大模型微调【2】之使用AutoDL进行模型微调入门
文章目录
- AutoDL服务器租用
- 说明
- 一 Unsloth安装部署
- 二 VLLM部署
- 2.1 VLLM部署
- 2.2 Qwen3模型权重下载
- 三 EvalScope安装部署
- 3.1 EvalScope安装
- 3.2 借助EvalScope进行压力测试
- 3.3 结果分析
- 3.4 模型性能评估
- 3.5 EvalScope可视化
- 四 wandb安装与注册
- 4.1 wandb简介
- 4.2 wandb注册与使用
- 五 Qwen3混合推理模型微调数据集
- 六 实践中的问题
- 6.1 系统盘容量不足及解决方法
AutoDL服务器租用
- 本次学习GPU服务器租用情况如下:

- 详细租用教程参看AutoDL使用学习
说明
- 本次将需要使用如下四项工具:
- 【必须】Unsloth:高效微调框架,必须安装使用。
- 【必选】vLLM:模型调度框架,用于验证微调后模型效果,也可以使用ollama或者其他调度框架进行模型微调后效果验证。
- 【可选】EvalScope:模型评测框架,用于对比微调前后模型性能,也可以通过人工观察进行评估。
- 【可选】wandb:模型训练数据在线记录工具,用于保存模型训练过程中损失之的变化情况,并监控服务器硬件数据。
- 若想尽快完成微调,可以只安装Unsloth即可,若希望完整执行完微调、过程监督和效果测试各环节,则需要完整安装完各框架工具。
一 Unsloth安装部署
- 由于要安装多个项目,因此建议创建虚拟环境以避免依赖冲突。
# 加速github和hugging face访问
source /etc/network_turbo
# 创建unsloth虚拟环境并激活
conda create --name unsloth python=3.11
conda init
source ~/.bashrc
conda activate unsloth
# 安装内核
conda install jupyterlab
conda install ipykernel
python -m ipykernel install --user --name unsloth --display-name "Python unsloth"
# 安装unsloth
pip install --upgrade --force-reinstall --no-cache-dir unsloth unsloth_zoo
-
安装完成后在Jupyter中选择unsloth kernel,即可进入对应的虚拟环境进行代码编写。
-
在jupyter notebook中执行如下代码:
from unsloth import FastLanguageModel import torch -
如果没有任何输出,说明安装成功;如果出现如下内容,可尝试执行下面的代码进行修复。
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning. /root/miniconda3/envs/unsloth/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm 🦥 Unsloth Zoo will now patch everything to make training faster!pip install --upgrade jupyter ipywidgets jupyter labextension install @jupyter-widgets/jupyterlab-manager pip install --upgrade "unsloth[cu128]" # 适用于 CUDA 12.8(NVIDIA GPU)
二 VLLM部署
2.1 VLLM部署
- 在AutoDL租赁的服务器,可以选择在默认环境中进行安装,也可以使用专门的虚拟环境进行安装
conda create --name vllm python=3.11
conda init
source ~/.bashrc
conda activate vllmpip install bitsandbytes
pip install --upgrade vllm
2.2 Qwen3模型权重下载
- 在魔搭社区上搜索
Qwen3-unsloth-bnb-4bit选择模型下载即可。(带有Unsloth标志的是动态量化模型,而不带unsloth则是普通量化模型)
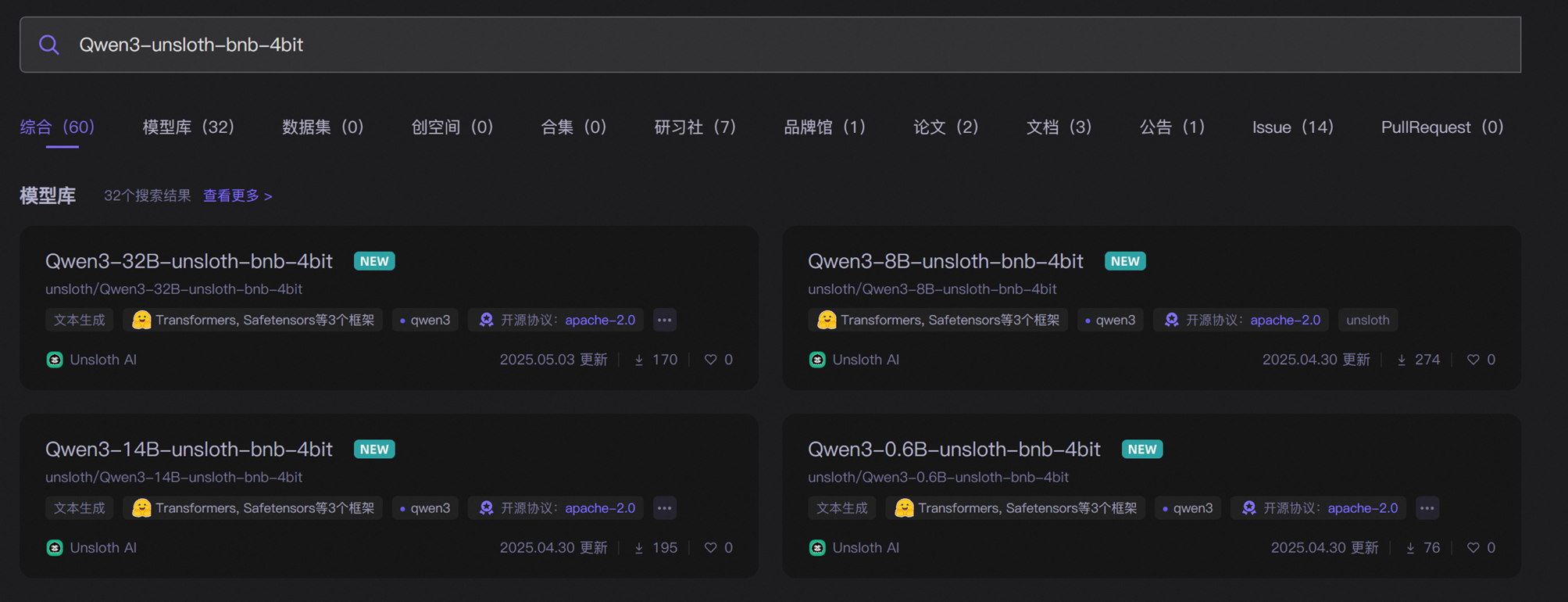
- 安装魔搭社区工具并进行下载
Qwen3-32B-unsloth-bnb-4bit模型pip install modelscope modelscope download --model unsloth/Qwen3-32B-unsloth-bnb-4bit --local_dir /root/autodl-tmp/Qwen3-32B-unsloth-bnb-4bit
vllm serve /root/autodl-tmp/Qwen3-32B-unsloth-bnb-4bit \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--pipeline-parallel-size 2
pip install openai
from openai import OpenAI# 初始化客户端
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)def check_models():"""查询并返回可用模型列表"""try:models = client.models.list()return [model.id for model in models.data]except Exception as e:print(f"Error checking models: {e}")return []def chat_with_model(model_name, message):"""与指定模型对话"""try:response = client.chat.completions.create(model=model_name,messages=[{"role": "user", "content": message}],)return response.choices[0].message.contentexcept Exception as e:return f"Error: {e}"# 主程序
if __name__ == "__main__":# 1. 检查可用模型available_models = check_models()print("Available models:", available_models)# 2. 使用正确的模型名称进行对话if available_models:# 使用第一个可用模型或指定模型model_to_use = available_models[0] # 或手动指定 "/root/autodl-tmp/Qwen3-32B-unsloth-bnb-4bit"response = chat_with_model(model_to_use, "你好,好久不见!")print("Model response:", response)else:print("No available models found. Please check server configuration.")
Available models: ['/root/autodl-tmp/Qwen3-32B-unsloth-bnb-4bit']
Model response: <think>
好的,用户发来“你好,好久不见!”,需要回复。首先,用户用了中文,所以保持中文回复。语气友好,可能需要热情回应。用户提到“好久不见”,说明之前有过交流,所以需要表达出高兴见到对方的感觉。可能需要询问近况,或者提到之前的对话内容,但如果没有记忆的话,可以保持一般性问候。注意保持自然,避免机械化的回复。可以加入表情符号或亲切的称呼,比如“朋友”或者“你”。同时,保持开放式的提问,鼓励用户继续对话。需要检查是否有拼写错误,确保回复流畅。最后,确认是否符合用户设定的角色,比如是否要活泼、正式或幽默。根据这些点,组织一个合适的回复。
</think>你好呀!是啊,好久不见啦~😊 最近过得怎么样?有什么有趣的事情想和我分享吗?或者需要帮忙解答什么问题?随时告诉我哦!
(base) root@autodl-container-9b594ca734-2819ef55:~# nvidia-smi
Sun Aug 17 18:04:58 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.64.05 Driver Version: 575.64.05 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA vGPU-48GB On | 00000000:64:00.0 Off | Off |
| 31% 38C P8 32W / 450W | 45019MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA vGPU-48GB On | 00000000:BD:00.0 Off | Off |
| 31% 35C P8 28W / 450W | 45535MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 18932 C ...nda3/envs/vllm/bin/python3.11 45010MiB |
| 1 N/A N/A 18933 C ...nda3/envs/vllm/bin/python3.11 45526MiB |
+-----------------------------------------------------------------------------------------+
三 EvalScope安装部署
3.1 EvalScope安装
- EvalScope官网
- 为了避免和Unsloth的依赖产生冲突,EvalScope需要再单独创建虚拟环境。
conda create --name evalscope python=3.11
conda init
source ~/.bashrc
conda activate evalscope
conda install ipykernel
python -m ipykernel install --user --name evalscope --display-name "Python evalscope"
- 或者将其安装在数据盘
conda create --prefix /root/autodl-tmp/evalscope --name evalscope python=3.11 -y
conda activate /root/autodl-tmp/evalscope
conda install ipykernel
python -m ipykernel install --user --name evalscope --display-name "Python evalscope"
# 必选
pip install evalscope# 安装 Native backend (默认)
pip install 'evalscope[perf]'#安装 模型压测模块依赖
pip install 'evalscope[app]'#安装 可视化 相关依赖
# 或者
pip install --cache-dir=/root/autodl-tmp/pip_cache 'evalscope[all]'
pip install --cache-dir=/root/autodl-tmp/pip_cache 'evalscope[perf]'
pip install --cache-dir=/root/autodl-tmp/pip_cache 'evalscope[app]'
# 额外选项
pip install 'evalscope[opencompass]'# 安装 Opencompass backend
pip install1 'evalscope[vlmeval]'# 安装 VLMEvalkit backend
pip install] 'evalscope[rag]'# 安装 RAGEva] backend
pip install 'evalscope[perf]'#安装 模型压测模块依赖
pip install 'evalscope[app]'#安装 可视化 相关依赖
# 或可以直接输入all,安装全部模块
# pip install 'evalscope[all]' # 安装所有 backends (Native,OpenCompass,VLMEvalkit, RAGEval)
3.2 借助EvalScope进行压力测试
- 尝试进行模型的压力测试,可以测试当前4bit动态量化模型在单卡H800上,由vllm调度框架驱动时的实际性能表现。
- 以下命令均在
evalscope环境中执行,下列参数中模型名称和vllm启动模型时模型名称保持一致。
cd /root/autodl-tmp/
mkdir Qwen3_32B_test/
cd Qwen3_32B_test
evalscope perf \--url "http://127.0.0.1:8000/v1/chat/completions" \--parallel 5 \--model /root/autodl-tmp/Qwen3-32B-unsloth-bnb-4bit \--number 20 \--api openai \--dataset openqa \--stream
3.3 结果分析
- 查看
/root/autodl-tmp/Qwen3_32B_test/outputs/20250817_200441/Qwen3-32B-unsloth-bnb-4bit/benchmark_summary.json文件,即可查看压测的benchmark。
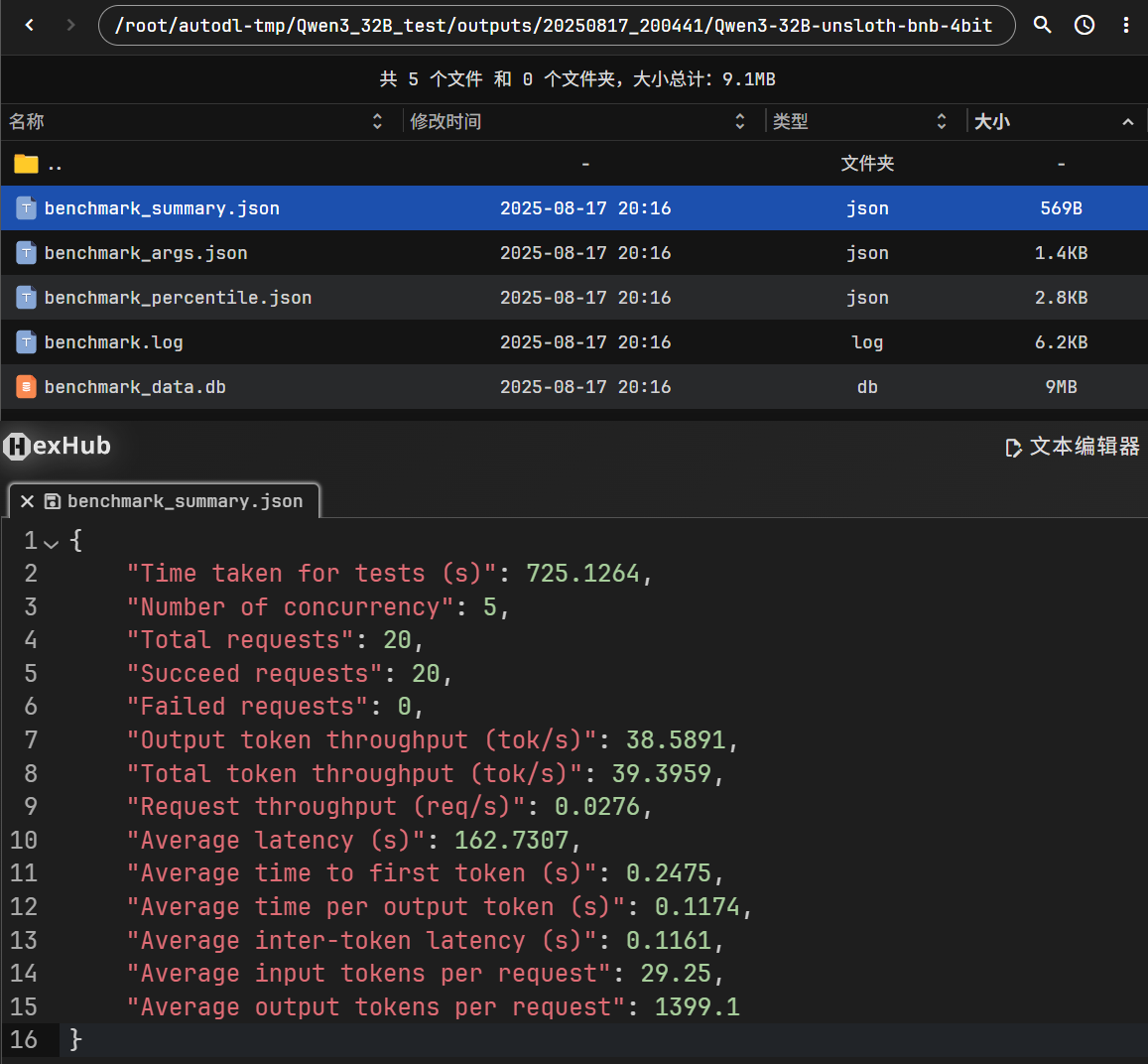
- Benchmarking summary
2025-08-17 20:16:51,989 - evalscope - INFO -
Benchmarking summary:
+-----------------------------------+-----------+
| Key | Value |
+===================================+===========+
| Time taken for tests (s) | 725.126 |
+-----------------------------------+-----------+
| Number of concurrency | 5 |
+-----------------------------------+-----------+
| Total requests | 20 |
+-----------------------------------+-----------+
| Succeed requests | 20 |
+-----------------------------------+-----------+
| Failed requests | 0 |
+-----------------------------------+-----------+
| Output token throughput (tok/s) | 38.5891 |
+-----------------------------------+-----------+
| Total token throughput (tok/s) | 39.3959 |
+-----------------------------------+-----------+
| Request throughput (req/s) | 0.0276 |
+-----------------------------------+-----------+
| Average latency (s) | 162.731 |
+-----------------------------------+-----------+
| Average time to first token (s) | 0.2475 |
+-----------------------------------+-----------+
| Average time per output token (s) | 0.1174 |
+-----------------------------------+-----------+
| Average inter-token latency (s) | 0.1161 |
+-----------------------------------+-----------+
| Average input tokens per request | 29.25 |
+-----------------------------------+-----------+
| Average output tokens per request | 1399.1 |
+-----------------------------------+-----------+
2025-08-17 20:16:51,998 - evalscope - INFO -
Percentile results:
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| Percentiles | TTFT (s) | ITL (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Output (tok/s) | Total (tok/s) |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| 10% | 0.2432 | 0.1191 | 0.1198 | 116.711 | 21 | 973 | 8.3065 | 8.4368 |
| 25% | 0.2438 | 0.1197 | 0.12 | 131.1056 | 26 | 1090 | 8.3116 | 8.4571 |
| 50% | 0.2453 | 0.1201 | 0.1202 | 175.6586 | 28 | 1510 | 8.3165 | 8.4949 |
| 66% | 0.2481 | 0.1203 | 0.1202 | 187.3121 | 31 | 1575 | 8.3256 | 8.5318 |
| 75% | 0.2491 | 0.1204 | 0.1203 | 192.5738 | 34 | 1635 | 8.3285 | 8.5634 |
| 80% | 0.2811 | 0.1205 | 0.1203 | 196.4327 | 37 | 1659 | 8.3333 | 8.5853 |
| 90% | 0.2824 | 0.1208 | 0.1203 | 212.1873 | 41 | 2048 | 8.3368 | 8.9661 |
| 95% | 0.283 | 0.121 | 0.1204 | 245.9431 | 45 | 2048 | 15.0027 | 15.1932 |
| 98% | 0.283 | 0.1213 | 0.1204 | 245.9431 | 45 | 2048 | 15.0027 | 15.1932 |
| 99% | 0.283 | 0.1215 | 0.1204 | 245.9431 | 45 | 2048 | 15.0027 | 15.1932 |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
- 压测核心指标解读
| 指标项 | 含义 | 解读 |
|---|---|---|
| Time taken for tests (s) | 总测试耗时 | 725.126 秒,表示本次压测运行了约 12 分钟。 |
| Number of concurrency | 并发数 | 使用了 5 个并发请求同时测试,表明模型支持一定程度的并发推理能力。 |
| Total requests | 总请求数 | 总共向模型发起了 20 次推理请求。 |
| Succeed requests / Failed requests | 成功与失败数 | 全部成功(20/20),说明模型稳定性良好。 |
- 吞吐性能
| 指标项 | 含义 | 解读 |
|---|---|---|
| Output token throughput (tok/s) | 每秒生成 token 数 | 38.5891 tok/s,生成速度在 4bit 动态量化大模型中属于正常偏低水平。 |
| Total token throughput (tok/s) | 总吞吐(包括输入+输出) | 39.39 tok/s,说明输入 token 占比较小,推理主要时间在输出部分。 |
| Request throughput (req/s) | 每秒处理请求数 | 0.0276 req/s,即大约 27 秒才完成一次请求(见下方 latency)。适用于高吞吐非交互式任务。 |
- 延迟分析
| 指标项 | 含义 | 解读 |
|---|---|---|
| Average latency (s) | 单次请求平均耗时 | 162 秒,即每个请求耗时超过 2 分钟,说明单次生成量很大。 |
| Average time to first token (s) | 首 token 延迟 | 0.2475 秒,响应启动速度非常快,体现了量化模型的推理启动效率。 |
| Average time per output token (s) | 每个生成 token 的平均耗时 | 0.1174 秒,略高,意味着模型速度偏慢,可能与显存带宽或激活参数有关。 |
- Token 分布与批处理
| 指标项 | 含义 | 解读 |
|---|---|---|
| Average input tokens per request | 每次输入平均 token 数 | 29.25,说明输入 prompt 很短。 |
| Average output tokens per request | 每次输出平均 token 数 | 1399.1,生成文本非常长,这解释了高 latency 与低 req/s。 |
- 优点:
- 模型非常稳定(20 次请求 100% 成功)
- 首 token 响应迅速(0.24 秒),表明部署结构良好
- 适合长文本生成类任务
- 缺点:
- 整体吞吐较低(35 tok/s),属于 32B 大模型的正常范围
- 单次推理耗时较长(每次平均 162 秒),适用于非实时场景。
3.4 模型性能评估
- 先尝试对其进行初始状态下的性能评估,然后等微调结束后,再进行新一轮的评估,进而对比微调前后模型性能变化情况。需要在
Jupyter中选择Python evalscope。 - 【可选】数据集构造代码:
from evalscope.collections import CollectionSchema, DatasetInfo, WeightedSampler
from evalscope.utils.io_utils import dump_jsonl_dataschema = CollectionSchema(name='Qwen3',datasets=[CollectionSchema(name='English',datasets=[DatasetInfo(name='mmlu_pro',weight=1,task_type='exam',tags=['en'],args={'few_shot_num': 0}),DatasetInfo(name='mmlu_redux',weight=1,task_type='exam',tags=['en'],args={'few_shot_num': 0}),DatasetInfo(name='ifeval',weight=1,task_type='instruction',tags=['en'],args={'few_shot_num': 0}),]),CollectionSchema(name='Chinese',datasets=[DatasetInfo(name='ceval',weight=1,task_type='exam',tags=['zh'],args={'few_shot_num': 0}),DatasetInfo(name='iquiz',weight=1,task_type='exam',tags=['zh'],args={'few_shot_num': 0}),]),CollectionSchema(name='Code',datasets=[DatasetInfo(name='live_code_bench',weight=1,task_type='code',tags=['en'],args={'few_shot_num': 0,'subset_list': ['v5_v6'],'extra_params': {'start_date': '2025-01-01', 'end_date': '2025-04-30'}}),]),CollectionSchema(name='Math&Science',datasets=[DatasetInfo(name='math_500',weight=1,task_type='math',tags=['en'],args={'few_shot_num': 0}),DatasetInfo(name='aime24',weight=1,task_type='math',tags=['en'],args={'few_shot_num': 0}),DatasetInfo(name='aime25',weight=1,task_type='math',tags=['en'],args={'few_shot_num': 0}),DatasetInfo(name='gpqa',weight=1,task_type='knowledge',tags=['en'],args={'subset_list': ['gpqa_diamond'], 'few_shot_num': 0})])]
)# 获取混合数据
mixed_data = WeightedSampler(schema).sample(100000000) # 设置大数以确保所有数据集被采样
# 将混合数据转储到jsonl文件
dump_jsonl_data(mixed_data, 'outputs/qwen3_test.jsonl')
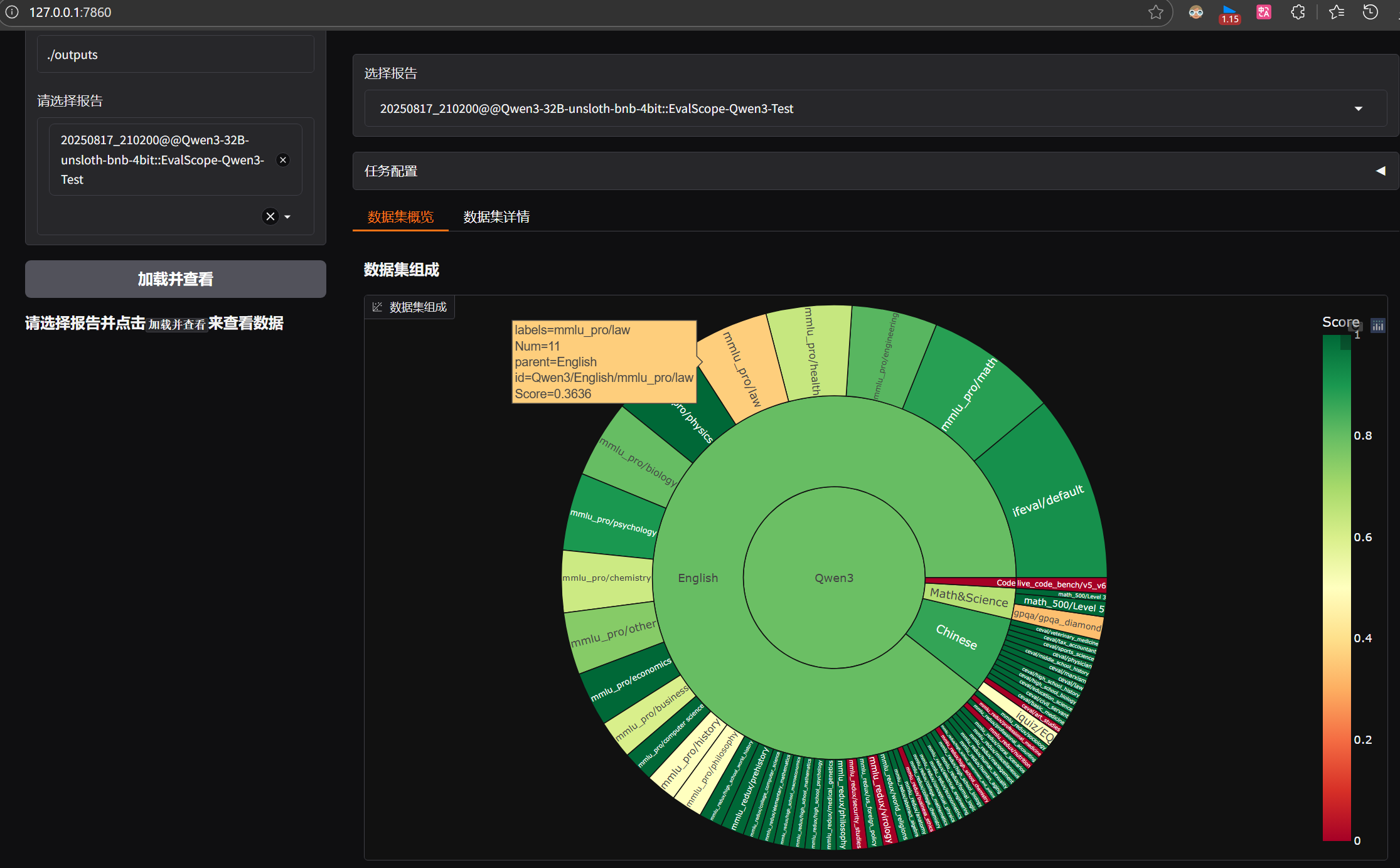
- EvalScope专门为Qwen3准备的modelscope/EvalScope-Qwen3-Test数据集进行评测,会围绕模型的推理、指令跟随、代理能力和多语言支持方面能力进行测试,该数据包含mmlu_pro 、ifeval 、live_code_bench 、math_500 、aime24 等各著名评估数据集。
- 评测代码如下:
from evalscope import TaskConfig, run_tasktask_cfg = TaskConfig(model='/root/autodl-tmp/Qwen3-32B-unsloth-bnb-4bit',api_url='http://127.0.0.1:8000/v1/chat/completions',eval_type='service',datasets=['data_collection',],dataset_args={'data_collection': {'dataset_id': 'modelscope/EvalScope-Qwen3-Test','filters': {'remove_until': '</think>'} # 过滤掉思考的内容}},eval_batch_size=128,generation_config={'max_tokens': 30000, # 最大生成token数,建议设置为较大值避免输出截断'temperature': 0.6, # 采样温度 (qwen 报告推荐值)'top_p': 0.95, # top-p采样 (qwen 报告推荐值)'top_k': 20, # top-k采样 (qwen 报告推荐值)'n': 1 # 每个请求产生的回复数量},timeout=60000, # 超时时间stream=True, # 是否使用流式输出limit=200 # 设置为200条数据进行测试
)run_task(task_cfg=task_cfg)
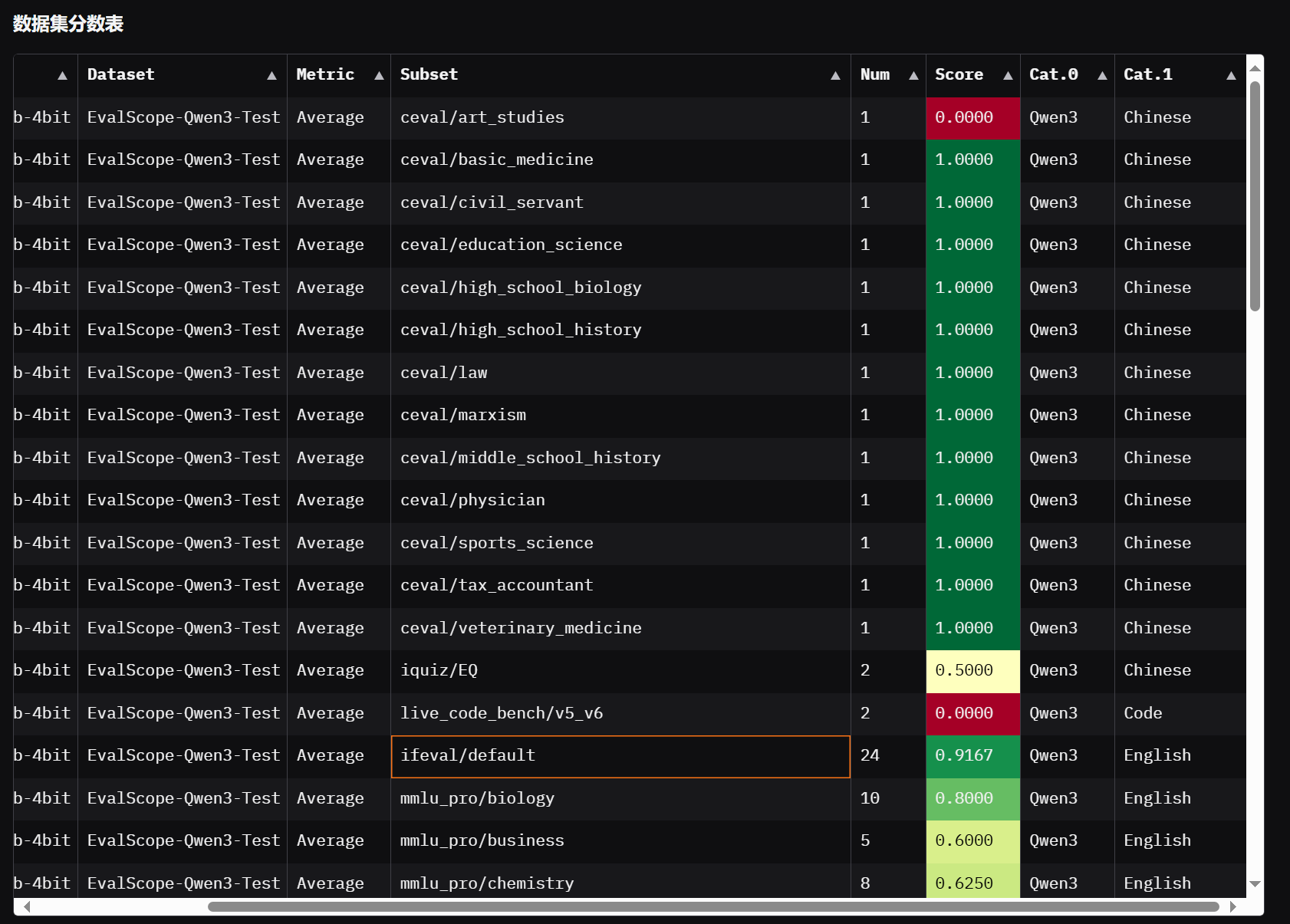
3.5 EvalScope可视化
-
EvalScope可视化详细参考资料ModelScope EvalScope可视化指南
-
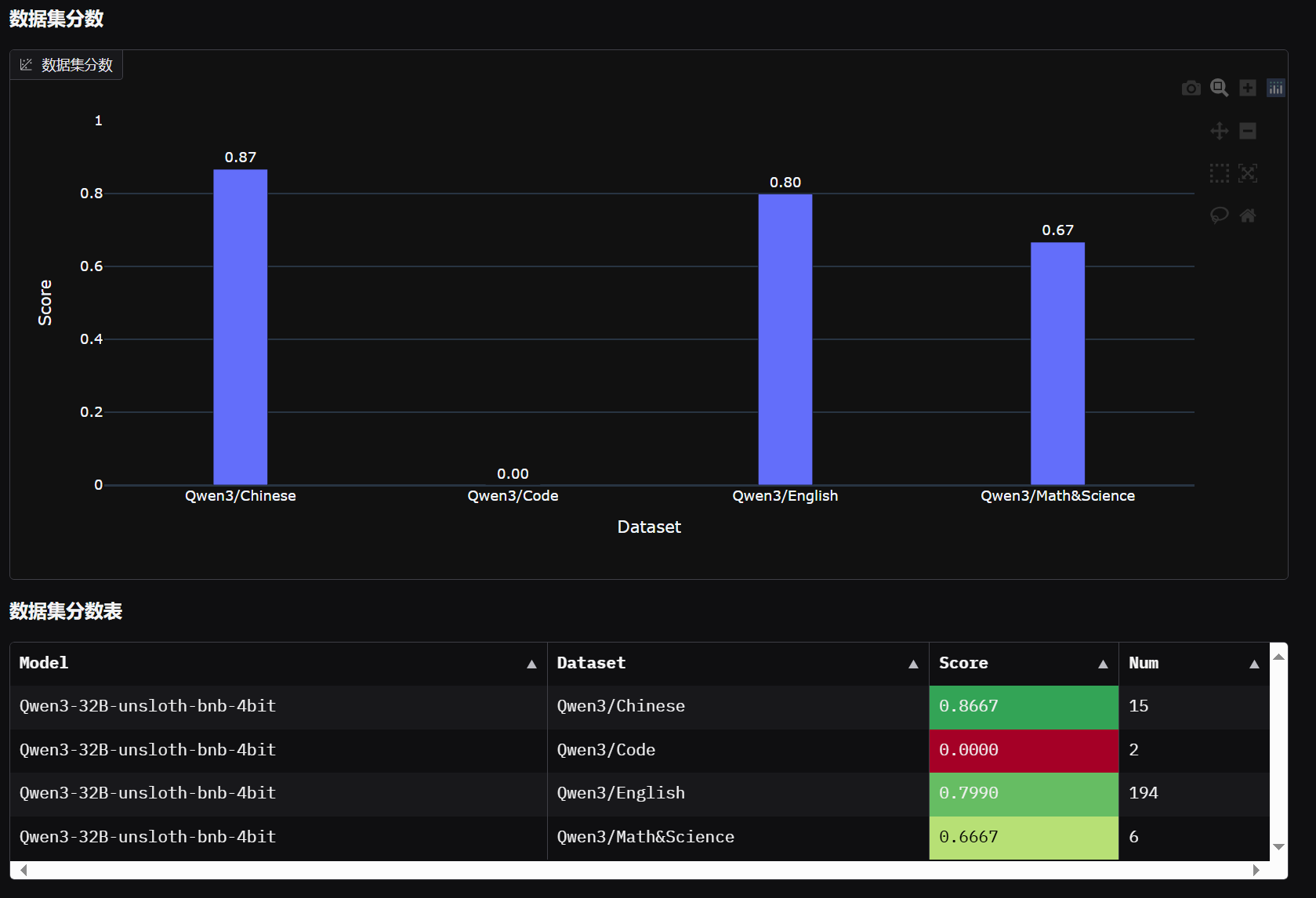
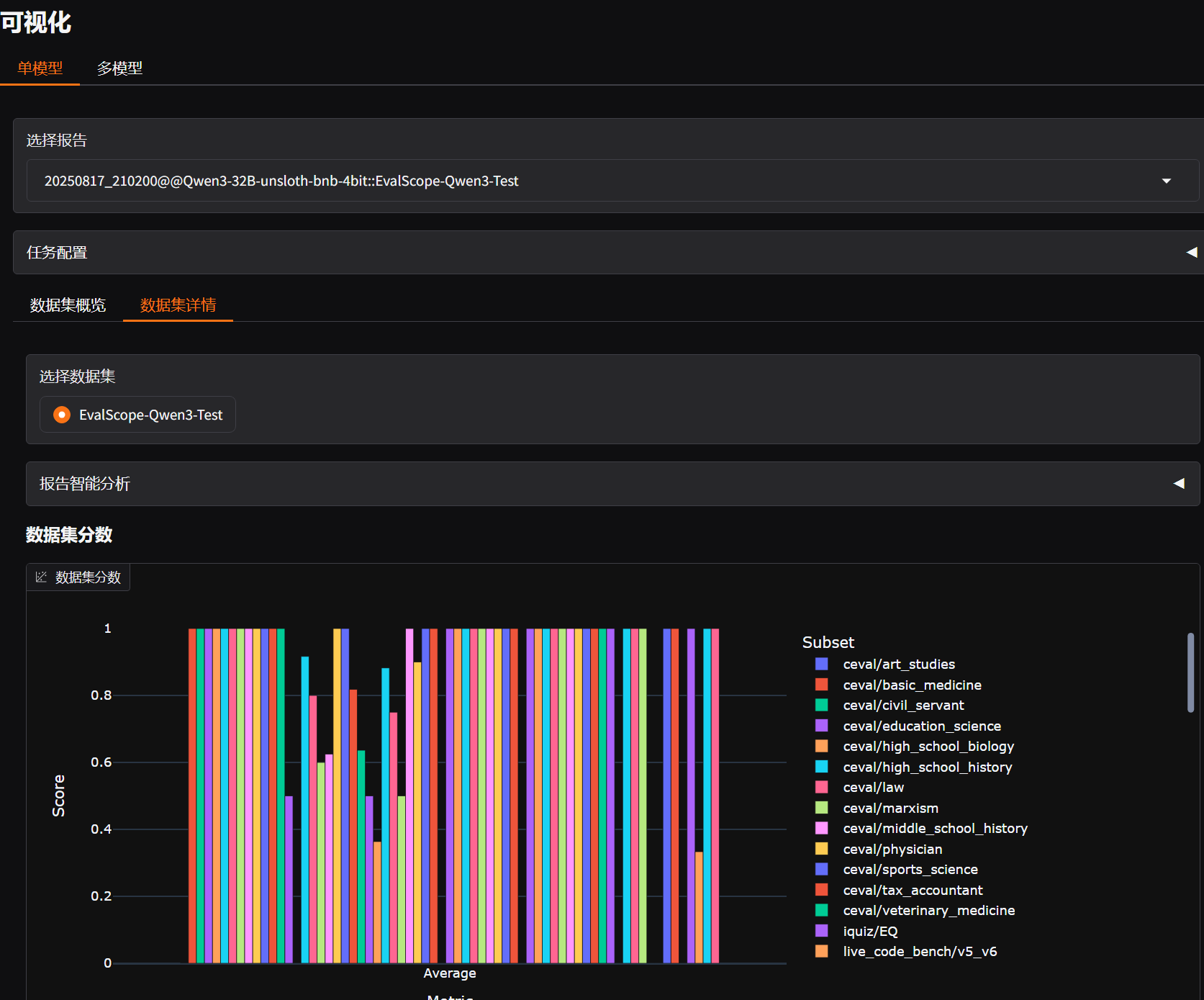
查看模型能力评测结果,在evalscope虚拟环境终端中执行:
evalscope app -
支持的命令行参数如下:
--outputs: 类型为字符串,用于指定评测报告所在的根目录,默认值为./outputs。--lang: 类型为字符串,用于指定界面语言,默认值为中文zh,支持zh和en。--share: 作为标志参数,是否共享应用程序,默认值为False。--server-name: 类型为字符串,默认值为0.0.0.0,用于指定服务器名称。--server-port: 类型为整数,默认值为7860,用于指定服务器端口。--debug: 作为标志参数,是否调试应用程序,默认值为False。
-
执行命令:
(/root/autodl-tmp/evalscope) root@autodl-container-9b594ca734-2819ef55:~/autodl-tmp# evalscope app
2025-08-17 20:31:56,198 - matplotlib.font_manager - INFO - generated new fontManager
* Running on local URL: http://0.0.0.0:7860To create a public link, set `share=True` in `launch()`.
- 通过AutoDL SSH隧道工具挂载7860服务到本地进行访问。
四 wandb安装与注册
4.1 wandb简介
- 在大规模模型训练中,往往需要监控和分析大量的训练数据,而WandB可以帮助我们实现这一目标。它提供了以下几个重要的功能:
- 实时可视化:WandB可以实时展示训练过程中关键指标的变化,如损失函数、学习率、训练时间等。通过这些可视化数据,能够直观地了解模型的训练进展,快速发现训练中的异常或瓶颈。
- 自动记录与日志管理:WandB会自动记录每次实验的参数、代码、输出结果,确保实验结果的可追溯性。无论是超参数的设置,还是模型的架构调整,WandB都能够帮助我们完整保留实验记录,方便后期对比与调优。
- 支持中断与恢复训练:在长时间的预训练任务中,系统中断或需要暂停是常见的情况。通过WandB的checkpoint功能,可以随时恢复训练,从上次中断的地方继续进行,避免数据和时间的浪费。
- 多实验对比:当我们尝试不同的模型配置或超参数时,WandB允许我们在多个实验之间轻松进行对比分析,帮助我们选择最优的模型配置。
- 团队协作:WandB还支持团队协作,多个成员可以共同查看实验结果,协同调试模型。这对研究和项目开发中团队的合作非常有帮助。
4.2 wandb注册与使用

- 在unsloth虚拟环境中安装wandb
pip install wandb - 在unsloth微调前,我们即可设置wandb进行微调记录,并可在对应网站上观察到训练过程
五 Qwen3混合推理模型微调数据集
- 可以考虑在微调数据集中加入如普通对话数据集FineTome,以及带有推理字段的数学类数据集OpenMathReasoning,并围绕这两个数据集进行拼接,从而在确保能提升模型的数学能力的同时,保留非推理的功能。同时还需要在持续微调训练过程中不断调整COT数学数据集和普通文本问答数据集之间的配比,以确保模型能够在提升数学能力的同时,保留混合推理的性能。
- **OpenMathReasoning**是为 AI Mathematical Olympiad - Progress Prize 2(AIMO-2)竞赛开发的高质量数学推理数据集。该数据集包含:540,000 道独特的高质量数学问题,涵盖代数、组合、几何和数论等领域;3,200,000 条详细的长推理解答;1,700,000 条工具集成推理(Tool-Integrated Reasoning)解答,结合了代码执行与推理过程;生成式解答选择(GenSelect) 方法,用于从多个候选解答中选择最优解。该数据集旨在推动 AI 在复杂数学推理任务中的能力提升,已被用于训练在多个数学推理基准上表现优异的模型。
- OpenMathReasoning数据集格式包含
expected_answer、problem和generated_solution三个核心字段,分别代表问题答案、问题和模型思考过程。 - FineTome是由 Maxime Labonne 创建的高质量多轮对话数据集,采用 ShareGPT 风格,适用于大语言模型的微调。该数据集特点包括:100,000 条多轮对话样本;数据以 JSONL 格式存储,每条记录包含一个 “conversations” 字段,记录对话的完整历史;对话格式类似于 ShareGPT,适合训练模型进行多轮对话;可转换为 Hugging Face 通用的多轮对话格式,以适配不同的训练框架。
六 实践中的问题
6.1 系统盘容量不足及解决方法
/root/autodl-tmp数据盘扩容,如扩容50GB。- 删除创建的evalscope虚拟环境,并删除内核,安装在
/root/autodl-tmp数据盘。
conda env remove --name evalscope
conda create --prefix /root/autodl-tmp/evalscope --name evalscope python=3.11 -y
```python
# 列出所有 Jupyter 内核
jupyter kernelspec list
# 删除指定内核
jupyter kernelspec remove evalscope
# 检查是否彻底删除
ls ~/.local/share/jupyter/kernels/ # 查看是否残留
```
- 清理 Conda 缓存(可选)
conda clean --all -y - 修改默认pip缓存目录
export PIP_CACHE_DIR=/root/autodl-tmp/pip_cache mkdir -p $PIP_CACHE_DIR