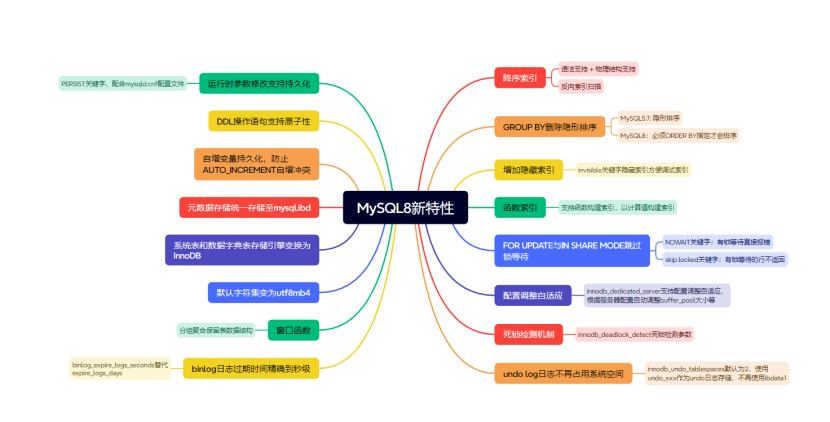
MySQL深度理解-MySQL8新特性
1.新增降序索引
降序索引是什么?降序索引是将索引字段使用倒序的方式进行组织,默认情况下索引的组织方式都是升序排列的。
1.1表结构的体现
MySQL在语法上很早就已经支持降序索引了,但是实际上创建的仍然是升序索引,现在使用MySQL5.7的版本测试一下。
先创建一个数据表:
CREATE TABLE t1(c1 int, c2 int, index idx_c1_c2(c1, c2 desc)))展示一下数据表:
SHOW CREATE TABLE t1;查询的结果如下:
Table: t1
Create Table: CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` int(11) DEFAULT NULL,KEY `idx_c1_c2` (`c1`, `c2`) -- 注意这里,c2字段是升序
)可以发现虽然MySQL5.7版本在语法上已经支持降序索引了,但是实际创建出来的还是升序索引。
我们再使用MySQL8.0.17的版本进行测试。
创建一个数据表:
CREATE TABLE t1(c1 int, c2 int, index idx_c1_c2(c1, c2 desc)))展示一下数据表:
SHOW CREATE TABLE t1;查询的结果如下:
Table: t1
Create Table: CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` int(11) DEFAULT NULL,KEY `idx_c1_c2` (`c1`, `c2` DESC) -- 注意这里的区别,降序索引生效了
)1.2查询数据时的体现
现在我们使用MySQL5.7版本进行测试。
先向数据库中插入数据:
INSERT INTO t1 (c1, c2) VALUES(1, 10), (2, 50), (3, 50), (4, 100), (5, 80);然后使用EXPLAIN + SELECT查询语句查看执行计划:
EXPLAIN SELECT * FROM t1 ORDER BY c1, c2 DESC;该ORDER BY排序设定的时先根据c1字段排序,再根据c2字段进行倒序排序。创建数据表的时候,c1字段构建的索引是升序索引,c2字段构建的索引是降序索引。
正常情况下来说,按照逻辑上来说,是可以正常走索引的,但是执行计划中,Extra中是Using index;Using filesort,表明该查询语句走了索引,但是也走了外部排序。
为什么会出现这种情况呢?
因为MySQL5.7是不支持降序索引的,在上文中我们指出,虽然在语法层面上,我们创建c2字段的索引是降序的,但是实际生成的数据表是升序的,所以当我们使用ORDER BY进行排序的时候,由于索引c1是升序排序,且索引的构建方式也是升序的,所以在根据c1字段进行排序的时候,本身其索引构建就是有序的,所以是可以走索引的,故会有Using Index。但是在根据c2字段进行排序的时候,c2字段在物理数据结构上是升序排序的,但是ORDER BY排序的时候,是使用降序排序的,其与物理数据结构是不一致的,所以不能使用索引直接完成排序,只能使用sort_buffer进行外部排序。
但是当我们使用MySQL8.0的时候,我们需要大喊一声:将大局逆转吧。
先向数据库中插入数据:
INSERT INTO t1 (c1, c2) VALUES(1, 10), (2, 50), (3, 50), (4, 100), (5, 80);然后使用EXPLAIN + SELECT查询语句查看执行计划:
EXPLAIN SELECT * FROM t1 ORDER BY c1, c2 DESC;这次的查询计划中Extra的值是Using index,表示走的都是索引,此时降序索引便生效了。当时我们创建表的时候,c1字段使用的是默认的升序索引,c2字段使用的是指定的降序索引,并且表结构上确实也是如此,排序的时候我们使用的也是c1字段是升序的,c2字段是降序的,这与表的物理结构是一致的,所以可以直接使用索引进行排序,而无需使用filesort进行外部排序。
1.3反向扫描索引
并且MySQL8也借助降序索引的特性引入了反向扫描索引的功能,执行下面的EXPLAIN + SELECT语句:
EXPLAIN SELECT * FROM t1 ORDER BY c1 DESC. c2;查询出来的执行计划中Extra的值是Backward index scan;Using index,意思是使用了索引,并且是反向扫描索引。
其中c1字段的索引物理结构是默认升序的,c2字段的索引物理结构默认是降序的,在ORDER BY排序的时候,c1字段使用的降序排序,c2字段使用的是升序排序,也就是说c1和c2均反转过来了,这样在排序的时候,MySQL可以进行整体的反向扫描,这样也是可以走索引的。
但是需要注意的是,反向扫描索引只能应用于排序的索引字段均反向的情况,不能应用于局部反向排序!
我们接下来看一下局部反向排序,执行下面的EXPLAIN + SELECT语句:
EXPLAIN SELECT * FROM t1 ORDER BY c1 DESC, c2 DESC;这个SQL语句中c1字段出现了反向排序,c字段没有反向排序,是一个局部反向排序,其执行计划中Extra是Using index,Using filesort,说明其中一个字段直接使用的索引排序,但是其中一个字段也是使用了filesort外部排序,说明不能完全利用索引,所以局部反向排序不能完全利用索引,不适用于反向扫描索引,必须是完全反向才行。
2.Group By不再隐式排序
在MySQL8.0之前,Group By进行分组的时候,是会进行隐式排序的,即分组后会默认按照升序的方式对查询的结果进行排序。
但是从MySQL8.0开始,Group By字段不再对查询的数据进行隐式排序,如果需要对查询的结果进行排序,必须要加上Order By指定排序。
在MySQL5.7中进行执行下面的查询语句:
SELECT count(*), c2 FROM t1 GROUP BY c2;该SQL语句根据c2字段进行分组查询,查询出来的结果为:
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
| count(*) | c2 |
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
| 1 | 10 |
| 2 | 50 |
| 1 | 80 |
| 1 | 100 |
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
4 rows in set (0.00 sec)可以发现,在MySQL5.7中查询出来的数据,按照GROUP BY的分组字段c2进行了升序排序,说明GROUP BY进行了隐藏的排序。
在MySQL8。0中进行执行下面的查询语句:
SELECT count(*), c2 FROM t1 GROUP BY c2;该SQL语句根据c2字段进行分组查询,查询出来的结果为:
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
| count(*) | c2 |
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
| 1 | 10 |
| 2 | 50 |
| 1 | 100 |
| 1 | 80 |
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
4 rows in set (0.00 sec)可以发现,在MySQL8.0中查询出来的数据,并没有按照GROUP BY的分组字段c2进行升序排序,说明GROUP BY没有进行隐藏的排序。
只有当在SQL中明确声明ORDER BY的时候,才会进行排序:
SELECT count(*), c2 FROM t1 GROUP BY c2 ORDER BY c2;查询出来的数据如下:
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
| count(*) | c2 |
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
| 1 | 10 |
| 2 | 50 |
| 1 | 80 |
| 1 | 100 |
+‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐+
4 rows in set (0.00 sec)3.增加隐藏索引
使用invisible关键字在创建表或者进行表变更中设置索引为隐藏索引。索引隐藏只是不可见,但是数据库后台还是会维护隐藏索引,在查询时优化器不会选择使用该所以你,即使使用force index,优化器也不会使用该索引,同样优化器也不会抛出索引不存在的错误,因为索引仍然真是存在,必要时,也可以把隐藏索引快速恢复成可见。
需要注意的是,主键索引是不可以设置为invisible的。
软删除就可以使用隐藏索引,比如我们觉得某个索引没用了,删除后发现这个索引在某些时候还是有用的,于是又得把这个索引加回来,如果表的数据量非常大的话,这种操作是非常消耗事件的,成本很高。我们可以采用隐藏索引的手段看,先将索引设置为隐藏索引,确认该索引确实没有用的时候再将该索引删除。
4.新增函数索引
在MySQL5.7中,如果在查询中加入了函数,索引会不生效,所以MySQL 8引入了函数索引,MySQL8.0.13开始支持在索引中使用函数(表达式)的值。
函数索引基于虚拟列功能实现,在MySQL中相当于新增了一个列,这个列会根据你的函数来进行计算结果,然后使用函数索引的时候就会用这个计算后的列作为索引。
首先创建一个数据表:
CREATE TABLE t3(c1 varchar(10), c2 varchar(10));给c1字段创建一个普通索引:
CREATE INDEX idx_c1 ON t3(c1); -- 创建普通索引使用函数(表达式)给c2字段创建一个大写的函数索引:
CREATE INDEX func_idx ON t3(UPPER(c2))); -- 创建一个大写的函数索引查询t3表的所有索引:
SHOW INDEX FROM t3;查询结果如下:
*************************** 1. row ***************************
Table: t3
Non_unique: 1
Key_name: idx_c1
Seq_in_index: 1
Column_name: c1
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: t3
Non_unique: 1
Key_name: func_idx
Seq_in_index: 1
Column_name: NULL
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: upper(`c2`) ‐‐函数表达式根据Expression属性可以发现,t3表上c1字段的索引是非函数(表达式)索引,t3表上c2字段的索引是函数(表达式)索引。
执行下面的SQL语句:
EXPLAIN SELECT * FROM t3 WHERE UPPER(c1)='XINGHAI';根据该SQL语句的执行计划可以发现,Extra的值是Using where,即没有进行索引优化,而是进行的全表扫描。
执行下面的SQL语句:
EXPLAIN SELECT * FROM t3 WHERE UPPER(c2)='XINGHAI';根据该SQL语句的执行计划可以发现,Extra的值是Using index,即进行了索引优化,可以发现函数索引起作用了。
5.INNODB存储引擎SELECT FOR UPDATE跳过锁等待
对于SELECT ... FOR SHARE(8.0新增的加查询共享锁的语法)或者SELECT ... FOR UPDATE,在语句后面添加NOWAIT,SKIP LOCKED语法可以跳过锁1等待,或者跳过锁定。
在5.7即之前的版本,SELECT ... FOR UPDATE,如果获取不到锁,会一直等待,直到innodb_lock_wait_timeout锁超时。
在8.0版本中,通过在语句后面添加NOWAIT,SKIP LOCKED语法,可以实现立刻返回。如果查询的行已经加锁,那么NOWAIT会立刻报错返回,而SKIP LOCKED也会立即返回,只是返回的结果中不包含被锁定的行。
应用场景比如查询余票记录,如果某些记录已经被锁定,使用SKIP LOCKED可以跳过被锁定的记录,只返回没有锁定的记录,提高系统性能。
6.新增innodb_dedicated_server自适应参数
innodb_dedicated_server自适应参数能够让InnoDB根据服务器上检测的内存大小自行配置innodb_buffer_pool_size,innodb_log_file_size等参数,会尽可能多的占用系统可还在那用资源提升性能。解决非专业人员安装数据库后默认初始化数据库参数默认值偏低的问题,前提是服务器是专用来给MySQL数据库的,如果还有其它软件或者资源或者多实例MySQL使用,不建议开启该参数,不然会影响其它程序。
执行下面的SQL语句:
SHOW VARIABLES LIKE '%innodb_dedicated_server%'; -- 默认是OFF关闭,修改为ON打开下面是查询结果:
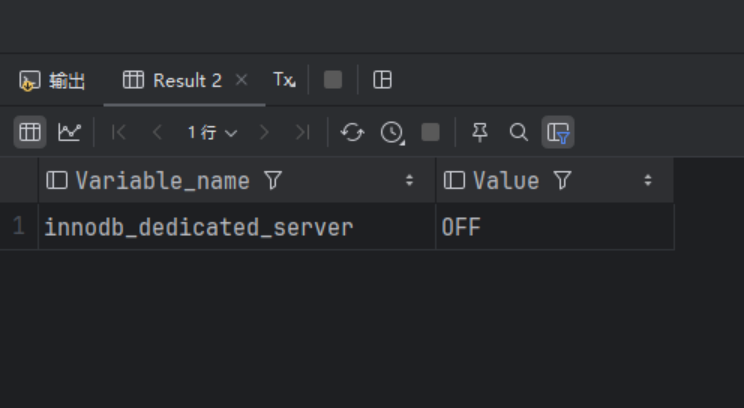
可以看到默认自适应参数是关闭的,即不开始InnoDB的自适应功能。
7.死锁检查控制
MySQL8.0(MySQL5.7.15)增加了一个新的动态变量innodb_deadlock_detect,用于控制系统是否执行InnoDB死锁检查,默认是打开的。死锁检测会耗费数据库性能的。对于高并发的系统,可以关闭死锁检测功能,提高系统形态能。如果要关闭死锁检测功能,要确保系统有很低的概率会出现死锁,同时要将锁等待超时的参数调小一点,一面出现死锁等待过久的情况。
使用下面的SQL语句查看死锁探测是否开启:
SHOW VARIABLES LIKE '%innodb_deadlock_detect';查询出来的数据如下:
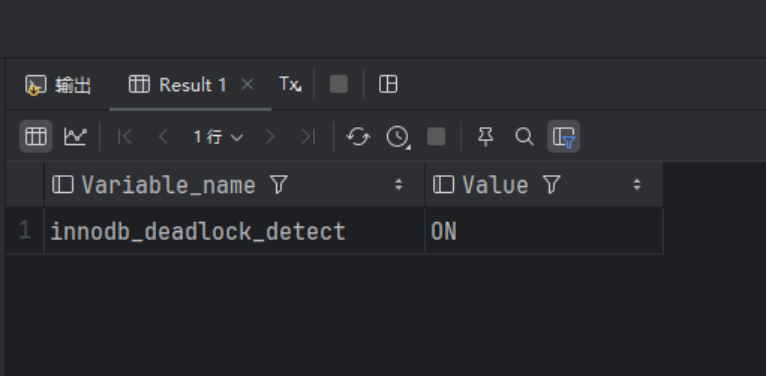
在新版本中,默认死锁探测是开启的,只要探测到死锁,直接破坏死锁,而不是继续等待。
8.undo文件不再使用系统表空间
在MySQL8.0之前的版本中,innodb_undo_tablespaces默认值是1,undo log日志记录在data数据目录下的ibdata1文件中,其占用的是系统表空间,但是MySQL8.0开始,将innodb_undo_tablespaces默认值更改为2,在存储undo log日志的时候,会生成两个文件undo_001和undo_002,会将undo log日志数据存储到这两个文件中,即不占用系统表空间,而是直接使用专门给undo log记录的空间。
9.binlog日志过期时间精确到秒
在MySQL8之前,binlog的日志过期时间只能精确到天,不是特别方便配合整库备份SQL完成库表的备份,但是从MySQL8开始,binlog的日志过期时间可以精确到秒,保证了binlog数据的精准记录。
在MySQL8.0版本之前,binlog日志过期时间设置可以使用expire_logs_days参数。
在MySQL8.0版本中,binlog日志过期时间设置可以使用binlog_expire_logs_seconds参数。
10.窗口函数(Window Functions):分析函数
从MySQL8.0开始,新增了一个教窗口函数的概念,它可以用来实现若干新的查询方式。窗口函数与SUM(),COUNT()这种分组聚合函数累死,在聚合函数后面加上了over()就变成窗口函数了,在over的括号内可以加上paritition by等分组关键字指定如何分组,窗口函数即使分组也不会将多行查询结果合并为一行,而是将结果放回多行当中,即窗口函数不需要再使用GROUP BY进行分组,GROUP BY进行分组时会将分好组的数据合并放在一行里。
先创建一张账户余额表:
CREATE TABLE `account_channel` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL COMMENT '姓名',`channel` varchar(20) DEFAULT NULL COMMENT '账户渠道',`balance` int DEFAULT NULL COMMENT '余额',PRIMARY KEY (`id`)
) ENGINE=InnoDB;插入一些数据,方便进行模拟操作:
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('1', 'zhuge', 'wx','100');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('2', 'zhuge', 'alipay','200');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('3', 'zhuge', 'yinhang','300');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('4', 'lilei', 'wx','200');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('5', 'lilei', 'alipay','100');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('6', 'hanmeimei', 'wx','500');使用聚合函数SUM + GROUP BY根据name进行分组查询:
SELECT `name`, SUM(balance) FROM account_channel GROUP BY `name`;查询出的结果如下:
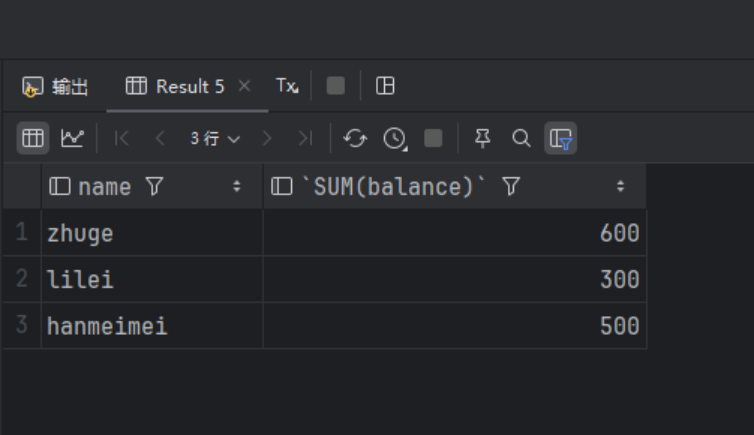
可以看到在MySQL8之前,想要使用聚合函数计算,必须要使用GROUP BY去指定某个字段做分组,分组时需要指定name,查询出来的数据会根据name进行整合分组,并对指定字段完成聚合。
在聚合函数后面加上over()就变成分析函数了,后面可以不再使用GROUP BY去指定分组,因为在over里面已经使用partition关键字指定了如何进行分组计算了,这种可以保留原有表数据的结构,不会像分组聚合函数那样每组只返回一个数据。
使用聚合函数SUM + 窗口函数over和partition条件根据name进行分析:
SELECT `name`, `channel`, `balance`, SUM(balance) OVER(PARTITION BY name) FROM account_channel;查询出来的数据如下:
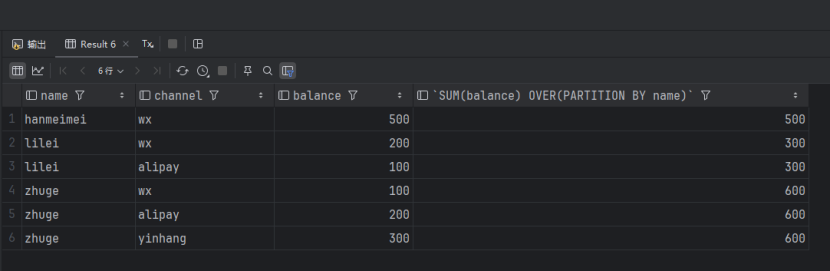
可以发现其保留了原来表数据的结构,并没有像GROUP BY一样,根据分组的字段,将每个组的数据整合为一行。
如果over()中不添加条件,则默认使用整个表的数据进行计算。
执行下面的语句,over()中不添加条件:
SELECT `name`, `channel`, `balance`, SUM(balance) OVER() FROM account_channel;查询出来的数据如下:
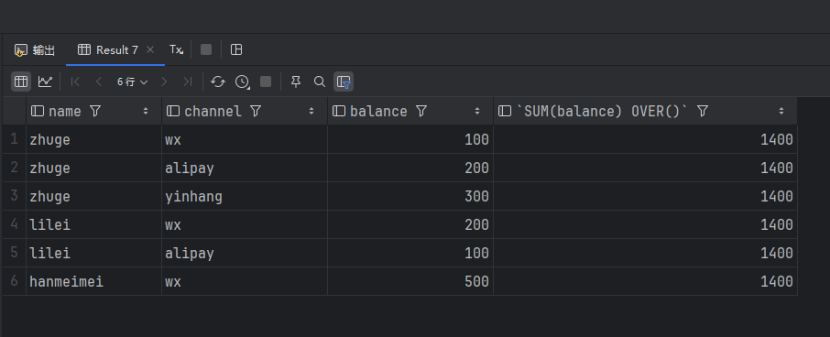
专用的窗口函数:
- 序号函数 ROW_NUMBER(),RANK(),DENSE_RANK()。
- 分布函数 PERCENT_RANK(),CUME_DIST()。
- 前后函数 LAG(),LEAD()。
- 头尾函数 FIRST_VALUE(),LAST_VALUE()。
- 其它函数 NTH_VALUE(),NTILE()。
按照balance字段排序,展示序号:
SELECT `name`, `channel`, `balance`, ROW_NUMBER() OVER(ORDER BY balance DESC) AS `row_number` FROM account_channel;查询出来的数据如下:
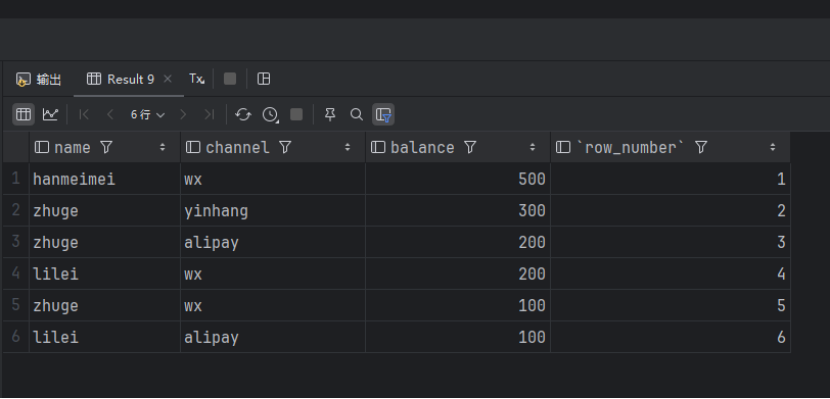
按照balance字段排序,first_value()选出排序第一的余额:
SELECT `name`, `channel`, `balance`, FIRST_VALUE(balance) OVER (ORDER BY balance DESC) AS max_balance FROM account_channel;查询出来的数据如下:
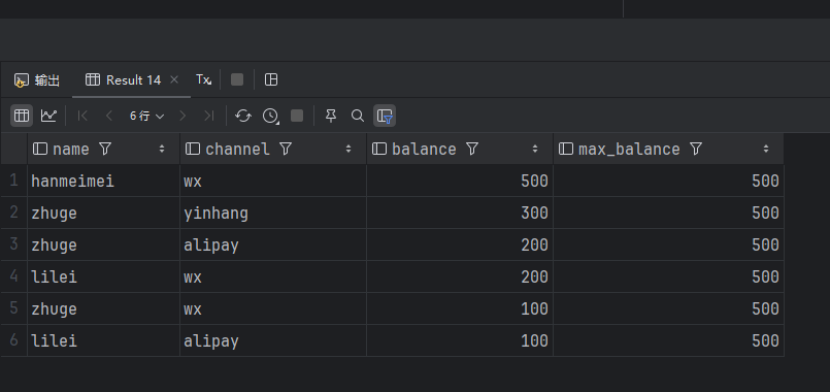
11.默认字符集由latin1变为utf8mb4
在MySQL8.0版本之前,默认的字符集为latin1,utf8指向的是utf8mb3,MySQL8.0版本默认字符集是utf8mb4,utf8默认指向的也是utf8mb4。
12.MyISAM系统表全部换成InnoDB表
MySQL8.0中系统表和数据字典表都是使用的MyISAM引擎,在MySQL8.0中,将所有的系统表和数据字典表都修改为了InnoDB引擎,并且默认的MySQL实例不会包含MyISAM引擎的表,除非自己手动创建。
13.元数据存储变动
MySQL8.0之前所有的数据表的元数据文件都对应着一些文件,比如表结构.frm等文件,从MySQL8.0开始,这些元数据均被迁移到了mysql.ibd文件中。
14.自增变量持久化
在MySQL之前的版本,自增主键AUTO_INCREMENT的值如果大于max(priamry key) + 1,在MySQL重启之后,会重置AUTO_INCREMENT=max(primary key) + 1,这种现象在某些情况下会导致业务主键冲突或者其它难以发现的问题。自增逐渐重启重置问题狠招就被发现了,直到MySQL8.0才被解决,MySQL8.0版本将会对AUTO_INCREMENT的值进行持久化,MySQL重启后,该值不会变化。
15.DDL原子化
InnoDB表的DDL支持事务完整性,要么成功要么回滚。
MySQL8.0开始支持原子DDL操作,其中与表相关的原子DDL只支持InnoDB存储引擎。
一个原子DDL操作内容包括:更新数据字典,存储引擎的操作,在binlog记录DDL操作。
支持与表相关的DDL:数据库、表空间、表、索引的CREATE、ALTER、DROP以及TRUNCATION TABLE。
支持的其它DDL:存储程序、触发器、视图、UDF的CREATE、DROP和ALTER语句。
支持账户管理相关的DDL:用户和角色的CREATE、ALTER、DROP以及适用的RENAME等等。
16.参数修改持久化
MySQL版本支持运行时修改全局参数并持久化,通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从改哦配置文件中获取到最新运行时修改的配置参数,进行整合修改。
如果不适用PERSIST,在MySQL8中使用SET GLOBAL设置的变量参数在MySQL重启之后是会失效的,必须要在MySQL8中使用新增的PERSIST关键字,MySQL8之前的版本是没有提供这个关键字的,所以MySQL8之前的版本是不支持运行时更改全局参数的。
执行下面的语句:
SET PERSIST innodb_lock_wait_timeout=25;系统会在data数据目录下面生成一个mysql-auto.cnf文件,里面存储的是JSON格式的数据,当原始的配置文件my.cnf和mysqld-auto.cnd文件同时存在时,mysqld-auto.cnf中的配置优先级更高。
mysqld-auto.cnf配置数据如下:
{"Version": 1,"mysql_server": {"innodb_lock_wait_timeout": {"Value": "25","Metadata": {"Timestamp": 1675290252103863,"User": "root","Host": "localhost"}}}
}17.总结MySQL8新特性