Java-101 深入浅出 MySQL InnoDB 锁机制全景图:行锁原理、Next-Key Lock、Gap Lock 详解
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!“快的模型 + 深度思考模型 + 实时路由”,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到:
Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

锁机制
锁分类
在 MySQL 中锁有很多不同的分类。
粒度区分
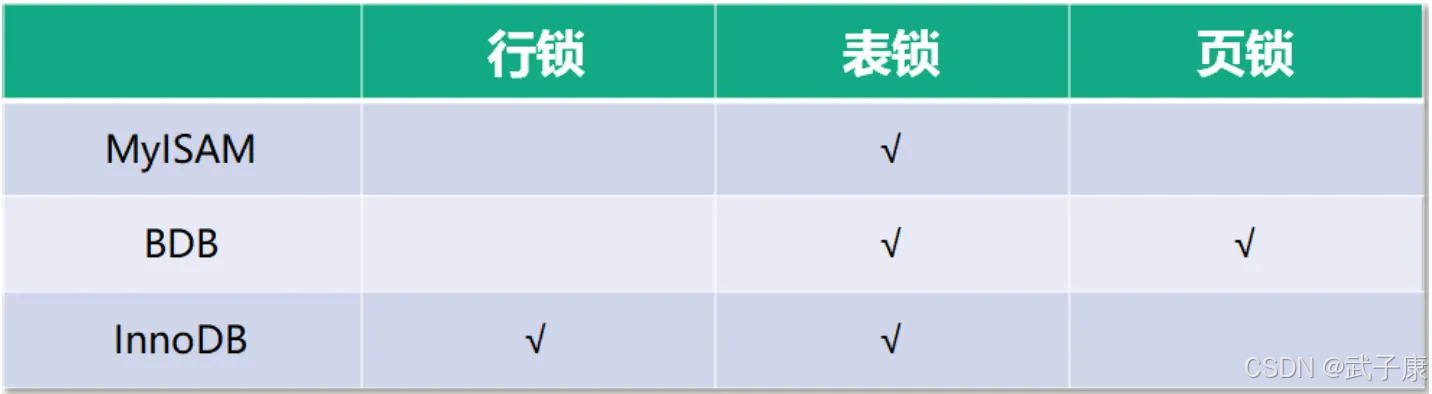
从操作的粒度可以分为:表级锁、行级锁、页级锁三种主要类型:
● 表级锁(Table-level Locking):
- 基本特性:每次操作会锁住整张表,是最粗粒度的锁机制
- 性能特点:锁定粒度大,系统开销小,加锁快,但并发性能差
- 冲突概率:发生锁冲突的概率最高,容易出现阻塞等待
- 典型应用:主要用于MyISAM、Memory等非事务型存储引擎,在InnoDB中也会在特定场景使用(如DDL操作)
- 使用场景:适合读多写少、对并发要求不高的操作,如数据仓库报表查询
● 行级锁(Row-level Locking):
- 基本特性:每次操作只锁住需要访问的行记录
- 性能特点:锁定粒度最小,系统开销大,加锁慢,但并发性能最优
- 冲突概率:发生锁冲突的概率最低,不同事务可以同时修改不同行
- 实现机制:InnoDB通过索引项加锁实现行锁,如果没有使用索引会退化为表锁
- 典型应用:InnoDB存储引擎的默认锁机制
- 使用场景:适合高并发、事务型的OLTP系统,如电商订单系统
● 页级锁(Page-level Locking):
- 基本特性:每次锁定相邻的一组记录(通常是4KB的存储页)
- 性能特点:锁定粒度中等,开销和加锁时间介于表锁和行锁之间
- 冲突概率:并发度一般,比表锁高但低于行锁
- 典型应用:BDB(Berkeley DB)存储引擎使用这种锁机制
- 特殊说明:在MySQL中较少使用,因为BDB引擎已逐渐被淘汰
补充说明:
- 不同粒度的锁各有优劣,需要根据具体业务场景选择
- 现代数据库系统通常支持多种锁粒度,如InnoDB同时支持表锁和行锁
- 锁升级机制:当行锁数量达到阈值时,数据库可能自动升级为表锁以提高性能
类型区分
数据库锁机制详解
基本锁类型
读锁(S锁/共享锁)
读锁是一种共享锁,允许多个事务同时读取同一份数据而不会互相干扰。典型应用场景包括:
- 报表生成:多个用户同时查询销售数据生成报表
- 数据统计:并发执行多个统计查询操作
特点:
- 多个事务可以同时持有同一数据的S锁
- 事务持有S锁期间,其他事务可以继续获取S锁
- 事务持有S锁期间,其他事务不能获取X锁
写锁(X锁/排他锁)
写锁是一种排他锁,用于保证数据修改时的独占性。典型应用场景包括:
- 订单处理:防止多个用户同时修改同一订单
- 库存扣减:确保库存数量变更的原子性
特点:
- 同一时间只有一个事务可以持有某数据的X锁
- 事务持有X锁期间,其他事务无法获取该数据的S锁或X锁
- 事务持有X锁期间,可以同时进行读和写操作
锁的层级关系
意向锁(IS、IX锁)
意向锁是表级锁,用于提高锁检测效率:
IS锁(意向共享锁):
- 在对表记录添加S锁之前,会先获取表的IS锁
- 表示事务有意向在表的某些行上加S锁
- 示例:
SELECT * FROM table WHERE id=1 LOCK IN SHARE MODE
IX锁(意向排他锁):
- 在对表记录添加X锁之前,会先获取表的IX锁
- 表示事务有意向在表的某些行上加X锁
- 示例:
UPDATE table SET column=value WHERE id=1
锁兼容矩阵
| 请求\持有 | 无锁 | IS | IX | S | X |
|---|---|---|---|---|---|
| IS | ✓ | ✓ | ✓ | ✓ | ✗ |
| IX | ✓ | ✓ | ✓ | ✗ | ✗ |
| S | ✓ | ✓ | ✗ | ✓ | ✗ |
| X | ✓ | ✗ | ✗ | ✗ | ✗ |
行级锁详解
S锁(共享锁)工作流程
- 事务A执行:
SELECT * FROM accounts WHERE id=1 LOCK IN SHARE MODE - 数据库先在accounts表上加IS锁
- 然后在id=1的记录上加S锁
- 事务B可以同时执行相同的语句获取S锁
- 但如果事务B尝试获取X锁(如UPDATE),必须等待事务A释放S锁
X锁(排他锁)工作流程
- 事务A执行:
UPDATE accounts SET balance=1000 WHERE id=1 - 数据库先在accounts表上加IX锁
- 然后在id=1的记录上加X锁
- 事务B尝试读取或修改该记录时都会被阻塞
- 直到事务A提交或回滚释放X锁
实际应用示例
银行转账场景:
-- 事务1
BEGIN;
SELECT balance FROM accounts WHERE id=1 FOR UPDATE; -- 获取X锁
UPDATE accounts SET balance = balance - 100 WHERE id=1;
-- 此时其他事务无法读取或修改id=1的记录-- 事务2(并发执行)
BEGIN;
SELECT balance FROM accounts WHERE id=1; -- 普通SELECT可以执行
SELECT balance FROM accounts WHERE id=1 FOR UPDATE; -- 会被阻塞
报表查询场景:
-- 事务1(报表生成)
BEGIN;
SELECT * FROM sales LOCK IN SHARE MODE; -- 获取S锁
-- 可以与其他只读事务并发执行-- 事务2(数据维护)
BEGIN;
UPDATE sales SET amount=200 WHERE id=5; -- 需要等待S锁释放
性能区分
从操作的性能角度可以分为乐观锁和悲观锁两种并发控制策略:
● 乐观锁(Optimistic Locking):
这是一种假设并发冲突发生概率较低的锁机制,其核心思想是不加锁直接操作,在提交时进行冲突检测。常见实现方式包括:
- 版本号机制:为每条记录增加一个version字段,每次更新时先读取版本号,更新时检查版本号是否改变
- 时间戳机制:使用最后修改时间戳作为版本标识
- 条件更新:在更新语句中加入原始值作为条件判断
应用场景:适用于读多写少、冲突率低的场景,如电商库存系统(在用户下单时检查库存版本)、文档协作编辑等。例如:
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 100 AND version = 5
如果返回影响行数为0,说明数据已被其他事务修改,需要提示用户"库存已发生变化,请刷新重试"。
● 悲观锁(Pessimistic Locking):
这是一种假设并发冲突必然发生的保守策略,在执行操作前先获取锁,确保排他访问。主要分为:
- 共享锁(S锁):允许多个事务同时读取,但阻止其他事务获取排他锁
- 排他锁(X锁):阻止其他事务获取任何锁,保证独占访问
实现方式包括:
- 数据库行锁:SELECT … FOR UPDATE
- 表锁:LOCK TABLES
- 应用层互斥锁
应用场景:适用于写操作频繁、冲突概率高的场景,如银行转账、票务系统等。例如:
BEGIN;
SELECT * FROM accounts WHERE id = 1 FOR UPDATE; -- 获取排他锁
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
COMMIT;
两种锁机制各有优劣:乐观锁性能更好但需要处理冲突重试,悲观锁能避免冲突但会降低并发度。实际选择需要根据业务场景的读写比例、冲突概率和性能要求综合考量。
行锁原理
InnoDB 行锁是通过对索引数据页上的记录加锁实现的,主要实现的算法有三种:
-
Record Lock(记录锁)
- 锁定单个行记录的锁,仅锁住索引记录本身
- 支持事务隔离级别:RC(读已提交)和 RR(可重复读)
- 实现方式:当使用唯一索引进行精确查询(如 where id = 1)时,InnoDB 会使用记录锁
- 示例:事务A执行
SELECT * FROM users WHERE id = 1 FOR UPDATE,只会锁住id=1这一行记录
-
Gap Lock(间隙锁)
- 锁定索引记录之间的间隙,防止其他事务在这个间隙中插入新记录
- 仅支持RR(可重复读)隔离级别
- 实现方式:锁定一个范围但不包括记录本身
- 典型应用场景:防止幻读问题
- 示例:表中有id为1,3,5的记录,执行
SELECT * FROM users WHERE id > 1 AND id < 5 FOR UPDATE会锁定(1,3)和(3,5)这两个间隙
-
Next-Key Lock(临键锁)
- Record Lock 和 Gap Lock 的组合,既锁住记录本身,也锁住记录之前的间隙
- 仅支持RR(可重复读)隔离级别
- InnoDB 默认的行锁算法
- 实现方式:对于索引记录R,临键锁会锁定R前面的间隙+R记录本身
- 示例:表中有id为1,3,5的记录,执行
SELECT * FROM users WHERE id = 3 FOR UPDATE会锁定(1,3]这个区间
补充说明:
- 在InnoDB中,行锁都是加在索引上的
- 如果没有索引或无法使用索引,InnoDB会退化为表锁
- 不同事务隔离级别下锁的行为不同:RC级别下只有记录锁,RR级别会有三种锁
- 锁的兼容性:共享锁之间兼容,排他锁与其他锁都不兼容
在 RR 隔离级别,InnoDB 对于记录加锁行为都是先采用 NextKey Lock,但是当 SQL 操作含有唯一索引时,InnoDB 会对 NextKey Lock进行优化,降级为 RecordLock,仅锁住索引本身而非范围。
InnoDB 锁机制详解
SELECT FROM 语句
InnoDB 引擎采用 MVCC(多版本并发控制)机制实现非阻塞读。对于普通的 SELECT 查询语句(如 SELECT * FROM table_name WHERE id=1),InnoDB 不会施加任何锁,而是通过读取事务开始时的快照数据来实现一致性读取。这使得读操作不会阻塞写操作,写操作也不会阻塞读操作,极大提高了并发性能。
SELECT FROM lock in share mode 语句
当使用 SELECT * FROM table_name WHERE id=1 LOCK IN SHARE MODE 语法时,InnoDB 会为查询结果集中的记录追加共享锁(S锁)。这种锁机制的特点是:
- 使用 NextKey Lock(临键锁)进行处理,锁住记录本身和记录之前的间隙
- 如果扫描发现查询条件使用了唯一索引(如主键或唯一约束),则会自动降级为 RecordLock(记录锁)
- 多个事务可以同时获取同一记录的共享锁
- 常用于需要确保查询期间数据不被其他事务修改的场景
SELECT FROM for update 语句
当使用 SELECT * FROM table_name WHERE id=1 FOR UPDATE 语法时,InnoDB 会为查询结果集中的记录追加排他锁(X锁)。这种锁机制的特点是:
- 默认使用 NextKey Lock 进行处理
- 如果扫描发现查询条件使用了唯一索引,会自动降级为 RecordLock
- 排他锁会阻塞其他事务获取相同记录的共享锁或排他锁
- 常用于需要先查询后更新的业务场景
UPDATE WHERE 语句
在执行 UPDATE table_name SET column=value WHERE condition 语句时,InnoDB 的锁机制如下:
- 使用 NextKey Lock 对符合 WHERE 条件的记录加锁
- 如果 WHERE 条件使用了唯一索引,会自动降级为 RecordLock
- 在事务提交前,这些锁会一直保持
- 如果更新操作导致索引键值变化,还会对相关索引记录加锁
DELETE WHERE 语句
在执行 DELETE FROM table_name WHERE condition 语句时,InnoDB 的锁机制与 UPDATE 类似:
- 使用 NextKey Lock 对符合 WHERE 条件的记录加锁
- 如果 WHERE 条件使用了唯一索引,会自动降级为 RecordLock
- 删除操作会同时锁定主键索引和所有二级索引中的相关记录
- 在事务提交前,这些锁会一直保持
INSERT 语句
在执行 INSERT INTO table_name (...) VALUES (...) 语句时,InnoDB 的锁机制如下:
- 对将要插入的新行设置排他的 RecordLock
- 在插入操作完成前,其他事务无法访问或修改该行
- 如果插入操作导致唯一键冲突,会短暂获取共享锁来检查冲突
- 在事务提交前,这些锁会一直保持
- 对于自增主键,还会对自增计数器加锁,防止并发插入导致的值冲突
这里按 UPDATE t1 SET name=‘xx’ where id = 10 为例子,举例分析 InnoDB 对不同索引加锁,以 RR 隔离级别为例子。
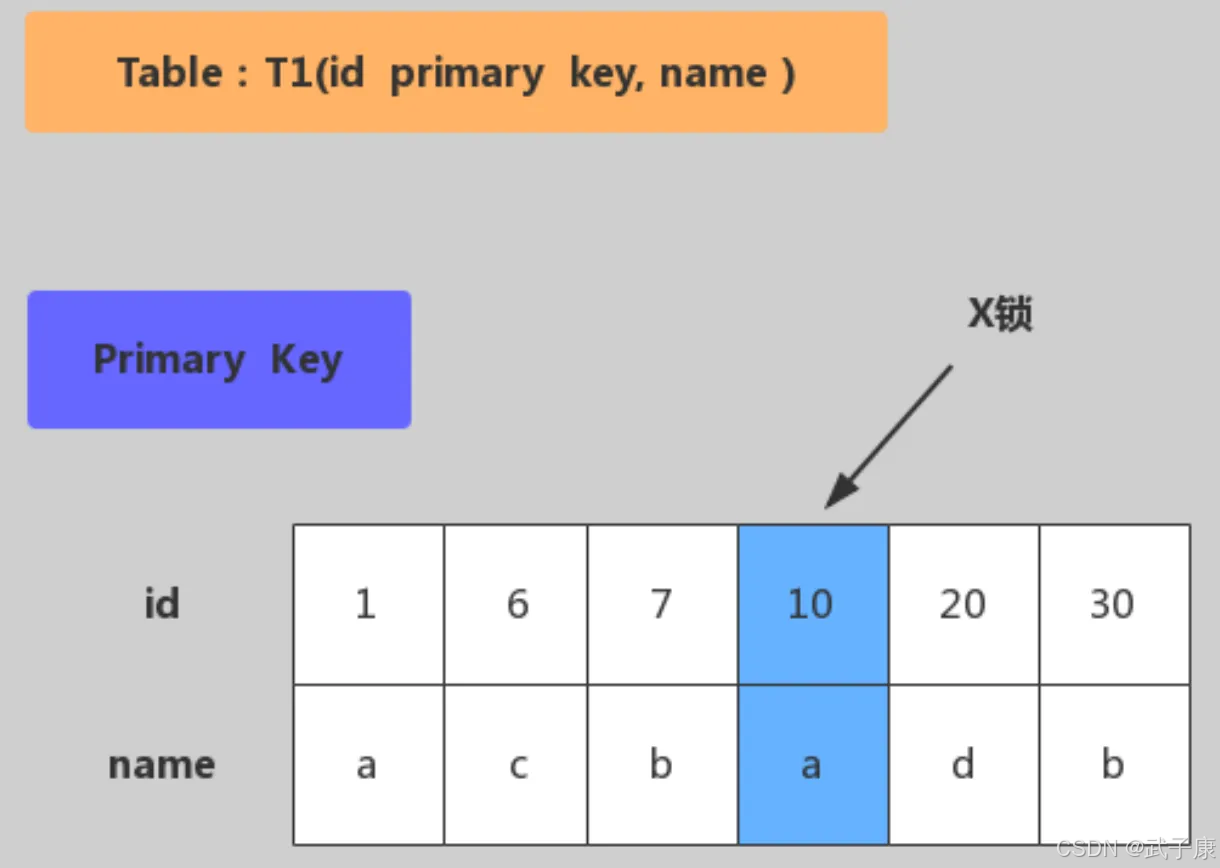
下面是主键加锁,加锁行为:仅在 id=10 的主键索引记录上加 X 锁:
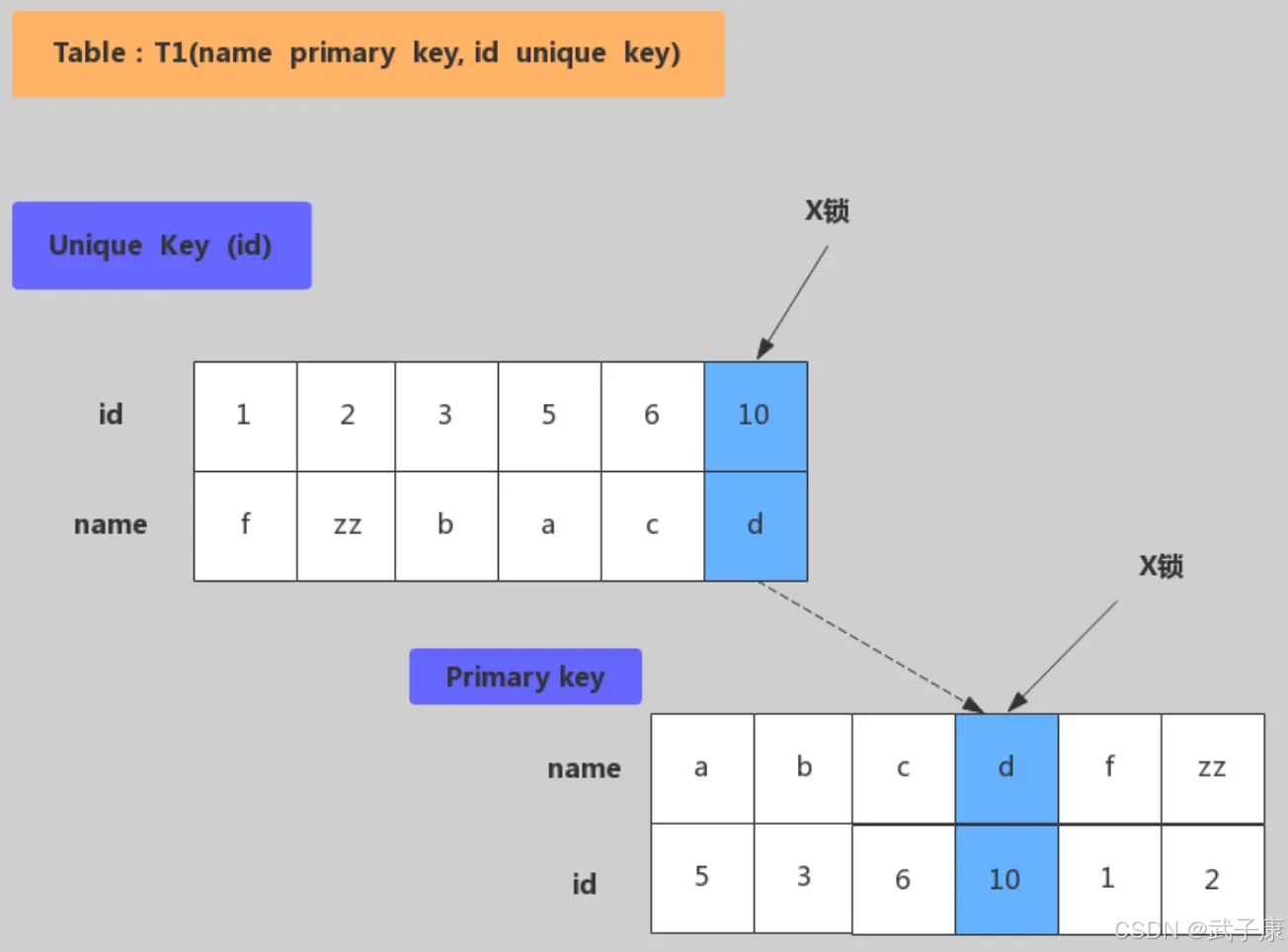
下面是唯一键加锁,加锁行为:在唯一索引id上加X锁,然后在id=10的主键索引记录上加X锁。
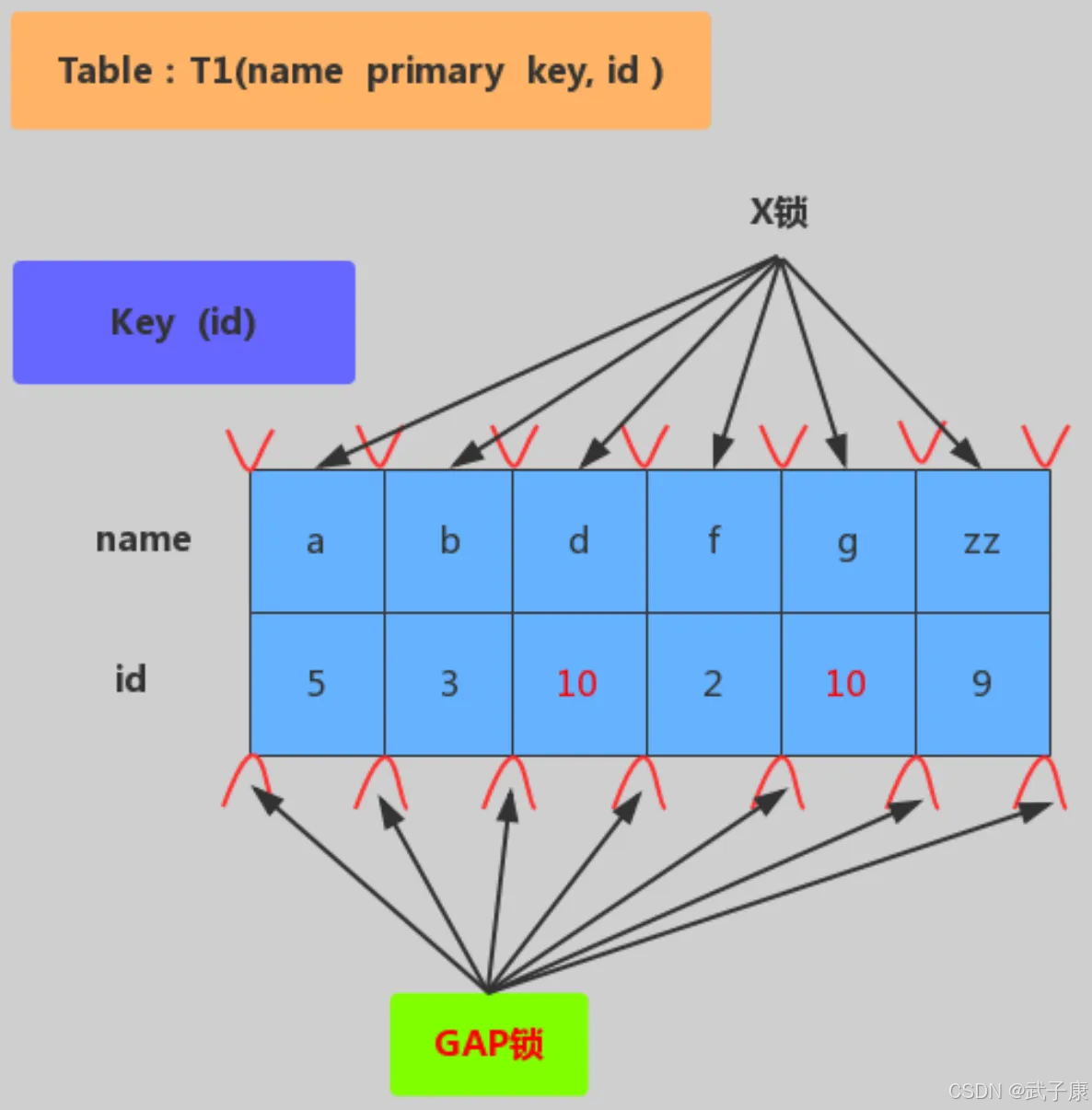
下面是非唯一键加锁,加锁行为:对满足 id=10 条件的记录和主键分别加X锁,然后在 (6,c)-(10,b)、(10,b)-(10,d)、(10,d)-(11,f)范围内加入 Gap Lock:
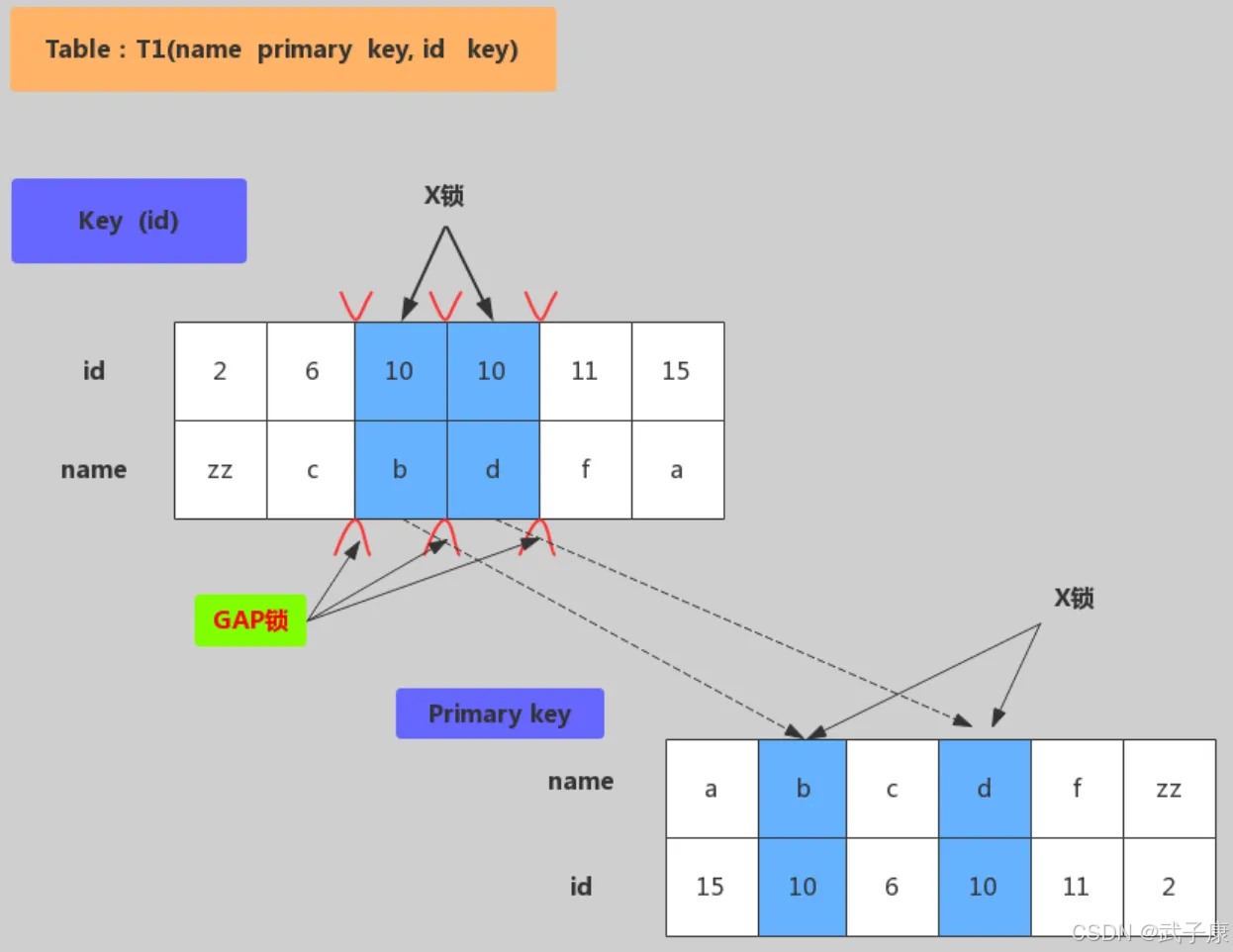
下面是无索引加锁,加锁行为:表里所有的行和间隙都回家X锁,当没有索引时,会导致全表锁定,因为 InnoDB 引擎锁机制是基于索引实现的记录锁定: