实习两个月总结
目录
1.业务熟悉
1.1司测流水线
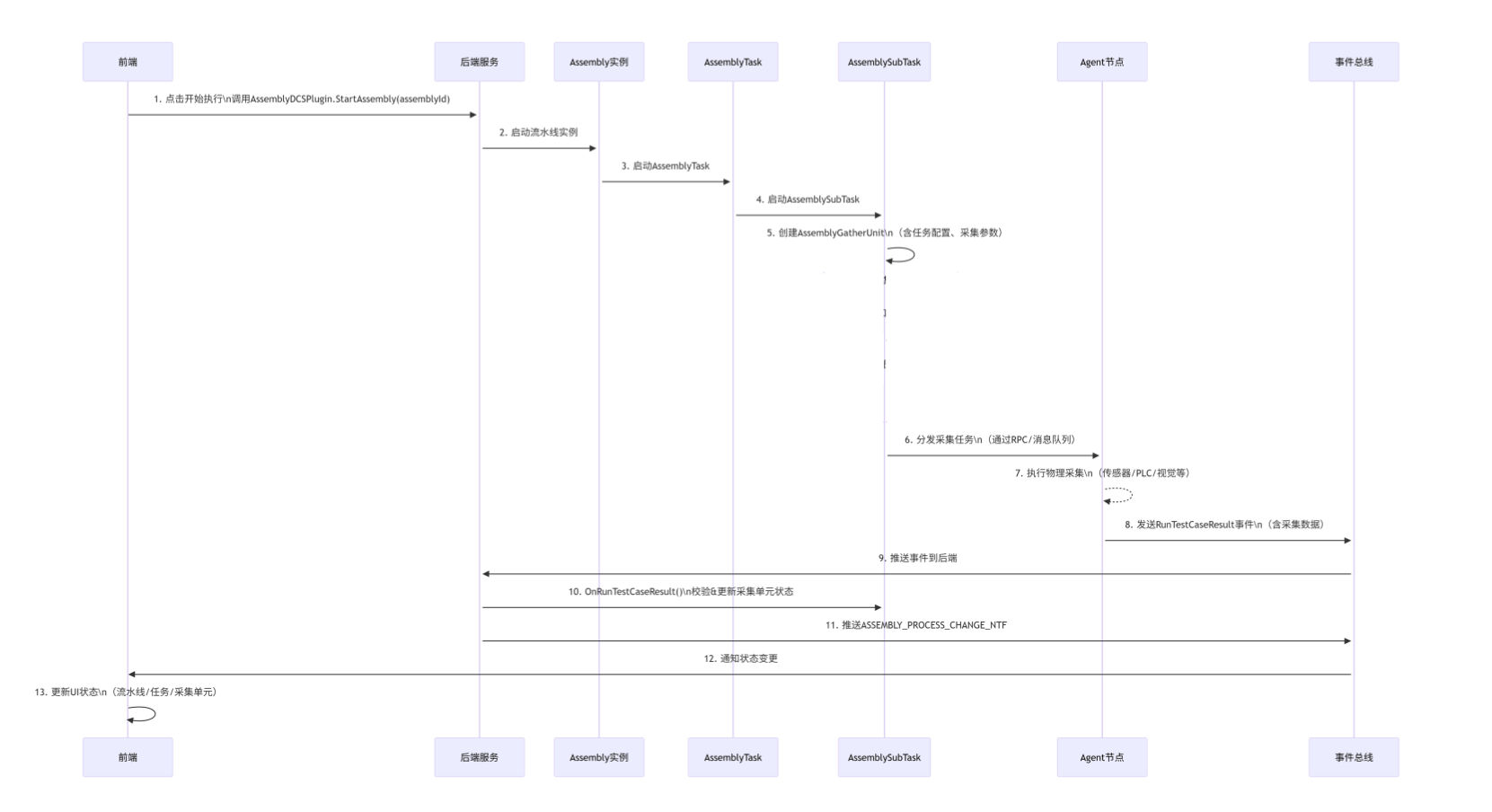
1.2工作台
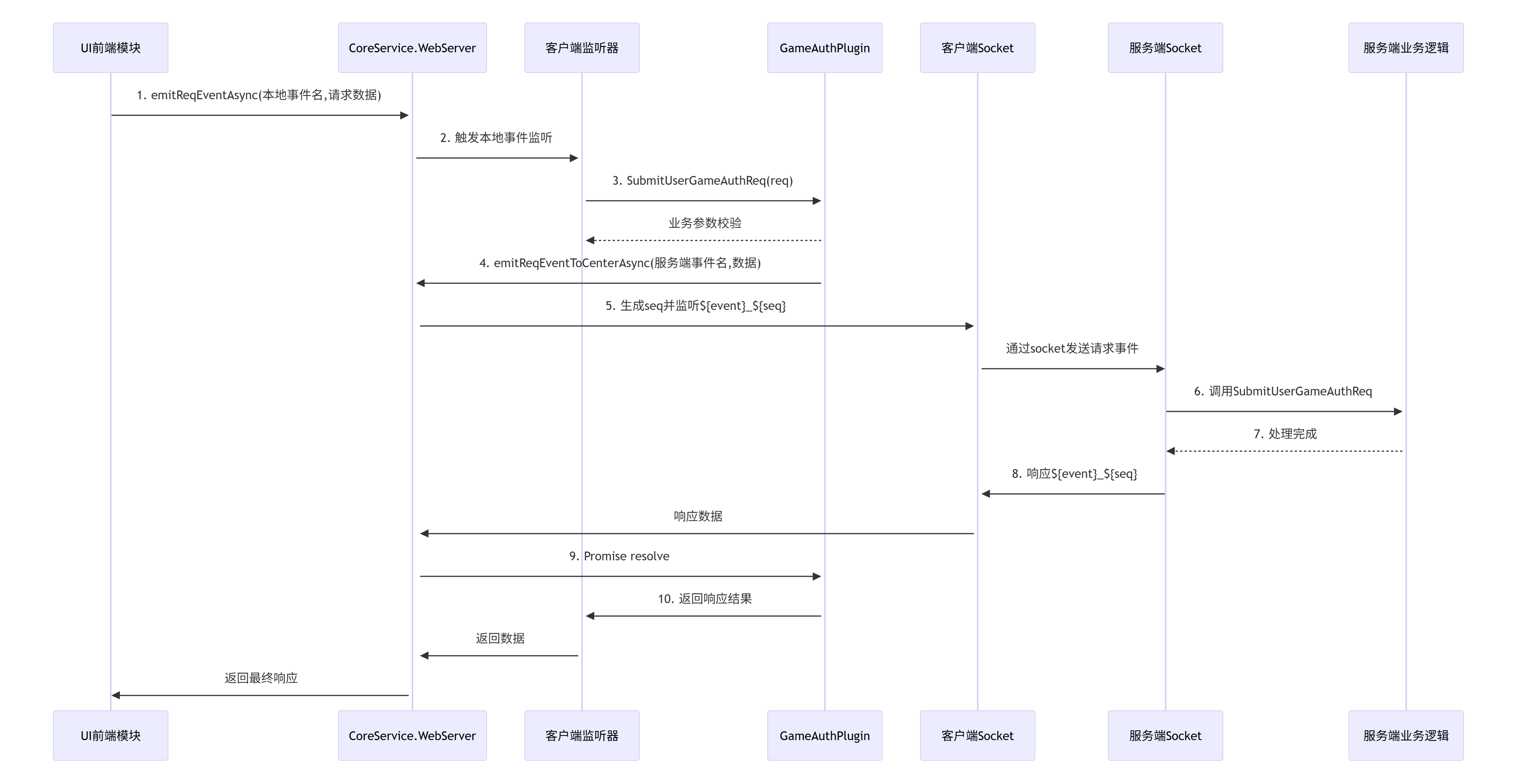
1.3数据中心
2.技术学习
2.1HTTP
2.2mongodb
2.3Node.js
3.需求开发
3.1工作台游戏权限申请Gopenid简单校验
3.2简单记录流水线编辑历史
3.3优化日志查看过慢
3.4设备池分组名排序优化
3.5CP与导师关系
3.6资源路径查询
1.业务熟悉
1.1司测流水线
基于ActionTestPictureByFenxi:
(1)Agent触发、采集、上报流程:
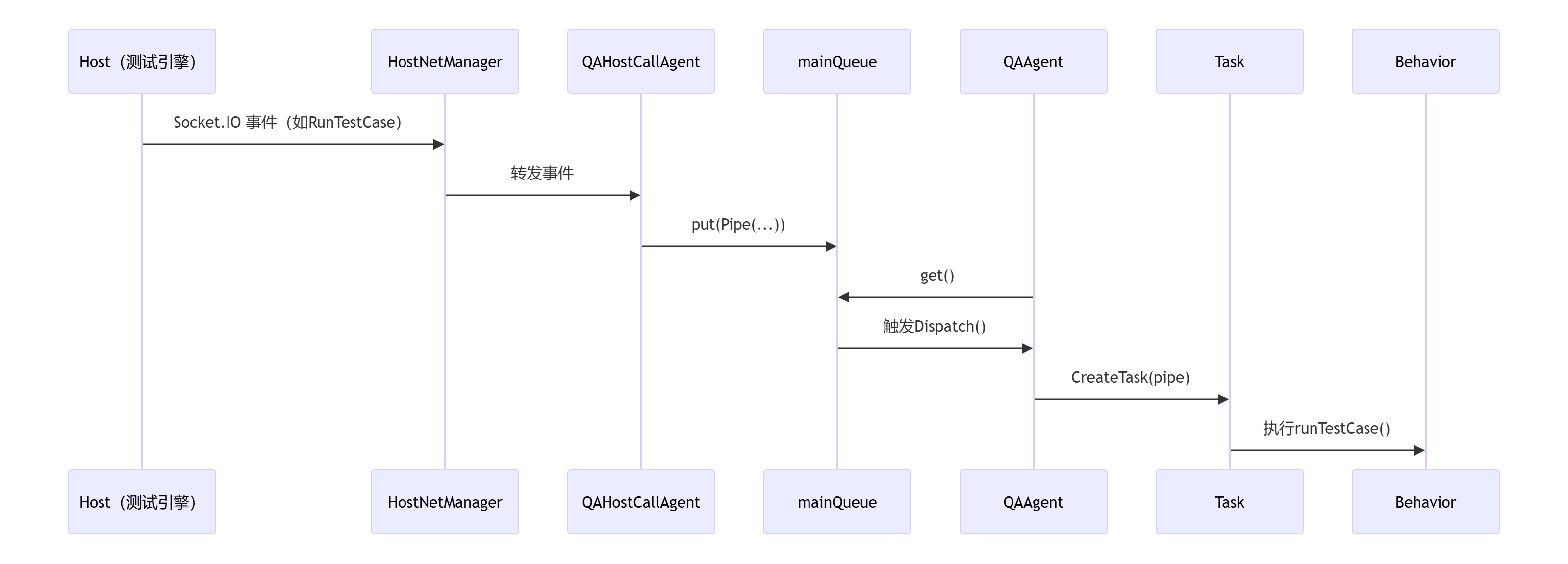
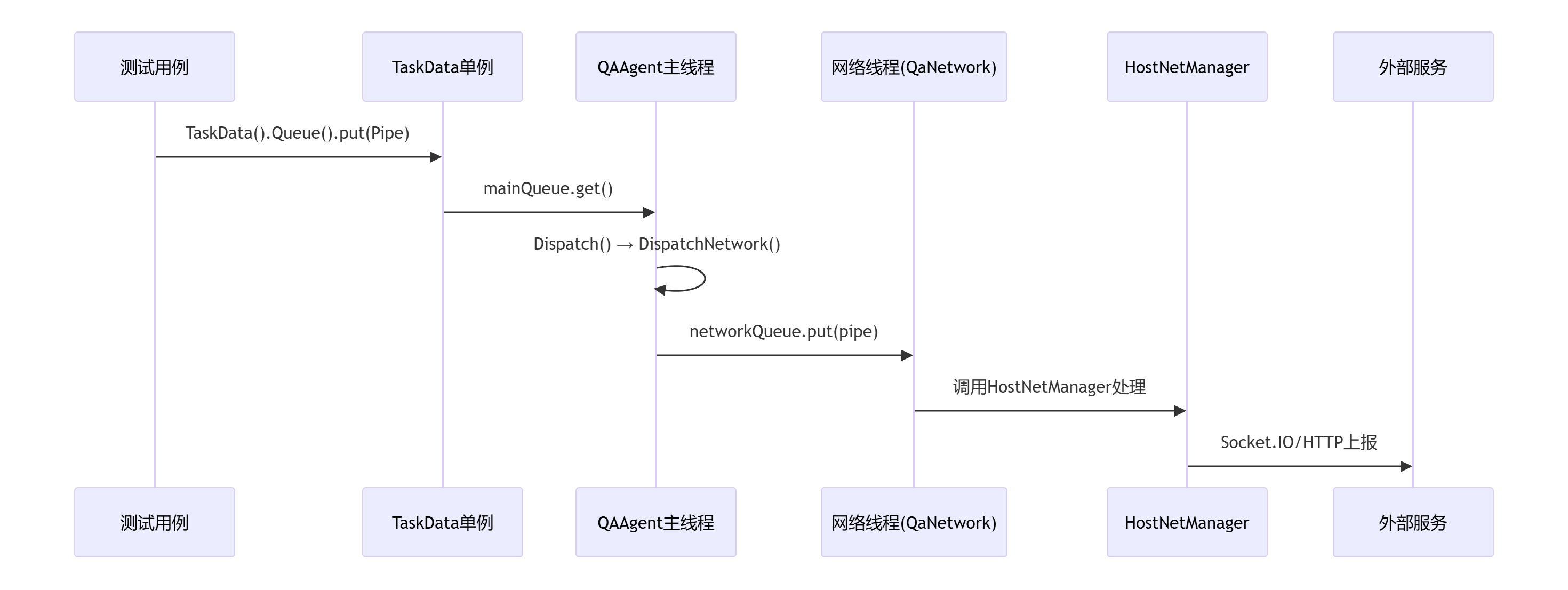
(2)Host端触发、分发Agent、收集结果、通知前端:
1.2工作台
前端-客户端-服务端模式
1.3数据中心
基于司测框架
2.技术学习
2.1HTTP
2.1.1网页资源加载和呈现流程
2.1.2Http请求和响应的组成
- HTTP 响应由两部分组成:
- 响应头:告诉浏览器内容类型、编码、缓存等信息。
- 响应体(Response Body):实际的内容,比如 HTML、JSON、图片等。
2.1.3Get请求与Post请求的区别
| 请求类型 | 参数传递位置 | requests 参数 | 传输格式示例 |
| GET | URL 查询字符串 | params | ?key1=value1&key2=value2 |
| POST | 请求体 | data 或 json | 表单格式( key1=value1&key2=value2 )或 JSON 格式 |
2.1.4 Http请求携带参数
| 参数 | 作用 | 适用请求类型 | 传入数据类型 | 发送方式 |
| params | URL 查询参数 | GET、DELETE 等 | dict、list、bytes | 编码成 URL 查询字符串,附加在 URL 后面 |
| data | 请求体数据(表单或原始数据) | POST、PUT、PATCH | dict、bytes、文件 | 以表单格式或原始格式放在请求体中发送 |
| json | 请求体 JSON 数据 | POST、PUT、PATCH | Python 对象(dict) | 自动编码成 JSON,设置 Content-Type |
2.2mongodb
2.2.1 mongodb常用指令
增删查改、建索引.....
2.2.2 mongodb索引
单键索引、复合索引、唯一索引....
2.3Node.js
2.3.1Node.js核心机制
1. 调用栈(Call Stack)
2. 事件队列(Event Queue / Task Queue)
3. 事件循环(Event Loop)
-
事件循环的核心职责是:不断监视调用栈是否为空。
-
当调用栈为空时,事件循环会从事件队列中取出第一个任务(回调函数)放入调用栈执行。
-
这样保证了异步回调不会打断当前正在执行的同步代码。
2.3.2 async与await字段

2.3.3回调函数
回调函数(callback)就是作为参数传递给另一个函数的函数,用来在某个时刻被调用。
3.需求开发
3.1工作台游戏权限申请Gopenid简单校验
任务:对Gopenid的大小进行限制(Uint64)
调试收获:
1.在客户端打印返回值进行判断服务器的处理结果
2.在前端(ApplyAuth.tsx)即控制台打印消息log进行判断客户端的返回值
开发收获:
在客户端先做校验进行过滤,确保请求参数合法(减小服务端压力)
再在服务端添加校验,防止部分用户未更新客户端造成遗漏
对校验字符进行数字转化后比较 ;BigInt()函数:可转化无限大的数值
对代码公用部分尽量做到复用
3.2简单记录流水线编辑历史
任务:记录流水线编辑操作的信息,在修改流水线成功时保存相关信息
开发收获:
建立流水线id和修改时间的联合索引,后续可查某条流水线的最近修改/某段时间修改记录
掌握司测QAD开发模式,用于声明DAO层数据结构,表结构。
掌握司测插件注册管理,通过coreService统一调用。
3.3优化日志查看过慢
任务:为日志查看建立硬盘缓存
开发收获:
在不同的编码格式下,中英文字符占用的字节数不同,例:1个UFT-16的编码单元占两个字节。
掌握司测QAP开发模式,用于声明协议、req、rsp,封装请求响应。
优化方案采用建立硬盘缓存日志文件,用队列+LRU的方式进行淘汰缓存,map内存缓存用来管理硬盘缓存淘汰。
3.4设备池分组名排序优化
任务:全部分组在最前面,公共分组次之,新增分组在最后面,其它分组按照字典序排列
开发收获:
掌握sort()函数进行排序
3.5CP与导师关系
任务:腾讯文档更新入库、CP/非CP用户查询
开发收获:
WSD/WSP是工作台中定义协议和数据的文件,司测用的是QAD/QAP。
数据库采用增量更新时,筛选条件必须唯一,如果筛选出多条就会导致不准确。
将CP与普通用户合为一张表,建立userType+userName的复合唯一索引,在查询时联合查询。
调用腾讯文档API进行获取数据时:req格式、rsp格式、接口错误信息(阅读API文档获得)
3.6资源路径查询
任务:按日期获取某个分支下的某个类型下的所有异常资源路径、某个资源路径的具体异常信息
涉及多表查询,需要先从第一张表中根据req字段定位一条资源,再去第二张表中查看这条资源的多条扫描结果,再去第三张表中查具体扫描结果中是否含异常信息。
开发收获:
涉及到的数据库表数据量较大(数百万),在用查第二张表的结果集查第三张表时会过慢,聚合keys进行查询,分次访问数据库频次过多会卡顿,将查得结果集再分类即可。
但速度仍旧比较慢,引入内存缓存缓解多次请求时过慢问题,但在初次请求仍旧耗时。(需求方表示按照此方案,可以接受数据量大时响应慢)
联调收获:
功能实现的基础上,一定要注意性能消耗、响应时间,是否在需求方接受的范围内。
关于需求确认、原模块实现要和相关人员提前沟通,经过转述会导致较大偏差,影响效率。