Neural Bandit Based Optimal LLM Selection for a Pipeline of Tasks
Neural Bandit Based Optimal LLM Selection for a Pipeline of Tasks
Authors: Baran Atalar, Eddie Zhang, Carlee Joe-Wong
Deep-Dive Summary:
神经网络强盗算法在任务流水线中的最优大语言模型选择
Baran Atalar, Eddie Zhang, Carlee Joe-Wong
卡内基梅隆大学,5000 Forbes Ave, Pittsburgh, PA 15213, USA
{batalar, eyzhang, cjoewong}@andrew.cmu.edu
摘要
随着大型语言模型(LLMs)在各种任务中的日益普及,预测一组LLM中哪个模型能够以低成本提供成功答案的策略引起了越来越多的关注。随着像微软这样的服务提供商允许用户轻松创建针对特定类型查询的定制LLM“助手”,这一问题将变得越来越重要。然而,某些任务(即查询)可能过于专业和复杂,单一LLM难以独立处理。这些应用通常受益于将任务分解为更小的子任务,然后由预期在特定子任务上表现良好的LLM执行每个子任务。例如,在从医疗记录中提取诊断时,可以首先选择一个LLM来总结记录,选择另一个LLM验证总结,然后选择另一个(可能不同)的LLM从总结的记录中提取诊断。与现有的LLM选择或路由算法不同,这种设置要求我们选择一系列LLM,每个LLM的输出都会输入到下一个LLM,并可能影响其成功。因此,与单一LLM选择不同,每个子任务输出的质量直接影响下游LLM的输入,从而影响成本和成功率,产生了复杂的性能依赖关系,必须在选择过程中学习和考虑。我们提出了一种基于神经上下文强盗的算法,以在线方式训练神经网络,建模每个子任务上LLM的成功情况,从而学习指导不同子任务的LLM选择,即使缺乏历史LLM性能数据。在电信问题回答和医疗诊断预测数据集上的实验表明,我们提出的方法相较于其他LLM选择算法具有有效性。
引言部分总结 (中文)
大语言模型 (LLMs) 的应用与选择挑战
大语言模型 (LLMs) 通过总结、生成和解释文本,极大地改变了众多应用领域。由于不同的训练配置和模型结构,LLMs 在不同任务上的表现差异很大,因此需要识别并选择最适合特定任务的模型。然而,随着可用 LLMs 数量的急剧增加,为特定任务选择最佳模型变得愈加复杂 (Shnitzer 等人,2023)。一些 LLM 运营商甚至允许用户构建定制化的 LLM 代理,例如 OpenAI 的市场或 Azure 的助手 (Microsoft 2025),这进一步扩大了可用于完成任务的代理范围。因此,一个自然的问题是:我们应如何选择最适合完成给定任务的 LLM 代理?
任务分解与管道式处理的复杂性
为特定任务或一系列子任务选择最合适的 LLM 带来了显著挑战,特别是在计算效率和性能优化方面 (Zhang 等人,2024; Xia 等人,2024; Zhao 等人,2023)。由于计算、成本和延迟的限制,简单地通过所有可用模型运行查询并选择表现最佳的模型并不可行 (Shazeer 等人,2017)。而简单选择最昂贵的模型可能会忽略高度专业化 LLM 在特定任务上的潜力。对于过于复杂或单个 LLM 难以处理的任务,这种朴素方法尤其不可行。这类任务通常被分解为多个子任务,每个子任务可由不同的 LLM 完成,导致可能的 LLM 组合呈指数增长,每种组合都会带来不同的成功率和成本。LLM 代理在分解和完成复杂多步任务中的“代理型”AI 应用日益流行 (Qiu 等人,2024b)。
管道式任务中的相互影响与成本考量
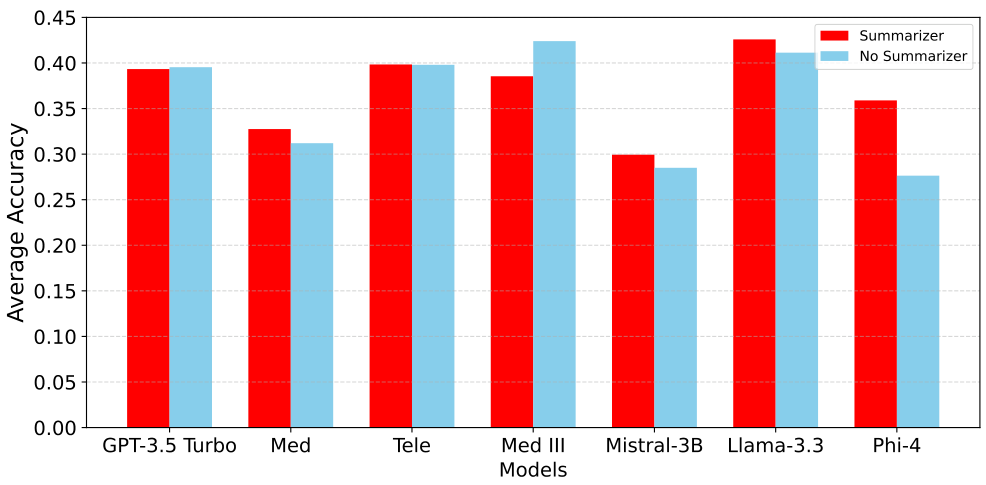
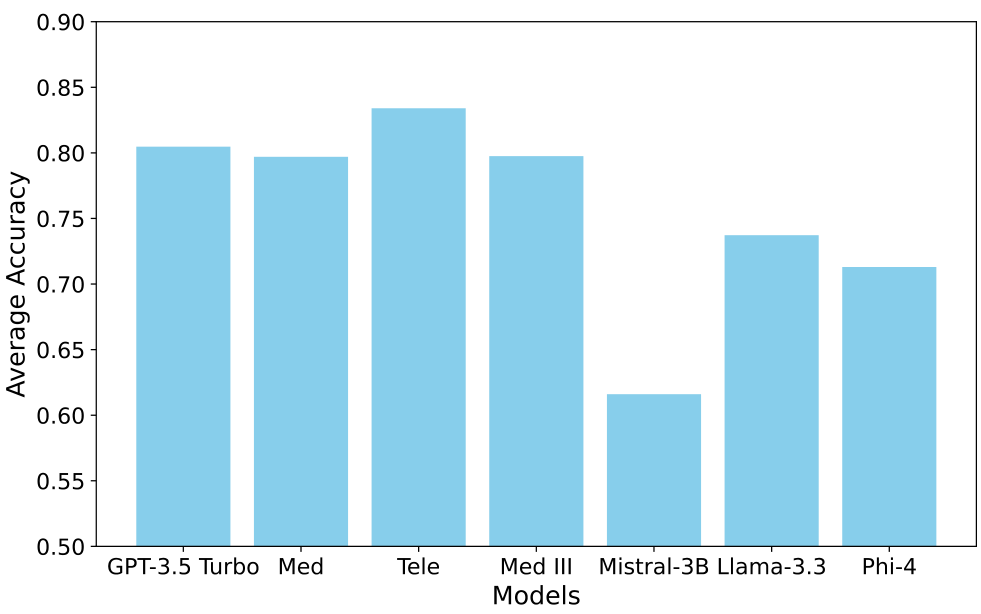
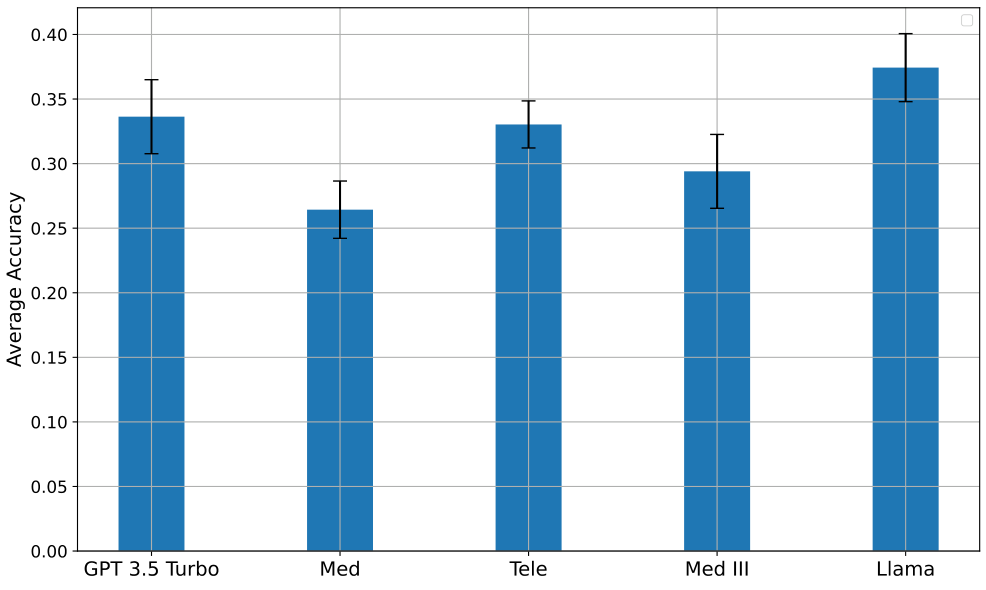
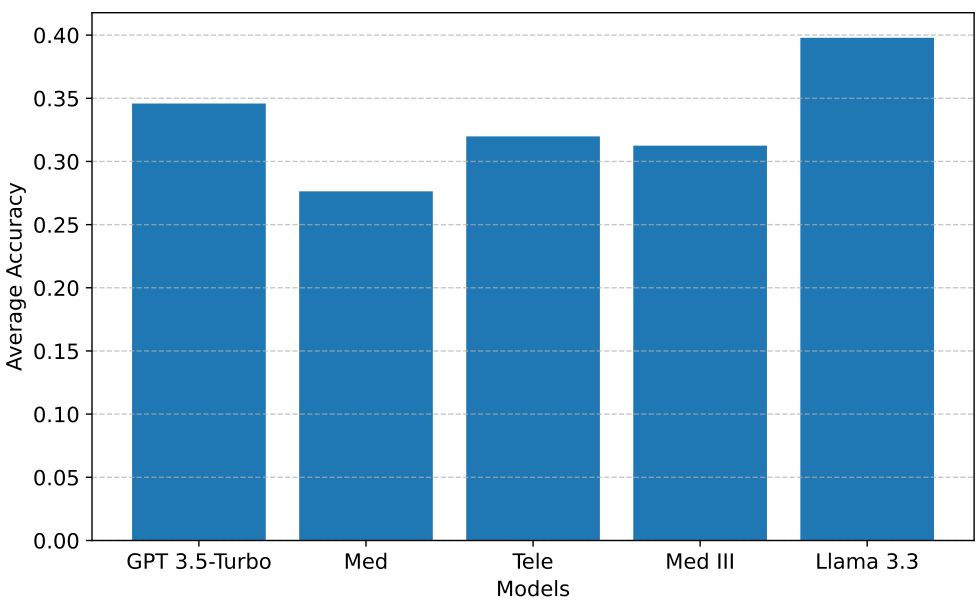
例如,图 1 显示了 LLMs 在从医疗报告预测医疗诊断任务中的平均准确率。结果表明,先使用一个总结型 LLM 处理输入,再将其输出作为诊断型 LLM 的提示(即采用管道式方法),比单独使用单个 LLM 表现更好。只有 Med III 模型在使用总结器时准确率明显下降,这可能是因为该模型是基于相同数据集微调的 GPT-4o 模型。使用总结器还改变了诊断任务的最佳模型选择:没有总结器时 Med-III 模型表现最佳,而允许使用总结器时 Llama 表现最佳。因此,管道中早期任务选择的 LLM 可能会影响后续的最佳选择,增加了决策复杂性。此外,总结任务中选择的 LLM 会影响诊断任务中不同 LLM 的成本,因为诊断成本通常与输入 token 数量成正比,而 token 数量取决于总结内容的长度和生成总结的 LLM。
研究挑战与在线学习方法
在实际应用中,用户可能缺乏特定任务类型下 LLM 性能的历史数据,特别是对于一些定制化的“助手”模型。因此,一个自然的解决方案是采用在线方法,用户在发送查询/任务时同时学习和优化 LLM 选择。在线 LLM 选择可视为经典上下文多臂老虎机 (MAB) 问题的一个实例 (Chu 等人,2011; Chen, Wang, 和 Yuan,2013)。每个 LLM 可建模为一个“臂”,MAB 算法依次拉动该臂(即向 LLM 提交查询),监控查询提交的成功情况,并利用反馈影响未来的 LLM 选择。MAB 在探索(尝试新模型以期望超越当前最佳模型)和利用(选择当前发现的最佳模型)之间取得平衡。然而,传统的上下文 MAB 方法无法捕捉任务管道中 LLM 选择的顺序性问题,因此本文提出了一种专为顺序 LLM 选择设计的新型 MAB 变体。
本文主要贡献
- 提出了一种新颖的问题公式,即选择一组 LLM 管道来解决分解为相互关联的较小子任务的任务。
- 将上下文 MAB 算法改编为顺序 bandits 算法 (Sequential Bandit),该算法在任务管道中顺序选择 LLMs,利用神经网络有效学习每个 LLM 在管道中每个子任务上的成功率,并在线优化 LLM 成功率和成本的组合。
- 为评估 SeqBandits 算法,基于现有医疗数据集 (Johnson 等人,2016) 创建了一个新的诊断预测数据集。
- 实验证明 SeqBandits 算法在管道式医疗诊断预测任务和电信数据集上比现有 MAB 算法识别出更好的 LLMs。
相关工作总结
以下是对论文中“Related Work”部分的中文总结,保留了原文中的 markdown 格式和图片位置。
问题建模总结(中文)
以下是对论文中“Problem Formulation”部分的中文总结,保留了原文中的图片部分及其格式。
问题建模
我们考虑了多轮次的问题,其中每一轮 t=1,2,…t = 1, 2, \dotst=1,2,… 由一个输入查询 qtq_tqt 定义。在我们的建模中,我们假设一个任务已经被分解为一系列更简单的子任务 {T1,T2,…,Tk}\{T_1, T_2, \dots, T_k\}{T1,T2,…,Tk},这些子任务构成一个有向无环图(DAG),因为一个子任务的输出会成为下一个子任务的输入。例如,一个查询可能是基于医疗报告进行诊断预测,分解为以下子任务:(i) 总结报告,(ii) 验证总结,(iii) 基于验证后的总结预测诊断。在本文的剩余部分中,我们假设这 kkk 个子任务是给定的,我们的目标是为每个子任务选择能够提供最高准确率的大型语言模型(LLM)。需要注意的是,一个特殊情况是查询只有一个子任务(即查询本身)。
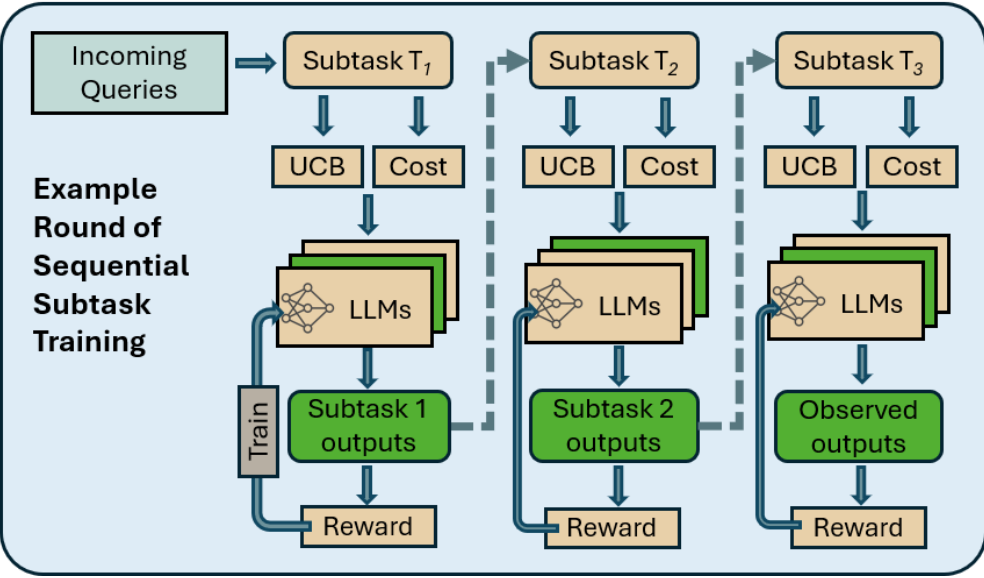
如图2所示,我们的问题设置是一个流水线/顺序处理方式。这种方法在本质上类似于流行的思维链(Chain-of-Thought, CoT)提示方法(Wei等,2023年),但我们允许不同的LLM完成各个子任务,而不像CoT那样由单一LLM分解任务并完成所有子任务。接下来,我们对这一选择问题进行形式化描述。我们用 [N][N][N],其中 N∈Z+N \in \mathbb{Z}^+N∈Z+,表示集合 {1,2,…,N}\{1, 2, \dots, N\}{1,2,…,N}。
bandit 建模
在本文中,我们将LLM选择问题建模为一个神经上下文bandit问题。我们考虑 TTT 轮次。子任务 {T1,T2,…,Tk}\{T_1, T_2, \dots, T_k\}{T1,T2,…,Tk} 分别对应 {N1,N2,…,Nk}\{N_1, N_2, \dots, N_k\}{N1,N2,…,Nk} 个可用的LLM,我们将每个LLM称为特定子任务的一个“臂(arm)”。我们用 MMM 表示所有LLM的集合。在每一轮 ttt,代理为查询 qtq_tqt 的每个子任务选择一个臂(LLM),我们将所选的整体臂集合称为超级臂 StS_tSt,遵循组合bandit文献的命名(Chen, Wang, Yuan 2013)。形式上,对于每个子任务 TiT_iTi(其中 i∈{1,…,k}i \in \{1, \dots, k\}i∈{1,…,k}),选择一个臂 ai,ja_{i,j}ai,j,其中 j∈[Ni]j \in [N_i]j∈[Ni]。则 St=(a1,j,a2,j,…,ak,j)S_t = (a_{1,j}, a_{2,j}, \dots, a_{k,j})St=(a1,j,a2,j,…,ak,j),其中 ai,ja_{i,j}ai,j 表示为子任务 iii 从 [Ni][N_i][Ni] 中选择的臂 jjj。当在第 ttt 轮选择了超级臂 StS_tSt 时,代理观察到所选超级臂的基础臂奖励,即 {rt,j}ai,j∈St\{r_{t,j}\}_{a_{i,j} \in S_t}{rt,j}ai,j∈St,并获得总奖励(超级臂奖励)R(St,rt)R(S_t, r_t)R(St,rt),其中 rt=[rt,j]ai,j∈Str_t = [r_{t,j}]_{a_{i,j} \in S_t}rt=[rt,j]ai,j∈St,即超级臂奖励是各个基础臂奖励的函数。在我们的设置中,基础臂奖励对应于该臂所属子任务结果的“优度”,而超级臂奖励是LLM在查询上的整体结果优度的度量,是所选基础臂奖励的函数。例如,超级臂奖励可以是流水线中最后一个LLM在预测任务(如医疗诊断)中返回的输出准确率,这是返回给用户的最终输出。
我们还考虑了为每个子任务部署所选LLM的成本。虽然我们将其视为货币成本,但也可以将其视为能量消耗或LLM在给定子任务上的推理延迟。我们根据所选LLM的输入和输出令牌数计算成本,并将使用LLM jjj 处理子任务查询 qtq_tqt 的预测成本记为 Cj(qt)C_j(q_t)Cj(qt)。关于 CjC_jCj 的构建细节将在下一节中进一步说明。
上下文、奖励和成本估计
在每一轮 ttt,代理观察每个臂 ai,ja_{i,j}ai,j 的上下文 xt(ai,j)x_t(a_{i,j})xt(ai,j)(其中 i∈{1,…,k},j∈[Ni]i \in \{1, \dots, k\}, j \in [N_i]i∈{1,…,k},j∈[Ni]),这有助于指导预测LLM jjj 在子任务 iii 上的成功概率。在我们的应用中,上下文 xt(ai,j)x_t(a_{i,j})xt(ai,j) 是子任务 i∈{1,…,k}i \in \{1, \dots, k\}i∈{1,…,k} 给定提示的函数,该提示是前一子任务 i−1i-1i−1 所选LLM的输出(如图2所示),以及对应于臂 (i,j)(i, j)(i,j) 的LLM的特征。在我们的实验中,这些特征包括LLM能力的描述,以及它是否针对特定任务的数据集进行了微调,还是仅为未微调的通用LLM。关于如何构建臂的上下文的更多细节将在补充材料中提供。我们将LLM jjj 的描述记为 djd_jdj,所有可用LLM的描述集合记为 DDD。
遵循神经bandit的先前工作,我们使用神经网络学习底层奖励函数。基础臂奖励 rt(ai,j)r_t(a_{i,j})rt(ai,j) 的生成方式如下(Zhou, Li, Gu 2020; Zhang et al. 2021):
rt(ai,j)=hi,j(xt(ai,j))+ϵtr_t(a_{i,j}) = h_{i,j}(x_t(a_{i,j})) + \epsilon_t rt(ai,j)=hi,j(xt(ai,j))+ϵt
其中 hi,jh_{i,j}hi,j 是臂 ai,ja_{i,j}ai,j 的未知奖励函数,ϵt\epsilon_tϵt 是零均值噪声,用于建模不确定性。我们为不同的(子任务,臂)组合设置不同的奖励函数,因为每个组合对应于不同的模型结构和任务。为了学习基础臂奖励函数 hi,jh_{i,j}hi,j,我们使用深度为 L+1≥3L+1 \geq 3L+1≥3、宽度为 nnn 的全连接神经网络,定义如下:
fi,j(x;θ)=mWi,j(L)σ(Wi,j(L−1)σ(…σ(Wi,j(0)x)))f_{i,j}(x; \theta) = \sqrt{m} W_{i,j}^{(L)} \sigma(W_{i,j}^{(L-1)} \sigma(\dots \sigma(W_{i,j}^{(0)} x))) fi,j(x;θ)=mWi,j(L)σ(Wi,j(L−1)σ(…σ(Wi,j(0)x)))
其中 σ(x)=max{x,0}\sigma(x) = \max\{x, 0\}σ(x)=max{x,0} 是ReLU激活函数,θi,j\theta_{i,j}θi,j 是权重向量。我们还定义了神经网络的梯度为 gi,j(x;θi,j)=∇θi,jfi,j(x;θi,j)g_{i,j}(x; \theta_{i,j}) = \nabla_{\theta_{i,j}} f_{i,j}(x; \theta_{i,j})gi,j(x;θi,j)=∇θi,jfi,j(x;θi,j)。
成本 Cj(qt)C_j(q_t)Cj(qt) 建模为输入和输出令牌数,乘以LLM jjj 在Microsoft Azure中的每输入令牌和输出令牌成本(更多细节见补充材料)。我们知道输入令牌数,因为 qtq_tqt 是给定的,但在选择LLM jjj 之前,我们不知道它对于给定输入提示会输出多少令牌。为了解决这一挑战,我们训练了一个输出令牌长度预测模型,如Qiu等(2024a)所述,详见实验部分。
代理目标
代理的主要目标是最大化奖励(准确率),同时最小化部署LLM的成本。为了将这两个指标合并为一个,我们定义时间 ttt 的净奖励为 N(t)=R(St,rt)−Q⋅C(St)N(t) = R(S_t, r_t) - Q \cdot C(S_t)N(t)=R(St,rt)−Q⋅C(St),其中 Q=[Q1,Q2,…,Qk]Q = [Q_1, Q_2, \dots, Q_k]Q=[Q1,Q2,…,Qk] 权衡每个子任务的奖励和成本的相对重要性,C(St)C(S_t)C(St) 是所选LLM的成本向量。最大化奖励同时也导致最小化遗憾(regret),这是多臂bandit(MAB)中的一个标准度量,衡量最优臂和所选臂之间的奖励差距。形式上,遗憾定义为 R(T)=∑t=1T[R(St∗,rt)−R(St,rt)]R(T) = \sum_{t=1}^T [R(S_t^*, r_t) - R(S_t, r_t)]R(T)=∑t=1T[R(St∗,rt)−R(St,rt)],其中 St∗S_t^*St∗ 表示第 ttt 轮的最优超级臂,即产生最高奖励的臂组合,R(St,rt)R(S_t, r_t)R(St,rt) 是我们所选超级臂在第 ttt 轮的奖励。
序列 bandits 算法
在本节中,我们提出了我们的算法——序列 bandits(Sequential Bandits,算法 1),旨在最大化净回报。序列 bandits 是一种基于神经网络的上下文 bandit 算法,为每个(子任务,大语言模型 LLM)组合初始化一个神经网络。图 2 展示了这些网络如何使用奖励反馈进行训练,这在算法 1 中有正式描述。
任务首先被分解成更易于 LLM 处理的简单子任务,然后开始在线训练循环。对于第一个子任务,我们为每个可用的 LLM 构建一个关于奖励的上置信界(UCB),使用神经网络估计进行利用(exploitation),并使用其梯度进行探索(exploration)(第 6 行),类似于 Zhou、Li 和 Gu (2020) 的方法。这里我们用正定矩阵 AAA 表示 l2l_2l2 范数,定义为 ∣x∣A:=xTAx|x|_A := \sqrt{x^T A x}∣x∣A:=xTAx。然而,与 Zhou、Li 和 Gu (2020) 不同的是,我们的算法引入了一个成本敏感参数 QQQ,该参数与成本项 CCC(即使用所选 LLM jjj 处理子任务 iii 的预测成本)相乘,然后从 UCB 项中减去。设置 Q=0Q = 0Q=0 会退化为不考虑成本的情况,而 Q>0Q > 0Q>0 表示代理对成本敏感。由于成本项在第 6 行从 UCB 项中减去,这导致了准确性和成本之间的权衡。随着 QQQ 值的增大,算法将倾向于选择成本较低的模型,优先考虑模型成本而非模型在给定任务上的准确性。
神经网络的输入是每个 LLM jjj 的描述 ddd 的嵌入以及传入查询 qtq_tqt 的函数。然后,我们选择具有最高奖励估计的 LLM(第 7 行),并将所选 LLM 的输出作为管道中下一个子任务的输入提示(第 8-9 行)。对于其他子任务,我们遵循相同的步骤,只是输入提示不再是输入查询 qtq_tqt,而是管道中下一阶段(下一个子任务)的 LLM 的输入提示,即前一个所选 LLM 的输出(第 11-14 行)。为每个子任务选择 LLM 后,我们观察相应的奖励以及整体超级臂奖励 R(St,rt)R(S_t, r_t)R(St,rt),这是子任务奖励的函数(第 17 行)。然后,我们使用观察到的奖励以及探索参数更新所选 LLM 对应网络的权重(第 18-19 行)。
引入成本:另一种引入成本项的方法是施加成本约束(例如,每个查询或任务的货币预算),而不是将其纳入目标函数中。然而,由于 LLM 推理成本在查询执行前本质上是不确定的(取决于输出 token 数量),硬性预算约束可能会偏向于管道早期的子任务,因为成本低估可能导致后期子任务面临严重的预算限制。将成本纳入我们的目标函数还允许我们调整 QQQ;对于不同的子任务 iii,可能具有不同的固有成本:例如,摘要任务可能相当昂贵,因为其输入包含要摘要的长文本。
与现有神经 MAB 算法的区别:之前的神经上下文 bandit 算法(Zhou、Li 和 Gu 2020;Xu 等人 2020)可以通过简单地按顺序用于每个子任务的 LLM 选择来适应我们的任务设置。然而,此类算法为每个子任务训练并使用一个神经网络进行奖励估计和 LLM 选择。使用单一模型处理所有 LLM 并未考虑不同模型对不同子任务意味着不同的固有奖励函数这一事实。因此,序列 bandits 为每个(子任务,臂)组合使用单独的神经网络。实验表明,使用单独的神经网络鼓励更多的探索,因为对每个(子任务,臂)组合使用相同的神经网络估计器会导致更相似的成功估计。不同臂的相对排名随后被(确定的)成本估计所主导,这可能使算法过早锁定某个臂,导致高遗憾。我们注意到,使用多个神经网络并不会增加我们的训练开销:虽然我们为每个(子任务,LLM)组合使用不同的网络,但在每一轮中,我们仅训练为每个子任务选择的 LLM 的神经网络。因此,我们所需的计算量并不比其他神经上下文 bandit 算法更大。在下一节中,我们将实验比较序列 bandits 与其他上下文神经 bandit 算法的性能。
算法 1:序列赌博机 (Sequential Bandits) 总结
以下是对论文中“算法 1:序列赌博机”部分的中文总结,保持了原始 markdown 格式中的图像部分(虽然原文中未包含图像,但如果有图像位置,会在适当位置保留)。
算法描述总结
该算法提出了一种序列赌博机 (Sequential Bandits) 方法,用于在多个大型语言模型 (LLMs) 中动态选择最适合的模型来处理一系列查询任务。算法的核心目标是通过平衡性能和成本,选择最佳的 LLM 来完成每个子任务。以下是算法的主要步骤和逻辑:
- 输入与初始化:算法接收一组 LLMs、任务描述、查询序列、梯度下降步数 JJJ、学习率、成本权重参数 QiQ_iQi、轮数 TTT 以及正则化参数 λ\lambdaλ。初始时,所有臂 (arm,指代 LLM 的选择) 的计数器 Z0(ai,j)Z_0(a_{i,j})Z0(ai,j) 被初始化为 λ\lambdaλ。
- 每轮迭代 (t=1t=1t=1 到 TTT):
- 观察当前的任务描述 d∈Dd \in Dd∈D 和子任务编号 i∈{1,2,…,∣T∣}i \in \{1, 2, \dots, |T|\}i∈{1,2,…,∣T∣}。
- 对每个子任务 iii:
- 如果是第一轮 (t=1t=1t=1),计算每个 LLM 的得分 ui,ju_{i,j}ui,j,公式为 ui,j=fi,j(qt,dj)+gi,j(xt(ai,j);θ1)/nZ(ai,i)−αC(qt)u_{i,j} = f_{i,j}(q_t, d_j) + g_{i,j}(x_t(a_{i,j}); \theta_1)/\sqrt{n}Z(a_{i,i}) - \alpha C(q_t)ui,j=fi,j(qt,dj)+gi,j(xt(ai,j);θ1)/nZ(ai,i)−αC(qt),其中 fi,jf_{i,j}fi,j 和 gi,jg_{i,j}gi,j 分别表示预测奖励和探索项,C(qt)C(q_t)C(qt) 为成本项,α\alphaα 为权重参数。
- 否则,计算得分 ui,j=fi,j(pi,dj)+gi,j(xt(ai,j);θ)/Z(ai,i)−αC(pi)u_{i,j} = f_{i,j}(p_i, d_j) + g_{i,j}(x_t(a_{i,j}); \theta)/\sqrt{Z(a_{i,i})} - \alpha C(p_i)ui,j=fi,j(pi,dj)+gi,j(xt(ai,j);θ)/Z(ai,i)−αC(pi),基于当前提示 pip_ipi。
- 选择得分最高的 LLM (si=argmax(ui)s_i = \arg\max(u_i)si=argmax(ui)) 来处理查询或提示,并观察输出 pi+1p_{i+1}pi+1。
- 播放超级臂 (super arm) StS_tSt,观察每个臂的奖励 rt,jr_{t,j}rt,j 和超级臂的总奖励 R(St,rt)R(S_t, r_t)R(St,rt)。
- 更新被选中臂的计数器 Zt(ai,j)Z_t(a_{i,j})Zt(ai,j),公式为 Zt(ai,j)=Zt−1(ai,j)+1Z_t(a_{i,j}) = Z_{t-1}(a_{i,j}) + 1Zt(ai,j)=Zt−1(ai,j)+1。
- 使用梯度下降法,通过最小化均方误差 (MSE) 损失更新被选中臂的权重 θi,j\theta_{i,j}θi,j,迭代 JJJ 次,步长为学习率。
- 循环结束:完成所有轮次后,算法结束。
该算法通过结合奖励预测、探索和成本敏感性,动态选择最优的 LLM 来处理每个子任务,旨在提高整体任务性能并控制成本。
实验部分总结
实验部分介绍了所提出的序列赌博机算法在两个应用场景中的结果:医疗诊断预测和电信问题回答任务。算法与以下基线方法进行了比较:
- Random:为每个子任务随机选择一个 LLM。
- Llama:始终选择 Llama 模型(因其在多个任务中表现最佳)。
- Cost-Aware NeuralUCB (Zhou, Li, and Gu 2020):NeuralUCB 的成本敏感版本,使用神经网络预测每个子任务的奖励,并在目标函数中加入与序列赌博机相同的加权成本项。
- Cost-Aware NeuralLinUCB (Xu et al. 2020):NeuralLinUCB 的成本敏感版本,利用神经网络学习上下文表示,并在其上应用线性模型预测奖励,同时加入加权成本项。
通过与这些算法的比较,作者展示了以下几点价值:(1) 提出了一种随时间学习的非静态算法;(2) 能够智能地为每个子任务选择合适的 LLM;(3) 使用独立的神经网络预测每个 LLM 在每个子任务上的表现。
(注:原文中未包含图像部分,因此未在总结中插入图像占位符。如果原文有图像,将保留其 markdown 格式并放置在合适位置。)
实验设置
在我们的实验中,我们使用两个数据集评估了基于神经 bandits 的 LLM 选择框架的有效性:一个是从 MIMIC-III 创建的数据集(详见下一小节),这是一个包含超过 40,000 名重症患者的去身份化健康相关数据的全面临床数据库(Johnson 等人,2016 年);另一个是 TeleQnA 数据集,包含 10,000 个多选题,旨在评估 LLM 在电信领域的知识(Maatouk 等人,2023 年)。这些数据集使我们能够评估框架在多样化、领域特定任务中的表现。我们分别针对医疗和电信数据集考虑了包含 2 个和 3 个子任务的流水线。
子任务:在医疗数据集上的两个子任务分别是:(1) 一个汇总器,负责总结长篇医疗报告,其摘要随后被输入到 (2) 一个诊断器,根据摘要进行诊断。汇总子任务的奖励通过一个评估 LLM 获得,该 LLM 接收提示、上下文和基准。诊断子任务的奖励则是通过将 LLM 输出的诊断与患者的实际诊断进行比较来评估。超级臂(super arm)的奖励仅是诊断子任务准确性的函数。例如,如果一名患者有两个诊断,而为第二个子任务选择的 LLM 正确预测了其中一个诊断,我们会分配 0.5 的奖励。
对于 TeleQnA 数据集,我们采用了 3 个子任务的结构。首先是与医疗数据集的汇总任务类似奖励指标的汇总子任务。第二个子任务是回答问题,我们通过将 LLM 的输出选项(4-5 个选项中)与正确答案进行比较来计算奖励。第三个子任务是解释前一子任务获得的答案,其奖励通过与 TeleQnA 的解释基准进行比较获得。
成本预测:对于输出 token 长度预测模型,该模型用于构建 LLM 查询执行的预期成本(算法 1 中的 CjC_jCj),我们基于 LMSYS-Chat-1M 数据集(Zheng 等人,2023 年)使用 L1 损失训练了一个 Bert 回归模型,参考了 Qiu 等人(2024a)的方法。该模型在在线训练循环中保持固定。我们在补充材料中提供了有关该模型训练和损失曲线的更多信息。
我们在实验中使用的所有模型均部署在 Microsoft Azure 上。模型包括基础模型(GPT-3.5-turbo、GPT-4o、Llama-3.3-70B-instruct、Mistral-3B、Phi-4)、在 Azure 上使用一般医疗和电信知识进行微调的模型,以及使用文件搜索提示相关领域知识的 GPT-3.5-turbo 助手。模型的选择方式确保了包含低性能/SLM、基础模型以及微调/定制领域知识的 LLM(见图 1)。然而,由于我们用于训练 token 长度预测模型的 LMSYS-Chat-1M 数据集(Zheng 等人,2023 年)不包含 Mistral 和 Phi 模型,因此我们在主论文中呈现的实验中省略了它们。我们在补充材料中的额外成本无关(Q=OQ = OQ=O)结果包括了 Phi 和 Mistral 模型。按每 token 成本从最便宜到最昂贵的模型排序如下:GPT-3.5-turbo、Llama 3.3、Med、Tele、Med III。
n2c2 吸烟数据集(Uzuner、Juo 和 Szolovits,2007 年)被用于微调 Med 模型,通过提取报告中嵌入的诊断,将单个报告构建为输入/标签对。鉴于医疗报告的格式,它们首先通过汇总器处理以提取一般医疗知识,然后用于微调 GPT-4o 模型。另外两个微调模型 Med III 和 Tele 分别使用 MIMIC-III 和 TeleQnA 数据集进行微调。评估使用 Microsoft Azure 评估器进行,微调模型在它们被调优的任务上通常表现优于基础模型。
诊断预测数据集
在现有的医疗数据集中,有一些广泛使用的包含去标识化患者医疗报告的数据集。然而,据我们所知,目前尚无专门针对基于医疗报告的诊断预测的数据集。因此,我们从 MIMIC III 数据集(Johnson 等人,2016)中开发了自己的数据集,以便能够成功评估我们算法的性能。
Johnson 等人(2016)的 MIMIC III 数据集包含入院诊断以及后续确定的诊断,并附有患者住院期间的详细信息。每位患者根据其住院时间有多个报告,我们将这些报告合并为每位患者的单一报告,并删除了所有明确提及患者已识别诊断的内容,以及医生提出的与诊断相关的评论。我们在报告中包含了患者的观察记录和测试结果。纳入数据集的患者主要被诊断出患有与心脏、肾脏、肝脏和大脑相关的疾病。我们的数据集包含 100 份医疗报告及其相应的诊断。我们在补充材料中提供了患者诊断的更全面列表以及一些示例患者报告。完整的数据集可在我们发布的代码中获取。
实验结果
我们现在展示在医疗诊断数据集和TeleQnA数据集上的实验结果。所有算法在医疗和电信设置下分别运行了十次和五次,并调整了超参数。图3中的阴影区域表示标准差。有关超参数调整和其他实验设置的详细信息,例如使用嵌入形成上下文的方法,可在补充材料中找到。
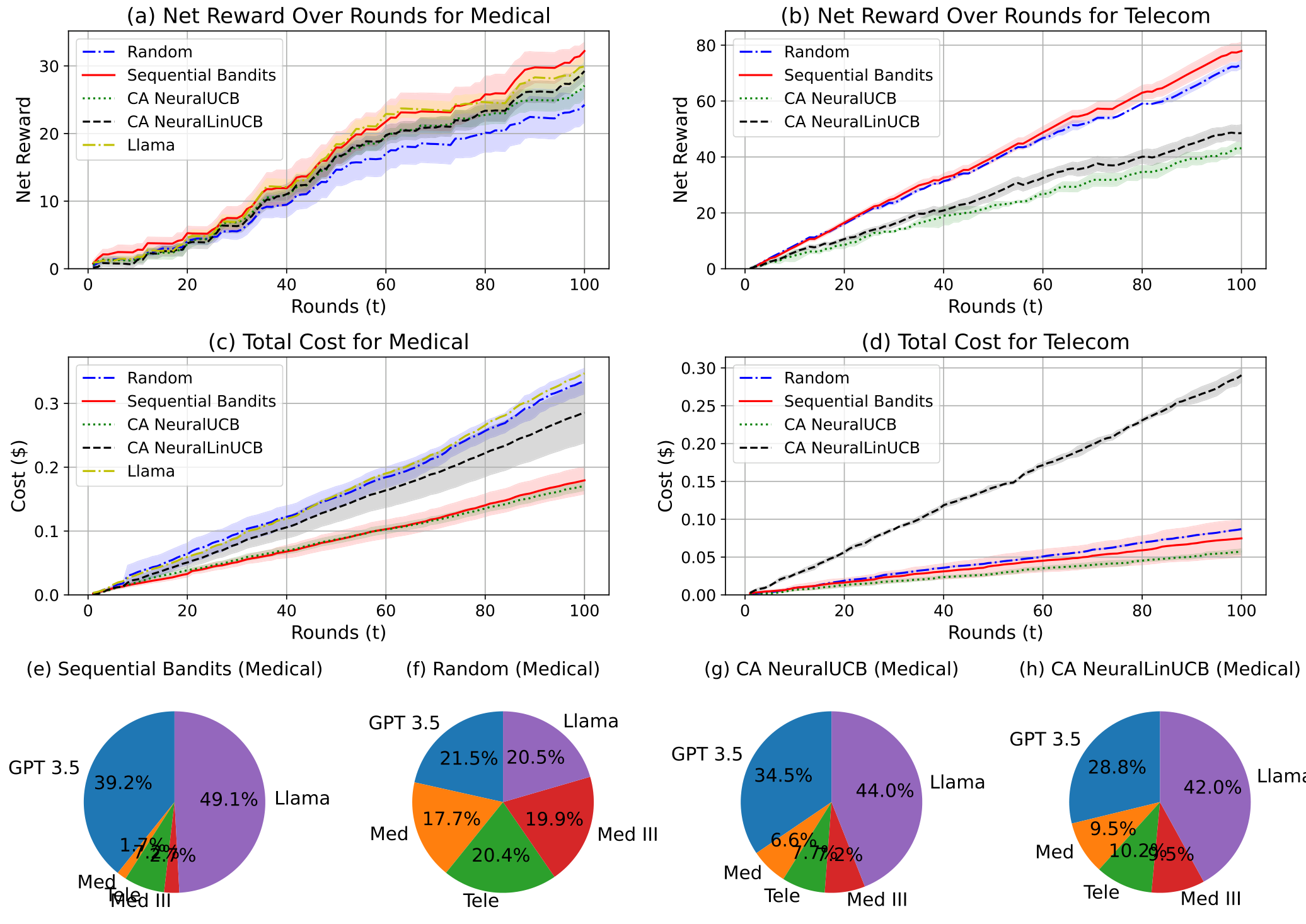
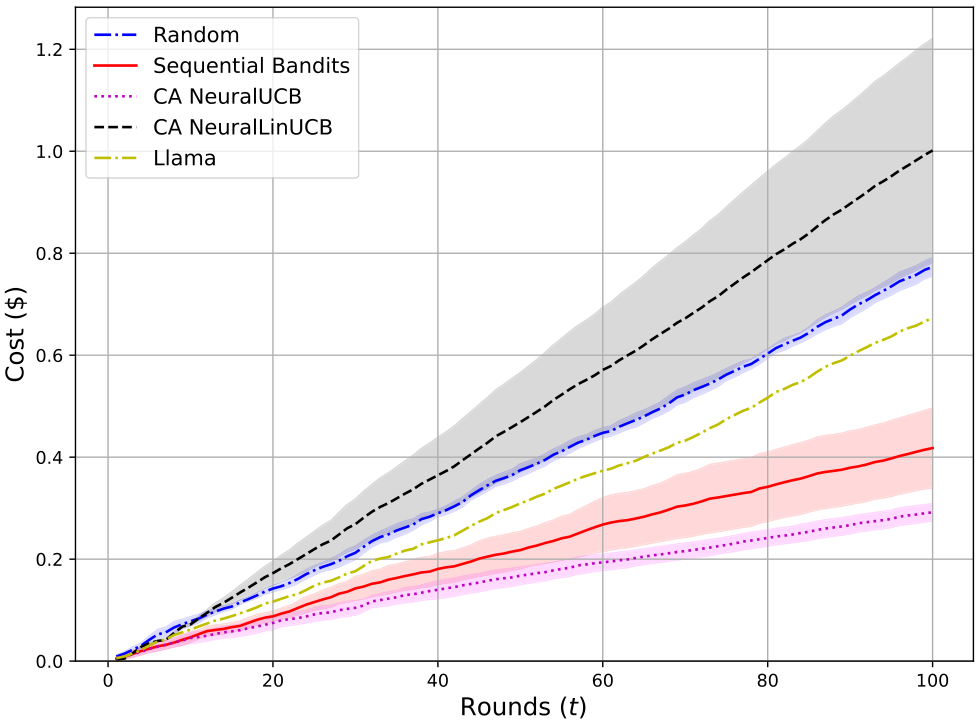
净奖励和成本:首先,我们展示SequentialBandits在两个流水线设置中获得的净奖励 N(t)N(t)N(t) 高于基线算法。在医疗设置中,我们将奖励视为流水线中最终子任务的奖励(即诊断准确性);而在电信设置中,奖励是解释和多项选择答案的奖励总和。图3显示我们的算法(红色实线)在两个设置中均取得了最高的净奖励,并且成本仅次于Cost Aware NeuralUCB,位居第二。在比较最终净奖励时,Sequential Bandits在医疗设置中比最具竞争力的基线(Llama)提高了7.60%,在电信设置中比最具竞争力的基线(Random)提高了6.51%。事实上,当我们查看图1(显示医疗设置中不同模型的诊断准确性)时,我们原本预期Llama会优于Sequential Bandits,因为Llama在此设置中具有最高准确性。然而,我们的算法超越Llama的结果表明,它能够学习子任务之间的复杂依赖关系,因为除了Llama之外,摘要和诊断的组合可能获得更高的奖励成本比。意料之中,Random在医疗设置中的表现最差,而在电信设置中,它意外地优于CA NeuralUCB和NeuralLinUCB。
分析LLM选择:最后,我们仔细观察了每种算法在医疗诊断子任务中选择的LLM。图3(e)显示Sequential Bandits最常选择Llama和GPT 3.5(分别为49.1%和39.2%),这使其能够获得高净奖励和低成本,因为这些模型价格最低,并且在该子任务中分别具有最高和第二高的准确性(完整图表见补充材料)。如图3(f)-(h)所示,其他基线选择这两个模型的频率较低,并且更多地做出了次优选择,例如更频繁地选择准确性最低的Med模型。电信设置中模型选择的饼图可在补充材料中找到。
额外实验:我们在补充材料中包含了更多实验结果,包括(i)每种算法实现的遗憾值和每个子任务上的模型准确性。我们还展示了(ii)主论文中2个子任务医疗流水线的3个子任务版本的结果,以及(iii)医疗诊断子任务流水线的成本无关(Q=0Q = 0Q=0)版本,以及单一子任务TeleQnA任务的结果。由于成本也可以解释为响应延迟,我们进一步展示了模型响应延迟的结果。最后,我们包含了一个示例医疗报告及其摘要,以展示摘要步骤如何使诊断子任务变得更容易。
结论
在本文中,我们提出了一种新颖的方法来选择大型语言模型(LLM)的流水线以执行分解的任务,采用上下文多臂 bandit 算法,以在线方式依次为每个子任务选择最佳的 LLM。我们的方法,称为 Sequential Bandits,利用神经网络来建模每个 LLM 的预期成功率,从而在依赖性子任务序列中实现更有效的任务完成。我们通过涉及两个任务的实验展示了我们方法的有效性:医学诊断预测和多选电信问题回答。我们的工作提供了一个可以适应各种领域的框架,在这些领域中任务分解是可行的。未来的工作包括扩展我们的框架以处理难度和相互依赖性不同的更广泛任务,考虑响应延迟作为成本,并提供遗憾保证或其他性能界限。
成本无关设置结果
首先,我们展示了成本无关版本算法的实验结果,针对非流水线的单一任务电信设置,使用 TeleQnA 数据集(Matouk 等人,2023 年),以及我们在主论文中介绍的成本无关版本的 2 个子任务医学流水线。在这里,考虑的所有算法(NeuralUCB 和 NeuralLinUCB)也是成本无关版本。由于我们处于成本无关设置,Q=OQ = OQ=O,因此净奖励在此设置中简化为奖励。
电信设置结果
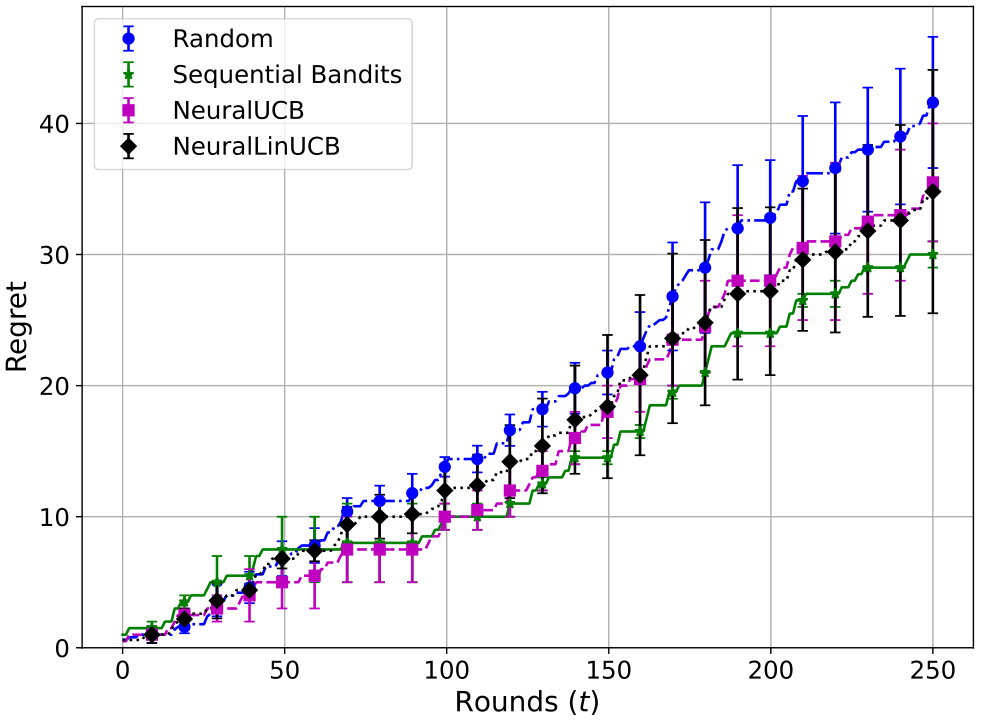
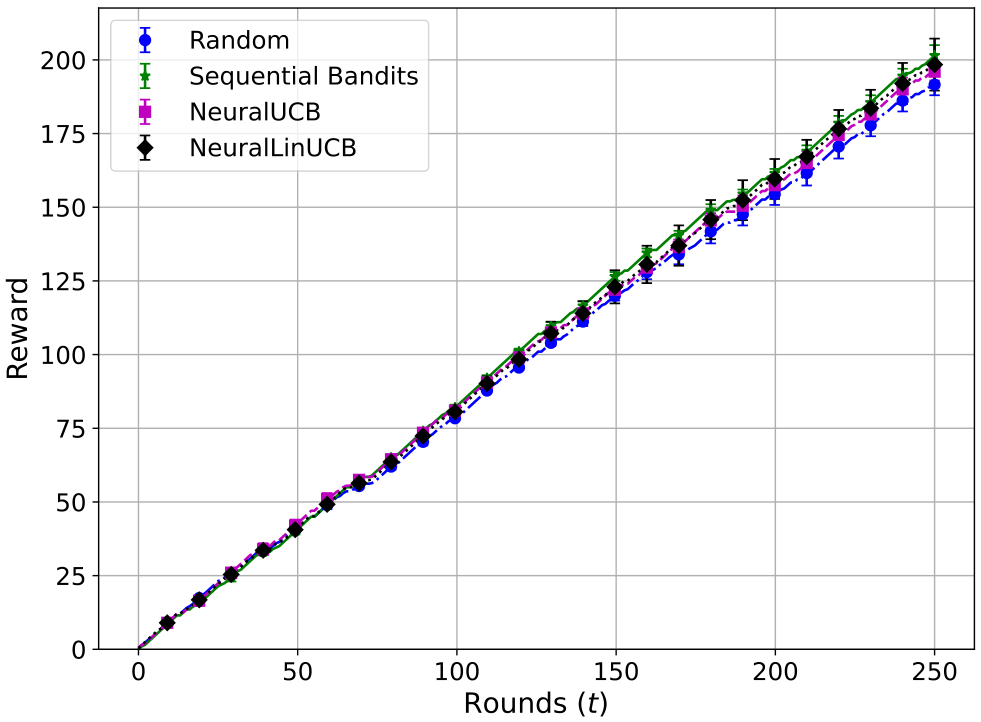
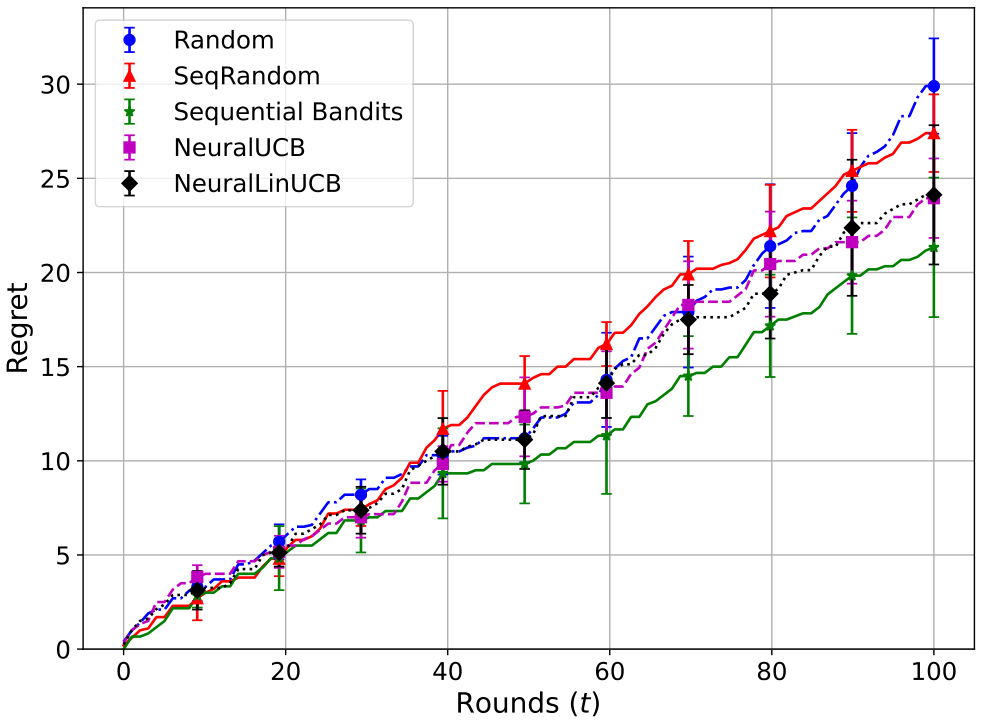
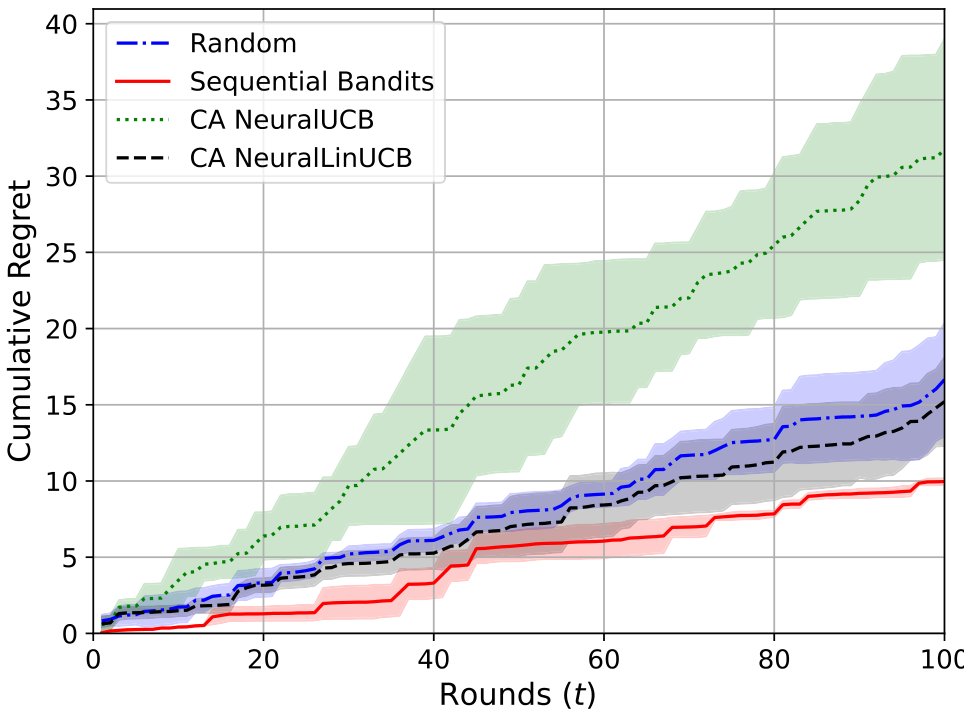
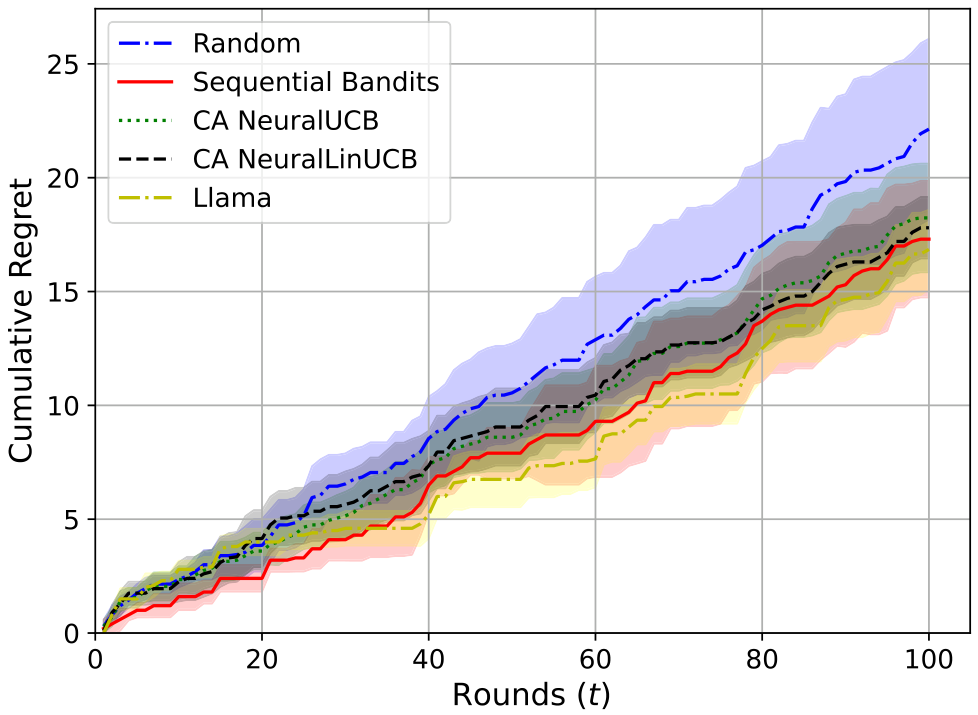
在本节中,我们展示了非流水线多选电信问题回答任务的结果。在这种设置中,选择一个单一的 LLM,将电信问题作为输入,并输出可用选项之一。现在,我们展示此设置的奖励和遗憾图表。图 4 和图 5 显示了累积遗憾和奖励,表明我们的算法优于基线。误差条表示标准偏差,通过 5 次运行的平均值获得。

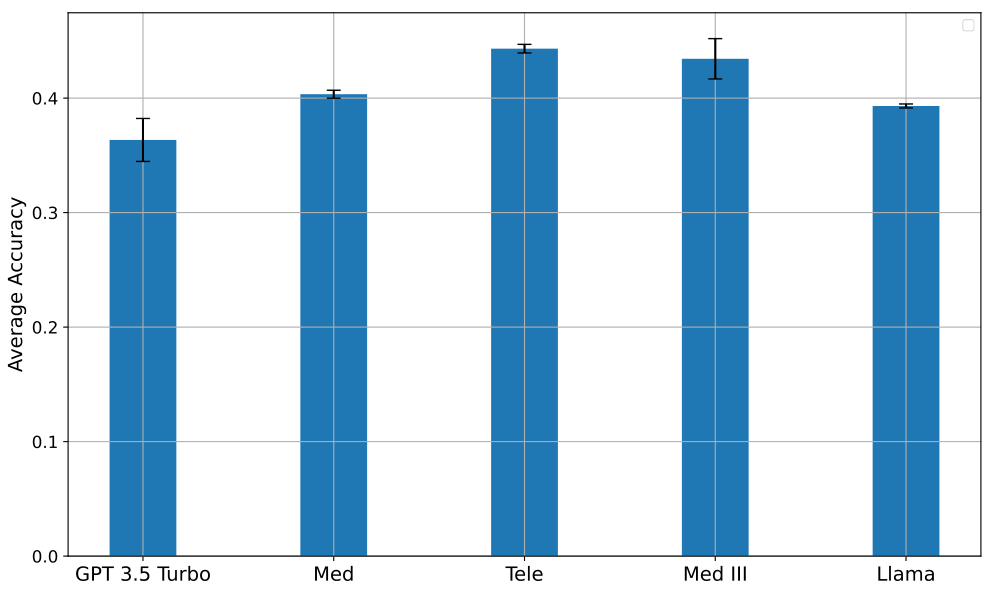
接下来,我们展示了此任务中 LLM 的平均准确率。平均值是通过 15 次运行得出的。在此设置中,每轮的准确率是二元的,因为每轮都有一个传入的多选电信问题,只有一个正确选项。图 6 显示了不同 LLM 模型的准确率,表明从 GPT-4o 微调的 Telecom 模型表现最佳,其次是 GPT-3.5 Turbo、MedIHI 和 Med 模型。与诊断预测任务一样,Mistral-3B 在此任务中的准确率也是最低的。

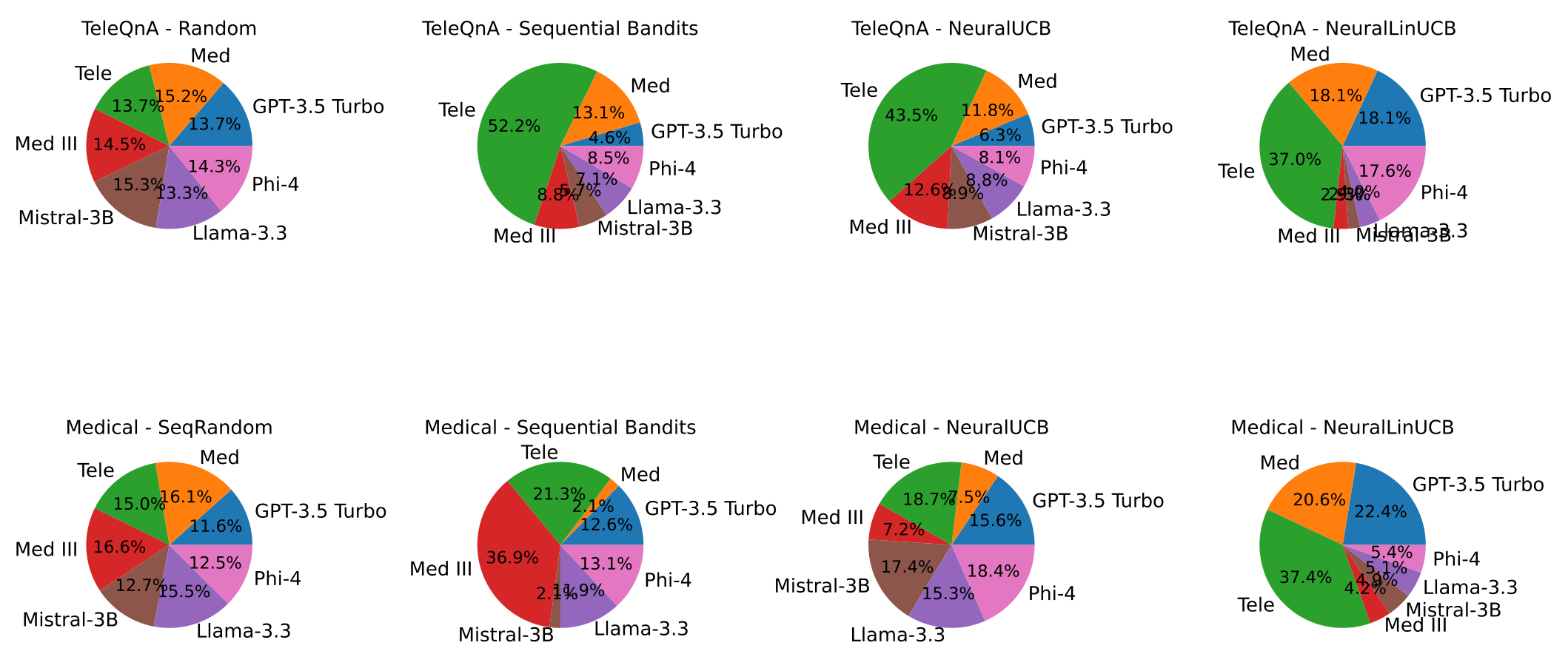
图 7 中可以看到的饼图显示了电信任务的模型选择百分比,平均值通过 5 次运行得出。Random 算法如预期那样表现出相对均匀的模型选择,而其余算法选择 Telecom 模型的次数最多。我们的算法 Sequential Bandits 大多数时间(52.2%)选择了 Telecom 模型,这是所有算法中最高的。与之前的医学报告诊断预测应用相比,NeuralUCB 和 NeuralLinUCB 表现更好,从它们的模型选择可以看出,它们能够识别准确率更高的模型并更多地使用它们。

医学场景的结果
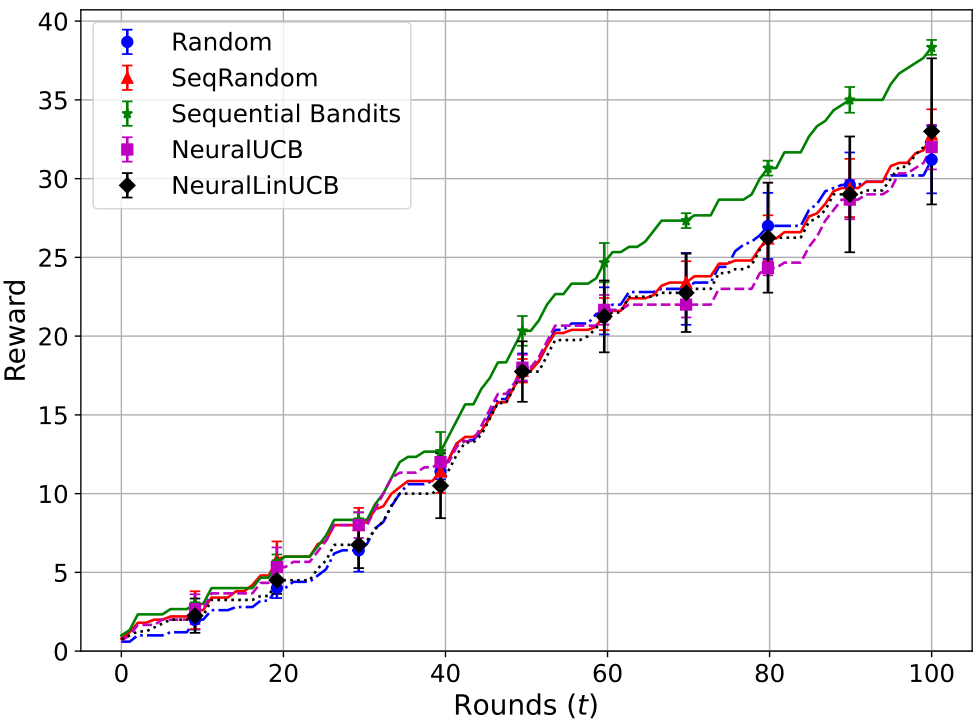
在这一部分,我们将展示医学成本无关设置下两个子任务的结果。这与主论文中介绍的医学场景相同,其中我们使用一个摘要大语言模型(LLM)来总结输入的医学报告,然后将总结后的报告传递给诊断大语言模型(LLM)进行诊断。主要的区别在于,现在我们处于成本无关的设置中,这意味着我们只关注模型的预测准确性,而不考虑其成本。在这些实验中,我们考虑了两种不同类型的随机选择算法。Random 算法随机选择一个 LLM 来完成基于未总结医学报告的诊断预测任务,而 SeqRandom 则在两个子任务中采用随机选择(相当于主论文中的 Random 算法)。
从图 8 和图 9 中可以看出,Sequential Bandits 在基线中取得了最高的奖励,同时也实现了最低的遗憾。图 7 中的饼图显示了每个算法在诊断预测子任务中选择的模型百分比。正如预期的那样,Sequential Random 在模型选择上显示出大致均匀的分布。令人惊讶的是,NeuralUCB 尽管使用神经网络预测 LLM 的成功率,但似乎也表现出类似的趋势;然而,这是因为这些饼图显示的是五个独立实验的平均模型选择。在每个实验中,NeuralUCB 都专注于一个不同的、通常是次优的 LLM,导致平均值在各个 LLM 上看起来接近均匀。我们的算法 Sequential Bandits 显示出对 Med II 和 Telecom 模型的偏好,同时对 Llama-3.3、GPT-3.5 Turbo 和 Phi-4 的选择相对平均。值得注意的是,我们的算法很少选择 Mistral-3B 和 Medical 模型(两者均为 2.1%),而这两个模型在此子任务中表现最差,如图 1 中的红色条所示。
NeuralLinUCB 也很少选择 Mistral-3B(4.9%);然而,它却经常选择 Medical 模型(20.6%)。
实验设置与超参数调整
我们现在详细说明了我们为所有算法调整的超参数,以及如何从输入提示和LLM的描述中为不同任务形成上下文。为了获取提示和描述的嵌入,我们使用了HuggingFace的“Paraphrase-MiniLM-L6-v2”句子转换器模型,该模型将文本嵌入为384维向量。我们通过对LLM的描述和其输入提示进行逐元素乘法来形成(LLM,子任务)组合的上下文。逐元素乘法是一种常用的相似性度量方法,因此我们在实验中也采用了这种方式。该上下文作为输入提供给神经网络,这些神经网络是宽度为 n=50n = 50n=50 的两层全连接网络。我们在所有实验中设置正则化参数 X=1X = 1X=1,并在 10−210^{-2}10−2 到 10−410^{-4}10−4 之间调整学习率。我们将梯度下降步数设置为 J=5J = 5J=5。我们还调整了算法中利用项(μ\muμ)和探索项(σ\sigmaσ)的比例,从0.1到2不等,以尽可能优化地平衡探索和利用。最后,我们还对所有实验调整了成本敏感参数 QQQ。我们调整该参数以确保算法1中目标函数中的成本项和准确性项的大小大致相等,从而对成本和准确性给予相似的重视。在我们的实验中,QQQ 值的范围为50到150。
关于我们诊断预测数据集的详细信息
我们现在提供关于我们创建的诊断预测数据集的更多细节,列出了100名患者的诊断结果,并给出了一个医疗报告示例。所有100名患者的医疗报告及其相应的诊断可以在补充材料文件中找到。患者的诊断包括以下内容:充血性心力衰竭、冠状动脉疾病、败血症、急性冠状综合征、心动过速、不稳定型心绞痛、急性心肌梗死、主动脉瓣狭窄、肺栓塞、肺炎、阿片类药物中毒、颈动脉狭窄、完全性心脏传导阻滞、呼吸衰竭、肝衰竭、脑病、心包填塞、神经结节病、主动脉夹层、腹胸主动脉瘤、腔静脉综合征、尿路败血症、低钠血症、缺氧、主动脉瓣关闭不全、肝硬化、椎基底动脉狭窄、肾衰竭、慢性阻塞性肺疾病、尿路感染、肺水肿。以下是一个患者的医疗报告示例:
(此处省略了详细的医疗报告内容,原文中包含了多个检查报告的描述,包括胸部X光、CT扫描、腹部X光等影像学检查的结果,以及心脏运动实验室的发现。报告中提到的主要发现包括心脏扩大、肺部浸润、肺水肿的可能性、小肠机械性梗阻的迹象等。)
我们通过整合患者在不同时间点(新的观察、测试结果、影像学检查等)后的多份报告创建了上述医疗报告,并删除了任何明确提及诊断的内容。上述医疗报告对应的患者诊断为肺水肿。以下是该报告通过助手总结器处理后的摘要版本:
(此处省略了总结后的医疗报告内容,总结中提取了关键信息,包括心脏扩大、肺部浸润、可能的肺水肿、小肠梗阻的迹象等,并指出没有心肌灌注缺陷或肺栓塞的证据。)
如上所示,上述医疗报告的总结突出了可能有助于做出诊断的最重要信息,从而简化了后续流水线中大型语言模型(LLM)的任务。
输出Token长度预测模型
接下来,我们将详细介绍用于预测给定输入提示长度下输出token数量的输出token长度预测模型。正如我们在主论文中简要解释的,我们使用LMSYS-Chat 1M数据集(Zheng 等人,2023年)训练了一个带有L1损失的Bert回归模型来训练此模型。
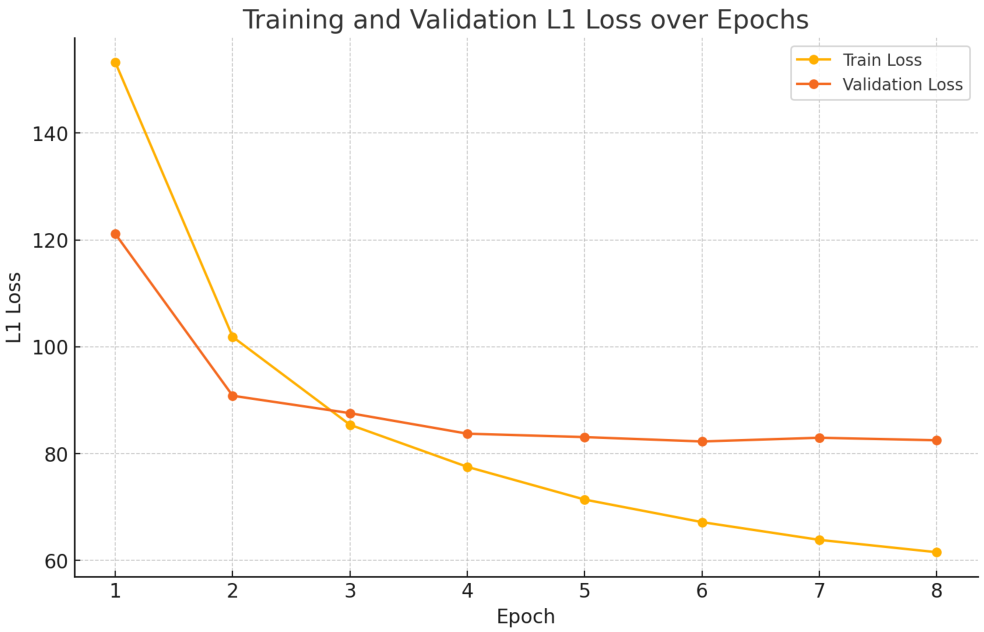
我们在图10中展示了使用50,000个示例、按90%训练和10%验证比例划分的Bert回归模型在不同训练轮数(epoch)下的训练和验证损失曲线。验证损失在6个epoch后开始增加,因此我们在实验中使用了训练至6个epoch的模型进行输出token长度预测。此模型在开始成本感知设置的实验前仅训练一次,并在算法1所示的训练过程中保持不变。
LLM部署成本的计算
为了构建如图3所示的总成本图表,我们使用了微软Azure上提供的每token定价信息,我们的所有实验均在该平台上运行。GPT 3.5 Turbo的每输入token成本为0.00000050.00000050.0000005,微调后的GPT 4o模型(Med, Tele, Med III)的每输入token成本为0.000000250.000000250.00000025,Llama的每输入token成本为0.000000710.000000710.00000071。GPT 3.5 Turbo的每输出token成本为0.00000150.00000150.0000015,微调后的GPT 4o模型(Med, Tele, Med II)的每输出token成本为0.000010.000010.00001,Llama的每输出token成本为0.000000710.000000710.00000071。因此,微调后的模型是成本最高的模型,其次是Llama,而最便宜的是GPT 3.5 Turbo。我们使用这些输入和输出的每token成本,并将其与实际输入token数量和预测的输出token数量相乘,以获得使用这些LLM的相应成本值。
成本感知设置结果
在这一部分中,我们展示了在主论文中详细描述的3个子任务电信设置的额外结果,包括模型选择的饼图、模型在该设置下的准确性,以及之前考虑的3个子任务版本的医疗流程和主论文中详细描述的2个子任务医疗流程的额外结果。
我们考虑将任务分解为三个顺序子任务:总结、辩论和诊断。辩论子任务的奖励通过获取前述总结的亲幻觉和反幻觉偏差并计算差值来获得。此处呈现的结果是5次独立运行的平均值。
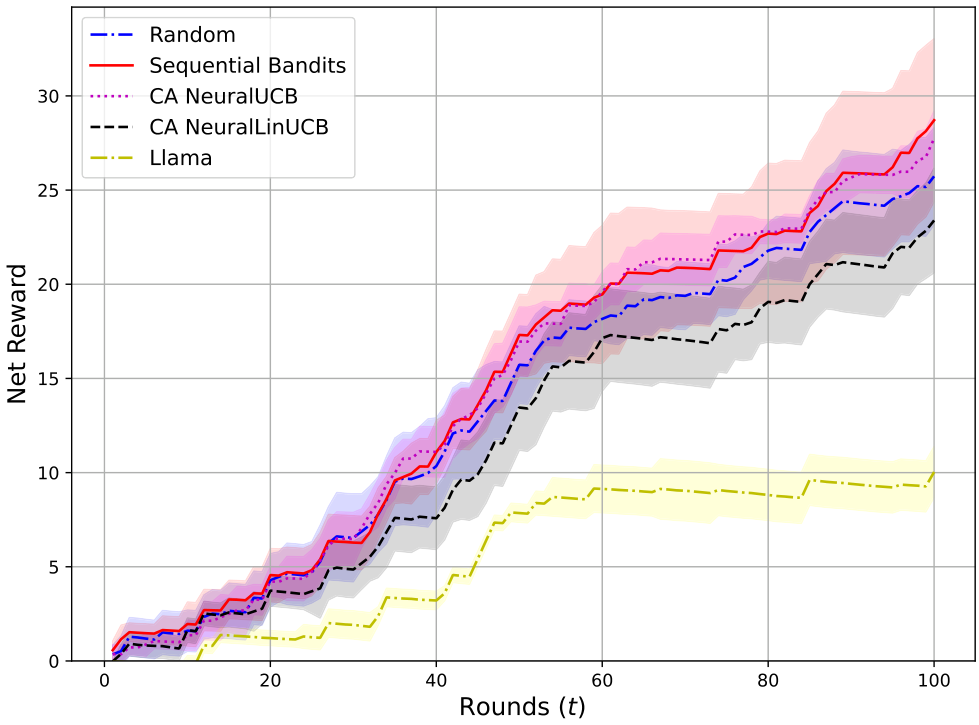
从图11中可以看出,我们的算法(用实心红线表示)在这一成本感知设置中实现了最高的净奖励。成本感知NeuralUCB的表现也与我们的算法相当,显示了其成功。令人惊讶的是,Random的表现优于成本感知NeuralLinUCB和Llama,而Llama的表现明显比其他所有算法差,这表明在这些更复杂的流程中,静态LLM选择策略可能不太可靠和有效。
接下来,我们考虑算法的遗憾值,如图12所示。可以看出,除了Llama的表现明显较差外,其他算法的遗憾值大多相似。遗憾值的测量涉及一些随机性,因为我们将其定义为该轮最佳模型性能与所选模型性能之间的差异。这意味着即使我们事后能够识别出该子任务的最佳模型,我们仍可能因该模型在特定类型的输入上表现不佳而产生遗憾,而另一个模型可能获得1的准确性,从而使我们产生遗憾。因此,这可以被视为比通常测量的更具竞争性的遗憾。
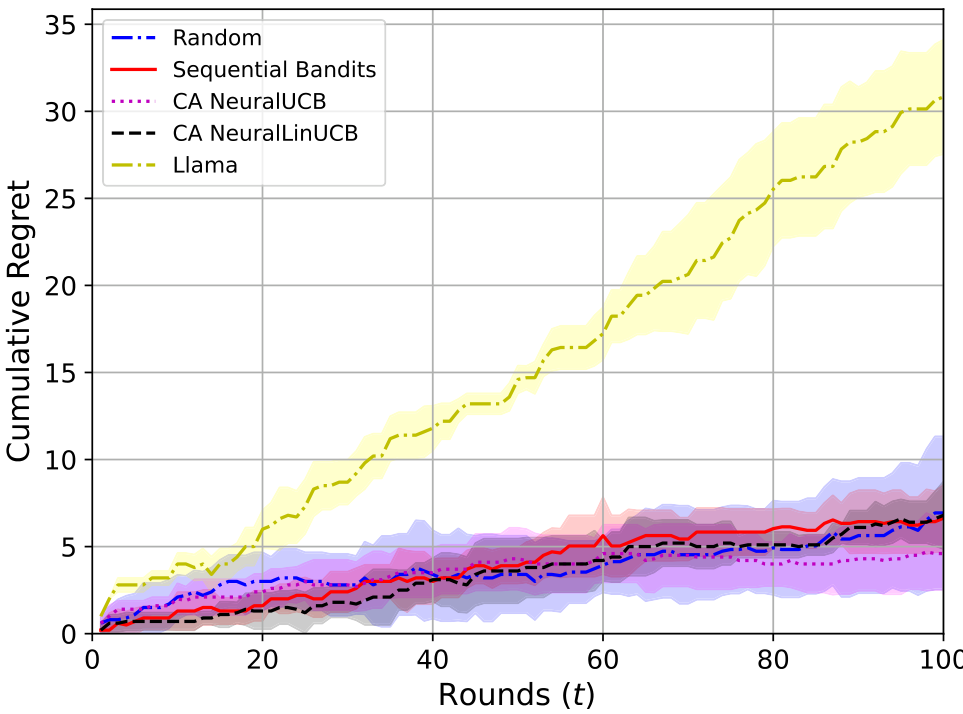
接下来,我们展示了3个子任务医疗设置下算法产生的总成本。从图13中可以看出,成本感知NeuralLinUCB的成本最高,其次是Random、Llama、Sequential Bandits和成本感知NeuralLinUCB。可以观察到,与其他算法相比,Llama基线的总成本标准差最低,因为其阴影区域几乎不可见。这是静态LLM选择基线的一个优势,因为它们在不同运行中的总成本变化较小。
接下来,我们展示了在3个子任务流程设置中诊断子任务的模型平均准确性,如图14所示。与图1类似,这里的准确性表明LLM能够正确预测的诊断数量。可以看出,Llama获得了最高的平均准确性,其次是GPT 3.5 Turbo、Tele、Med III和Med,这一顺序与图1中的类似。
对于3个子任务医疗设置,图17的第一行显示了诊断子任务的模型选择。Sequential Bandits和CA NeuralUCB是表现最好的,这从它们的模型选择中可以看出,因为它们选择Med的频率较低,而选择Llama的频率较高。
在本节中,我们提供了主论文中介绍的成本感知3个子任务电信设置的更多结果。首先,我们展示了该设置的累积遗憾,如图15所示。我们观察到与图3中净奖励类似的趋势,Sequential Bandits在遗憾方面也优于其他基线,而CA NeuralUCB表现最差,CA NeuralLinUCB和Random的表现则相当接近。
接下来,我们查看了回答和解释子任务的模型平均准确性,其结果影响了主论文中呈现的净奖励图。图16显示,Tele和Med III在这些任务中实现了最高的准确性,其次是Med、Llama和GPT 3.5 Turbo。
现在,我们分析了各算法在该设置下的模型选择。如图17的第二行所示,我们的算法Sequential Bandits选择Med III的次数最多,其次是Med和Llama,而对GPT 3.5 Turbo和Tele的选择较少。尽管我们的算法未能识别出这些任务的最佳模型Tele,但它也避免了选择其中最差的选项GPT 3.5。重新考虑图16中显示的准确性,Med III和Tele之间的性能差异并不大,这也是我们的算法实现最高净奖励和最低遗憾的原因。CA NeuralUCB在所有基线中做出了最次优的选择,选择Llama和GPT 3.5的比例总计高达90%,这就是它获得最高遗憾和最低净奖励的原因。CA NeuralLinUCB的表现优于NeuralUCB,因为它选择Llama和GPT 3.5 Turbo的频率较低,而更多选择Med和Med III。
2 子任务医疗设置
在这一部分中,我们展示了在主论文中详细讨论的2子任务医疗设置的一些额外结果。
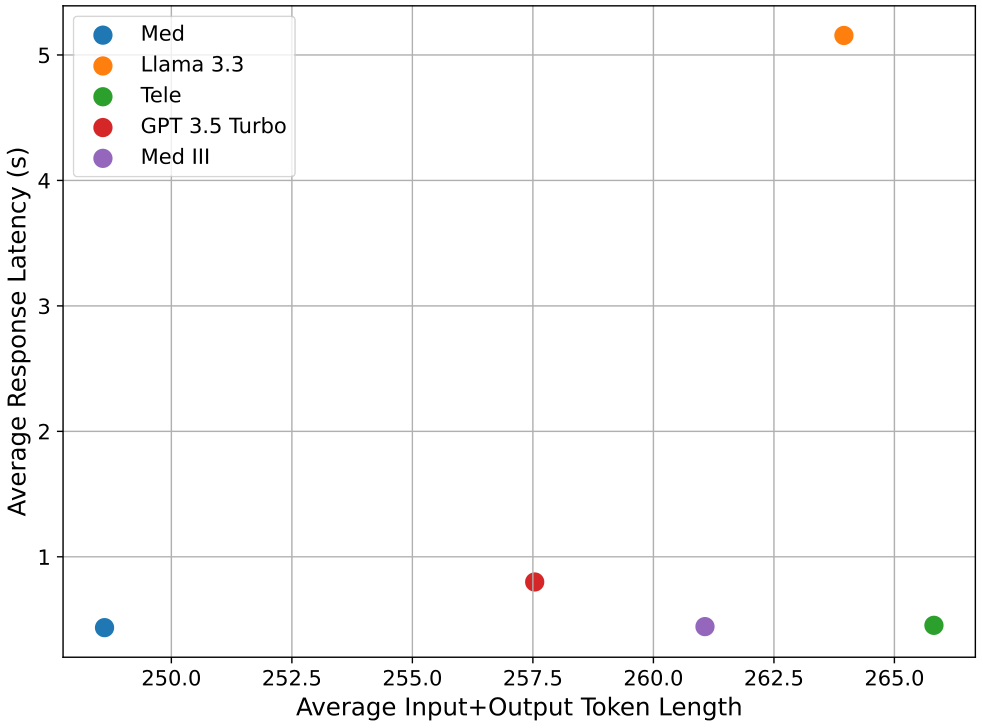
首先,我们展示了模型在摘要子任务上的平均准确率结果,运行了10次,如图18所示。Assistant 是一个我们使用的定制化专业GPT 3.5 Turbo模型,替代了Med III,因为使用Med II模型进行摘要时会触发OpenAI政策相关的安全错误。摘要任务的最高可用准确率为100,可以看出GPT 3.5、Tele和Llama表现非常相似,是最好的摘要者,而Assistant和Med表现最差。
接下来,我们研究更高的摘要准确率是否必然导致更高的诊断准确率。图19中的结果显示情况并非必然如此,尽管两者之间存在一定的相关性。图19基本上显示了当某个模型被选为摘要者时的平均诊断准确率。因此,所示的值是模型给出的摘要导致的诊断预测的平均值。在这种情况下,诊断者和摘要者都是随机选择的,以减少任何偏差。如果一个好的摘要始终导致成功的诊断,我们预期图18和图19在排序上看起来会相似。虽然Assistant的准确率最低,但如图19所示,其他模型在准确率上非常相似,而图18的情况并非如此。此外,图19中误差条显示的标准差值相当大,表明方差很高,这使得更难得出摘要准确率和诊断准确率之间存在直接相关性的结论。因此,这表明无法通过在流程早期设置较低的α来优先考虑摘要的准确性,然后通过设置较高的Q来优先考虑成本,因为高准确率的摘要并不一定保证诊断的高准确率。
现在,我们来看看在这种成本感知设置下模型在诊断子任务上的平均准确率。图20显示了该子任务中模型的准确率,其中Llama和GPT 3.5具有最高的准确率,而Med最低。
接下来,我们展示了这种设置下的累积遗憾结果,如图21所示。正如预期的那样,Random获得了最高的遗憾,而其他算法表现相当,Sequential Bandits和Llama baseline略微优于CA NeuralUCB和NeuralLinUCB。这一结果与2子任务的净奖励结果一致。
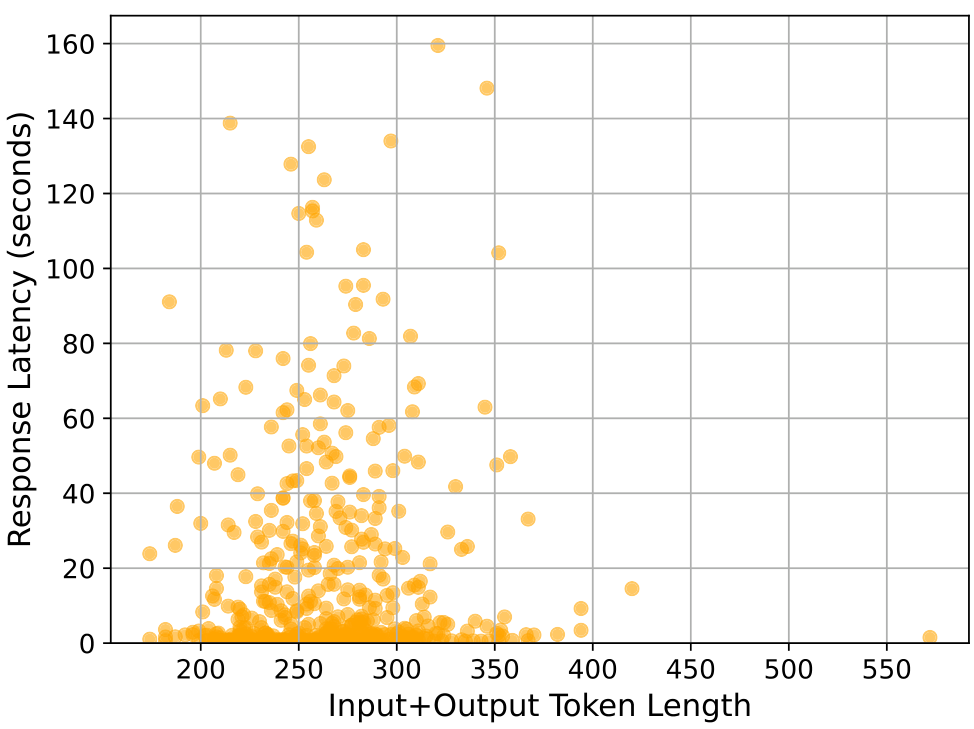
响应延迟与令牌长度关系的研究结果
以下是对论文中关于响应延迟与令牌长度关系部分的总结,用中文表述,并保留原文中的图片部分在适当位置。
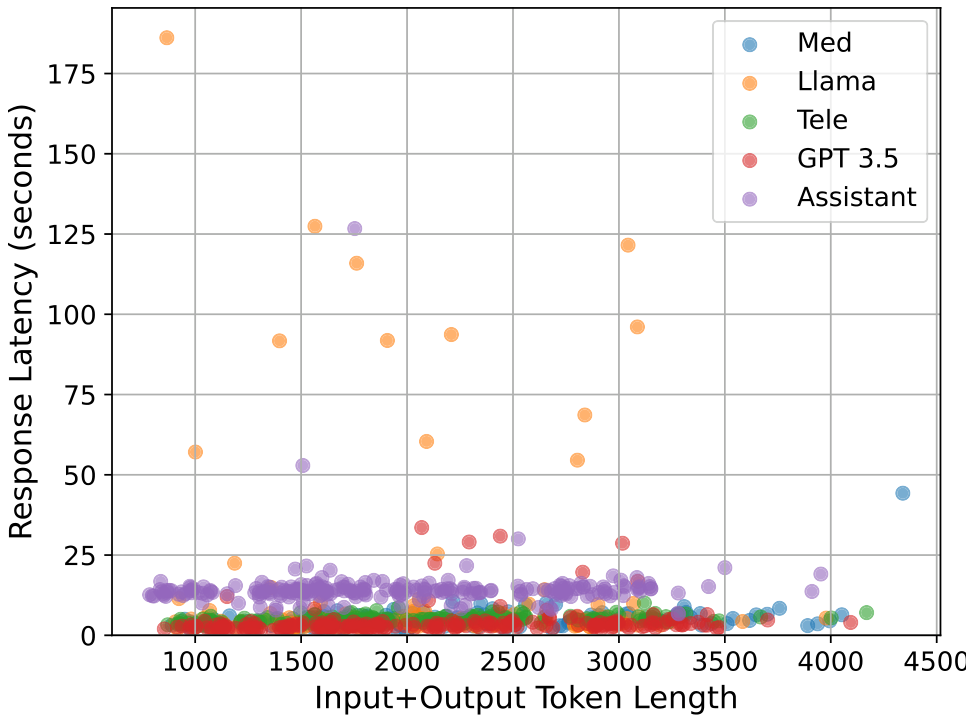
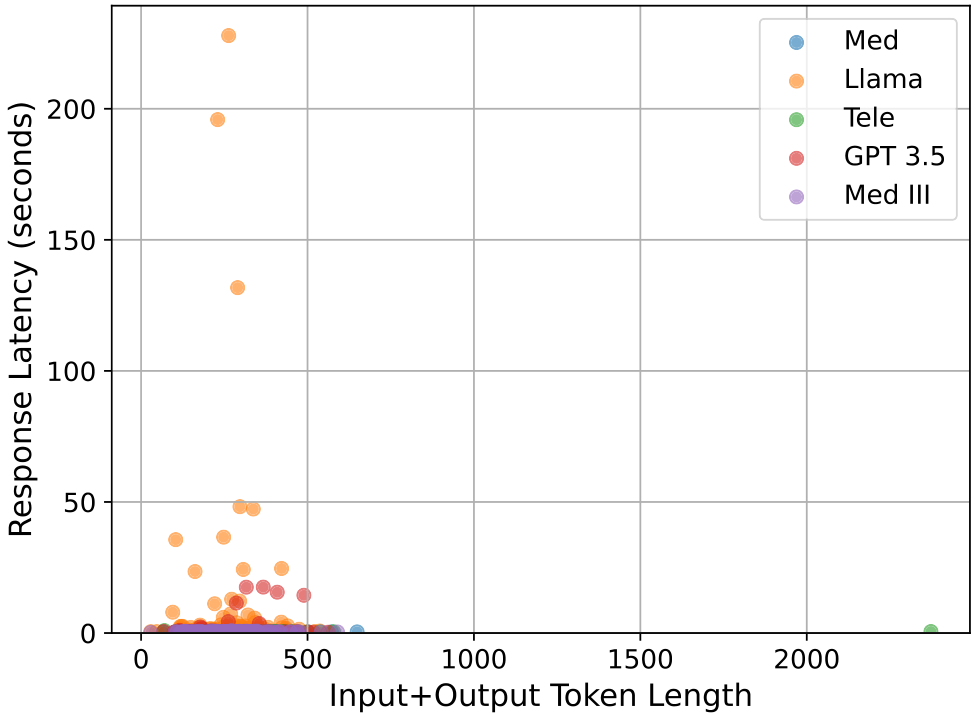
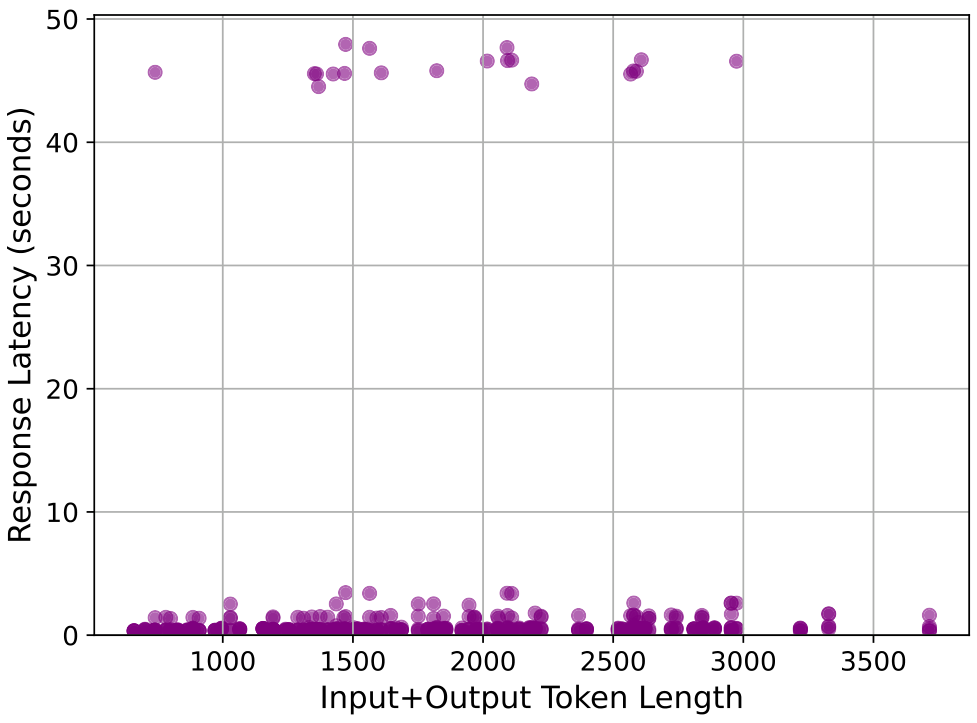
我们首先展示了响应延迟及其与令牌长度的变化关系。正如主论文中提到的,响应延迟也可以被视为一种成本,这是未来研究的一个可能方向,即将响应延迟纳入目标函数中。我们首先对1000个实例(10次运行)进行随机选择,并绘制所有点的散点图,如图22所示。我们发现,相比其他模型,Assistant的总体延迟较高,但并没有明确的趋势表明总令牌数增加会导致更高的响应延迟。在图23中,我们观察到诊断子任务的响应延迟与令牌数的变化趋势相似,主要区别在于令牌数量相较于摘要任务要少得多。我们注意到Llama模型有一些异常值,如图22中的黄色散点所示。我们推测这可能是由于Llama作为最广泛使用的大型语言模型之一,存在拥塞现象。
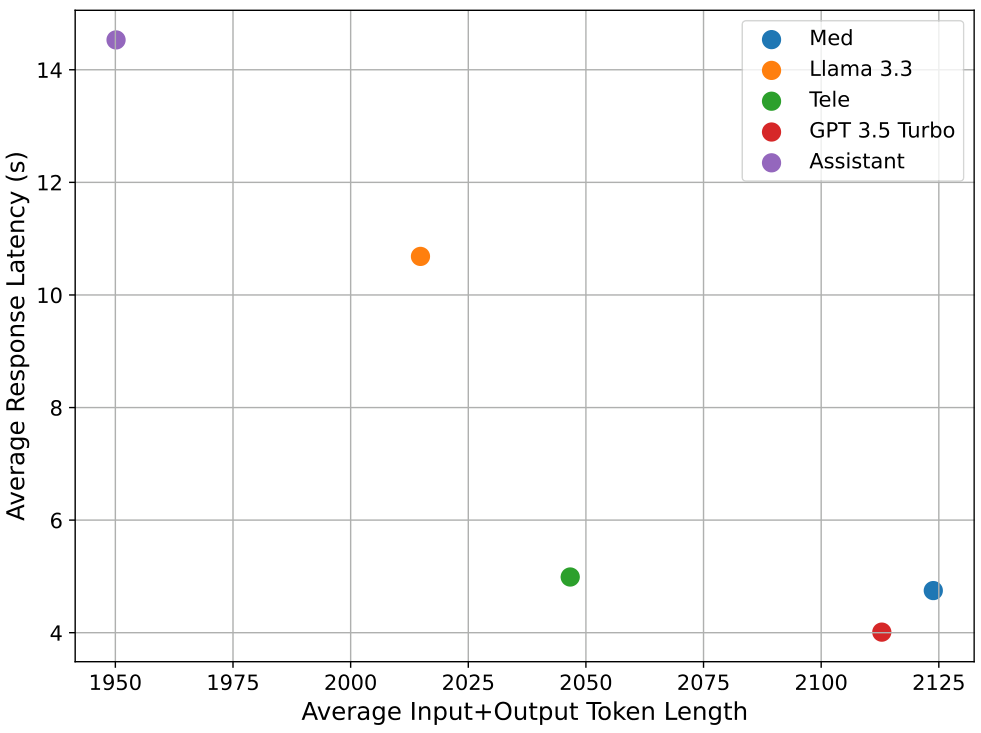
接下来,我们展示了不同模型的平均响应延迟与总令牌数的关系。从图24和图25中可以看出,正如图22所显示,Assistant的平均响应延迟最高,尽管其总令牌数最低。Med和Tele的延迟值相似,因为它们都是基于GPT 4o基础模型进行微调的,而Llama在Assistant之后具有最高的延迟。我们还观察到,Llama的延迟高于其他模型,而其他模型的延迟值相似。
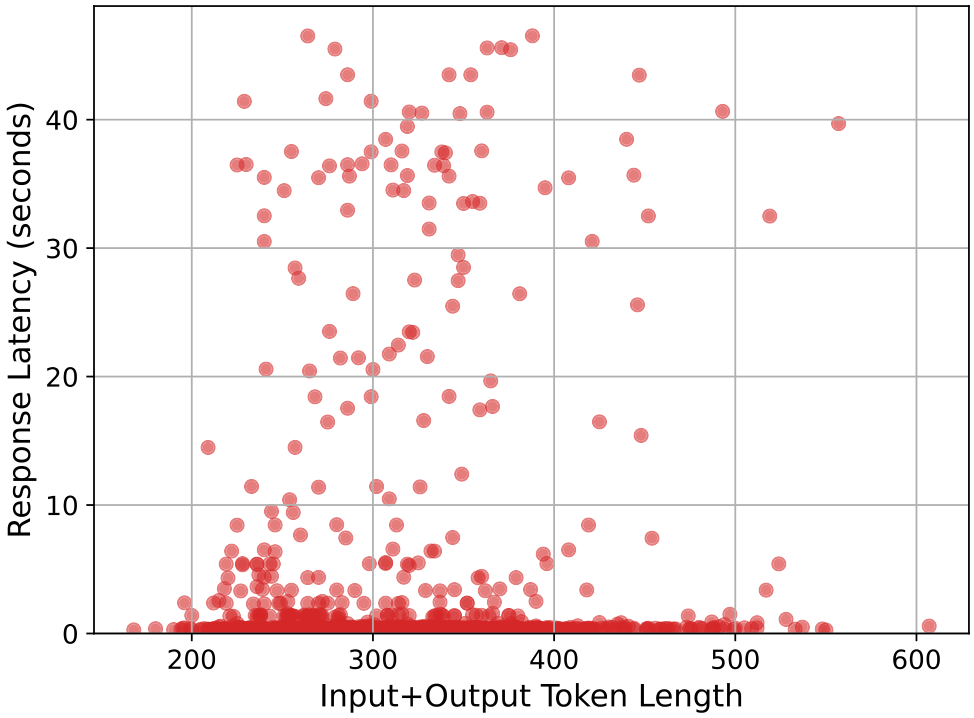
最后,我们分别查看了部分模型的响应延迟与令牌数的散点图,以探究是否存在某种相关性。图26、图27和图28分别展示了Med IHI、GPT 3.5 Turbo和Llama模型在诊断子任务中的变化情况,每张图中包含500个点。尽管响应延迟与令牌数之间似乎没有特定趋势,但可以观察到,通过API广泛使用的模型(如Llama和GPT 3.5)显示出更多的变化性和某些查询的延迟时间增加,如图中众多的异常值所示。另一方面,图26显示,对于我们自己微调的Med mf模型,这种情况要少得多,这表明使用非广泛使用或对外开放的微调模型具有优势。这进一步强调了大型语言模型选择算法的必要性,因为如果我们能识别出某些针对特定任务的专用模型在性能上表现更好或相似,但响应延迟大大改善,我们就可以避免选择延迟较高的模型。
Original Abstract: With the increasing popularity of large language models (LLMs) for a variety
of tasks, there has been a growing interest in strategies that can predict
which out of a set of LLMs will yield a successful answer at low cost. This
problem promises to become more and more relevant as providers like Microsoft
allow users to easily create custom LLM “assistants” specialized to particular
types of queries. However, some tasks (i.e., queries) may be too specialized
and difficult for a single LLM to handle alone. These applications often
benefit from breaking down the task into smaller subtasks, each of which can
then be executed by a LLM expected to perform well on that specific subtask.
For example, in extracting a diagnosis from medical records, one can first
select an LLM to summarize the record, select another to validate the summary,
and then select another, possibly different, LLM to extract the diagnosis from
the summarized record. Unlike existing LLM selection or routing algorithms,
this setting requires that we select a sequence of LLMs, with the output of
each LLM feeding into the next and potentially influencing its success. Thus,
unlike single LLM selection, the quality of each subtask’s output directly
affects the inputs, and hence the cost and success rate, of downstream LLMs,
creating complex performance dependencies that must be learned and accounted
for during selection. We propose a neural contextual bandit-based algorithm
that trains neural networks that model LLM success on each subtask in an online
manner, thus learning to guide the LLM selections for the different subtasks,
even in the absence of historical LLM performance data. Experiments on
telecommunications question answering and medical diagnosis prediction datasets
illustrate the effectiveness of our proposed approach compared to other LLM
selection algorithms.
PDF Link: 2508.09958v1
部分平台可能图片显示异常,请以我的博客内容为准
