只有0和1 两个参数
检验一个id(文章id)是否存在,需要多个索引值进行校验,value值同时为1说明数据存在
布隆过滤器存在误判率,这个误判率我们可以手动去设置
下面的图示,描述一个id对应的值,然后进行判断
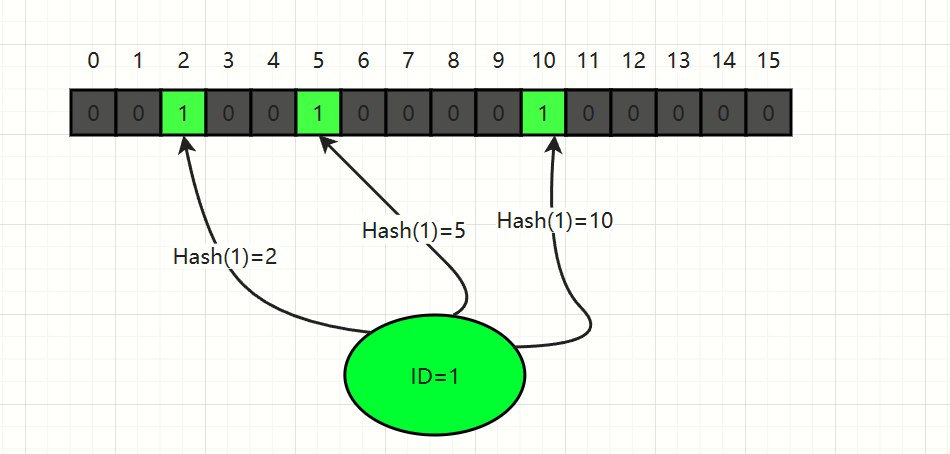
若id为1获取到的是索引0、1、2的参数值,那么说明当前的id为1的参数不存在
6.2、涉及到名解释
初次看到布隆过滤器,我想到的一些问题:
为啥一个参数需要多个索引值进行判断?
为啥会存在误判?
我能控制误判率么?
…
通过下面的一些解释,就会明白他的工作原理,心里就跟明镜似的
预期元素数量:就是指我们初步需要将多少数据放入到这个数组当中,我们记作 n
位数组长度:这个布隆数组的长度是多少,记作m
假阳性概率:就是我们前面说的误判率,我们记作p
现在我们已知预期的元素数量【n】,以及我们可以设置的误判率【p】
可以得到 :
数组长度【m】 ≈ -n × ln§ / (ln2)²
所以:预期数量越大,误判率要求越低,数组的长度就越大!
还有一个参数 哈希函数的个数:K。也就是前期说的,一个参数需要查询几个索引去确定当前数据是否存在;
K过小:元素映射的位置少,容易和其他元素的位置重叠,导致假阳性概率升高;
K过大:每个元素需要计算更多哈希值,增加时间开销,且会更快填满位数组(反而提高假阳性概率)。
最优值计算:当n和m确定后,最优K的公式为:
K ≈ (m / n) × ln2
实际的K值一般都是通过计算得到,我们在使用的过程中非必要情况下不用进行手动设置。
6.3、代码实现
我是java开发,我就按照我的思路进行实现
6.3.1、依赖
需要查找对应的依赖,方式也同上AI检索或者百度,找到自己合适的就行
可在 maven仓库 进行查询合适版本
<dependencies><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.45.1</version></dependency>
</dependencies>
6.3.2、配置Redis参数
在resource目录下,找到我们的配置文件配置修改redis信息
# Redis服务器地址
spring.redis.host=localhost
# Redis服务器端口
spring.redis.port=6379
# Redis密码(如果没有密码可以省略)
# spring.redis.password=yourpassword
# Redis数据库索引(默认为0)
spring.redis.database=0
# 连接超时时间(毫秒)
spring.redis.timeout=3000
6.3.3、创建布隆过滤器配置类
@Configuration
public class BloomFilterConfig {/*** 初始化布隆过滤器* @param redissonClient Redisson客户端* @return 布隆过滤器实例*/@Beanpublic RBloomFilter<String> stringBloomFilter(RedissonClient redissonClient) {// 创建布隆过滤器,指定名称RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("userFilter");// 初始化布隆过滤器// 第一个参数:预计元素数量// 第二个参数:期望误判率bloomFilter.tryInit(1000000, 0.01);return bloomFilter;}
}
6.3.4、业务实现
我这里只单独写一个service类,大家根据自己的代码层级进行创建所需的接口以及实现类
@Service
public class BloomFilterService {private final RBloomFilter<String> bloomFilter;@Autowiredpublic BloomFilterService(RBloomFilter<String> bloomFilter) {this.bloomFilter = bloomFilter;}/*** 向布隆过滤器添加元素* @param element 要添加的元素*/public void addElement(String element) {bloomFilter.add(element);}/*** 批量添加元素* @param elements 元素数组*/public void addElements(String... elements) {for (String element : elements) {bloomFilter.add(element);}}/*** 判断元素是否可能存在* @param element 要检查的元素* @return true: 可能存在; false: 一定不存在*/public boolean mightContain(String element) {return bloomFilter.contains(element);}/*** 获取布隆过滤器的预计元素数量* @return 预计元素数量*/public long getExpectedInsertions() {return bloomFilter.getExpectedInsertions();}/*** 获取布隆过滤器的误判率* @return 误判率*/public double getFalseProbability() {return bloomFilter.getFalseProbability();}/*** 获取当前布隆过滤器中的元素数量* @return 元素数量*/public long count() {return bloomFilter.count();}
}
6.3.5、控制器
@RestController
@RequestMapping("/bloom")
public class BloomFilterController {private final BloomFilterService bloomFilterService;@Autowiredpublic BloomFilterController(BloomFilterService bloomFilterService) {this.bloomFilterService = bloomFilterService;}/*** 添加元素到布隆过滤器*/@PostMapping("/add")public String addElement(@RequestParam String element) {bloomFilterService.addElement(element);return "元素 '" + element + "' 已添加到布隆过滤器";}/*** 检查元素是否可能存在*/@GetMapping("/check")public String checkElement(@RequestParam String element) {boolean mightExist = bloomFilterService.mightContain(element);if (mightExist) {return "元素 '" + element + "' 可能存在于布隆过滤器中";} else {return "元素 '" + element + "' 一定不存在于布隆过滤器中";}}/*** 获取布隆过滤器信息*/@GetMapping("/info")public String getInfo() {StringBuilder info = new StringBuilder();info.append("布隆过滤器信息:\n");info.append("预计元素数量: ").append(bloomFilterService.getExpectedInsertions()).append("\n");info.append("误判率: ").append(bloomFilterService.getFalseProbability()).append("\n");info.append("当前元素数量: ").append(bloomFilterService.count()).append("\n");return info.toString();}
}
7、总结
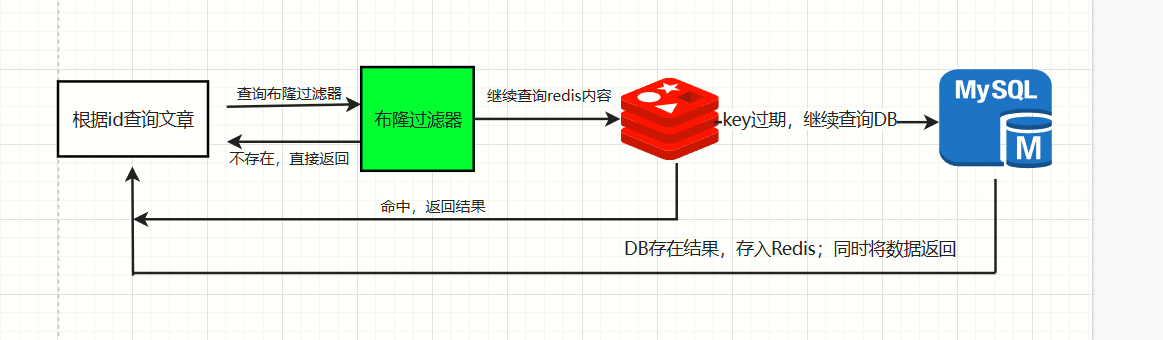
以上的代码实现都是基础最简单的路线,具体的大家可自行嵌入到自己的逻辑当中,比如我们在启动程序初始化的过程就需要将所需的数据放到布隆控制器中,后续的管理员在添加的时候同步到过滤器当中,这都是我们需要考虑到的。
加入过滤器后的处理流程:
说说他的缺点:
在我们实际使用的过程中,考虑业务量的大小以及用户量一些因素,可以选择不同的解决方案;
1、实现稍微复杂点,需要加入一些其他的技术模块
2、存在误判,看我们实际需要吧!
感想:
1、一般存在这种情况下,可能是一些人的恶意操作,她知道我们的请求路径
2、在我们实际的项目中,如果存在识别ip访问限制,熔断等一些机制也可能减少这种情况的出现
3、对请求链接以及参数进行加密保护,不要使用明文!
今天就到这里~拜拜
希望大家多多提一些建议,有什么需要改进的地方
我不是技术大拿,一些过滤器的底层原理没有过深的研究,我明前只保证看到能用
能比较清晰的理解这个东西
看过之后方便大家上手理解 ~