图神经网络分享系列-node2vec(二)
目录
一、相关工作
1、特征工程
2、无监督特征学习方法
3、“skip-gram”的启发
二、特征学习框架
条件独立性
特征空间对称性
1 、经典搜索策略
1、广度优先采样(BFS)
2、深度优先采样(DFS)
3、同质性与结构等价性
4、BFS与DFS的表征差异
5、关键差异总结
2、node2vec
1、随机游走
1、关键术语解析
2、核心逻辑
2、搜索偏差
1、随机游走的偏置方法
2、BFS与DFS的局限性
3、二阶随机游走设计
1、参数p和q的作用
2、返回参数p
3、入-出参数q
4、随机游走的优势
3、node2vec 算法
1、算法原理与实现细节
2、三阶段执行流程
3、资源获取
3、学习边缘特征
1、节点对 特征表示的扩展方法
2、二元操作符定义
3、常见操作符选择
承接上一篇文章,继续分享:图神经网络分享系列-node2vec(一)-CSDN博客
一、相关工作
1、特征工程
特征工程在机器学习领域已被广泛研究,并涉及多种研究方向。传统网络节点特征生成方法依赖于基于网络属性的手工设计特征提取技术(如文献[8,11]所述)。与之不同,当前目标是通过将特征提取转化为表示学习问题来实现全流程自动化,从而摆脱人工设计特征的局限。
2、无监督特征学习方法
无监督特征学习方法通常利用图的各种矩阵表示(特别是拉普拉斯矩阵和邻接矩阵)的谱性质。从线性代数视角看,这些方法可被视为降维技术,包括线性方法(如主成分分析PCA)和非线性方法(如等距映射IsoMap)(见文献[3,27,30,35])。但这类方法存在计算效率和统计性能的双重缺陷:计算层面,数据矩阵特征分解成本高昂,除非采用严重影响解质量的近似方法,因此难以扩展到大型网络;统计层面,这些方法优化的目标函数对网络中多样模式(如同质性和结构等价性)缺乏鲁棒性,且需假设网络底层结构与预测任务的关系。例如谱聚类强烈假设图切割对分类有效(文献[29]),这种假设虽在多数场景合理,却难以泛化到多样化网络。
3、“skip-gram”的启发
自然语言处理中表征学习的最新进展为离散对象(如词语)的特征学习开辟了新途径。Skip-gram模型(文献[21])通过优化邻域保留似然目标,学习词语的连续特征表示:扫描文档词汇时,对每个词学习能预测上下文窗口内邻近词汇的特征表示,采用负采样随机梯度下降优化目标(文献[22])。该模型基于分布假说——相似语境中的词语往往含义相近(文献[9])。
受此启发,近期研究将网络类比为"文档"(文献[24,28]):如同文档是词语的有序序列,可从网络中采样节点序列来构建有序节点序列。但不同采样策略会导致不同特征表示,事实上不存在适用于所有网络和预测任务的通用采样策略,这是现有方法无法灵活采样节点的主要缺陷(文献[24,28])。node2vec算法通过设计不依赖特定采样策略的灵活目标函数,并提供调节搜索空间的参数克服了这一局限。
在节点和边预测任务方面,近期出现基于图特定深度网络架构的监督特征学习方法(文献[15,16,17,31,39])。这些架构通过多层非线性变换直接最小化下游预测任务的损失函数,虽能获得高精度,却因训练耗时面临可扩展性挑战
二、特征学习框架
将网络中的特征学习建模为一个最大似然优化问题。给定网络 G = (V, E),该分析具有普适性,适用于任何(非)有向图、(非)加权网络。设 f: V → ℝᵈ 为待学习的映射函数,用于将节点转换为下游预测任务所需的特征表示,其中 d 为特征表示的维度参数。该函数可等价视为一个大小为 |V| × d 的参数矩阵。对于任意源节点 u ∈ V,定义 Nₛ(u) ⊂ V 为通过邻域采样策略 S 生成的节点 u 的网络邻域。
总结:
关键术语说明
最大似然优化问题:通过概率模型最大化观测数据的似然函数
映射函数 f:将节点嵌入到低维向量空间的数学表示
网络邻域 Nₛ(u):基于策略 S(如随机游走、广度优先搜索)生成的节点局部拓扑结构
技术细节
维度参数 d:控制特征向量的稠密程度,影响模型表达能力和计算复杂度
邻域采样策略 S:决定如何探索节点间关系,常见方法包括 DeepWalk 的随机游走或 Node2Vec 的有偏游走(即,本篇论文)
我们通过扩展Skip-gram架构使其适用于网络[21, 24]。目标是优化以下目标函数,该函数在给定节点u的特征表示f(u)条件下,最大化观察其网络邻域的对数概率:
(1)
为了使优化问题易于处理,我们做出两个标准假设:
-
条件独立性
- 通过假设在给定源节点特征表示的情况下,观察邻域节点的概率彼此独立,从而对似然函数进行分解:
- 通过假设在给定源节点特征表示的情况下,观察邻域节点的概率彼此独立,从而对似然函数进行分解:
-
特征空间对称性
- 源节点与邻域节点在特征空间中具有对称性影响。因此,将每对源-邻域节点的条件似然建模为softmax单元,其参数由两者特征的点积决定:
- 源节点与邻域节点在特征空间中具有对称性影响。因此,将每对源-邻域节点的条件似然建模为softmax单元,其参数由两者特征的点积决定:
在以上两个假设条件下,式(1),目标函数可简化为:
(2)
其中,每个节点的配分函数 ( ) 在大型网络中计算成本极高,因此采用负采样技术[22]进行近似估计。通过随机梯度上升法对定义特征 ( f ) 的模型参数进行优化,以求解式(2),即优化后的目标函数。
基于 Skip-gram 架构的特征学习方法最初源于自然语言处理领域[21]。文本的线性特性使得邻域概念可通过连续词语的滑动窗口自然定义。然而网络结构不具备线性特征,因此需要更丰富的邻域定义方式。为解决此问题,提出一种随机化方法,对给定源节点 ( u ) 采样多种不同的邻域。邻域 ( ) 不仅限于直接相邻节点,其结构可因采样策略 ( S ) 的不同而呈现显著差异
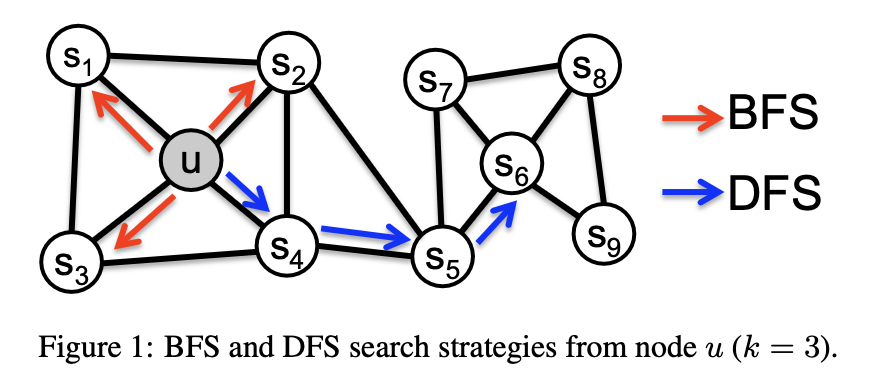
1 、经典搜索策略
将源节点的邻域采样问题视为一种局部搜索。如图1所示,给定源节点u,目标是生成(采样)其邻域。为公平比较不同采样策略S,需将邻域集
的大小限制为k个节点,并对单个节点u采样多组邻域。通常,生成k个节点的邻域集
存在两种极端策略:
1、广度优先采样(BFS)
邻域N_S仅包含源节点的直接邻居。例如,图1中k=3时,BFS采样节点s₁、s₂、s₃。
2、深度优先采样(DFS)
邻域由从源节点逐步增加距离的节点序列构成。图1中,DFS采样节点s₄、s₅、s₆。
广度优先与深度优先采样代表了搜索空间探索的两种极端情况,对学习到的表征产生不同影响。
3、同质性与结构等价性
节点预测任务通常涉及两种相似性:同质性(homophily)与结构等价性(structural equivalence)。
- 同质性假设:高度互联且属于相似网络簇或社区的节点应嵌入相近(如图1中节点s₁和u属于同一社区)。
- 结构等价性假设:具有相似网络结构角色的节点应嵌入相近(如图1中节点u和s₆均作为各自社区的中心枢纽)。与同质性不同,结构等价性不强调连通性,节点可能相距较远但角色相同。实际网络中,两种现象常共存。
4、BFS与DFS的表征差异
BFS和DFS策略对上述等价性的表征具有关键作用:
- BFS:采样的邻域生成的嵌入更倾向于反映结构等价性。通过精确刻画局部邻域(如桥梁或枢纽角色),仅需观察节点的直接邻域即可推断结构等价性。由于限制在附近节点,采样邻域会多次重复,但探索的图范围有限。
- DFS:能探索网络中更广的区域(固定k下移动至更远节点),采样的节点更反映邻域的宏观视图,有助于基于同质性推断社区。但DFS需平衡节点间依赖关系的性质刻画:采样节点可能远离源节点且代表性不足,导致复杂依赖关系。
5、关键差异总结
- BFS:聚焦局部结构,重复采样近邻,适合捕捉结构等价性。
- DFS:探索全局社区,但可能引入噪声,适合捕捉同质性。
- 实际应用中需根据任务目标权衡两种策略的特性。
2、node2vec
基于上述观察,设计了一种灵活的邻域采样策略,可在广度优先搜索(BFS)和深度优先搜索(DFS)之间实现平滑过渡。通过开发一种灵活的偏向性随机游走算法,既能以BFS方式也能以DFS方式探索邻域结构。
1、随机游走
给定一个源节点u,模拟一个固定长度为l的随机游走。用ci表示游走中的第i个节点,起始点c0=u。节点ci的生成遵循以下分布:
1、关键术语解析
:节点v和x之间的未归一化转移概率
- Z:归一化常数(确保概率和为1)
- E:图的边集合
2、核心逻辑
该分布描述了随机游走中从节点v转移到节点x的概率,仅当v和x之间存在边时概率非零。转移概率由未归一化的πvx决定,最终通过Z调整为合法概率值。
2、搜索偏差
1、随机游走的偏置方法
最简单的偏置方法是通过静态边权重采样下一个节点,即
(对于无权图,
)。但这种方法无法考虑网络结构,也无法引导搜索过程探索不同类型的网络邻域。
2、BFS与DFS的局限性
BFS和DFS是两种极端采样范式,分别适用于结构等价性和同质性。然而现实中的网络通常同时体现这两种特性,且它们并非互斥关系。因此需要一种更灵活的随机游走方法。
3、二阶随机游走设计
引入参数和
的二阶随机游走可解决上述问题。假设游走刚经过边
到达节点
,此时需通过未归一化转移概率
决定下一步,其中:
表示节点
与
的最短路径距离,其取值只能为
。这两个参数能够有效引导游走方向。
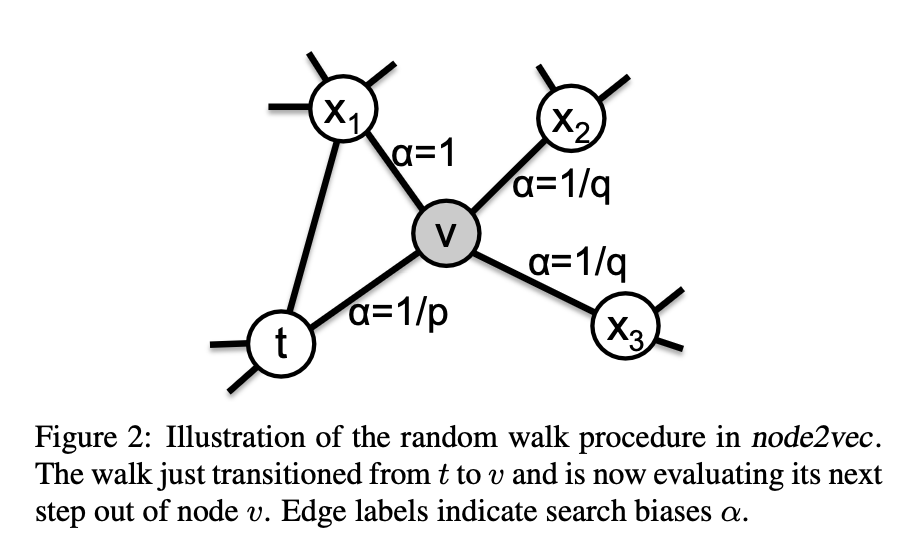
1、参数p和q的作用
参数p和q直观上控制随机游走探索和离开起始节点u邻域的速度。这两个参数使搜索过程能够在广度优先搜索(BFS)和深度优先搜索(DFS)之间灵活调整,从而反映对不同节点等价概念的偏好。
2、返回参数p
参数p的作用
参数p控制随机游走中立即重新访问同一节点的概率。当p设置为较高值(> max(q, 1))时,游走在接下来的两步中不太可能重复采样已访问的节点(除非下一节点没有其他邻居)。这种策略鼓励适度探索,避免采样时的二跳冗余。
低p值的影响
若p值较低(< min(q, 1)),游走倾向于回溯到上一步节点(如图2所示),导致游走范围局限在起始节点u附近,形成局部性更强的采样。
3、入-出参数q
- 参数 q 的定位作用
- 参数 q 用于区分随机游走中“向内”与“向外”节点的倾向。以图 2 为例,当 q > 1 时,游走会偏向访问靠近节点 t 的邻近节点。此类游走能捕捉图中以起始节点为中心的局部结构,近似广度优先搜索(BFS)行为,使采样节点集中在较小范围内
- 深度探索机制
- 当 q < 1 时,游走更倾向于访问远离节点 t 的节点,模拟深度优先搜索(DFS)的向外探索特性。不同之处在于,这种探索通过随机游走框架实现,采样节点并非严格按与源节点 u 的距离递增分布,但能兼顾可处理的预处理过程和更高的采样效率。
- 二阶马尔可夫性
- 通过将转移概率 πv,x 设为游走中前一节点 t 的函数,该随机游走具备二阶马尔可夫性。
4、随机游走的优势
相比纯BFS/DFS方法,随机游走具有多重优势。其在空间和时间复杂度上均具备较高的计算效率。存储图中每个节点的直接邻居所需空间复杂度为O(|E|)。对于二阶随机游走,需额外存储节点邻居间的互连关系,空间复杂度为O(a²|V|),其中a为图的平均度数,而现实网络中的a通常较小。
随机游走相较于传统基于搜索的采样策略的另一关键优势在于时间复杂度。通过在样本生成过程中保持图连通性,随机游走提供了一种高效机制,可跨不同源节点复用样本以提高有效采样率。由于随机游走的马尔可夫性质,模拟长度为l > k的游走可一次性为l−k个节点生成k个样本,因此单样本有效复杂度为O(l/(k(l−k))。例如,图1中采样长度为6的随机游走{u, s4, s5, s6, s8, s9},可同时得到NS(u) = {s4,s5,s6}、NS(s4) = {s5,s6,s8}及NS(s5) = {s6,s8,s9}。
需注意样本复用可能导致整体过程存在偏差,但实际观测表明其显著提升了效率。
3、node2vec 算法

1、算法原理与实现细节
node2vec的伪代码由算法1给出。在任意随机游走过程中,起始节点u的选择会引入隐式偏差。由于需要为所有节点学习表征,这一偏差通过从每个节点出发模拟r次固定长度l的随机游走来消除。游走的每一步根据转移概率
2、三阶段执行流程
node2vec包含三个串行阶段:预处理阶段计算转移概率、随机游走模拟阶段、基于随机梯度下降(SGD)的优化阶段。每个阶段均支持并行化和异步执行,这一设计显著提升了算法的整体可扩展性。
3、资源获取
node2vec的完整实现可通过以下链接获取:http://snap.stanford.edu/node2vec
3、学习边缘特征
1、节点对 特征表示的扩展方法
node2vec算法提供了一种半监督方法,用于学习网络中节点的丰富特征表示。但在实际应用中,预测任务往往涉及节点对而非单个节点。例如在链接预测中,需要预测网络中两个节点间是否存在连接关系。由于随机游走本质上是基于网络底层节点间的连接结构,因此可通过节点特征表示的自举扩展方法将其应用于节点对。
2、二元操作符定义
给定节点u和v及其对应的特征向量f(u)和f(v),定义一个二元操作符◦来生成节点对的联合表示g(u,v),其中g: V × V → ℝᵈ′(d′表示节点对 表示的维度)。该操作符需满足通用性要求:即使节点对间不存在边也能生成有效表示,这对链接预测任务至关重要——测试集通常同时包含正样本(存在边)和负样本(不存在边)。
3、常见操作符选择

考虑多种维度保持(d′=d)的二元操作符设计,具体包括:
- 均值运算:对特征向量进行逐元素平均
- 哈达玛积:对应元素相乘
- 加权L1距离:向量差的绝对值加权和
- 加权L2距离:向量差的平方加权和
这些操作符在保留原始特征空间维度的同时,能捕获节点对间的不同交互模式,为下游任务(如链接预测)提供灵活的表示能力。典型实现方式可参考算法相关文献中的对照表(如表1所示)。
好啦~本篇文章讲完,想必大家对node2vec的核心算法的来龙去脉有了比较深入的了解了,后面的文章会进一步去进行实验的论证。
传送门: