【AI论文】GLM-4.5:具备智能体特性、推理能力与编码能力的(ARC)基础模型
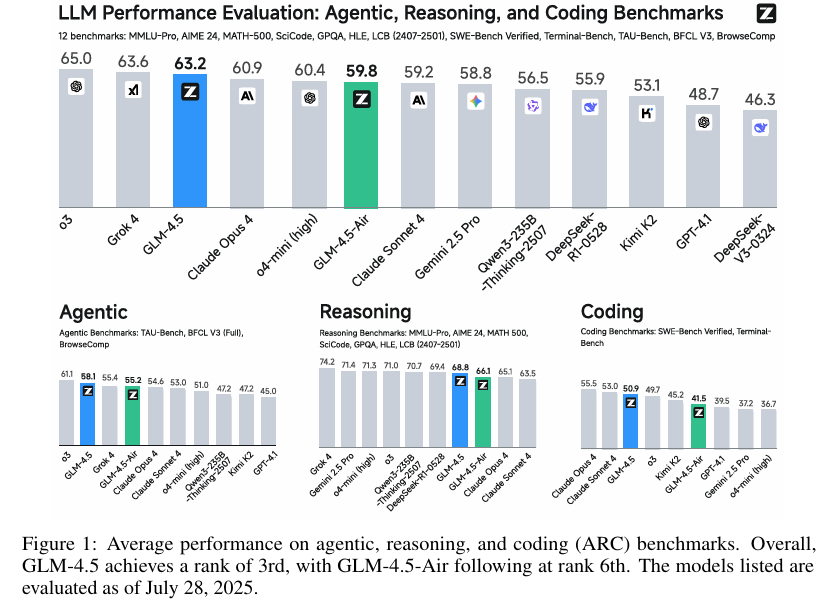
摘要:我们推出GLM-4.5,这是一款开源的混合专家(Mixture-of-Experts,MoE)大语言模型,其总参数量达3550亿,激活参数量为320亿。该模型采用了一种混合推理方法,支持“思考”与“直接响应”两种模式。通过对23万亿tokens进行多阶段训练,并结合专家模型迭代与强化学习的全面后训练,GLM-4.5在智能体特性、推理能力与编码能力(ARC)任务上展现出卓越性能,在TAU-Bench测试中得分70.1%,在AIME 24测试中得分91.0%,在SWE-bench Verified测试中得分64.2%。尽管参数量远少于多个竞争对手,GLM-4.5在所有评估模型中总体排名第三,在智能体特性基准测试中排名第二。我们同时发布GLM-4.5(3550亿参数量)及其精简版本GLM-4.5-Air(1060亿参数量),以推动推理与智能体人工智能系统领域的研究。代码、模型及更多信息详见:Github。Huggingface链接:Paper page,论文链接:2508.06471
研究背景和目的
研究背景:
随着人工智能技术的迅猛发展,大语言模型(LLMs)已经逐渐从单纯的知识库转变为具备复杂问题解决能力的通用系统。这一转变的核心在于,如何使模型具备类似于人类的认知能力,包括与外部工具和现实世界交互的智能体特性(Agentic abilities)、解决数学和科学领域多步问题的复杂推理能力(Reasoning abilities),以及处理实际软件工程任务的高级编码能力(Coding abilities)。尽管一些专有模型如OpenAI的o1/o3和Anthropic的Claude Sonnet 4在特定ARC领域内展示了突破性的性能,但一个能够统一并卓越表现于所有这三个领域的强大开源模型仍然稀缺。
研究目的:
本研究旨在开发并评估一个名为GLM-4.5的开源大语言模型,该模型不仅具备上述三种核心能力,而且能够在各种实际应用场景中表现出色。具体而言,研究目标包括:
- 验证GLM-4.5在智能体特性、推理和编码任务上的性能:通过一系列基准测试,评估GLM-4.5在这些任务上的表现,并与现有的开源和专有模型进行比较。
- 探索并优化模型的混合推理方法:研究支持“思考”和“直接响应”两种模式的混合推理方法,以提升模型在处理复杂任务时的灵活性和效率。
- 发布模型及工具:通过开源GLM-4.5及其精简版本GLM-4.5-Air,以及提供一个评估工具包,推动推理和智能体人工智能系统的研究。
研究方法
模型架构:
GLM-4.5采用了混合专家(MoE)架构,总参数量为3550亿,激活参数量为320亿。该架构通过减少模型宽度(隐藏维度和路由专家数量)并增加深度(层数),提高了推理能力。同时,模型在自注意力组件中引入了分组查询注意力(GQA)和部分旋转位置嵌入(RoPE),进一步提升了性能。
预训练数据:
预训练数据集涵盖了网页、社交媒体、书籍、论文和代码库等多个来源。为了提高模型在推理任务上的表现,研究团队特别收集了与数学和科学相关的文档,并根据教育内容比例进行评分和采样。代码数据则来自GitHub和各种代码托管平台,经过初步过滤和分类后,采用填充中间(Fill-In-the-Middle)训练目标进行处理。
多阶段训练:
GLM-4.5的训练过程分为预训练和中期训练两个阶段。预训练阶段主要在大规模通用文档上进行,而中期训练阶段则利用特定领域的域数据集进行性能提升,包括仓库级代码训练、合成推理数据训练和长上下文及智能体训练。
后训练:
后训练过程分为专家模型训练和统一训练两个阶段。在专家模型训练阶段,构建了专门针对推理、智能体和通用聊天的专家模型。随后,在统一训练阶段,通过自我蒸馏技术将多个专家的能力整合到一个综合模型中,使其能够通过深思熟虑的推理和直接响应模式生成回答。
研究结果
基准测试性能:
GLM-4.5在12个ARC基准测试中表现出色,总体排名第三,智能体基准测试中排名第二。具体而言,GLM-4.5在TAU-Bench上得分为70.1%,在BFCL v3上得分为77.8%,在BrowseComp上得分为26.4%,显示出与Claude Sonnet 4相当的智能体能力。在推理任务上,GLM-4.5在AIME24上得分为91.0%,在GPQA上得分为79.1%,在LiveCodeBench上得分为72.9%。在编码任务上,GLM-4.5在SWE-bench Verified上得分为64.2%,在Terminal-Bench上得分为37.5%,超过了GPT-4.1和Gemini-2.5-Pro。
混合推理方法的有效性:
GLM-4.5的混合推理方法显著提升了模型在处理复杂任务时的灵活性和效率。通过支持“思考”和“直接响应”两种模式,模型能够根据任务需求自动选择合适的推理策略,从而在保证准确性的同时提高响应速度。
模型效率与可扩展性:
GLM-4.5在参数效率方面表现出色,其激活参数量远低于多个竞争对手,但性能却名列前茅。此外,研究还发布了GLM-4.5-Air这一精简版本,进一步证明了模型架构的可扩展性和效率。
研究局限
数据质量和多样性的挑战:
尽管研究团队在数据收集和处理方面付出了巨大努力,但数据的质量和多样性仍然对模型性能产生了一定影响。特别是在处理长尾知识和罕见概念时,模型的表现仍有提升空间。
评估基准的局限性:
现有的基准测试可能无法完全反映模型在实际应用中的表现。部分基准测试可能存在数据污染或设计上的缺陷,导致评估结果存在偏差。
模型大小的权衡:
虽然GLM-4.5在参数效率方面表现出色,但更大的模型往往意味着更高的训练和推理成本。如何在保持高性能的同时进一步减小模型大小,是未来研究需要解决的问题。
未来研究方向
持续优化模型架构和训练方法:
未来的研究可以进一步探索更高效的模型架构和训练策略,以在保持高性能的同时降低计算成本。例如,通过改进进的神经网络架构设计、优化训练算法和参数效率,提升模型的整体表现。
增强数据多样性和质量:
为了提高模型的泛化能力和鲁棒性,未来的研究可以聚焦于收集和生成更多样化、更高质量的数据集。特别是针对特定领域和复杂任务的数据增强方法,将有助于模型更好地适应各种实际应用场景。
更全面的评估框架:
开发更全面、更细致的评估框架,以准确衡量模型在各种复杂任务上的表现。引入多维度评估指标和真实场景测试,将有助于更真实地反映模型的实际能力和局限性。
跨领域和跨任务应用:
将GLM-4.5的研究成果应用于其他领域和任务,如医疗、教育、金融等,验证其普适性和有效性。通过跨领域应用,可以进一步挖掘大语言模型的潜力,推动人工智能技术在更多实际场景中的落地。