PyTorch数据处理工具箱(数据处理工具箱概述)
数据处理工具箱概述
通过第3章,读者应该对torchvision、data等数据处理包有了初步的认识,但可能理解
还不够深入,接下来我们将详细介绍。PyTorch涉及数据处理(数据装载、数据预处理、
数据增强等)主要工具包及相互关系如图4-1所示。
图4-1的左边是torch.utils.data工具包,它包括以下4个类。
1)Dataset:是一个抽象类,其他数据集需要继承这个类,并且覆写其中的两个方法
(getitem_、len)。
2)DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据
(shuffle)并提供并行加速等功能。
3)random_split:把数据集随机拆分为给定长度的非重叠的新数据集。
4)*sampler:多种采样函数。
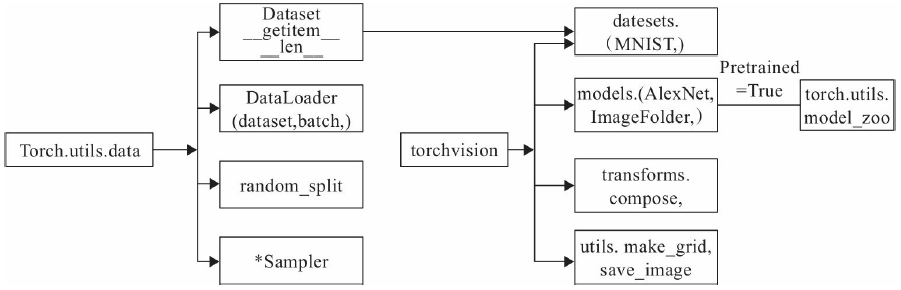
图4-1中间是PyTorch可视化处理工具(Torchvision),其是PyTorch的一个视觉处理
工具包,独立于PyTorch,需要另外安装,使用pip或conda安装即可
pip install torchvision #或conda install torchvision
它包括4个类,各类的主要功能如下。
1)datasets:提供常用的数据集加载,设计上都是继承自torch.utils.data.Dataset,主要
包括MMIST、CIFAR10/100、ImageNet和COCO等。
2)models:提供深度学习中各种经典的网络结构以及训练好的模型(如果选择
pretrained=True),包括AlexNet、VGG系列、ResNet系列、Inception系列等。
3)transforms:常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
4)utils:含两个函数,一个是make_grid,它能将多张图片拼接在一个网格中;另一
个是save_img,它能将Tensor保存成图片。