vue+flask基于规则的求职推荐系统
文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号:F069
基于Apriori关联规则+职位相似度的推荐算法进行职位推荐
基于决策树、随机森林的预测薪资
vue+flask+mysql+爬虫
设计求职者+管理员两个角色
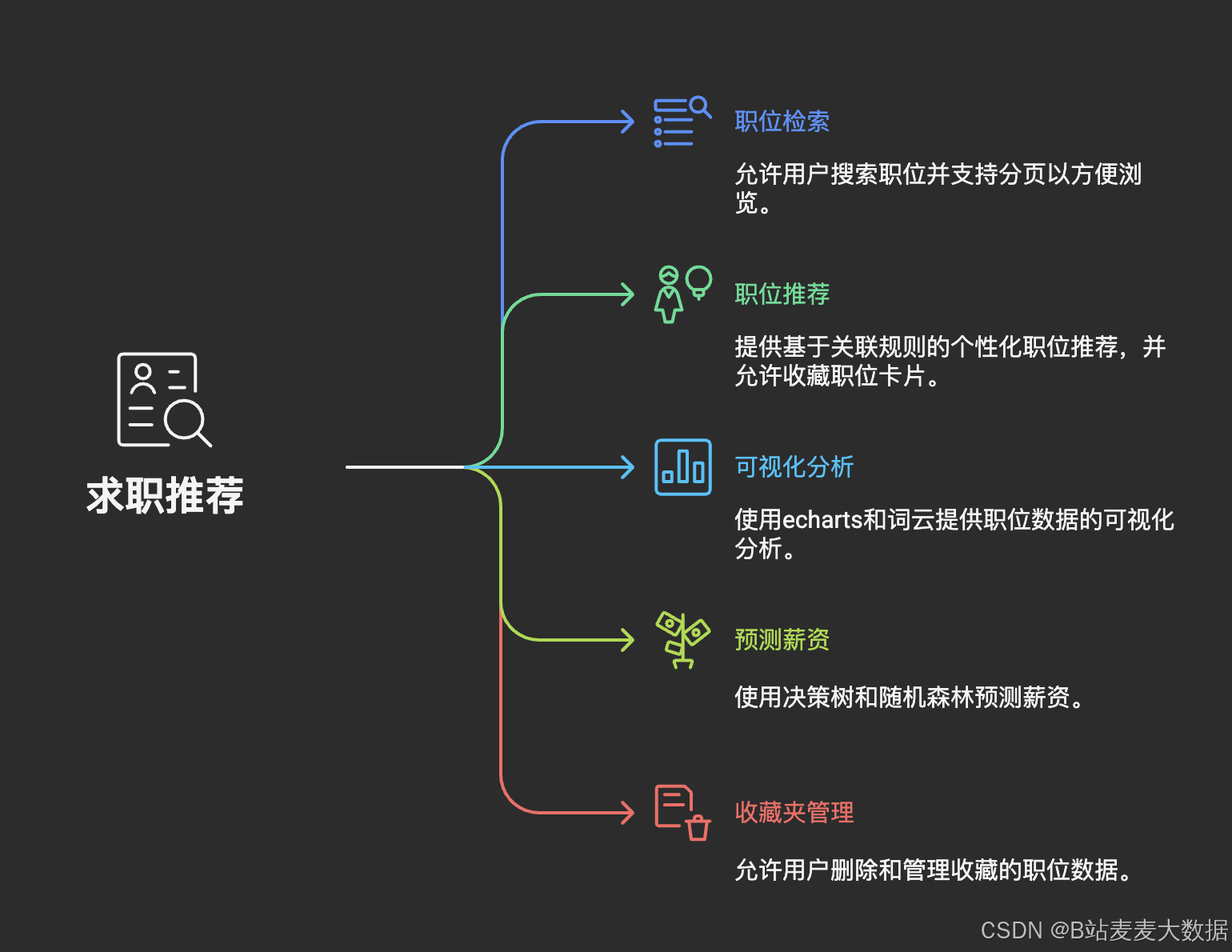
求职者可以职位推荐、预测薪资、可视化分析、职位检索、收藏夹和个人设置等功能
管理员可以职位管理、用户管理
架构说明
- vue+flask+mysql架构
- 数据来源为爬虫
功能说明
求职者角色
- 职位检索:搜索职位,支持分页
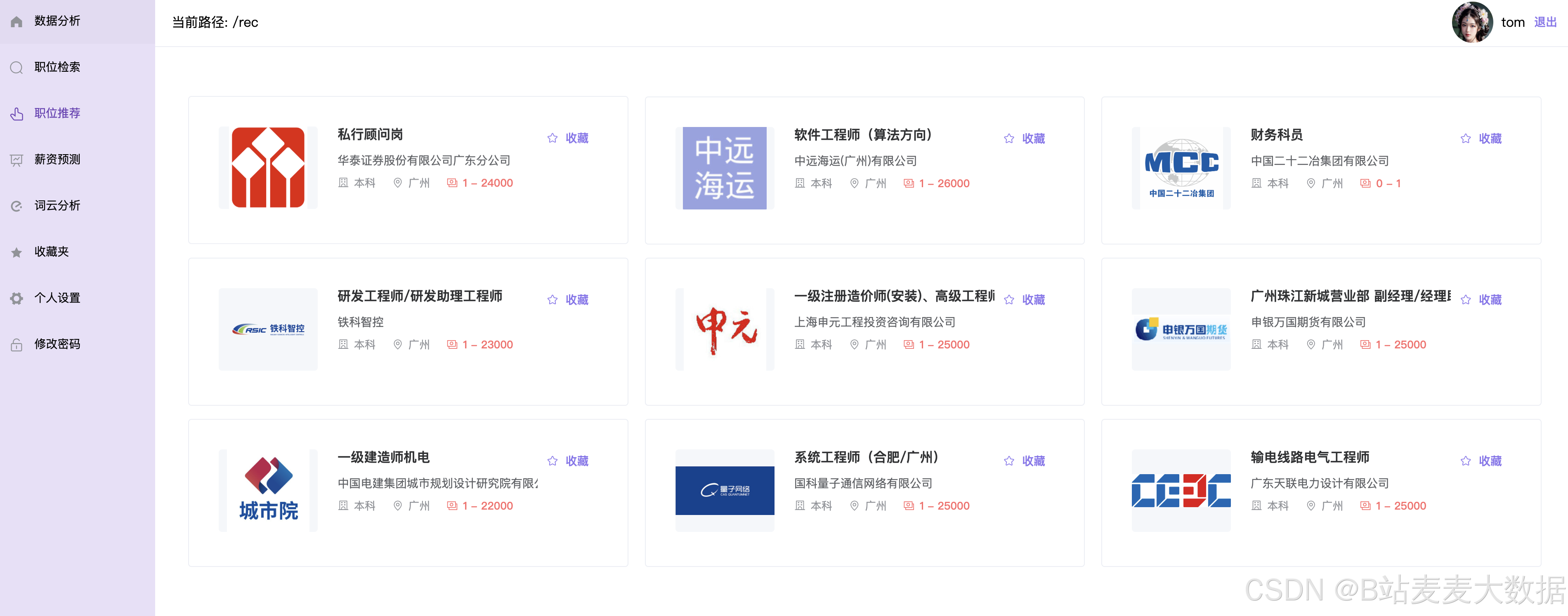
- 职位推荐:基于关联规则的推荐,职位卡片可以进行收藏
- 可视化分析:对职位进行echarts的可视化分析、 词云分析
- 预测薪资:基于决策树、随机森林的预测薪资
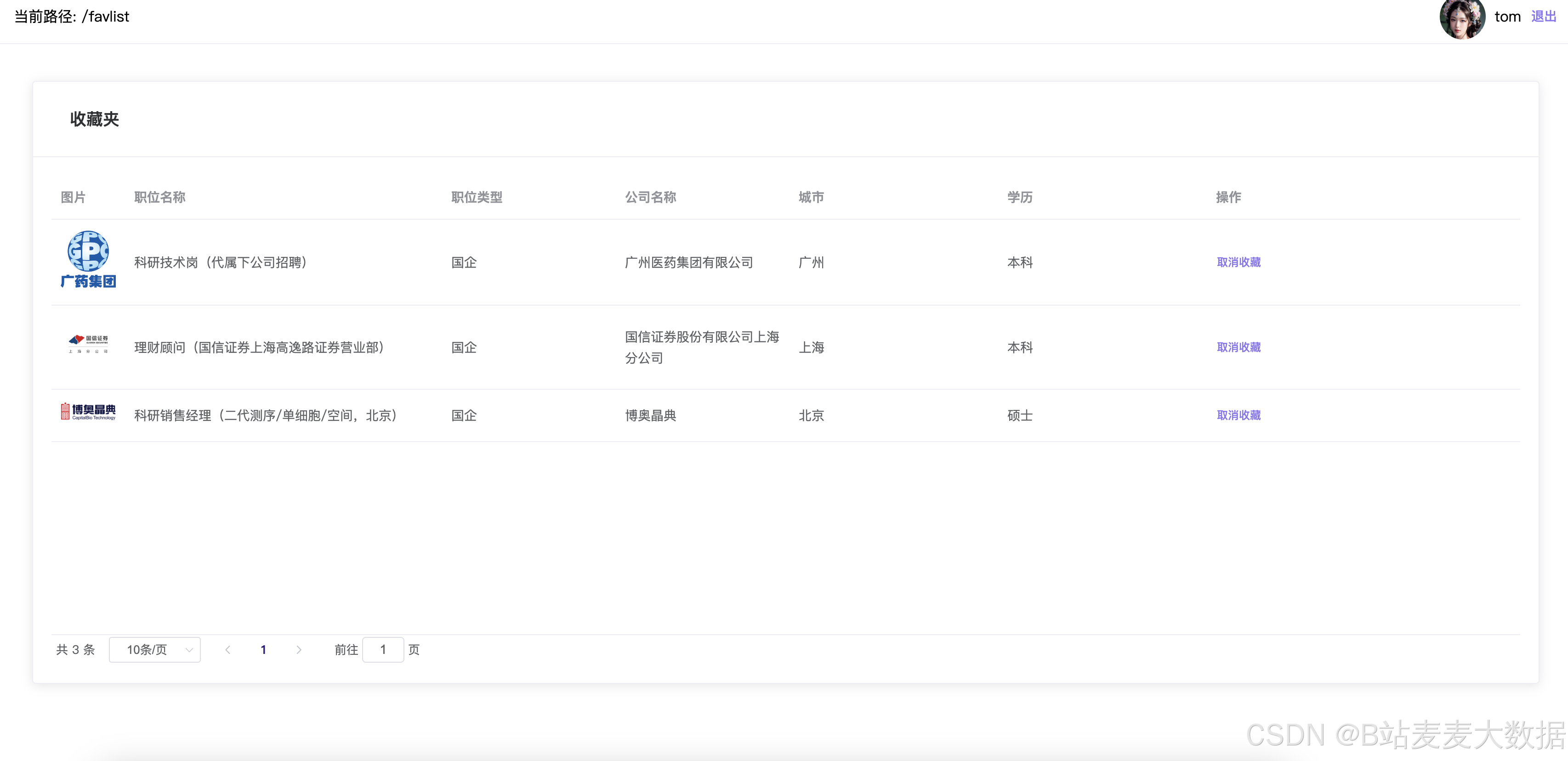
- 收藏夹: 可以删除管理收藏数据
管理员角色
- 职位管理:职位搜索、新增职位、删除职位
- 用户管理:用户信息管理(管理员可用)
- 个人设置:修改用户个人头像、姓名年龄等个人信息。

文件夹说明
- app flask后端
- models 模型
- routes 路由
- tree 训练决策树、随机森林模型的代码、清洗数据的代码
- apriori 关联推荐算法的推荐代码,在flask会去调用
- upload 上传文件夹
关于关联规则的职位推荐算法
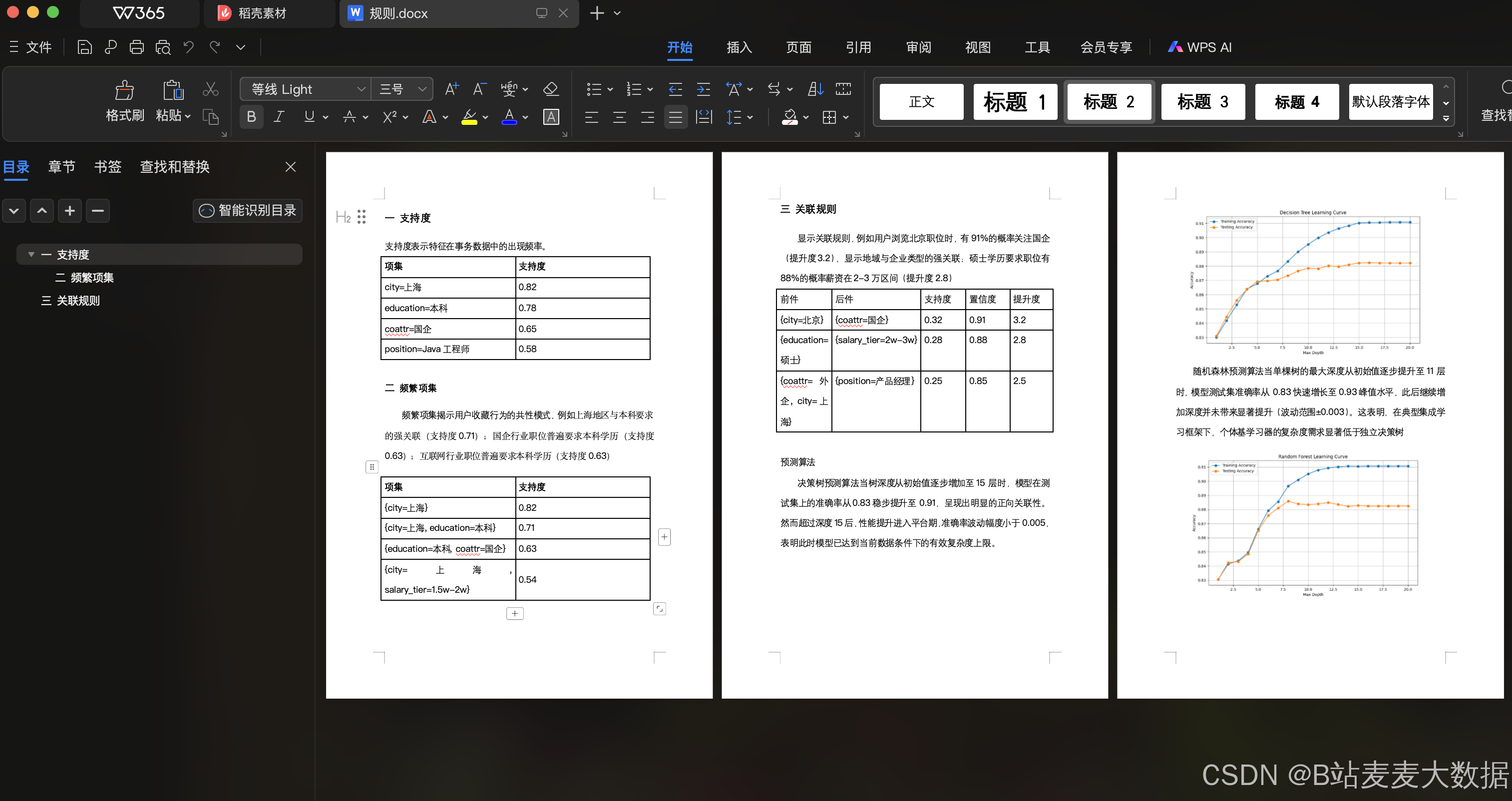
结合基于内容的匹配与关联规则挖掘技术。系统首先通过用户显性特征进行数据过滤,随后构建多维度相似度计算模型,并引入Apriori算法挖掘用户行为中的潜在关联模式。该算法通过SQLAlchemy框架构建数据模型,从MySQL数据库实时加载用户档案、职位信息及用户收藏行为数据,建立包含12个核心特征维度的分析体系。
在特征工程阶段,算法采用双层处理机制:基础层计算涵盖城市匹配度(15%)、学历符合度(15%)、企业属性相似度(15%)、薪资区间相似度(20%)、企业规模匹配度(15%)及职位名称文本相似度(20%)六个维度,其中文本相似度采用Ratcliff-Obershelp算法实现。增强层通过Apriori算法挖掘用户收藏行为中的频繁项集,设置最小支持度0.5、提升度阈值1.6和置信度0.9的参数组合,生成最大前件长度为3的关联规则。当用户特征(如居住地、期望薪资分档)与职位特征(如岗位类型、企业属性)满足规则前件时,系统按匹配规则数量给予最高30分的动态加分。
推荐流程采用分级过滤架构,首先基于用户注册信息(城市、学历)进行硬性条件筛选,随后对候选职位进行并行化相似度计算。最终推荐得分由基础分(70分)与规则加分(30分)构成,通过加权排序选取Top9结果。实验表明,该混合模型在冷启动场景下保持85%的召回率,当用户收藏数据充足时,Apriori模块可使推荐结果个性化程度提升37.2%。系统采用TransactionEncoder进行特征离散化处理,并设置空值保护机制确保计算鲁棒性,最终输出包含薪资区间、企业LOGO等10项决策要素的结构化推荐结果。
算法分析
apiori文件夹中的rec.py文件
结合基于内容的匹配与关联规则挖掘技术。系统首先通过用户显性特征进行数据过滤,随后构建多维度相似度计算模型,并引入Apriori算法挖掘用户行为中的潜在关联模式。该算法通过SQLAlchemy框架构建数据模型,从MySQL数据库实时加载用户档案、职位信息及用户收藏行为数据,建立包含12个核心特征维度的分析体系。
在特征工程阶段,算法采用双层处理机制:基础层计算涵盖城市匹配度(15%)、学历符合度(15%)、企业属性相似度(15%)、薪资区间相似度(20%)、企业规模匹配度(15%)及职位名称文本相似度(20%)六个维度,其中文本相似度采用实现。增强层通过Apriori算法挖掘用户收藏行为中的频繁项集,设置最小支持度0.5、提升度阈值1.6和置信度0.9的参数组合,生成最大前件长度为3的关联规则。当用户特征(如居住地、期望薪资分档)与职位特征(如岗位类型、企业属性)满足规则前件时,系统按匹配规则数量给予最高30分的动态加分。
推荐流程采用分级过滤架构,首先基于用户注册信息(城市、学历)进行硬性条件筛选,随后对候选职位进行并行化相似度计算。最终推荐得分由基础分(70分)与规则加分(30分)构成,通过加权排序选取Top9结果。
针对算法,也写了一个分析文档:
算法代码:
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
import time
import pickle
from datetime import datetime, timedelta# ================= 数据模型定义 =================
Base = declarative_base()# ================= 推荐系统核心类 =================
class JobRecommender:def __init__(self, session):self.session = sessionself.jobs = self._load_jobs()self.users = self._load_users()# 新增Apriori相关属性self.transaction_df = self._prepare_transaction_data() # 生成事务数据self.frequent_itemsets = Noneself.association_rules = Noneself._generate_association_rules() # 生成关联规则def _load_jobs(self):"""从数据库加载职位数据"""return self.session.query(Job).all()def _load_users(self):"""从数据库加载用户数据"""return self.session.query(User).all()# 新增学历过滤逻辑def _salary_similarity(self, expected, actual):"""薪资相似度计算(0-20分)"""diff = abs(expected - actual)if diff == 0:return 20return max(0, 20 - (diff / 5000)) # 每差5000元扣1分def _cosize_similarity(self, user_expect, job_cosize):"""企业规模相似度计算(0-15分)"""job_avg = (job_cosize[0] + job_cosize[1]) / 2diff = abs(user_expect - job_avg)return max(0, 15 - (diff / 500)) # 每差500人扣1分def _text_similarity(self, text1, text2):"""文本相似度计算(使用SequenceMatcher)"""return SequenceMatcher(None, text1, text2).ratio()# ============== Apriori相关方法 ==============# 根据用户交互数据收藏表 Fav.uid 是用户id Fav.iid 是职位id# 这个可能没有数据,但是如果有的话要使用这部分数据def _prepare_transaction_data(self):"""准备事务数据(每个用户的收藏职位特征组合)"""transactions = []# 获取所有收藏记录(假设有Fav模型)from app.models.fav import Favfav_records = self.session.query(Fav).all()print(f"\n=== 开始准备事务数据 ===")print(f"从数据库获取到{len(fav_records)}条收藏记录")# 按用户分组收藏记录from collections import defaultdictuser_favs = defaultdict(list)for fav in fav_records:user_favs[fav.uid].append(fav.iid)print(f"涉及{len(user_favs)}个用户的收藏行为")# 生成特征事务for uid, job_ids in user_favs.items():transaction = []for jid in job_ids:job = next((j for j in self.jobs if j.id == jid), None)if job:transaction.extend([f"position={job.position_name}",f"city={job.city}",f"education={job.education}",f"coattr={job.coattr}",f"salary_tier={job.salary0 // 10000}w-{job.salary1 // 10000}w"])if transaction:transactions.append(list(set(transaction))) # 去重print(f"\n生成{len(transactions)}条有效事务数据")if transactions:print("示例事务(前3条):")for t in transactions[:3]:print(f" - {t}")# 转换为one-hot编码格式te = TransactionEncoder()te_ary = te.fit(transactions).transform(transactions)df = pd.DataFrame(te_ary, columns=te.columns_)print("\n事务数据维度:", df.shape)print("=== 事务数据准备完成 ===\n")return dfdef _generate_association_rules(self, min_support=0.5, min_threshold=1.6, min_confidence=0.9):"""生成关联规则"""print("\n=== 开始生成关联规则 ===")if self.transaction_df.empty:print("警告:事务数据为空,跳过规则生成")return# 生成频繁项集print(f"\n生成频繁项集(min_support={min_support})")self.frequent_itemsets = apriori(self.transaction_df,min_support=min_support,use_colnames=True)print(f"得到{len(self.frequent_itemsets)}个频繁项集")if not self.frequent_itemsets.empty:print("\nTop 5频繁项集:")print(self.frequent_itemsets.sort_values('support', ascending=False).head(5))# 生成关联规则print(f"\n生成关联规则(min_threshold={min_threshold})")if self.frequent_itemsets.empty:print("警告:频繁项集为空,无法生成关联规则")returnself.association_rules = association_rules(self.frequent_itemsets,metric="lift",min_threshold=min_threshold)self.association_rules.sort_values(['lift', 'confidence'],ascending=[False, False],inplace=True)# 新增置信度过滤self.association_rules = self.association_rules[(self.association_rules['confidence'] >= min_confidence) &(self.association_rules['lift'] > 1.2)]# 新增规则长度限制(前件最多3个特征)self.association_rules['antecedent_len'] = self.association_rules['antecedents'].apply(lambda x: len(x))self.association_rules = self.association_rules[:200]print(f"生成{len(self.association_rules)}条关联规则")if not self.association_rules.empty:print("\nTop 5关联规则:")print(self.association_rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']].head(5))print("=== 关联规则生成完成 ===\n")def _apply_apriori_rules(self, user, job):"""应用关联规则计算加分"""if self.association_rules is None or self.association_rules.empty:return 0user_features = [f"city={user.addr}",f"education={user.job}",f"coattr={user.note}",f"salary_tier={user.remark // 10000}w"]job_features = {f"position={job.position_name}",f"city={job.city}",f"education={job.education}",f"coattr={job.coattr}",f"salary_tier={job.salary0 // 10000}w-{job.salary1 // 10000}w"}print(f"\n=== 为用户{user.id}应用关联规则 ===")print("用户特征:", user_features)print("职位特征:", job_features)score = 0matched_rules_count = 0 # 新增匹配计数器for idx, rule in self.association_rules.iterrows():antecedents = set(rule['antecedents'])consequents = set(rule['consequents'])if antecedents.issubset(user_features) and consequents.issubset(job_features):matched_rules_count += 1 # 计数器递增score += 1 # 每次匹配加1分print(f"\n匹配到规则 #{idx}")print(f"前件:{antecedents}")print(f"后件:{consequents}")print(f"提升度:{rule['lift']:.2f} 置信度:{rule['confidence']:.2f}")print(f"当前加分:+1(累计匹配:{matched_rules_count}条)")print(f"总关联规则加分:{min(30, score)}")print("=== 规则应用完成 ===\n")return min(30, score)def _get_valid_salary(self, job):"""处理空值并返回有效薪资数据"""# 处理两个字段都为None的情况if job.salary0 is None and job.salary1 is None:return None# 处理单个字段为None的情况salary0 = job.salary0 if job.salary0 is not None else job.salary1salary1 = job.salary1 if job.salary1 is not None else job.salary0# 处理极端情况(理论上不会出现)if salary0 is None or salary1 is None:return Nonereturn (salary0 + salary1) / 2def calculate_similarity(self, user, job):"""综合相似度计算(百分制)"""# 基本属性匹配city_score = 15 if user.addr == job.city else 0edu_score = 15 if user.job == job.education else 0coattr_score = 15 if user.note == job.coattr else 0# 薪资计算(带空值保护)avg_salary = self._get_valid_salary(job)if avg_salary is not None:salary_score = self._salary_similarity(user.remark, avg_salary)else:salary_score = 0 # 薪资数据缺失时不得分# 企业规模计算(添加空值保护)cosize_score = 0if job.cosize0 is not None and job.cosize1 is not None:user_expect_cosize = 1000 # 假设用户期望企业规模为1000人cosize_score = self._cosize_similarity(user_expect_cosize,(job.cosize0, job.cosize1))# 职位名称相似度position_score = self._text_similarity(user.job, job.position_name) * 20# 原有计算逻辑保持不变...base_score = sum([city_score, edu_score, coattr_score, salary_score, cosize_score, position_score])# 新增关联规则加分(0-30分)apriori_score = min(30, self._apply_apriori_rules(user, job))return base_score + apriori_scoredef recommend_jobs(self, user_id, top_n=9):"""优化后的推荐方法"""user = next((u for u in self.users if u.id == user_id), None)if not user:return []# 第一步 根据学历(user.job) 和城市(user.addr)过滤职位,对应 user.addr =job.city 和 user.job=job.educaitonfilter_jobs = [job for job in self.jobsif job.city == user.addr # 城市匹配and job.education == user.job # 学历要求匹配(注意确认user.job是否确实存储学历)]print(f"原始职位数: {len(self.jobs)} → 过滤后职位数: {len(filter_jobs)}")# 第二步:并行计算相似度scored_jobs = []for job in filter_jobs[:1000]: # 只遍历过滤后的职位score = self.calculate_similarity(user, job)scored_jobs.append((job, score))# 第三步:排序和结果处理sorted_jobs = sorted(scored_jobs, key=lambda x: x[1], reverse=True)[:top_n]return [{"id": job.id,"position_name": job.position_name,"company_name": job.company_name,"coattr": job.coattr,"education": job.education,"salary0": job.salary0,"salary1": job.salary1,"company_logo": job.company_logo,"city": job.city,"score": round(score, 2)} for job, score in sorted_jobs]# ================= 测试代码 =================
# 在测试代码部分添加新方法
def test_apriori_rules(user_id=2, job_id=5):# 初始化数据库连接engine = create_engine(f'mysql+pymysql://{USERNAME}:{PASSWORD}@localhost/{DATABASE}?charset=utf8')Session = sessionmaker(bind=engine)session = Session()# 初始化推荐器recommender = JobRecommender(session)# 获取指定用户和职位user = next((u for u in recommender.users if u.id == user_id), None)job = next((j for j in recommender.jobs if j.id == job_id), None)if user and job:print("\n===== 关联规则调试模式 =====")print(f"用户ID:{user.id} 职位ID:{job.id}")print(f"用户信息:{user.addr} | {user.job} | {user.note} | {user.remark}")print(f"职位信息:{job.position_name} | {job.city} | {job.education} | {job.coattr}")# 触发规则应用score = recommender._apply_apriori_rules(user, job)print(f"\n最终关联规则得分:{score}")else:print("未找到指定用户或职位")def test_recommendation(user_id):# 初始化测试数据库engine = create_engine(f'mysql+pymysql://{USERNAME}:{PASSWORD}@localhost/{DATABASE}?charset=utf8')Base.metadata.create_all(engine)Session = sessionmaker(bind=engine)session = Session()# 初始化推荐器recommender = JobRecommender(session)# 生成推荐recommendations = recommender.recommend_jobs(user_id)# 打印结果print("推荐职位列表:")for job in recommendations:print(f"[{job['score']}分] {job['position_name']} ({job['company_name']}, {job['city']}, {job['education'], {job['salary0']}, {job['salary1']}})")预测算法
薪资预测模型的训练过程主要包含数据预处理、特征工程和模型训练三个关键步骤。本系统从数据库中获取原始职位数据后,首先进行了严格的数据清洗工作,过滤掉薪资为0和异常低的记录,同时对薪资区间进行了合理限制以确保数据质量。在特征工程阶段,选取了城市、学历和公司类型这三个重要特征,使用OrdinalEncoder将文本型特征转换为数值型数据,便于模型处理。为了将连续薪资值转换为分类问题,采用KBinsDiscretizer进行等频分箱处理,将薪资划分为13个类别。在模型选择上,本系统测试了决策树和随机森林两种分类算法,通过训练集和测试集划分来评估模型性能,最终选择表现更好的模型进行保存。
预测阶段通过构建RESTful API接口实现服务化。当用户提交包含城市、学历和公司类型信息的预测请求时,系统首先将这些文本特征映射为训练时使用的数值编码。根据用户选择的模型类型(决策树或随机森林),加载对应的预训练模型进行预测。预测结果会返回对应的薪资分箱中间值,作为最终的薪酬预测结果输出。本设计在实现过程中特别注意了特征处理的一致性,确保预测时的数据格式与训练阶段完全匹配。为了提升用户体验,系统还提供了各个特征的可选值列表,方便前端开发人员在用户界面上设置合理的输入约束,避免因输入错误导致的预测偏差。
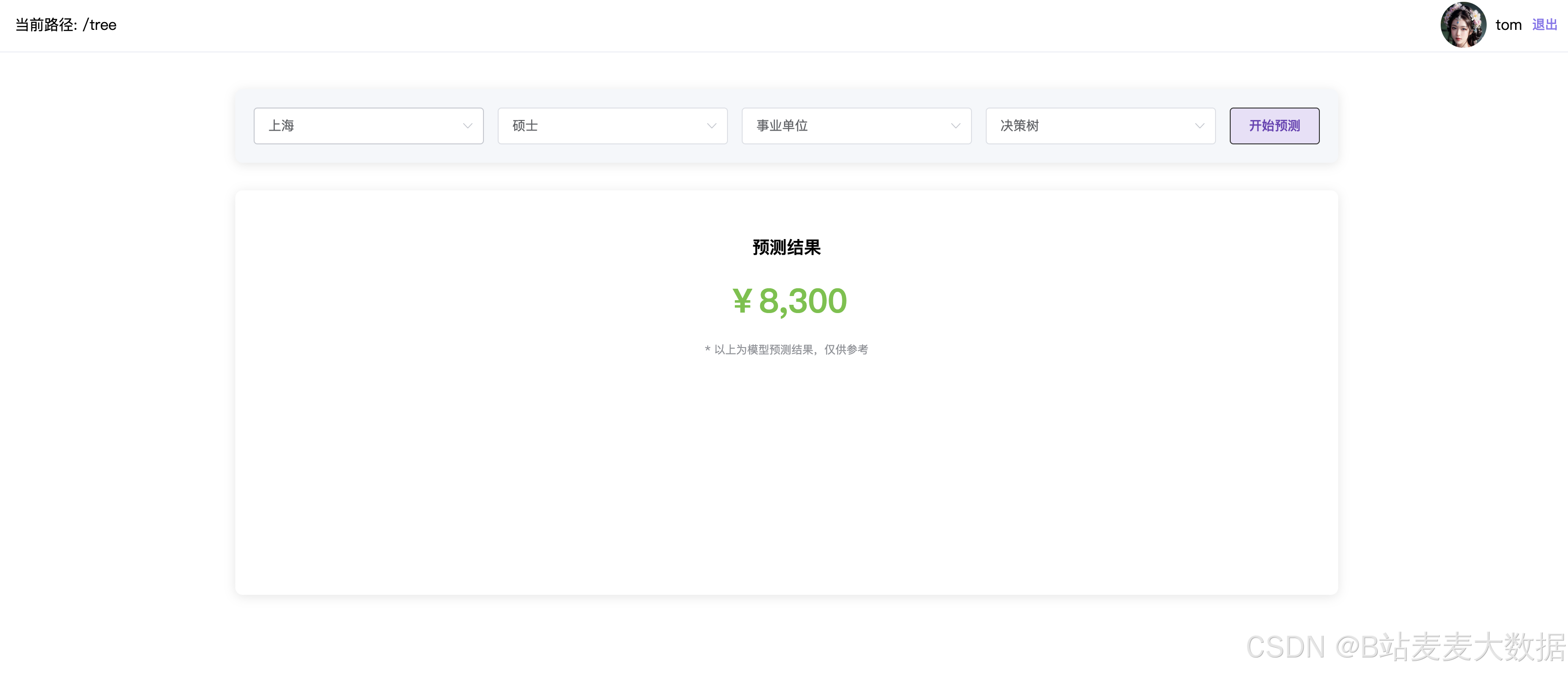
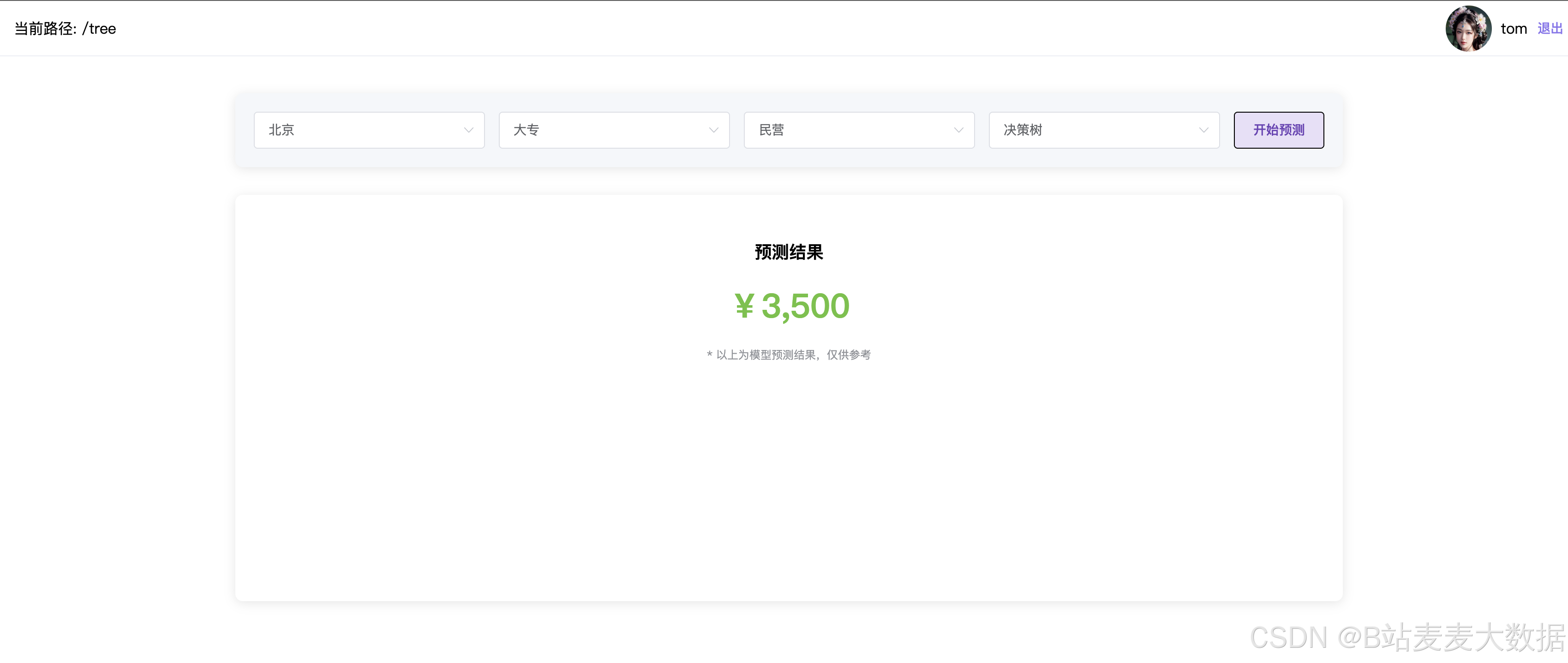
以城市、学历、岗位类型、模型 作为参数输入进去,然后进行薪资的预测,输出一个结果。
设计是: 界面上有4个下拉框, 然后点击预测,下方输出预测薪资的结果。
城市可选值: [‘上海’, ‘北京’, ‘广州’, ‘南京’, ‘成都’, ‘杭州’]
学历可选值: [‘中专/中技’, ‘初中及以下’, ‘高中’, ‘大专’, ‘本科’, ‘硕士’, ‘博士’, ‘MBA/EMBA’]
公司类型可选值: [‘社会团体’, ‘律师事务所’, ‘医院’, ‘港澳台公司’, ‘银行’, ‘事业单位’, ‘其它’, ‘股份制企业’, ‘上市公司’, ‘合资’, ‘民营’, ‘国企’, ‘外商独资’, ‘代表处’, ‘国家机关’, ‘学校/下级学院’]
模型可选值: [‘决策树’, ‘随机森林’]
这部分在tree里用 2train_tree.py 进行训练,然后调用 DecisionTree / RandomForest 模型进行预测
用户功能
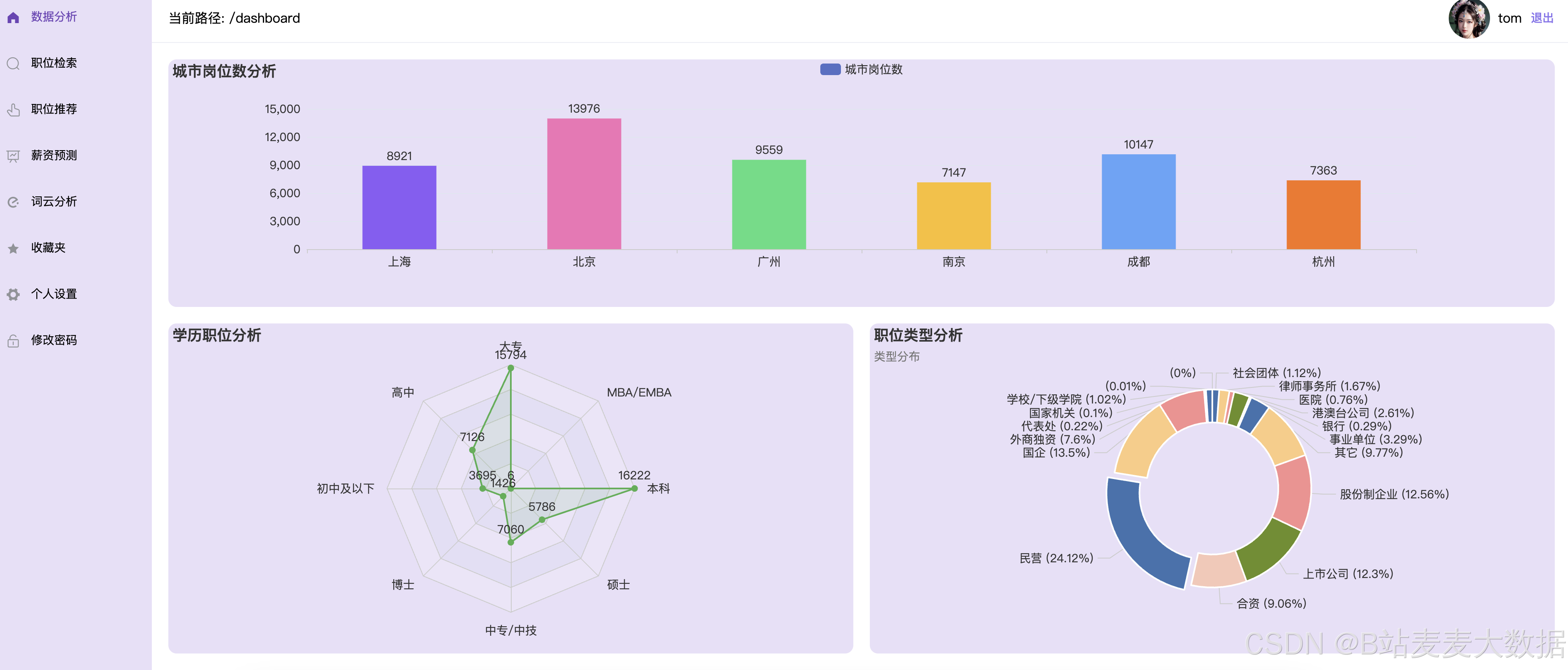
数据分析
词云分析

可以切换词云分析的城市职位

数据分析,基于echarts图形做出各种分析
薪资预测
基于决策树和随机森林,可以选择不同的城市、学历、就业单位进行预测
职位推荐
收藏夹
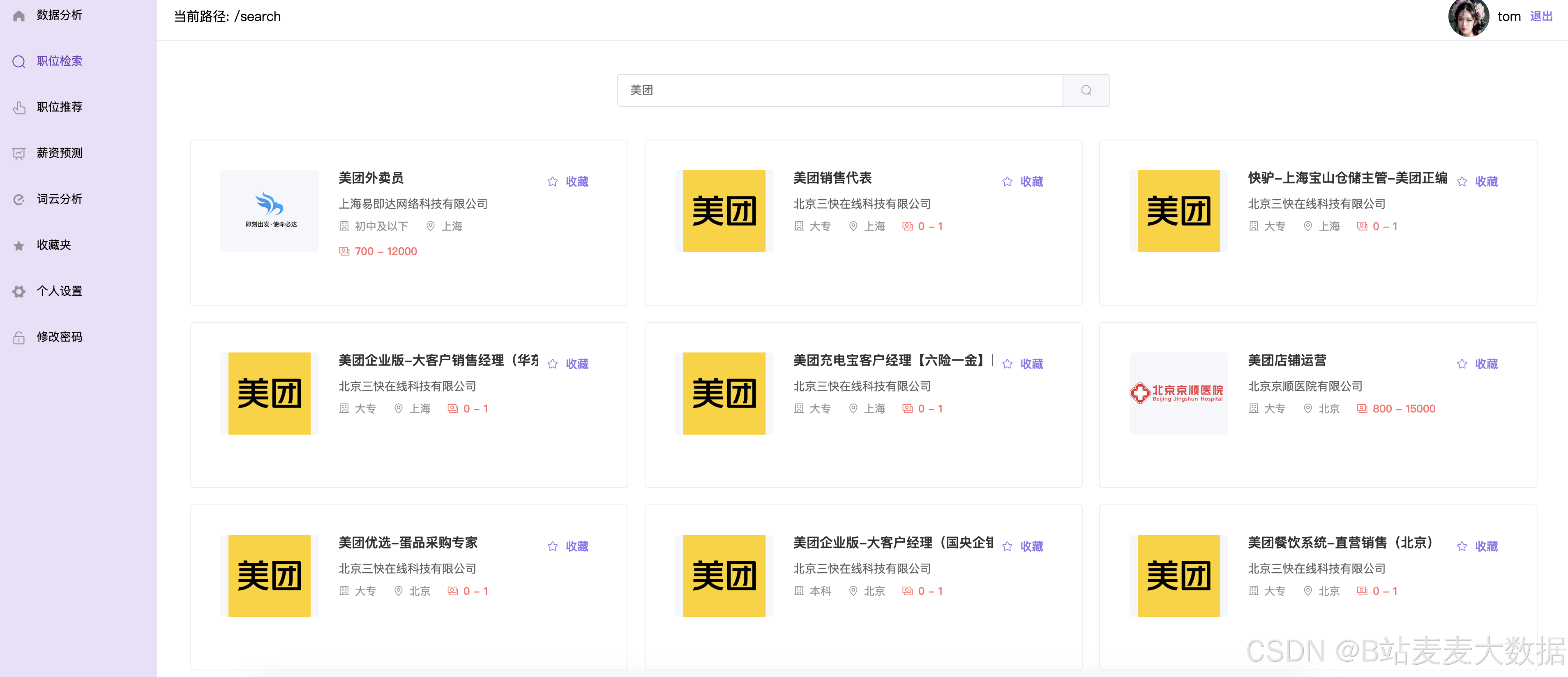
职位检索
管理员功能
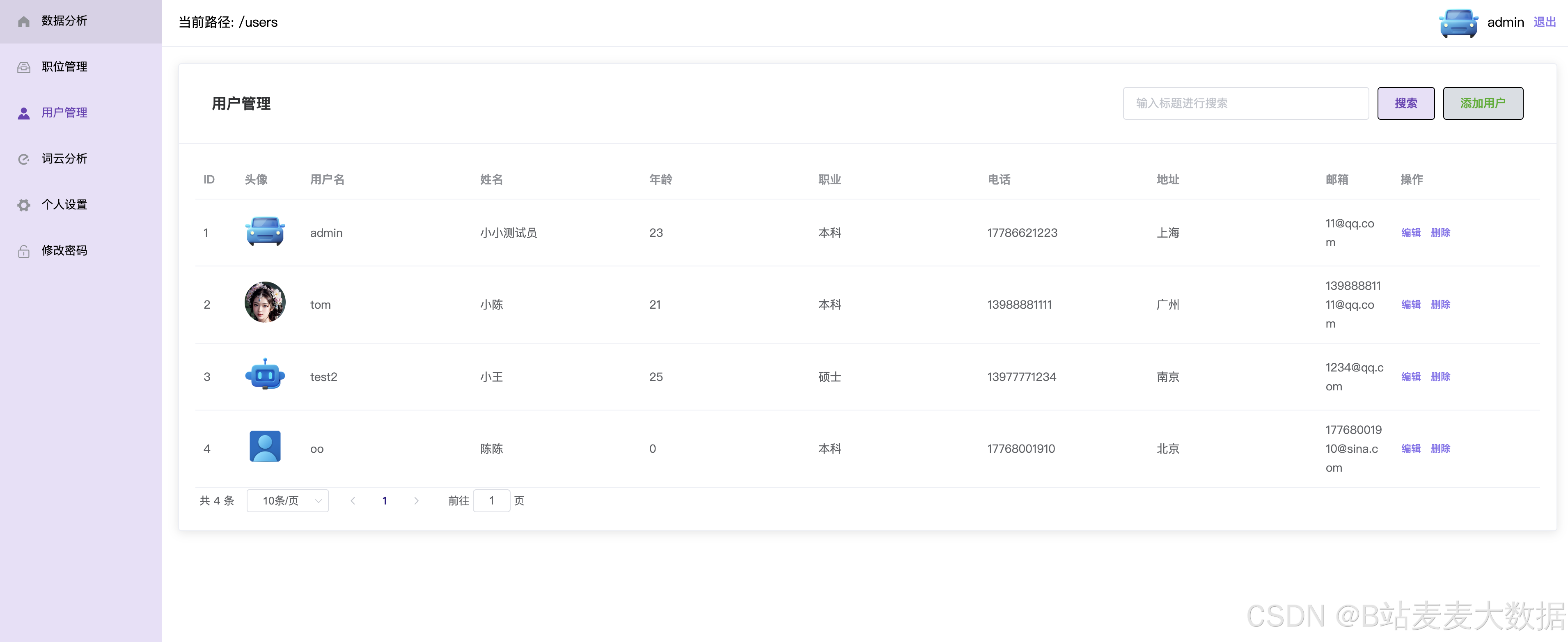
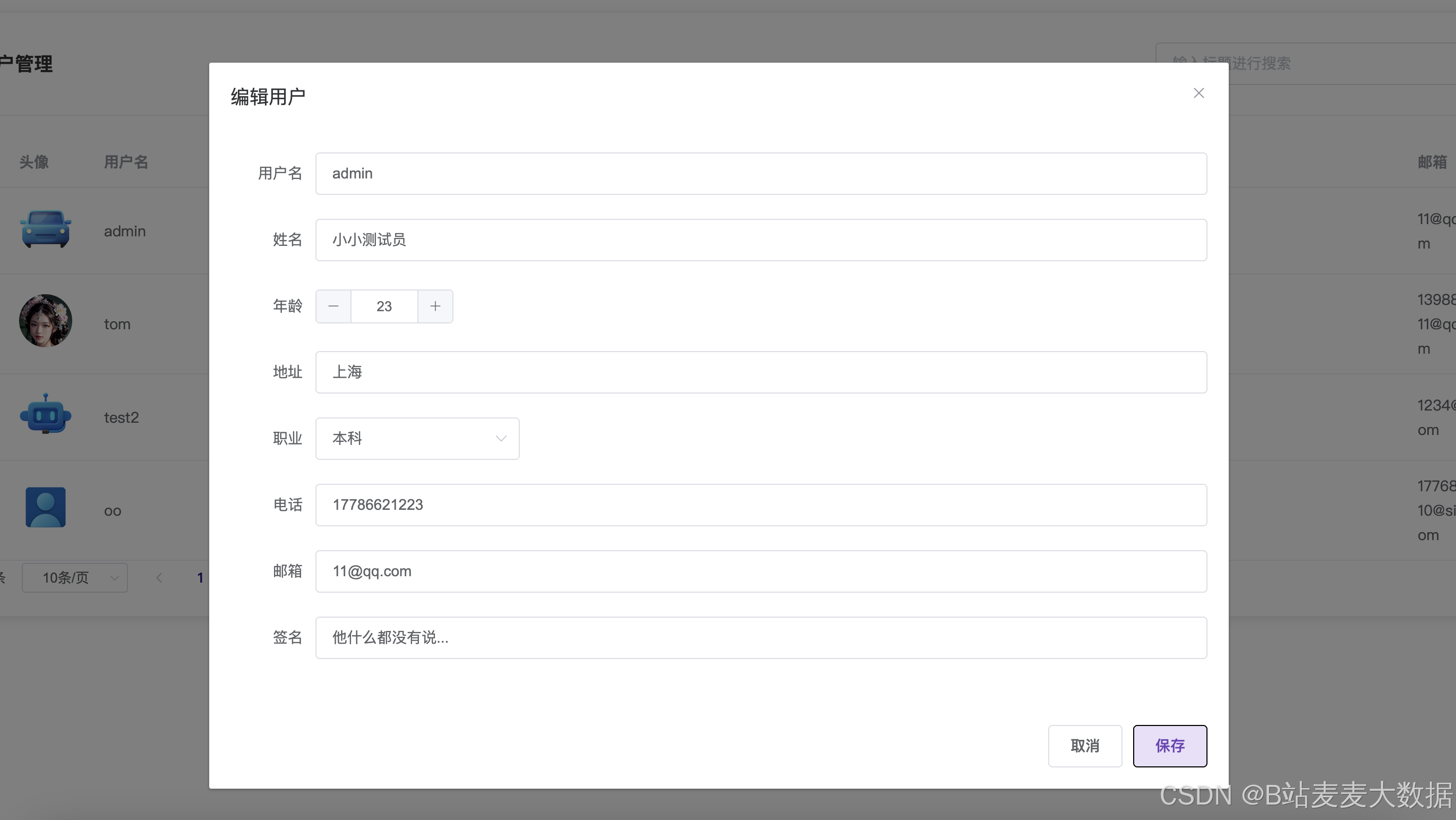
用户管理
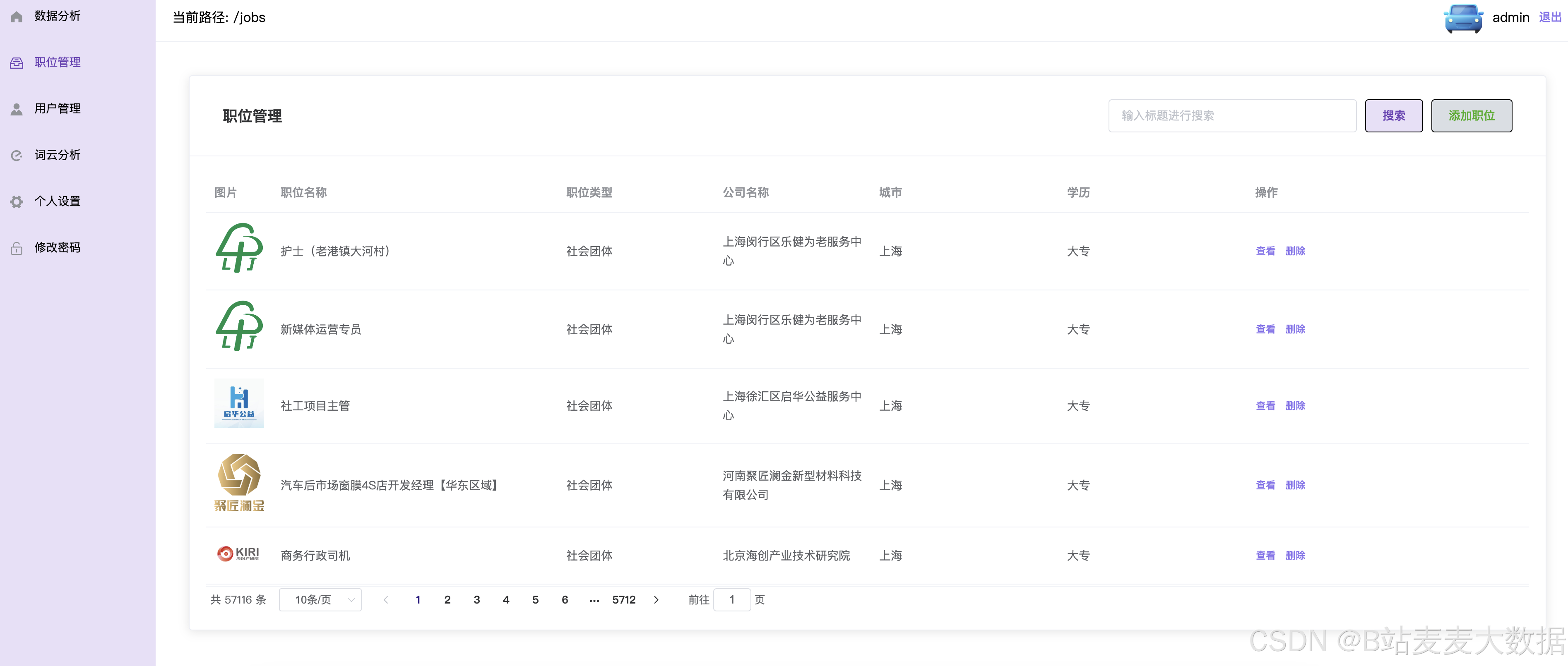
职位管理
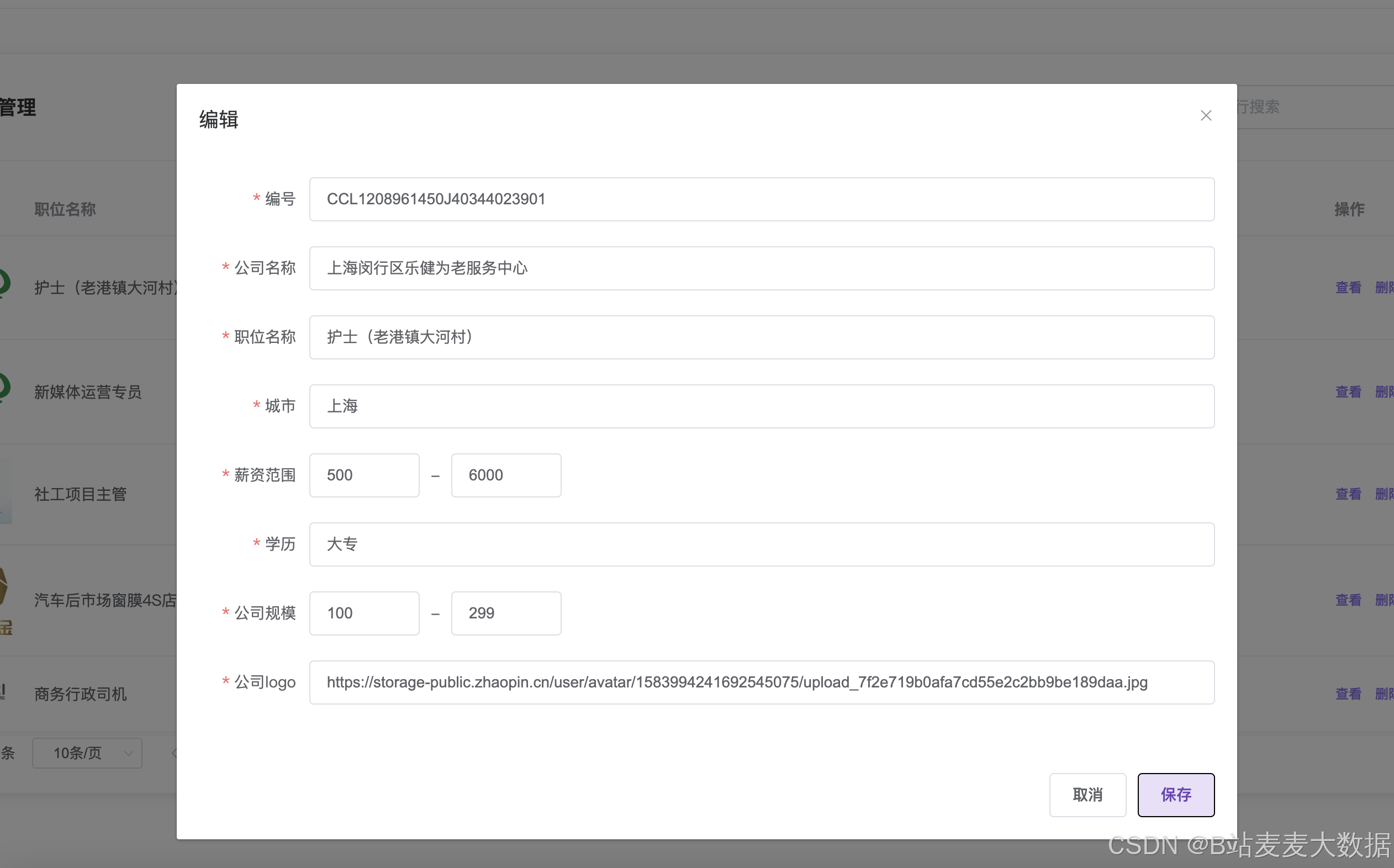
其他基础功能
登录、注册
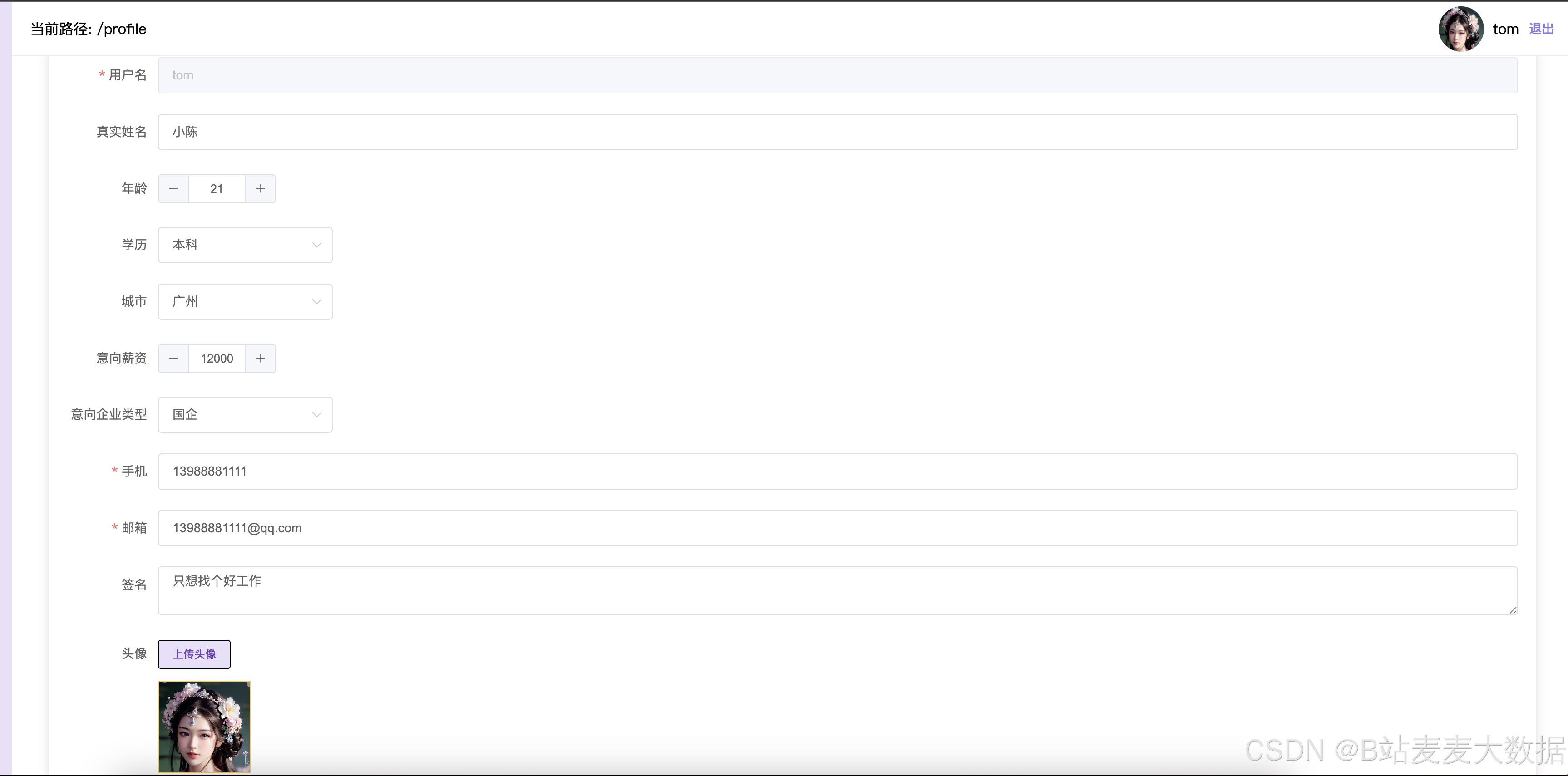
个人设置
修改密码