C++——分布式
文章目录
- 一、什么是分布式?
- 核心特点
- 为什么需要分布式?
- 分布式 vs 集中式
- 常见分布式场景
- 挑战与难点
- 二、 简述下CAP理论
- 2.1 简述
- 2.2 详细
- 三、 简述下分布式中的2PC
- 2.1 详细
- 3.2 简述
- 三 、简述下Raft协议
- 3.1 详细
- 3.2 简述
- 四 grpc框架
- 4.1 RPC(Remote Procedure Call,远程过程调用).0
- 4.2 gRPC
- 4.2 gRPC的一些特性
- 4.3 gRPC的使用场景
- 4.3 gRPC的数据封装和数据传输
- 4.3.1 网络传输中的内容封装数据体积问题
- 4.3.2 网络传输效率问题
- 4.5 RPC注册发现
- 4.6 gRPC 4种模式
- 4.6.1 简答记忆模式
- 4.6.2 详细解答
- 4.6.3 `trailer` 元数据
- 4.7 gRPC同步异步模式
- 4.7.1 基本概念概览
- 4.7.2 RPC 和 API 的区别
- 4.7.3 同步模式
- 4.7.4 异步模式
- 4.7.5 gRPC 异步模式的实现细节
一、什么是分布式?
“分布式” 是计算机科学和软件工程中的一个核心概念,指的是将一个大型系统或任务拆解为多个部分,通过多个独立的计算节点(如服务器、计算机)协同工作来完成,节点之间通过网络进行通信和协调。
核心特点
- 拆分性:系统被拆分为多个可独立运行的子模块(或 “节点”),每个节点负责一部分特定功能。
- 协同性:节点之间通过网络协议(如 TCP/IP、HTTP)交换数据,共同完成整体任务。
- 独立性:单个节点的故障通常不会导致整个系统崩溃,其他节点可继续工作(容错性的基础)。
为什么需要分布式?
- 解决单机性能瓶颈
单台计算机的算力、存储、带宽都是有限的。例如,一个每天处理 10 亿次请求的电商平台,单台服务器无法承载,必须通过多台服务器分工(如拆分订单、支付、物流等模块)来分担压力。 - 提高可靠性
单机故障会导致系统瘫痪,而分布式系统中,多个节点可以互为备份。比如,银行的交易系统会在不同城市部署服务器,即使某一地区机房故障,其他节点仍能继续服务。 - 资源利用率优化
不同功能模块对资源的需求不同(如数据库模块需要大存储,计算模块需要强算力),分布式架构可针对性地为节点分配资源,避免浪费。 - 扩展性灵活
当业务增长时,只需增加新的节点(如多加几台服务器)即可扩展系统能力,无需重构整个架构(即 “水平扩展”)。
分布式 vs 集中式
| 对比维度 | 集中式系统 | 分布式系统 |
|---|---|---|
| 结构 | 所有功能集中在单节点运行 | 功能拆分到多个节点,通过网络连接 |
| 性能瓶颈 | 受限于单机硬件 | 可通过增加节点突破瓶颈 |
| 可靠性 | 单节点故障导致系统崩溃 | 部分节点故障不影响整体运行 |
| 复杂度 | 设计简单,无需考虑节点协作 | 需解决通信延迟、数据一致性等问题 |
| 典型例子 | 个人电脑上的单机程序 | 云计算平台(如 AWS)、分布式数据库(如 HBase) |
常见分布式场景
- 分布式存储:如 HDFS(将大文件拆分存储在多台服务器)、分布式数据库(如 MySQL 集群)。
- 分布式计算:如 MapReduce(将大规模计算任务拆分到多个节点并行处理)。
- 分布式服务:如微服务架构(将电商系统拆分为用户服务、商品服务、订单服务等,各自独立部署)。
- 分布式缓存:如 Redis 集群(多台服务器共同提供缓存服务,分担访问压力)。
挑战与难点
分布式系统的核心难题源于节点间的 “网络不可靠性” 和 “数据一致性”:
- 网络延迟 / 中断:节点通信可能因网络波动延迟或失败,需设计重试、超时等机制。
- 数据一致性:多个节点存储同一份数据时,如何保证修改后所有节点的数据同步(如银行转账时,转出和转入账户的金额需同时更新)。
- 节点时钟同步:不同节点的本地时间可能存在偏差,会影响任务调度、日志排序等。
这些问题催生了很多经典理论和技术,如 CAP 定理(分布式系统无法同时保证一致性、可用性、分区容错性)、Paxos/Raft 共识算法(解决数据一致性问题)等。
简单来说,分布式的本质是 “分而治之”,通过多个节点的协作突破单机限制,但也引入了额外的复杂性,需要专门的技术来解决协同问题。
二、 简述下CAP理论
2.1 简述
CAP 定理指出:分布式系统无法法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)三项特性,最多只能同时满足其中两项。其核心是描述分布式系统在状态层面的权衡关系,具体解析如下:
-
一致性(C):聚焦数据状态的统一性。当写请求发生时,若系统中所有节点均同步更新数据,且后续读请求能获取到一致的最新数据,则称此次操作实现了数据一致性。若节点间数据同步失败(如网络问题),为避免返回不一致的旧数据或多版本数据,系统可能选择不返回结果,以此保障对外的数据一致性。
-
可用性(A):要求系统持续响应请求。无论接收的是写请求还是读请求,所有正常运行的节点都需在业务定义的 “合理时间” 内返回明确结果(成功或失败),不能出现无响应或无限等待的情况。
-
分区容错性(P):针对网络不可靠性设计。分布式系统的节点通过网络通信,当网络故障或机器失效导致节点间无法通信时,即发生 “分区”。分区容错性要求系统在这种情况下仍能继续运行,不整体崩溃。
在分布式场景中,网络分区是不可避免的,因此分区容错性(P)是必须具备的基础特性。这使得系统设计通常需在 “一致性(C)” 和 “可用性(A)” 之间做取舍:仅当分区发生时才需二选一,正常无分区时,系统应同时保证一致性和可用性。
需注意的是,CAP 的三项特性并非非黑即白的布尔值,而是具有程度差异的范围值(如一致性可分为强一致性、最终一致性等,可用性可衡量响应效率和成功率),实际设计中往往是在三者间寻找动态平衡。
2.2 详细
CAP 理论是分布式系统设计中的一个基础理论,由加州大学伯克利分校的 Eric Brewer 在 2000 年提出,它指出:在一个分布式系统中,不可能同时满足以下三个特性:
- 一致性(Consistency)
所有节点在同一时间看到的数据是完全一致的。当数据更新后,所有节点必须立即呈现最新状态,不存在中间状态的可见性。 - 可用性(Availability)
只要收到用户的请求,系统就必须在合理时间内返回一个非错误的响应(无论保证数据最新,但要保证服务能正常响应)。 - 分区容错容错性(Partition Tolerance)
当分布式系统中的网络发生分区(部分节点与其他节点通信中断)时,系统仍能继续运行,不会因为网络故障而整体崩溃。
核心结论:
在分布式系统中,网络分区是不可避免的(必然会发生),因此系统设计必须优先保证分区容错性(P)。在此前提下,只能在一致性(C)和可用性(A)之间做出权衡:
- CP 系统:优先保证一致性和分区容错性。网络分区时,为避免数据不一致,可能会拒绝部分请求(牺牲可用性)。例如:分布式数据库(如 HBase)、分布式锁服务(如 ZooKeeper)。
- AP 系统:优先保证可用性和分区容错性。网络分区时,允许节点返回不一致的数据,但始终保证服务可用(牺牲一致性)。例如:分布式缓存(如 Redis 集群)、社交网络的消息系统。
CAP 理论揭示了分布式系统设计的根本约束,指导开发者根据业务场景在一致性和可用性之间做合理取舍(如金融交易系统需优先保证一致性,而社交应用可能更侧重可用性)。
三、 简述下分布式中的2PC
在分布式系统中,“原子性”(Atomicity)是指一个操作或一组操作要么全部成功执行,要么全部不执行,不存在 “部分成功、部分失败” 的中间状态。它是保证分布式数据一致性的核心特性之一,类似于数据库事务中的 ACID 原则里的 “原子性”,但应用场景扩展到了多节点协同的分布式环境。
2.1 详细
分布式中的 2PC(Two-Phase Commit,两阶段提交) 是一种经典的分布式事务一致性协议,用于在多个节点(或数据库、服务)之间协调事务的最终提交或回滚,确保所有参与节点对事务的处理结果达成一致。它通过将事务过程分为两个阶段来实现这一目标,是解决分布式系统中 “原子性” 问题的重要方案。
在 2PC 协议中,通常包含两类核心角色:
-
协调者:统筹事务全流程,向所有参与者发送指令,根据反馈决定事务最终提交或回滚。
-
参与者:执行本地事务操作,向协调者反馈执行结果,并根据协调者指令完成最终提交或回滚。
第一阶段:准备阶段(Prepare Phase)
目标:确认所有参与者是否具备提交事务的条件。具体流程如下:
-
发起请求:协调者向所有参与者发送 “准备请求”,附带事务信息,等待响应。
-
执行本地事务:参与者执行本地事务操作(如增删改),但不提交,仅记录日志(用于追溯和恢复)。
-
反馈结果:
-
若本地执行成功且可提交,返回 “同意(Yes)”;
-
若执行失败(如数据冲突),返回 “拒绝(No)”。
-
-
等待反馈:协调者收集齐所有参与者的响应后,进入下一阶段。
第二阶段:提交 / 回滚阶段(Commit/Rollback Phase)
目标:确认所有参与者是否具备提交事务的条件。具体流程取决于第一阶段的结果:
情况 1:所有参与者返回 “同意”
-
协调者发送 “提交请求”;
-
参与者正式提交本地事务(持久化日志操作),释放资源,返回 “提交成功(Ack)”;
-
协调者收到所有 Ack 后,标记事务完成。
情况 2:存在 “拒绝” 或超时未响应
-
协调者发送 “回滚请求”;
-
参与者根据日志撤销操作,恢复数据,释放资源,返回 “回滚成功(Ack)”;
-
协调者收到所有 Ack 后,标记事务终止。
通过两阶段确认,2PC 确保了分布式事务的原子性。
3.2 简述
2PC(Two-Phase Commit,两阶段提交)是分布式系统中解决数据一致性的经典协议,主要用于确保多个节点(如数据库、服务)在执行事务时达成一致的结果(要么全部成功提交,要么全部失败回滚)。
其核心思想是通过 “协调者”(Coordinator)和 “参与者”(Participants)的两步交互,实现分布式事务的原子性:
第一阶段:准备阶段(Prepare)
- 协调者向所有参与者发送 “准备提交” 请求,询问是否可以执行事务并做好提交准备。
- 每个参与者执行事务操作(如数据库更新),但不实际提交,仅记录事务日志(便于回滚)。
- 参与者向协调者返回响应:
- 若自身操作成功,返回 “同意提交”(Yes)。
- 若自身操作失败,返回 “拒绝提交”(No)。
第二阶段:提交 / 回滚阶段(Commit/Rollback)
协调者根据所有参与者的响应做最终决策:
- 若所有参与者均返回 Yes:
- 协调者向所有参与者发送 “正式提交”(Commit)指令。
- 参与者执行最终提交,并释放资源,返回 “提交成功” 确认。
- 若有任何参与者返回 No,或超时未响应:
- 协调者向所有参与者发送 “回滚”(Rollback)指令。
- 参与者根据日志撤销已执行的操作,返回 “回滚成功” 确认。
优缺点:
- 优点:原理简单,能保证分布式事务的强一致性。
- 缺点:
- 阻塞问题:若协调者崩溃,参与者会长期处于 “准备” 状态,锁定资源。
- 性能较差:需多轮网络通信,且参与者需等待其他节点响应。
- 单点风险:协调者故障可能导致整个事务中断。
2PC 是早期分布式系统中常用的一致性协议,适用于对一致性要求高但对性能要求不极致的场景(如银行转账)。后续的 3PC(三阶段提交)等协议试图改进其缺陷,但复杂度更高。
三 、简述下Raft协议
3.1 详细
Raft 是一种分布式一致性算法,旨在解决分布式系统中多个节点如何就某一状态达成一致的问题。其核心作用是在分布式集群中保证数据的一致性、可用性和容错性,广泛应用于分布式数据库、分布式存储、服务发现等场景(如 etcd、Consul、CockroachDB 等)。
Raft协议中的每个节点都处于三种状态之一:领导人、跟随者、候选人。
-
领导人 :所有请求的处理者,Leader接受client的更新请求,本地处理后再同步至多个其他副本;
-
跟随者 :请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件
-
候选人 :如果Follower副本在一段时间内没有收到领导人副本的心跳,则判断领导人可能已经故障,此时启动选主过程,此时副本会变成候选人状态,直到选主结束。
Raft 采用心跳机制触发领导人选举,流程如下:
-
初始状态与选举触发
所有服务器启动时均为跟随者。若跟随者在指定超时时间内未收到领导人的心跳(AppendEntries RPC),则将自身任期号加 1 并转换为候选人,同时向集群中所有其他节点并行发送请求投票 RPC,为自己争取选票。 -
选举规则与结果判定
-
每个服务器在一个任期内最多投一票,遵循先来先服务原则。
-
若候选人获得集群多数节点的选票,即当选为新领导人,并立即向所有节点发送心跳以确立地位。
-
若候选人在等待期间收到其他节点的 AppendEntries RPC,且该节点的任期号不小于自身当前任期号,则承认其领导地位并退回跟随者状态;若对方任期号更小,则拒绝该 RPC 并保持候选人状态。
-
若选票被多个候选人瓜分导致无人获多数票,所有候选人将在随机超时后(通常 150-300ms 区间)重新发起选举(任期号递增)。随机超时机制可减少选票瓜分概率,确保快速产生领导人。
-
日志复制机制:
领导人产生后,通过以下流程保证日志一致性:
-
接收客户端请求(含状态机执行指令),将其作为新日志条目追加到本地日志。
-
向所有跟随者并行发送 AppendEntries RPC,要求复制日志条目。
-
当多数跟随者确认接收该条目后,领导人将其应用到本地状态机,并向客户端返回结果。
-
对于崩溃、延迟或网络异常的跟随者,领导人会持续重试 AppendEntries RPC,直至所有跟随者最终同步该日志条目。
若跟随者日志与领导人不一致,领导人将强制覆盖跟随者的冲突日志条目,确保所有节点日志最终一致。
3.2 简述
Raft 是一种分布式系统中用于实现数据一致性的共识算法(Consensus Algorithm),旨在解决多个节点在异步网络环境下(可能存在网络延迟、丢包、节点故障)如何达成一致决策的问题。它比 Paxos 算法更易理解和实现,已被广泛应用于分布式数据库(如 etcd、MongoDB)、服务发现等场景。
Raft 的核心思想是通过 “领导者(Leader)- 跟随者(Follower)- 候选者(Candidate)” 的角色分工,以及 “任期(Term)” 机制,确保集群在动态变化中维持数据一致性。
核心机制:
- 角色与任期
- 任期(Term):时间被划分为连续的任期(整数编号),每个任期最多产生一个领导者,类似 “选举周期”。
- 领导者:负责接收客户端请求,向跟随者同步数据,协调集群达成一致。
- 跟随者:被动接收领导者的数据同步,不主动发起请求。
- 候选者:当跟随者长时间未收到领导者心跳时,转化为候选者发起选举。
- 领导选举
- 若跟随者在超时时间内未收到领导者心跳,会自增任期号并转为候选者,向其他节点发送 “投票请求”。
- 其他节点在一个任期内只能投一票,优先给任期号更高、日志更新的候选者投票。
- 候选者获得多数节点(超过半数)投票后当选为新领导者,开始向所有节点发送心跳维持领导地位。
- 日志复制
- 领导者接收客户端请求后,将操作作为日志条目追加到本地日志。
- 领导者向所有跟随者同步日志条目,等待多数跟随者确认已写入日志。
- 当多数节点确认后,领导者将该日志条目标记为 “已提交”,并通知所有跟随者提交,最后向客户端返回成功。
关键特性:
- 安全性:确保所有节点最终达成一致的日志序列,已提交的日志不会被推翻。
- 活性:在没有网络分区或节点故障的情况下,系统能正常处理请求并选举出领导者。
- 简单性:通过清晰的角色划分和阶段分离(选举、日志复制),比 Paxos 更易理解和实现。
Raft 的设计目标是在保证一致性的同时,兼顾可理解性和工程实现的便捷性,成为分布式系统共识问题的主流解决方案之一。
四 grpc框架
RPC 即远程过程调用协议(Remote Procedure Call Protocol),可以让我们像调用本地对象一样发起远程调用。
gRPC是一个现代的、高性能、开源的和语言无关的通用 RPC 框架,基于 HTTP2 协议设计,序列化使用PB(Protocol Buffer),PB 是一种语言无关的高性能序列化框架,基于 HTTP2+PB 保证了的高性能。
RPC 是一种 “远程调用” 的思想,而 gRPC 是实现这一思想的具体框架,它通过 Protobuf 和 HTTP/2 实现了高性能、跨语言的远程通信,是现代分布式系统中常用的通信方案。
4.1 RPC(Remote Procedure Call,远程过程调用).0
RPC 是一种进程间通信协议,允许一台计算机(客户端)像调用本地函数一样调用另一台计算机(服务器)上的函数或方法,无需显式处理网络通信细节(如 Socket、HTTP 等)。
其核心思想是 “屏蔽分布式细节”,让开发者能以本地调用的方式编写分布式程序。例如,在微服务架构中,订单服务调用支付服务的接口,就可以通过 RPC 实现,无需手动处理网络连接、数据序列化等底层逻辑。
工作流程:
- 客户端调用本地 “桩函数”(Stub,类似代理),传入参数。
- 桩函数将参数序列化(转为网络可传输格式,如二进制),并通过网络发送给服务器。
- 服务器端的 “桩函数” 接收数据,反序列化为本地参数,调用实际的函数。
- 服务器将结果序列化后返回给客户端,客户端反序列化得到结果。
常见的 RPC 框架有:Dubbo(Java)、gRPC、Thrift 等。
4.2 gRPC
gRPC 是 Google 开发的高性能 RPC 框架,基于 HTTP/2 协议传输,使用 Protocol Buffers(Protobuf)作为接口定义语言(IDL)和数据序列化格式。
核心特点:
- 高效的序列化:使用 Protobuf(二进制格式),比 JSON/XML 更紧凑,序列化 / 反序列化速度更快。
- HTTP/2 支持:支持多路复用(单连接并发处理多个请求)、双向流、头部压缩等,提升网络效率。
- 强类型接口:通过 Protobuf 定义服务接口(
.proto文件),生成多语言代码(如 Java、Go、Python),确保类型安全。 - 多语言支持:原生支持多种编程语言,方便跨语言服务调用。
- 流式通信:支持单向流、双向流(如客户端持续发送数据,服务器实时处理并返回),适合实时场景(如聊天、监控)。
典型使用场景:
- 微服务间的高效通信(如订单服务调用库存服务)。
- 跨语言的服务交互(如 Go 服务调用 Java 服务)。
- 需要低延迟、高吞吐量的实时数据传输(如游戏服务器、监控系统)。
4.2 gRPC的一些特性
-
**gRPC基于服务的思想:**定义一个服务,描述这个服务的方法以及入参出参,服务器端有这个服务的具体实现,客户端保有一个存根,提供与服务端相同的服务;
-
首先通过接口定义语言(如 Protobuf)明确声明一个服务,该声明包含服务中可被调用的所有方法,以及每个方法的输入参数类型和返回值类型。
-
服务端根据上述定义,实现这些方法的具体业务逻辑,形成可对外提供服务的实体。
-
客户端通过工具生成与服务端服务定义完全匹配的本地代理(即存根,Stub),该存根对外暴露的方法签名(包括方法名、参数、返回值)与服务端定义完全一致。
-
客户端调用本地存根的方法时,存根会自动处理网络通信、数据序列化等底层细节,将请求发送至服务端;服务端处理后将结果返回,存根再将结果解析后返回给客户端。
-
-
使用 Protocol Buffers 作为接口定义语言(IDL):
- 通过
.proto文件严格定义服务接口(包含方法名、参数类型、返回值类型) - 生成的二进制数据序列化效率高,体积远小于 JSON/XML
- 原生支持多语言,可自动生成各语言的客户端和服务端代码
- 通过
-
gRPC同时支持同步调用和异步调用,同步RPC调用时会一直阻塞直到服务端处理完成返回结果,异步RPC是客户端调用服务端时不等待服务端处理完成返回,而是服务端处理完成后主动回调客户端告诉客户端处理完成;
-
基于 HTTP/2 协议:采用二进制传输、多路复用和头部压缩技术,相比 HTTP/1.1 大幅提升传输效率,减少延迟并提高并发能力。
-
基于http2协议的特性:gRPC允许定义如下四类服务方法:
- 一元RPC:客户端发送一次请求,等待服务端响应结构,会话结束,就像一次普通的函数调用这样简单;
- 服务端流式RPC:客户端发起一起请求,服务端会返回一个流,客户端会从流中读取一系列消息,直到没有结果为止;
- 客户端流式RPC:客户端提供一个数据流并写入消息发给服务端,一旦客户端发送完毕,就等待服务器读取这些消息并返回应答;
- 双向流式RPC:客户端和服务端都有一个数据流,都可以通过各自的流进行读写数据,这两个流是相互独立的,客户端和服务端都可以按其希望的任意顺序读写。
4.3 gRPC的使用场景
- 低延迟,高度可扩展的分布式系统
- 开发与云服务器通信的客户端
- 设计一个准确,高效,且与语言无关的新协议时
- 分层设计,以实现扩展,例如。身份验证,负载平衡,日志记录和监控等
- 微服务之间高频通信(高效、跨语言)
- 多语言系统间调用(统一接口,自动生成代码)
- 需要流式传输的场景(实时日志、聊天、文件传输)
- 对性能要求高的内部系统(比 JSON/REST 快)
- 云原生 / 容器化环境(易集成,适合大规模部署)
4.3 gRPC的数据封装和数据传输
4.3.1 网络传输中的内容封装数据体积问题
早期的RPC采用JSON的方式,目前的RPC基本上都采用类似Protobuf的二进制序列化方式。
其差别在于:json的设计是给人看的,protobuf则是利于机器。
JSON的优缺点分别是:
-
优点:在body中用JSON对内容进行编码,极易跨语言,不需要约定特定的复杂编码格式和Stub文件。 在版本兼容性上非常友好,扩展也很容易。
-
缺点:JSON难以表达复杂的参数类型,如结构体等;数据冗余和低压缩率使得传输性能差。
gRPC对此的解决方案是丢弃json、xml这种传统策略,使用 Protocol Buffer(是Google开发的一种跨语言、跨平台、可扩展的用于序列化数据协议)。
protobuf是一个以跨语言为目标的序列化方案,它能做到多种语言以同一份proto文件作为约定,不用A语言写一份,B语言写一份,各个依赖的服务将proto文件原样拷贝一份即可。但.proto文件并不是代码,不能执行,要想直接跨语言是不行的,必须得有对应语言的中间代码才行,中间代码要有以下能力:
-
将message转成对象,例如C++里是class,golang里是struct,需要各自表达后,才能被理解
-
需要有进行编解码的代码,能解码内容为自己语言的对象、能将对象编码为对应的数据
4.3.2 网络传输效率问题
grpc采用HTTP2.0,相对于HTTP1.0 在更快的传输和更低的成本两个目标上做了改进。有以下几个基本点:
-
HTTP2 未改变HTTP的语义(如GET/POST等),只是在传输上做了优化
-
引入帧、流的概念,在TCP连接中,可以区分出多个request/response
-
一个域名只会有一个TCP连接,借助帧、流可以实现多路复用,降低资源消耗
-
引入二进制编码,降低header带来的空间占用
HTTP1.0核心问题在于:在同一个TCP连接中,没办法区分response是属于哪个请求,一旦多个请求返回的文本内容混在一起,则没法区分数据归属于哪个请求,所以请求只能一个个串行排队发送。这直接导致了TCP资源的闲置。
HTTP2为了解决这个问题,提出了流的概念,每一次请求对应一个流,有一个唯一ID,用来区分不同的请求。基于流的概念,进一步提出了帧,一个请求的数据会被分成多个帧,方便进行数据分割传输,每个帧都唯一属于某一个流ID,将帧按照流ID进行分组,即可分离出不同的请求。这样同一个TCP连接中就可以同时并发多个请求,不同请求的帧数据可穿插在一起,根据流ID分组即可。这样直接解决了HTTP1.0的核心痛点,通过这种复用TCP连接的方式,不用再同时建多个连接,提升了TCP的利用效率。
HTTP/2 相对于 HTTP/1.0 在传输优化上的核心改进(分点):
- 保持 HTTP 语义不变
未改变 GET/POST 等请求方法、状态码等核心语义,仅优化数据传输方式。 - 引入帧和流的概念
- 流:每个请求对应唯一 ID 的流,用于区分不同请求。
- 帧:请求数据被拆分为多个帧,每个帧标记所属流 ID,实现数据分割传输。
- 实现多路复用
- 一个域名仅建立一个 TCP 连接。
- 多个请求的帧可在同一连接中穿插传输,通过流 ID 分组还原数据,解决 HTTP/1.0 串行排队问题。
- 采用二进制编码
降低头部信息的空间占用,减少传输成本。 - 提升 TCP 利用效率
避免 HTTP/1.0 中多连接资源浪费,通过复用单连接并发处理请求,减少闲置。
4.5 RPC注册发现
服务注册与发现:
- 服务注册与发现是分布式系统中,让服务之间能找到并通信的 “导航系统”,核心解决 “服务在哪” 和 “如何找到服务” 的问题,分两部分理解:
核心作用:
- 解决分布式环境下服务地址动态变更的问题,让调用方无需硬编码地址即可灵活、可靠地找到并调用服务,是 RPC 框架实现跨服务通信的基础。
1.服务注册
- 谁来做:服务启动时(比如一个支付服务、用户服务),主动把自己的 “地址信息”(IP、端口、服务名称等)告诉一个专门的 “中介”(叫注册中心,比如 Zookeeper、Consul)。
- 目的:让其他服务知道 “我在这里,可以调用我”。
2. 服务发现
- 谁来做:当 A 服务需要调用 B 服务时,A 先去 “注册中心” 查 “B 服务现在有哪些地址可用”。
- 过程:注册中心返回 B 的可用地址列表,A 从中选一个(比如用轮询、随机等策略),直接调用 B。
RPC 服务注册与发现的基本原理可概括为 “注册 - 维护 - 发现 - 调用” 四个核心步骤:
- 服务注册
服务启动时,主动向注册中心(如 Zookeeper、Consul)提交自身信息(IP、端口、服务名等),注册中心将这些信息记录为 “可用服务”。 - 状态维护
服务通过定期发送 “心跳” 给注册中心证明自己存活;注册中心若长时间未收到心跳,会将该服务标记为 “不可用” 并从列表中移除(健康检查)。 - 服务发现
客户端需要调用服务时,向注册中心查询目标服务的可用地址列表;注册中心返回最新的可用地址,客户端本地缓存该列表并定期刷新(应对服务动态变化)。 - 负载均衡调用
客户端从缓存的地址列表中,通过预设策略(如轮询、随机)选择一个服务地址,直接发起远程调用。
整个过程通过注册中心作为 “中介”,动态维护服务地址信息,让客户端无需关心服务的具体位置和状态,即可实现灵活、可靠的远程通信。gRPC开源组件官方并未直接提供服务注册与发现的功能实现,但其设计文档已提供实现的思路,并在不同语言的gRPC代码API中已提供了命名解析和负载均衡接口供扩展。其实现基本原理:1. 服务启动后gRPC客户端向命名服务器发出名称解析请求,名称将解析为一个或多个IP地址,每个IP地址标示它是服务器地址还是负载均衡器地址,以及标示要使用那个客户端负载均衡策略或服务配置。2. 客户端实例化负载均衡策略,如果解析返回的地址是负载均衡器地址,则客户端将使用grpclb策略,否则客户端使用服务配置请求的负载均衡策略。3. 负载均衡策略为每个服务器地址创建一个子通道(channel)。4. 当有RPC请求时,负载均衡策略决定那个子通道即gRPC 服务器将接收请求,当可用服务器为空时客户端的请求将被阻塞。根据gRPC官方提供的设计思路,基于进程内LB方案(阿里开源的服务框架 Dubbo 也是采用类似机制),结合分布式一致的组件(如Zookeeper、Consul、Etcd),可找到gRPC服务发现和负载均衡的可行解决方案。此方案将LB的功能集成到服务消费方进程里,也被称为软负载或者客户端负载方案。服务提供方启动时,首先将服务地址注册到服务注册表,同时定期报心跳到服务注册表以表明服务的存活状态,相当于健康检查,服务消费方要访问某个服务时,它通过内置的LB组件向服务注册表查询,同时缓存并定期刷新目标服务地址列表,然后以某种负载均衡策略 (Round Robin, Random, etc) 选择一个目标服务地址,最后向目标服务发起请求。LB和服务发现能力被分散到每一个服务消费者的进程内部,同时服务消费方和服务提供方之间是直接调用,没有额外开销,性能比较好。
4.6 gRPC 4种模式
4.6.1 简答记忆模式
- Unary RPC(简单 RPC)
客户端发送一个请求,服务端返回一个响应(类似普通函数调用),是最基础的模式。 - Server Streaming Streaming RPC(服务端流式 RPC)
客户端发一个请求,服务端返回连续的数据流(多个响应),直到结束(如实时日志推送)。 - Client Streaming RPC(客户端流式 RPC)
客户端发送连续的数据流(多个请求),服务端处理完成后返回一个响应(如大文件分片上传)。 - Bidirectional Streaming RPC(双向流式 RPC)
客户端和服务端可同时发送流式数据,双方独立读写(如实时聊天、游戏对战)。
4.6.2 详细解答
1. 一元RPC模式
一元 RPC 模式也被称为简单 RPC 模式。在该模式中,当客户端调用服务器端的远程方法时,客户端发送请求至服务器端并获得一个响应,与响应一起发送的还有状态细节以及 trailer 元数据。
2. 服务器端流RPC模式
在一元 RPC 模式中,gRPC 服务器端和 gRPC 客户端在通信时始终只有一个请求和一个响应。在服务器端流 RPC 模式中,服务器端在接收到客户端的请求消息后,会发回一个响应的序列。这种多个响应所组成的序列也被称为“流”。在将所有的服务器端响应发送完毕之后,服务器端会以 trailer 元数据的形式将其状态发送给客户端,从而标记流的结束。
3. 客户端流RPC模式
在客户端流 RPC 模式中,客户端会发送多个请求给服务器端,而不再是单个请求。服务器端则会发送一个响应给客户端。但是,服务器端不一定要等到从客户端接收到所有消息后才发送响应。基于这样的逻辑,我们可以在接收到流中的一条消息或几条消息之后就发送响应,也可以在读取完流中的所有消息之后再发送响应。
4. 双向流RPC模式
在双向流 RPC 模式中,客户端以消息流的形式发送请求到服务器端,服务器端也以消息流的形式进行响应。调用必须由客户端发起,但在此之后,通信完全基于 gRPC 客户端和服务器端的应用程序逻辑。
4.6.3 trailer 元数据
在 gRPC 中,trailer 元数据是一种特殊的元数据,用于在 RPC 调用的最后阶段传递附加信息,与 “请求开始时发送的元数据(header)” 相对应。
简单说:
- header:是 RPC 调用刚开始时,客户端或服务端发送的元数据(如认证信息、超时设置等)。
- **trailer:**是 RPC 调用即将结束时,服务端(或客户端)发送的元数据,通常用于传递与本次调用结果相关的补充信息,比如:
- 调用的状态细节(如错误码、处理耗时);
- 流模式中标记流的结束(如服务器端流结束时的收尾信息);
- 其他需要在响应完成后才确定的附加数据。
trailer 的核心作用是在不影响主响应数据的前提下,传递 “调用结束时才产生” 的额外信息,保证通信的完整性和灵活性。
4.7 gRPC同步异步模式
4.7.1 基本概念概览
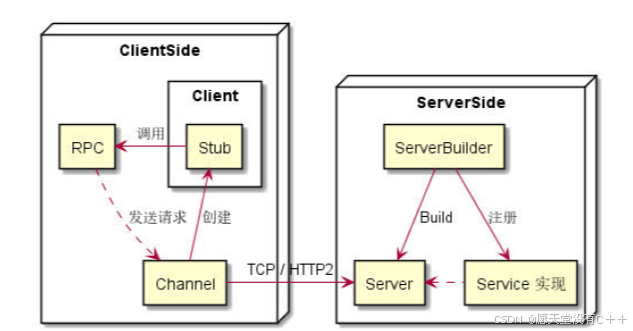
上图中列出了 gRPC 基础概念及其关系图。其中包括:Service(定义)、RPC、API、Client、Stub、Channel、Server、Service(实现)、ServiceBuilder 等。
RPC 和 API 的区别:RPC (Remote Procedure Call) 是一次远程过程调用的整个动作,而 API(Application Programming Interface) 是不同语言在实现 RPC 中的具体接口。一个 RPC 可能对应多种API,比如同步的、异步的、回调的。一次 RPC 是对某个 API 的一次调用。
不管是哪种类型 RPC,都是由 Client 发起请求。
4.7.2 RPC 和 API 的区别
RPC(远程过程调用)和 API(应用程序接口)是软件开发中两个容易混淆的概念,二者既有关联又有本质区别。以下从核心定义、作用范围、实现方式等方面详细对比:
- 核心定义
- API(应用程序接口)
是一个抽象的规范或契约,定义了不同软件组件(如函数、类、服务)之间如何交互的规则。它规定了 “能调用什么功能”“需要传入什么参数”“会返回什么结果”,但不限制具体的实现方式(比如用 HTTP、RPC 还是本地函数调用)。
例如:手机 APP 调用后端 “获取用户信息” 的接口,API 就定义了请求参数(用户 ID)和返回格式(用户名、年龄等)。 - RPC(远程过程调用)
是一种具体的通信技术,允许一台计算机的程序调用另一台计算机的程序(过程 / 函数),就像调用本地函数一样,屏蔽了远程通信的细节(如网络传输、序列化等)。
例如:服务 A 通过 RPC 调用服务 B 的 “计算订单金额” 函数,无需手动处理网络请求。
- 本质区别:抽象规范 vs 具体技术
| 维度 | API | RPC |
|---|---|---|
| 性质 | 抽象的 “交互规则”( WHAT to do ) | 具体的 “远程调用技术”( HOW to do ) |
| 范围 | 可用于本地(如类的方法)或远程交互 | 仅用于远程程序间的调用 |
| 关注点 | 定义 “接口格式”(输入、输出、功能) | 解决 “远程调用的实现”(网络、序列化) |
| 依赖关系 | RPC 可以是 API 的一种实现方式 | API 可以基于 RPC 技术设计 |
- 实现方式与场景
- API 的实现方式
API 是抽象规则,其具体实现可以是:- 本地函数调用(如 Java 类的 public 方法);
- 远程调用(如基于 HTTP 的 REST API、基于 RPC 的接口);
- 甚至硬件接口(如打印机的驱动 API)。
最常见的远程 API 是REST API(基于 HTTP 协议,通过 URL 和 JSON 传递数据)。
- RPC 的实现方式
RPC 是具体技术,通常基于自定义协议(如 gRPC 基于 HTTP/2 和 Protocol Buffers),或使用 TCP 直接传输。其核心是 “模拟本地调用”,例如:- gRPC:通过 protobuf 定义接口,生成客户端 / 服务端代码,底层用 HTTP/2 传输;
- Dubbo:基于 TCP 的二进制协议,更轻量高效。
- 典型场景对比
- 用 API 但不用 RPC:
前端(浏览器)调用后端接口(REST API),通过 HTTP 协议传递 JSON,遵循 API 规范,但不涉及 RPC 技术。 - 用 RPC 且遵循 API:
微服务中,服务 A 调用服务 B 的 “库存扣减” 功能,双方通过 gRPC 通信(RPC 技术),同时接口定义了参数和返回值(API 规范)。 - 本地 API:
同一个程序中,一个类调用另一个类的方法(如UserService.getUserId()),这是本地 API,与 RPC 无关。
总结
- API 是 “接口规范”:定义了 “如何交互”,覆盖本地和远程场景,是更宽泛的概念。
- RPC 是 “远程调用技术”:解决了 “远程如何像本地一样调用”,是 API 在远程场景下的一种实现方式。
简单说:RPC 可以实现 API,而 API 不一定依赖 RPC。
4.7.3 同步模式
核心特点
同步模式中,调用方会阻塞当前线程,直到获取响应或发生错误,流程类似 “请求 - 等待 - 响应” 的阻塞式交互。
工作流程
-
客户端发起 RPC 调用后,当前线程进入阻塞状态,暂停执行后续逻辑;
-
服务器接收到请求后,在处理线程中同步处理并返回响应;
-
客户端收到响应后,阻塞解除,继续执行后续代码。
4.7.4 异步模式
核心特点:
- 异步模式中,调用方发起请求后立即返回,不阻塞当前线程,通过回调函数或轮询方式处理响应,适合高并发场景。
工作流程:
-
客户端发起异步 RPC 调用,指定回调函数(或注册完成通知),立即返回;
-
当前线程可继续处理其他任务,无需等待响应;
-
服务器处理完成后,响应通过底层 I/O 线程通知客户端;
-
客户端通过事件循环触发回调函数,处理响应结果。
关键组件:
-
CompletionQueue:用于接收异步操作的完成通知(客户端和服务器均需使用);
-
Tag:关联异步操作的标识,用于在回调中区分不同的 RPC 请求;
-
事件循环:不断从
CompletionQueue中获取完成的操作并触发处理逻辑。
4.7.5 gRPC 异步模式的实现细节
gRPC 异步模式基于底层 I/O 线程池和事件驱动模型:
-
客户b 端 / 服务器启动时会创建少量 I/O 线程(默认与 CPU 核心数一致),负责处理网络通信;
-
异步 RPC 操作的网络交互由 I/O 线程完成,不阻塞业务线程;
-
操作完成后,I/O 线程将结果放入
CompletionQueue,业务线程通过轮询cq.Next()获取并处理。