大模型微调分布式训练-大模型压缩训练(知识蒸馏)-大模型推理部署(分布式推理与量化部署)-大模型评估测试(OpenCompass)
大模型微调分布式训练
LLama Factory与Xtuner分布式微调大模型
大模型分布式微调训练的基本概念
为什么需要分布式训练?
模型规模爆炸:现代大模型(如GPT-3、LLaMA等)参数量达千亿级别,单卡GPU无法存储完整模型。
计算资源需求:训练大模型需要海量计算(如GPT-3需数万GPU小
时),分布式训练可加速训练过程。
内存瓶颈:单卡显存不足以容纳大模型参数、梯度及优化器状态。
分布式训练的核心技术
注意:分页式并行训练,所有的显卡都是同系列的显卡
数据并行(Data Parallelism)
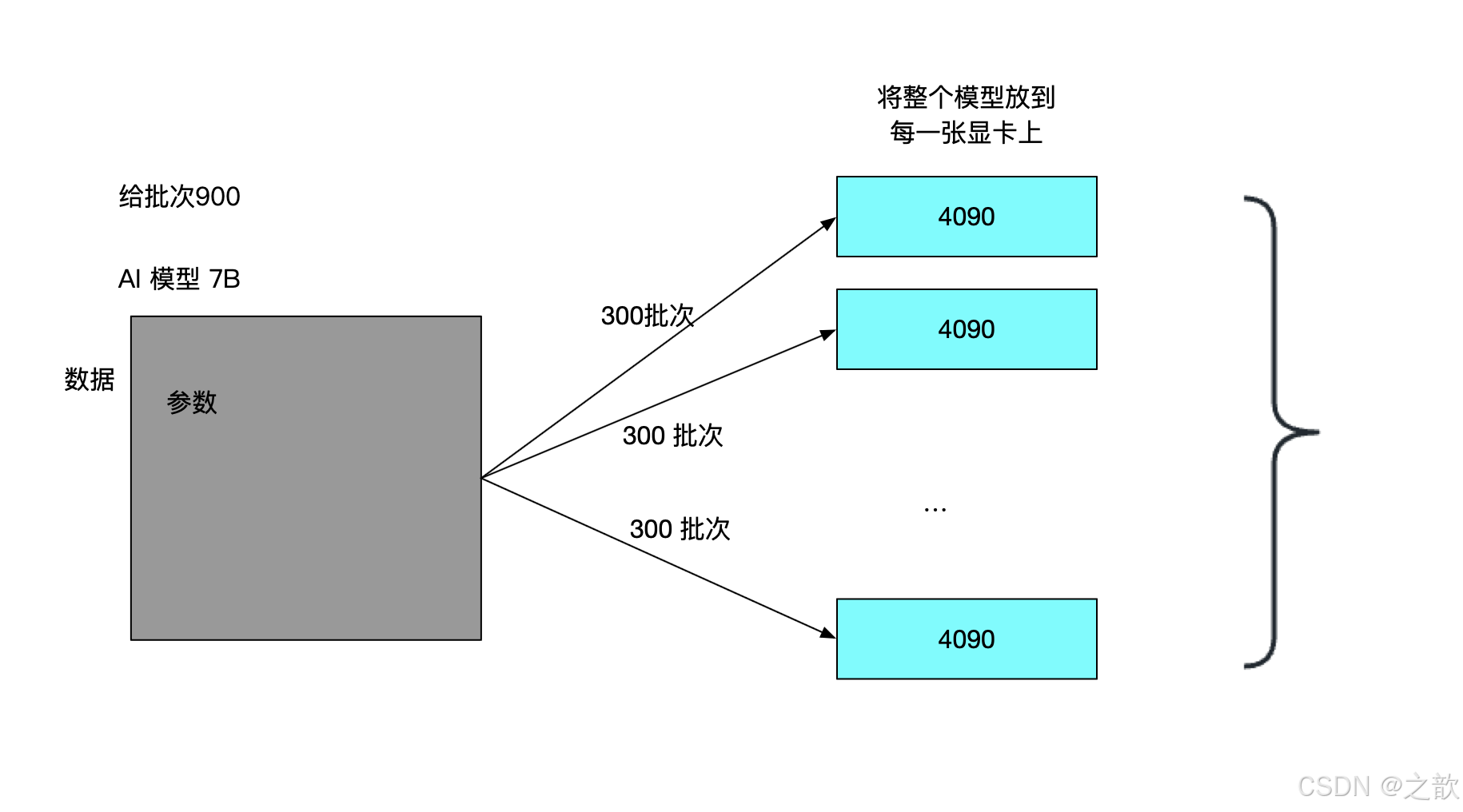
原理:将数据划分为多个批次,分发到不同设备,每个设备拥有完整的模型副本。
同步方式:通过All-Reduce操作同步梯度(如PyTorch的DistributedDataParallel)。
最后再将所有的模型合并
挑战:通信开销大,显存占用高(需存储完整模型参数和优化器状态)。
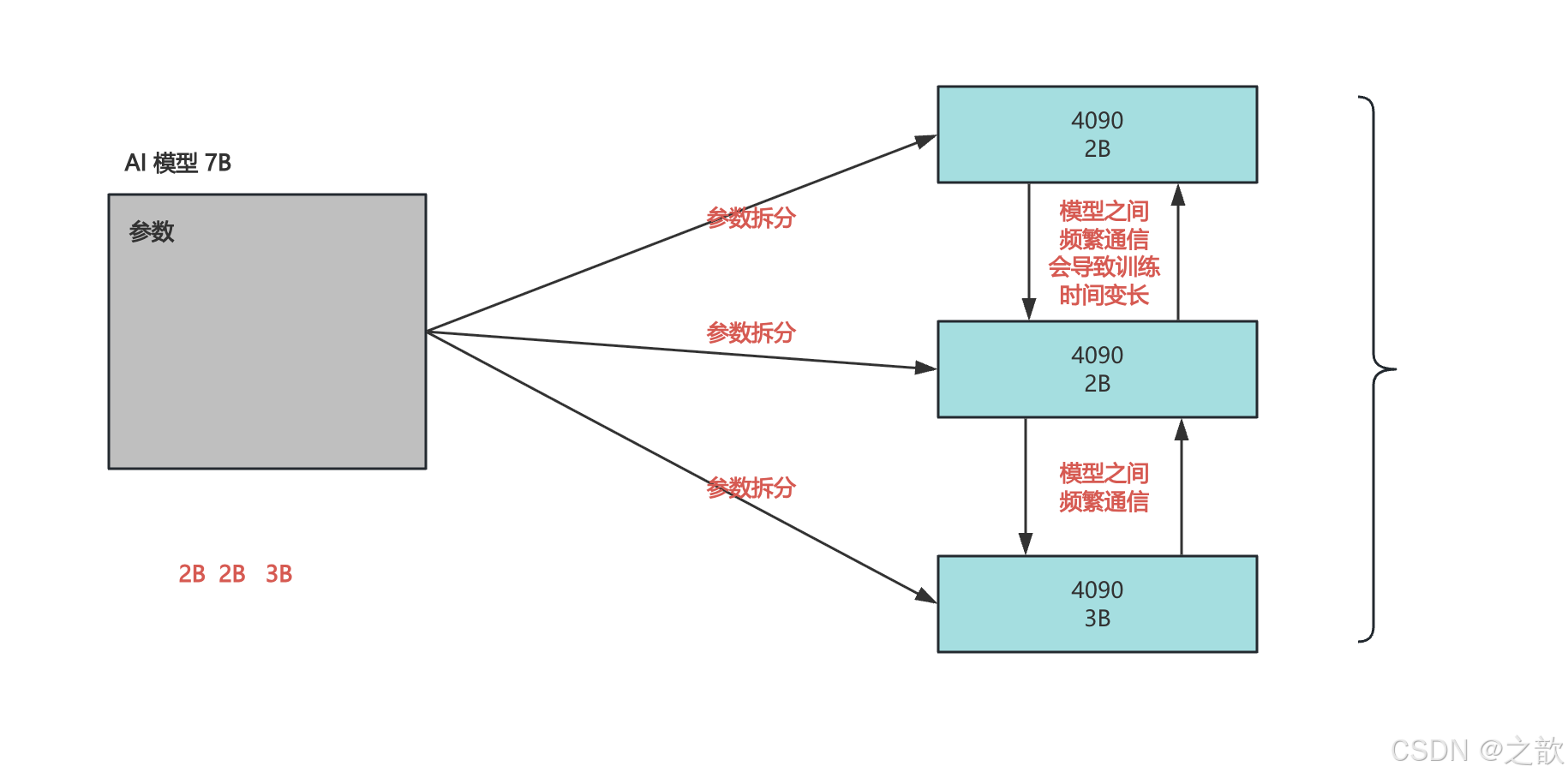
模型并行(Model Parallelism)
原理:将模型切分到不同设备(如按层或张量分片)。
类型:
- 横向并行(层拆分):将模型的层分配到不同设备。
- 纵向并行(张量拆分):如Megatron-LM将矩阵乘法分片。
- 挑战:设备间通信频繁,负载均衡需精细设计。
流水线并行(Pipeline Parallelism)
原理:将模型按层划分为多个阶段(stage),数据分块后按流水线执行。
优化:微批次(Micro-batching)减少流水线气泡(Bubble)。
挑战:需平衡阶段划分,避免资源闲置。
混合并行(3D并行)
组合策略:结合数据并行、模型并行、流水线并行,典型应用如训练千亿级模型。
案例:微软Turing-NLG、Meta的LLaMA-2。
deepspeed框架介绍
DeepSpeed概述
定位:微软开源的分布式训练优化框架,支持千亿参数模型训练。核心目标:降低大模型训练成本,提升显存和计算效率。
集成生态:与PyTorch无缝兼容,支持Hugging Face Transformers库。
DeepSpeed框架介绍
核心技术
ZeRO(Zero Redundancy Optimizer)
原理:通过分片优化器状态、梯度、参数,消除数据并行中的显存冗余。
阶段划分:
- ZeRO-1:优化器状态分片。
- ZeRO-2:梯度分片 + 优化器状态分片。
- ZeRO-3:参数分片 + 梯度分片 + 优化器状态分片。
优势:显存占用随设备数线性下降,支持训练更大模型。
显存优化技术
梯度检查点(Activation Checkpointing):用时间换空间,减少激活值显存占用。
CPU Offloading:将优化器状态和梯度卸载到CPU内存。
混合精度训练:FP16/BP16与动态损失缩放(Loss Scaling)。
其他特性
大规模推理支持:模型并行推理(如ZeRO-Inference)。
自适应通信优化:自动选择最佳通信策略(如All-Reduce vs. All-Gather)。
优势与特点
显存效率高:ZeRO-3可将显存占用降低至1/设备数。
易用性强:通过少量代码修改即可应用(如DeepSpeed配置JSON文件)。
扩展性优秀:支持千卡级集群训练。
开源社区支持:持续更新,与Hugging Face等生态深度集成。
使用场景
训练百亿/千亿参数模型(如GPT-3、Turing-NLG)。
资源受限环境:单机多卡训练时通过Offloading扩展模型规模。
快速实验:通过ZeRO-2加速中等规模模型训练。
XTuner微调大模型
xtuner微调大模型教程
构建虚拟环境
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
拉取 XTuner,过程大约需要几分钟
git clone https://github.com/InternLM/xtuner.git
然后安装依赖的软件,这步需要的时间比较长。
cd xtuner
pip install -e ‘.[all]’
等以上所有步骤完成后,再进行下面的操作。
下载模型
from modelscope import snapshot_download
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2-chat-1_8b',cache_dir='/root/llm/internlm2-1.8b-chat')
微调
创建微调训练相关的配置文件在左侧的文件列表,xtuner 的文件夹里,打开
xtuner/xtuner/configs/internlm/internlm2_chat_1_8b/internlm2_chat_1_8b_qlora_alpaca_e3.py,复制一份至根目录。打开这个文件,然后修改预训练模型地址,数据文件地址等。
### PART 1中
#预训练模型存放的位置
pretrained_model_name_or_path =
#微调数据存放的位置
'/root/llm/internlm2-1.8b-chat
data_files =
'/root/public/data/target_data.json'#基座模型路径
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小
batch_size = 2
#最大训练轮数
max_epochs = 3
#验证数据
evaluation_inputs = [
'只剩一个心脏了还能活吗?'
,'爸爸再婚,我是不是就有了个新娘?'
,'樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买'
,'马上要上游泳课了,昨天洗的泳裤还没干,怎么办'
,'我只出生了一次,为什么每年都要庆生'
]
# PART 3中
dataset=dict(type=load_dataset, path="json",dataset_map_fn=None)
微调训练
在当前目录下,输入以下命令启动微调脚本
xtuner train internlm2_chat_1_8b_qlora_alpaca_e3.py
杂记
每次安装环境之后,将requirements.txt保存起来,如果环境安装不了,可以指定相应的版本安装 。 因为框架的新版本可能会存在bug 。 目前每个框架更新还是很频繁的。
激活环境:
conda activate /root/autodl-tmp/lamafactory
导出:
pip list --format=freeze> requirements.txt
如果环境安装失败:可以使用下面方法安装 python环境 。
pip install -r requirements.txt
LLamaFactory与Xtuner多卡微调大模型
LLamaFactory 训练单机多卡
https://autodl.com/console/instance/list?tag_id= 申请单机多卡
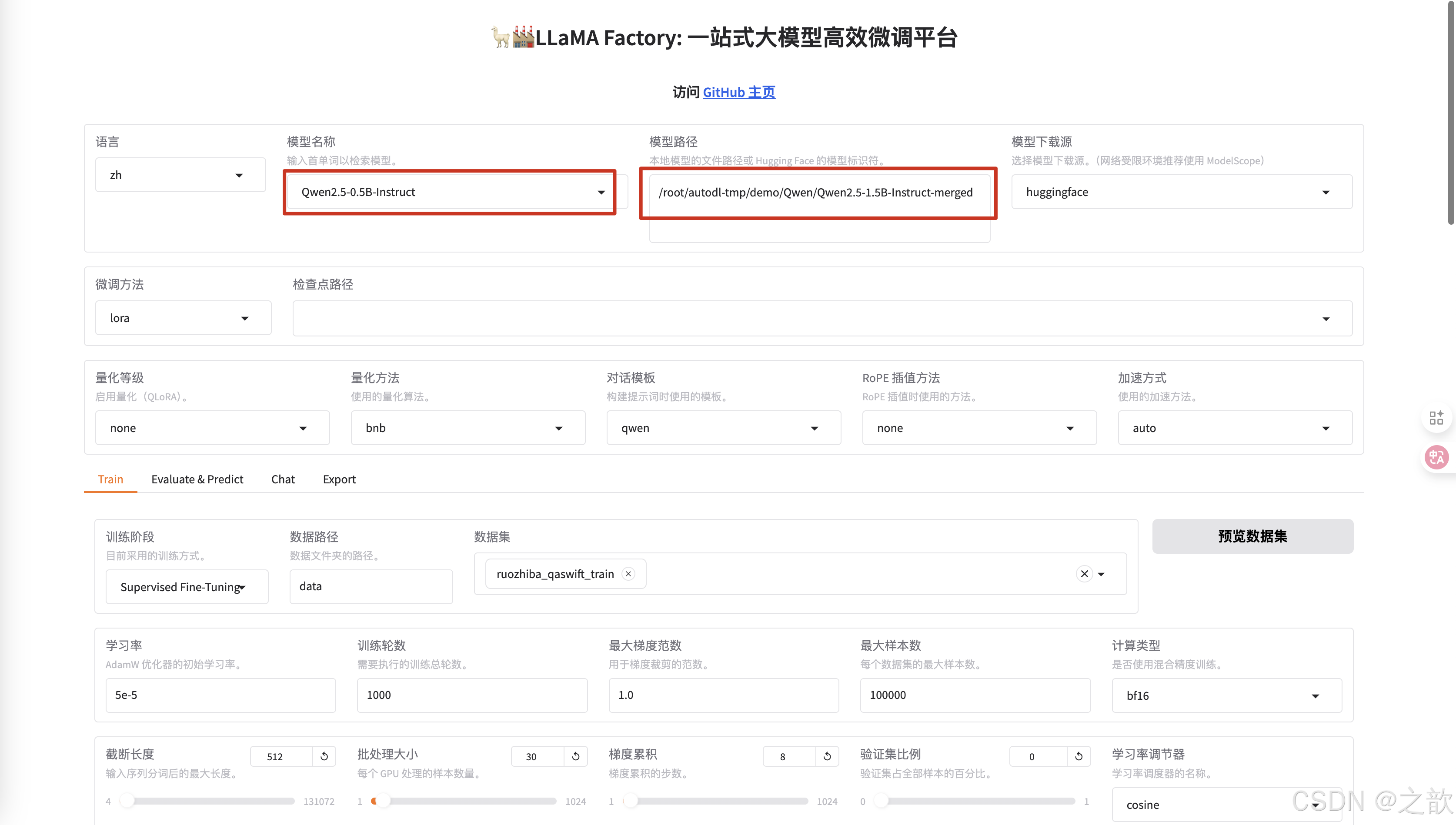
启动llamafactory
llamafactory-cli webui
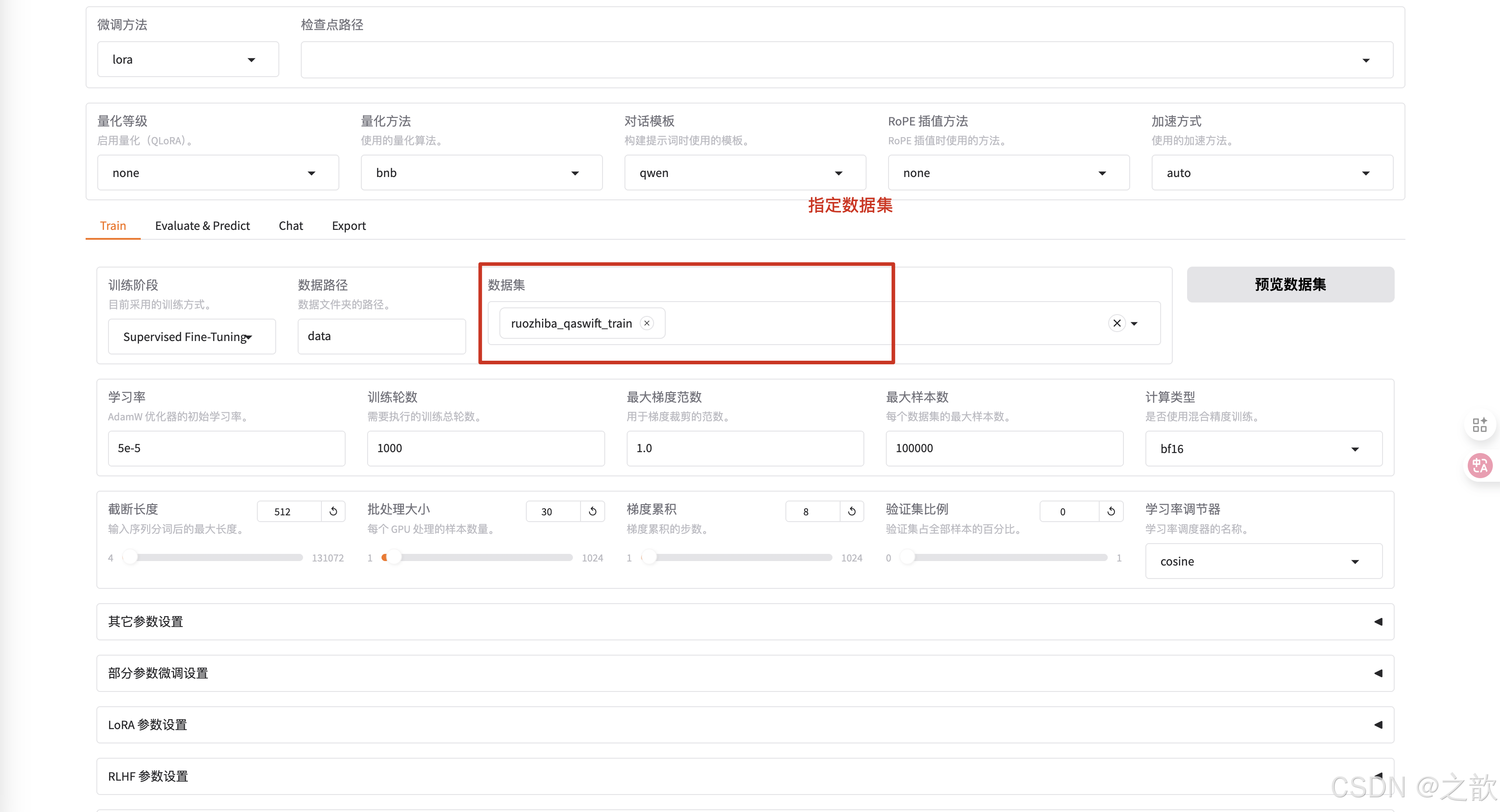
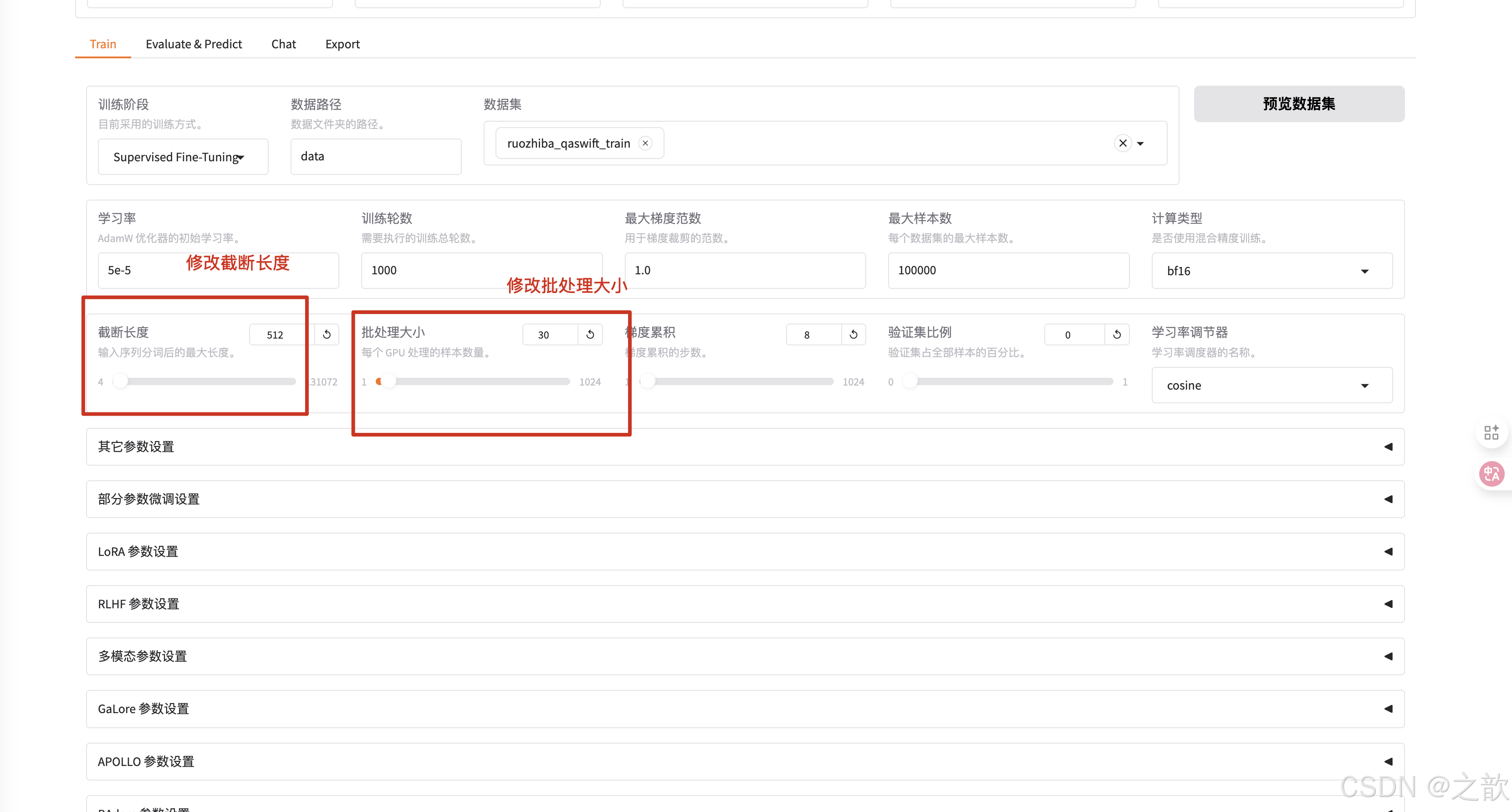
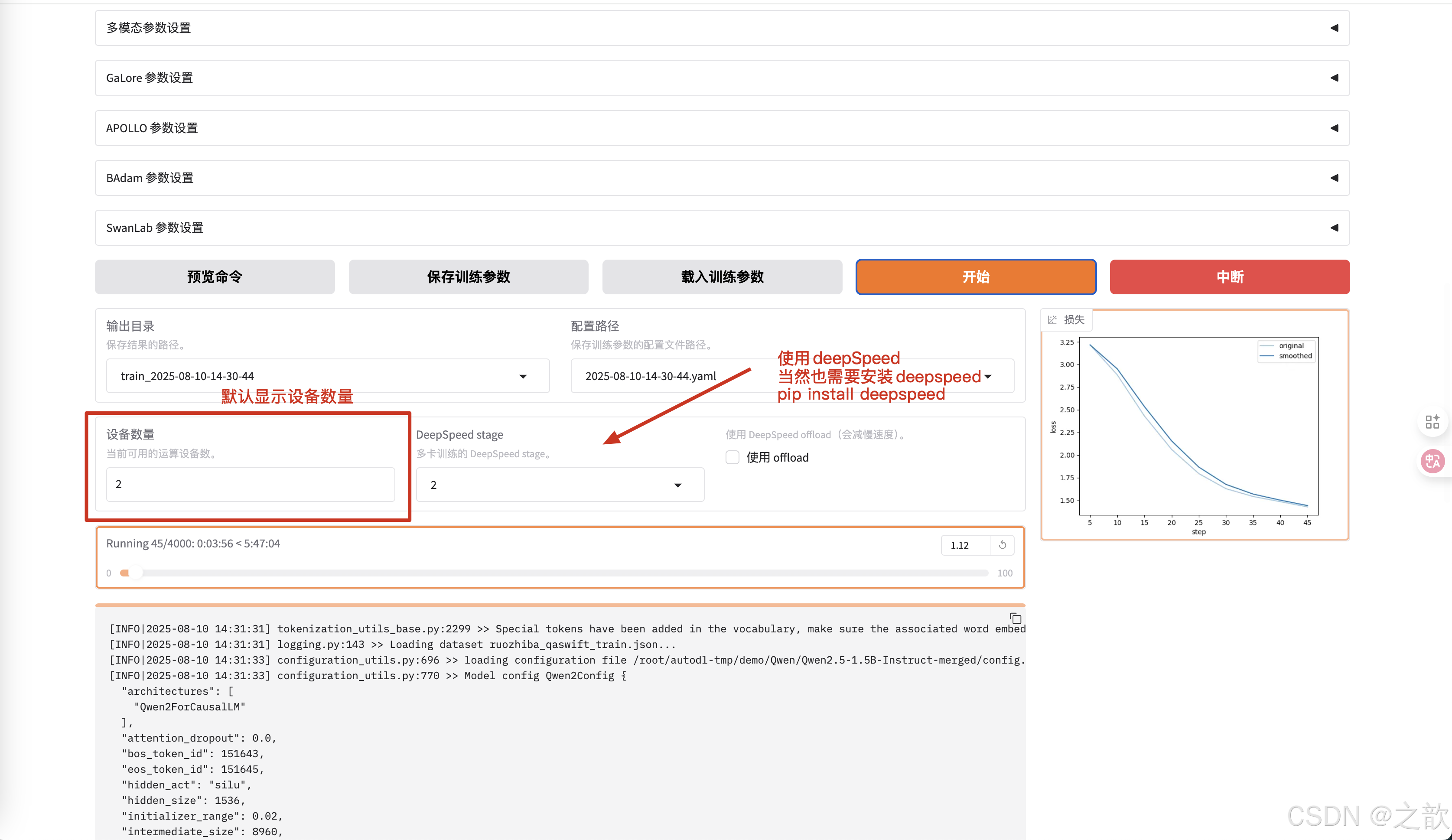
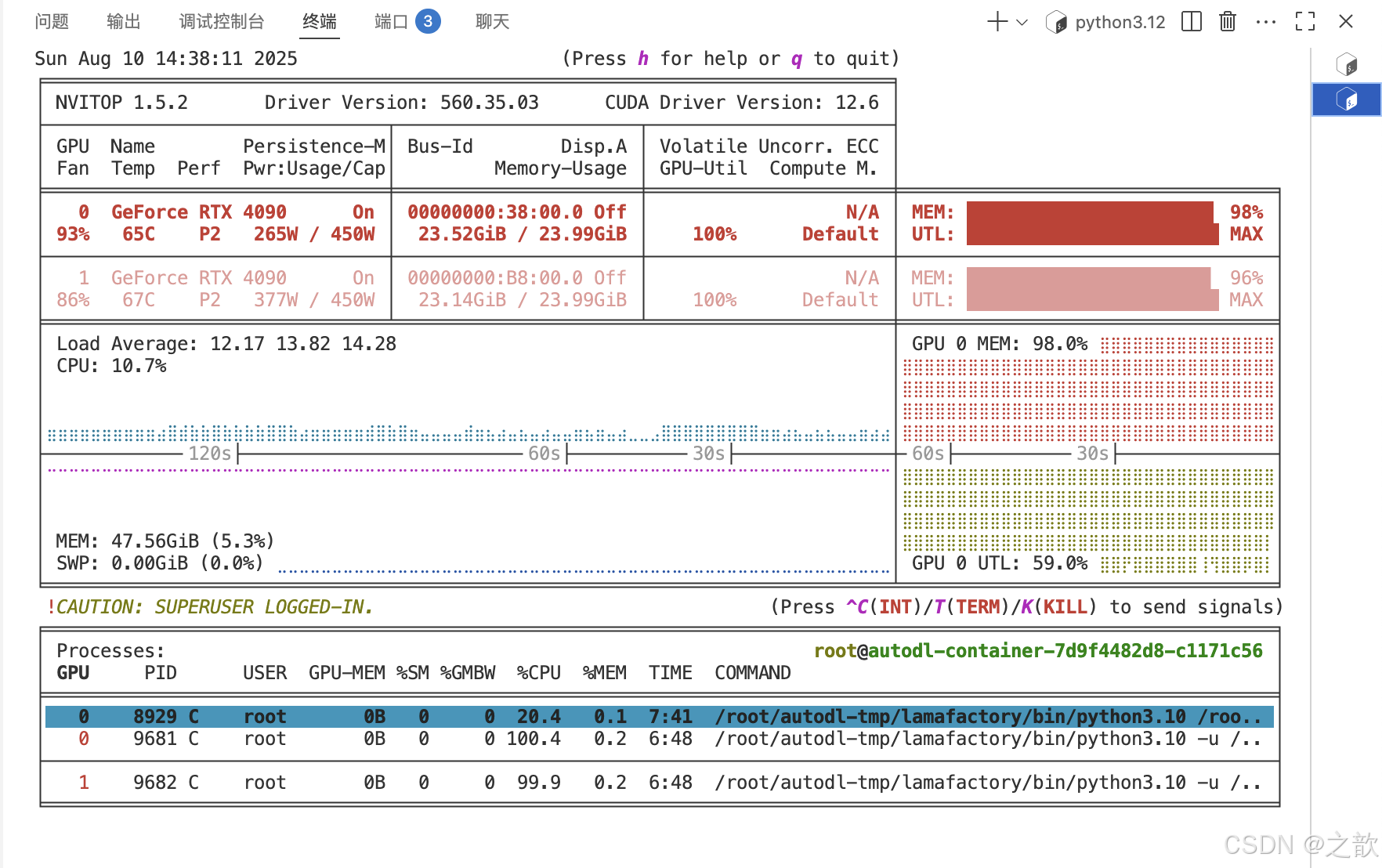
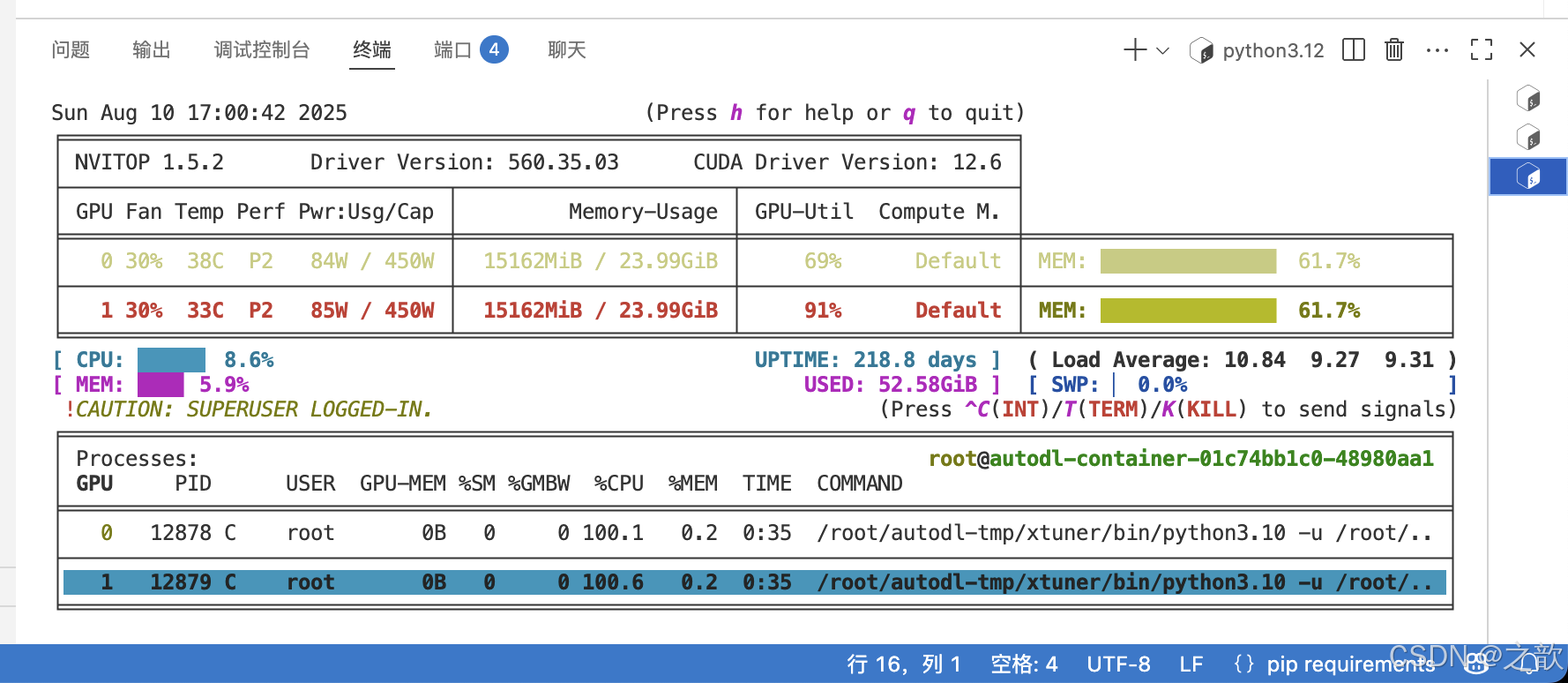
可以看到损失越来越接受收敛,速度比单机单卡要快得多。
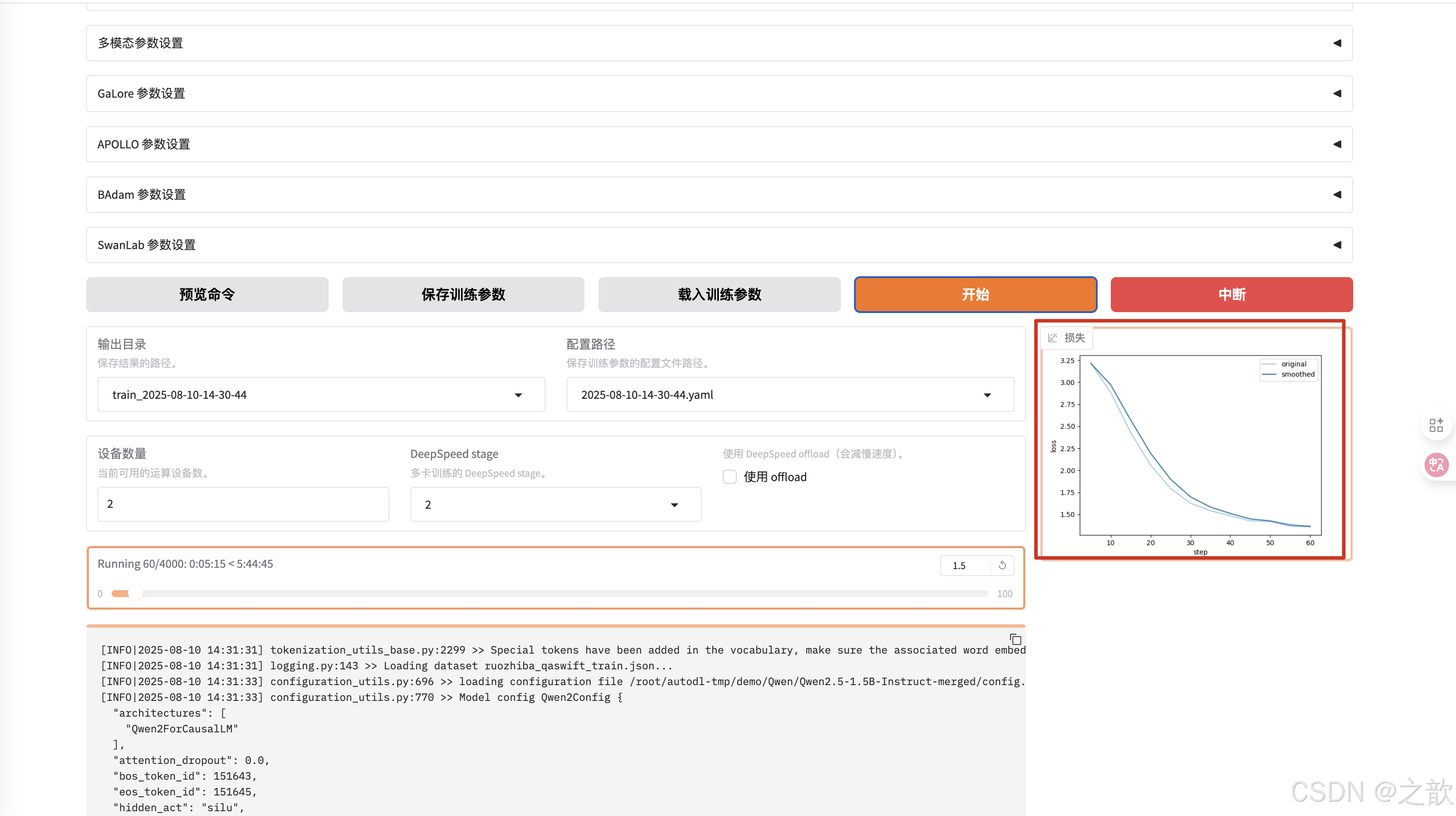
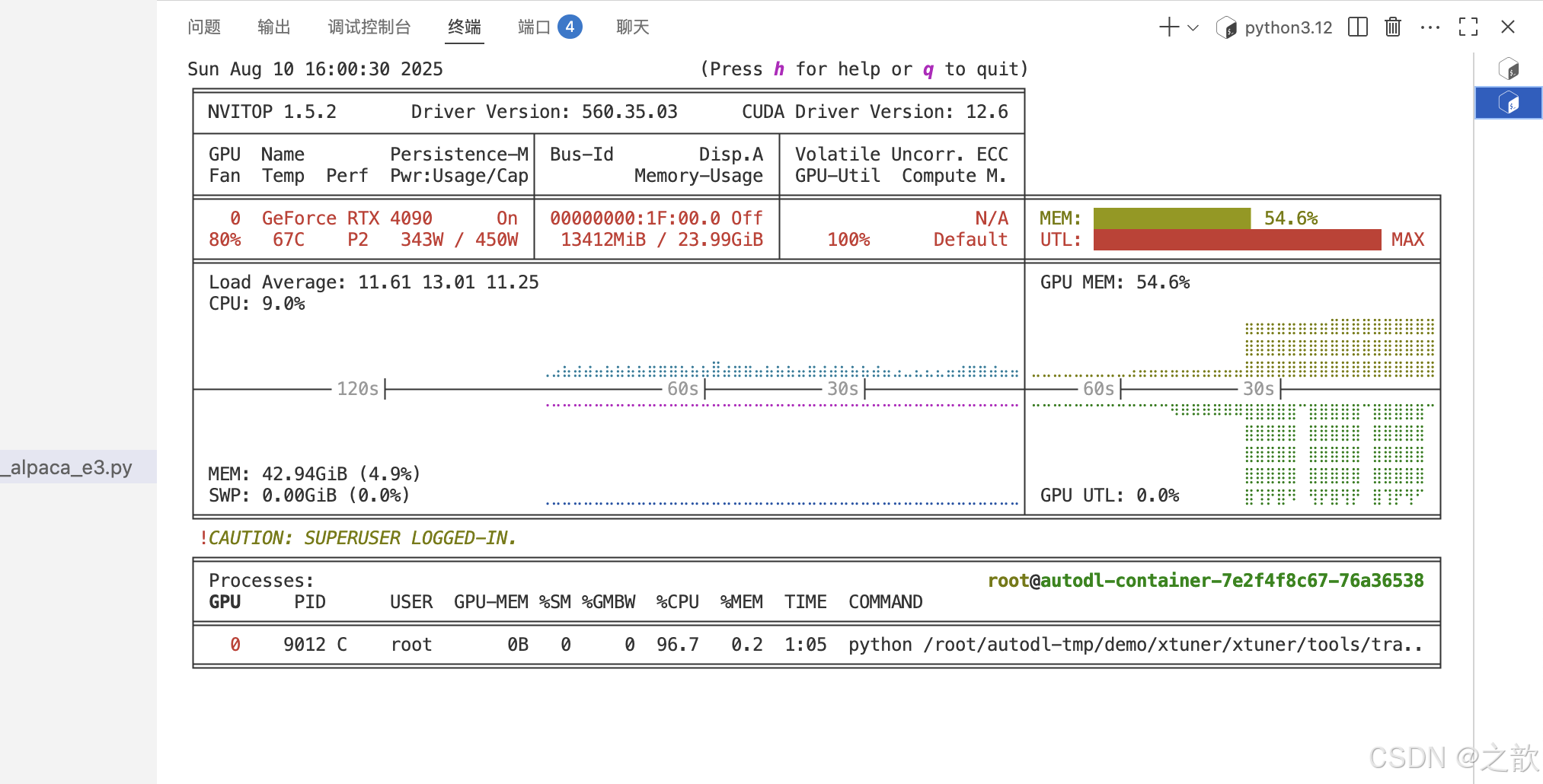
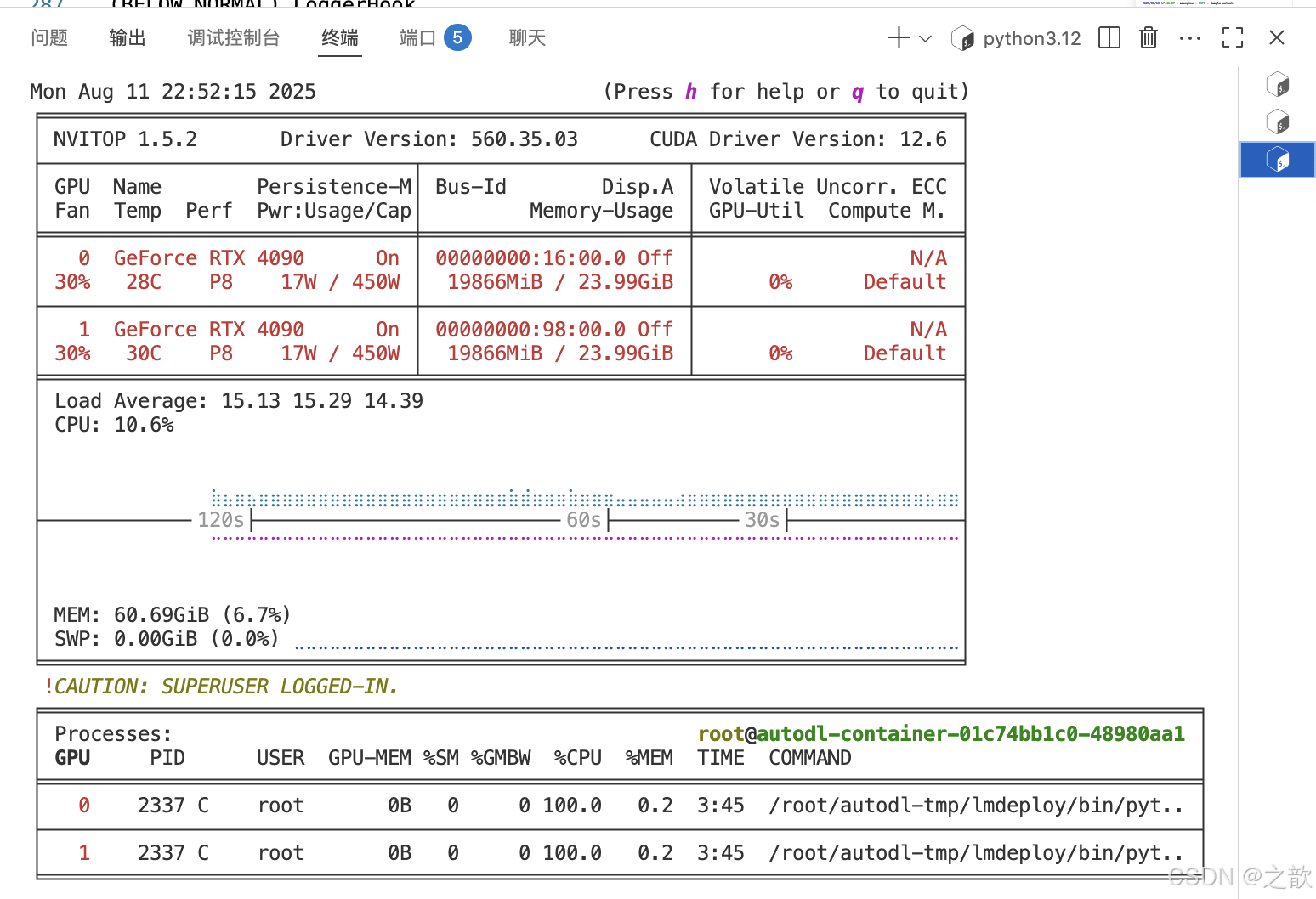
用nvitop 来看显卡使用情况 。
Xtuner 环境搭建
官方文档 https://xtuner.readthedocs.io/zh-cn/latest/get_started/installation.html
步骤 0. 使用 conda 先构建一个 Python-3.10 的虚拟环境
conda create --prefix=/root/autodl-tmp/xtuner python=3.10 -y
conda activate /root/autodl-tmp/xtuner xtuner
方案b: 从源码安装
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e ‘.[deepspeed]’
拷贝配置文件到根目录下
复制一个文件到 /root/autodl-tmp/demo/xtuner 目录下
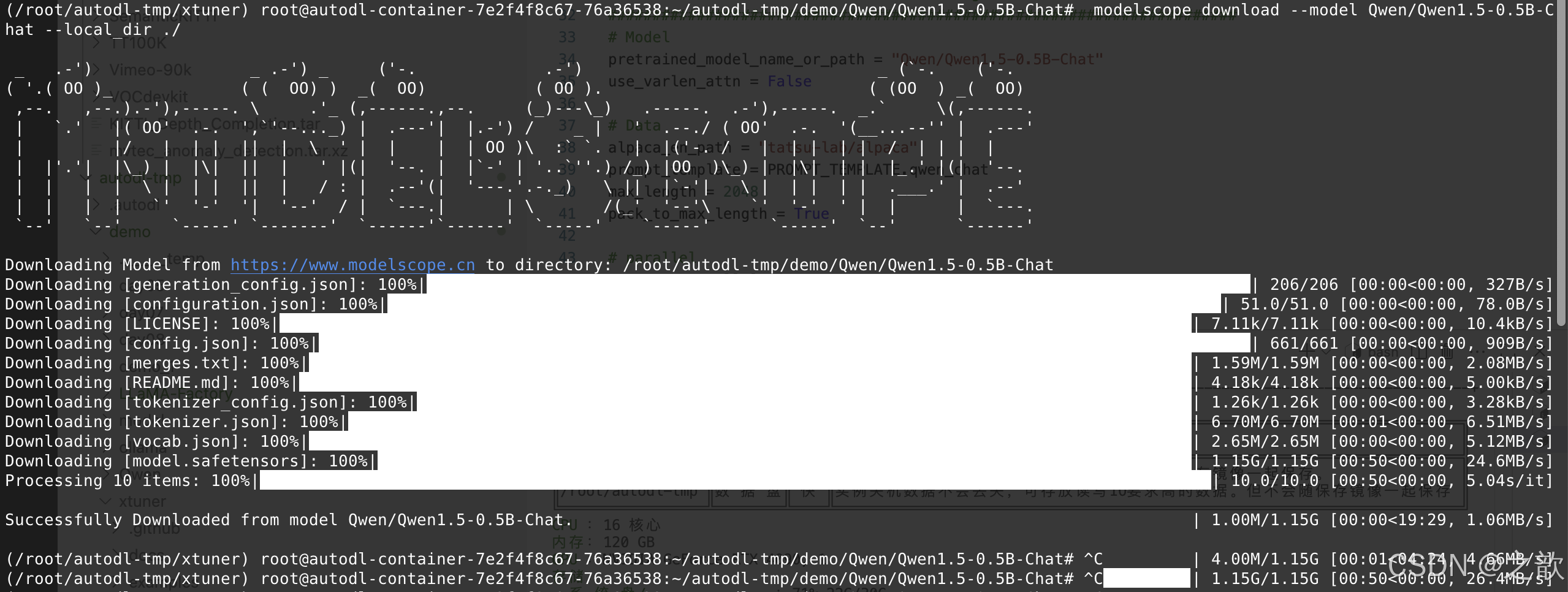
下载Qwen1.5-0.5B-Chat 模型
下载https://www.modelscope.cn/models/Qwen/Qwen1.5-0.5B-Chat 模型
mkdir -p ~/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
cd ~/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir ./
准备Xtuner所需要的数据集target_data.json
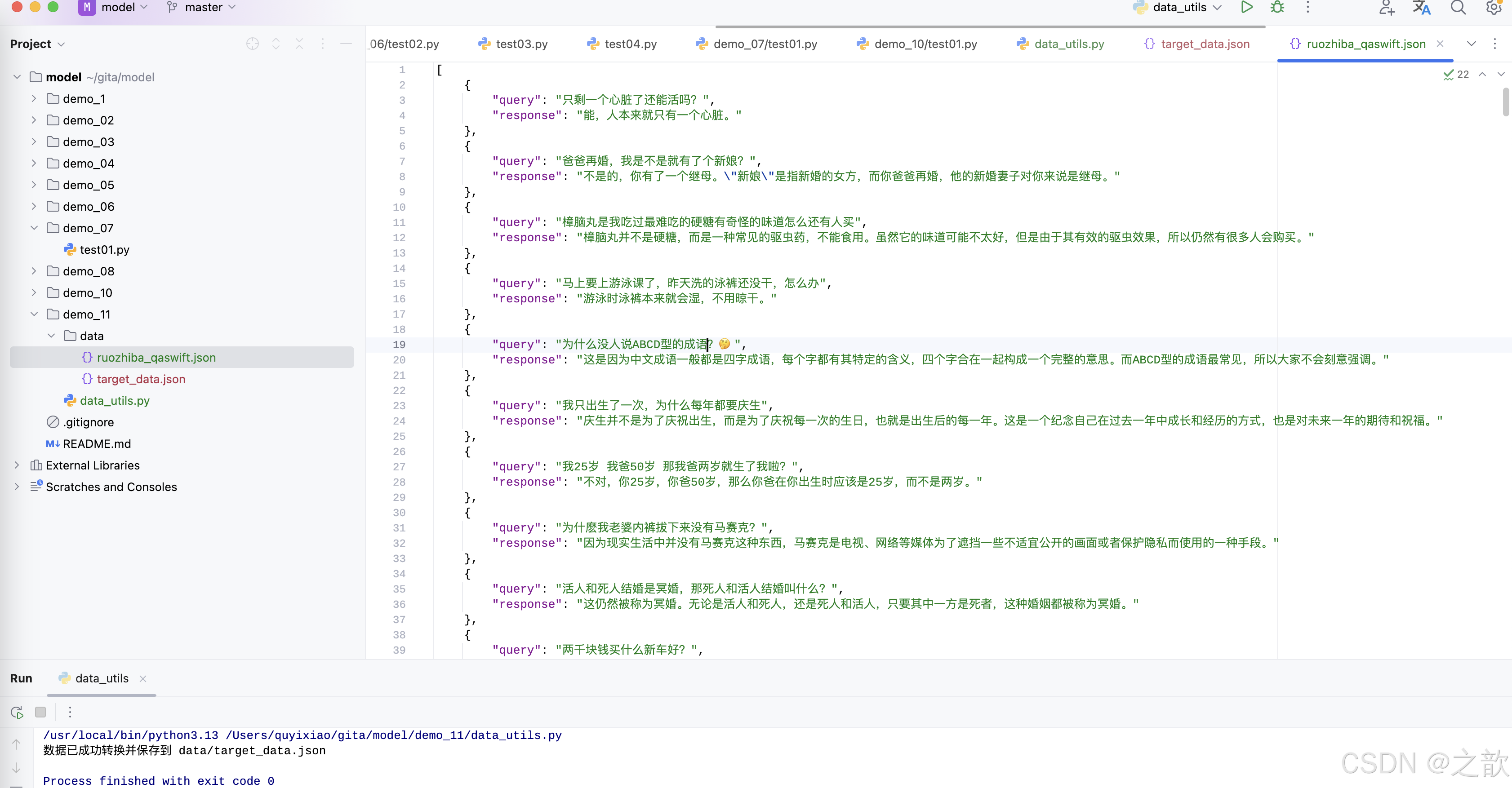
import json# 源数据文件路径
source_file = 'data/ruozhiba_qaswift.json'
# 目标数据文件路径
target_file = 'data/target_data.json'# 读取源数据
with open(source_file, 'r', encoding='utf-8') as f:source_data = json.load(f)# 转换数据
target_data = []
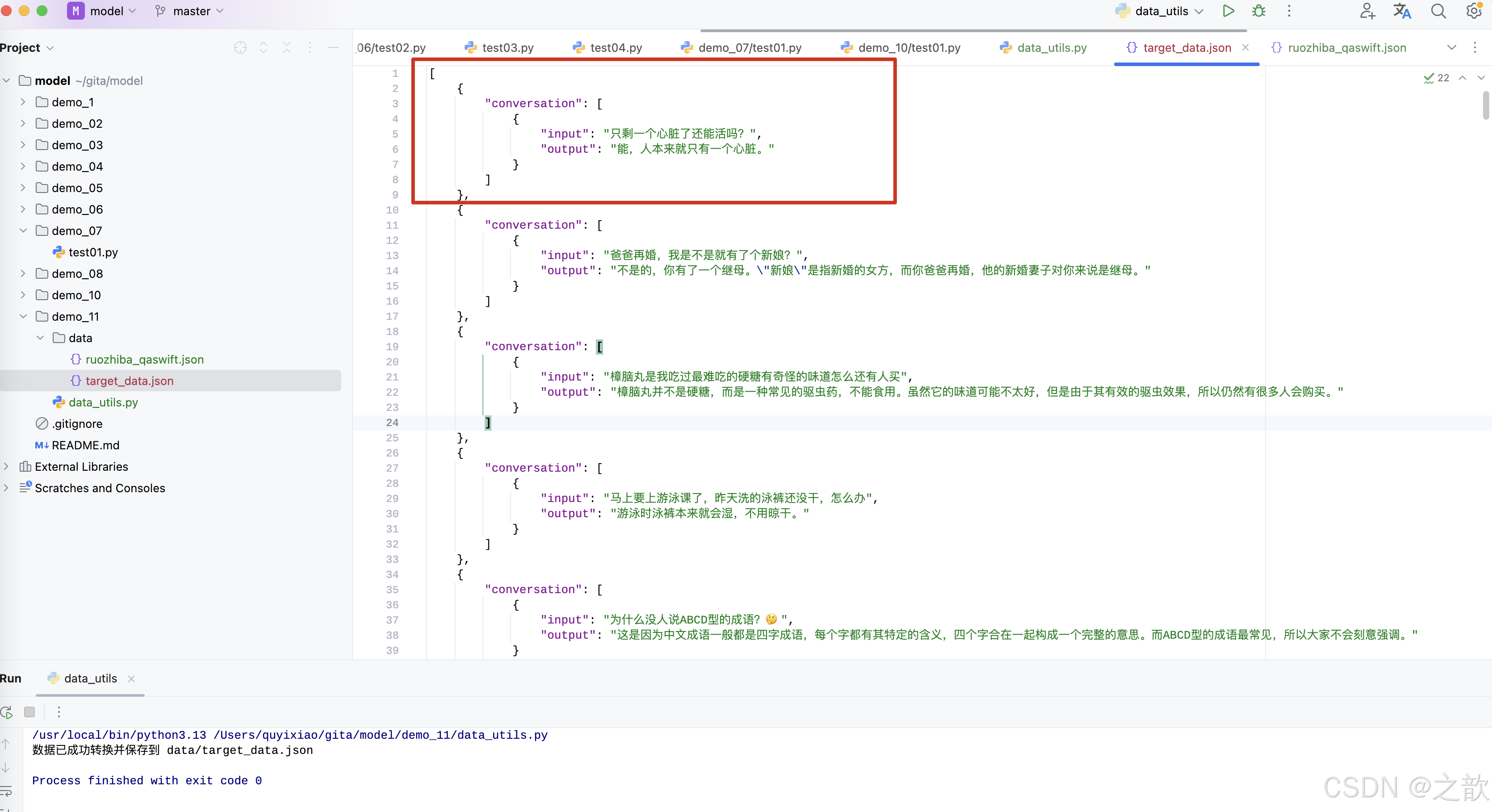
for item in source_data:conversation = {"conversation": [{"input": item["query"],"output": item["response"]}]}target_data.append(conversation)# 保存转换后的数据
with open(target_file, 'w', encoding='utf-8') as f:json.dump(target_data, f, ensure_ascii=False, indent=4)print(f"数据已成功转换并保存到 {target_file}")ruozhiba_qaswift.json 的源格式
target_data.json 生成数据格式
修改之后的 /root/autodl-tmp/demo/xtuner/qwen1_5_0_5b_chat_qlora_alpaca_e3.py文件如下
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook,DistSamplerSeedHook,IterTimerHook,LoggerHook,ParamSchedulerHook,
)from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfigfrom xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook,EvaluateChatHook,VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model 模型文件
pretrained_model_name_or_path = "/root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat"
use_varlen_attn = False# Data 数据集
data_files = "/root/autodl-tmp/demo/demo_11/target_data.json"
prompt_template = PROMPT_TEMPLATE.qwen_chat
max_length = 512 # 数据截断长度
pack_to_max_length = True# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 30 # per_device 批次
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 1000 # 轮次
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03# Save
save_steps = 500
# 保存最近的几次权重 ,如果需要保存每一次的结果,设置一个-1 即可。
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca# 主观验证
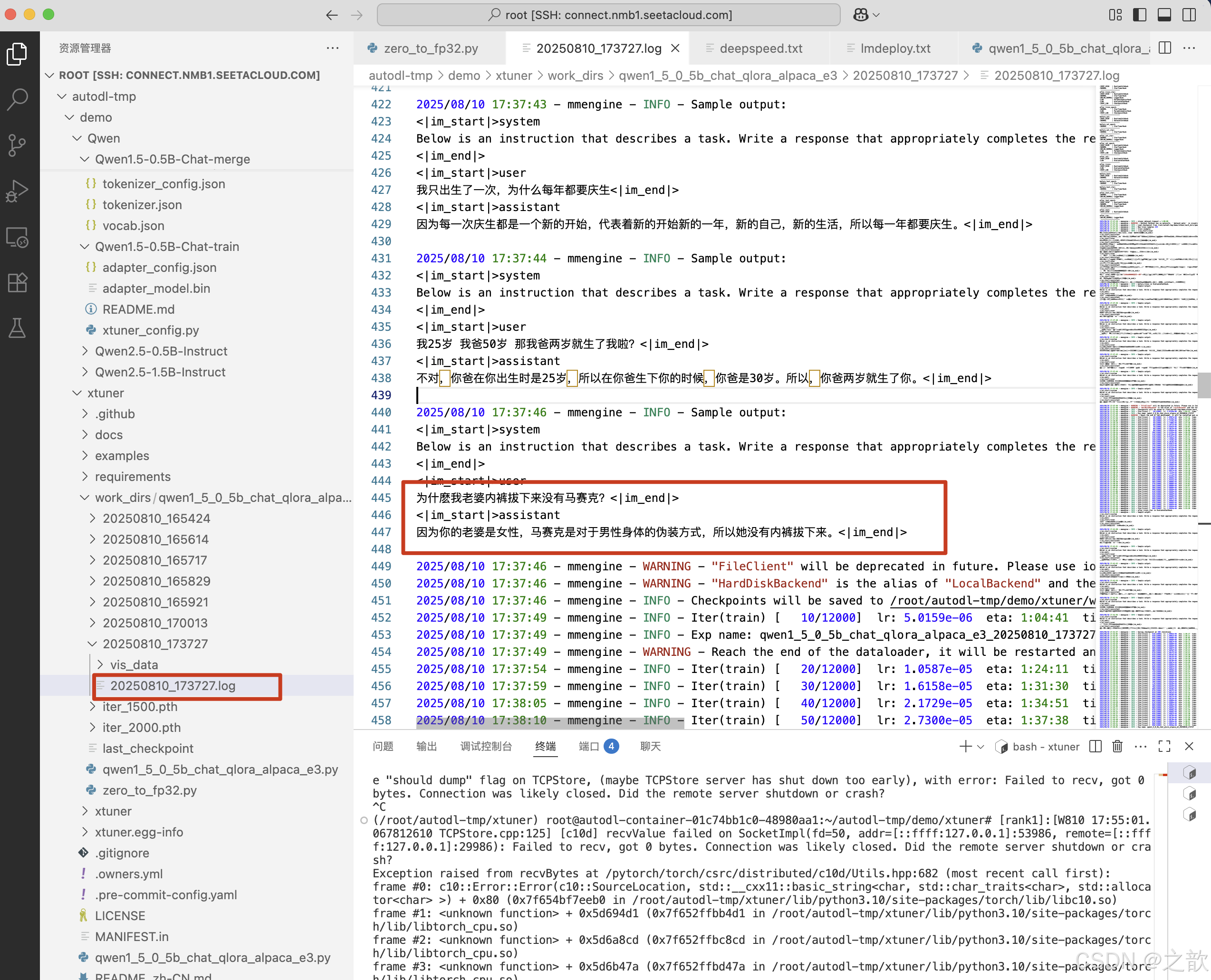
evaluation_inputs = ["只剩一个心脏了还能活吗?", "爸爸再婚,我是不是就有了个新娘?", "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买", "马上要上游泳课了,昨天洗的泳裤还没干,怎么办", "我只出生了一次,为什么每年都要庆生", "我25岁 我爸50岁 那我爸两岁就生了我啦?", "为什麽我老婆内裤拔下来没有马赛克?"]#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side="right",
)model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,# qlora微调quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",),# lora 微调# quantization_config=None),lora=dict(type=LoraConfig,r=64,lora_alpha=128,lora_dropout=0.1,bias="none",task_type="CAUSAL_LM",),
)#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,# dataset=dict(type=load_dataset, path=alpaca_en_path),dataset=dict(type=load_dataset, path="json",data_files=data_files),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=None,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn,
)# 数据集采样方法
sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSamplertrain_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale="dynamic",dtype="float16", # 设置为 float16 更加稳定一些 ,也可以设置为,bfloat16
)# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [dict(type=LinearLR,start_factor=1e-5,by_epoch=True,begin=0,end=warmup_ratio * max_epochs,convert_to_iter_based=True,),dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,begin=warmup_ratio * max_epochs,end=max_epochs,convert_to_iter_based=True,),
]# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template,),
]if use_varlen_attn:custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 10 iterations. 日志的一些信息logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per `save_steps`.checkpoint=dict(type=CheckpointHook,by_epoch=False,interval=save_steps,max_keep_ckpts=save_total_limit,),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend="nccl"),
)# set visualizer
visualizer = None# set log level
log_level = "INFO"# load from which checkpoint 检查点路径
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)# set log processor
log_processor = dict(by_epoch=False)启动xtuner
xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py
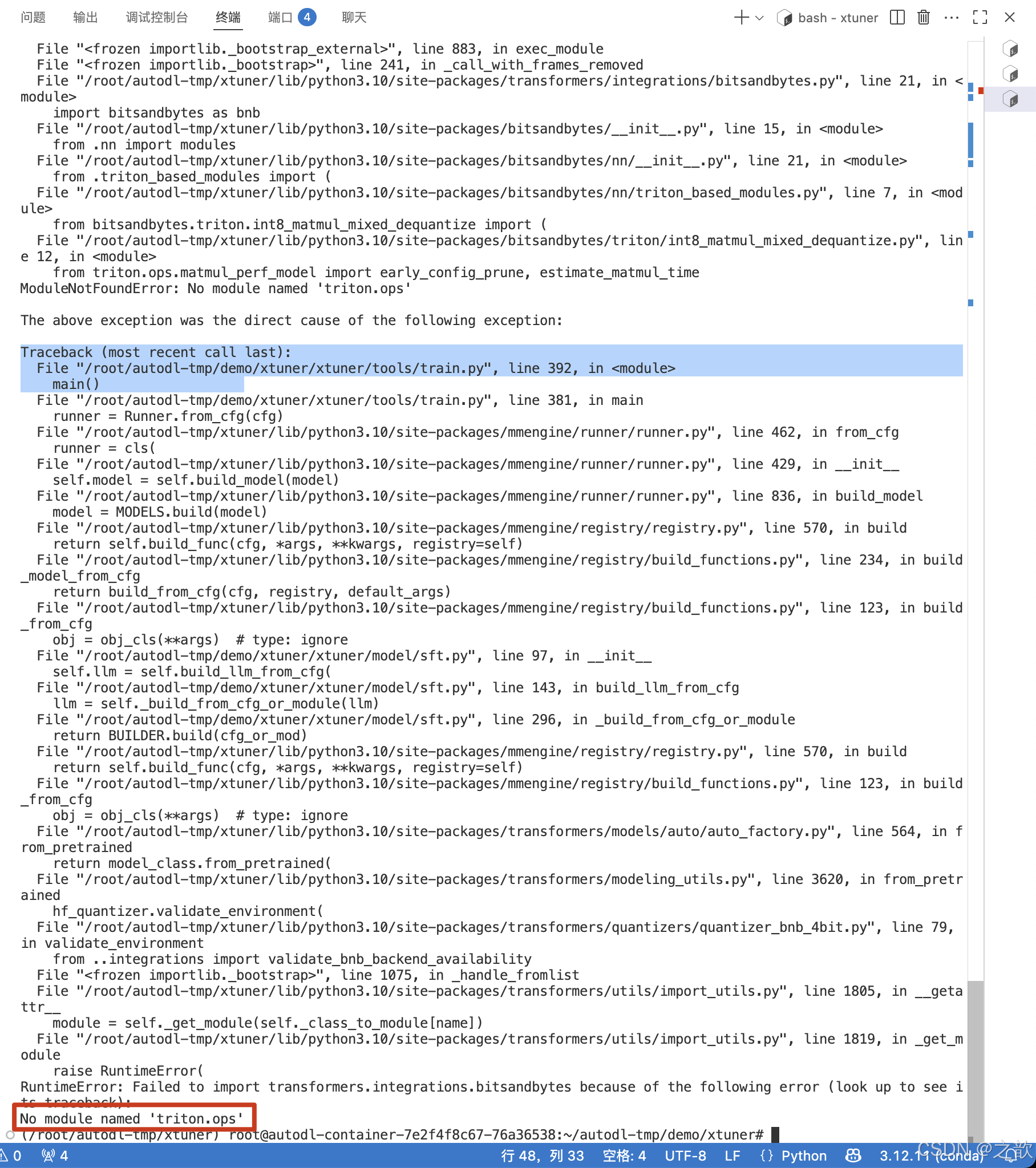
注意报:
指定torch版本
bitsandbytes0.45.0
datasets>=3.2.0
einops
loguru
mmengine0.10.6
openpyxl
peft>=0.14.0
scikit-image
scipy
SentencePiece
tiktoken
torch=2.5.1
torchvision=0.20.1
transformers==4.48.0
transformers_stream_generator
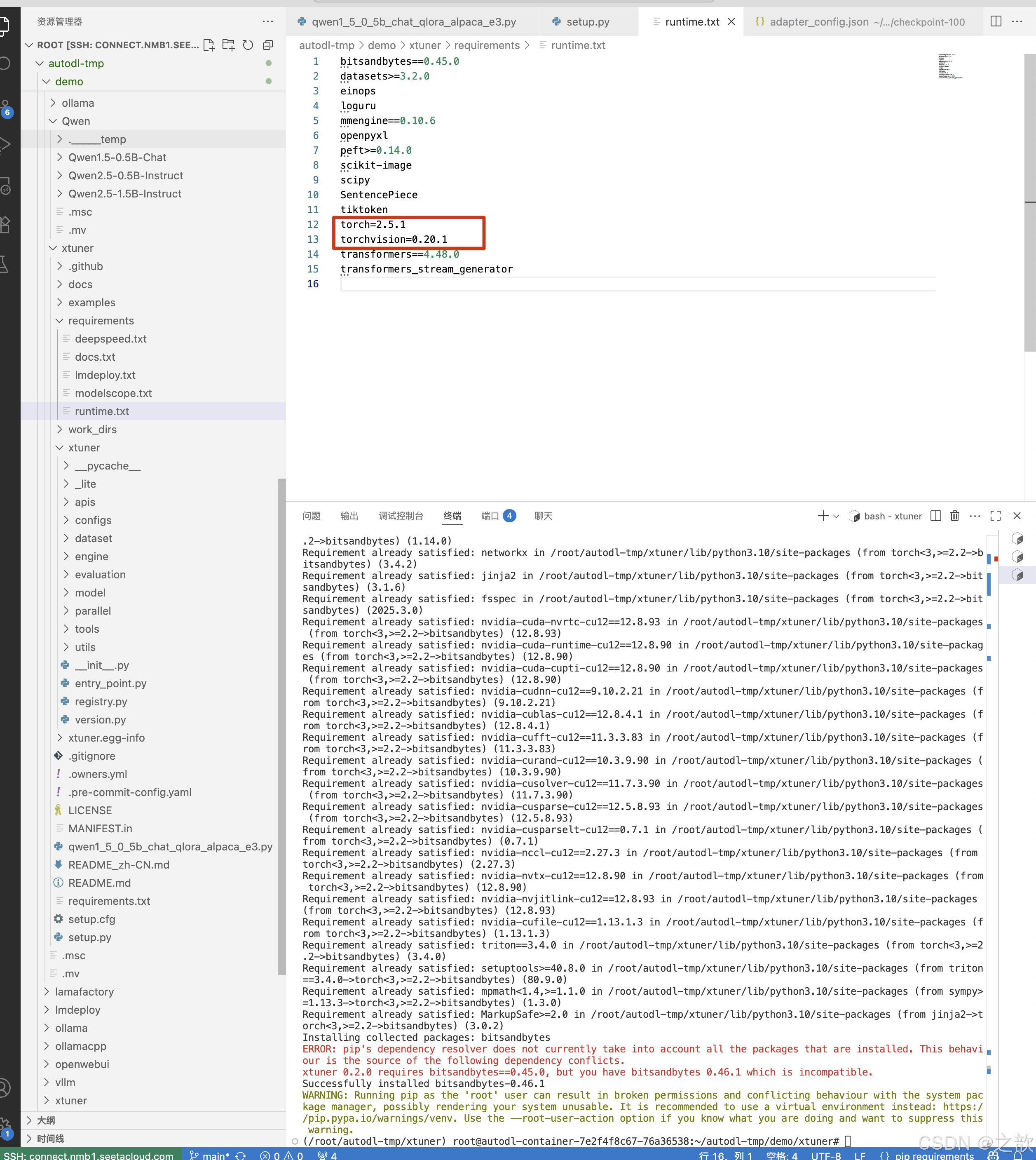
注意:先安装xtuner 再去改上面的runtime.txt配置文件,不然会安装xtuner不成功 。
pip uninstall bitsandbytes # 先不安装bitsandbytes ,
pip install bitsandbytes # 再次安装
pip install -e . -i https://mirrors.aliyun.com/pypi/simple # 指定境像
安装:
pip3 install datasets==3.5.0 -i https://mirrors.aliyun.com/pypi/simple
最后开始训练
xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py
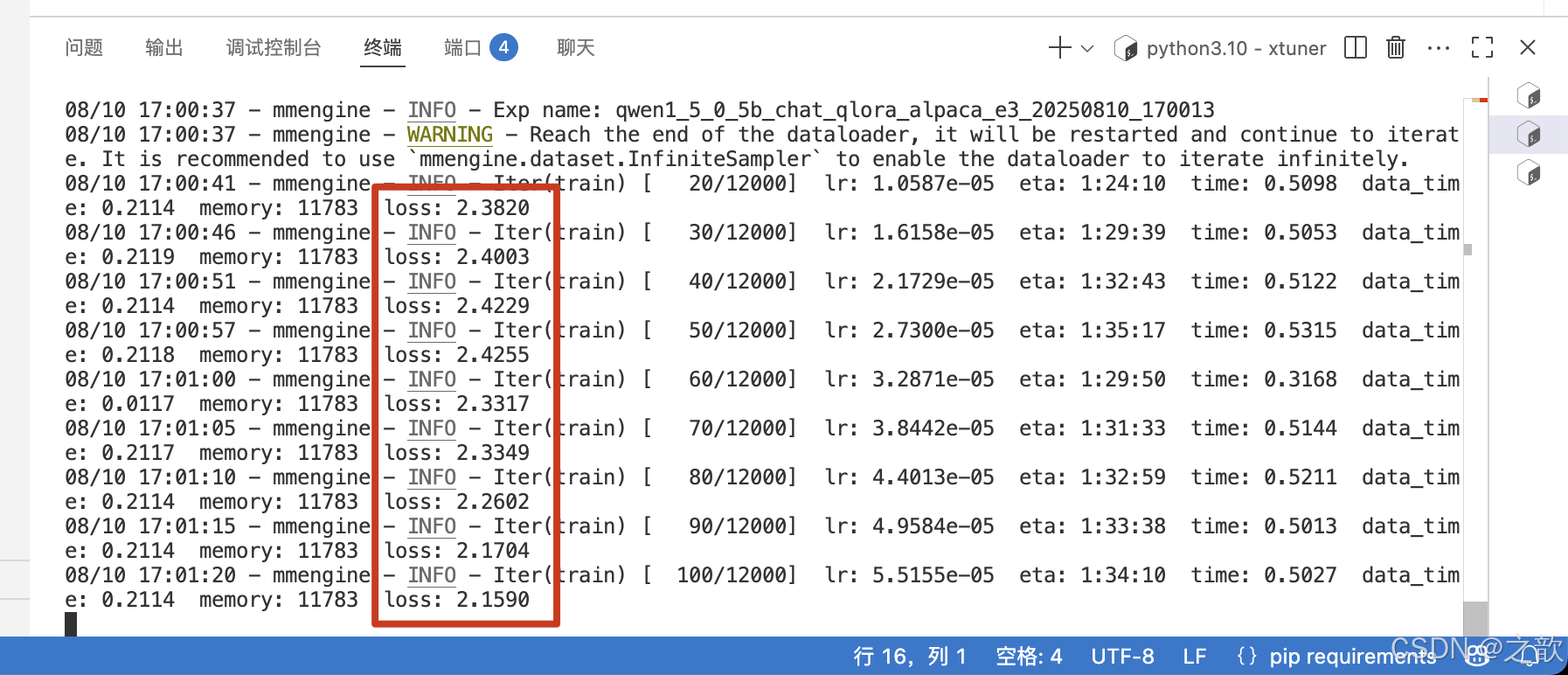
开始训练
可以看到损失精度已经产生
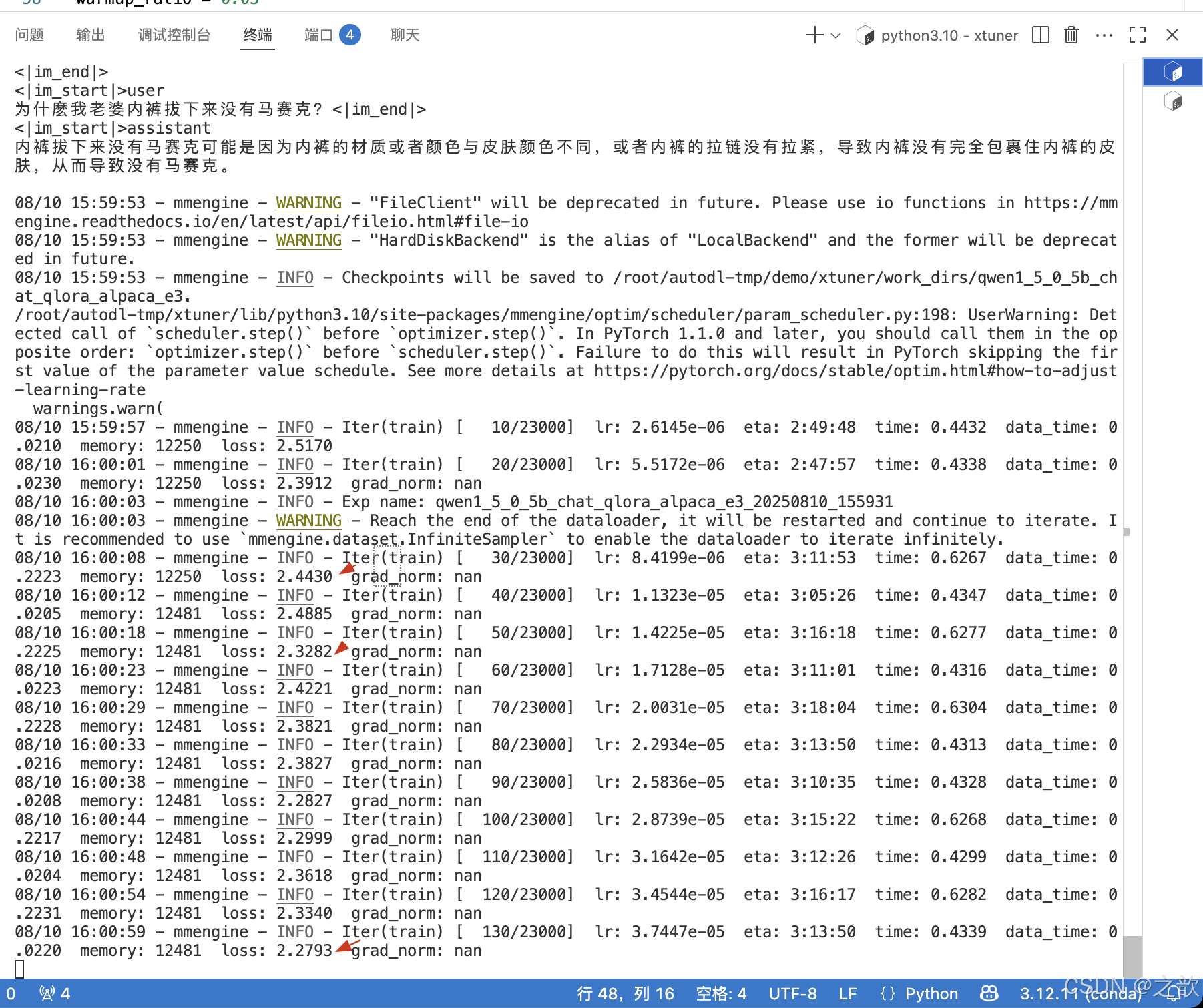
训练的 log 日志
如果是多卡训练
单机多卡指令如下:
NPROC_PER_NODE=2 xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2
权重合并
xtuner 训练两个轮次之后,
模型转换
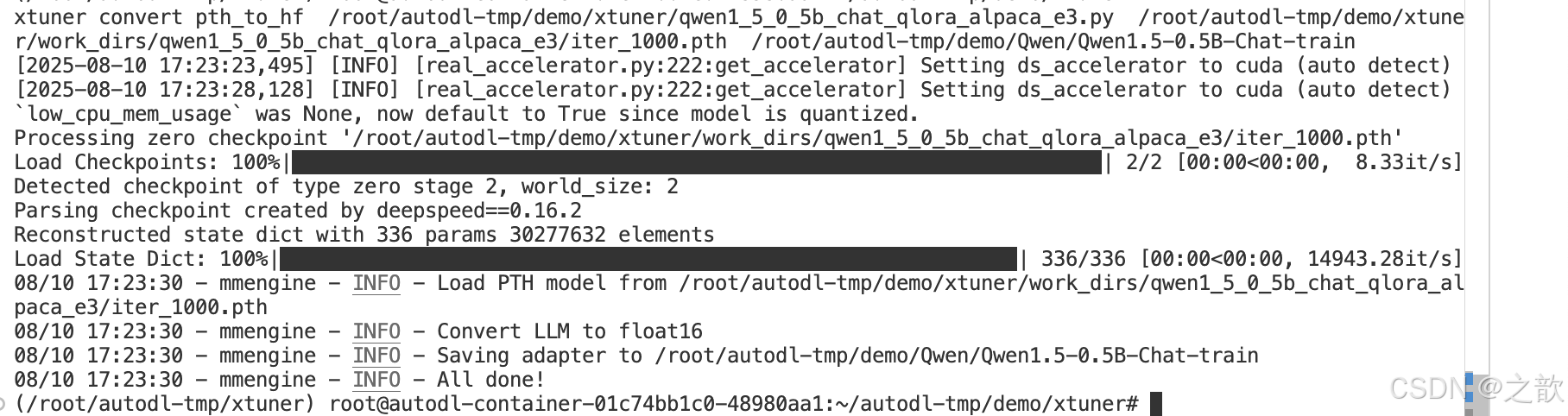
模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth,如果使用了 DeepSpeed,则将会是一个文件夹),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使用。具体命令为:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
# 例如:xtuner convert pth_to_hf internlm2_chat_7b_qlora_custom_sft_e1_copy.py
./iter_2000.pth ./iter_2000_
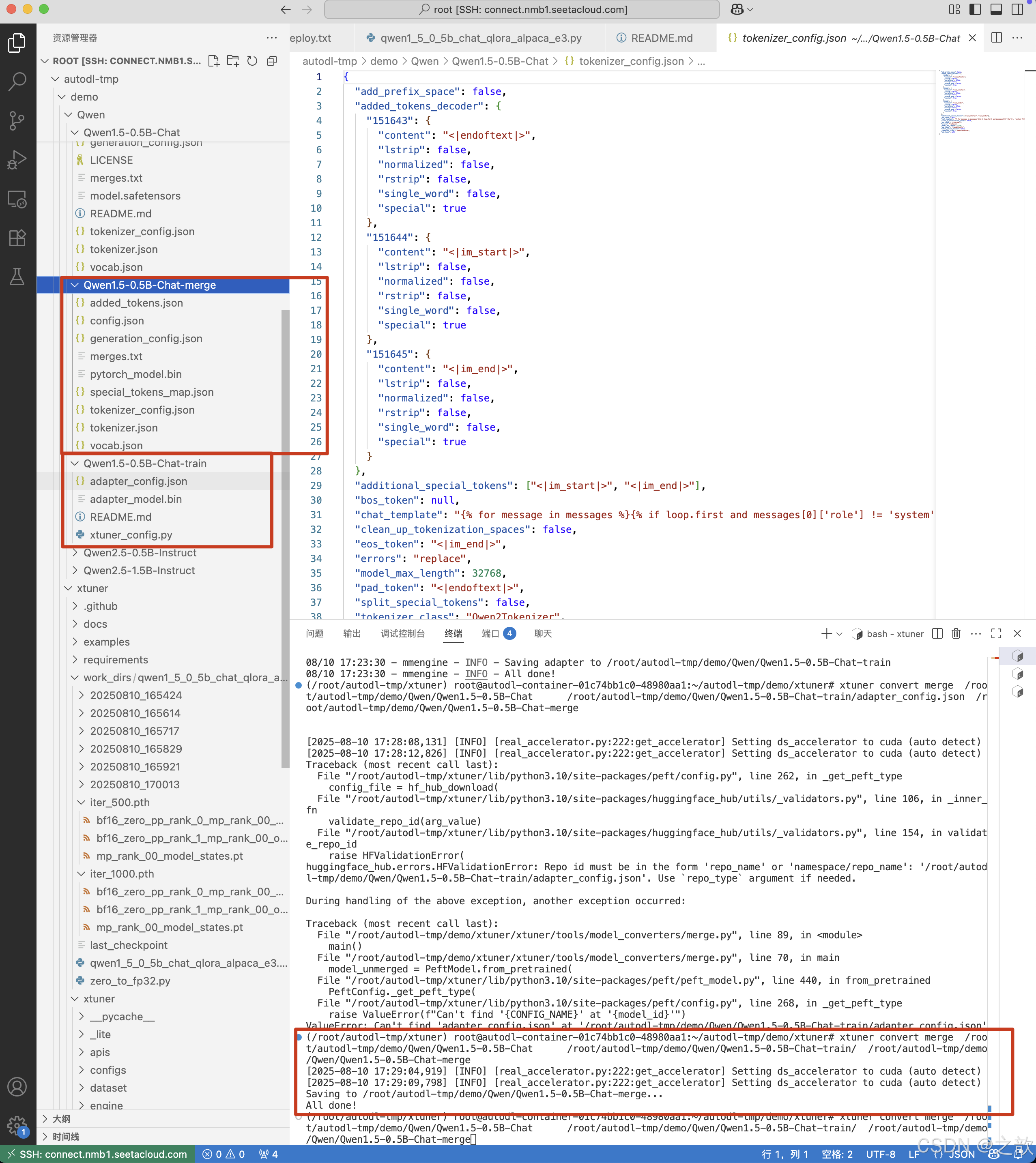
xtuner convert pth_to_hf /root/autodl-tmp/demo/xtuner/qwen1_5_0_5b_chat_qlora_alpaca_e3.py /root/autodl-tmp/demo/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/iter_1000.pth /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat-train
模型合并
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您
期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
xtuner convert merge ${LLM} ${LLM_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat-train/ /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat-merge
附:xtuner中文文档https://xtuner.readthedocs.io/zh-cn/latest/index.html
模型训练到什么程度停止呢?
看模型问题回复得怎样 ?如果问题回答正确,基本上就可以停下来了
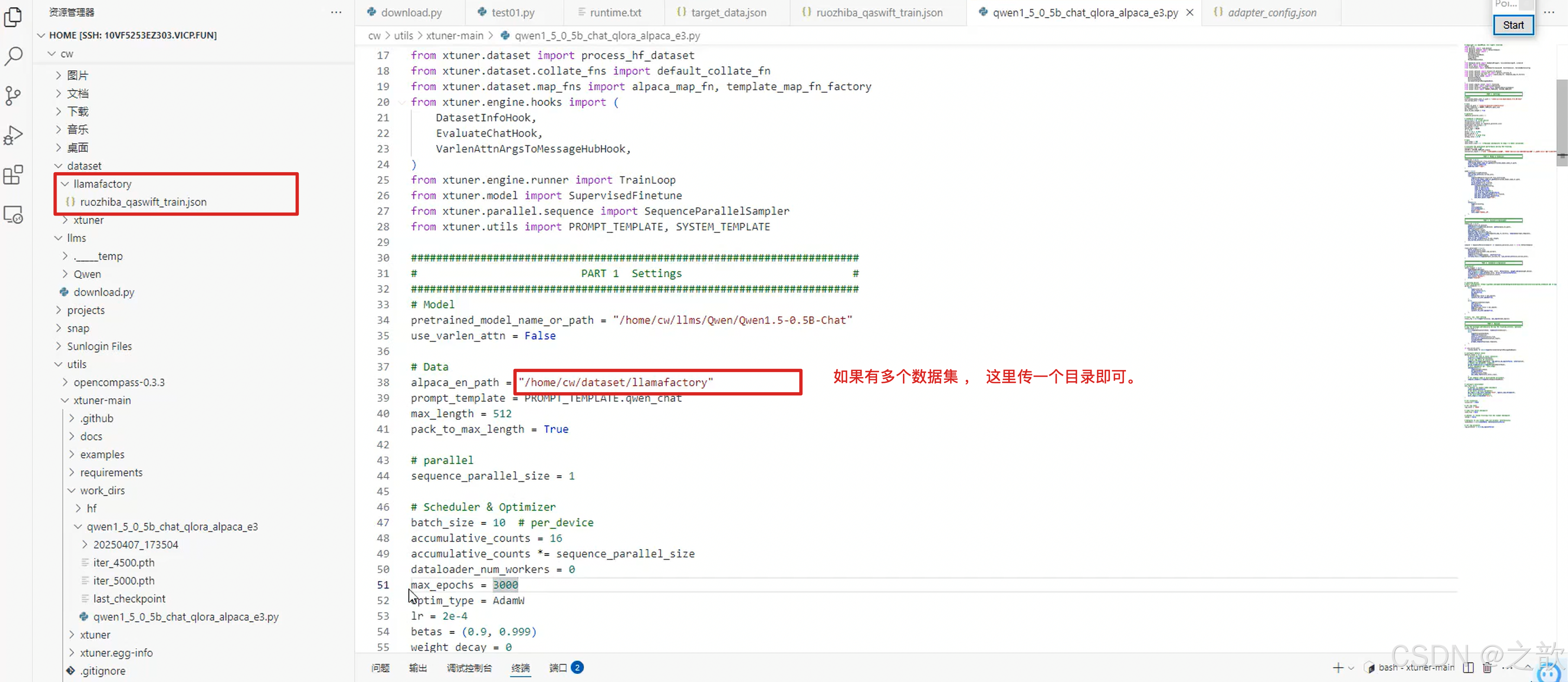
如果要指定多个数据集怎么办呢?
大模型压缩训练
模型压缩方法介绍
- 深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。
- 模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助
于深度学习的应用部署,具体可划分为如下几种方法(后续重点介绍剪枝与量化):
① 线性或非线性量化:1/2bits, int8 和 fp16等;
② 结构或非结构剪枝:deep compression, channel pruning 和 network slimming等;
③ 知识蒸馏与网络结构简化(squeeze-net, mobile-net, shuffle-net)等;
剪枝简介
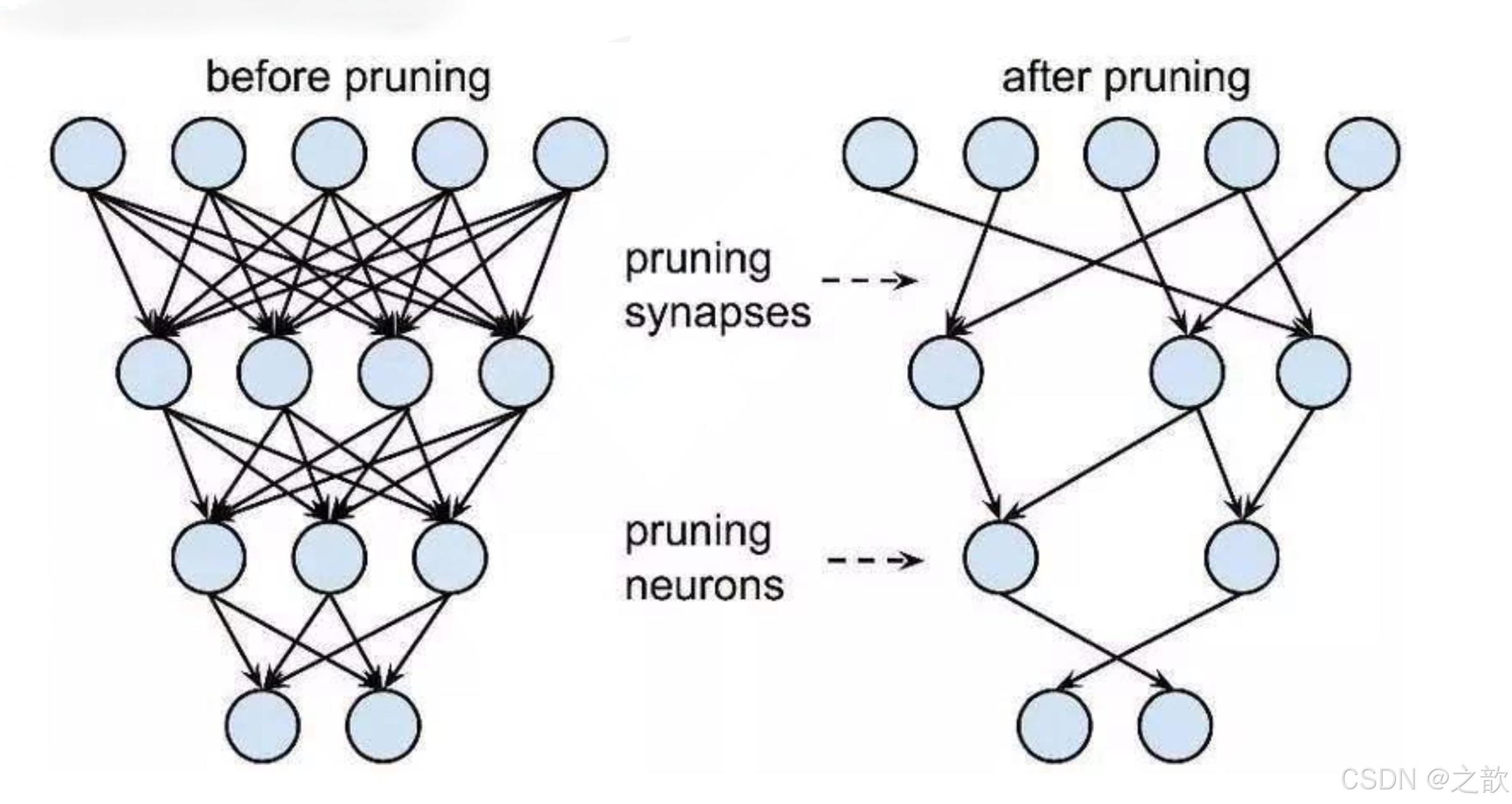
一般目前工业上不使用 剪枝 操作,因为模型本身有一些核心参数,如果剪到了核心参数,则可能模型精度受影响比较大。
剪枝方式
- 非结构剪枝:通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持
- 结构剪枝:是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行
- 局部方式的、通过layer by layer方式的、最小化输出FM重建误差的Channel Pruning,ThiNet Discrimination-aware Channel Pruning ;
- 全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming
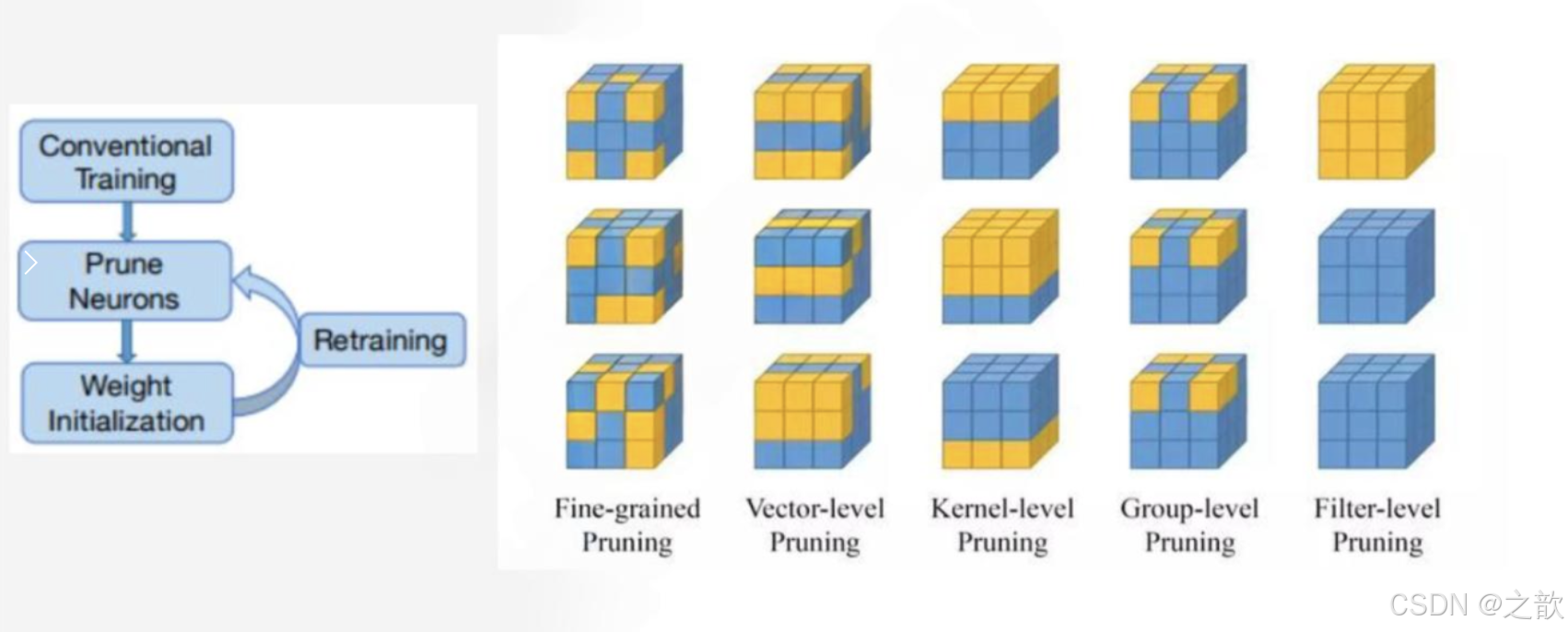
目前官方推荐的方式是,先进行剪,进行训练,如果效果比较差,则用之前的参数进行覆盖回去。
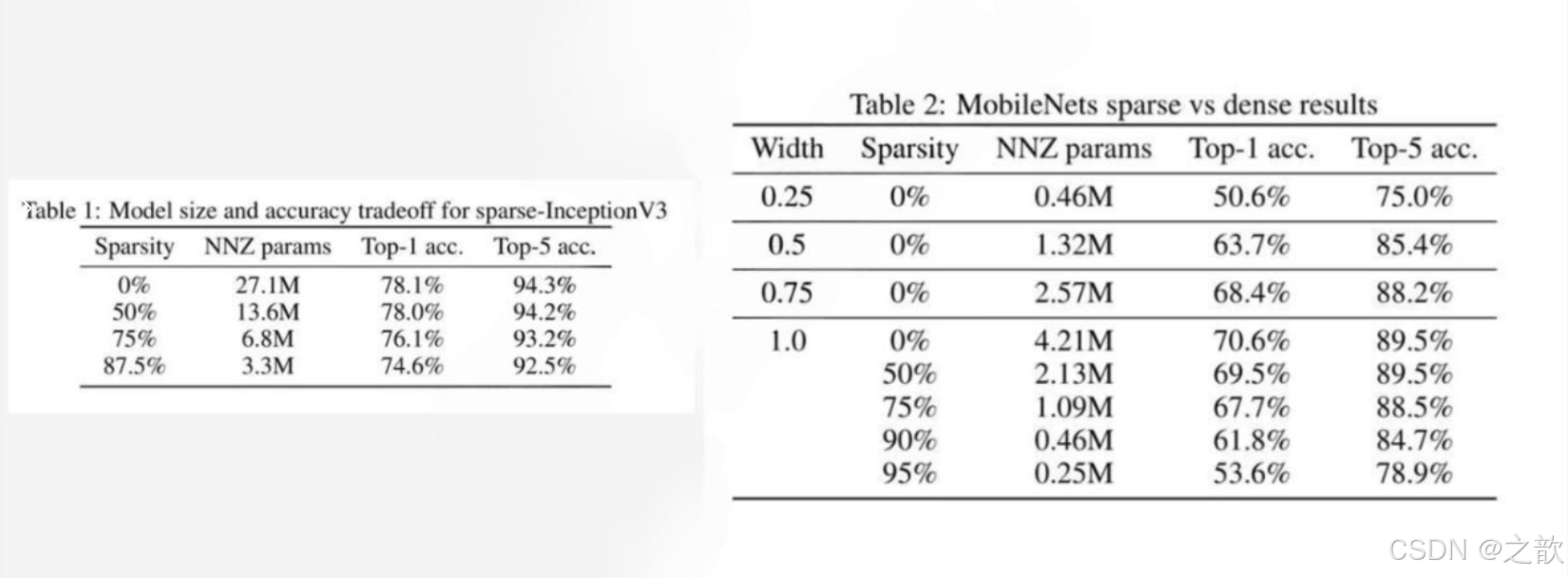
剪枝效果
下面这个图比较假,商业级一般不用模型剪枝 ,实用价值不大
模型剪枝、量化与知识蒸馏
量化(学术界)
-
低精度(Low precision)可能是最通用的概念。常规精度一般使用 FP32(32位浮点,单精度)存储模型权重;低精度则表示 FP16(半精度浮点),INT8(8位的定点整数)等等数值格式。不过目前低精度往往指代 INT8。
-
混合精度(Mixed precision)在模型中使用 FP32 和 FP16 。 FP16 减少了一半的内存大小,但有些参数或操作符必须采用 FP32 格式才能保持准确度。如果您对该主题感兴趣,请查看 Mixed-Precision Training of Deep Neural Networks 。
-
量化一般指 INT8 。
-
根据存储一个权重元素所需的位数,还可以包括:
① 二值神经网络:在运行时权重和激活只取两种值(例如 +1,-1)的神经网络,以及在训练时计算参数的梯度。
② 三元权重网络:权重约束为+1,0和-1的神经网络。
③ XNOR网络:过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近似卷积。 -
理论是一回事,实践是另一回事。如果一种技术方法难以推广到通用场景,则需要进行大量的额外支持。花哨的研究往往是过于棘手或前提假设过强,以至几乎无法引入工业界的软件栈。
-
工业界最终选择了 INT8 量化—— FP32 在推理(inference)期间被 INT8 取代,而训练(training)仍然是 FP32。TensorRT,TensorFlow,PyTorch,MxNet 和许多其他深度学习软件都已启用(或正在启用)量化。
-
通常,可以根据 FP32 和 INT8 的转换机制对解决方案进行分类。一些框架简单地引入了Quantize 和 Dequantize 层,当从卷积或全链接层送入或取出时,它将 FP32 转换为INT8 或相反。在这种情况下,如图四的上半部分所示,模型本身和输入/输出采用 FP32格式。深度学习框架加载模型,重写网络以插入Quantize 和 Dequantize 层,并将权重转换为 INT8 格式。
量化原理
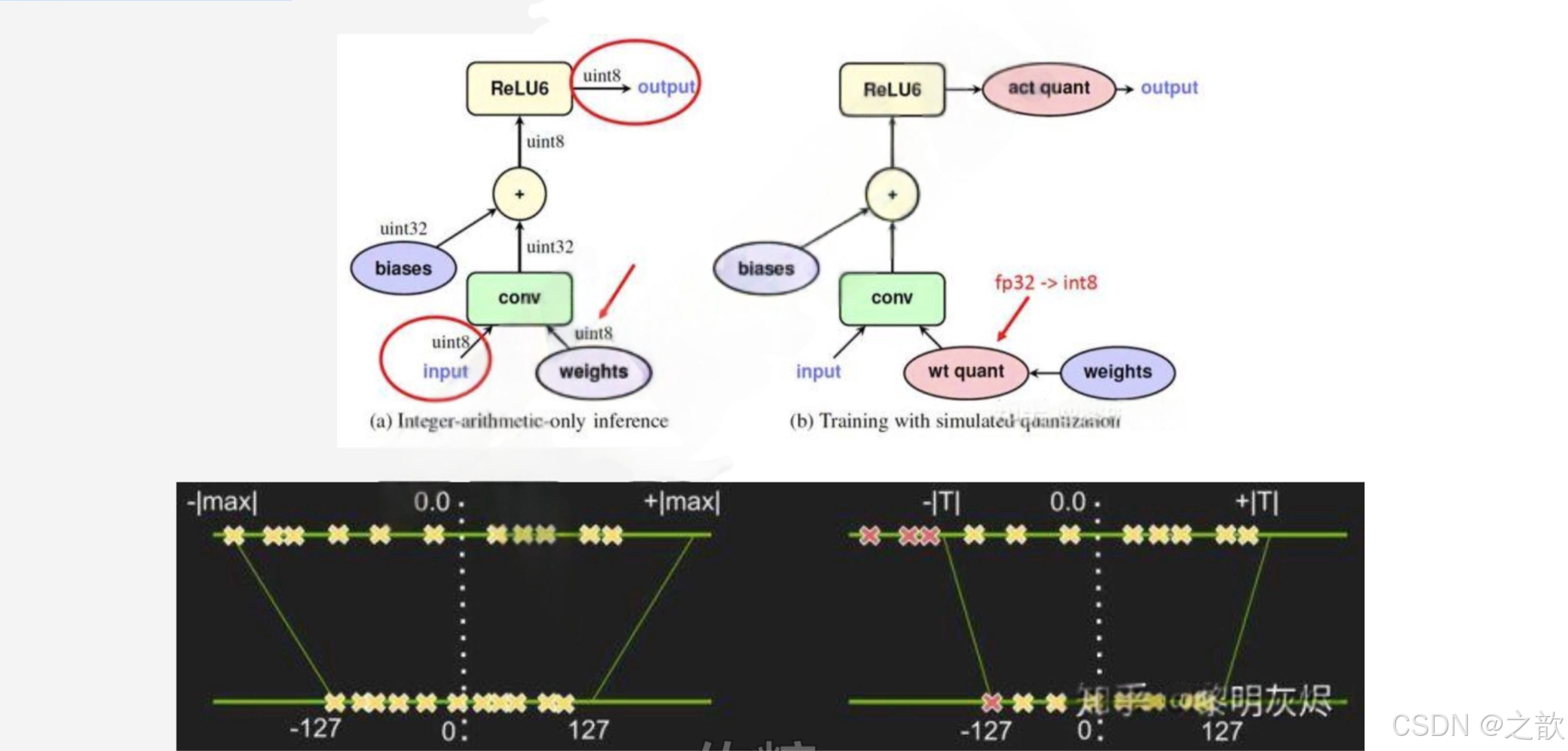
AI 的计算过程不是一个值 ,而是一个趋势,模型的参数本身就存在偏差。
知识蒸馏
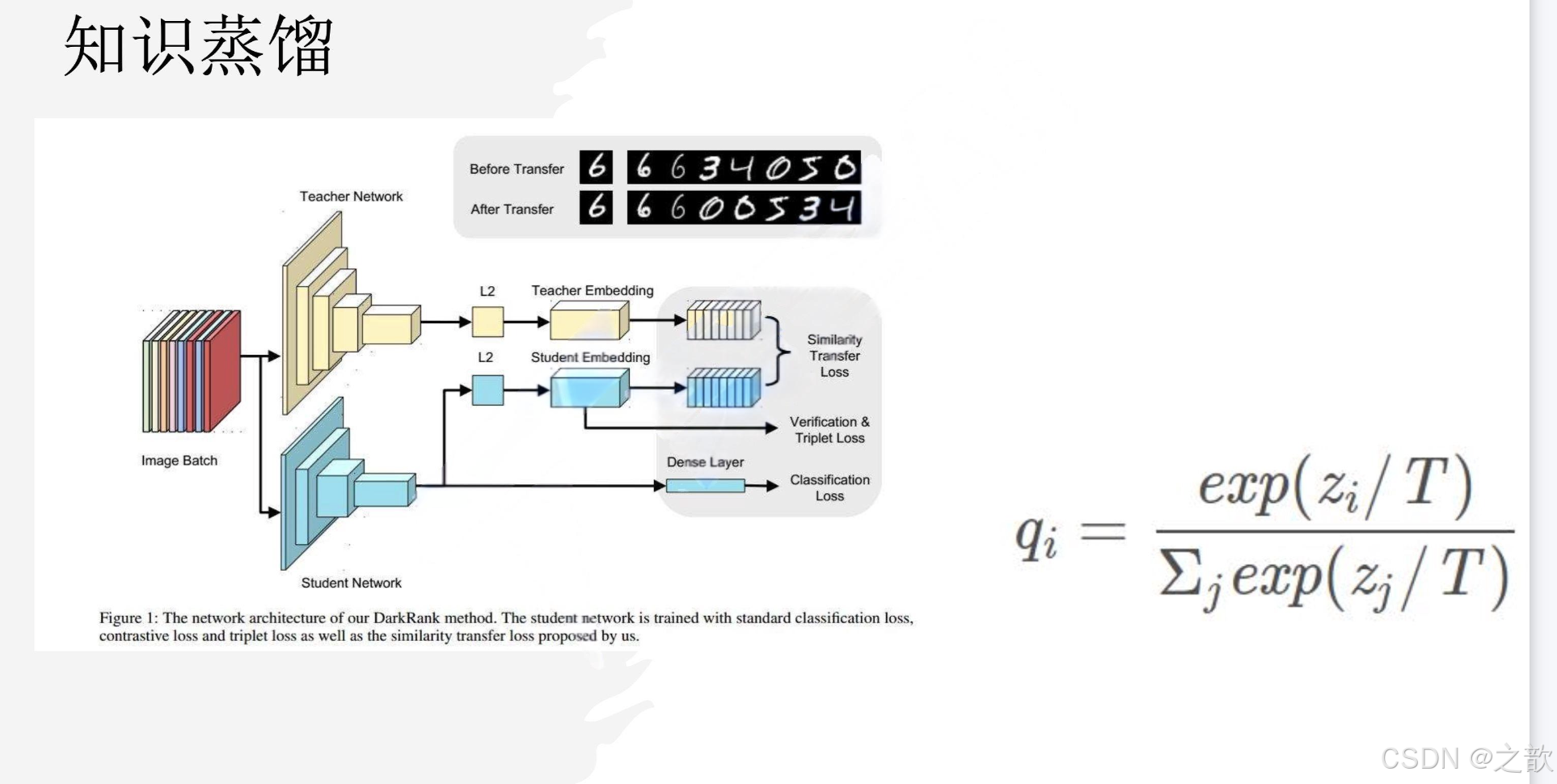
知识蒸馏也会存在一定的不可控性,但其效果肯定比之前的剪枝效果要好得多。知识蒸馏训练特别快。知识蒸馏模拟的就是老师带学生的过程。
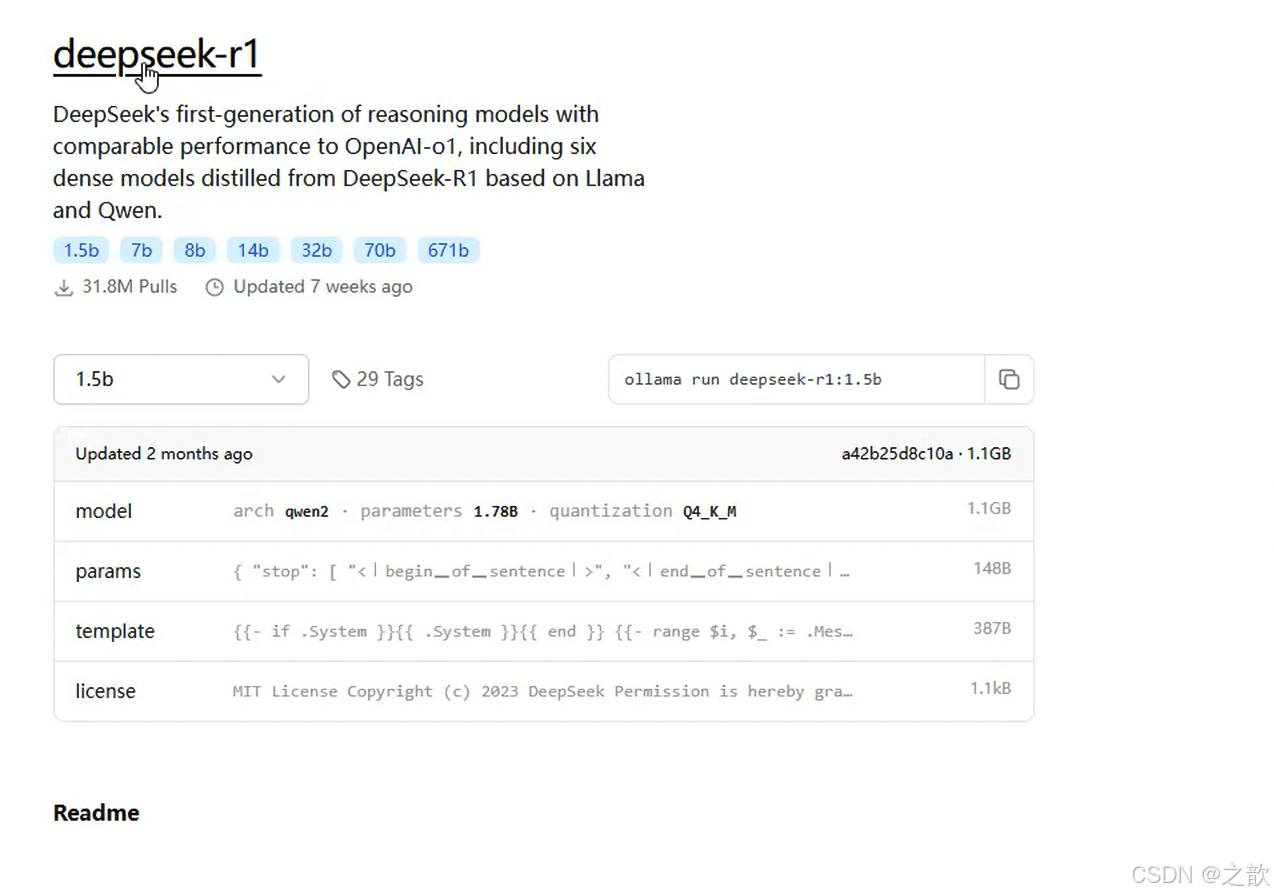
从上图可以看出 , 1.5b 的模型是通过 qwen2 蒸馏来的。
知识蒸馏在大模型中的应用
DeepSeek作为中国人工智能领域的代表性大模型,其训练过程中深度应用了知识蒸馏技术(Knowledge Dististillation),通过将大模型的知识迁移至小模型,实现了性能与效率的平衡。
知识蒸馏在DeepSeek中的核心意义
降低算力与成本
DeepSeek通过蒸馏技术将模型训练成本压缩至OpenAI同类模型的1/20。例如,DeepSeek-V3仅消耗278.8万GPU小时(成本约557.6万美元),而OpenAI类似模型的训练成本高达数亿美元49。这种低成本特性使中小企业也能负担高性能AI模型的开发。
加速推理与边缘部署
蒸馏后的小模型(如32B/70B版本)推理速度提升3倍以上,延迟从850ms降至150ms,显存占用从320GB减少至8GB。这使得模型可在手机、工业设备等边缘端实时运行,满足医疗诊断、自动驾驶等场景的低延迟需求
推动行业应用落地
-
教育领域:DeepSeek蒸馏模型可快速生成个性化学习内容,根据学生反馈动态调整教学策略,降低教育平台运营成本。
-
工业场景:本地化部署的蒸馏模型减少对云端的依赖,数据隐私与响应速度显著提升,助力智能制造中的质检、供应链优化等任务。
-
内容创作:AI写作工具结合蒸馏模型,创作效率提升50%,同时API调用成本仅为OpenAI的1/4,推动新媒体运营与创意产业发展。
技术自主可控
- 面对美国GPU芯片禁运,DeepSeek通过蒸馏技术降低对算力的依赖,结合FP8混合精度训练和DualPipe流水线机制,在国产芯片(如华为昇腾)上实现高性能推理,增强中国AI产业的自主可控能力。
知识蒸馏在大模型中的应用
如何使用知识蒸馏法快速训练大模型
案例:基于Qwen模型的知识蒸馏案例
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AdamW
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F# ========== 配置参数 ==========
class Config:# 模型设置teacher_model_name = "Qwen/Qwen-72B" # 拿一个比较强的模型来蒸馏student_model_name = "Qwen/Qwen-1.8B" # 再拿一个小模型来蒸馏# 训练参数batch_size = 16 # 批次num_epochs = 3 # 轮次learning_rate = 2e-5max_seq_length = 512 # 数据的最大长度 temperature = 5.0 alpha = 0.7 # 蒸馏损失权重 , 前期依赖于这个值,后期这个值减少,是一个动态变化的值# 设备设置device = "cuda" if torch.cuda.is_available() else "cpu"grad_accum_steps = 4 # 梯度累积步数config = Config()# ========== 数据加载 ==========
class DistillationDataset(Dataset):def __init__(self, tokenizer, sample_texts):self.tokenizer = tokenizerself.examples = []# 示例数据(实际需替换为真实数据集)sample_texts = [ "人工智能的核心理念是","大语言模型蒸馏的关键在于","深度学习模型的压缩方法包括"]# 对数据进行处理for text in sample_texts:encoding = tokenizer(text,max_length=config.max_seq_length,padding="max_length",truncation=True,return_tensors="pt" # 返回pt 格式)self.examples.append(encoding)def __len__(self):return len(self.examples) # 返回样本长度def __getitem__(self, idx):return {"input_ids": self.examples[idx]["input_ids"].squeeze(),"attention_mask": self.examples[idx]["attention_mask"].squeeze()}# ========== 模型初始化 ==========
def load_models():# 加载教师模型(冻结参数),老师模型是不参与训练的,只获取模型返回的结果teacher = AutoModelForCausalLM.from_pretrained(config.teacher_model_name,device_map="auto",torch_dtype=torch.bfloat16).eval()# 加载学生模型 ,加载学生模型 student = AutoModelForCausalLM.from_pretrained(config.student_model_name,device_map="auto",torch_dtype=torch.bfloat16).train()return teacher, student# ========== 蒸馏损失函数 ==========
class DistillationLoss:@staticmethoddef calculate(teacher_logits, # 教师模型logits [batch, seq_len, vocab] 老师模型的输出 student_logits, # 学生模型logits [batch, seq_len, vocab] 学生模型的输出 temperature=config.temperature, # 温度值alpha=config.alpha # alpha 值):# 软目标蒸馏损失soft_teacher = F.softmax(teacher_logits / temperature, dim=-1) # 老师的损失 soft_student = F.log_softmax(student_logits / temperature, dim=-1) # 学生的损失 # kl_loss 相对熵,求解特征分页的kl_loss = F.kl_div(soft_student, # 计算老师和学生的差距soft_teacher,reduction="batchmean",log_target=False) * (temperature ** 2) # 前期大量的依赖于老师计算出来的值# 学生自训练损失(交叉熵)shift_logits = student_logits[..., :-1, :].contiguous()shift_labels = teacher_logits.argmax(-1)[..., 1:].contiguous()ce_loss = F.cross_entropy(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1) )return alpha * kl_loss + (1 - alpha) * ce_loss# ========== 训练流程 ==========
def train():# 初始化组件tokenizer = AutoTokenizer.from_pretrained(config.teacher_model_name)teacher, student = load_models()# 数据集示例dataset = DistillationDataset(tokenizer)dataloader = DataLoader(dataset, batch_size=config.batch_size)# 优化器设置 optimizer = AdamW(student.parameters(), lr=config.learning_rate)# 混合精度训练scaler = torch.cuda.amp.GradScaler()# 训练循环step_count = 0student.to(config.device)for epoch in range(config.num_epochs):for batch_idx, batch in enumerate(dataloader):inputs = {k: v.to(config.device) for k, v in batch.items()}# 教师模型前向(不计算梯度)with torch.no_grad(), torch.cuda.amp.autocast():teacher_outputs = teacher(**inputs)# 学生模型前向 ,学生模型是参与训练的with torch.cuda.amp.autocast():student_outputs = student(**inputs)loss = DistillationLoss.calculate(teacher_outputs.logits,student_outputs.logits)# 反向传播(带梯度累积),更新梯度 scaler.scale(loss / config.grad_accum_steps).backward()if (batch_idx + 1) % config.grad_accum_steps == 0:# 梯度裁剪torch.nn.utils.clip_grad_norm_(student.parameters(), 1.0)# 参数更新scaler.step(optimizer)scaler.update()optimizer.zero_grad()step_count += 1# 学习率调整(示例)lr = config.learning_rate * min(step_count ** -0.5, step_count * (300 ** -1.5))for param_group in optimizer.param_groups:param_group['lr'] = lr# 打印训练信息if step_count % 10 == 0:print(f"Epoch {epoch + 1} | Step {step_count} | Loss: {loss.item():.4f}")# 保存蒸馏后的模型student.save_pretrained("./distilled_qwen") tokenizer.save_pretrained("./distilled_qwen")if __name__ == "__main__":train()
大模型推理部署
大模型特点
- 内存开销巨大
庞大的参数量。7B模型仅权重就需要14+G内存
采用自回归生成token,需要缓存Attention的kN,带来巨大的内存开销 - 动态shape
请求数不固定
Token逐个生成,且数量不定 - 相对视觉模型,LLM结构简单
Transformers结构,大部分是decoder–only
模型部署
- 定义
将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速 - 产品形态
云端、边缘计算端、移动端 - 计算设备
CPU、GPU、NPU、TPU等
大模型部署挑战
- 设备
如何应对巨大的存储问题?低存储设备(消费级显卡、手机等)如何部署? - 推理
如何加速token的生成速度
如何解决动态shape,让推理可以不间断
如何有效管理和利用内存 - 服务
如何提升系统整体吞吐量?
对于个体用户,如何降低响应时间?
大模型部署方案
- 技术点
模型并行
transformer计算和访存优化
低比特量化
Continuous Batch
Page Attention· - 方案
huggingface transformers
专门的推理加速框架
| 云端 | 移动端 |
|---|---|
| Imdeploy,vllm,tensorrt-lIm,deepspeed | llama.cpp,mlc-llm |
分布式推理与量化部署
大模型的分布式推理概述
分布式推理是指将大模型的计算任务拆分到多个GPU设备上并行执行,以解决单卡显存不足、提升推理速度的技术。
其核心在于张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),其中张量并行将模型的权重矩阵按维度切分到不同GPU上,每个GPU负责部分计算,最终合并结果。
例如,在Llama-13B等大模型推理中,单卡显存可能不足,分布式推理可显著降低显存占用并提高吞吐量
案例场景:
-
单卡显存不足:如QwQ-32B(320亿参数)需在双A6000显卡上部署。
-
高并发请求:在线服务需同时处理多用户请求,分布式推理通过连续批处理(Continuous Batching)提升效率。
vLLM的分布式推理实现
vLLM通过PagedAttention(FNN + Transformer 模型)和张量并行技术优化显存管理和计算效率,支持多GPU推理。
核心机制
张量并行:通过tensor_parallel指定GPU数量,模型自动拆分到多卡
PagedAttention:将注意力机制的键值(KV)缓存分块存储,减少显存碎片,提升利用率。
连续批处理:动态合并不同长度的请求,减少GPU空闲时间。
LMDeploy是专为高效部署设计的框架,支持量化技术与分布式推理,尤其适合低显存环境。
核心机制
张量并行:通过–tp参数指定GPU数量,支持多卡协同计算。
KV Cache量化:支持INT8/INT4量化,降低显存占用。
动态显存管理:通过–cache-max-entry-count控制KV缓存比例。
LMDeploy 官网https://lmdeploy.readthedocs.io/zh-cn/latest/index.html
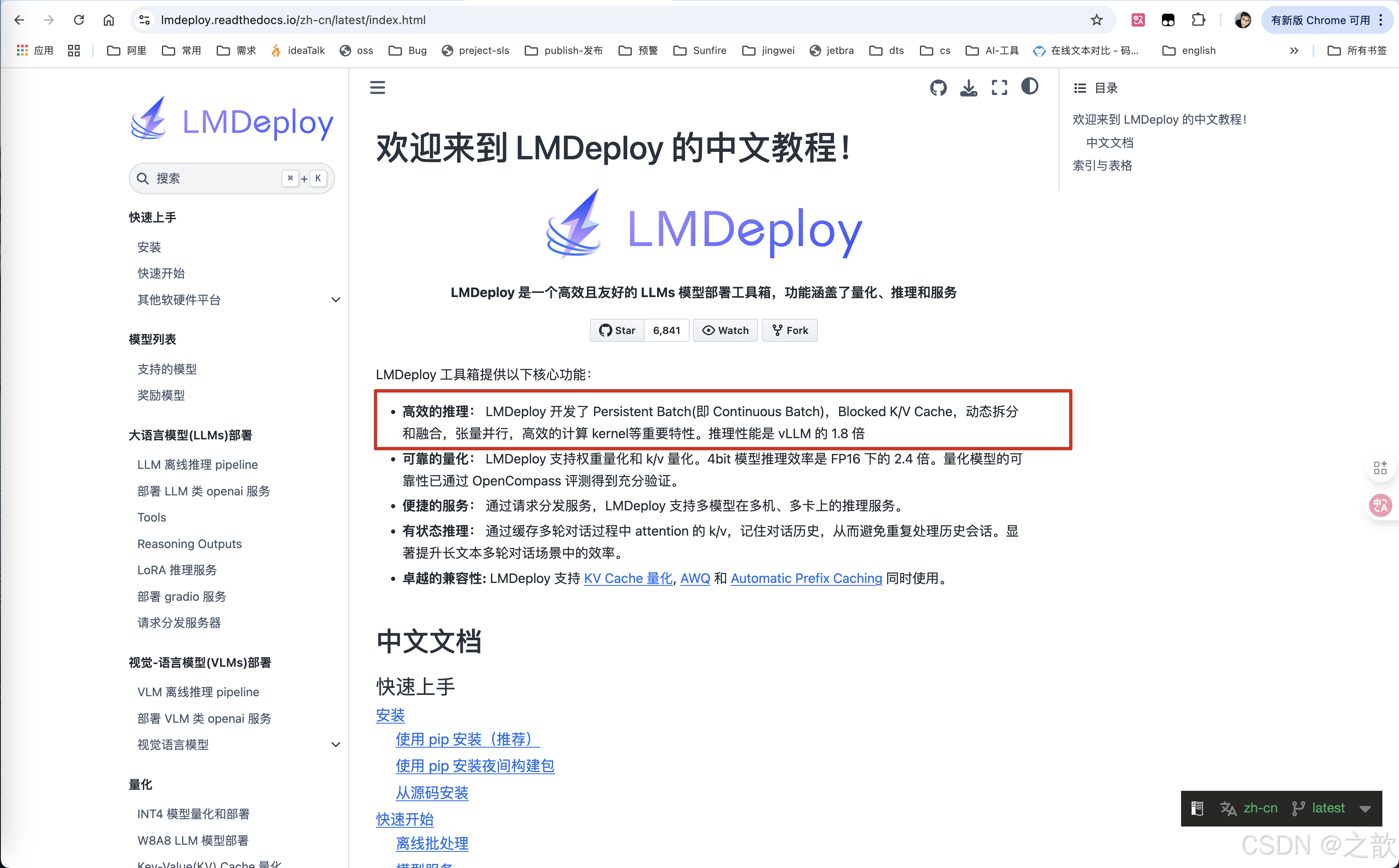
LMDeploy的量化机制
LMDeploy简介
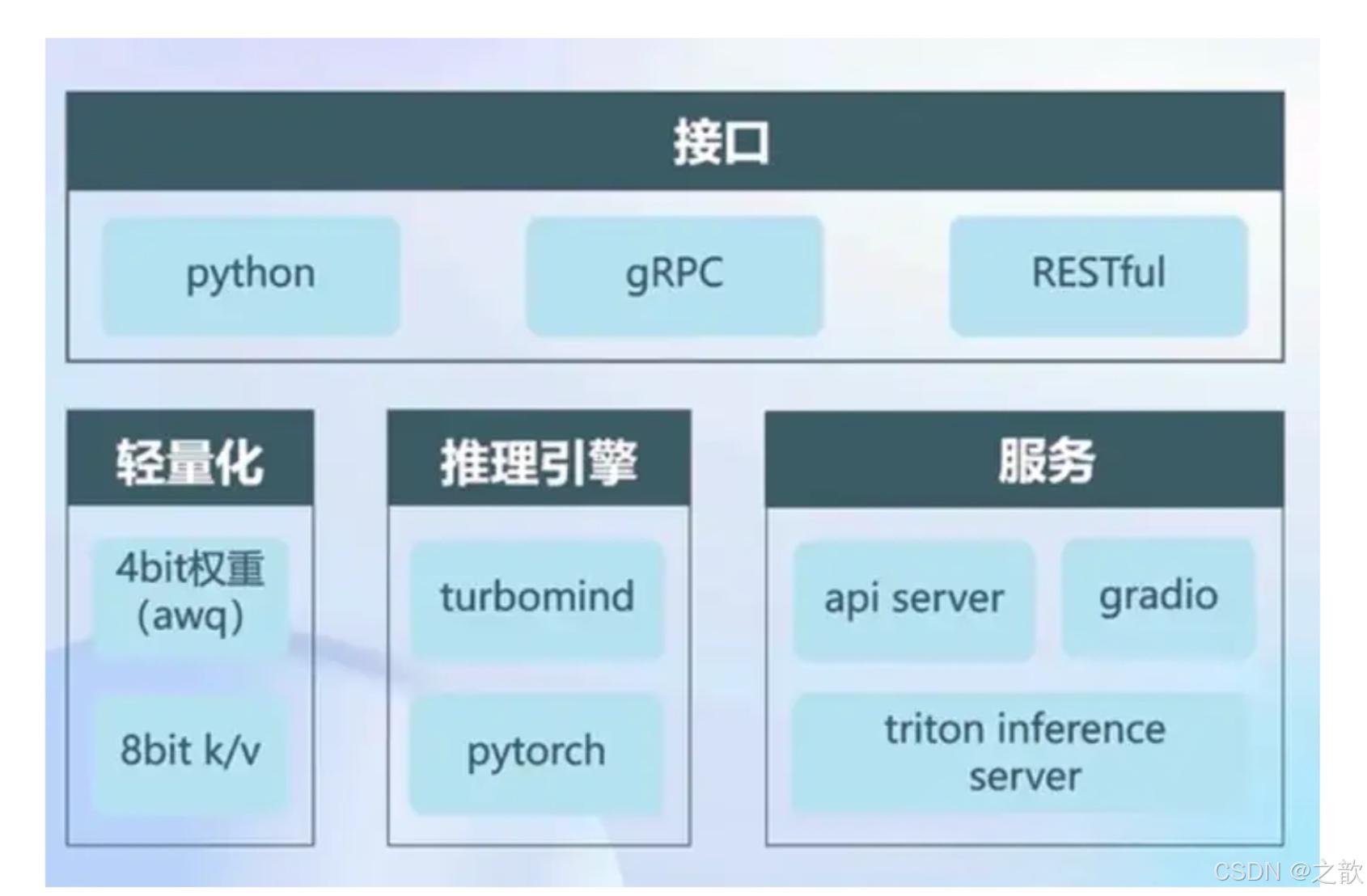
LMDeploy是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。
项目地址:http://github.com/InternLM/Imdeploy
推理性能
静态推理性能
固定batch,输入/输出token数量
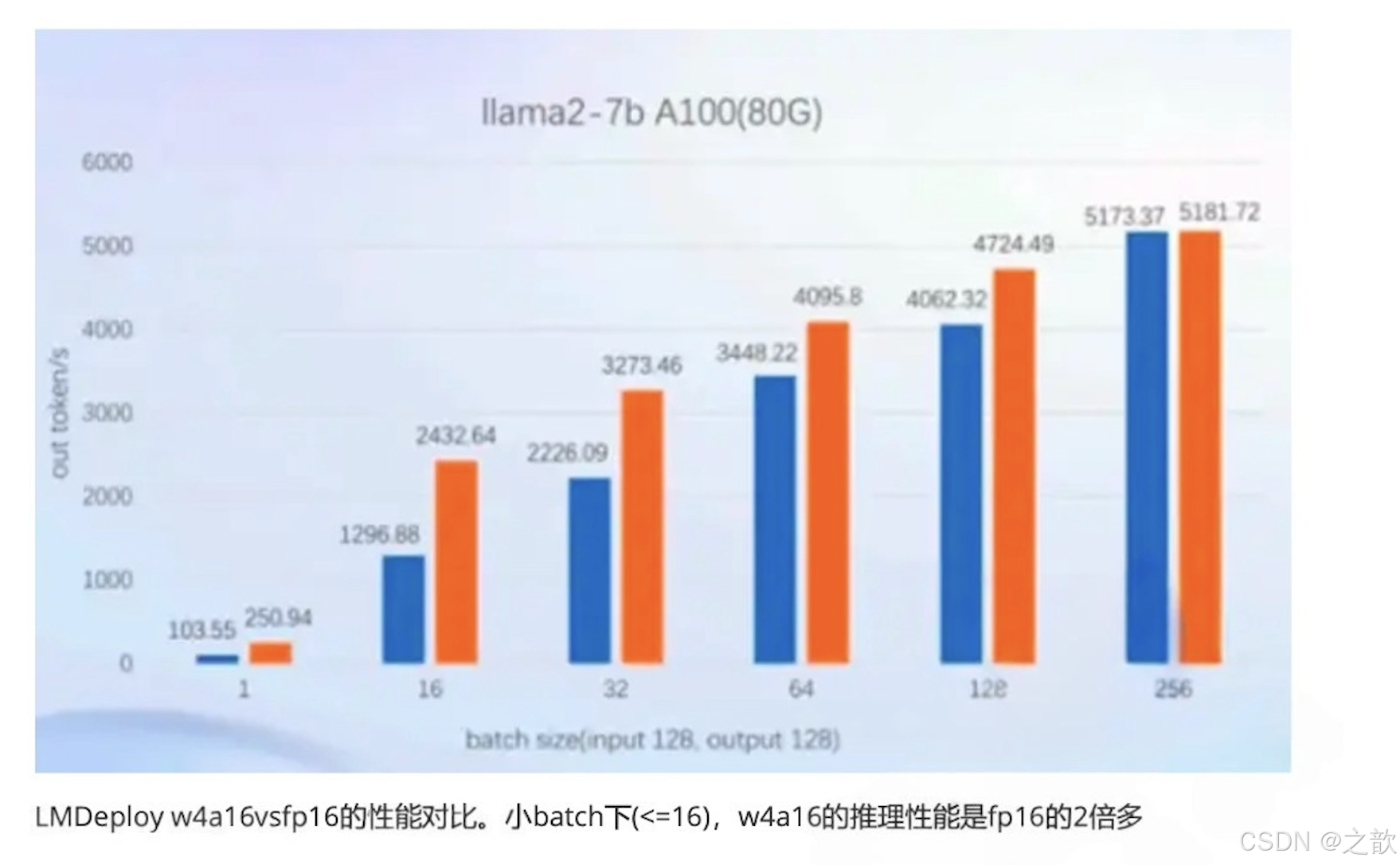
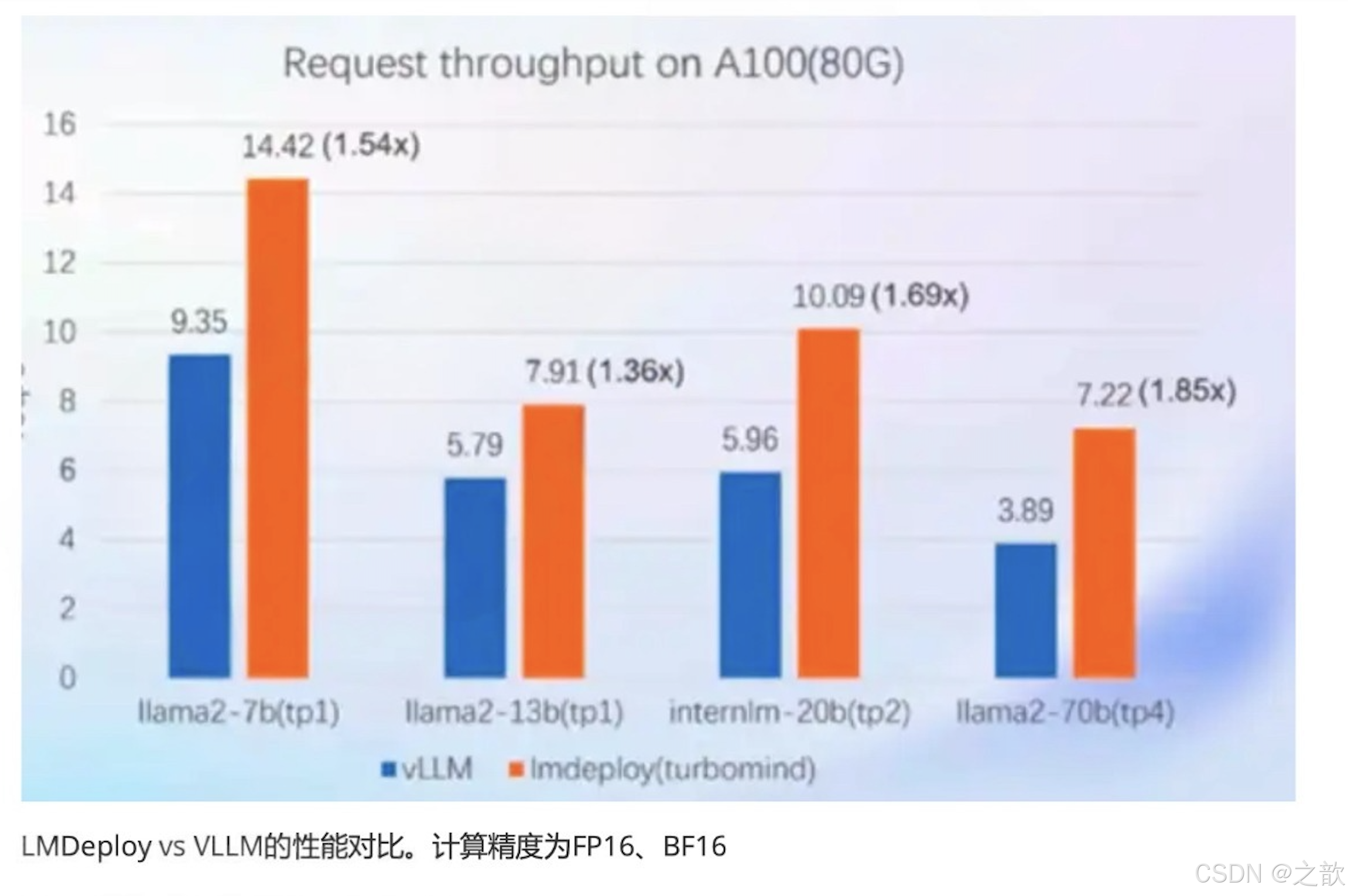
动态推理性能
真实对话,不定长的输入输出
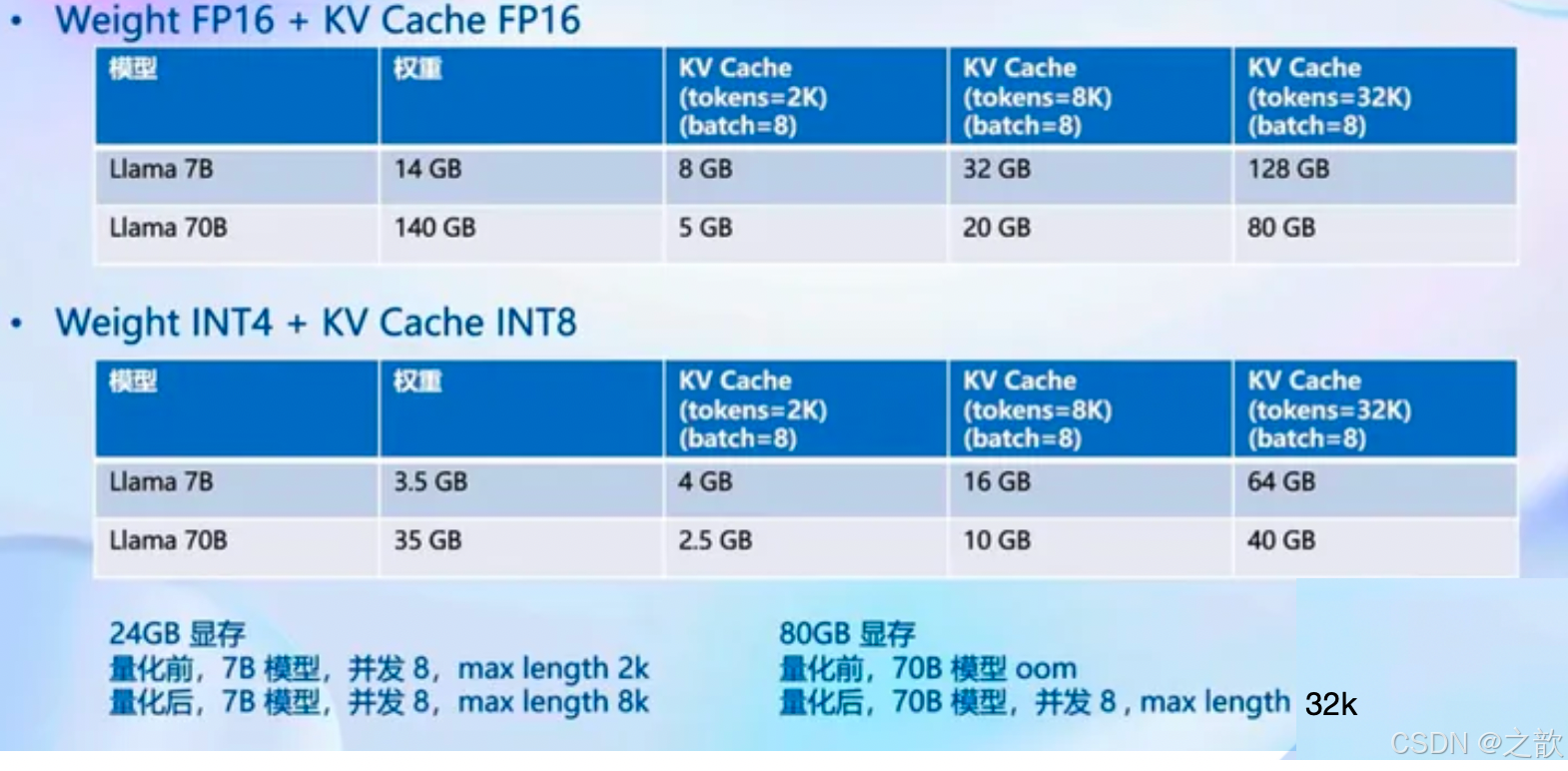
核心功能一量化
为什么要做量化?
为什么做Veight Only的量化?
- 两个基本概念
1、计算密集(compute-bound):推理的绝大部分时间消耗在数值计算上;针对计算密集场景,可
以通过使用更快的硬件计算单元来提升计算速度,比如量化为W8A8使用INT8 Tensor Core来
加速计算。
2、访存密集(memory-bound):推理时,绝大部分时间消耗在数据读取上;针对访存密集型场
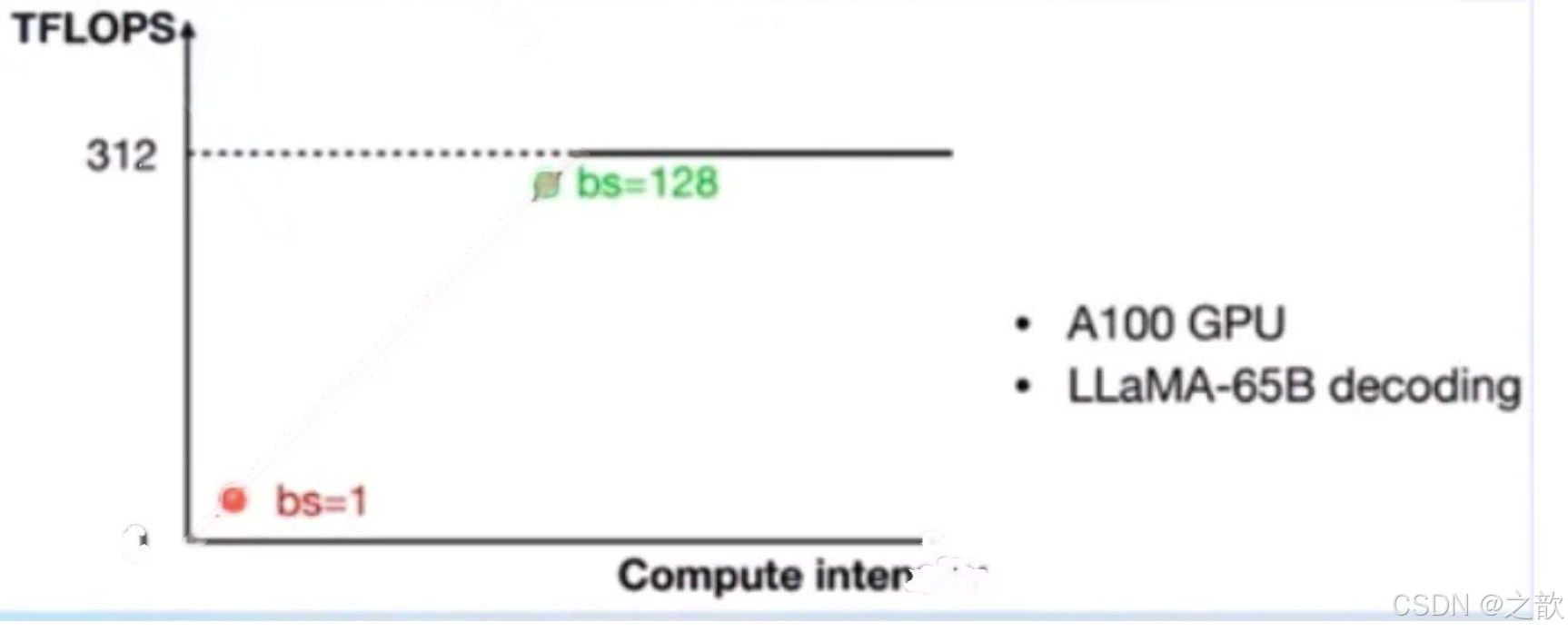
景,一般是通过提高计算访存比来提升性能。 - LLM是典型的访存密集型任务,常见的LLM模型是Decoder Only架构。推理时大部分时间消耗在逐
Token生成阶段(Decoding阶段),是典型的访存密集型场景。
如下图,A100的FP16峰值算力为312 TFLOPS,只有在Batch Size达到128这个量级时,计算才成为推理
的瓶颈,但由于LLM模型本身就很大,推理时的KV Cache也会占用很多显存,还有一些其他的因素影响
(如Persistent Batch),实际推理时很难做到128这么大的Batch Size。
- Weight Only量化一举多得
4 bit Weight Only量化,将FP16的模型权重量化为NT4,访存量直接降为FP16模型的1/4,大
幅降低了访存成本,提高了Decoding的速度。 - 加速的同时还节省了显存,同样的设备能够支持更大的模型以及更长的对话长度
如何做Weight Only的量化?
- LMDeploy使用MIT HAN LAB开源的AWQ算法,量化为4bit模型,推理时,先把4bit权重,反量化回FP16(在Kernel内部进行,从Global Memory读取时仍是4bit),依旧使用的是FP16计算
- 相较于社区使用比较多的GPTQ算法,AWQ的推理速度更快,量化的时间更短
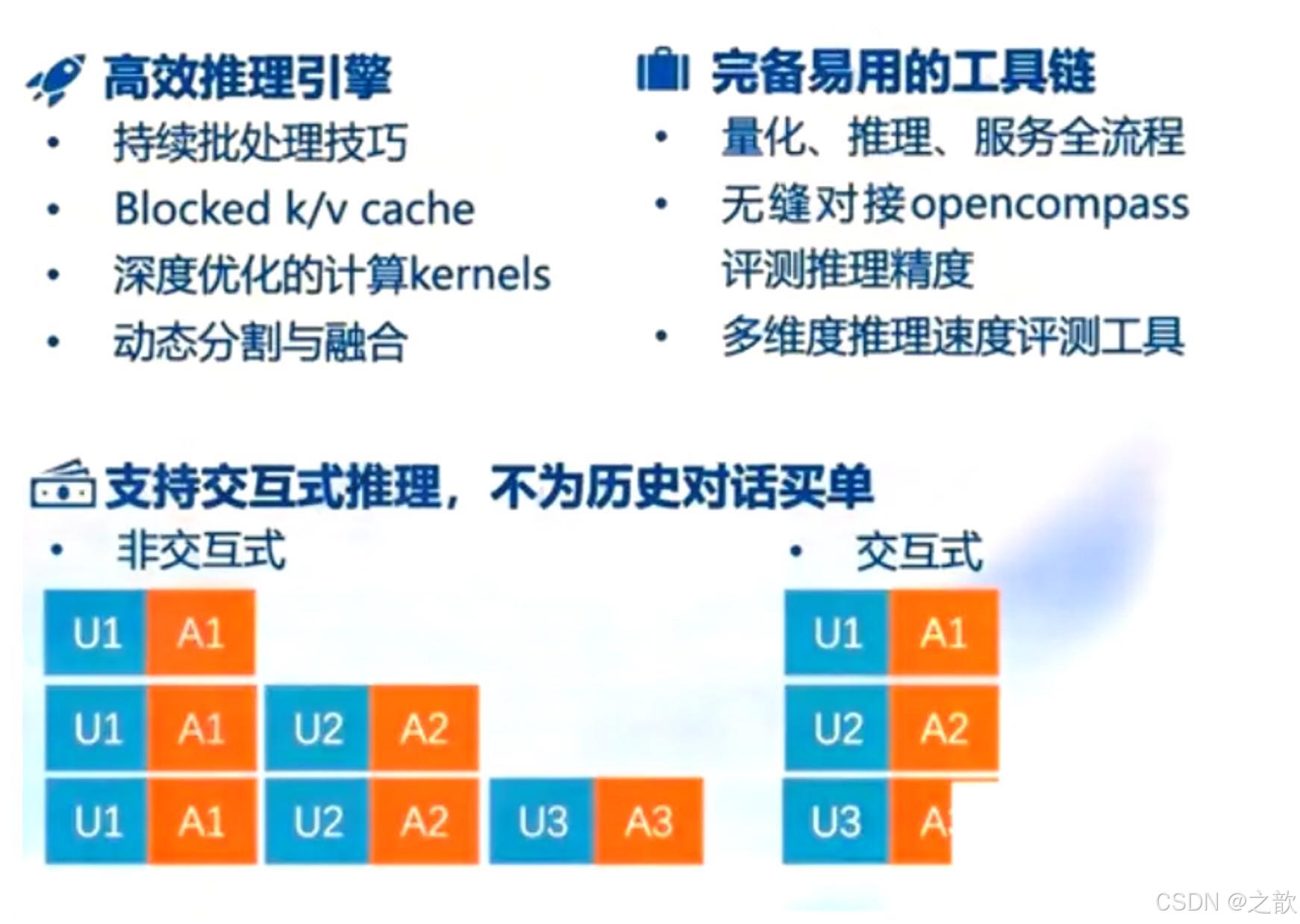
核心功能-推理引擎TurboMind
- 持续批处理
请求可以及时加入batch中推理
Batch中已经完成推的请求及时退出

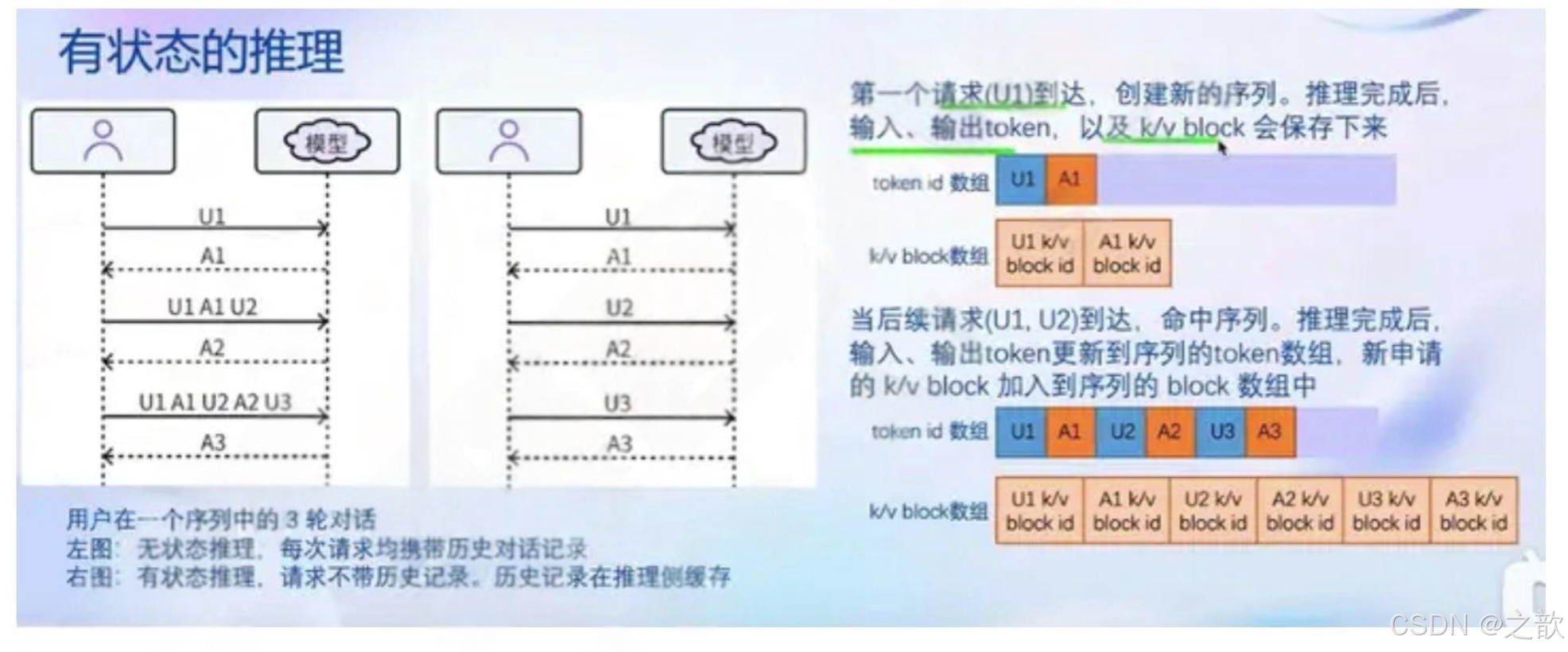
- 有状态的推理
对话token被缓存在推理侧
用户侧请求无需带上历史对话记录
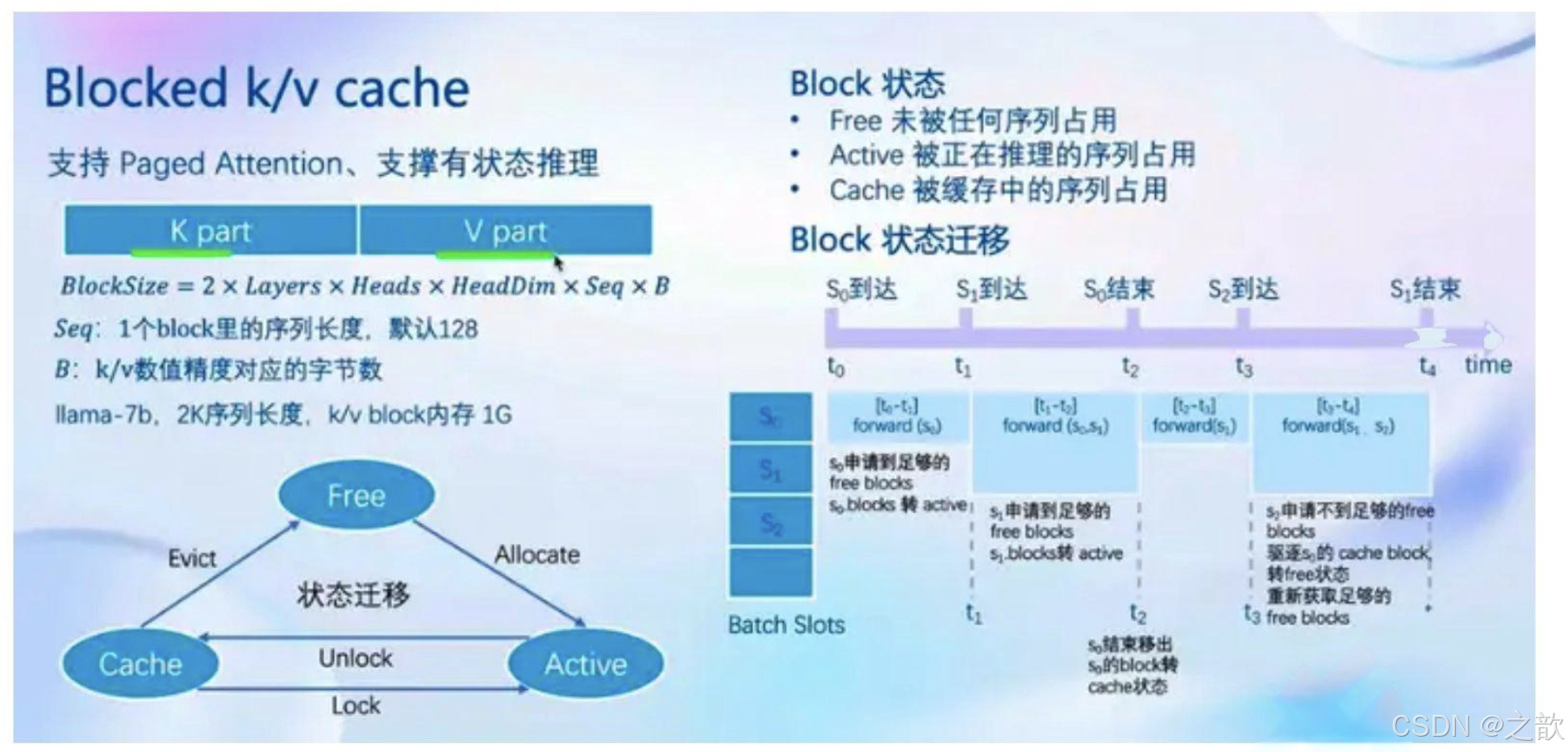
- Blocked k/v cache
Attention支持不连续的kW
block(Paged Attention)
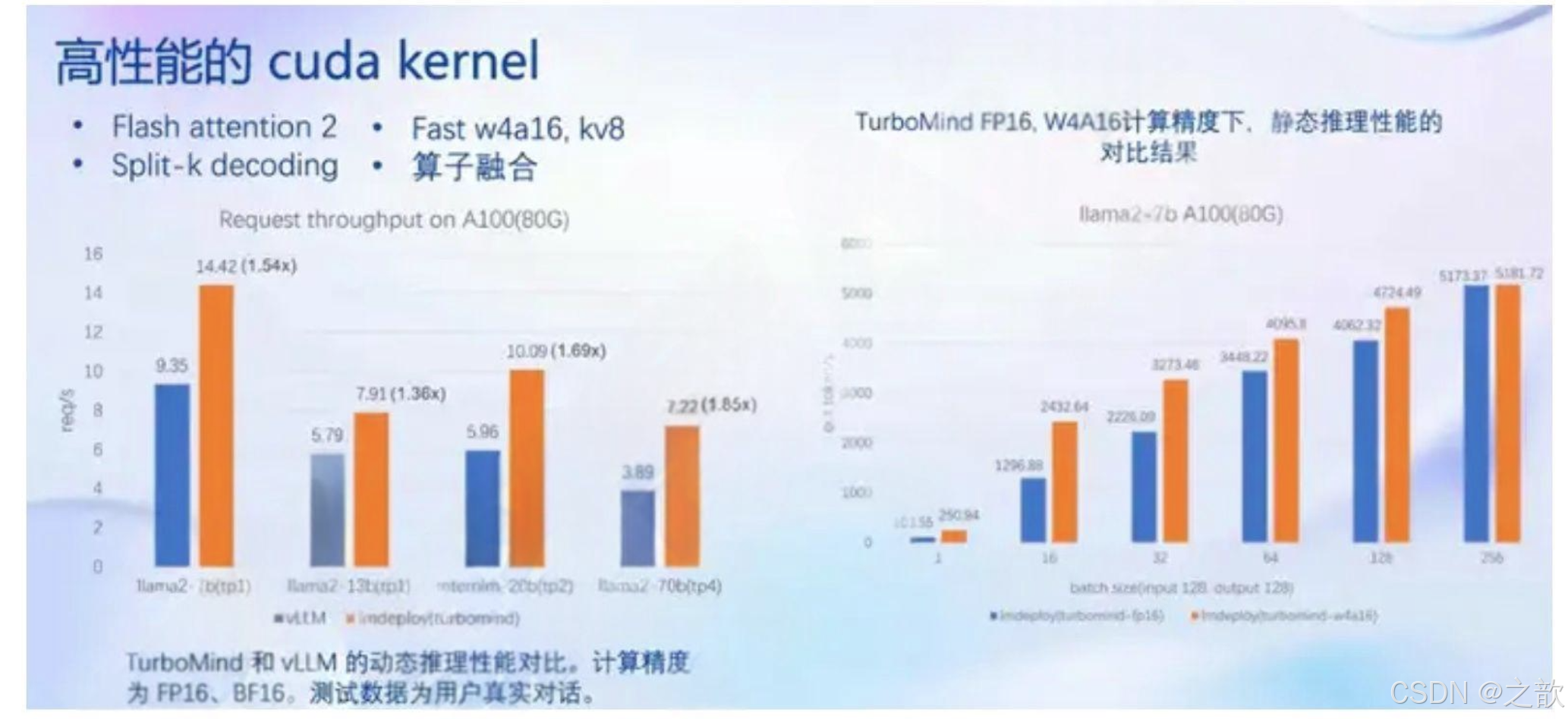
- 高性能cuda kernel
Flash Attention 2
Split-K decoding
高效的w4a16,kv8反量化kernel
核心功能-推理服务api server
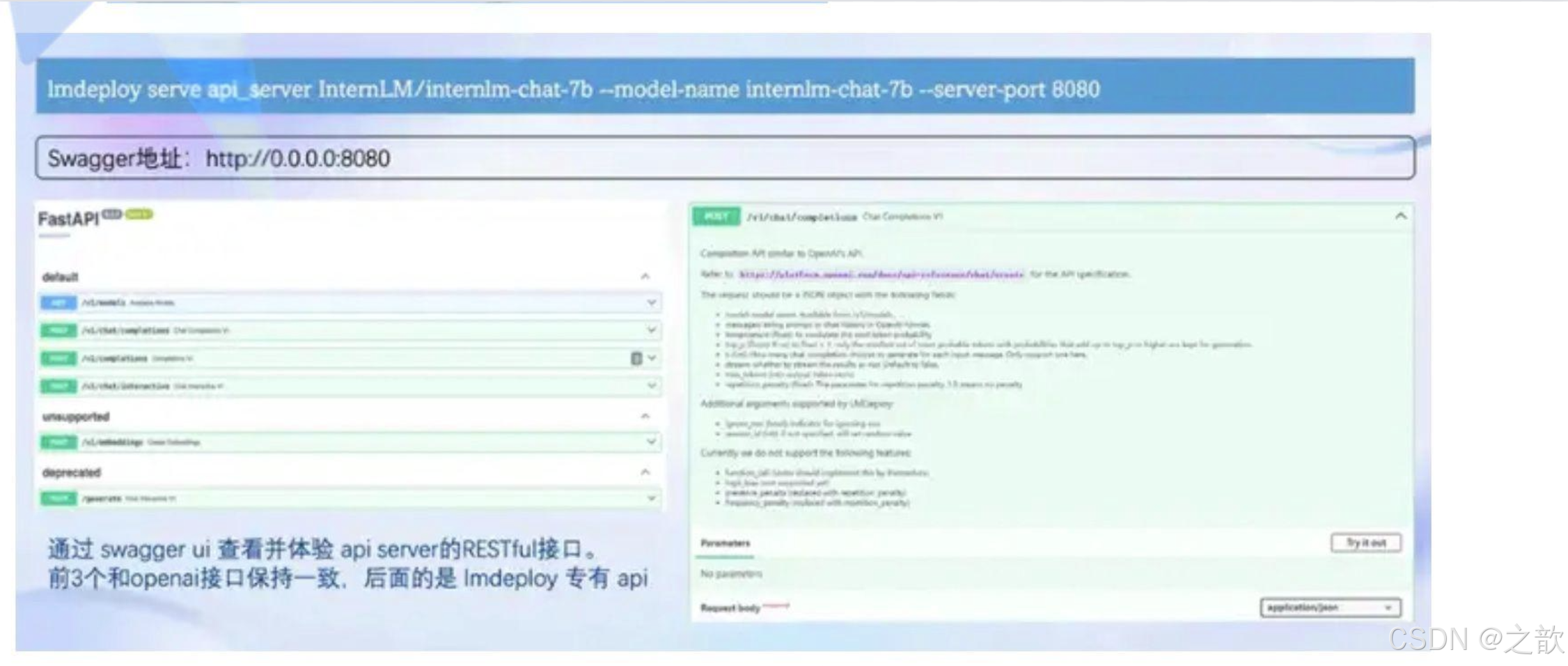
服务部署
这一部分主要涉及本地推理和部署。我们先看一张图。
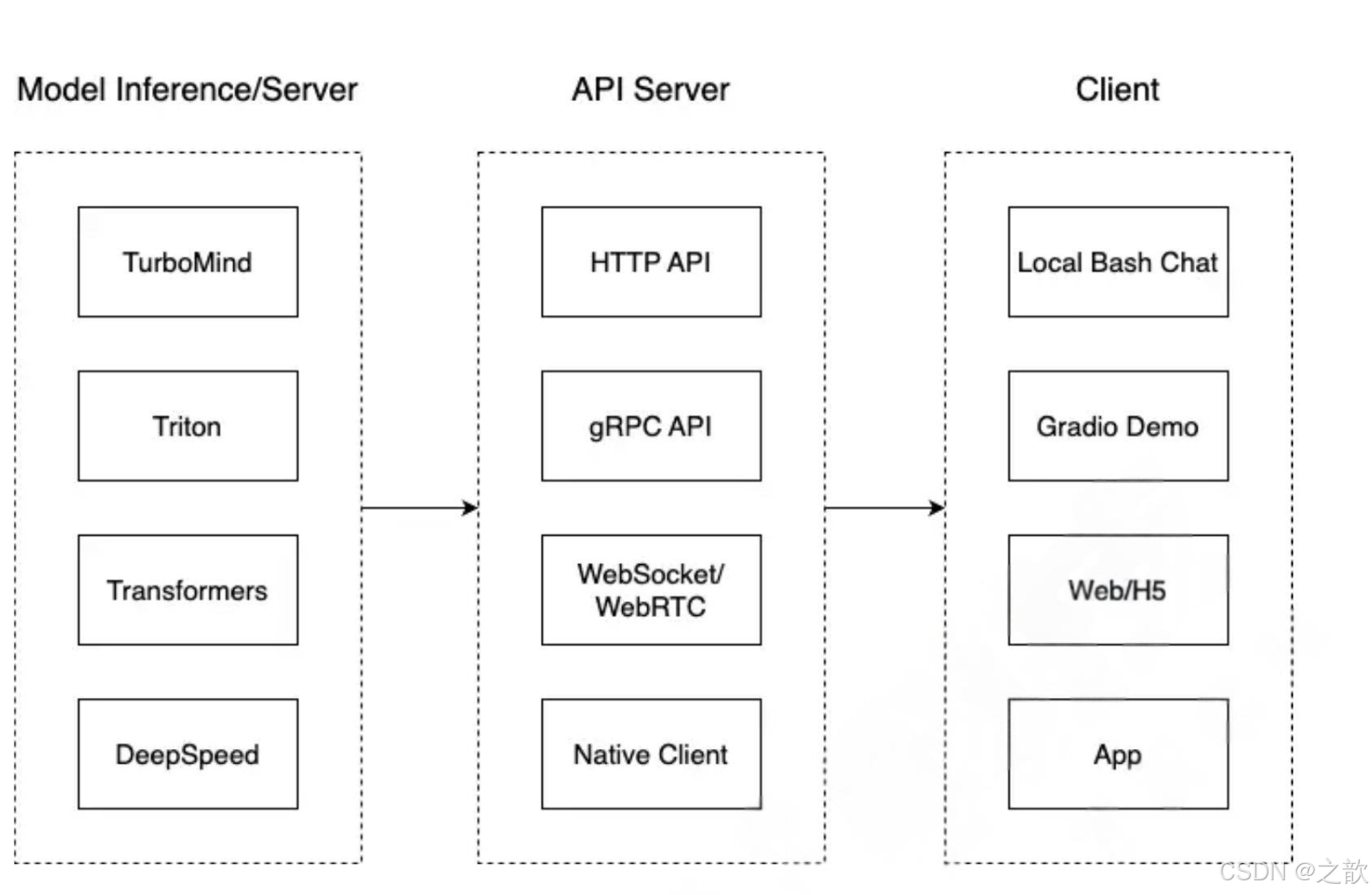
我们把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- Client。可以理解为前端,与用户交互的地方。
- API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持。 值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“APIServer”合并,有的甚至是三个流程打包在一起提供服务。
模型转换与合并
模型转换
训练后的pth格式参数转Hugging Face格式
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
例如:
xtuner convert pth_to_hf ./internlm2_5_chat_7b_qlora_oasst1_e3.py
./work_dirs/internlm_chat_7b_qlora_oasst1_e3/iter_1050.pth ./hf
将base模型与LORA模型合并
xtuner convert merge $NAME_OR_PATH_TO_LLM $NAME_OR_PATH_TO_ADAPTER $SAVE_PATH –
max-shard-size 2GB
例如:
xtuner convert merge ./internlm2_5-7b-chat ./hf ./merged --max-shard-size 2GB
与合并后的模型对话
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
LMDeploy的分布式推理实现
对量化前的模型部署验证
查询/root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat的config.json文件可知,该模型的权重被存储为bfloat16格式:
{
“architectures”: [
“Qwen2ForCausalLM”
],
“attention_dropout”: 0.0,
“bos_token_id”: 151643,
“eos_token_id”: 151645,
“hidden_act”: “silu”,
“hidden_size”: 1024,
“initializer_range”: 0.02,
“intermediate_size”: 2816,
“max_position_embeddings”: 32768,
“max_window_layers”: 21,
“model_type”: “qwen2”,
“num_attention_heads”: 16,
“num_hidden_layers”: 24,
“num_key_value_heads”: 16,
“rms_norm_eps”: 1e-06,
“rope_theta”: 1000000.0,
“sliding_window”: 32768,
“tie_word_embeddings”: true,
“torch_dtype”: “bfloat16”,
“transformers_version”: “4.37.0”,
“use_cache”: true,
“use_sliding_window”: false,
“vocab_size”: 151936
}
对于一个7B(70亿)参数的模型,每个参数使用 16位浮点数(等于 2个 Byte)表示,则模型的权重大
小约为:
70×10^9 parameters×2 Bytes/parameter=14GB
70亿个参数×每个参数占用2个字节=14GB
所以我们需要大于14GB的显存。
- 创建环境,安装依赖
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
#以上基础环境有的可以忽略
#安装lmdeploy及其依赖
pip install timm==1.0.8 openai==1.40.3 lmdeploy[all]==0.5.3
https://blog.csdn.net/shw384348082/article/details/147055032 <CondaError: Run ‘conda init‘ before ‘conda activate‘ 解决方案>
启动项目
#lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat --quant-policy 8
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat --tp 2 # 指定多张显卡
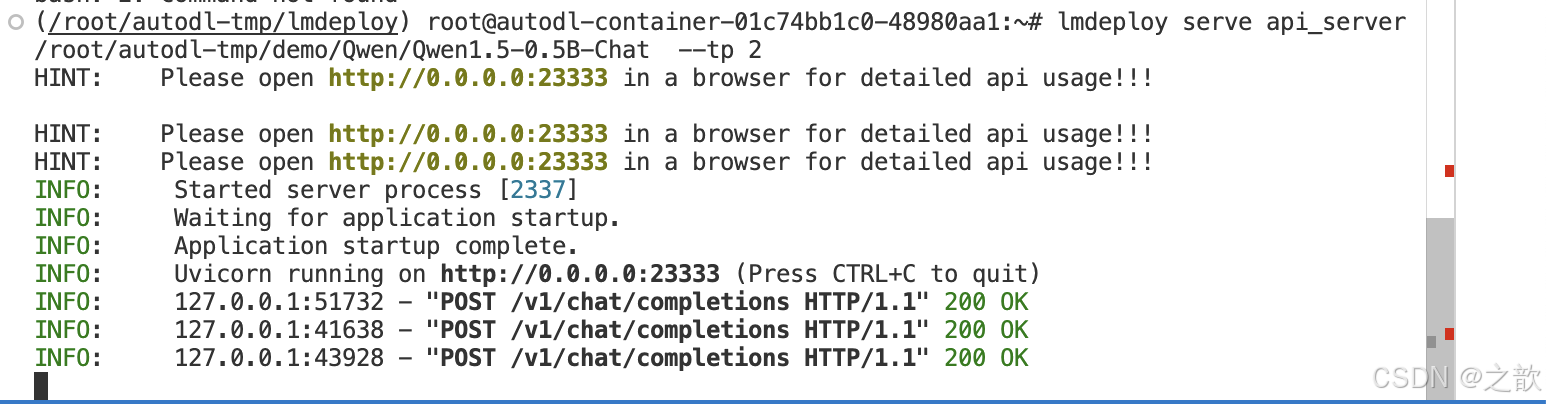

#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答 你是try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()
输出:
使用LMdeploy 验证模型
在量化工作正式开始前,我们还需要验证一下获取的模型文件能否正常工作。进入创建好的环境并启动
https://www.modelscope.cn/models/Shanghai_AI_Laboratory/internlm2_5-7b-chat
mkdir -p /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat
cd /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat
modelscope download --model Shanghai_AI_Laboratory/internlm2_5-7b-chat --local_dir ./
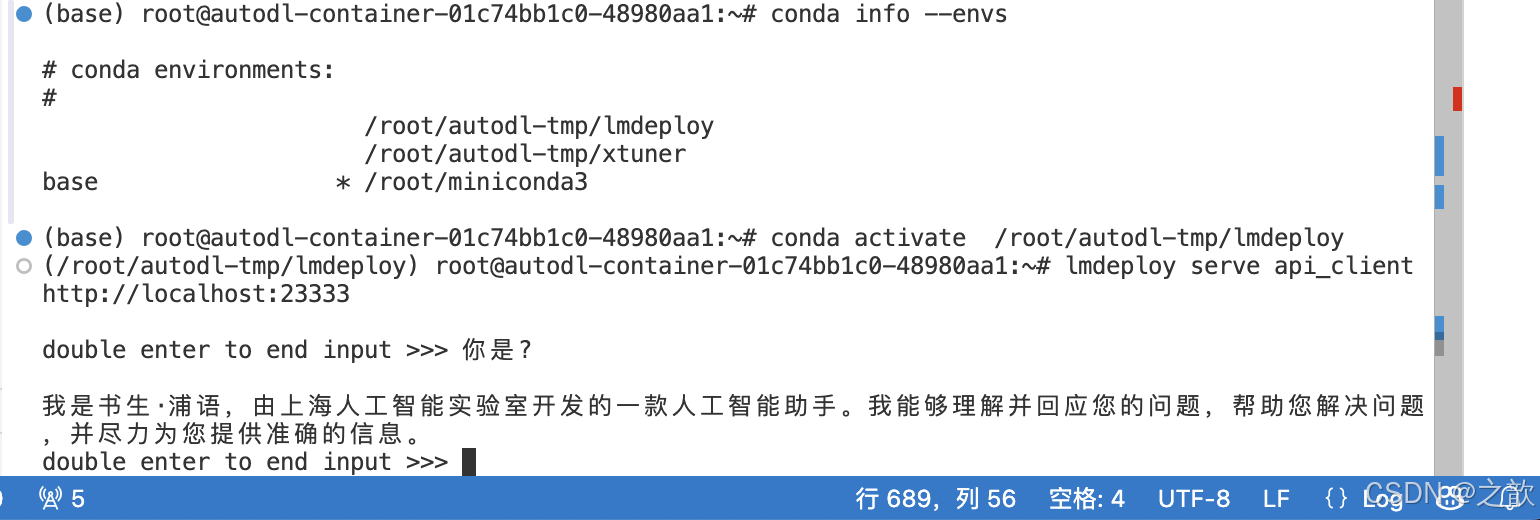
lmdeploy chat /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat
LMDeploy部署/量化InternLM2.5
- InternLM2.5部署
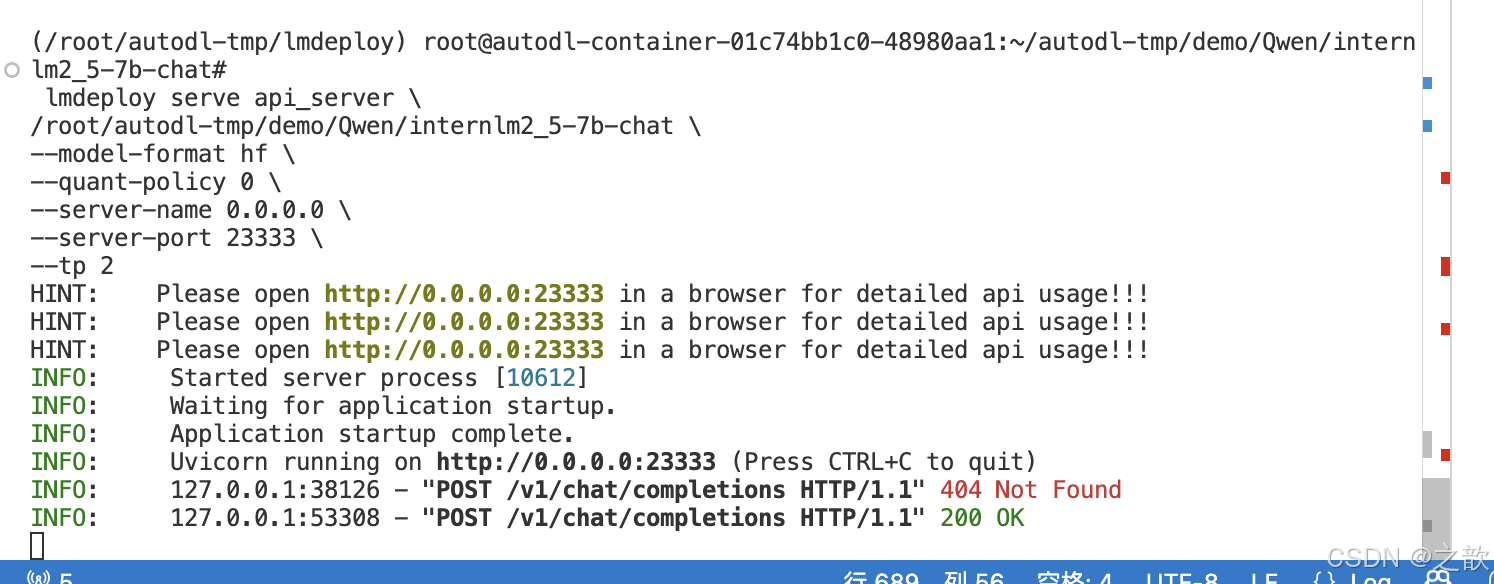
lmdeploy serve api_server \/root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 2
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答 你是try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()
输出:

命令说明:
lmdeploy serve api_server:这个命令用于启动API服务器。
/root/models/internlm2_5-7b-chat:这是模型的路径。
–model-format hf:这个参数指定了模型的格式。hf代表“Hugging Face”格式。
–quant-policy 0:这个参数指定了量化策略。
–server-name 0.0.0.0:这个参数指定了服务器的名称。在这里,0.0.0.0是一个特殊的IP地址,它表
示所有网络接口。
–server-port 23333:这个参数指定了服务器的端口号。在这里,23333是服务器将监听的端口号。
–tp 1:这个参数表示并行数量(GPU数量)。
启动完成日志输出
访问 http://127.0.0.1:23333/ ,可以看到API 信息
以命令行形式连接API服务器
lmdeploy serve api_client http://localhost:23333
LMDeploy Lite
随着模型变得越来越大,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。LMDeploy 提供了权重量化和 k/v cache两种策略。
- 设置最大kv cache缓存大小
kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,kv cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache全部存储于显存,以加快访存速度。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy的kv cache管理器可以通过设置–cache-max-entry-count参数,控制kv缓存占用剩余显存的最大比例。默认的比例为0.8。
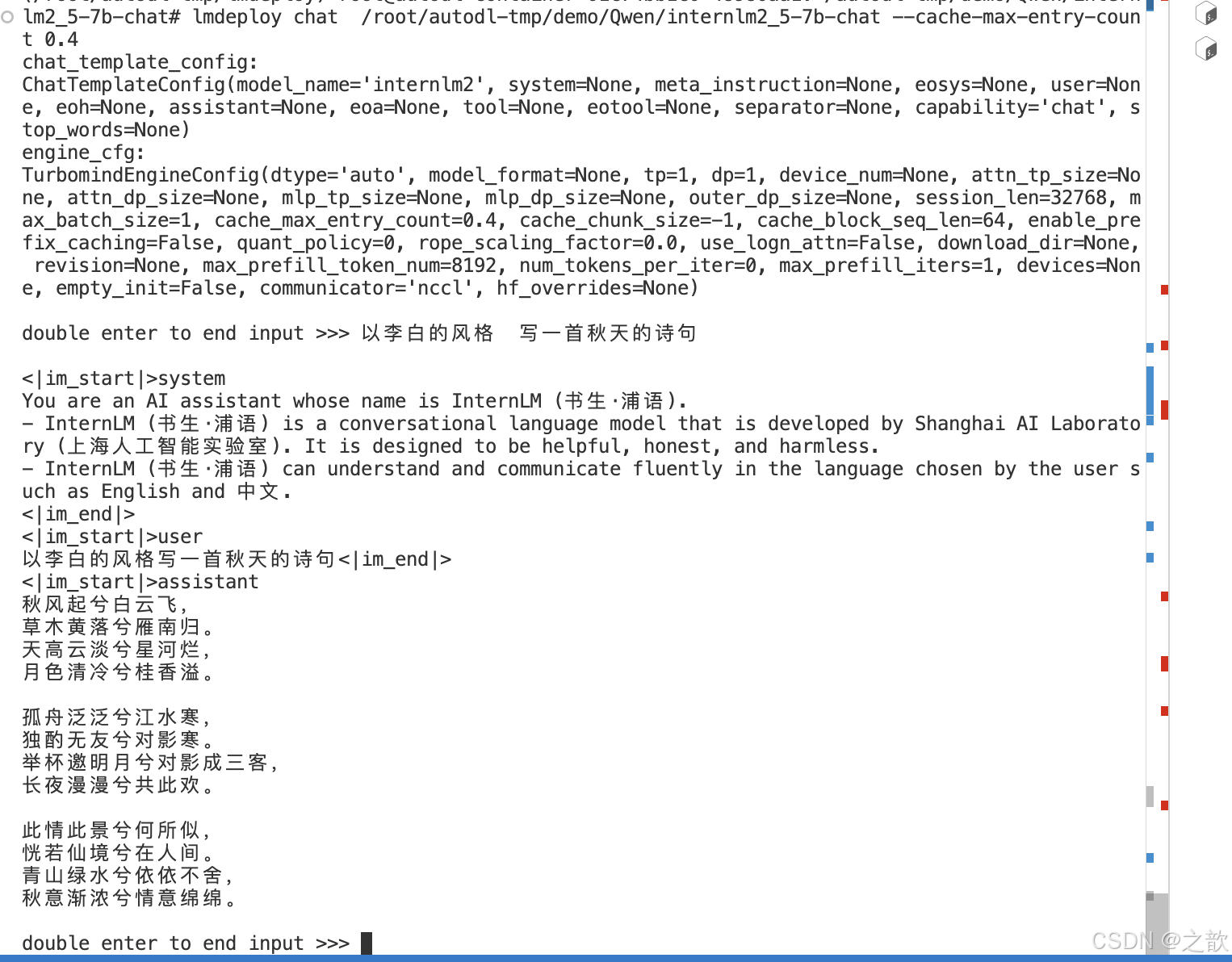
设置kv 最大比例为0.4,执行如下命令:
lmdeploy chat /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat --cache-max-entry-count 0.4
- 设置在线 kv cache int4/int8 量化
自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy和 cache-max-entry-count参数。目前,LMDeploy 规定 qant_policy=4表示 kv int4 量化, quant_policy=8表示 kv int8量化。
lmdeploy serve api_server \/root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 4 \
--cache-max-entry-count 0.8 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 2
相比使用BF16精度的kv cache,int4的Cache可以在相同4GB的显存下只需要4位来存储一个数值,而BF16需要16位。这意味着int4的Cache可以存储的元素数量是BF16的四倍。
- W4A16 模型量化和部署
准确说,模型量化是一种优化技术,旨在减少机器学习模型的大小并提高其推理速度。量化通过将模型的权重和激活从高精度(如16位浮点数)转换为低精度(如8位整数、4位整数、甚至二值网络)来实现。
那么标题中的W4A16又是什么意思呢?
- W4:这通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16,Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。
- A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
因此,W4A16的量化配置意味着:
- 权重被量化为4位整数。
- 激活保持为16位浮点数。
在最新的版本中,LMDeploy使用的是AWQ算法,能够实现模型的4bit权重量化。输入以下指令,执行量化工作。(本步骤耗时较长,请耐心等待)
lmdeploy lite auto_awq \/root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--work-dir /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat-w4a16-4bit
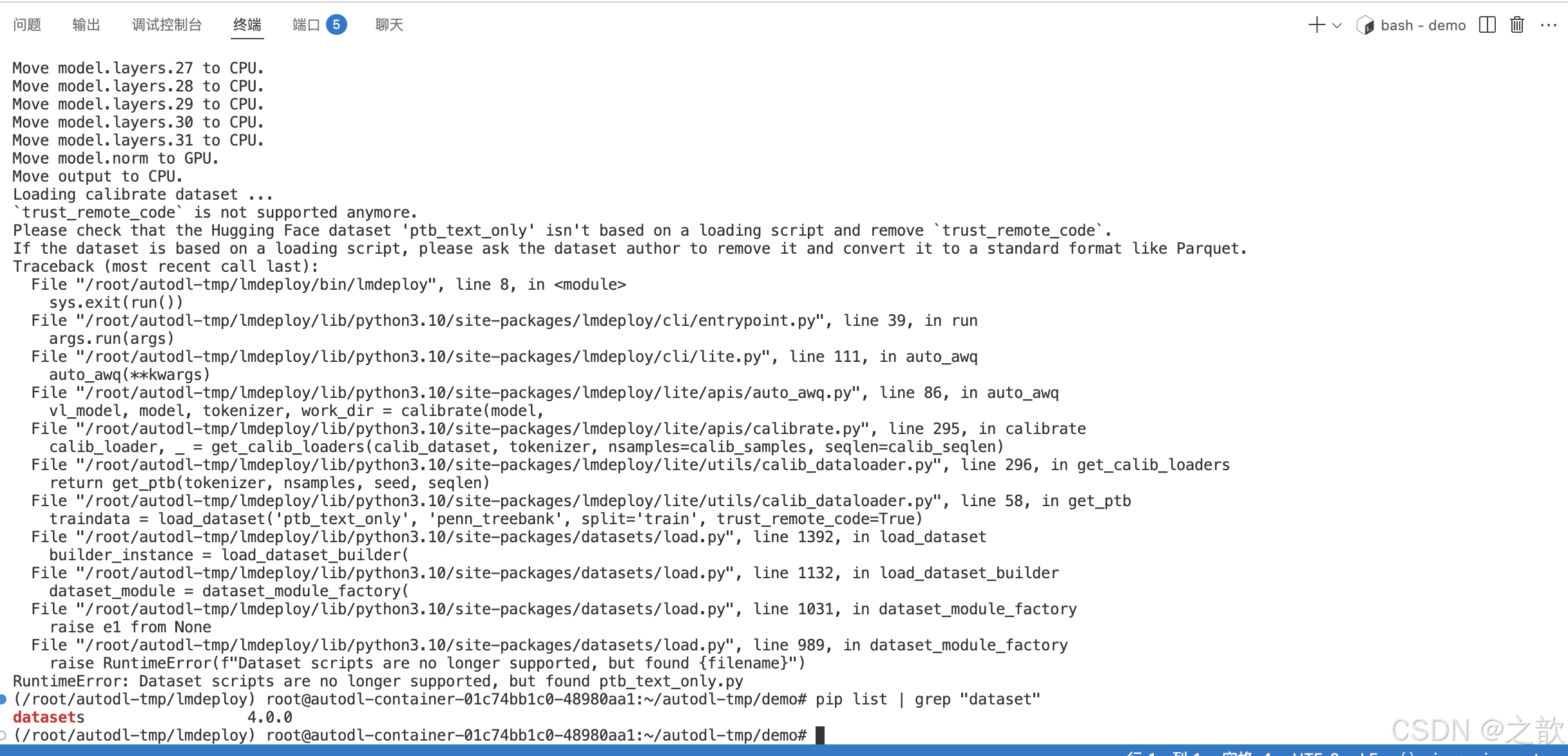
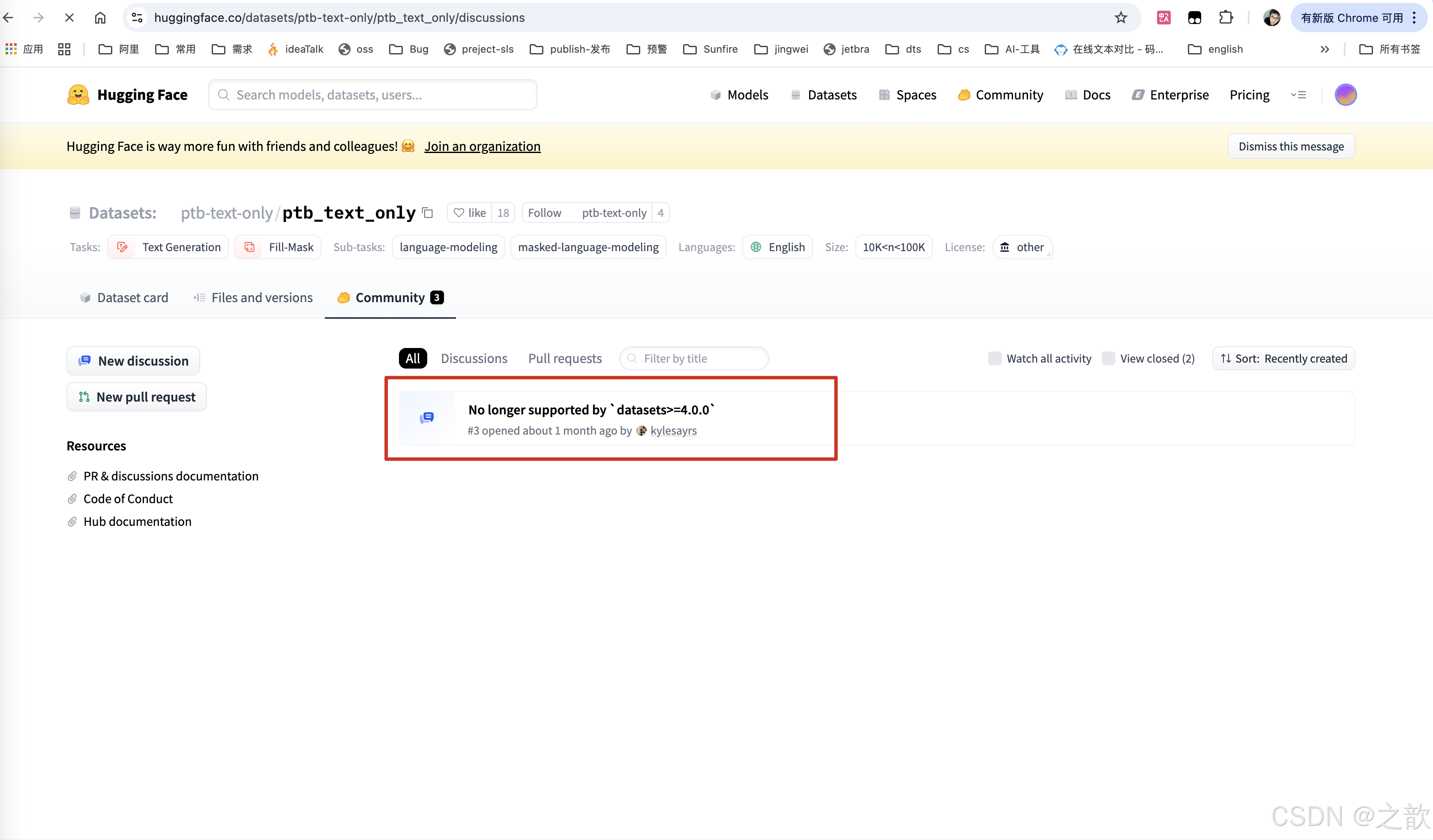
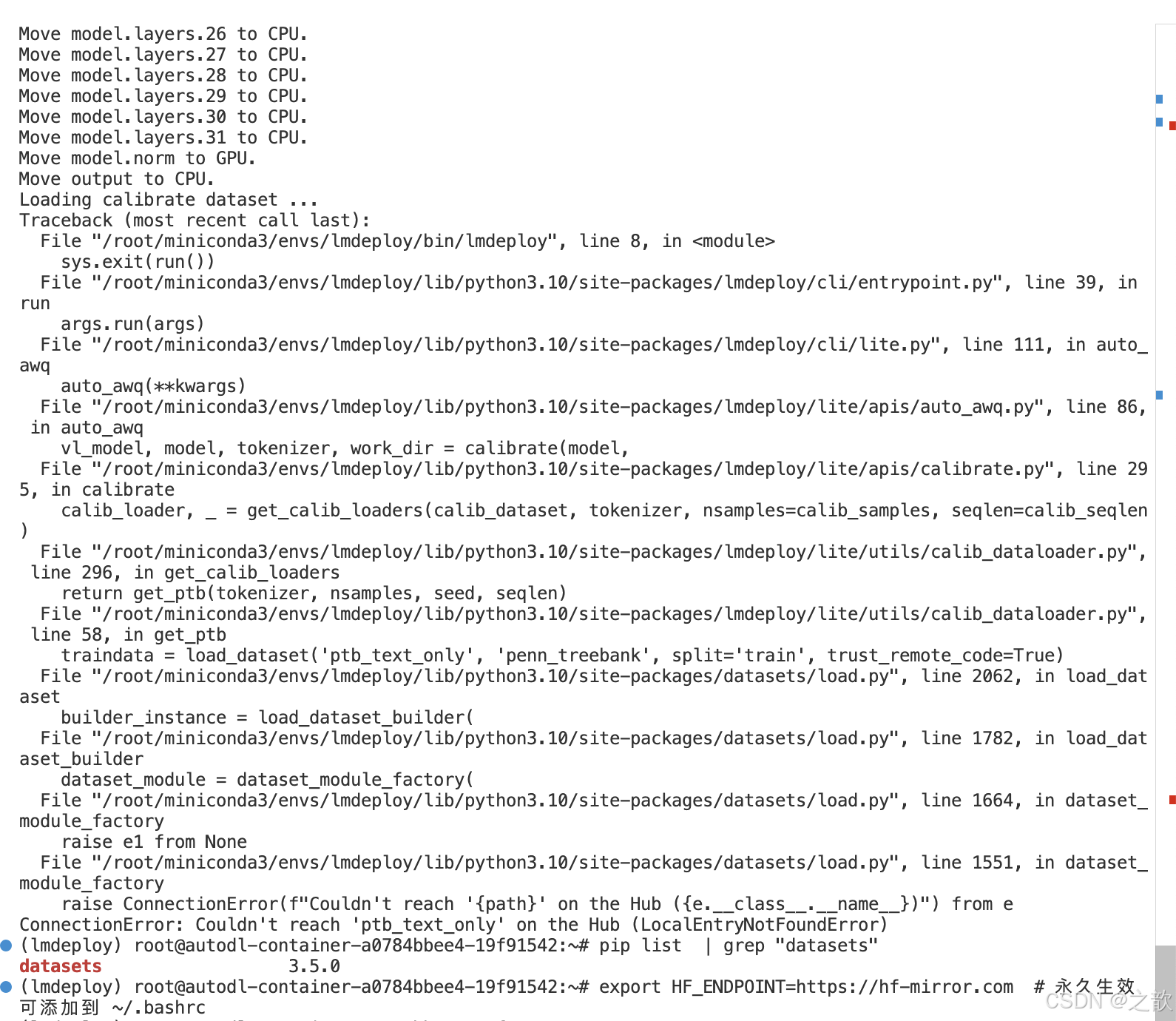
注意: 在启动过程中可能会报如下错误,
我找到了一篇文章 并不支持datasets 4.0.0 以上的版本
解决办法 :这里将之前环境的python包的脚本导出一份
即使降低版本也可能存在另外一个错误
export HF_ENDPOINT=https://hf-mirror.com # 指定国内的huggingface境像, 永久生效 可添加到 ~/.bashrc
datasets目录:
~/.cache/huggingface/datasets
如果遇到问题,这里有一篇文章可以参考 :
https://github.com/InternLM/lmdeploy/issues/1142
from datasets import load_dataset
traindata = load_dataset('ptb_text_only', 'penn_treebank', split='train')
运行上面代码
会多出一个 /root/.cache/huggingface/datasets/downloads 文件
mv /root/.cache/huggingface/datasets/downloads /root/.cache/huggingface/datasets/ptb_text_only
即可
当然,在huggingface 中 ptb 数据集 很难下载 ,可以使用另外一个方法 ,下载其他数据集 。
从 LLaMA获取数据集, git clone https://github.com/hiyouga/LLaMA-Factory.git
LMDeploy 环境依赖
accelerate==1.6.0
addict==2.4.0
aiohappyeyeballs==2.6.1
aiohttp==3.11.16
aiosignal==1.3.2
airportsdata==20250224
annotated-types==0.7.0
anyio==4.9.0
async-timeout==5.0.1
attrs==25.3.0
certifi==2025.1.31
charset-normalizer==3.4.1
click==8.1.8
cloudpickle==3.1.1
datasets==3.5.0
dill==0.3.8
diskcache==5.6.3
distro==1.9.0
einops==0.8.1
exceptiongroup==1.2.2
fastapi==0.115.12
filelock==3.18.0
fire==0.7.0
frozenlist==1.5.0
fsspec==2024.12.0
genson==1.3.0
h11==0.14.0
httpcore==1.0.7
httpx==0.28.1
huggingface-hub==0.30.1
idna==3.10
interegular==0.3.3
iso3166==2.1.1
Jinja2==3.1.6
jiter==0.9.0
jsonschema==4.23.0
jsonschema-specifications==2024.10.1
lark==1.2.2
llvmlite==0.44.0
lmdeploy==0.7.1
markdown-it-py==3.0.0
MarkupSafe==3.0.2
mdurl==0.1.2
mmengine-lite==0.10.7
mpmath==1.3.0
msgpack==1.1.0
multidict==6.3.2
multiprocess==0.70.16
nest-asyncio==1.6.0
networkx==3.4.2
numba==0.61.0
numpy==1.26.4
nvidia-cublas-cu12==12.4.5.8
nvidia-cuda-cupti-cu12==12.4.127
nvidia-cuda-nvrtc-cu12==12.4.127
nvidia-cuda-runtime-cu12==12.4.127
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.2.1.3
nvidia-curand-cu12==10.3.5.147
nvidia-cusolver-cu12==11.6.1.9
nvidia-cusparse-cu12==12.3.1.170
nvidia-ml-py==12.570.86
nvidia-nccl-cu12==2.21.5
nvidia-nvjitlink-cu12==12.4.127
nvidia-nvtx-cu12==12.4.127
openai==1.70.0
outlines==0.0.46
outlines_core==0.1.26
packaging==24.2
pandas==2.2.3
partial-json-parser==0.2.1.1.post5
peft==0.14.0
pillow==11.1.0
platformdirs==4.3.7
propcache==0.3.1
protobuf==6.30.2
psutil==7.0.0
pyairports==2.1.1
pyarrow==19.0.1
pycountry==24.6.1
pydantic==2.11.2
pydantic_core==2.33.1
Pygments==2.19.1
pynvml==12.0.0
python-dateutil==2.9.0.post0
pytz==2025.2
PyYAML==6.0.2
ray==2.44.1
referencing==0.36.2
regex==2024.11.6
requests==2.32.3
rich==14.0.0
rpds-py==0.24.0
safetensors==0.5.3
sentencepiece==0.2.0
shortuuid==1.0.13
six==1.17.0
sniffio==1.3.1
starlette==0.46.1
sympy==1.13.1
termcolor==3.0.1
tiktoken==0.9.0
tokenizers==0.21.1
tomli==2.2.1
torch==2.5.1
torchvision==0.20.1
tqdm==4.67.1
transformers==4.51.0
triton==3.1.0
typing-inspection==0.4.0
typing_extensions==4.13.1
tzdata==2025.2
urllib3==2.3.0
uvicorn==0.34.0
xxhash==3.5.0
yapf==0.43.0
yarl==1.19.0
vLLM环境依赖
aiohappyeyeballs==2.6.1
aiohttp==3.11.16
aiosignal==1.3.2
airportsdata==20250224
annotated-types==0.7.0
anyio==4.9.0
astor==0.8.1
attrs==25.3.0
blake3==1.0.4
cachetools==5.5.2
certifi==2025.1.31
charset-normalizer==3.4.1
click==8.1.8
cloudpickle==3.1.1
compressed-tensors==0.9.2
cupy-cuda12x==13.4.1
depyf==0.18.0
dill==0.3.9
diskcache==5.6.3
distro==1.9.0
dnspython==2.7.0
einops==0.8.1
email_validator==2.2.0
fastapi==0.115.12
fastapi-cli==0.0.7
fastrlock==0.8.3
filelock==3.18.0
frozenlist==1.5.0
fsspec==2025.3.2
gguf==0.10.0
h11==0.14.0
hf-xet==1.0.2
httpcore==1.0.7
httptools==0.6.4
httpx==0.28.1
huggingface-hub==0.30.1
idna==3.10
importlib_metadata==8.6.1
interegular==0.3.3
Jinja2==3.1.6
jiter==0.9.0
jsonschema==4.23.0
jsonschema-specifications==2024.10.1
lark==1.2.2
llguidance==0.7.13
llvmlite==0.44.0
lm-format-enforcer==0.10.11
markdown-it-py==3.0.0
MarkupSafe==3.0.2
mdurl==0.1.2
mistral_common==1.5.4
modelscope==1.24.1
mpmath==1.3.0
msgpack==1.1.0
msgspec==0.19.0
multidict==6.3.2
nanobind==2.6.1
nest-asyncio==1.6.0
networkx==3.4.2
ninja==1.11.1.4
numba==0.61.0
numpy==2.1.3
nvidia-cublas-cu12==12.4.5.8
nvidia-cuda-cupti-cu12==12.4.127
nvidia-cuda-nvrtc-cu12==12.4.127
nvidia-cuda-runtime-cu12==12.4.127
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.2.1.3
nvidia-curand-cu12==10.3.5.147
nvidia-cusolver-cu12==11.6.1.9
nvidia-cusparse-cu12==12.3.1.170
nvidia-cusparselt-cu12==0.6.2
nvidia-ml-py==12.570.86
nvidia-nccl-cu12==2.21.5
nvidia-nvjitlink-cu12==12.4.127
nvidia-nvtx-cu12==12.4.127
nvitop==1.4.2
openai==1.70.0
opencv-python-headless==4.11.0.86
outlines==0.1.11
outlines_core==0.1.26
packaging==24.2
partial-json-parser==0.2.1.1.post5
pillow==11.1.0
prometheus-fastapi-instrumentator==7.1.0
prometheus_client==0.21.1
propcache==0.3.1
protobuf==6.30.2
psutil==7.0.0
py-cpuinfo==9.0.0
pycountry==24.6.1
pydantic==2.11.2
pydantic_core==2.33.1
Pygments==2.19.1
python-dotenv==1.1.0
python-json-logger==3.3.0
python-multipart==0.0.20
PyYAML==6.0.2
pyzmq==26.4.0
ray==2.43.0
referencing==0.36.2
regex==2024.11.6
requests==2.32.3
rich==14.0.0
rich-toolkit==0.14.1
rpds-py==0.24.0
safetensors==0.5.3
scipy==1.15.2
sentencepiece==0.2.0
setuptools==75.8.0
shellingham==1.5.4
six==1.17.0
sniffio==1.3.1
starlette==0.46.1
sympy==1.13.1
tiktoken==0.9.0
tokenizers==0.21.1
torch==2.6.0
torchaudio==2.6.0
torchvision==0.21.0
tqdm==4.67.1
transformers==4.51.0
triton==3.2.0
typer==0.15.2
typing-inspection==0.4.0
typing_extensions==4.13.1
urllib3==2.3.0
uvicorn==0.34.0
uvloop==0.21.0
vllm==0.8.3
watchfiles==1.0.4
websockets==15.0.1
wheel==0.45.1
xformers==0.0.29.post2
xgrammar==0.1.17
yarl==1.19.0
zipp==3.21.0
注意,降低 datasets 的包版本 命令如下
pip uninstall datasets
pip install datasets==3.5.0 # 降低 datasets 的包版本
输出如下:
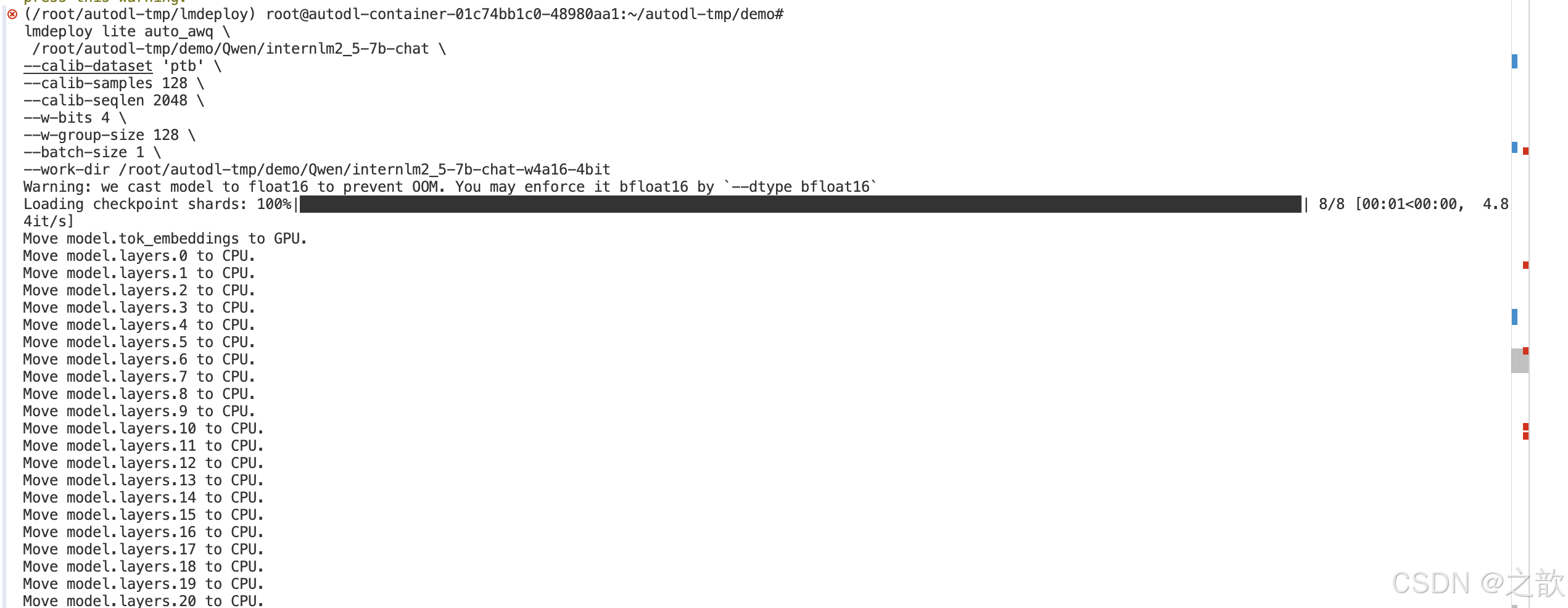
命令解释:
lmdeploy lite auto_awq: lite这是LMDeploy的命令,用于启动量化过程,而auto_awq代表自动权重量化(auto-weight-quantization)。
/root/models/internlm2_5-7b-chat: 模型文件的路径。
--calib-dataset 'ptb': 这个参数指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank,一个常用的语言模型数据集)。
--calib-samples 128: 这指定了用于校准的样本数量—128个样本
--calib-seqlen 2048: 这指定了校准过程中使用的序列长度—1024
--w-bits 4: 这表示权重(weights)的位数将被量化为4位。
--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit: 这是工作目录的路径,用于存储量化后的模型和中间结果。
等待推理完成,便可以直接在你设置的目标文件夹看到对应的模型文件。
推理后的模型和原本的模型区别是模型文件大小以及占据显存大小。
我们可以输入如下指令查看在当前目录中显示所有子目录的大小。
cd /root/models/
du -sh *
输出结果如下。(其余文件夹都是以软链接的形式存在的,不占用空间,故显示为0)
0 InternVL2-26B
0 internlm2_5-7b-chat
4.9G internlm2_5-7b-chat-w4a16-4bit
(lmdeploy) root@intern-studio-50009084:~/models#
那么原模型大小呢?输入以下指令查看。
cd /root/autodl-tmp/demo/Qwen
du -sh *
执行结果如下:

对比发现,模型的大小15G 和 4.9G ,差异还是比较大。可以输入下面的命令启动量化后的模型
lmdeploy chat /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat-w4a16-4bit/ --model-format awq

W4A16 量化+ KV cache+KV cache 量化
输入以下指令,让我们同时启用量化后的模型、设定kv cache占用和kv cache int4量化。
lmdeploy serve api_server \
/root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
离线转换TurboMind 格式
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式,如下所示。
转换模型(FastTransformer格式) TurboMind
在线加载方式
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat --model-name chat2_5 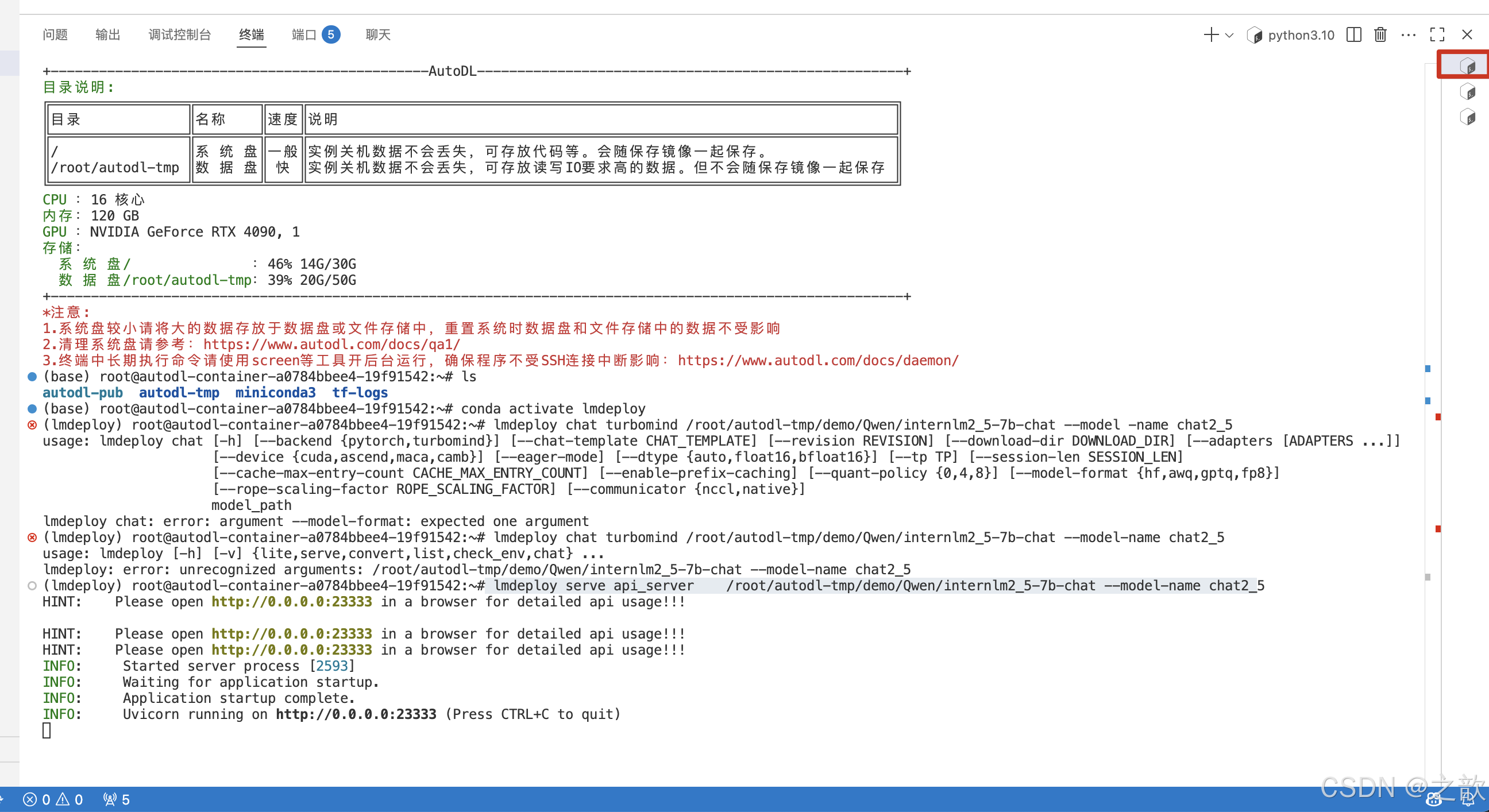
lmdeploy chat chat2_5

lmdeploy convert internlm2_5-7b-chat /root/autodl-tmp/demo/Qwen/internlm2_5-7b-chat
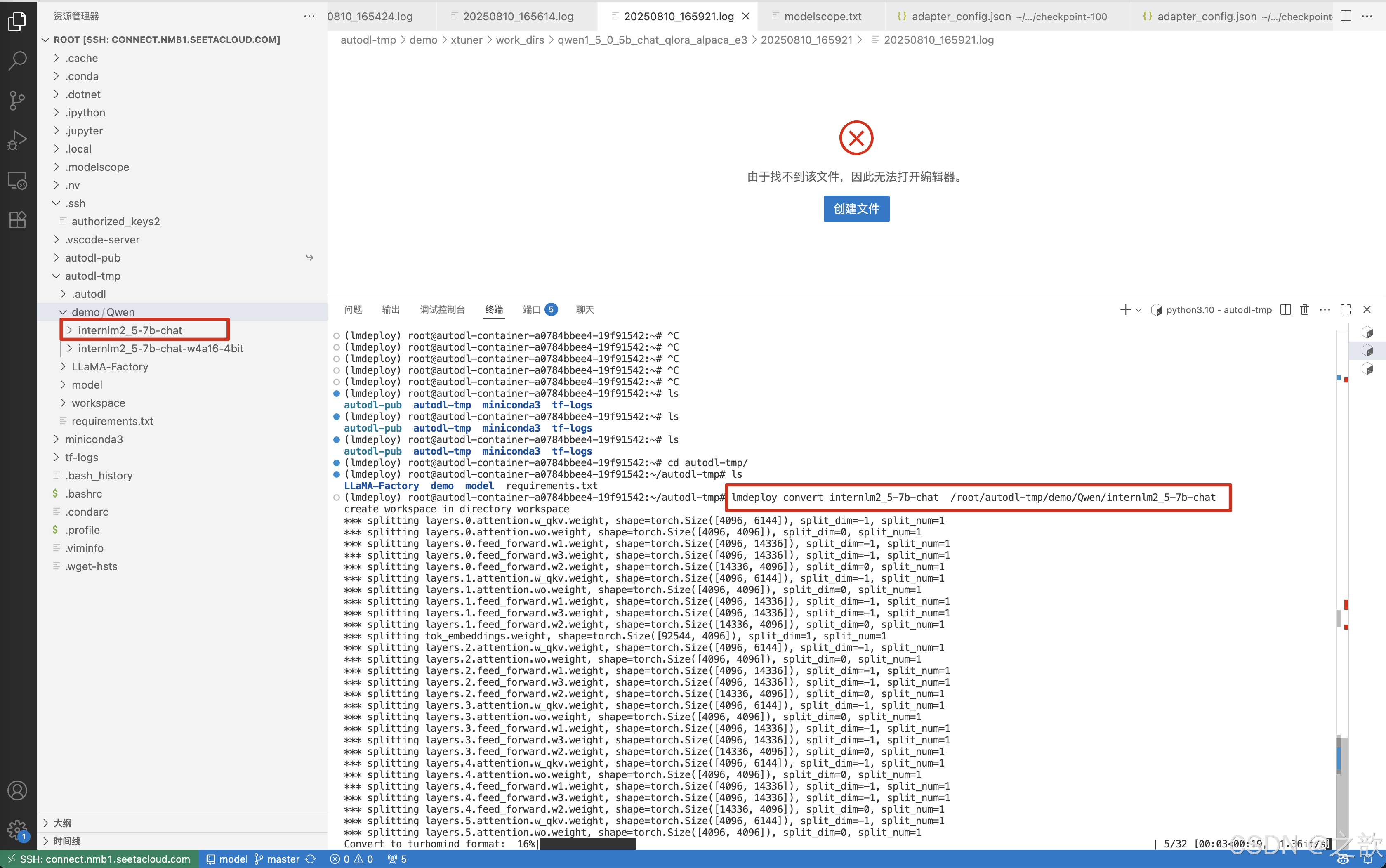
会在/root/autodl-tmp目录生成一个workspace的文件夹 。
执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton
“模型推理”需要到的文件。
目录如下图所示。
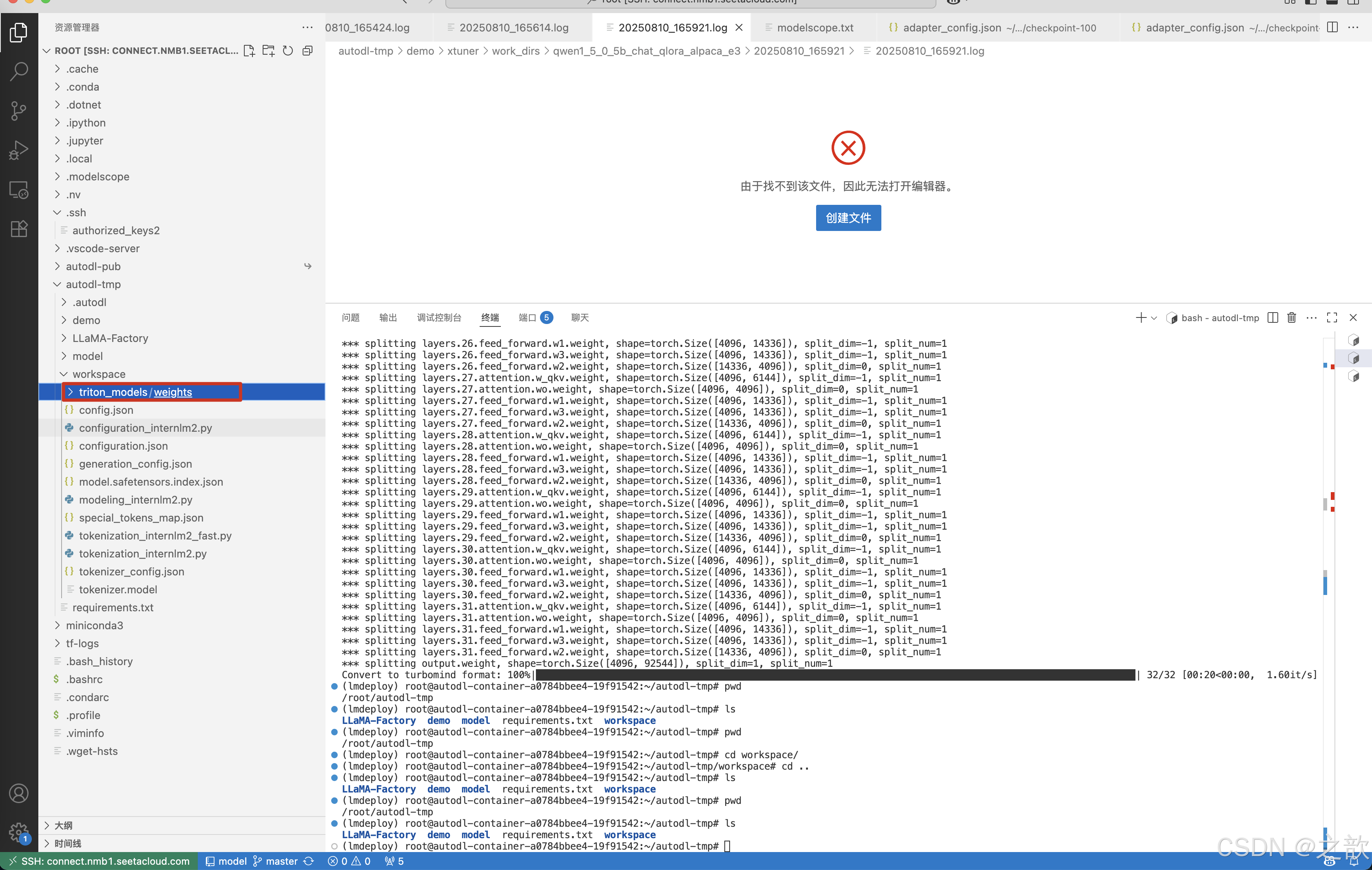
weights 和 tokenizer 目录分别放的是拆分后的参数和 Tokenizer。如果我们进一步查看 weights
的目录,就会发现参数是按层和模块拆开的,如下图所示。
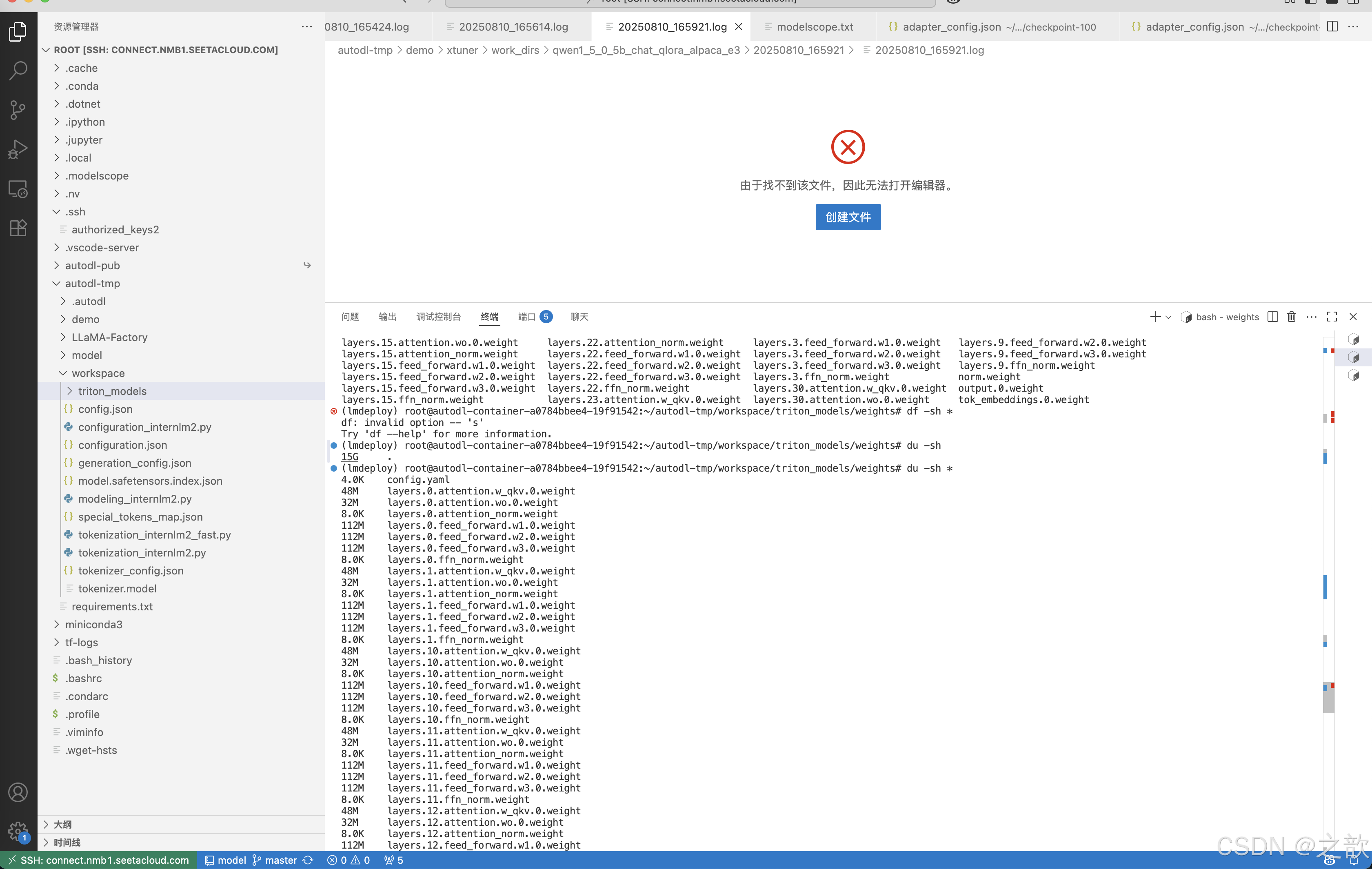
每一份参数第一个 0 表示“层”的索引,后面的那个0表示 Tensor 并行的索引,因为我们只有一张卡,所以被拆分成 1 份。如果有两张卡可以用来推理,则会生成0和1两份,也就是说,会把同一个参数拆成两份。比如 layers.0.attention.w_qkv.0.weight 会变成 layers.0.attention.w_qkv.0.weight和 layers.0.attention.w_qkv.1.weight。执行 lmdeploy convert 命令时,可以通过 --tp 指定(tp 表示 tensor parallel,该参数默认值为1也就是一张卡)。
TurboMind 推理+命令行本地对话
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。我们可以尝试本地对话,在这里其实是跳过 API Server 直接调用 TurboMind执行命令如下。
lmdeploy chat ./workspace
启动后就可以和它进行对话了。
网页 Demo 演示
lmdeploy serve api_server ./workspace

这一部分主要是将 Gradio 作为前端 Demo 演示。
pip install gradio
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333
结果如下图所示。
大模型评估框架
OpenCompass模型评估
什么是OpenCompass?
OpenCompass 是一个开源项目,旨在机器学习和自然语言处理领域提供多功能、易于使用的工具和框架。其中包含的多个开源模型和开源数据集(BenchMarks),方便进行模型的效果评测。
生成式大模型的评估指标
核心评估指标
OpenCompass支持以下主要评估指标,覆盖生成式大模型的多样化需求:
准确率(Accuracy):田于选择题或分类任务工通过比对生成结果与标准答案计算正确率。在OpenCompass中
通过metric=Accuracy配置困惑度(Perplexity,PPL):衡量模型对候选答案的预测能力,适用于选择愿评估。需使用ppl类型的数据集配置(如ceval_ppl)
生成质量(GEN):通过文本生成结果提取答案,需结合后处理脚本解析输出。使用gen类型的数据集(如ceval_gen),配置metric=gen并指定后处理规则
ROUGE/LCS:用于文本生成任务的相似度评估,需安装rouge==1.0.1依焕,并在数据配置中设置metric=rouge
条件对数概率(CLP):结合上下文计算答案的条件概率,适用于复杂推理任务,需在模型配置中启用use_logprob=True
Open Compass框架介绍
支持的开源评估数据集及使用差异
主流开源数据集
OpenCompass内置超过70个数据集,覆盖五大能力维度:
知识类:C-Eval(中文考试题)、CMMLU(多语言知识问答)、MMLU(英文多逃题)。
推理类:GSM8K(数学推理)、BBH(复杂推理链)。
语言类:CLUE(中文理解)、AFQMC(语义相似度)。
代码类:HumanEval(代码生成)、MBPP(编程问题)。
多模态类:MMBench(图像理解)、SBED-Bench(多模态问答)。
数据集区别与选择
-
评估范式差异:
数据集区别与选择评估范式差异:
_gen 缀数据集: 生成式评估, 番后处理提取答案 ( (如ceval_gen)。
_ppl后缀数据集:困惑度评估,直接比对选项概率(如ceval_ppl)。 -
领域覆盖:
C-Eval:侧重中文STEM和社会科学知识,包含1.3万道选择题 。
LawBench:法律领域专项评估,需额外克隆仓库并配置路径。
Open Compass公开数据集评估模型
Open Compass自定义数据集评估模型
OpenCompass 官网文档 https://opencompass.readthedocs.io/zh-cn/latest/get_started/installation.html
基础安装
conda create --name opencompass python=3.10 -y
# conda create --name opencompass_lmdeploy python=3.10 -yconda activate opencompass
下载opencompass ,进行安装
cd autodl-tmp/
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .
下载数据集
cd /root/autodl-tmp/opencompass
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
如果下载不下来,可能自己从github下载到本机上,然后再上传到百度云盘,再通过bypy 下载到本地 。
查看模型与数据集
cd /root/autodl-tmp/opencompass
python tools/list_configs.py 
开始模型评估
命令行(自定义HF模型)
# 下载模型
pip install modelscope
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir ./# 开启模型评估
# demo_gsm8k_base_gen demo_math_base_gen 小学数学题数据集,数学推理数据集
python run.py \--datasets demo_gsm8k_base_gen demo_math_base_gen \--hf-type base \--hf-path /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat \--debug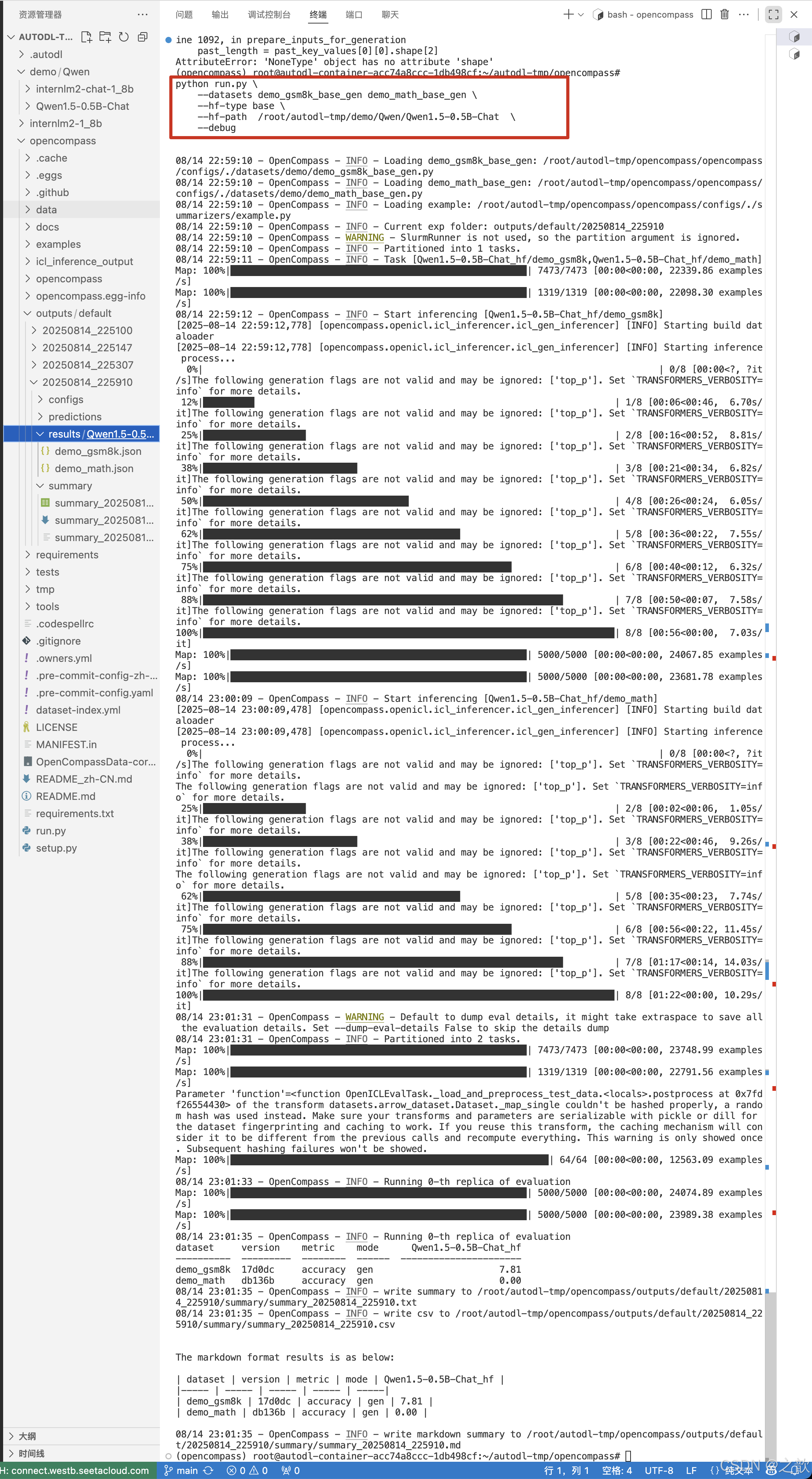
请注意,通过这种方式,OpenCompass 一次只评估一个模型,而其他方式可以一次评估多个模型。
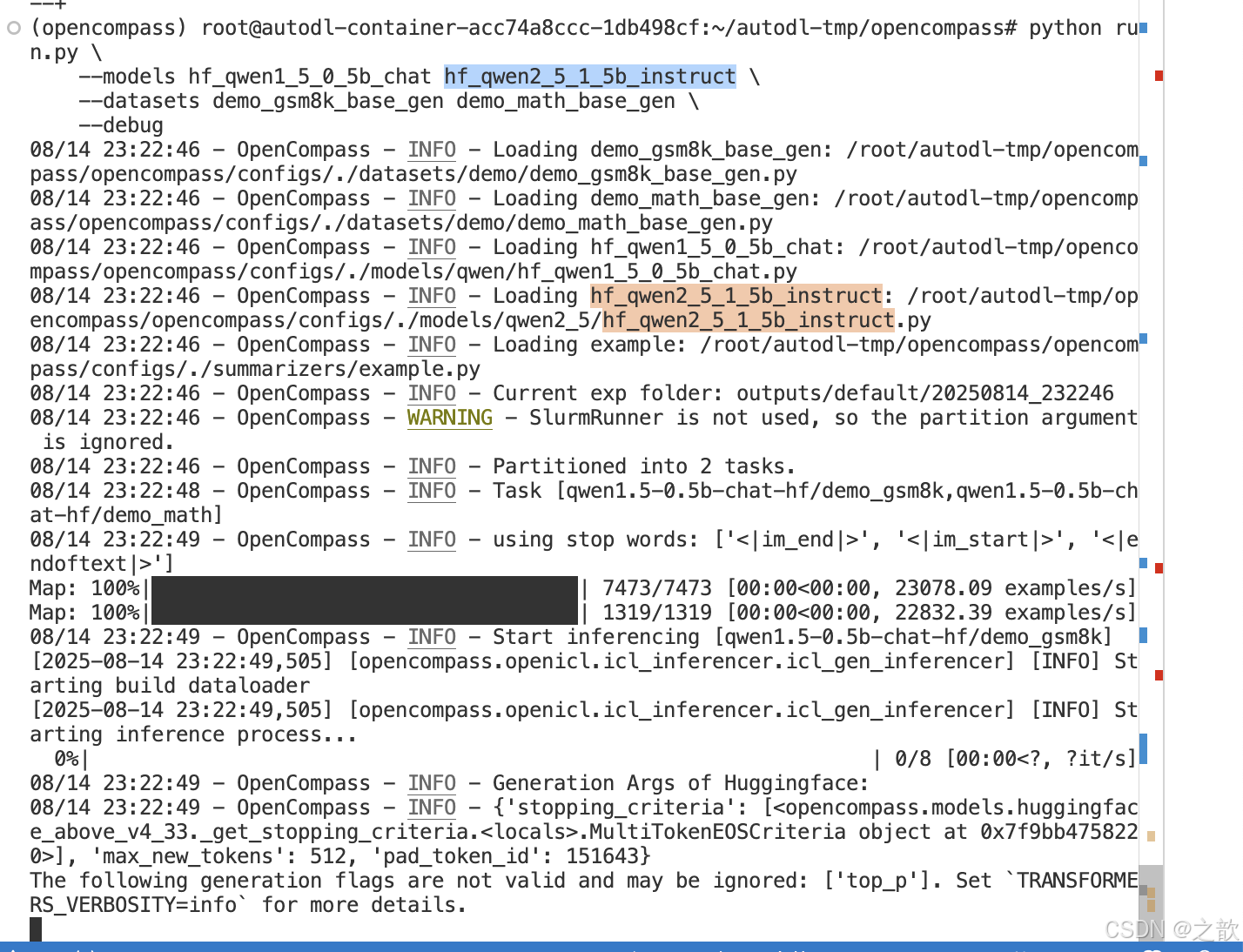
例如一个占用 2 卡进行测试的 Qwen1.5-0.5B-Chat, 开启数据采样,模型的命令如下:
python run.py \--datasets demo_gsm8k_base_gen demo_math_base_gen \--hf-type chat \--hf-path /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat \--max-out-len 1024 \--min-out-len 1 \--hf-num-gpus 1 \--generation-kwargs do_sample=True temperature=0.6 \--debug
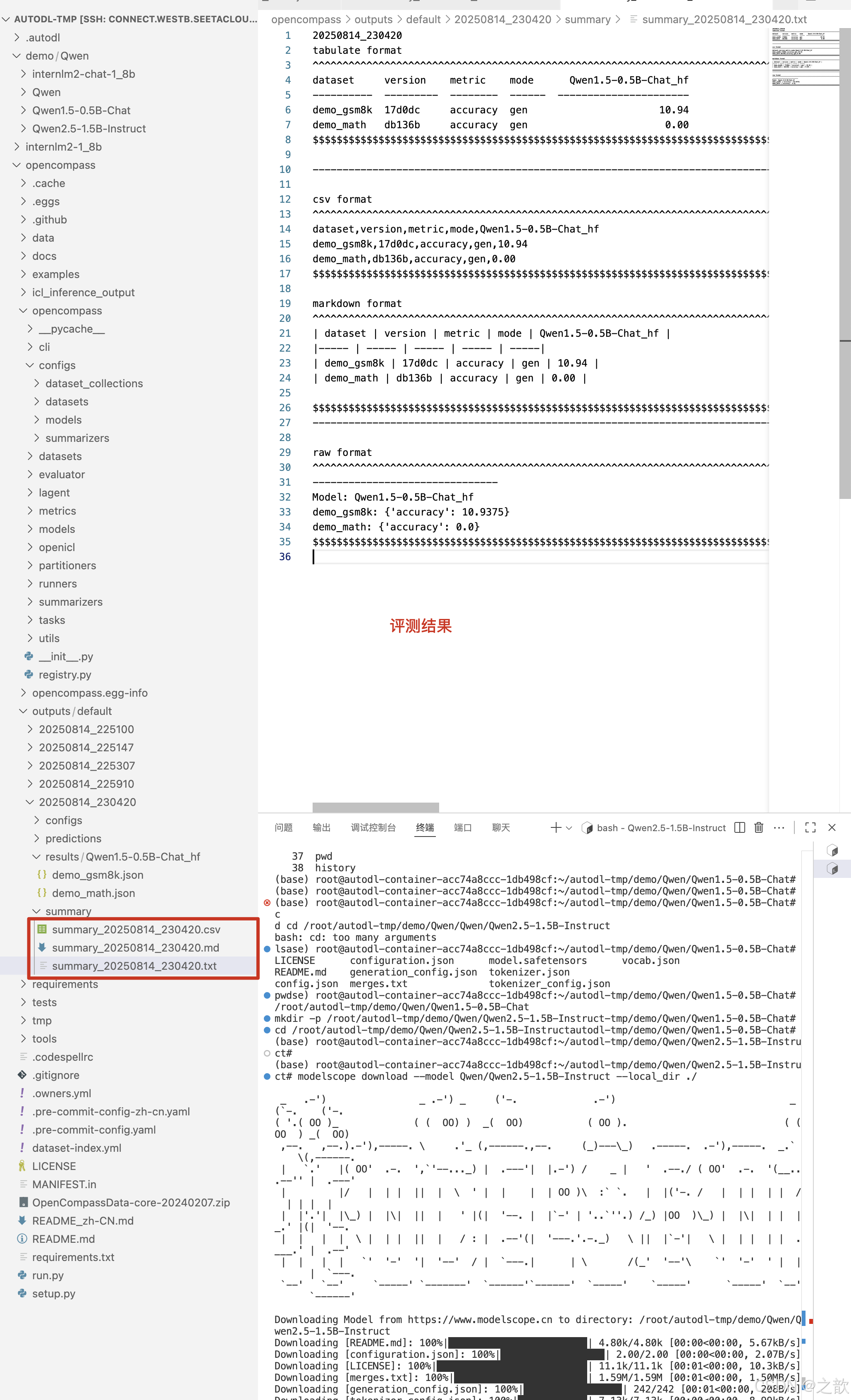
命令行
用户可以使用 --models 和 --datasets 结合想测试的模型和数据集。一次性可以评估多个模型 。
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct
cd /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir ./python run.py \--models hf_internlm2_1_8b hf_qwen2_1_5b \--datasets demo_gsm8k_base_gen demo_math_base_gen \--debug
修改
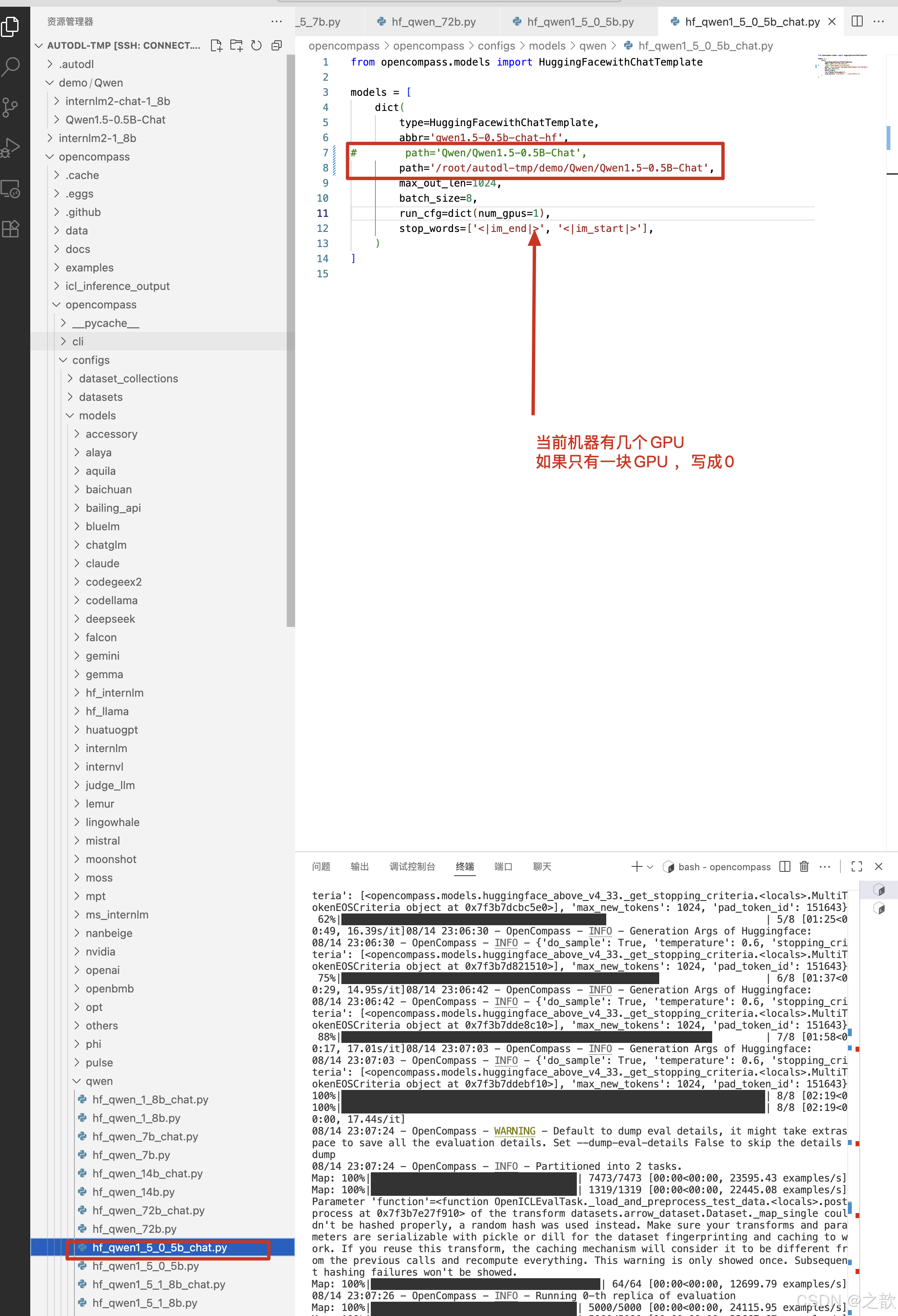
/root/autodl-tmp/opencompass/opencompass/configs/models/qwen/hf_qwen1_5_0_5b_chat.py
from opencompass.models import HuggingFacewithChatTemplatemodels = [dict(type=HuggingFacewithChatTemplate,abbr='qwen1.5-0.5b-chat-hf',
# path='Qwen/Qwen1.5-0.5B-Chat',path='/root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat',max_out_len=1024,batch_size=8,run_cfg=dict(num_gpus=0), # 一个一GPU 一定要写0 stop_words=['<|im_end|>', '<|im_start|>'],)
]
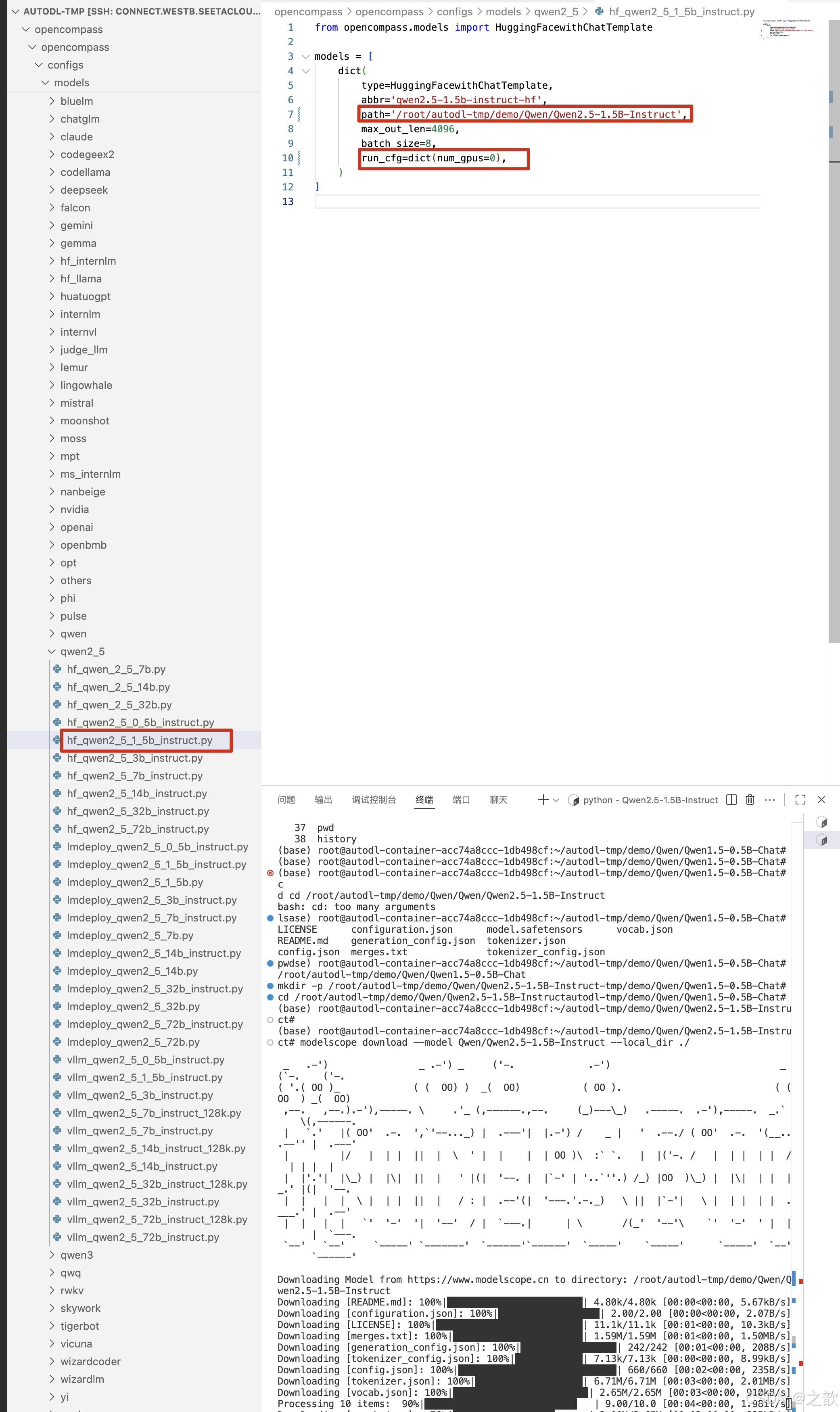
修改/root/autodl-tmp/opencompass/opencompass/configs/models/qwen2_5/hf_qwen2_5_1_5b_instruct.py
from opencompass.models import HuggingFacewithChatTemplatemodels = [dict(type=HuggingFacewithChatTemplate,abbr='qwen2.5-1.5b-instruct-hf',path='/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct',max_out_len=4096,batch_size=8,run_cfg=dict(num_gpus=0), # 一个gpu 一定要写0 )
]
查看修改的配置文件
python tools/list_configs.py hf_qwen
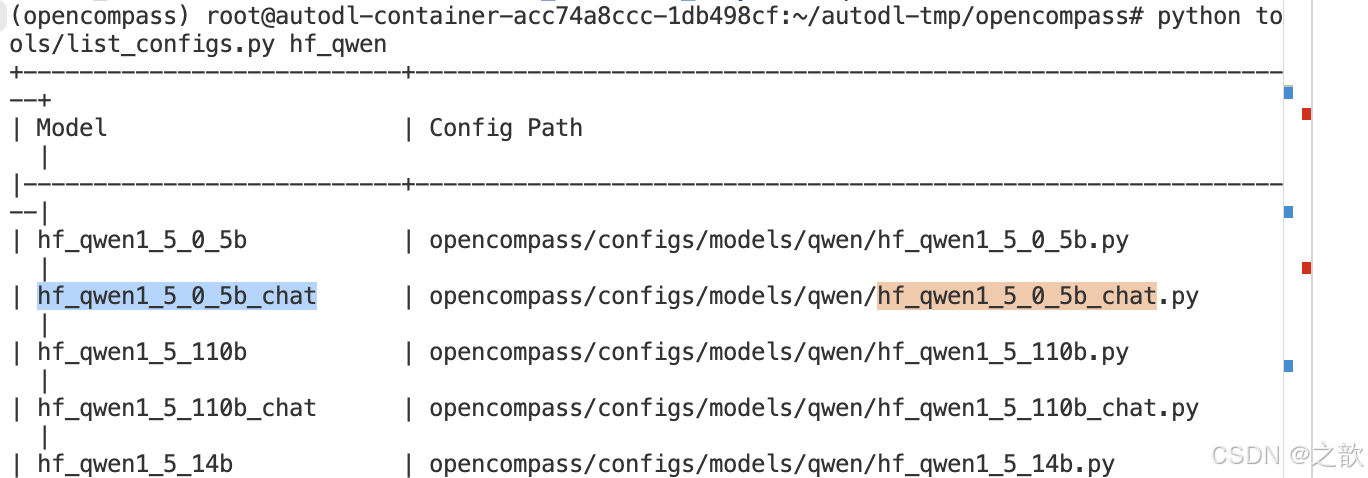

python run.py \--models hf_qwen1_5_0_5b_chat hf_qwen2_5_1_5b_instruct \--datasets demo_gsm8k_base_gen demo_math_base_gen \--debug
配置文件
除了通过命令行配置实验外,OpenCompass 还允许用户在配置文件中编写实验的完整配置,并通过 run.py 直接运行它。配置文件是以 Python 格式组织的,并且必须包括 datasets 和 models 字段。
本次测试配置在 examples/eval_base_demo.py 中。此配置通过 继承机制 引入所需的数据集和模型配置,并以所需格式组合 datasets 和 models 字段。
运行任务时,我们只需将配置文件的路径传递给 run.py:
cd /root/autodl-tmp/opencompass
vi test.py # 写入上面脚本 # 在test 脚本中写入如下内容 from mmengine.config import read_base
with read_base():from opencompass.configs.datasets.demo.demo_gsm8k_base_gen import gsm8k_datasetsfrom opencompass.configs.datasets.demo.demo_math_base_gen import math_datasetsfrom opencompass.configs.models.qwen.hf_qwen1_5_0_5b_chat import models as hf_qwen1_5_0_5b_chatfrom opencompass.configs.models.qwen2_5.hf_qwen2_5_1_5b_instruct import models as hf_qwen2_5_1_5b_instructdatasets = gsm8k_datasets + math_datasets
models = hf_qwen1_5_0_5b_chat + hf_qwen2_5_1_5b_instruct# 当然 /root/autodl-tmp/opencompass/opencompass/configs/models/qwen/hf_qwen1_5_0_5b_chat.py
# /root/autodl-tmp/opencompass/opencompass/configs/models/qwen2_5/hf_qwen2_5_1_5b_instruct.py
# 这两个文件要对应修改,上面改过了,这里就不再赘述

lmdeploy 评估方式
下载模型
pip install modelscope
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir ./
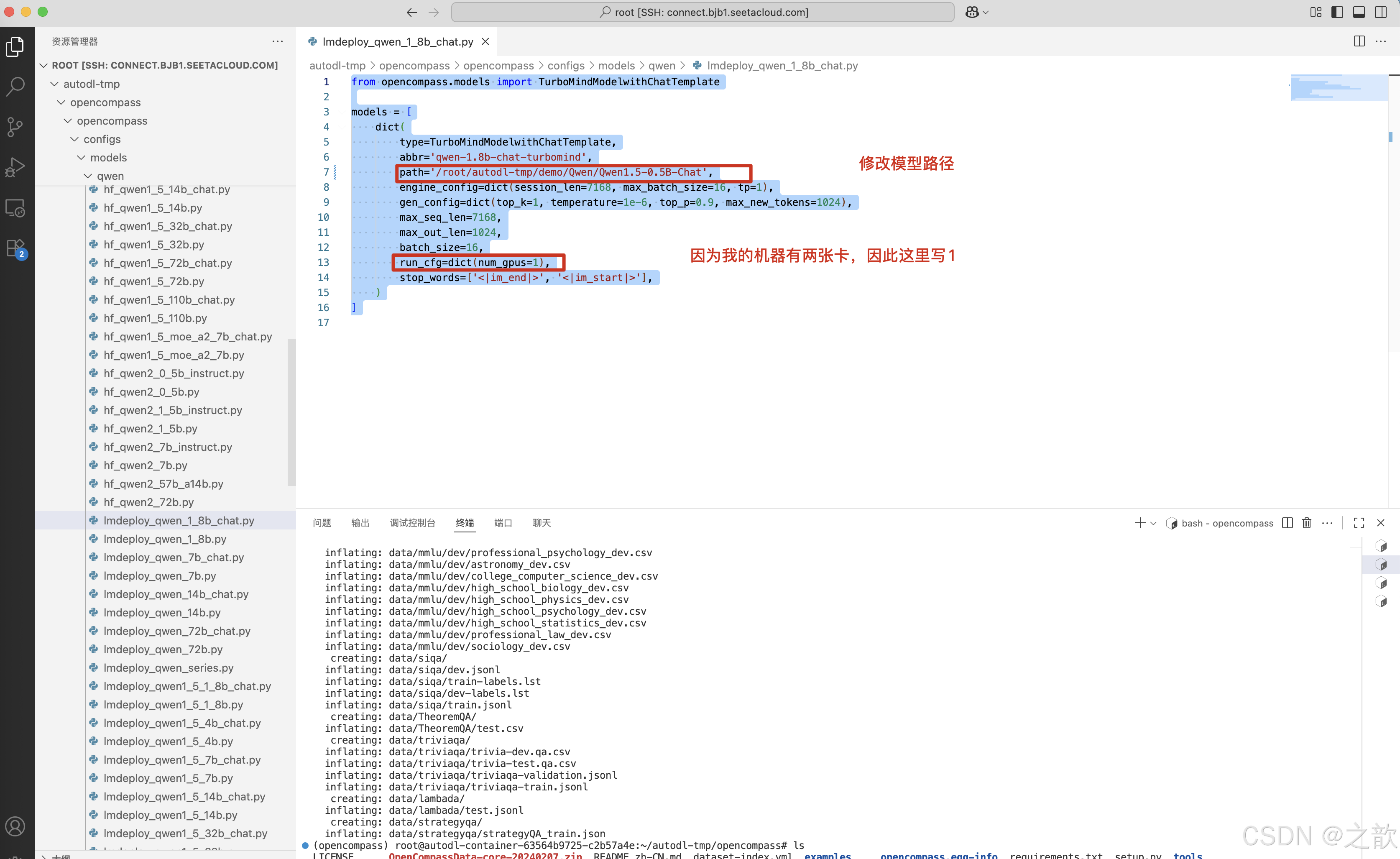
修改Imdeploy_qwen_1_8b_chat 配置文件
from opencompass.models import TurboMindModelwithChatTemplatemodels = [dict(type=TurboMindModelwithChatTemplate,abbr='qwen-1.8b-chat-turbomind',path='/root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat', # 修改从魔塔社区下载的文件路径 engine_config=dict(session_len=7168, max_batch_size=16, tp=1),gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=1024),max_seq_len=7168,max_out_len=1024,batch_size=16,run_cfg=dict(num_gpus=1), # 如果有两张卡,则配置为1 ,如果有一张卡,则配置0 stop_words=['<|im_end|>', '<|im_start|>'],)
]
开始评估
运行
pip install lmdeploypython run.py \--models lmdeploy_qwen_1_8b_chat \--datasets demo_gsm8k_base_gen demo_math_base_gen \--debug
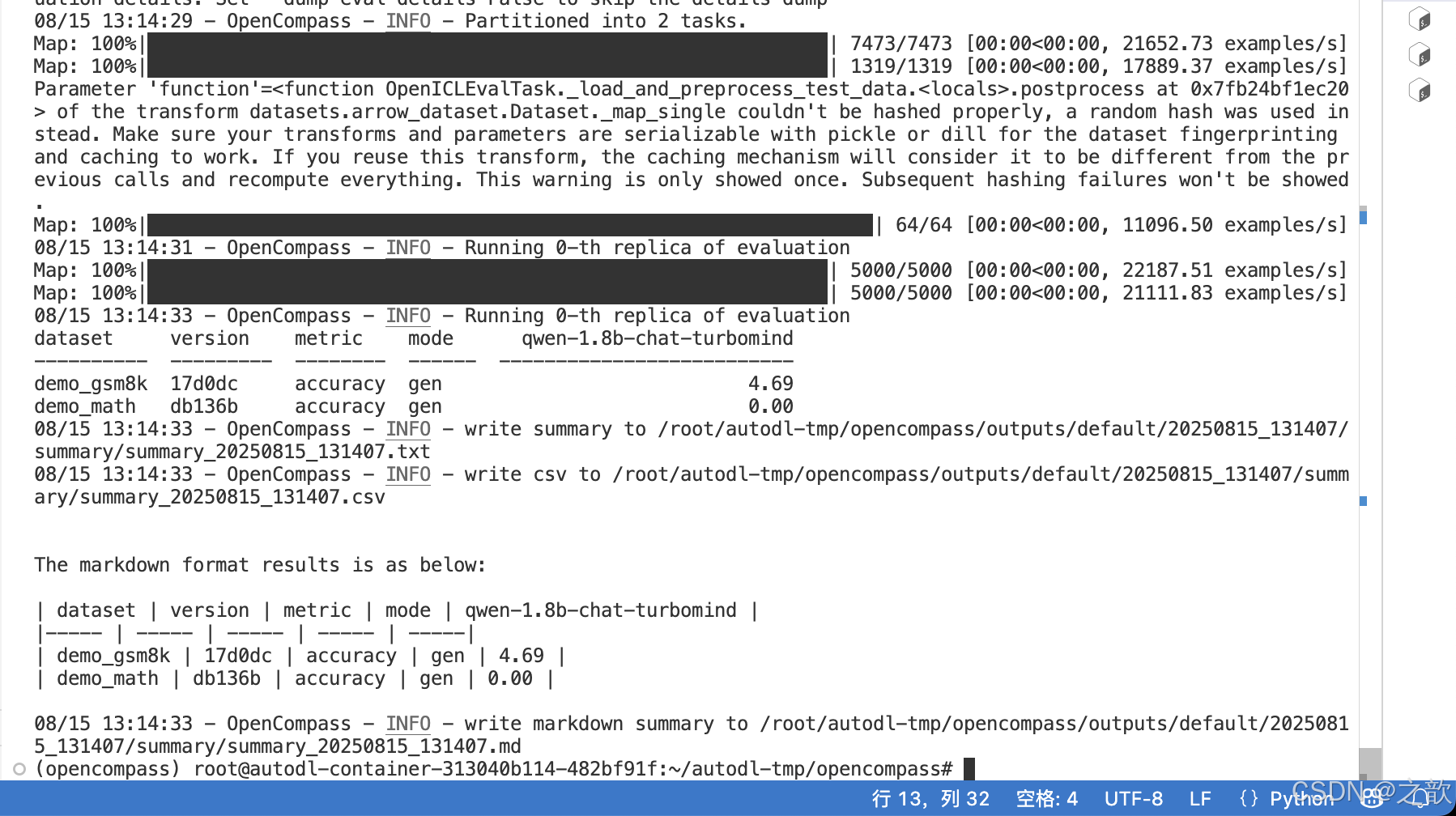
换一个数据集 ceval 评测
python tools/list_configs.py ceval
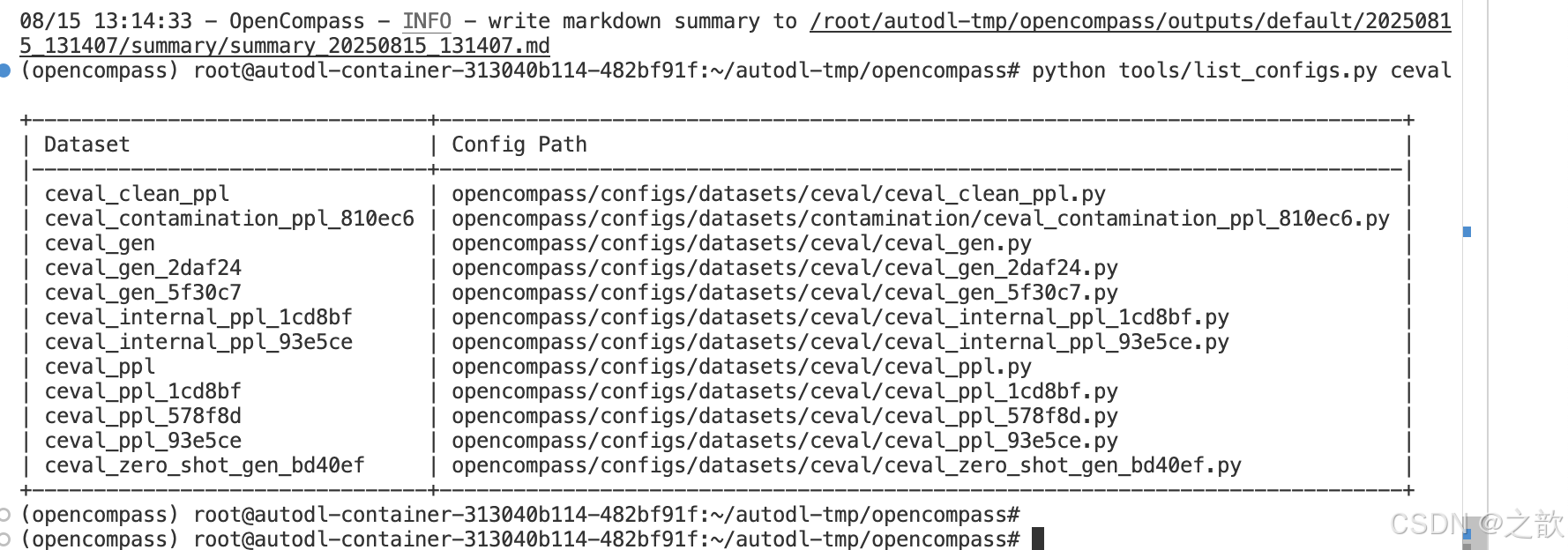
python run.py \--models lmdeploy_qwen_1_8b_chat \--datasets ceval_gen \--debug
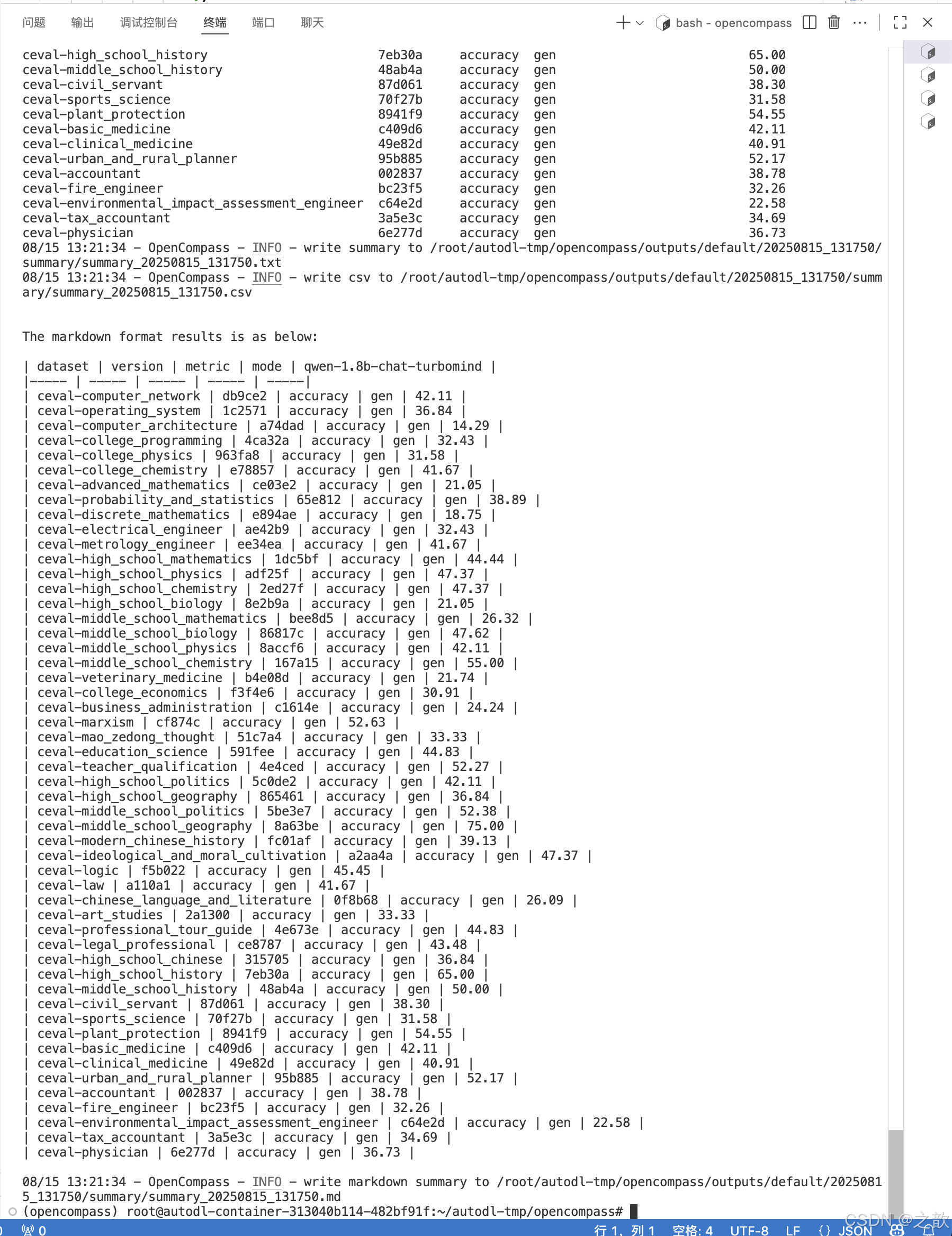
运行结果
自定义数据集
本教程仅供临时性的、非正式的数据集使用,如果所用数据集需要长期使用,或者存在定制化读取 / 推理 / 评测需求的,强烈建议按照 new_dataset.md 中介绍的方法进行实现。
在本教程中,我们将会介绍如何在不实现 config,不修改 OpenCompass 源码的情况下,对一新增数据集进行测试的方法。我们支持的任务类型包括选择 (mcq) 和问答 (qa) 两种,其中 mcq 支持 ppl 推理和 gen 推理;qa 支持 gen 推理。
数据集格式
我们支持 .jsonl 和 .csv 两种格式的数据集。
选择题 (mcq)
对于选择 (mcq) 类型的数据,默认的字段如下:
question: 表示选择题的题干
A, B, C, …: 使用单个大写字母表示选项,个数不限定。默认只会从 A 开始,解析连续的字母作为选项。
answer: 表示选择题的正确答案,其值必须是上述所选用的选项之一,如 A, B, C 等。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
创建
vi /root/autodl-tmp/test_qa.jsonl
写入如下内容 :
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
python run.py \
--hf_path /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
--custom-dataset-path /root/autodl-tmp/test_qa.jsonl