【完整源码+数据集+部署教程】小鼠行为识别系统源码和数据集:改进yolo11-RFAConv
背景意义
研究背景与意义
小鼠作为一种重要的实验动物,广泛应用于生物医学研究、药物开发和行为科学等领域。通过对小鼠行为的深入分析,研究人员能够获得关于神经生物学、心理学和药理学等方面的重要信息。传统的行为观察方法往往依赖于人工记录,不仅耗时耗力,而且容易受到观察者主观因素的影响。因此,开发一种高效、准确的小鼠行为识别系统显得尤为重要。
近年来,计算机视觉技术的快速发展为动物行为识别提供了新的解决方案。YOLO(You Only Look Once)系列模型因其实时性和高精度的特点,成为目标检测领域的热门选择。YOLOv11作为该系列的最新版本,进一步提升了模型的性能,能够在复杂环境中实现更为精确的行为识别。通过对小鼠行为的自动化识别,不仅可以提高实验数据的可靠性,还能为行为学研究提供更为丰富的定量分析。
本研究旨在基于改进的YOLOv11模型,构建一个小鼠行为识别系统。该系统将利用一个包含2200张图像的数据集,涵盖了小鼠的十种典型行为,包括前爪舔舐、前爪抬起、梳理、后爪舔舐、后爪抬起、原地、跳跃、直立、伸展和转身等。这些行为的多样性为模型的训练提供了丰富的样本,有助于提高识别的准确性和鲁棒性。
通过本项目的实施,期望能够为小鼠行为研究提供一种高效、自动化的工具,推动相关领域的研究进展。同时,基于YOLOv11的改进模型也将为其他动物行为识别的研究提供借鉴,促进计算机视觉技术在生物医学领域的应用与发展。
图片效果
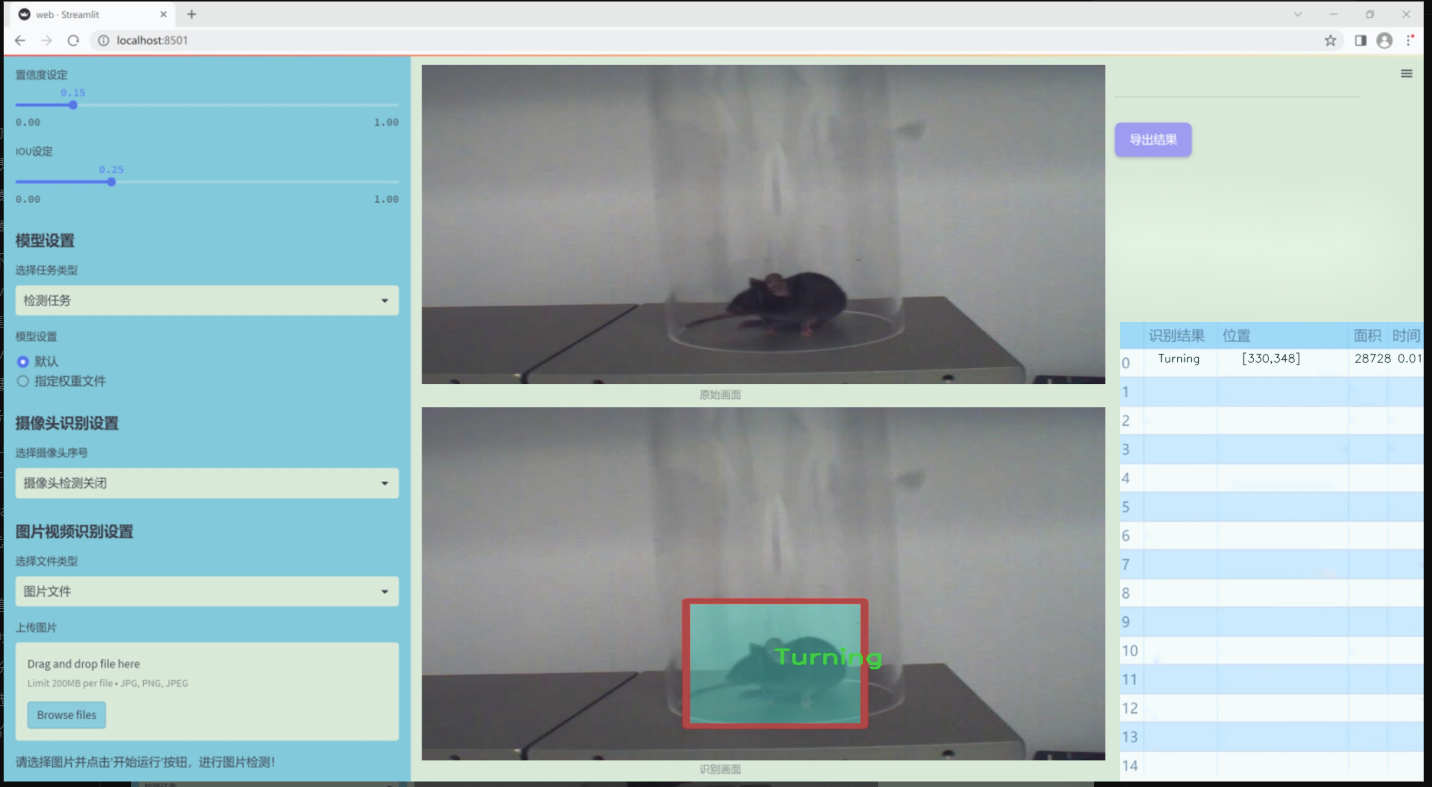
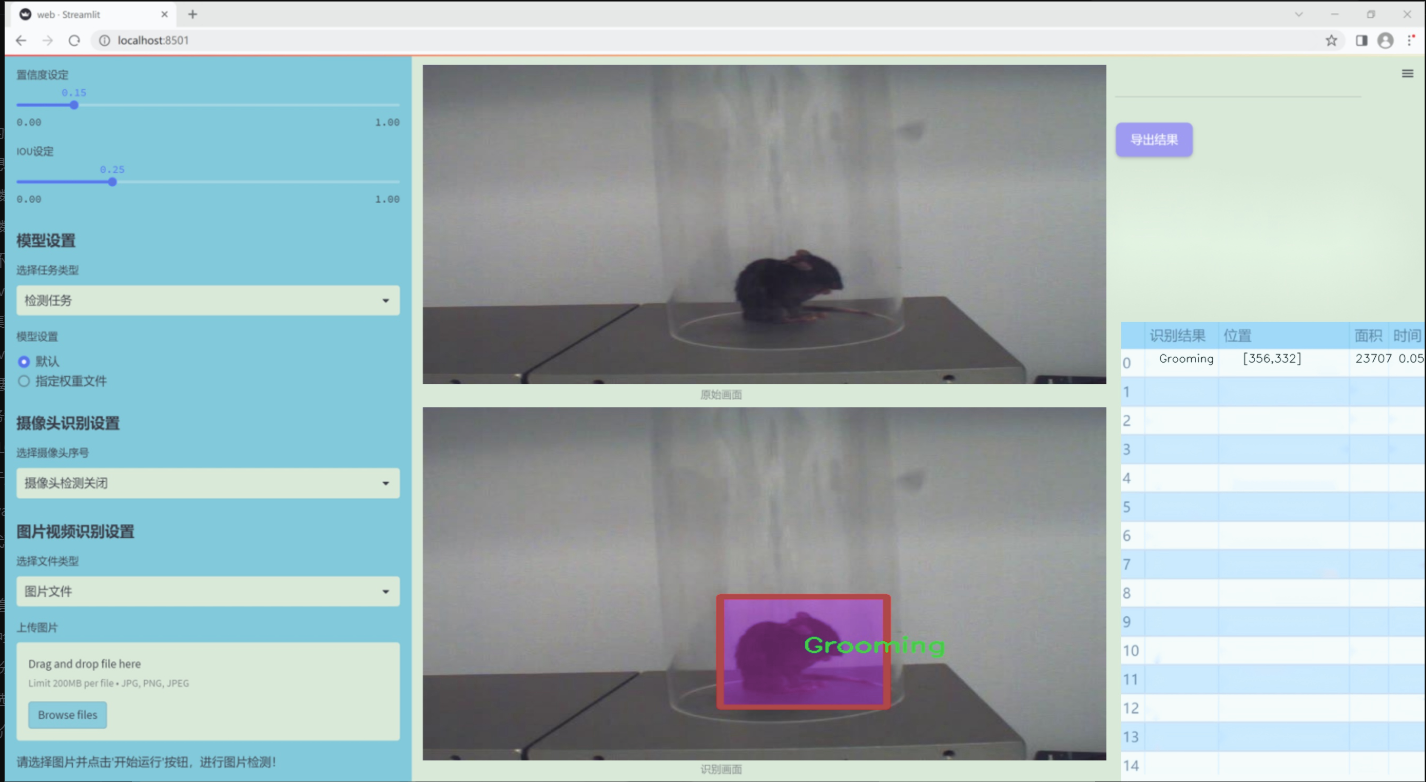
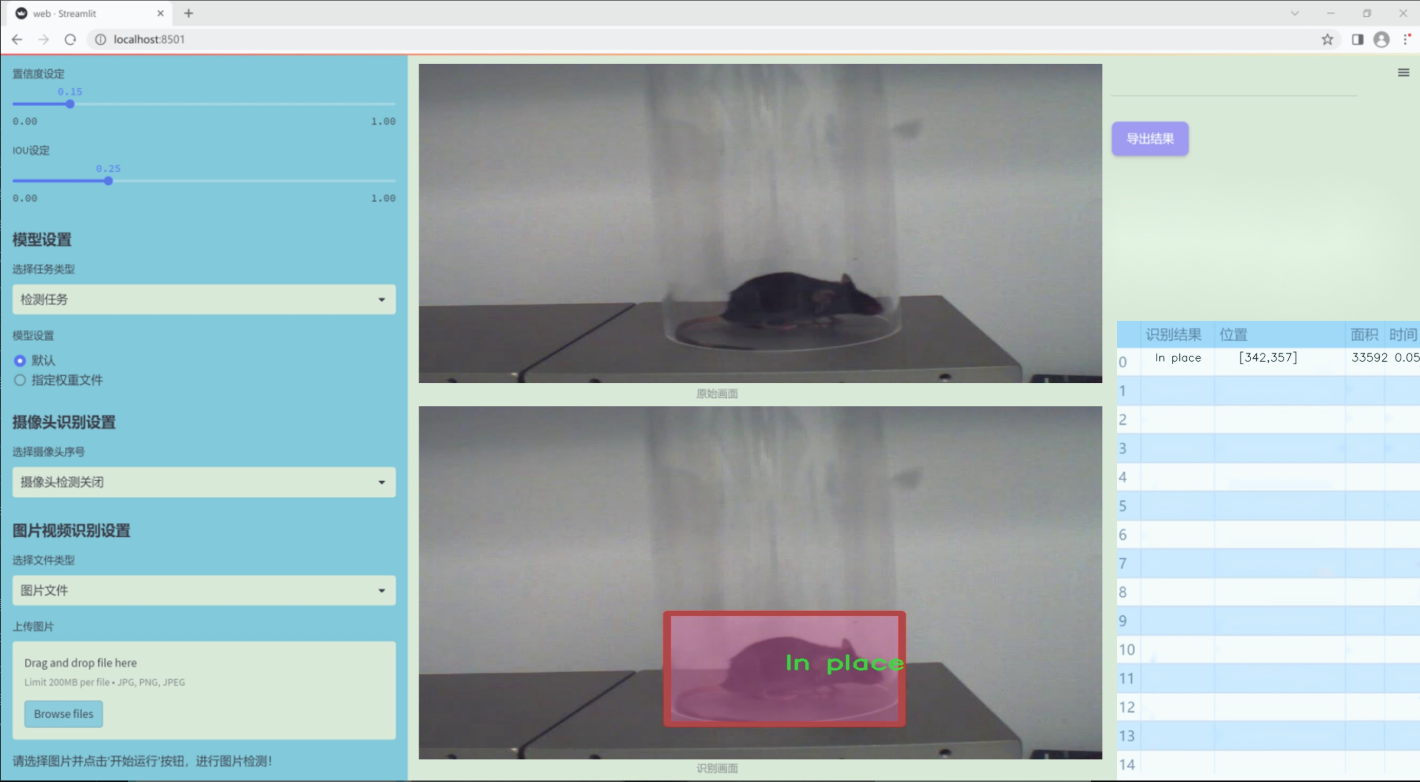
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11模型,提升小鼠行为识别系统的准确性与效率。为实现这一目标,我们采用了“Hotplate_behavior_annotations”数据集,该数据集专注于小鼠在热板实验中的多种行为表现,涵盖了丰富的行为类别,适合用于训练和验证深度学习模型。数据集中包含10个主要的行为类别,具体包括:前爪舔舐、前爪抬起、梳理、后爪舔舐、后爪抬起、原地活动、跳跃、竖立、伸展以及转身。这些行为类别不仅具有显著的生物学意义,还能为研究小鼠的疼痛反应、活动水平及其他生理行为提供重要的参考。
在数据集的构建过程中,所有行为均经过精确标注,确保每个样本的行为特征清晰可辨。这一过程涉及到对小鼠在热板上行为的细致观察与记录,确保数据的真实性和可靠性。通过对这些行为的深入分析,我们能够更好地理解小鼠在不同环境刺激下的反应机制,为相关生物医学研究提供坚实的数据基础。
此外,数据集的多样性和丰富性为模型的训练提供了广泛的样本支持,使得YOLOv11在识别小鼠行为时能够具备更强的泛化能力。通过使用这一数据集,我们希望能够在小鼠行为识别领域取得突破性进展,推动相关研究的深入发展。整体而言,“Hotplate_behavior_annotations”数据集不仅为本项目提供了必要的训练数据,也为未来在小鼠行为学及其相关领域的研究奠定了坚实的基础。





核心代码
以下是经过简化和注释的代码,保留了核心部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
“”" 多层感知机 (MLP) 模块。 “”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_features # 输出特征数hidden_features = hidden_features or in_features # 隐藏层特征数self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换self.act = act_layer() # 激活函数self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换self.drop = nn.Dropout(drop) # Dropout层def forward(self, x):""" 前向传播函数。 """x = self.fc1(x) # 线性变换x = self.act(x) # 激活x = self.drop(x) # Dropoutx = self.fc2(x) # 线性变换x = self.drop(x) # Dropoutreturn x
class WindowAttention(nn.Module):
“”" 窗口注意力机制模块。 “”"
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # 窗口大小self.num_heads = num_heads # 注意力头数head_dim = dim // num_heads # 每个头的维度self.scale = head_dim ** -0.5 # 缩放因子# 定义相对位置偏置参数self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))# 计算相对位置索引coords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成坐标网格coords_flatten = torch.flatten(coords, 1) # 展平坐标relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 重新排列relative_coords[:, :, 0] += self.window_size[0] - 1 # 偏移relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1self.relative_position_index = relative_coords.sum(-1) # 计算相对位置索引self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 线性变换生成Q, K, Vself.attn_drop = nn.Dropout(attn_drop) # 注意力Dropoutself.proj = nn.Linear(dim, dim) # 输出线性变换self.proj_drop = nn.Dropout(proj_drop) # 输出Dropouttrunc_normal_(self.relative_position_bias_table, std=.02) # 初始化相对位置偏置self.softmax = nn.Softmax(dim=-1) # Softmax层def forward(self, x, mask=None):""" 前向传播函数。 """B_, N, C = x.shape # 获取输入形状qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # 分离Q, K, Vq = q * self.scale # 缩放Qattn = (q @ k.transpose(-2, -1)) # 计算注意力分数# 添加相对位置偏置relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()attn = attn + relative_position_bias.unsqueeze(0)attn = self.softmax(attn) # 应用Softmaxattn = self.attn_drop(attn) # 注意力Dropoutx = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 计算输出x = self.proj(x) # 输出线性变换x = self.proj_drop(x) # 输出Dropoutreturn x
class SwinTransformer(nn.Module):
“”" Swin Transformer 主体。 “”"
def __init__(self, patch_size=4, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):super().__init__()self.patch_embed = PatchEmbed(patch_size=patch_size, in_chans=3, embed_dim=embed_dim) # 图像分块self.layers = nn.ModuleList() # 存储每一层# 构建每一层for i_layer in range(len(depths)):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=7,mlp_ratio=4.)self.layers.append(layer)def forward(self, x):""" 前向传播函数。 """x = self.patch_embed(x) # 图像分块outs = []for layer in self.layers:x = layer(x) # 通过每一层outs.append(x) # 收集输出return outs
def SwinTransformer_Tiny(weights=‘’):
“”" 创建一个小型的Swin Transformer模型。 “”"
model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24])
if weights:
model.load_state_dict(torch.load(weights)[‘model’]) # 加载权重
return model
代码注释说明:
Mlp类:实现了一个简单的多层感知机,包括两个线性层和一个激活函数,支持Dropout。
WindowAttention类:实现了窗口注意力机制,计算Q、K、V,并添加相对位置偏置。
SwinTransformer类:构建了Swin Transformer的主要结构,包括图像分块和多个层的堆叠。
SwinTransformer_Tiny函数:创建一个小型的Swin Transformer模型,并可选择加载预训练权重。
此代码是Swin Transformer的核心实现,包含了模型的基本结构和注意力机制。
这个程序文件实现了Swin Transformer模型,主要用于计算机视觉任务。Swin Transformer是一种分层的视觉Transformer,采用了窗口注意力机制,通过在不同层次上处理图像块来提高效率和效果。
首先,文件导入了必要的库,包括PyTorch和一些自定义的模块。接着定义了多个类和函数。
Mlp类实现了一个多层感知机(MLP),包含两个线性层和一个激活函数(默认为GELU),并在每个线性层后面加上了Dropout层,以防止过拟合。
window_partition和window_reverse函数用于将输入特征图分割成窗口,以及将窗口合并回特征图。窗口的大小由参数window_size指定。
WindowAttention类实现了基于窗口的多头自注意力机制(W-MSA),支持相对位置偏置。该类的构造函数定义了输入通道数、窗口大小、注意力头数等参数,并初始化了相对位置偏置表。forward方法计算输入特征的注意力权重,并应用于输入特征。
SwinTransformerBlock类实现了Swin Transformer的基本块,包含归一化层、窗口注意力层和MLP。该类支持循环移位,以实现Shifted Window Attention(SW-MSA)。forward方法处理输入特征,进行归一化、窗口分割、注意力计算和特征合并。
PatchMerging类用于将特征图的块合并,以减少特征图的空间维度。它通过线性层将4个输入通道合并为2个输出通道,并在合并前进行归一化。
BasicLayer类表示Swin Transformer的一个基本层,包含多个Swin Transformer块,并在必要时进行下采样。它还计算SW-MSA的注意力掩码。
PatchEmbed类将输入图像分割成不重叠的块,并通过卷积层进行嵌入。它还支持对嵌入后的特征进行归一化。
SwinTransformer类是整个模型的主类,负责构建模型的各个层次,包括图像块嵌入、绝对位置嵌入、多个基本层和输出层。它的forward方法处理输入图像,生成多个输出特征图。
最后,update_weight函数用于更新模型的权重,从给定的权重字典中加载匹配的权重。SwinTransformer_Tiny函数创建一个Swin Transformer模型实例,并可选择加载预训练权重。
整体来看,这个文件实现了Swin Transformer的核心组件和结构,适用于图像分类、目标检测等视觉任务。
10.4 RFAConv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
class RFAConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size, stride=1):
super().init()
self.kernel_size = kernel_size
# 生成权重的卷积模块self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel, bias=False))# 生成特征的卷积模块self.generate_feature = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 最终的卷积层self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 获取输入的批次大小和通道数weight = self.get_weight(x) # 计算权重h, w = weight.shape[2:] # 获取特征图的高和宽# 对权重进行softmax归一化weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2, h, w# 生成特征并调整形状feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) # b c*kernel**2, h, w# 加权特征weighted_data = feature * weighted# 重排特征数据以适应卷积层的输入conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)return self.conv(conv_data) # 返回卷积结果
class SE(nn.Module):
def init(self, in_channel, ratio=16):
super(SE, self).init()
self.gap = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):b, c = x.shape[0:2] # 获取输入的批次大小和通道数y = self.gap(x).view(b, c) # 进行全局平均池化并调整形状y = self.fc(y).view(b, c, 1, 1) # 通过全连接层return y # 返回通道注意力
class RFCBAMConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size=3, stride=1):
super().init()
self.kernel_size = kernel_size
# 生成特征的卷积模块self.generate = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 计算权重的卷积模块self.get_weight = nn.Sequential(nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False), nn.Sigmoid())self.se = SE(in_channel) # 通道注意力模块# 最终的卷积层self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 获取输入的批次大小和通道数channel_attention = self.se(x) # 计算通道注意力generate_feature = self.generate(x) # 生成特征h, w = generate_feature.shape[2:] # 获取特征图的高和宽generate_feature = generate_feature.view(b, c, self.kernel_size ** 2, h, w) # 调整形状# 重排特征数据generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)# 加权特征unfold_feature = generate_feature * channel_attention# 计算最大值和均值特征max_feature, _ = torch.max(generate_feature, dim=1, keepdim=True)mean_feature = torch.mean(generate_feature, dim=1, keepdim=True)# 计算接收场注意力receptive_field_attention = self.get_weight(torch.cat((max_feature, mean_feature), dim=1))# 返回卷积结果return self.conv(unfold_feature * receptive_field_attention) # 返回卷积结果
代码核心部分说明:
RFAConv:该类实现了一种卷积操作,结合了权重生成和特征生成。它通过对输入特征进行加权,生成新的特征图,并通过卷积层输出最终结果。
SE(Squeeze-and-Excitation):该类实现了通道注意力机制,通过全局平均池化和全连接层来计算每个通道的重要性,并生成相应的权重。
RFCBAMConv:该类结合了特征生成、通道注意力和接收场注意力的机制,进一步增强了卷积操作的效果。它通过最大池化和均值池化来计算接收场注意力,并与生成的特征相结合,最终通过卷积层输出结果。
这个程序文件定义了几个用于卷积神经网络的模块,主要包括RFAConv、RFCBAMConv和RFCAConv。文件中使用了PyTorch库,并且结合了一些自定义的激活函数和卷积操作。
首先,文件引入了必要的库,包括torch和torch.nn,以及用于重排张量的einops库。接着,定义了两个自定义的激活函数:h_sigmoid和h_swish。h_sigmoid是一个改进的sigmoid函数,使用ReLU6来限制输出范围;h_swish则是将输入与h_sigmoid的输出相乘,形成一个新的激活函数。
RFAConv类是一个卷积模块,初始化时接收输入通道数、输出通道数、卷积核大小和步幅。它包含两个主要部分:一个用于生成权重的卷积层和一个用于生成特征的卷积层。权重通过对输入进行平均池化和卷积得到,特征则通过卷积、批归一化和ReLU激活得到。在前向传播中,首先计算权重,然后对特征进行处理,最后通过重排和卷积得到输出。
RFCBAMConv类在RFAConv的基础上增加了通道注意力机制。它通过SE(Squeeze-and-Excitation)模块来生成通道注意力,并结合最大池化和平均池化来获取特征的全局信息。生成的特征经过重排后与通道注意力相乘,最后通过卷积得到输出。
RFCAConv类则进一步扩展了功能,结合了空间注意力机制。它在生成特征后,分别对特征在高度和宽度方向进行自适应平均池化,生成两个特征图。然后将这两个特征图拼接,经过一系列卷积和激活操作后,得到空间注意力。最终,生成的特征与空间注意力相乘,并通过卷积得到最终输出。
整个文件实现了基于注意力机制的卷积操作,旨在提升特征提取的能力,使得网络在处理图像时能够更加关注重要的区域和通道。这些模块可以被集成到更大的神经网络中,以提高性能。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻