Python数据分析案例82——基于机器学习的航空公司满意度分析
背景
之前很早写过这些经典的一个数据集的航空公司的聚类的文章,然后现在又有另外一个航空公司满意度的数据集,这个数据集还挺大的,有十几万的数据要用来做一个机器学习的模型是非常合适的。本案例就是一个分类问题的全流程展示。用各种特征去预测客户对这个航空公司的体验是不是满意的一个分类模型,包括数据的预处理,探索性分析变量的可视化特征工程,特征组合数据标准化模型的选择和构建模型的训练对比评估,评价指标,变量重要性排序以及模型的解释。解释用的是shap包。
非常全的流程,可视化的图也很好,很适合写论文或者做作业的一些机器学习初学入门的学生。
数据介绍
数据就一个表格文件:

还有一个中文表头的文件,方便把英文变量来映射为中文:

数据量还是很大的,12.9w的数据量,做机器学习模型完全足够了。
当然需要本文的全部代码文件和数据的同学还是可以参考:航空满意度
代码实现
导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsplt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'(一)数据预处理
读取数据,名称为中文
name=pd.read_excel('中文首行.xlsx').columns
df=pd.read_csv('airline_passenger_satisfaction.csv').set_index('ID')
df.columns=name[1:]
df.shape![]()
12.9w的数据,23列变量。
把一些类别型变量转为中文
## 转为中文
df['乘客性别'] = df['乘客性别'].map({'Male': '男性', 'Female': '女性'})
df['乘客类型'] = df['乘客类型'].map({'Returning': '忠诚顾客', 'First-time': '非忠诚顾客'})
df['乘客出行目的'] = df['乘客出行目的'].map({'Business': '公务出行', 'Personal': '个人出行'})
df['客舱等级'] = df['客舱等级'].map({'Business': '商务舱', 'Economy Plus': '头等舱', 'Economy': '经济舱'})
df['总体满意度'] = df['总体满意度'].map({'Satisfied': '满意', 'Neutral or Dissatisfied': '中立或不满意'})查看数据前2行
df.head(2)
都是中文,看起来没有问题。
查看数据基本信息
df.info()
可以看到除了抵达延误时间有400个缺失值外,其他的变量都没有缺失值。
缺失值处理
## 缺失值数量
df.isna().sum()
#只有‘抵达延误时间’ 有缺失值,使用均值填充
df['抵达延误时间']=df['抵达延误时间'].fillna(df['抵达延误时间'].mean())(二)探索性分析EDA
1.描述性统计
非数值型变量进行描述性统计计算
df.select_dtypes(exclude=['number']).describe().T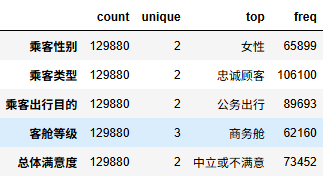
数值型变量进行描述性统计计算
df.select_dtypes(include=['number']).describe().round(3).T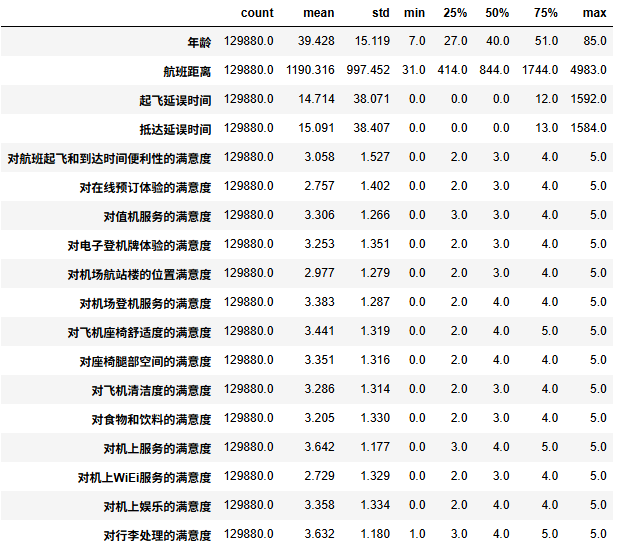
2.可视化分析
响应变量分布
satisfaction_counts = df['总体满意度'].value_counts()
# 绘制饼图
plt.figure(figsize=(3, 3), dpi=128)
plt.pie(satisfaction_counts, labels=satisfaction_counts.index, colors=['pink','skyblue'],autopct='%1.2f%%', startangle=90)
plt.title('总体满意度分布')
plt.axis('equal') # 确保饼图为圆形
plt.show()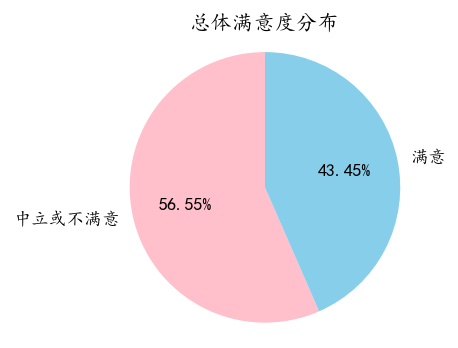
类别变量可视化
# Select non-numeric columns
non_numeric_columns = df.select_dtypes(exclude=['number'])
f, axes = plt.subplots(2, 2, figsize=(5,5),dpi=128)
# Flatten axes for easy iterating
axes_flat = axes.flatten()
for i, column in enumerate(non_numeric_columns):if i < 4: sns.countplot(x=column, data=df, ax=axes_flat[i])axes_flat[i].set_title(f'Count of {column}')for label in axes_flat[i].get_xticklabels():label.set_rotation(90) #类别标签旋转一下,免得多了堆叠看不清
#Hide any unused subplots
for j in range(i + 1, 2):f.delaxes(axes_flat[j])
plt.tight_layout()
plt.show()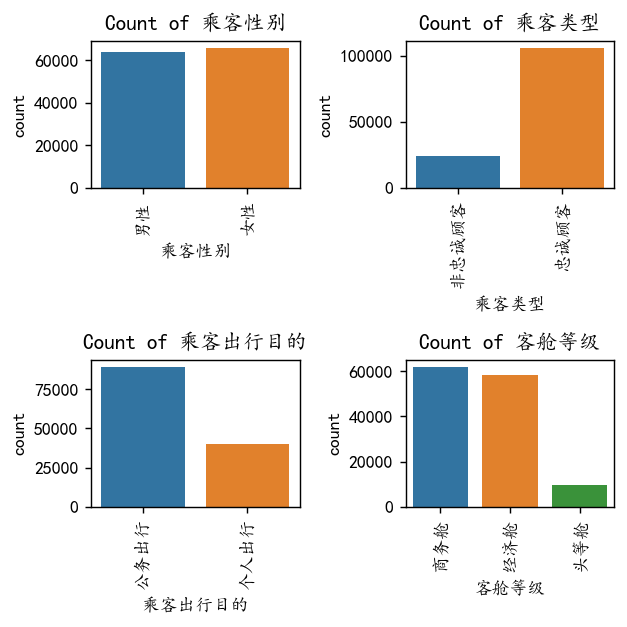
数值变量可视化
#画密度图,
num_columns = df.select_dtypes(include=['number']).columns
dis_cols = 4 #一行几个
dis_rows = len(num_columns)
plt.figure(figsize=(3 * dis_cols, 2 * dis_rows),dpi=128)for i in range(len(num_columns)):ax = plt.subplot(dis_rows, dis_cols, i+1)ax = sns.kdeplot(df[num_columns[i]], color="skyblue" ,fill=True)ax.set_xlabel(num_columns[i],fontsize = 14)
plt.tight_layout()
#plt.savefig('密度图',formate='png',dpi=500)
plt.show()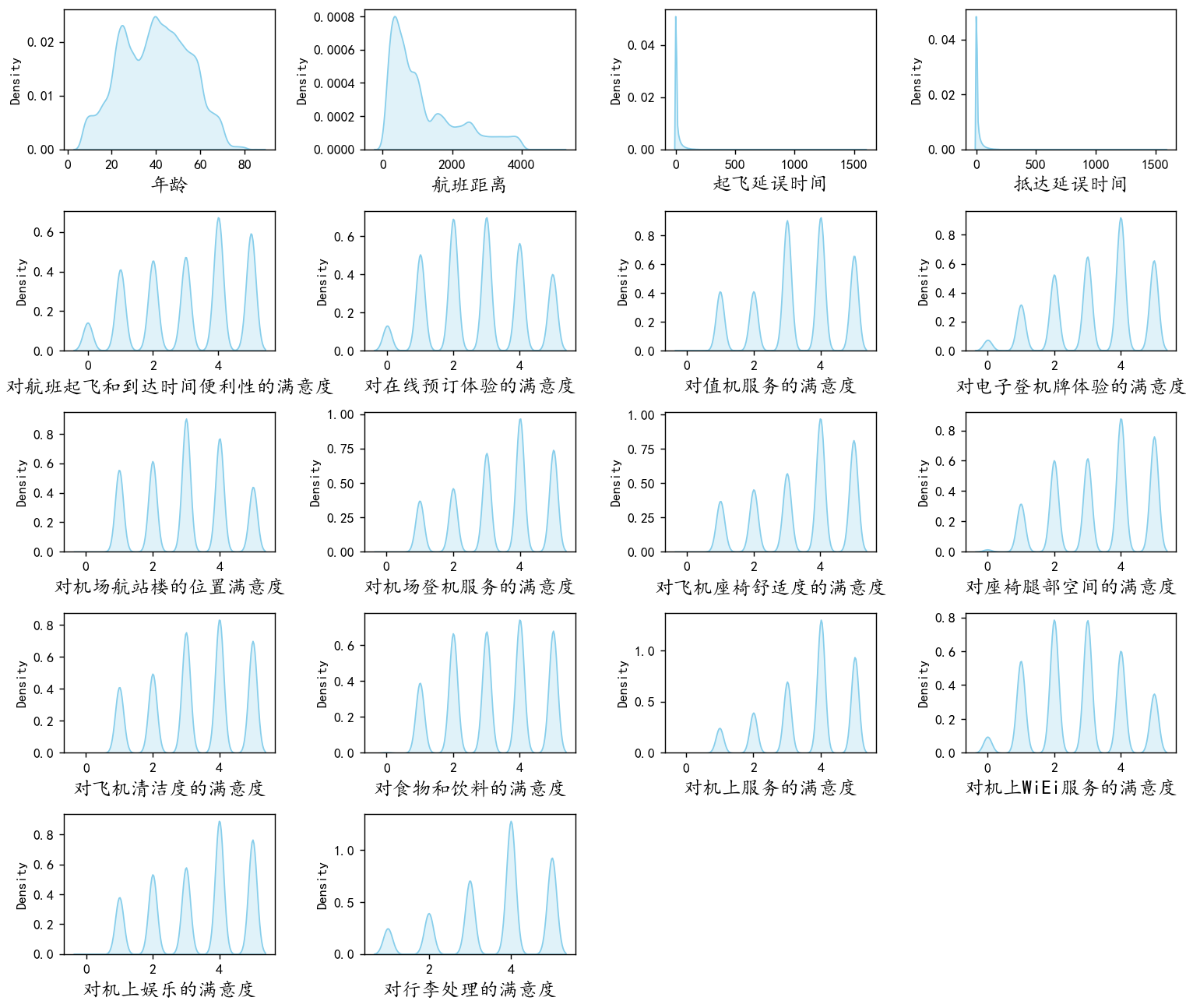
可以看到年龄,航班距离和下面的一些满意度变量分布都较为均匀,而起飞延误时间跟抵达延误时间具有较多的异常值,他们是一个右偏分布,具有很多极大值,后续可能需要进行一定的异常值处理。
不同变量之间的分析
人口统计学分析:
绘制性别、年龄分布图,分析不同群体满意度差异,
plt.figure(figsize=(8, 6),dpi=128)# 1. 性别分布和满意度分析
plt.subplot(2, 2, 1)
sns.countplot(data=df, x='乘客性别', palette='pastel')
plt.title('性别分布')plt.subplot(2, 2, 2)
sns.boxplot(data=df, x='乘客性别', y='年龄', palette='pastel')
plt.title('不同性别的年龄分布')# 2. 年龄分布
plt.subplot(2, 2, 3)
sns.histplot(data=df, x='年龄', bins=30, kde=True, color='skyblue')
plt.title('年龄分布')# 3. 不同群体的满意度比较
plt.subplot(2, 2, 4)
sns.boxplot(data=df, x='总体满意度', y='年龄', hue='乘客性别', palette='pastel')
plt.title('不同性别和年龄段的总体满意度')plt.tight_layout()
plt.show()
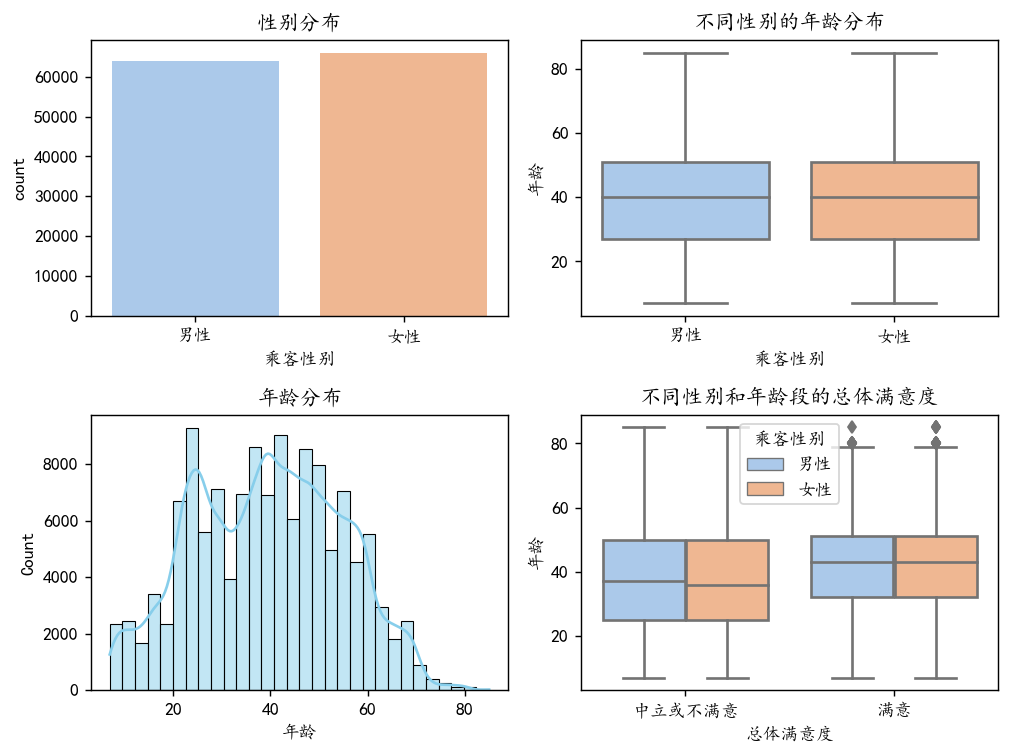
从上图我们可以看出,男性和女性的人数分布较为均衡,年龄分布整体也较为正态,大多数人都集中在20~60岁之间,并且不同的性别对于满意度似乎没有很显著的差异。
但是在不同年龄段明显满意度会不一样。满意的客户中的年龄均值会比中立或者不满意要偏大一些。
服务评分分析:
通过箱线图/热力图分析各服务评分(如机上服务、座椅舒适度)与总体满意度的关系。
# 绘制满意度指标的关联分析(热图)
plt.figure(figsize=(12, 9),dpi=128)
# 选择所有满意度评分列
satisfaction_cols = df.columns[df.columns.str.contains('满意度')]
# 计算相关性
corr = df[satisfaction_cols].apply(lambda x: pd.factorize(x)[0]).corr()
sns.heatmap(corr, annot=True, cmap='coolwarm', center=0)
plt.title('各满意度指标相关性热图')
plt.show()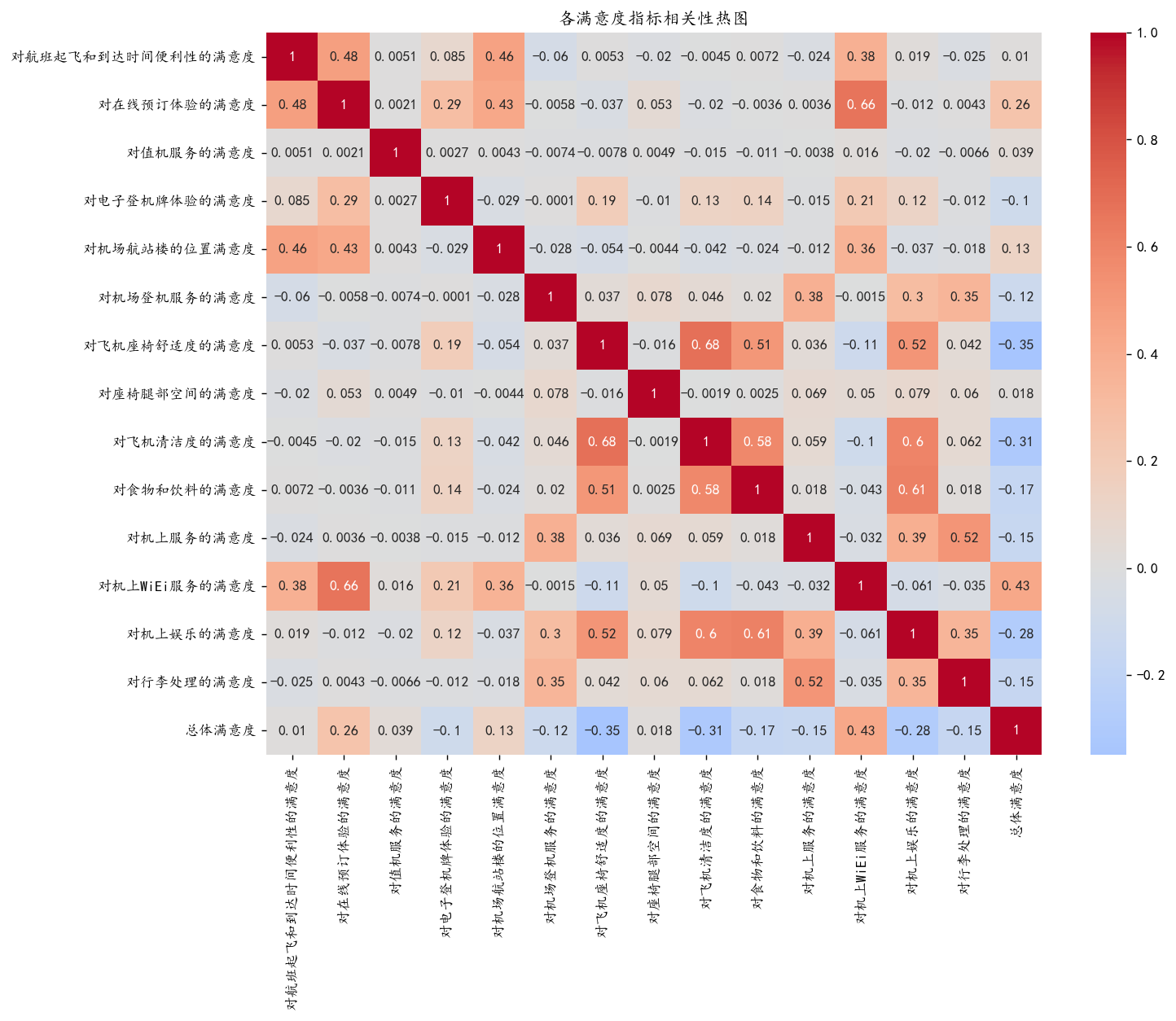
可以看到和总体满意度相关性较高的是WiFi服务和在线预定服务
航功延误影响:
分析起飞/抵达延误时间与满意度的相关性(散点图或分组统计)。
plt.figure(figsize=(10, 5),dpi=128)
# 子图1:起飞延误时间 vs 总体满意度
plt.subplot(1, 2, 1)
sns.stripplot( data=df, x='总体满意度',y='起飞延误时间', jitter=0.25, hue='总体满意度',palette="viridis",alpha=0.6)
plt.title('起飞延误时间与总体满意度')
plt.xlabel('总体满意度')
plt.ylabel('起飞延误时间(分钟)')# 子图2:抵达延误时间 vs 总体满意度
plt.subplot(1, 2, 2)
sns.stripplot(data=df, x='总体满意度', y='抵达延误时间',hue='总体满意度',jitter=0.25, palette="magma", alpha=0.6)
plt.title('抵达延误时间与总体满意度')
plt.xlabel('总体满意度')
plt.ylabel('抵达延误时间(分钟)')
plt.tight_layout()
plt.show()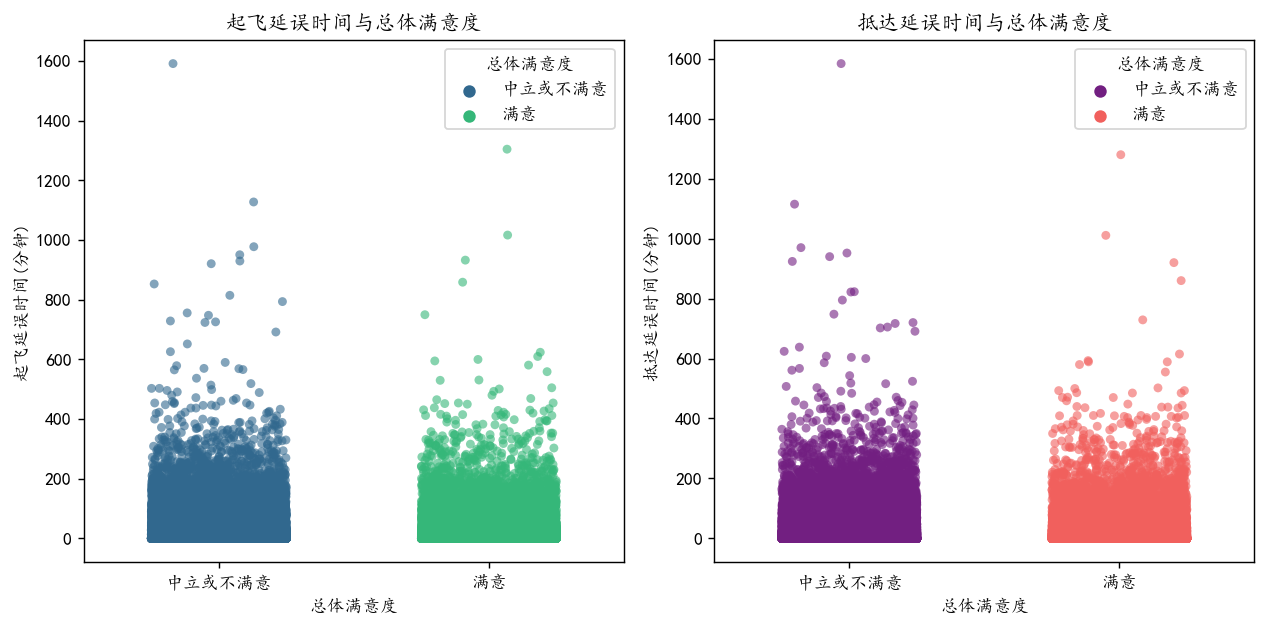
可以看到有很多极大值和前面的密度图结论是类似
客舱等级与满意度:
统计不同客舱等级(经济舱、商务舱、头等舱)的满意度比例
# 创建 1 行 2 列的子图
plt.figure(figsize=(10, 4), dpi=128)# 1. 条形图:不同舱位的满意度数量
ax1 = plt.subplot(1, 2, 1)
bar1 = sns.barplot(data=satisfaction_counts, x='客舱等级', y='数量', hue='总体满意度', palette=['lightblue', 'lightgreen', 'salmon'])
plt.title('不同舱位的总体满意度分布')
plt.xlabel('客舱等级')
plt.ylabel('满意度数量')
plt.xticks(rotation=0)
plt.legend(title='总体满意度')# 在柱子上添加数值标签
for p in bar1.patches:height = p.get_height()bar1.text(p.get_x() + p.get_width()/2., height + 3,f'{int(height)}', ha='center')# 2. 堆叠条形图:不同乘客类型的满意度比例
ax2 = plt.subplot(1, 2, 2)
bar2 = sns.barplot(data=satisfaction_counts2, x='乘客类型', y='数量', hue='总体满意度', palette='pastel')
plt.title('不同乘客类型的总体满意度比例')
plt.xlabel('乘客类型')
plt.ylabel('数量')
plt.xticks(rotation=0)
plt.legend(title='总体满意度')# 在柱子上添加数值标签
for p in bar2.patches:height = p.get_height()bar2.text(p.get_x() + p.get_width()/2., height + 3,f'{int(height)}', ha='center')# 显示图形
plt.tight_layout()
plt.show()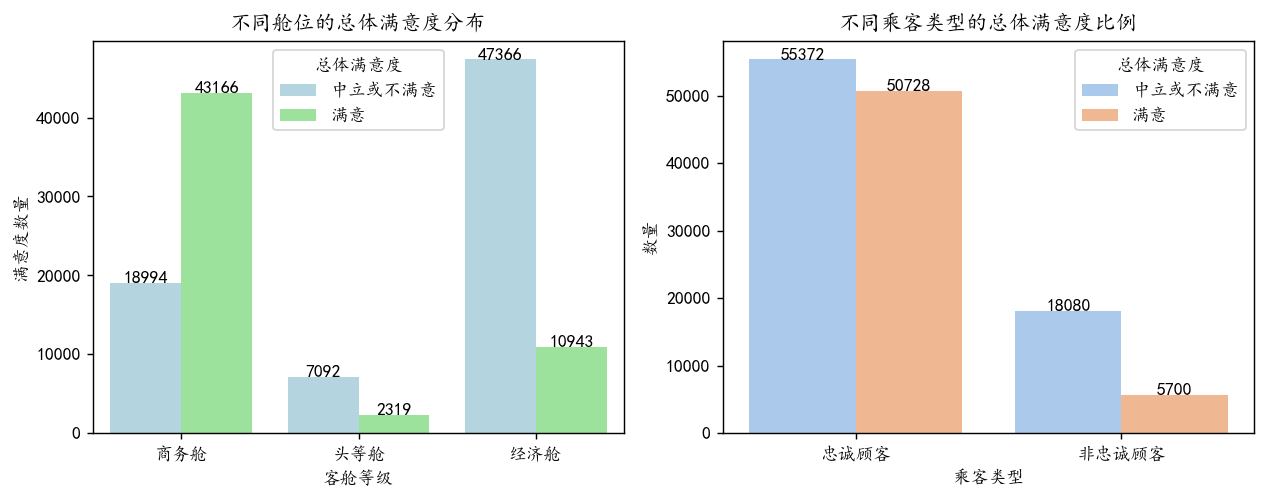
相关性分析:
计算数值型特征与目标变量的相关系数(PearsonSpearman) 筛选高相关特征
plt.figure(figsize=(15, 10),dpi=128)
# 计算spearman相关系数
corr = df.apply(lambda x: pd.factorize(x)[0]).corr('spearman').round(3)
sns.heatmap(corr, annot=True, cmap='viridis', center=0)
plt.show()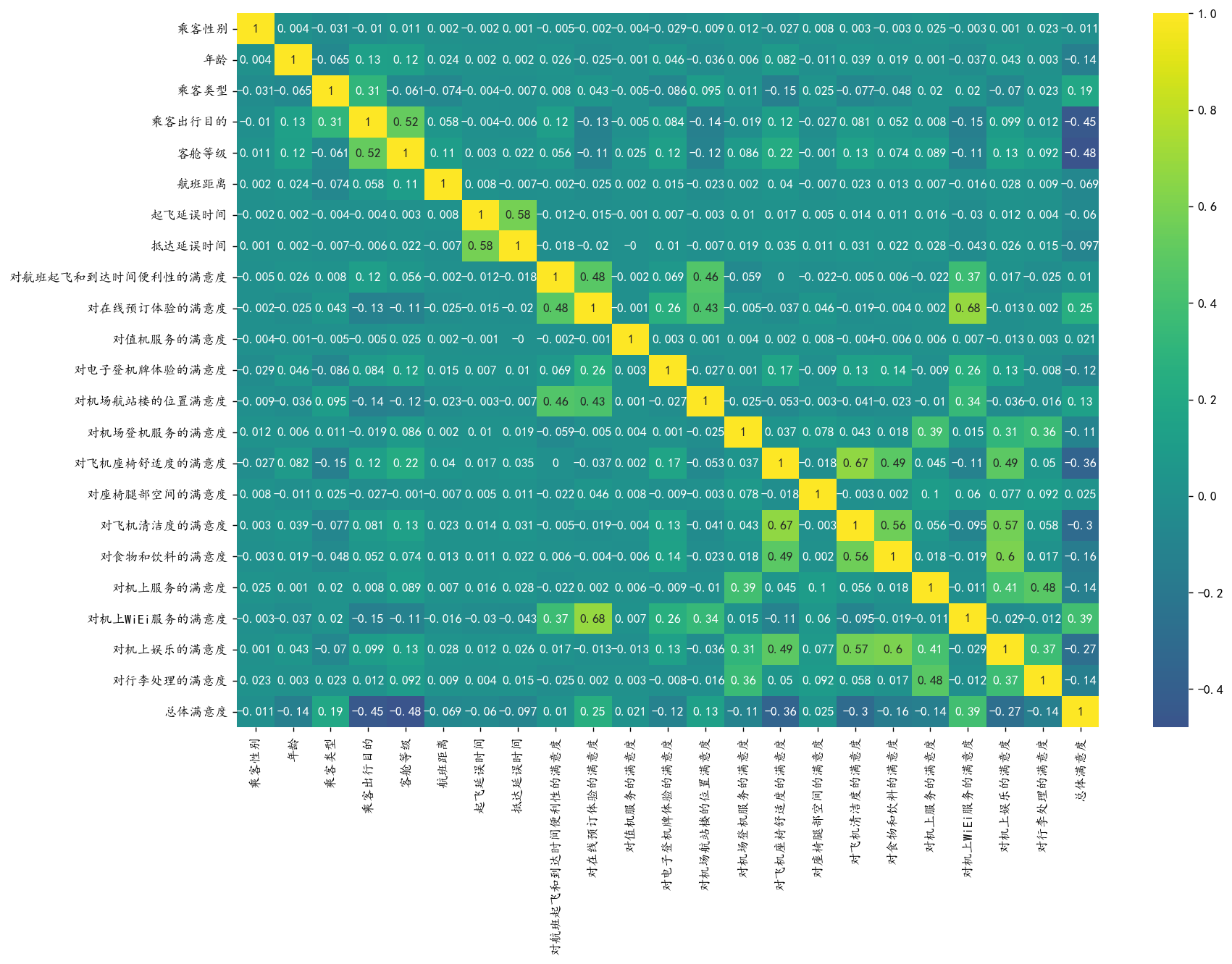
#### 高相关的特征
corr['总体满意度'][corr['总体满意度'].abs()>0.1].index
(三)特征工程
先进行前面的数据预处理中的异常值处理和数据转化
异常值处理
通过前面的分析,我们知道起飞延误时间跟抵达延误时间具有很多较大的异常值,我们需要进行一定的预处理
def plot_time(): plt.figure(figsize=(10, 4), dpi=128)plt.subplot(1, 2, 1)sns.boxplot(data=df, x='总体满意度', y='起飞延误时间', palette="coolwarm")plt.title('起飞延误时间分布 by 满意度')plt.subplot(1, 2, 2)sns.boxplot(data=df, x='总体满意度', y='抵达延误时间', palette="coolwarm")plt.title('抵达延误时间分布 by 满意度')plt.tight_layout()plt.show()
plot_time()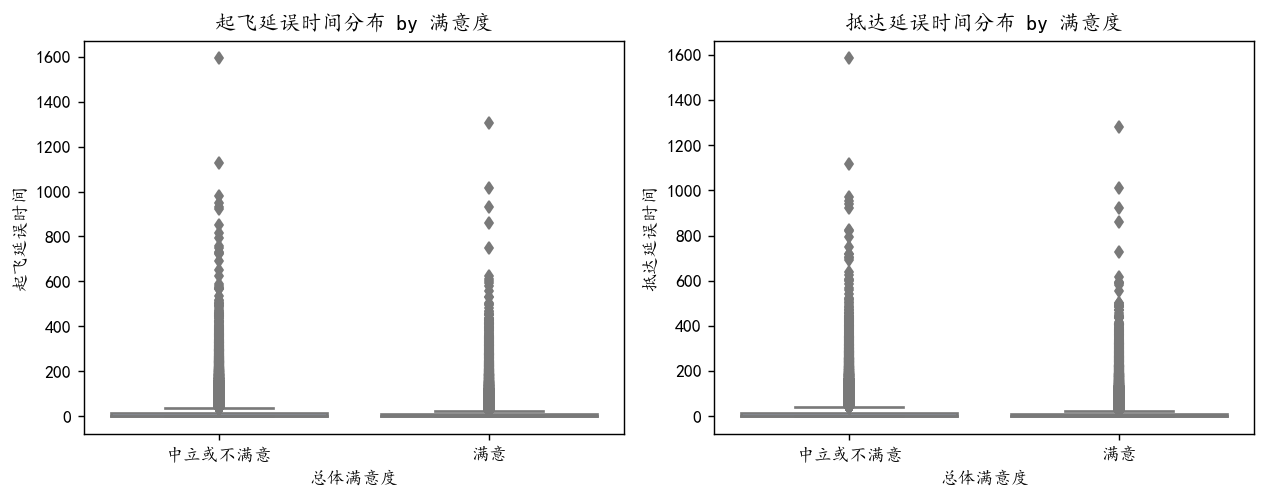
画出箱线图,我们可以观察到100以上的异常点较多,我们直接将100以上的异常值的样本都进行裁剪,数值压缩到100
df['起飞延误时间'] = df['起飞延误时间'].clip(upper=100)
df['抵达延误时间'] = df['抵达延误时间'].clip(upper=100)plot_time()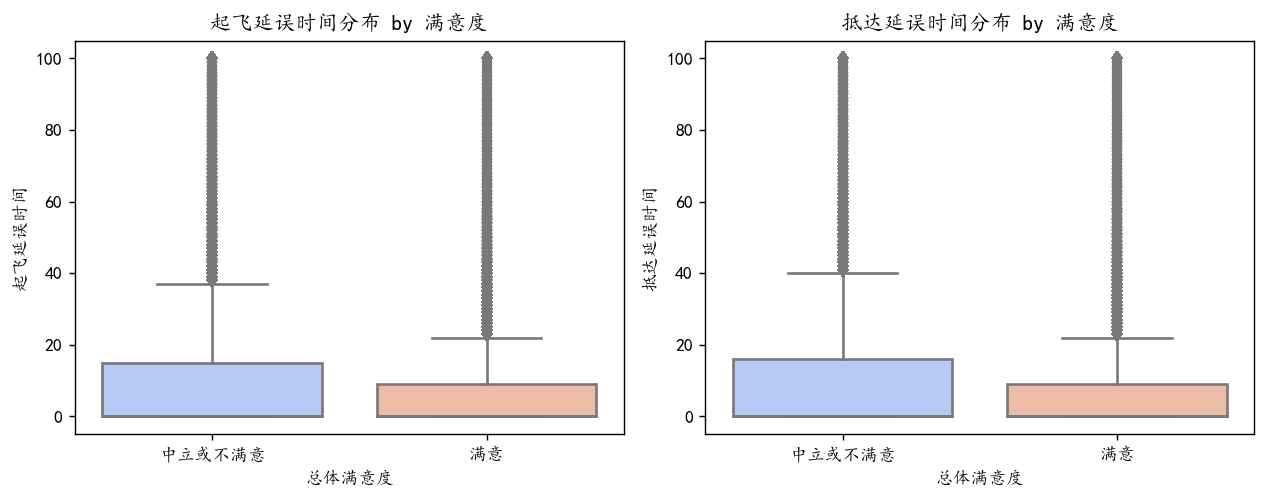
可以看到分布正常了很多
数据转化
首先需要包括将响应变量,特征变量,在类的分类型变量都转化为数值型变量进行标签编码
# 需要编码的列
cols_to_encode = ['乘客性别', '乘客类型', '乘客出行目的', '客舱等级', '总体满意度']# 标签编码
data = df.copy()
for col in cols_to_encode:data[col], uniques = pd.factorize(data[col])# 打印每个列的映射关系print(f"【{col}】映射表:")print(pd.Series(range(len(uniques)), index=uniques).to_frame('编码值'), '\n')
# 显示转换后的前5行
print("\n转换后的数据样例:")
display(data.head())
data.select_dtypes(exclude=['number']).columns #所有变量都转为了数值型变量,现在没有类别型变量了。
1. 特征组合
先组合衍生特征,再进行变量筛选
# # 1.1 总延误时间 = 起飞延误 + 抵达延误
# data['总延误时间'] = data['起飞延误时间'] + data['抵达延误时间']# # 1.2 是否延误(二值特征)
# data['是否延误'] = (data['总延误时间'] > 0.1).astype(int)# # 1.3 延误等级(离散化)
# data['延误等级'] = pd.cut(data['总延误时间'],bins=[-1, 0, 30, 120, float('inf')], labels=[0,1,2,3])# # 2.1 性别+客舱等级组合
# data['性别_舱位'] = data['乘客性别'].astype(str) + '_' + data['客舱等级'].astype(str)# # 2.2 类型+出行目的组合
# data['类型_目的'] = data['乘客类型'].astype(str) + '_' + data['乘客出行目的'].astype(str)# # 3.1 地面服务均分(值机+登机+行李)
# ground = ['对值机服务的满意度', '对机场登机服务的满意度', '对行李处理的满意度']
# data['地面服务分'] = data[ground].mean(axis=1)# # 3.2 机上服务均分(座椅+餐饮+娱乐)
# inflight = ['对飞机座椅舒适度的满意度', '对座椅腿部空间的满意度', '对食物和饮料的满意度', '对机上服务的满意度', '对机上娱乐的满意度']
# data['机上服务分'] = data[inflight].mean(axis=1)# # 3.3 数字体验均分(在线预订+电子登机牌+WiFi)
# digital = ['对在线预订体验的满意度', '对电子登机牌体验的满意度', '对机上WiEi服务的满意度']
# data['数字体验分'] = data[digital].mean(axis=1)衍生特征是必须要的尝试,但是我效果不好,感觉没必要,就注释掉了,可以运行,也可以不运行。
2. 特征重要性分析
from sklearn.ensemble import RandomForestClassifier# 准备数据 (y为'总体满意度', X为其他所有列)
y = data['总体满意度']
X = data.drop('总体满意度', axis=1)# 训练随机森林
rf = RandomForestClassifier(random_state=42)
rf.fit(X, y)画图可视化
mfs=pd.DataFrame(rf.feature_importances_,index=X.columns,columns=['Feature Importance']).sort_values('Feature Importance',ascending=False)
plt.figure(figsize=(6,7),dpi=128)
sns.barplot(y=mfs.index,x=mfs['Feature Importance'],orient='h')
plt.xlabel('Feature Importance')
#plt.ylabel('Feature')
plt.title('变量重要性')
plt.show()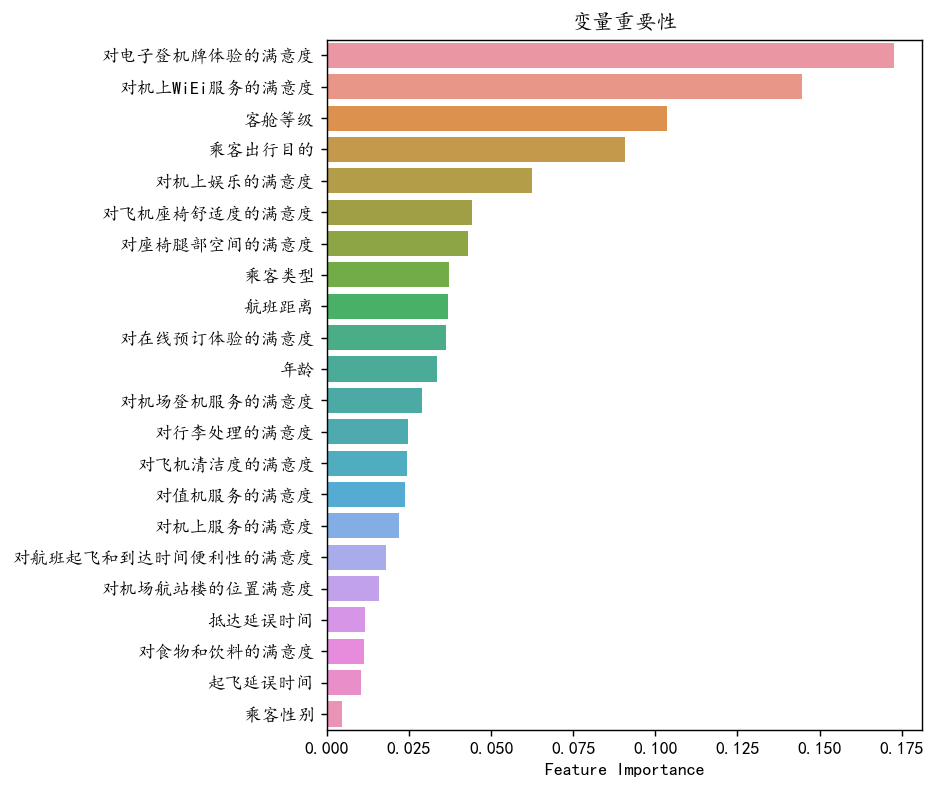
和描述性统计分析的类似乘客性别对于满意度没有任何显著性的影响,因此它最不重要。登机牌和WiFi上的服务对于变量有较强的影响。 我们选择过滤掉变量重要性不足0.015的变量
# 剔除的变量
mfs[mfs['Feature Importance']<0.015].index![]()
## 保留的变量
mfs[mfs['Feature Importance']>0.015].index
变量筛选后就已经进行了降维了 ,去掉了4个变量。
data_deal=data[mfs[mfs['Feature Importance']>0.015].index.to_list() +['总体满意度'] ]
data_deal.shape
数据标准化
X=data_deal.drop(columns='总体满意度')
y=data_deal['总体满意度']
X.shape,y.shape# 进行标准化
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X)
X_s = scaler.transform(X)
print('标准化后数据形状:')
print(X_s.shape,y.shape)
数据准备好了,12.98w,18列变量。
(四)模型构建与优化
模型选择
划分训练集和测测试集
#划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X_s,y,stratify=y,test_size=0.3,random_state=0)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)![]()
分类问题的评价指标体系 一般大家都是用准确率,精准度,召回率,F1值进行评价
### 定义评价指标函数
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_scoredef evaluation(y_test, y_predict):accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']precision=s['precision']recall=s['recall']f1_score=s['f1-score']#kappa=cohen_kappa_score(y_test, y_predict)return accuracy,precision,recall,f1_score #, kappa使用十种机器学习模型进行对比
#导包
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier#逻辑回归
model1 = LogisticRegression(C=1e10,max_iter=10000)#线性判别分析
model2 = LinearDiscriminantAnalysis()#K近邻
model3 = KNeighborsClassifier(n_neighbors=10)#决策树
model4 = DecisionTreeClassifier(random_state=7,max_features='sqrt',class_weight='balanced')#随机森林
model5= RandomForestClassifier(n_estimators=300, max_features='sqrt',random_state=7)#梯度提升
model6 = GradientBoostingClassifier(random_state=123)#极端梯度提升
model7 = XGBClassifier(objective='binary:logistic', random_state=1, eval_metric='logloss', use_label_encoder=False)#轻量梯度提升
model8 =LGBMClassifier(objective='binary', random_state=1, verbose=-1)#支持向量机
model9 = SVC(kernel="rbf", random_state=0, probability=True)#神经网络
model10 = MLPClassifier(hidden_layer_sizes=(16,8), random_state=1, max_iter=10000)model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['逻辑回归','线性判别','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']模型训练
#遍历所有的模型,训练,预测,评估
predictions = []df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
for i in range(len(model_list)):model_C=model_list[i]name=model_name[i]model_C.fit(X_train, y_train)pred=model_C.predict(X_test)y_proba = model_C.predict_proba(X_test)[:, 1] # Get predicted probabilitiespredictions.append((name, y_proba)) # Store model name and predictions#s=classification_report(y_test, pred)s=evaluation(y_test,pred)df_eval.loc[name,:]=list(s)print(f'{name}模型完成')
模型评估对比
df_eval.astype('float').style.bar(color='gold')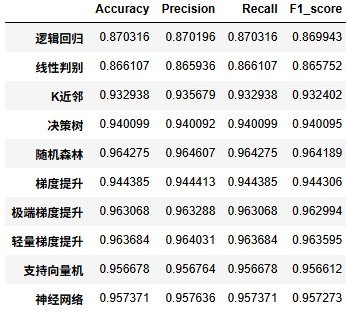
从上述模型的性能指标来看,随机森林和极端梯度提升(XGBoost)表现最佳,分别达到了 96.18% 和 96.27% 的准确率,显示出较强的分类能力。轻量梯度提升和随机森林紧随其后,准确率均在 96% 以上,提示它们在处理数据时依然有效。逻辑回归和线性判别分析的准确率相对较低,都在 86% 左右,可能是因为这些模型对数据的线性可分性假设不够强。
除了准确率之外,其他指标如精确率、召回率和 F1 分数也显示出相似的趋势,尤其是在lgbm和XGBoost中,这些指标均接近于 96%,表明这些模型在处理正负样本时都表现出良好的平衡。因此,考虑到模型的整体表现和复杂度,轻量梯度提升和极端梯度提升可能是该数据集的更优选择,适合进一步的应用和优化。
df_eval_sort = df_eval.sort_values('F1_score', ascending=False)# 设置颜色(十六进制颜色码前加#)
colors = ["#8f5362", "#b96570", "#d37b6d", "#e0a981", "#ecd09c","#d4daa1", "#a3c8a4", "#79b4a0", "#6888a5", "#706d94"
]# 创建图表
fig, ax = plt.subplots(2, 2, figsize=(12, 10), dpi=128)# 遍历每一列数据
for i, col in enumerate(df_eval_sort.columns):# 确定子图位置row = i // 2col_pos = i % 2# 获取当前子图current_ax = ax[row, col_pos]# 准备数据df_col = df_eval_sort[col]x = np.arange(len(df_col))heights = df_col.to_numpy()# 绘制柱状图bars = current_ax.bar(x, heights, width=bar_width, color=colors)# 添加数值标签for bar in bars:height = bar.get_height()current_ax.text(bar.get_x() + bar.get_width()/2., height,f'{height:.3f}', # 保留两位小数ha='center', va='bottom', fontsize=9) # 设置较小的字体大小# 设置坐标轴current_ax.set_xticks(x)current_ax.set_xticklabels(df_col.index, rotation=40, fontsize=10)current_ax.set_ylabel(col, fontsize=12)#current_ax.grid(axis='y', linestyle='--', alpha=0.7) # 添加横向网格线plt.tight_layout()
plt.show()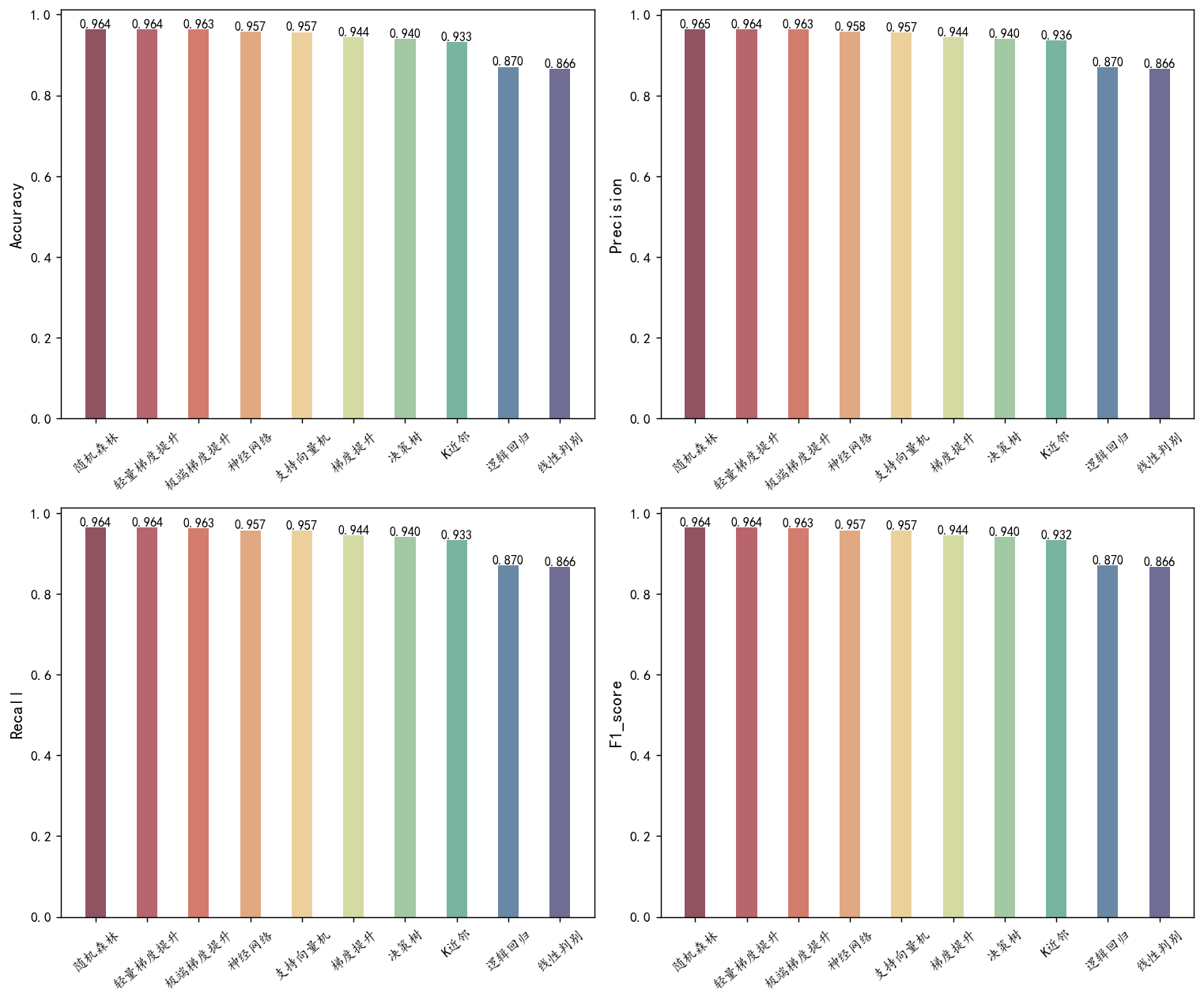
看起来 RF 和 LGBM 效果是最好的
不同模型的AUC曲线¶
from sklearn.metrics import confusion_matrix, roc_curve, auc
from sklearn.metrics import ConfusionMatrixDisplayplt.figure(figsize=(8, 6),dpi=128)# 遍历每个模型,绘制其 ROC 曲线
for name, y_proba in predictions:fpr, tpr, _ = roc_curve(y_test, y_proba)roc_auc = auc(fpr, tpr) # 计算 AUCplt.plot(fpr, tpr, label=f'{name} (AUC = {roc_auc:.6f})') # 绘制 ROC 曲线# 绘制对角线
plt.plot([0, 1], [0, 1], linestyle='--', color='grey', label='Random')
# 设置图形属性
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.show()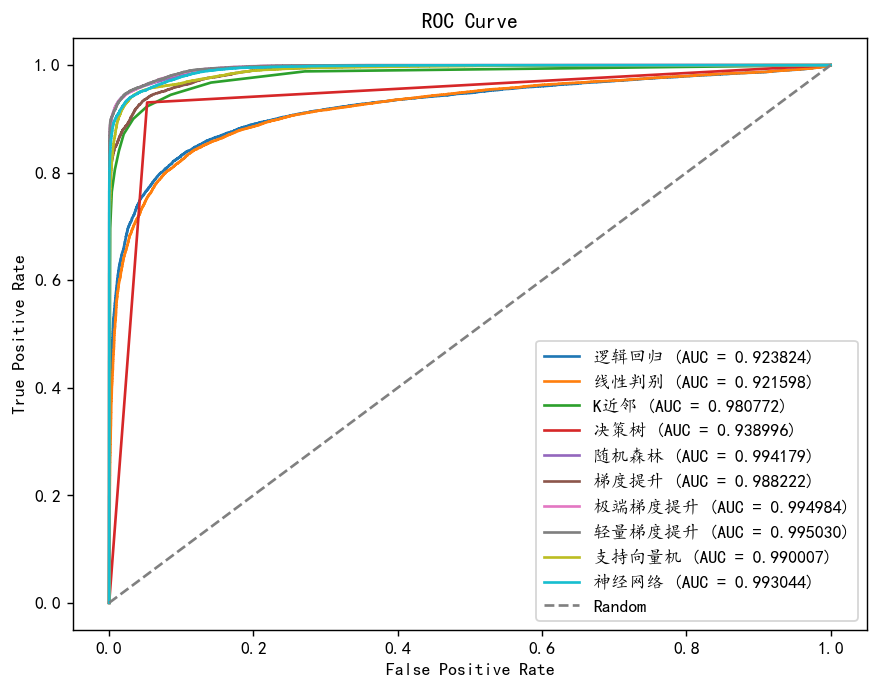
lightgbm表现最佳 ,作为最终的模型
(五)关键结果分析
影响满意度的核心因素 和 特征重要性排名
model =LGBMClassifier(objective='binary', random_state=1, verbose=-1)
model.fit(X_train, y_train)mfs1=pd.DataFrame(model.feature_importances_,index=data_deal.drop(columns=['总体满意度']).columns,columns=['Feature Importance']).sort_values('Feature Importance',ascending=False)
plt.figure(figsize=(6,6),dpi=128)
sns.barplot(y=mfs1.index,x=mfs1['Feature Importance'],orient='h')
plt.xlabel('Feature Importance')
#plt.ylabel('Feature')
plt.title('变量重要性')
plt.show()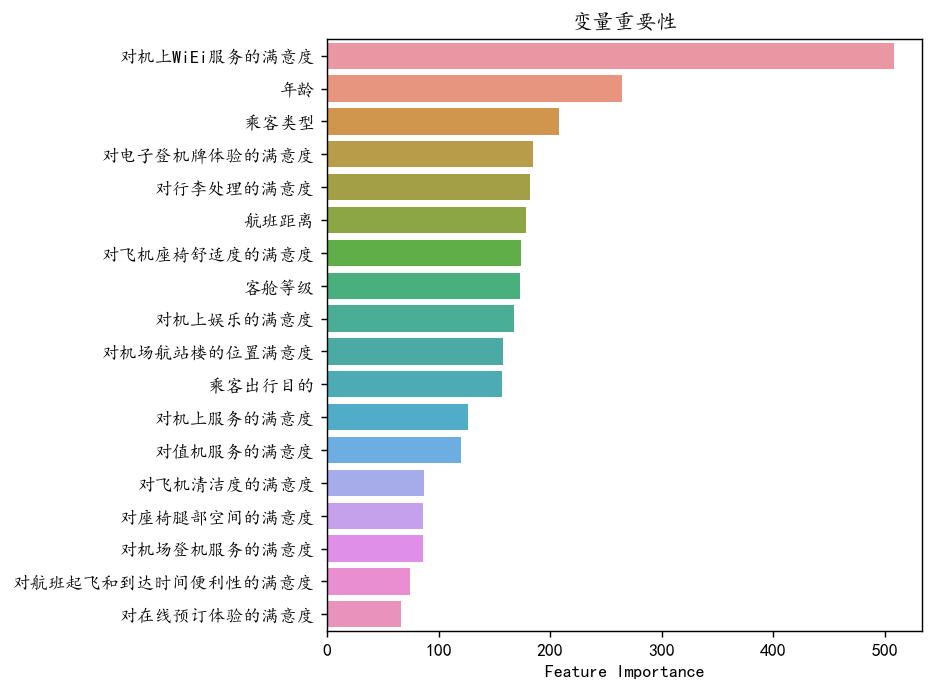
可以看到对对机上WiFi的满意程度年龄以及客户类型,等特征比较重要。
模型解释
X_test_shape= data_deal.drop(columns=['总体满意度']).sample(2000)# pd.DataFrame(data_deal,columns=data_deal.columns[:-1])由于shap包对于大数据比较慢,所以先采样。
计算shap值
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer(X_test_shape)shap值的重要性
shap.summary_plot(shap_values,X_test_shape, plot_type="bar")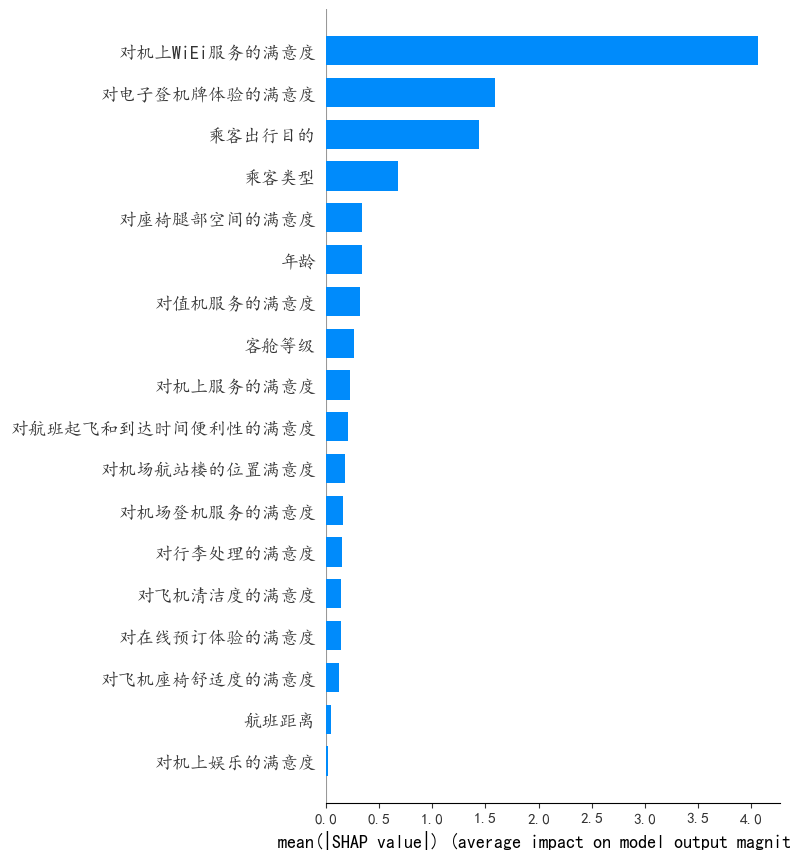
shap.plots.heatmap(shap_values, max_display=12)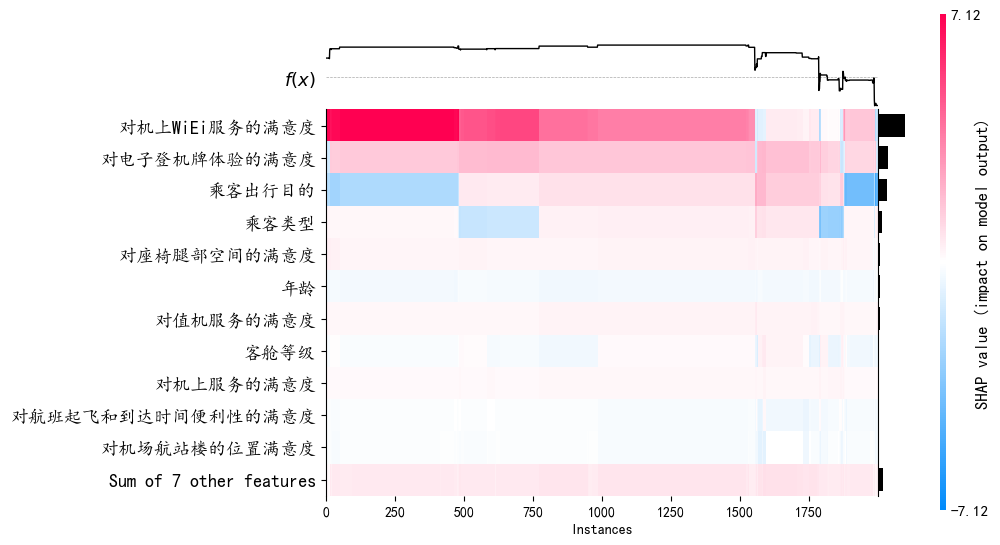
SHAP 值可视化解读
1. 图示说明
- 横轴(X轴):表示 SHAP 值(SHAP Value),即每个特征对模型预测的贡献大小。SHAP 值越大,表示该特征对预测结果的影响越大。
- 纵轴(Y轴):表示特征名称,按对模型预测的平均绝对 SHAP 值排序。越靠上的特征对模型预测的影响越大。
- 点的颜色:表示特征值的大小。颜色条右侧的数值表示特征值的范围(例如,红色表示特征值较高,蓝色表示特征值较低)。
- 点的分布:每个点代表一个样本,点的位置表示该样本的 SHAP 值和特征值。
2. 如何解读
- 正向影响:如果点的 SHAP 值为正(右侧),说明该特征值对预测结果有正向影响,即特征值越高,预测值可能越高。
- 负向影响:如果点的 SHAP 值为负(左侧),说明该特征值对预测结果有负向影响,即特征值越高,预测值可能越低。
3. 具体特征分析
以下是图中一些特征的解读:
-
对机上WiFi服务的满意度
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的 WiFi 满意度(红色)对预测结果有正向影响。
-
类型_目的
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的“类型_目的”特征值(红色)对预测结果有正向影响。
-
乘客出行目的
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的“乘客出行目的”特征值(红色)对预测结果有正向影响。
-
对电子登机牌体验的满意度
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的电子登机牌满意度(红色)对预测结果有正向影响。
-
客舱等级
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的客舱等级(红色)对预测结果有正向影响。
-
对行李处理的满意度
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的行李处理满意度(红色)对预测结果有正向影响。
-
数字体验分
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的数字体验分(红色)对预测结果有正向影响。
-
对飞机座椅舒适度的满意度
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的座椅舒适度满意度(红色)对预测结果有正向影响。
-
年龄
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的年龄(红色)对预测结果有正向影响。
-
对机上服务的满意度
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的机上服务满意度(红色)对预测结果有正向影响。
-
对值机服务的满意度
- 颜色分布:红色集中在右侧,蓝色集中在左侧。
- 解读:较高的值机服务满意度(红色)对预测结果有正向影响。
-
Sum of 9 other features
- 颜色分布:红色和蓝色分布较为均匀。
- 解读:其他 9 个特征的综合影响对预测结果的影响较小,且分布较为均匀。
计算shap平均值
mean_shap_values = np.abs(shap_values.values).mean(axis=0)
# 将结果放入DataFrame中便于比较
df_mean_shap_values = pd.DataFrame({ 'feature': X_test_shape.columns, 'mean_shap_value': mean_shap_values})
# 按平均绝对SHAP值排序
df_mean_shap_values = df_mean_shap_values.sort_values(by='mean_shap_value', ascending=False)
df_mean_shap_values.head(20).style.bar(color='skyblue')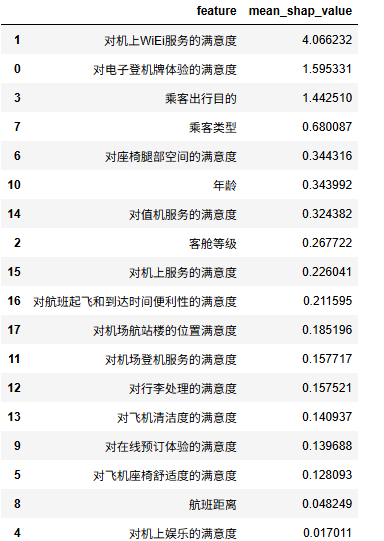
"对机上WiEi服务的满意度,类型_目的,乘客出行目的,对电子登机牌体验的满意度" 这四个变量在shap值很高,对于模型预测具有很强的作用
shap.summary_plot(shap_values, X_test_shape)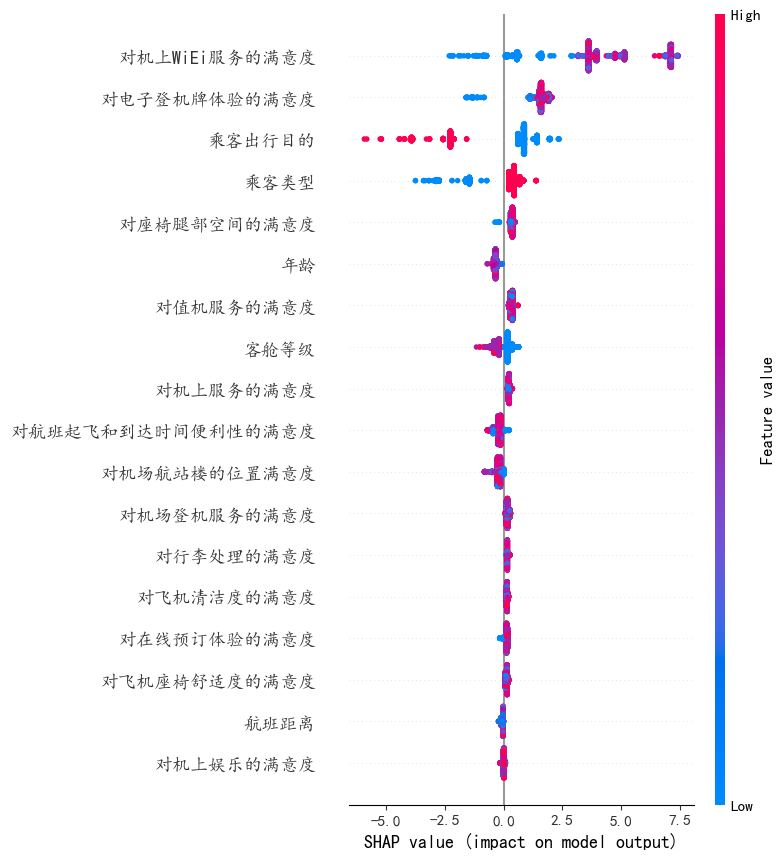
可以看到 红色表示取值高,前面的 “对机上WiEi服务的满意度对电子登机牌体验的满意度,乘客类型 ”取值越高,越可能预测为“满意” 而“客户出行目的,客舱等级” 越低越可能预测为满意
# 定义计算概率变化的函数
def prob_change(feature_shap, feature_name, threshold, X_data):"""计算当 feature_name < threshold 时,预测概率的变化"""mask = X_data[feature_name] < threshold# 将SHAP值转换为numpy数组后再索引shap_array = np.array(feature_shap)mean_shap_diff = shap_array[mask].mean() - shap_array[~mask].mean()
# print(explainer.expected_value)
# print(mean_shap_diff)# 计算概率变化(百分比)prob_increase = 100 * (1 / (1 + np.exp(-(explainer.expected_value + mean_shap_diff.values))) - 1 / (1 + np.exp(-explainer.expected_value)))return abs(prob_increase)# 要分析的特征列
wifi_col = "对机上WiEi服务的满意度"
boarding_col = "对电子登机牌体验的满意度"# 获取SHAP值(针对类别0,即不满意)
wifi_shap = shap_values[:, X_test_shape.columns.get_loc(wifi_col)]
boarding_shap = shap_values[:, X_test_shape.columns.get_loc(boarding_col)]# 计算不同阈值下的概率变化(确保X_test_shape改为X_test)
thresholds = [1, 2, 3, 4]
wifi_effects = {f"<{t}": prob_change(wifi_shap, wifi_col, t, X_test_shape)for t in thresholds
}
boarding_effects = {f"<{t}": prob_change(boarding_shap, boarding_col, t, X_test_shape)for t in thresholds
}print("机上WiFi服务评分阈值与不满意概率增加:", wifi_effects)
print("电子登机牌评分阈值与不满意概率增加:", boarding_effects)机上WiFi服务评分阈值与不满意概率增加: {'<1': 36.29717547995342, '<2': 35.92722060109572, '<3': 29.391566598479855, '<4': 18.41477977530111}
电子登机牌评分阈值与不满意概率增加: {'<1': 33.42452721349047, '<2': 15.846592511919125, '<3': 7.300050255122131, '<4': 4.345050384442367}
机上WiFi服务评分阈值与不满意概率增加:
- 评分小于1:如果乘客对机上WiFi服务的评分低于1分,那么他们表示不满意的概率会增加大约 **36.30%**。
- 评分小于2:如果乘客对机上WiFi服务的评分低于2分,那么他们表示不满意的概率会增加大约 **35.92%**。
- 评分小于3:如果乘客对机上WiFi服务的评分低于3分,那么他们表示不满意的概率会增加大约 **29.39%**。
- 评分小于4:如果乘客对机上WiFi服务的评分低于4分,那么他们表示不满意的概率会增加大约 **18.41%**。
电子登机牌评分阈值与不满意概率增加:
- 评分小于1:如果乘客对电子登机牌的评分低于1分,那么他们表示不满意的概率会增加大约 **33.42%**。
- 评分小于2:如果乘客对电子登机牌的评分低于2分,那么他们表示不满意的概率会增加大约 **15.84%**。
- 评分小于3:如果乘客对电子登机牌的评分低于3分,那么他们表示不满意的概率会增加大约 **7.3%**。
- 评分小于4:如果乘客对电子登机牌的评分低于4分,那么他们表示不满意的概率会增加大约 **4.34%**。
其他的特征分析
分析延误时间与满意度的关系
(验证"延误与满意度呈负相关")
### # 方法1:计算相关系数
from scipy.stats import spearmanr
corr, p = spearmanr(data['起飞延误时间'], data['总体满意度'])
print(f"延误时间与满意度相关系数: {corr:.3f} (p={p:.3f})")# 方法2:分组统计(更直观)
sns.boxplot(x='总体满意度', y='起飞延误时间', data=data)
plt.title("不同满意度组的起飞延误时间分布")
plt.show()![]()
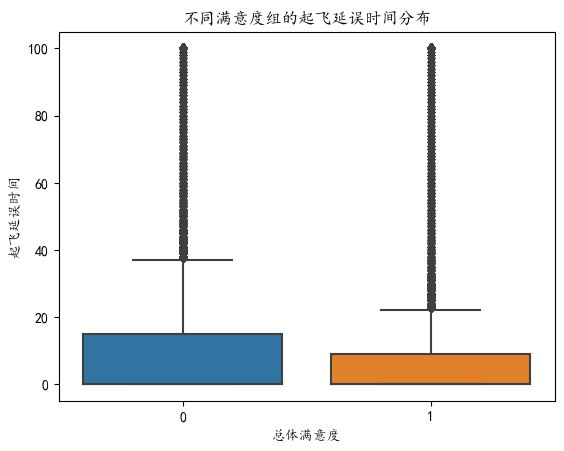
【总体满意度】映射表:
中立或不满意 0
满意 1
相关系数为负且显著(p<0.1),箱线图显示低满意度组(0)的延误时间中位数更高,说明总延误时间越长越不满意
分析商务舱乘客的延误容忍度
(验证"商务舱乘客对延误容忍度更高")
# 方法1:交互效应分析
sns.lmplot(x='起飞延误时间', y='总体满意度', hue='客舱等级', data=data, height=6, aspect=1.5)# 方法2:分组统计
delay_tolerance = data.groupby('客舱等级').apply( lambda x: spearmanr(x['起飞延误时间'], x['总体满意度']) )[0]
print("各舱位延误-满意度相关系数:\n", delay_tolerance)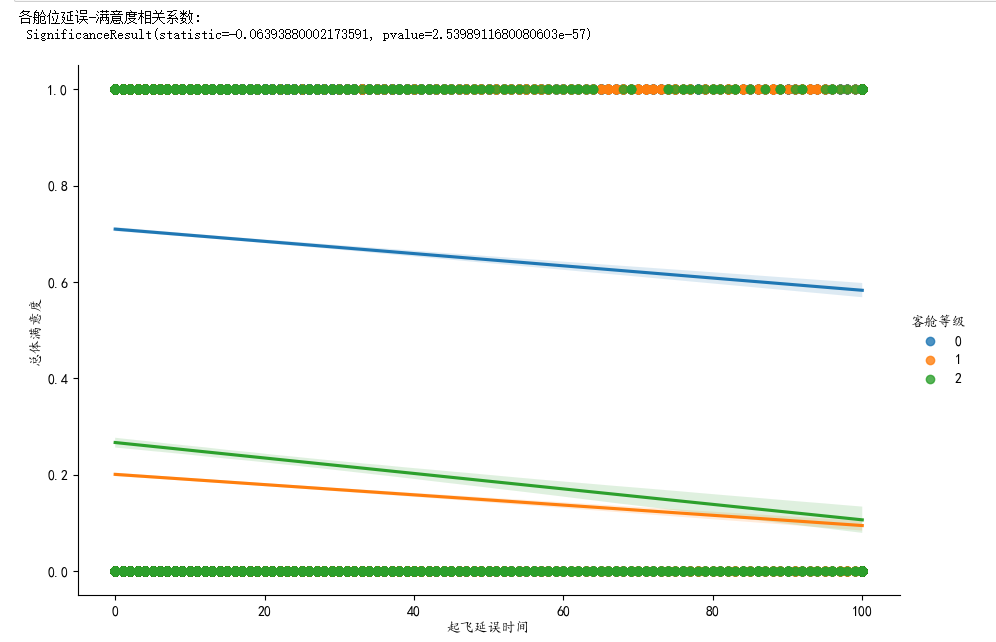 【客舱等级】映射表:
【客舱等级】映射表:
商务舱 0
经济舱 1
头等舱 2
可以看到 蓝色的商务舱满意度更高,并且交互性效的p值为0,说明不同客舱等级对于总体满意度是有显著性影响的
分析忠诚顾客的满意度
(验证"忠诚顾客满意度更高")
# 方法1:统计检验
from scipy.stats import mannwhitneyu
loyal = df[df['乘客类型']=='忠诚顾客']['总体满意度'].map({'中立或不满意': 0,'满意':1 })
non_loyal = df[df['乘客类型']=='非忠诚顾客']['总体满意度'].map({'中立或不满意': 0,'满意':1 })
stat, p = mannwhitneyu(loyal, non_loyal)
print(f"忠诚顾客 vs 非忠诚顾客满意度差异 p值: {p:.4f}")# 方法2:可视化
sns.violinplot(x='乘客类型', y='总体满意度', data=data)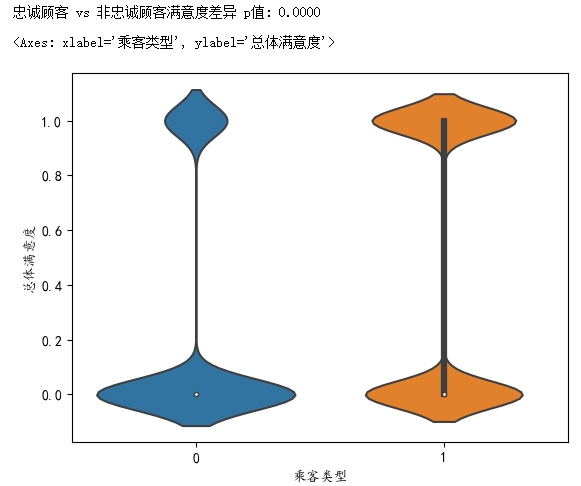
p<0.05,并且图从小提琴图很明显的可以看出乘客类型取值为1 (忠诚顾客)的时候总体满意度=1 的分布概率更高
非忠诚顾客 0
忠诚顾客 1
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~