系统介绍pca主成分分析算法
PCA(Principal Component Analysis,主成分分析)是一种经典的无监督线性降维技术,核心目标是通过正交变换将高维数据投影到低维空间,同时最大化保留原始数据的方差信息(即最重要的特征)。它广泛应用于数据压缩、可视化、去噪、特征提取等领域。以下是对PCA算法的系统介绍:
一、核心思想:用少数主成分概括数据变异
在高维空间中,数据的分布往往存在相关性(各维度并非独立),导致有效信息集中在某个低维子空间内。PCA通过寻找一组新的正交基(称为“主成分”),将这些基按对应方向的数据方差从大到小排序,仅保留前k个最大的主成分,即可用更少的维度近似原始数据的主要结构
简单来说:用尽量少的新变量(主成分),解释原数据的大部分变化
二、数学基础与关键概念
1. 标准化预处理(关键前提)
若原始数据的量纲差异大(如身高vs收入),直接计算会受尺度影响。因此第一步通常是对每个特征做中心化(减去均值)和/或标准化(除以标准差),使各维度均值为0、方差为1。这一步确保所有特征对结果的贡献平等。
2. 协方差矩阵与散度衡量
假设标准化后的样本矩阵为  (n个样本,p个特征),则其协方差矩阵为:
(n个样本,p个特征),则其协方差矩阵为: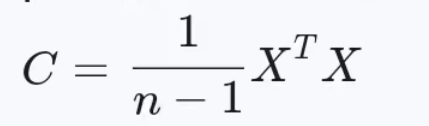
协方差的物理意义是两个维度之间的共变程度:
对角线元素是各维度自身的方差(反映该方向上的离散度),非对角线元素是不同维度间的相关性。PCA的本质是挖掘这个矩阵的最大特征值对应的方向——因为方差越大的方向,包含的信息越多。
3. 特征分解:从协方差矩阵到主成分
通过求解协方差矩阵的特征方程 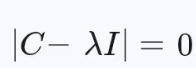 ,得到一组特征值
,得到一组特征值 ![]() 和对应的单位特征向量
和对应的单位特征向量 ![]() (相互正交)。其中:
(相互正交)。其中:
- 主成分的顺序由特征值大小决定:第1主成分(PC1)对应最大特征值,方向是数据变化最显著的方向;第2主成分(PC2)次之,且与PC1正交……依此类推。
- 总方差的比例:前k个主成分累计贡献的方差占比为
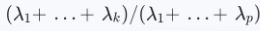 ,可用于确定保留多少维(如保留95%方差所需的最小k)。
,可用于确定保留多少维(如保留95%方差所需的最小k)。
4. 投影降维
- 选定前k个主成分后,将原始数据投射到这k个正交基上,得到低维表示:
![]()
其中![]() 是前k个特征向量组成的矩阵。此时Y的每行是一个样本在低维空间中的坐标,几乎不损失关键信息。
是前k个特征向量组成的矩阵。此时Y的每行是一个样本在低维空间中的坐标,几乎不损失关键信息。
三、几何直观理解
想象三维空间中的一群点大致分布在一个扁平的二维平面上(类似煎饼形状)。这时第三个维度(高度)的方差接近0,说明大部分变化发生在前两个维度。PCA会自动找到这个平面作为前两个主成分,将三维数据压缩到二维而几乎不失真。推广到更高维,PCA相当于找到数据的“超平面”,用最少的坐标轴覆盖主要散布方向。
四、实现步骤详解
以Python为例,完整流程如下:
1. 数据中心化:对每个特征列减去均值,使均值归零。
X_mean = np.mean(X, axis=0)
X_centered = X - X_mean2. 计算协方差矩阵(或直接用SVD替代):
cov_mat = np.cov(X_centered, rowvar=False) # rowvar=False表示按列计算特征间的协方差 3. 特征分解:获取特征值和特征向量。
eigenvalues, eigenvectors = np.linalg.eig(cov_mat)# 按特征值降序排序sorted_idx = np.argsort(eigenvalues)[::-1]eigenvalues_sorted = eigenvalues[sorted_idx]eigenvectors_sorted = eigenvectors[:, sorted_idx]4. 选择前k个主成分:根据累积解释方差比例决定k(如≥95%)。
5. 投影数据:将原数据与选中的特征向量相乘,得到降维结果。
pca_result = X_centered @ eigenvectors_sorted[:, :k] 注意:实际编程中更高效的方法是使用奇异值分解(SVD),因为直接计算协方差矩阵可能不稳定(尤其当p>>n时)。多数库(如Scikit-learn)底层采用SVD优化
五、优缺点分析
| 优点 | 缺点/局限性 |
|---|---|
| 无参数,完全基于数据驱动 | 线性方法,无法捕捉非线性结构 |
| 可解释性强(主成分是原特征的线性组合) | 对异常值敏感(方差易被极端值放大) |
| 计算效率高(经典算法复杂度低) | 假设数据服从高斯分布(效果最佳场景) |
| 消除特征间相关性 | 降维后的特征失去物理意义 |
六、典型应用场景
- 图像压缩:将彩色图片的RGB通道矩阵通过PCA降至百维以内,重建后肉眼难辨差异。
- 生物信息学:分析基因表达谱时,用前几个主成分代表不同实验条件下的主要差异模式。
- 金融风控:将海量交易记录降维后,快速识别异常行为模式。
- 可视化:把高维医疗数据集(如癌症患者的上千个基因指标)投射到2D/3D空间,辅助诊断分型。
七、常见误区澄清
- 误区1:“PCA一定能保留所有重要信息” → 错误。若数据的真实结构是非线性的(如螺旋形),PCA会失败,此时应考虑KPCA(核主成分分析)。
- 误区2:“必须标准化才能做PCA” → 取决于问题。如果特征本身量纲一致(如同一单位的传感器数据),可以跳过标准化;但多数情况下建议标准化以避免量纲干扰。
- 误区3:“主成分越多越好” → 相反,目标是用尽可能少的主成分解释足够多的方差(通常通过碎石图Scree Plot观察拐点确定k)。
八、扩展变体
- Kernel PCA (KPCA):通过核技巧将数据映射到高维特征空间,再执行PCA,适用于非线性可分场景。
- 增量式PCA:处理大规模数据时,无需一次性加载全部样本到内存。
- 稀疏PCA:约束主成分仅为稀疏向量,提升可解释性。
- 鲁棒PCA:对抗异常值的影响,使用L1范数替代方差作为优化目标。