[论文阅读] 人工智能 + 软件工程 | 代码变更转自然语言生成中的幻觉问题研究解析
代码变更转自然语言生成中的幻觉问题研究解析
论文信息
- 原标题:Hallucinations in Code Change to Natural Language Generation: Prevalence and Evaluation of Detection Metrics
- 主要作者:Chunhua Liu, Hong Yi Lin, Patanamon Thongtanunam
- 研究机构:School of Computing and Information Systems, The University of Melbourne
- APA引文格式:Liu, C., Lin, H. Y., & Thongtanunam, P. (2025). Hallucinations in code change to natural language generation: Prevalence and evaluation of detection metrics. arXiv preprint arXiv:2508.08661v1 [cs.SE]. https://arxiv.org/abs/2508.08661v1
一段话总结
该论文首次全面分析了代码变更到自然语言生成(CodeChange2NL)任务中幻觉的问题,聚焦提交信息生成和代码评审评论生成两大任务,发现约50%的生成代码评审和20%的生成提交信息存在幻觉,主要类型为输入不一致、逻辑不一致和意图偏离;同时评估了多种检测指标,发现单一指标效果有限,而组合多个指标(尤其是模型置信度和特征归因等无参考指标)可显著提升检测性能,为实时检测提供了可能。
研究背景
随着AI技术在软件工程领域的普及,基于语言模型的工具被广泛用于代码生成、提交信息撰写、代码评审等任务,极大提升了开发效率。然而,这些工具依赖的语言模型存在“幻觉”问题——生成与输入不一致或虚构的信息,就像人“凭空捏造”内容一样。
例如,在代码评审中,模型可能错误指出代码中存在某个未定义的变量;在提交信息中,模型可能误判代码变更的目的(如将“新增低版本支持”描述为“修复高版本问题”)。这类幻觉可能导致开发者浪费时间验证错误信息,甚至引入代码缺陷。
此前,幻觉研究多集中在纯代码生成或纯自然语言生成任务,而代码变更作为软件工程中的常见输入(包含新旧代码片段),因需要模型处理多状态代码和部分上下文,可能加剧幻觉风险,但相关研究几乎空白。因此,理解CodeChange2NL任务中的幻觉问题并找到有效检测方法,成为提升AI工具可靠性的关键。
创新点
- 首次聚焦CodeChange2NL任务:针对代码变更这一特殊输入形式,系统分析幻觉的发生率和类型,填补了该领域研究空白。
- 定制化幻觉标注流程:基于代码变更的特性,设计了决策树式的标注体系,能更精准地区分幻觉类型(如输入不一致、意图偏离等)。
- 全面评估检测指标:对比了参考型和无参考型指标的效果,发现无参考指标(如模型置信度、特征归因)在缺乏真实参考时仍能有效检测幻觉,解决了实际应用中参考数据不足的问题。
研究方法和思路、实验方法
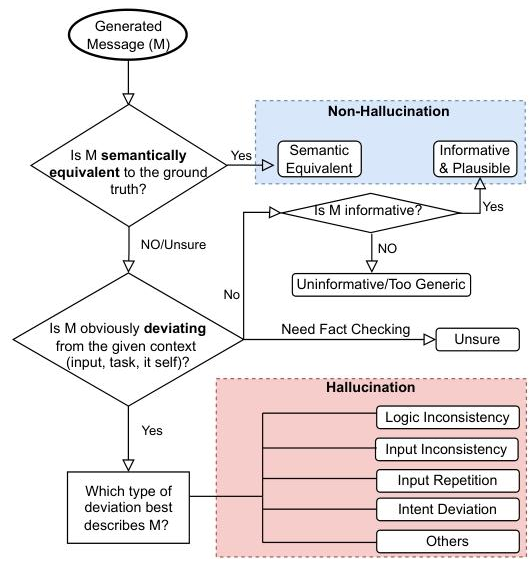
1. 幻觉标注流程
- 步骤1:判断生成文本与真实参考是否语义等价,等价则为非幻觉。
- 步骤2:不等价时,评估是否偏离上下文(代码输入、任务目标、文本自身)。
- 步骤3:若偏离,分类为五大幻觉类型:输入不一致(与代码冲突)、逻辑不一致(内部矛盾)、输入重复(复制输入)、意图偏离(脱离任务目标)、其他。
2. 实验设计
- 数据集:
- 代码评审任务:CodeReviewer,含118k训练、10k验证、10k测试样本,覆盖9种编程语言。
- 提交信息任务:CommitBench,含116万训练、25万验证/测试样本,覆盖6种编程语言。
- 模型选择:选取微调后的Qwen2.5-7B、Llama3.1-8B、CCT5(220M),因它们在BLEU-4指标上表现最优。
- 检测指标:
- 参考型:BLEU-4(词重叠)、NLI(自然语言推理,判断生成文本与参考的逻辑关系)。
- 无参考型:相似度(生成文本与代码的语义相似度)、不确定性(模型生成时的置信度,如logit、熵)、特征归因(输入对生成的影响程度)。
- 评估方法:用ROC-AUC衡量检测效果,值越接近1越好;通过逻辑回归组合多个指标,分析其性能提升。
主要贡献
| 核心贡献 | 具体内容 |
|---|---|
| 1. 系统表征幻觉 | 首次揭示CodeChange2NL任务中幻觉的发生率(代码评审50%、提交信息20%)和主要类型(输入不一致为主),为后续研究提供基础🔶1-17🔶1-65🔶。 |
| 2. 优化检测方法 | 证明组合多个指标可显著提升检测效果(代码评审ROC-AUC从56.6%→69.1%,提交信息从61.7%→75.3%),解决了单一指标效果差的问题🔶1-17🔶1-103🔶。 |
| 3. 支持实时检测 | 发现无参考指标(如Llama3.1的logit、CCT5的特征归因)表现接近全指标组合,无需真实参考即可检测,适用于生产环境🔶1-18🔶1-103🔶。 |
- 开源信息:所有代码和数据将在论文接受后发布。
关键问题
-
Q:代码变更到自然语言生成任务中,幻觉的发生率有多高?
A:约50%的生成代码评审和20%的生成提交信息存在幻觉,代码评审任务的幻觉风险更高🔶1-17。 -
Q:主要的幻觉类型有哪些?
A:输入不一致(与代码冲突)、逻辑不一致(内部矛盾)、意图偏离(脱离任务目标),其中输入不一致最为常见🔶1-17。 -
Q:单一检测指标的效果如何?
A:效果有限,仅略高于随机猜测(代码评审ROC-AUC 56.6%,提交信息61.7%)🔶1-17。 -
Q:如何提升幻觉检测效果?
A:组合多个指标,尤其是无参考指标(如模型置信度和特征归因),可显著提升性能🔶1-17。 -
Q:无参考指标能否替代参考型指标?
A:可以,其检测效果接近全指标组合,适用于缺乏真实参考的场景。
总结
该论文通过系统研究,揭示了代码变更到自然语言生成任务中幻觉的严重性——约一半的代码评审和五分之一的提交信息存在幻觉,且输入不一致是主要问题。研究还证明,单一指标检测效果有限,而组合模型置信度、特征归因等无参考指标,可有效提升检测性能,为实际开发中实时识别幻觉提供了可行方案。这一研究不仅填补了CodeChange2NL任务中幻觉研究的空白,还为提升AI软件工程工具的可靠性奠定了基础。